












































![@yourtwitterhandle | developer.confluent.io
{
final Properties props = KafkaProducerApplication.loadProperties(args[0]);
final String topic = props.getProperty(“output.topic.name”);
final Producer<String, String> producer = new KafkaProducer<>(props);
final KafkaProducerApplication producerApp = new KafkaProducerApplication(producer, topic);
}](https://image.slidesharecdn.com/apache-kafka-101-240503020318-30c2f512/85/Apache-Kafka-101-by-Confluent-Developer-Friendly-46-320.jpg)




![@yourtwitterhandle | developer.confluent.io
{
final Properties consumerAppProps = KafkaConsumerApplication.loadProperties(args[0]);
final String filePath = consumerAppProps.getProperty(“file.path”);
final Consumer<String, String> consumer = new KafkaConsumer<>(consumerAppProps);
final ConsumerRecordsHandler<String, String> recordsHandler = new FilewritingrecordsHandler(Paths.get(filePa …
final KafkaConsumerapplication consumerApplication = new KafkaConsumerApplication(consumer, recordsHandler);](https://image.slidesharecdn.com/apache-kafka-101-240503020318-30c2f512/85/Apache-Kafka-101-by-Confluent-Developer-Friendly-51-320.jpg)
























































































Ad
More Related Content
Similar to Apache Kafka 101 by Confluent Developer Friendly (20)
Recently uploaded (20)


















Ad
Apache Kafka 101 by Confluent Developer Friendly
- 2. @yourtwitterhandle | developer.confluent.io What’s Covered 1. Introduction 2. Hands On: Your First Kafka Application in 10 Minutes or Less 3. Topics 4. Partitioning 5. Hands On: Partitioning 6. Brokers 7. Replication 8. Producers 9. Consumers 10.Hands On: Consumers 11.Ecosystem 12.Kafka Connect 13.Hands On: Kafka Connect 14.Confluent Schema Registry 15.Hands On: Confluent Schema Registry 16.Kafka Streams 17.ksqlDB 18.Hands On: ksqlDB
- 3. Introduction
- 4. @yourtwitterhandle | developer.confluent.io Event ● Internet of Things
- 5. @yourtwitterhandle | developer.confluent.io Event ● Internet of Things ● Business process change
- 6. @yourtwitterhandle | developer.confluent.io Event ● Internet of Things ● Business process change ● User Interaction
- 7. @yourtwitterhandle | developer.confluent.io Event ● Internet of Things ● Business process change ● User Interaction ● Microservice output
- 10. Hands On: Your First Kafka Application in 10 Minutes or Less
- 11. GET STARTED TODAY Confluent Cloud cnfl.io/confluent-cloud PROMO CODE: KAFKA101 $101 of free usage
- 12. @yourtwitterhandle | developer.confluent.io Hands On: Your First Kafka Application in 10 Minutes or Less
- 13. Topics
- 15. @yourtwitterhandle | developer.confluent.io Topics ● Named container for similar events
- 16. @yourtwitterhandle | developer.confluent.io Topics ● Named container for similar events ○ System contains lots of topics ○ Can duplicate data between topics
- 17. @yourtwitterhandle | developer.confluent.io Topics ● Named container for similar events ○ System contains lots of topics ○ Can duplicate data between topics ● Durable logs of events
- 18. @yourtwitterhandle | developer.confluent.io Topics ● Named container for similar events ○ System contains lots of topics ○ Can duplicate data between topics ● Durable logs of events ○ Append only
- 19. @yourtwitterhandle | developer.confluent.io Topics ● Named container for similar events ○ System contains lots of topics ○ Can duplicate data between topics ● Durable logs of events ○ Append only ○ Can only seek by offset, not indexed
- 20. @yourtwitterhandle | developer.confluent.io Topics ● Named container for similar events ○ System contains lots of topics ○ Can duplicate data between topics ● Durable logs of events ○ Append only ○ Can only seek by offset, not indexed ● Events are immutable
- 21. @yourtwitterhandle | developer.confluent.io Topics are durable
- 22. @yourtwitterhandle | developer.confluent.io Retention period is configurable
- 23. Partitioning
- 24. @yourtwitterhandle | developer.confluent.io Partition 0 Partition 1 Partition 2 Partitioned Topic
- 25. @yourtwitterhandle | developer.confluent.io Partition 0 Partition 1 Partition 2
- 26. @yourtwitterhandle | developer.confluent.io Partition 0 Partition 1 Partition 2
- 27. @yourtwitterhandle | developer.confluent.io Partition 0 Partition 1 Partition 2 1 4 7 2 5 8 3 6 9 #
- 28. @yourtwitterhandle | developer.confluent.io Partition 0 Partition 1 Partition 2 1 2 3 4 5 7 6 8 9 #
- 29. @yourtwitterhandle | developer.confluent.io Partition 0 Partition 1 Partition 2 # 1 2 3 4 5 7 6 8 9
- 31. @yourtwitterhandle | developer.confluent.io Hands On: Partitioning
- 32. Brokers
- 33. @yourtwitterhandle | developer.confluent.io Brokers ● An computer, instance, or container running the Kafka process
- 34. @yourtwitterhandle | developer.confluent.io Brokers ● An computer, instance, or container running the Kafka process ● Manage partitions ● Handle write and read requests
- 35. @yourtwitterhandle | developer.confluent.io Brokers ● An computer, instance, or container running the Kafka process ● Manage partitions ● Handle write and read requests ● Manage replication of partitions
- 36. @yourtwitterhandle | developer.confluent.io Brokers ● An computer, instance, or container running the Kafka process ● Manage partitions ● Handle write and read requests ● Manage replication of partitions ● Intentionally very simple
- 37. Replication
- 38. @yourtwitterhandle | developer.confluent.io Partition 0 Partition 1 Partition 2 Partitioned Topic
- 39. @yourtwitterhandle | developer.confluent.io Replication ● Copies of data for fault tolerance
- 40. @yourtwitterhandle | developer.confluent.io Replication ● Copies of data for fault tolerance ● One lead partition and N-1 followers
- 41. @yourtwitterhandle | developer.confluent.io Replication ● Copies of data for fault tolerance ● One lead partition and N-1 followers ● In general, writes and reads happen to the leader
- 42. @yourtwitterhandle | developer.confluent.io Replication ● Copies of data for fault tolerance ● One lead partition and N-1 followers ● In general, writes and reads happen to the leader ● An invisible process to most developers
- 43. @yourtwitterhandle | developer.confluent.io Replication ● Copies of data for fault tolerance ● One lead partition and N-1 followers ● In general, writes and reads happen to the leader ● An invisible process to most developers ● Tunable in the producer
- 44. Producers
- 45. @yourtwitterhandle | developer.confluent.io Partition 0 Partition 1 Partition 2 Partitioned Topic Producer
- 46. @yourtwitterhandle | developer.confluent.io { final Properties props = KafkaProducerApplication.loadProperties(args[0]); final String topic = props.getProperty(“output.topic.name”); final Producer<String, String> producer = new KafkaProducer<>(props); final KafkaProducerApplication producerApp = new KafkaProducerApplication(producer, topic); }
- 47. @yourtwitterhandle | developer.confluent.io { final ProducerRecord<String, String> producerRecord = new ProducerRecord<>(outTopic, key, value); return producer.send(producerRecord); }
- 48. @yourtwitterhandle | developer.confluent.io Producers ● Client application ● Puts messages into topics ● Connection pooling ● Network buffering ● Partitioning
- 49. @yourtwitterhandle | developer.confluent.io Partition 0 Partition 1 Partition 2 Partitioned Topic Producer
- 50. Consumers
- 51. @yourtwitterhandle | developer.confluent.io { final Properties consumerAppProps = KafkaConsumerApplication.loadProperties(args[0]); final String filePath = consumerAppProps.getProperty(“file.path”); final Consumer<String, String> consumer = new KafkaConsumer<>(consumerAppProps); final ConsumerRecordsHandler<String, String> recordsHandler = new FilewritingrecordsHandler(Paths.get(filePa … final KafkaConsumerapplication consumerApplication = new KafkaConsumerApplication(consumer, recordsHandler);
- 52. @yourtwitterhandle | developer.confluent.io @ public void runConsume(final Properties consumerProps) { try { consumer.subscribe(Collections.singletonList(consumerProps.getProperty(“input.topic.name”))); while (keepConsuming) { final ConsumerRecords<String, String> consumerRecords =vconsumer.poll(Duration.ofSeconds(1)); recordsHandler.process(consumerRecords); }
- 53. @yourtwitterhandle | developer.confluent.io @ public void process(final ConsumerRecords<String, String> consumerRecords) { final List<String> valueList = new ArrayList<>(); consumerRecords.forEach(record -> valueList.add(record.value())); if (!valueList.isEmpty()) { try { Files.write(path, valueList, StandardOpenOption.CREATE, StandardOpenOption.WRITE, StandardOpenOption … } catch (IOException e) { throw new RuntimeException(e); } } }
- 54. @yourtwitterhandle | developer.confluent.io Consumers ● Client application ● Reads messages from topics ● Connection pooling ● Network protocol ● Horizontally and elastically scalable ● Maintains ordering within partitions at scale
- 55. @yourtwitterhandle | developer.confluent.io Partition 0 Partition 1 Partition 2 Partitioned Topic Consumer A Consumer B
- 56. @yourtwitterhandle | developer.confluent.io Partition 0 Partition 1 Partition 2 Partitioned Topic Consumer A
- 57. @yourtwitterhandle | developer.confluent.io Partition 0 Partition 1 Partition 2 Partitioned Topic Consumer A Consumer A Consumer B
- 58. @yourtwitterhandle | developer.confluent.io java application > configuration > dev.properties 1 group.id=movie_ratings 2 3 bootstrap.servers=localhost:29092 4 5 key.serializer=org.apache.kafka.common.serialization.StringSerializer 6 value.serializer=org.apache.kafka.common.serialization.StringSerializer 7 acks=all 8 9 #Properties below this line are specific to code in this application 10 input.topic.name=input-topic 11 output.topic.name=output-topic
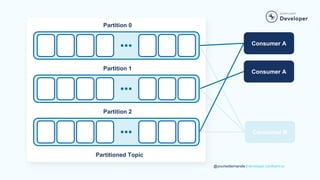
- 59. @yourtwitterhandle | developer.confluent.io Partition 0 Partition 1 Partition 2 Partitioned Topic Consumer A Consumer A Consumer B Consumer A
- 61. @yourtwitterhandle | developer.confluent.io Hands On: Consumers
- 62. Ecosystem
- 63. Kafka Connect
- 64. @yourtwitterhandle | developer.confluent.io Kafka Connect ● Data integration system and ecosystem ● Because some other systems are not Kafka ● External client process; does not run on brokers
- 65. @yourtwitterhandle | developer.confluent.io Cluster Data Source Kafka Connect Kafka Connect Data Sink
- 66. @yourtwitterhandle | developer.confluent.io Kafka Connect ● Data integration system and ecosystem ● Because some other systems are not Kafka ● External client process; does not run on brokers ● Horizontally scalable ● Fault tolerant
- 67. @yourtwitterhandle | developer.confluent.io { “connector.class”: “io.confluent.connect.elasticsearch.ElasticsearchSinkConnector”, “connector.url”: “http://elasticsearch:9200”, “tasks.max”: “1”, “topics”: “simple.elasticsearch.data”, “name”: “simple-elasticsearch-connector”, “type.name”: “doc”, “value.converter”: “org.apache.kafka.connect.json.JsonConverter” “value.converter.schemas.enable”: “false” }
- 68. @yourtwitterhandle | developer.confluent.io Kafka Connect ● Data integration system and ecosystem ● Because some other systems are not Kafka ● External client process; does not run on brokers ● Horizontally scalable ● Fault tolerant ● Declarative
- 69. @yourtwitterhandle | developer.confluent.io Connectors ● Pluggable software component
- 70. @yourtwitterhandle | developer.confluent.io Connectors ● Pluggable software component ● Interfaces to external system and to Kafka
- 71. @yourtwitterhandle | developer.confluent.io Connectors ● Pluggable software component ● Interfaces to external system and to Kafka ● Also exist as runtime entities
- 72. @yourtwitterhandle | developer.confluent.io Connectors ● Pluggable software component ● Interfaces to external system and to Kafka ● Also exist as runtime entities ● Source connectors act as producers
- 73. @yourtwitterhandle | developer.confluent.io Connectors ● Pluggable software component ● Interfaces to external system and to Kafka ● Also exist as runtime entities ● Source connectors act as producers ● Sink connectors act as consumers
- 75. Hands On: Kafka Connect
- 76. @yourtwitterhandle | developer.confluent.io Hands On: Kafka Connect
- 78. @yourtwitterhandle | developer.confluent.io New consumers will emerge
- 79. @yourtwitterhandle | developer.confluent.io Schemas evolve with the business
- 80. @yourtwitterhandle | developer.confluent.io Schema Registry ● Server process external to Kafka brokers
- 81. @yourtwitterhandle | developer.confluent.io Schema Registry ● Server process external to Kafka brokers ● Maintains a database of schemas
- 82. @yourtwitterhandle | developer.confluent.io Schema Registry ● Server process external to Kafka brokers ● Maintains a database of schemas ● HA deployment option available
- 83. @yourtwitterhandle | developer.confluent.io Schema Registry ● Server process external to Kafka brokers ● Maintains a database of schemas ● HA deployment option available ● Consumer/Producer API component
- 84. @yourtwitterhandle | developer.confluent.io Schema Registry ● Defines schema compatibility rules per topic
- 85. @yourtwitterhandle | developer.confluent.io Schema Registry ● Defines schema compatibility rules per topic ● Producer API prevents incompatible messages from being produced
- 86. @yourtwitterhandle | developer.confluent.io Schema Registry ● Defines schema compatibility rules per topic ● Producer API prevents incompatible messages from being produced ● Consumer API prevents incompatible messages from being consumer
- 87. @yourtwitterhandle | developer.confluent.io Supported Formats ● JSON Schema ● Avro ● Protocol Buffers
- 88. Hands On: Confluent Schema Registry
- 89. @yourtwitterhandle | developer.confluent.io Hands On: Confluent Schema Registry
- 90. Kafka Streams
- 91. @yourtwitterhandle | developer.confluent.io Kafka Streams ● Functional Java API
- 92. @yourtwitterhandle | developer.confluent.io Kafka Streams ● Functional Java API ● Filtering, grouping, aggregating, joining, and more
- 93. @yourtwitterhandle | developer.confluent.io Kafka Streams ● Functional Java API ● Filtering, grouping, aggregating, joining, and more ● Scalable, fault-tolerant state management
- 94. @yourtwitterhandle | developer.confluent.io Kafka Streams ● Functional Java API ● Filtering, grouping, aggregating, joining, and more ● Scalable, fault-tolerant state management ● Scalable computation based on consumer groups
- 95. @yourtwitterhandle | developer.confluent.io Kafka Streams ● Integrates within your services as a library
- 96. @yourtwitterhandle | developer.confluent.io Kafka Streams ● Integrates within your services as a library ● Runs in the context of your application
- 97. @yourtwitterhandle | developer.confluent.io Kafka Streams ● Integrates within your services as a library ● Runs in the context of your application ● Does not require special infrastructure
- 98. @yourtwitterhandle | developer.confluent.io Insert Code: https://youtu.be/UbNoL5tJEjc?t=443
- 99. ksqlDB
- 100. @yourtwitterhandle | developer.confluent.io ksqlDB ● A database optimized for stream processing
- 101. @yourtwitterhandle | developer.confluent.io ksqlDB ● A database optimized for stream processing ● Runs on its own scalable, fault-tolerant cluster adjacent to the Kafka cluster
- 102. @yourtwitterhandle | developer.confluent.io ksqlDB ● A database optimized for stream processing ● Runs on its own scalable, fault-tolerant cluster adjacent to the Kafka cluster ● Stream processing programs written in SQL
- 103. @yourtwitterhandle | developer.confluent.io src > main > ksql > rate-movies.sql 1 2 CREATE TABLE rated_movies AS 3 SELECT title, 4 SUM(rating)/COUNT(rating) AS avg_rating 5 FROM ratings 6 INNER JOIN movies 7 ON ratings.movie_id=movies.movie_id 8 GROUP BY title EMIT CHANGES;
- 104. @yourtwitterhandle | developer.confluent.io ksqlDB ● Command line interface ● REST API for application integration
- 105. @yourtwitterhandle | developer.confluent.io ksqlDB ● Command line interface ● REST API for application integration ● Java library
- 106. @yourtwitterhandle | developer.confluent.io ksqlDB ● Command line interface ● REST API for application integration ● Java library ● Kafka Connect integration
- 107. Hands On: ksqlDB
- 108. @yourtwitterhandle | developer.confluent.io Hands On: ksqlDB
- 109. Your Apache Kafka journey begins here developer.confluent.io