Apache Spark Data Source V2 with Wenchen Fan and Gengliang Wang

As a general computing engine, Spark can process data from various data management/storage systems, including HDFS, Hive, Cassandra and Kafka. For flexibility and high throughput, Spark defines the Data Source API, which is an abstraction of the storage layer. The Data Source API has two requirements. 1) Generality: support reading/writing most data management/storage systems. 2) Flexibility: customize and optimize the read and write paths for different systems based on their capabilities. Data Source API V2 is one of the most important features coming with Spark 2.3. This talk will dive into the design and implementation of Data Source API V2, with comparison to the Data Source API V1. We also demonstrate how to implement a file-based data source using the Data Source API V2 for showing its generality and flexibility.



































































![pseudo-code
class ParquetDataSource extends DataSourceReader with SupportsPushDownFilters {
override def pushFilters(filters: Array[Filter]): Array[Filter] = {
(partitionFilters, dataFilters) =
filters.span(_.outputSet.subsetOf(partitionColumns))
dataFilters
}
}
// For the selected row groups, we still need to evaluate data filters in Spark
// To be continued in #planInputPartitions
14](https://image.slidesharecdn.com/2wenchenfangengliangwang-180614202209/85/Apache-Spark-Data-Source-V2-with-Wenchen-Fan-and-Gengliang-Wang-72-320.jpg)







![pseudo-code
class ParquetDataSource extends DataSourceReader with SupportsPushDownFilters
with SupportsPushDownRequiredColumns {
override def planInputPartitions(): List[InputPartition[Row]] = {
val filePartitions = makeFilePartitions(fileIndex.listFiles(partitionFilters))
filePartitions.map { filePartition =>
// Row group skipping
ParquetInputFormat.setFilterPredicate(hadoopConf, dataFilters)
// Read requested columns from parquet file to Spark rows
ParquetReader(filePartition, requiredSchema)
}
}
22](https://image.slidesharecdn.com/2wenchenfangengliangwang-180614202209/85/Apache-Spark-Data-Source-V2-with-Wenchen-Fan-and-Gengliang-Wang-80-320.jpg)



















![class ParquetDataSource extends DataSourceWriter with SupportsWriteInternalRow {
override def createInternalRowWriterFactory(): DataWriterFactory[InternalRow] = {
val parquetOutputFactory = ParquetOutputFactory(dataSchema, partitionSchema)
ParquetWriterFactory(this.outputPath, parquetOutputFactory)
}
override def commit(messages: Array[WriterCommitMessage]): Unit = {
committedTaskPaths.foreach { taskPath =>
mergePath(taskPath, this.outputPath)
}
}
override def abort(messages: Array[WriterCommitMessage]): Unit = {
fs.delete(pendingJobAttemptsPath)
}
}
42](https://image.slidesharecdn.com/2wenchenfangengliangwang-180614202209/85/Apache-Spark-Data-Source-V2-with-Wenchen-Fan-and-Gengliang-Wang-100-320.jpg)
![class ParquetWriterFactory(
path: Path,
outputFactory: ParquetOutputFactory)
extends DataWriterFactory[InternalRow] {
override def createDataWriter(
partitionId: Int,
attemptNumber: Int,
epochId: Long): DataWriter[InternalRow] = {
val writer = outputFactory.newInstance()
ParquetWriter(writer, partitionId, attemptNumber)
}
}
43](https://image.slidesharecdn.com/2wenchenfangengliangwang-180614202209/85/Apache-Spark-Data-Source-V2-with-Wenchen-Fan-and-Gengliang-Wang-101-320.jpg)
![class ParquetWriter(writer: ParquetOutputWriter, partitionId: Int, attemptNumber: Int)
extends DataWriter[InternalRow] {
val pendingPath = new pendingTaskAttemptPath(partitionId, attemptNumber)
override def write(record: InternalRow): Unit = {
writer.write(pendingPath)
}
override def commit(): WriterCommitMessage = {
mergePath(pendingPath, pendingJobAttemptsPath)
}
override def abort(): Unit = {
fs.delete(pendingPath)
}
} 44](https://image.slidesharecdn.com/2wenchenfangengliangwang-180614202209/85/Apache-Spark-Data-Source-V2-with-Wenchen-Fan-and-Gengliang-Wang-102-320.jpg)































More Related Content
What's hot (20)
Similar to Apache Spark Data Source V2 with Wenchen Fan and Gengliang Wang (20)


















More from Databricks (20)




















Recently uploaded (20)




















Apache Spark Data Source V2 with Wenchen Fan and Gengliang Wang
- 1. Data Source API V2 Wenchen Fan 2018-6-6 | SF | Spark + AI Summit 1
- 2. Databricks’ Unified Analytics Platform DATABRICKS RUNTIME COLLABORATIVE NOTEBOOKS Delta SQL Streaming Powered by Data Engineers Data Scientists CLOUD NATIVE SERVICE Unifies Data Engineers and Data Scientists Unifies Data and AI Technologies Eliminates infrastructure complexity
- 3. What is Data Source API? 3
- 4. What is Data Source API? • Hadoop: InputFormat/OutputFormat • Hive: Serde • Presto: Connector ……. Defines how to read/write data from/to a storage system. 4
- 5. Ancient Age: Custom RDD HadoopRDD/CassandraRDD/HBaseRDD/… rdd.mapPartitions { it => // custom logic to write to external storage } Good in the ancient ages when users writing Spark applications with RDD API. 5
- 6. New Requirements When Switching to Spark SQL 6 6
- 7. How to read data? • How to read data concurrently and distributedly? (RDD only satisfy this) • How to skip reading data by filters? • How to speed up certain operations? (aggregate, limit, etc.) • How to convert data using Spark’s data encoding? • How to report extra information to Spark? (data statistics, data partitioning, etc.) • Structured Streaming Support ……. 7
- 8. How to write data? • How to write data concurrently and distributedly? (RDD only satisfy this) • How to make the write operation atomic? • How to clean up if write failed? • How to convert data using Spark’s data encoding? • Structured streaming support ……. 8
- 9. Data Source API V1 for Spark SQL 9 9
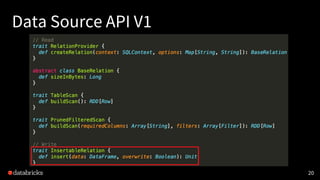
- 10. Data Source API V1 10
- 11. Data Source API V1 Pros: • Simple • Works well for the most common cases 11
- 12. Data Source API V1 Cons: • Coupled with other APIs. (SQLContext, RDD, DataFrame) 12
- 13. Data Source API V1 13
- 14. Data Source API V1 Cons: • Coupled with other APIs. (SQLContext, RDD, DataFrame) • Hard to push down other operators. 14
- 15. Data Source API V1 15
- 16. Data Source API V1 16 buildScan(limit) buildScan(limit, requiredCols) buildScan(limit, filters) buildScan(limit, requiredCols, filters) ...
- 17. Data Source API V1 Cons: • Coupled with other APIs. (SQLContext, RDD, DataFrame) • Hard to push down other operators. • Hard to add different data encoding. (columnar scan) 17
- 18. Data Source API V1 18
- 19. Data Source API V1 Cons: • Coupled with other APIs. (SQLContext, RDD, DataFrame) • Hard to push down other operators. • Hard to add different data encoding. (columnar scan) • Hard to implement writing. 19
- 20. Data Source API V1 20
- 21. Data Source API V1 Cons: • Coupled with other APIs. (SQLContext, RDD, DataFrame) • Hard to push down other operators. • Hard to add different data encoding. (columnar scan) • Hard to implement writing. • No streaming support 21
- 22. How to read data? • How to read data concurrently and distributedly? • How to skip reading data by filters? • How to speed up certain operations? • How to convert data using Spark’s data encoding? • How to report extra information to Spark? • Structured streaming support 22
- 23. How to write data? • How to write data concurrently and distributedly? • How to make the write operation atomic? • How to clean up if write failed? • How to convert data using Spark’s data encoding? • Structured streaming support 23
- 24. What’s the design of Data Source API V2? 2424
- 26. API Sketch (read) 26 Like RDD
- 29. Read Process 29 Spark Driver External Storage Spark Executors
- 30. Read Process 30 1. a query plan generated by user 2. the leaf data scan node generates DataSourceReader Spark Driver External Storage Spark Executors
- 32. Read Process 32 Spark Driver External Storage Spark Executors DataSourceReader: 1. connect to the external storage 2. push down operators 3. generate InputPartitions.
- 34. Read Process 34 Spark Driver External Storage Spark Executors InputPartition: Carries necessary information to create a reader at executor side.
- 36. Read Process 36 Spark Driver External Storage Spark Executors InputPartitionReader: talks to the external storage and fetch the data.
- 39. Write Process 39 Spark Driver External Storage Spark Executors
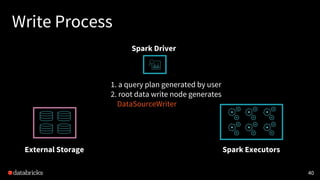
- 40. Write Process 40 Spark Driver External Storage Spark Executors 1. a query plan generated by user 2. root data write node generates DataSourceWriter
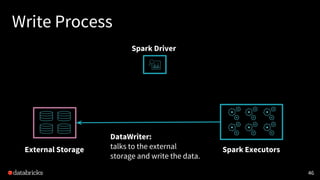
- 42. Write Process 42 Spark Driver External Storage Spark Executors DataSourceWriter: 1. connect to the external storage 2. prepare to write. (WAL, lock, etc.) 2. generate a DataWriterFactory
- 44. Write Process 44 Spark Driver External Storage Spark Executors DataWriterFactory: Carries necessary information to create a writer to write the data.
- 46. Write Process 46 Spark Driver External Storage Spark Executors DataWriter: talks to the external storage and write the data.
- 48. Write Process 48 Spark Driver External Storage Spark Executors DataWriter: succeed, commit this task and send a message to the driver. CommitMessage commit
- 50. Write Process 50 Spark Driver External Storage Spark Executors Exception DataWriter: fail, abort this task. Propagate exception to driver. abort and clean up
- 52. Write Process 52 Spark Driver External Storage Spark Executors DataSourceWriter: all writers succeed, commit the job. commit
- 54. Write Process 54 Spark Driver External Storage Spark Executors DataSourceWriter: some writers fail, abort the job. (all or nothing) abort and clean up
- 56. Streaming Data Source API V2 Structured Streaming Deep Dive: https://tinyurl.com/y9bze7ae Continuous Processing in Structured Streaming: https://tinyurl.com/ydbdhxbz 56
- 57. Ongoing Improvements • Catalog Supports: standardize the DDL logical plans, proxy DDL commands to data source, integrate data source catalog. (SPARK-24252) • More operator pushdown: limit pushdown, aggregate pushdown, join pushdown, etc. (SPARK-22388, SPARK-22390, SPARK-24130, ...) 57
- 59. Apache Spark Data Source V2 : Example Gengliang Wang Spark Summit 2018, SF 1
- 60. About me • Gengliang Wang (Github: gengliangwang) • Software Engineer at
- 61. Databricks’ Unified Analytics Platform DATABRICKS RUNTIME COLLABORATIVE NOTEBOOKS Delta SQL Streaming Powered by Data Engineers Data Scientists CLOUD NATIVE SERVICE Unifies Data Engineers and Data Scientists Unifies Data and AI Technologies Eliminates infrastructure complexity
- 62. About this talk • Part II of Apache Data Source V2 session. • See Wenchen’s talk for background and design details. • How to implement Parquet data source with the V2 API 4
- 63. 5 Spark Data Source V2 We are migrating...
- 64. Read Parquet files 6 6
- 65. Query example trainingData = spark.read.parquet("/data/events") .where("city = 'San Francisco' and year = 2018") .select("timestamp").collect() 7
- 66. Goal • Understand data and skip unneeded data • Split file into partitions for parallel read 8
- 67. ref: http://grepalex.com/2014/05/13/parquet-file-format-and-object-model/ Parquet 101 9ref: Understanding how Parquet integrates with Avro, Thrift and Protocol Buffers
- 68. Data layout 10 Events year=2018 year=2017 year=2016 year=2015 parquet files parquet file row group 0 city timestamp OS browser other columns.. row group 1 . . row group N Footer
- 69. pseudo-code class ParquetDataSource extends DataSourceReader { override def readSchema(): StructType = { fileIndex .listFiles() .map(readSchemaInFooter) .reduce(mergeSchema) } } 11
- 70. Prune partition columns 12 Events year=2018 year=2017 year=2016 year=2015 parquet files parquet file row group 0 city timestamp OS browser other columns.. row group 1 . . row group N Footer spark .read .parquet("/data/events") .where("city = 'San Francisco' and year = 2018") .select("timestamp").collect()
- 71. Skip row groups 13 Events year=2018 year=2017 year=2016 year=2015 parquet files parquet file row group 0 city timestamp OS browser other columns.. row group 1 . . row group N Footer spark .read .parquet("/data/events") .where("city = 'San Francisco' and year = 2018") .select("timestamp").collect()
- 72. pseudo-code class ParquetDataSource extends DataSourceReader with SupportsPushDownFilters { override def pushFilters(filters: Array[Filter]): Array[Filter] = { (partitionFilters, dataFilters) = filters.span(_.outputSet.subsetOf(partitionColumns)) dataFilters } } // For the selected row groups, we still need to evaluate data filters in Spark // To be continued in #planInputPartitions 14
- 73. Prune columns 15 Events year=2018 year=2017 year=2016 year=2015 parquet files parquet file row group 0 city timestamp OS browser other columns.. row group 1 . . row group N Footer spark .read .parquet("/data/events") .where("city = 'San Francisco' and year = 2018") .select("timestamp").collect()
- 74. pseudo-code class ParquetDataSource extends DataSourceReader with SupportsPushDownFilters with SupportsPushDownRequiredColumns { var requiredSchema: StructType = _ override def pruneColumns(requiredSchema: StructType): Unit = { this.requiredSchema = requiredSchema } } // To be continued in #planInputPartitions 16
- 75. Goal • Understand data and skip unneeded data • Split files into partitions for parallel read 17
- 76. Partitions of same size 18 File 0 File 1 Partition 0 Partition 1 Partition 2 File 2HDFS Spark
- 77. Driver: plan input partitions 19 Spark Driver Partition 0 Partition 1 Partition 2 1. Split into partitions
- 78. Driver: plan input partitions 20 Spark Driver Executor 0 Executor 1 Executor 2 1. Split into partitions 2. Launch read tasks Partition 0 Partition 1 Partition 2
- 79. Executor: Read distributedly 21 Spark Driver Executor 0 Executor 1 Executor 2 3. Actual Reading Partition 0 Partition 1 Partition 2 1. Split into partitions 2. Launch read tasks
- 80. pseudo-code class ParquetDataSource extends DataSourceReader with SupportsPushDownFilters with SupportsPushDownRequiredColumns { override def planInputPartitions(): List[InputPartition[Row]] = { val filePartitions = makeFilePartitions(fileIndex.listFiles(partitionFilters)) filePartitions.map { filePartition => // Row group skipping ParquetInputFormat.setFilterPredicate(hadoopConf, dataFilters) // Read requested columns from parquet file to Spark rows ParquetReader(filePartition, requiredSchema) } } 22
- 81. Summary • Basic • determine schema • plan input partitions • Mixins for optimization • push down filters • push down required columns • scan columnar data • ... 23
- 82. Parquet Writer on HDFS 2424
- 83. Query example data = spark.read.parquet("/data/events") .where("city = 'San Francisco' and year = 2018") .select("timestamp") data.write.parquet("/data/results") 25
- 85. 27 Executor 0 Executor 1 Executor 2 1. Write task Spark Driver
- 86. 28 part-00000Executor 0 Executor 1 Executor 2 1. Write task 2. write to files Spark Driver Each task writes to different temporary paths part-00001 part-00002
- 87. Everything should be temporary 29 results _temporary
- 88. Files should be isolated between jobs 30 results _temporary job id job id
- 89. Task output is also temporary results _temporary job id _temporary
- 90. Files should be isolated between tasks 32 results _temporary job id _temporary task attempt id parquet files task attempt id parquet files task attempt id parquet files
- 91. Commit task 33 Executor 0 Executor 1 Executor 2 1. Write task 3. commit task Spark Driver part-00000 2. write to file part-00001 part-00002
- 92. File layout 34 results _temporary job id task attempt id parquet files task id parquet files task id parquet files _temporary In progress Committed
- 93. 3. abort task If task aborts.. 35 Executor 0 Executor 1 Executor 2 1. Write task Spark Driver part-00000 2. write to file part-00001 part-00002
- 94. File layout 36 results _temporary job id task attempt id parquet files task id parquet files task id parquet files _temporary On task abort, delete the task output path
- 95. Relaunch task 37 Executor 0 Executor 1 Executor 2 1. Write task 3. abort task Spark Driver part-00000 2. write to file part-00001 part-00002 4. Relaunch task
- 96. Distributed and Transactional Write 38 Executor 0 Executor 1 Executor 2 1. Write task 3. commit task Spark Driver 4. commit job part-00000 2. write to file part-00001 part-00002
- 98. Almost transactional 40 Spark stages output files to a temporary location Commit? Move to final locations Abort; Delete staged files The window of failure is small See Eric Liang’s talk in Spark summit 2017
- 99. pseudo-code 4141
- 100. class ParquetDataSource extends DataSourceWriter with SupportsWriteInternalRow { override def createInternalRowWriterFactory(): DataWriterFactory[InternalRow] = { val parquetOutputFactory = ParquetOutputFactory(dataSchema, partitionSchema) ParquetWriterFactory(this.outputPath, parquetOutputFactory) } override def commit(messages: Array[WriterCommitMessage]): Unit = { committedTaskPaths.foreach { taskPath => mergePath(taskPath, this.outputPath) } } override def abort(messages: Array[WriterCommitMessage]): Unit = { fs.delete(pendingJobAttemptsPath) } } 42
- 101. class ParquetWriterFactory( path: Path, outputFactory: ParquetOutputFactory) extends DataWriterFactory[InternalRow] { override def createDataWriter( partitionId: Int, attemptNumber: Int, epochId: Long): DataWriter[InternalRow] = { val writer = outputFactory.newInstance() ParquetWriter(writer, partitionId, attemptNumber) } } 43
- 102. class ParquetWriter(writer: ParquetOutputWriter, partitionId: Int, attemptNumber: Int) extends DataWriter[InternalRow] { val pendingPath = new pendingTaskAttemptPath(partitionId, attemptNumber) override def write(record: InternalRow): Unit = { writer.write(pendingPath) } override def commit(): WriterCommitMessage = { mergePath(pendingPath, pendingJobAttemptsPath) } override def abort(): Unit = { fs.delete(pendingPath) } } 44