










![Sample
Movies similarity:
# Map ratings to key / value pairs: user ID => movie ID, rating
ratings = data.map(lambda l: l.split()).map(lambda l: (int(l[0]), (int(l[1]), float(l[2]))))
# Emit every movie rated together by the same user.
# Self-join to find every combination.
joinedRatings = ratings.join(ratings)](https://image.slidesharecdn.com/apachespark-1-200125100620/85/Apache-spark-14-320.jpg)










Apache spark
- 2. Overview ● Introduction ● What is apache Spark ● Spark stack ● RDD ● Operation ● Sample ● Architecture ● Spark Streaming ● Kafka Streaming
- 3. Map-Reduce ● It is a two step process ● Once data is processed through the map and reduce, it has to be stored again inefficient for iterative and interactive computing jobs Spark was designed to be fast for interactive queries and iterative algorithms, bringing in ideas like support for in-memory storage and efficient fault recovery
- 4. Apache Spark ● Speed ● Ease Of Use
- 5. What is apache spark Apache Spark is a cluster computing platform designed to be fast and general-purpose. The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application.
- 6. Who use spark, and for what? ● Data science tasks ○ Analyze and model data ● Data processing application ○ Parallelize application across cluster
- 8. Resilient Distributed Dataset(RDD) ● In-memory computation ● Lazy Evaluation ● Fault Tolerance ● Immutability ● Persistence ● Partitioning ● Parallel
- 9. Spark Operation ● Transformation ○ create a new dataset from an existing one ● Action ○ return a value to the driver program after running a computation on the dataset.
- 10. Spark Operation Transformation Action Map/Map partition Reduce Flatmap Count/Count by key Filter Foreach Sort by key Save as... Group/Reduce by key First/ Take Union/Join Collect Cartesian ... ...
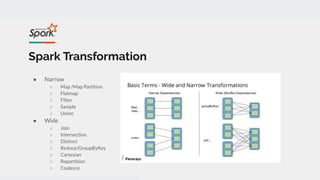
- 11. Spark Transformation ● Narrow ○ Map /Map Partition ○ Flatmap ○ Filter ○ Sample ○ Union ● Wide ○ Join ○ Intersection ○ Distinct ○ Reduce/GroupByKey ○ Cartesian ○ Repartition ○ Coalesce
- 12. Lazy evaluation
- 13. Sample Movies similarity: nameDict = loadMovieNames() data = sc.textFile("/SparkCourse/ml-100k/u.data")
- 14. Sample Movies similarity: # Map ratings to key / value pairs: user ID => movie ID, rating ratings = data.map(lambda l: l.split()).map(lambda l: (int(l[0]), (int(l[1]), float(l[2])))) # Emit every movie rated together by the same user. # Self-join to find every combination. joinedRatings = ratings.join(ratings)
- 15. Sample Movies similarity: # At this point our RDD consists of userID => ((movieID, rating), (movieID, rating)) # Filter out duplicate pairs uniqueJoinedRatings = joinedRatings.filter(filterDuplicates) # Now key by (movie1, movie2) pairs. moviePairs = uniqueJoinedRatings.map(makePairs)
- 16. Sample Movies similarity: # We now have (movie1, movie2) => (rating1, rating2) # Now collect all ratings for each movie pair and compute similarity moviePairRatings = moviePairs.groupByKey() # We now have (movie1, movie2) = > (rating1, rating2), (rating1, rating2) … # Can now compute similarities. moviePairSimilarities = moviePairRatings.mapValues(computeCosineSimilarity).cache()
- 17. Architecture
- 18. Terms ● Driver Program ● Cluster manager ● Executor ● Job ● Trask ● stage
- 19. Terms ● Driver Program ● Cluster manager ● Executor ● Job ● Trask ● stage
- 20. Spark Streaming
- 21. Streaming Flow:
- 22. Streaming Program Structure: After a context is defined, you have to do the following. 1. Define the input sources by creating input DStreams. 2. Define the streaming computations by applying transformation and output operations to DStreams. 3. Start receiving data and processing it using streamingContext.start(). 4. Wait for the processing to be stopped (manually or due to any error) using streamingContext.awaitTermination(). 5. The processing can be manually stopped using streamingContext.stop().
- 24. Source: ● https://www.kdnuggets.com/2018/07/introduction-apache-spark.html ● https://stackoverflow.com/questions/32621990/what-are-workers-executors-cores-in-spark-sta ndalone-cluster ● https://spark.apache.org/docs/latest/cluster-overview.html ● https://spark.apache.org/docs/latest/streaming-programming-guide.html ● https://dzone.com/articles/spark-streaming-vs-kafka-stream-1 ● https://www.edureka.co/blog/spark-architecture/