Apache Pinot Case Study: Building Distributed Analytics Systems Using Apache Kafka (Neha Pawar, Stealth Mode Startup) Kafka Summit 2020
0 likes7,769 views

The document describes Apache Pinot, an open source distributed real-time analytics platform used at LinkedIn. It discusses the challenges of building user-facing real-time analytics systems at scale. It initially describes LinkedIn's use of Apache Kafka for ingestion and Apache Pinot for queries, but notes challenges with Pinot's initial Kafka consumer group-based approach for real-time ingestion, such as incorrect results, limited scalability, and high storage overhead. It then presents Pinot's new partition-level consumption approach which addresses these issues by taking control of partition assignment and checkpointing, allowing for independent and flexible scaling of individual partitions across servers.
































Apache Pinot Case Study: Building Distributed Analytics Systems Using Apache Kafka (Neha Pawar, Stealth Mode Startup) Kafka Summit 2020
- 1. @apachepinot | @KishoreBytes Apache Pinot Case Study Building distributed analytics systems using Apache Kafka
- 3. @apachepinot | @KishoreBytes Pinot @LinkedIn
- 4. @apachepinot | @KishoreBytes 70+ Products Pinot @ LinkedIn User Facing Analytics 120k+ queries/sec ms - 1s latency
- 5. @apachepinot | @KishoreBytes Pinot @ LinkedIn Business Metrics Analytics 10k+ Metrics 50k+ Dimensions
- 6. @apachepinot | @KishoreBytes Pinot @ LinkedIn ThirdEye: Anomaly detection and root cause analysis 50+ Teams 100K Time Series
- 7. @apachepinot | @KishoreBytes Apache Pinot @ Other Companies 2.7k Github StarsSlack UsersCompanies 400+20+ Community has tripled in the last two quarters Join our growing community on the Apache Pinot Slack Channel https://communityinviter.com/apps/apache-pinot/apache-pinot
- 8. @apachepinot | @KishoreBytes User Facing Applications Business Facing Metrics Anomaly Detection Time Series Multiple Use Cases: One Platform Kafka 70+ 10k 100k 120k Queries/secEvents/sec 1M+
- 9. @apachepinot | @KishoreBytes Challenges of User facing real-time analytics Velocity of ingestion High Dimensionality 1000s of QPS Milliseconds Latency Seconds Freshness Highly Available Scalable Cost Effective User-facing real-time analytics system
- 10. @apachepinot | @KishoreBytes Pinot Real-time Ingestion Deep Dive
- 11. @apachepinot | @KishoreBytes Pinot Architecture Servers Brokers Queries Scatter Gather ● Servers - Consuming, indexing, serving ● Brokers - Scatter gather
- 12. @apachepinot | @KishoreBytes Server 1 Deep Store Pinot Realtime Ingestion Basics ● Kafka Consumer on Pinot Server ● Periodically create “Pinot segment” ● Persist to deep store ● In memory data - queryable ● Continue consumption
- 13. @apachepinot | @KishoreBytes Kafka Consumer Groups Approach 1
- 14. @apachepinot | @KishoreBytes Kafka Consumer Group based design ● Each consumer consumes from 1 or more partitions Server 2Server 1 time 3 partitions Consumer Group Kafka Consumer Kafka Consumer ● Periodic checkpointing ● Kafka Rebalancer Server1 starts consuming from 0 and 2 Checkpoint 350 Checkpoint 400 seg1 seg2 Kafka Rebalancer ● Fault tolerant consumption
- 15. @apachepinot | @KishoreBytes Challenges with Capacity Expansion Server 2S1 Add Server3 Partition 2 moves to Server 3 Server3 begins consumption from 400time Server 3 Duplicate Data! 3 partitions Kafka Consumer Kafka Consumer Consumer Group Kafka Consumer Checkpoint 350 Checkpoint 400 seg1 seg2 Kafka Rebalancer Server1 starts consuming from 0 and 2
- 16. @apachepinot | @KishoreBytes Deep store Multiple Consumer Groups Consumer Group 1 Consumer Group 2 3 partitions 2 replicas ● No control over partitions assigned to consumer ● No control over checkpointing ● Segment disparity Queries Fault tolerant ● Storage inefficient
- 17. @apachepinot | @KishoreBytes Operational Complexity Queries Consumer Group 1 Consumer Group 2 3 partitions 2 replicas ● Disable consumer group for node failure/capacity changes
- 18. @apachepinot | @KishoreBytes Server 4 Scalability limitation Queries Consumer Group 1 Consumer Group 2 3 partitions 2 replicas ● Scalability limited by #partitions Idle ● Cost inefficient
- 19. @apachepinot | @KishoreBytes Single node in a Consumer Group ● Eliminates incorrect results ● Reduced operational complexity Server 1 Server 2 ● Limited by capacity of 1 node ● Storage overhead ● Scalability limitation Consumer Group 1 Consumer Group 2 3 partitions 2 replicas The only deployment model that worked
- 20. @apachepinot | @KishoreBytes Incorrect Results Operational Complexity Storage overhead Limited scalability Expensive Multi-node Consumer Group Y Y Y Y Y Single-node Consumer Group Y Y Y Issues with Kafka Consumer Group based solution
- 21. @apachepinot | @KishoreBytes Problem 1 Lack of control with Kafka Rebalancer Solution Take control of partition assignment
- 22. @apachepinot | @KishoreBytes Problem 2 Segment Disparity due to checkpointing mechanism Solution Take control of checkpointing
- 23. @apachepinot | @KishoreBytes Partition Level Consumption Approach 2
- 24. @apachepinot | @KishoreBytes S1 S3 Partition Level Consumption Controller S23 partitions 2 replicas Partition Server State Start offset End offset S1 S2 CONSUMING CONSUMING 20 S3 S1 CONSUMING CONSUMING 20 S2 S3 CONSUMING CONSUMING 20 0 1 2 Cluster State ● Single coordinator across all replicas ● All actions determined by cluster state
- 25. @apachepinot | @KishoreBytes Deep Store S1 S3 Partition Level Consumption Controller S23 partitions 2 replicas Partition Server State Start offset End offset 0 S1 S2 CONSUMING CONSUMING 20 1 S3 S1 CONSUMING CONSUMING 20 2 S2 S3 CONSUMING CONSUMING 20 Cluster State Commit 80 110 110ONLINE ONLINE ● Only 1 server persists segment to deep store ● Only 1 copy stored
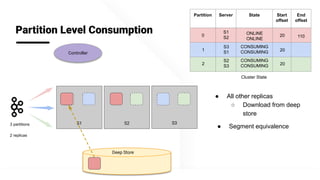
- 26. @apachepinot | @KishoreBytes Deep Store S1 S3 Partition Level Consumption Controller S23 partitions 2 replicas Partition Server State Start offset End offset 0 S1 S2 20 1 S3 S1 CONSUMING CONSUMING 20 2 S2 S3 CONSUMING CONSUMING 20 Cluster State 110 ONLINE ONLINE ● All other replicas ○ Download from deep store ● Segment equivalence
- 27. @apachepinot | @KishoreBytes Deep Store S1 S3 Partition Level Consumption Controller S23 partitions 2 replicas Partition Server State Start offset End offset 0 S1 S2 ONLINE ONLINE 20 110 1 S3 S1 CONSUMING CONSUMING 20 2 S2 S3 CONSUMING CONSUMING 20 Cluster State 0 S1 S2 CONSUMING CONSUMING 110 ● New segment state created ● Start where previous segment left off
- 28. @apachepinot | @KishoreBytes Deep Store S1 S3 Partition Level Consumption Controller S23 partitions 2 replicas Partition Server State Start offset End offset 0 S1 S2 ONLINE ONLINE 20 110 1 S3 S1 ONLINE ONLINE 20 120 2 S2 S3 ONLINE ONLINE 20 100 Cluster State 0 S1 S2 CONSUMING CONSUMING 110 1 S3 S1 CONSUMING CONSUMING 120 2 S2 S3 CONSUMING CONSUMING 100 ● Each partition independent of others
- 29. @apachepinot | @KishoreBytes Deep Store S1 S3 Capacity expansion Controller S23 partitions 2 replicas S4 ● Consuming segment - Restart consumption using offset in cluster state ● Pinot segment - Download from deep store ● Easy to handle changes in replication/partitions ● No duplicates! ● Cluster state table updated
- 30. @apachepinot | @KishoreBytes S1 S3 Node failures Controller S23 partitions 2 replicas S4 ● At least 1 replica still alive ● No complex operations
- 31. @apachepinot | @KishoreBytes S1 S3 Scalability Controller S23 partitions 2 replicas S4 ● Easily add nodes ● Segment equivalence = Smart segment assignment + Smart query routing S6 S5 Completed Servers Consuming Servers
- 32. @apachepinot | @KishoreBytes Incorrect Results Operational Complexity Storage overhead Limited scalability Expensive Multi-node Consumer Group Y Y Y Y Y Single-node Consumer Group Y Y Y Partition Level Consumers Summary