





































































































Ad
More Related Content
What's hot (20)
Similar to 大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto 講演資料) (20)





![[de:code 2019 振り返り Night!] Data Platform](https://cdn.slidesharecdn.com/ss_thumbnails/20190610decode2019dataplatformrecap-190610113039-thumbnail.jpg?width=560&fit=bounds)












Ad
More from NTT DATA Technology & Innovation (20)




















Ad
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto 講演資料)
- 1. © 2020 NTT DATA Corporation 大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介 - 基本から最新バージョン3.0まで - 2020/8/28 株式会社NTTデータ 技術開発本部 猿田 浩輔
- 2. 2© 2020 NTT DATA Corporation $ whoami 猿田 浩輔 株式会社NTTデータ 技術開発本部 シニア・ソフトウェアエンジニア / Apache Sparkコミッタ Hadoop/Sparkなど、OSSミドル関連のR&Dや技術支援 普及活動の一環で講演や書籍執筆なども Twitter: @raspberry1123
- 3. 3© 2020 NTT DATA Corporation 本日のお話 Apache Sparkの基本 Sparkとは何か Sparkのソフトウェアスタック • Spark SQLを掘り下げて解説 簡単に並列分散処理が行える裏側の仕掛け Apache Spark 3.0の主要なアップデートの紹介 Accelerator Aware Scheduling Adaptive Query Execution Dynamic Partition Pruning
- 4. Overview
- 5. 5© 2020 NTT DATA Corporation Apache Spark in a nutshell Apache Sparkとは? JVM上で動作するOSSの並列分散処理系
- 6. 6© 2020 NTT DATA Corporation Apache Spark in a nutshell Apache Sparkとは? JVM上で動作するOSSの並列分散処理系 大量のデータセットを (数100GBs, TBs, PBs...)
- 7. 7© 2020 NTT DATA Corporation Apache Spark in a nutshell Apache Sparkとは? JVM上で動作するOSSの並列分散処理系 大量のデータセットを (数100GBs, TBs, PBs...) 複数台のサーバで構成された クラスタを用いて
- 8. 8© 2020 NTT DATA Corporation Apache Spark in a nutshell Apache Sparkとは? JVM上で動作するOSSの並列分散処理系 大量のデータセットを (数100GBs, TBs, PBs...) 複数台のサーバで構成された クラスタを用いて 現実的な時間で処理する (数十分, 数時間のオーダー)
- 9. 9© 2020 NTT DATA Corporation Apache Spark in a nutshell Apache Sparkとは? JVM上で動作するOSSの並列分散処理系 並列分散処理に関する面倒な制御をSparkが肩代わりしてくれる。 エラーハンドリング 処理の分割やスケジューリング etc 大量のデータセットを (数100GBs, TBs, PBs...) 複数台のサーバで構成された クラスタを用いて 現実的な時間で処理する (数十分, 数時間のオーダー)
- 10. 10© 2020 NTT DATA Corporation データ処理ロジックの実装もシンプルに プログラミングインターフェイスの観点からも、分散処理の複雑さを隠蔽 SQLライクなクエリやAPIを用いて、テーブルを操作するように分散処理を記述できる whereselect groupBy avg val df = spark.read.json("/path/to/dataset") val result = df.select("col1", "col2").where("col3 > 0") .groupBy("col1").avg("col2")
- 11. 11© 2020 NTT DATA Corporation Sparkの動作環境 Sparkを動かすには、複数のサーバで構成されたクラスタが必要 利用するサーバは、IAサーバなどコモディティなものでよい YARNやKubernetes、Mesosといった既存のクラスタマネージャで管理されたクラス タ上で動作する Sparkに同梱されているStandalone Clusterと呼ばれるクラスタマネージャを利用 することもできる
- 12. 12© 2020 NTT DATA Corporation Sparkの動作環境 Sparkを動かすには、複数のサーバで構成されたクラスタが必要 利用するサーバは、IAサーバなどコモディティなものでよい YARNやKubernetes、Mesosといった既存のクラスタマネージャで管理されたクラス タ上で動作する Sparkに同梱されているStandalone Clusterと呼ばれるクラスタマネージャを利用 することもできる クラウドサービスでSparkを利用することも可能 Amazon Web Services: Amazon EMR Microsoft Azure: HDInsight Google Cloud Platform: Dataproc Databricks
- 13. 13© 2020 NTT DATA Corporation Sparkのソフトウェアスタックとプログラミング言語 Spark Core (実行エンジンおよび汎用的なデータ処理ライブラリ) Spark Streaming (ストリーム処理) Structured Streaming (ストリーム処理)GraphX (グラフ処理) MLlib (機械学習) Spark SQL (クエリ処理) SQL
- 14. 14© 2020 NTT DATA Corporation Sparkのソフトウェアスタックとプログラミング言語 Spark Core (実行エンジンおよび汎用的なデータ処理ライブラリ) Spark Streaming (ストリーム処理) Structured Streaming (ストリーム処理)GraphX (グラフ処理) MLlib (機械学習) Spark SQL (クエリ処理) SQL
- 15. 15© 2020 NTT DATA Corporation Spark Core (実行エンジンおよび汎用的なデータ処理ライブラリ) Spark Streaming (ストリーム処理) Structured Streaming (ストリーム処理)GraphX (グラフ処理) MLlib (機械学習) Spark SQL (クエリ処理) SQL Sparkのソフトウェアスタックとプログラミング言語
- 16. 16© 2020 NTT DATA Corporation Spark Core (実行エンジンおよび汎用的なデータ処理ライブラリ) Spark Streaming (ストリーム処理) Structured Streaming (ストリーム処理)GraphX (グラフ処理) MLlib (機械学習) Spark SQL (クエリ処理) SQL Sparkのソフトウェアスタックとプログラミング言語
- 17. 17© 2020 NTT DATA Corporation Spark Core (実行エンジンおよび汎用的なデータ処理ライブラリ) Spark Streaming (ストリーム処理) Structured Streaming (ストリーム処理)GraphX (グラフ処理) MLlib (機械学習) Spark SQL (クエリ処理) SQL Sparkのソフトウェアスタックとプログラミング言語
- 18. 18© 2020 NTT DATA Corporation Spark Core (実行エンジンおよび汎用的なデータ処理ライブラリ) Spark Streaming (ストリーム処理) Structured Streaming (ストリーム処理)GraphX (グラフ処理) MLlib (機械学習) Spark SQL (クエリ処理) SQL Sparkのソフトウェアスタックとプログラミング言語
- 19. 19© 2020 NTT DATA Corporation Spark Core (実行エンジンおよび汎用的なデータ処理ライブラリ) Spark Streaming (ストリーム処理) Structured Streaming (ストリーム処理)GraphX (グラフ処理) MLlib (機械学習) Spark SQL (クエリ処理) SQL Sparkのソフトウェアスタックとプログラミング言語
- 20. Spark SQL
- 21. 21© 2020 NTT DATA Corporation Spark SQLとは データセットをRDBMSのテーブルのように操作する手段を提供する DataFrameと呼ばれるテーブル表現に対してSQLに似たAPIでクエリを発行できる SQLで処理を記述することもできる カラムには名前やデータ型を付与でき、見通しの良いデータ処理の記述を可能にしている id,name,date 0,aaa,2020-05-21 1,bbb,2020-06-03 2,ccc,2020-07-08 ・・・ id (Integer) name (String) date (Date) 0 aaa 2020-05-21 1 bbb 2020-06-03 2 ccc 2020-07-08 ・・・ カラム名やデータ型は、明示的な指定だけでなく推論させることが可能 テーブル / DataFrame
- 22. 22© 2020 NTT DATA Corporation クエリから最適化データフローを生成する クエリエンジン SQL DataFrameの操作 • クエリのパース • 実行プランの生成 • 意味解析 • 最適化 • RDD(Sparkの最もプリミティブなデータ表現)レベルで表現されたデータフロー • 加工の仕方や順序などはクエリエンジンによって最適化済み RDD ロード 保存 RDD 加工 加工 RDD ・・・
- 23. 23© 2020 NTT DATA Corporation クエリエンジンによる最適化 RDDベースの処理を人手で記述する場合、プログラマが最適なデータフローを考える必要 があった Spark SQLではクエリエンジンが実行プランに対して、様々な最適化を適用する 最適化の一例 データフローの効率化 • 処理の順序の入れ替え • 適切なJoinアルゴリズムの選択 I/O量の削減 • 不要なカラムの読み込みを避ける (カラムプルーニング) • 不要なパーティションの読み込みを避ける (パーティションプルーニング) • フィルタリングをデータソース側に移譲する (フィルタプシュダウン) etc
- 24. 24© 2020 NTT DATA Corporation 実行プランに対して適用される最適化の例 論理プラン クエリの内容から生成される 最初の実行プラン Filter Join dimension table fact table
- 25. 25© 2020 NTT DATA Corporation 実行プランに対して適用される最適化の例 ジョインの前にフィルタできると判 断されたら、順序を入れ替える (ジョインの負荷が下がる)。 論理プラン 最適化済み論理プラン クエリの内容から生成される 最初の実行プラン Filter Join dimension table fact table Filter Join dimension table fact table
- 26. 26© 2020 NTT DATA Corporation 実行プランに対して適用される最適化の例 Filter Join dimension table fact table Filter Join dimension table Broadcast Hash Join Scan Scan + Filter • ジョインなどは具体的なア ルゴリズムが選択される • データソースの機能を利 用して、フィルタをプッシュ ダウンできる場合もある ジョインの前にフィルタできると判 断されたら、順序を入れ替える (ジョインの負荷が下がる)。 fact table 論理プラン 最適化済み論理プラン 物理プラン クエリの内容から生成される 最初の実行プラン
- 27. 27© 2020 NTT DATA Corporation Spark SQLをベースとするコンポーネントも増えてきた 他のコンポーネントも、Spark SQLをベースとしたものになってきた MLlib(spark.mlパッケージ) Structured Streaming Spark Core (実行エンジンおよび汎用的なデータ処理ライブラリ) Spark Streaming (ストリーム処理) Structured Streaming (ストリーム処理)GraphX (グラフ処理) MLlib (機械学習) Spark SQL (クエリ処理)
- 28. 分散処理が実現される裏側
- 29. 29© 2020 NTT DATA Corporation クラスタで分散処理が行われる全体像 ワーカノード ・・・ ワーカノード上で動作するExecutorプロセスが「タスク」を処理することで、クラスタ全体で 分散処理が行われる アプリ開発者が記述した処理内容をタスクに分解するのはスケジューラの役割 ワーカノード Driver (スケジューラ) クラスタ
- 30. 30© 2020 NTT DATA Corporation Executor クラスタで分散処理が行われる全体像 ワーカノード Executor ・・・ ワーカノード上で動作するExecutorプロセスが「タスク」を処理することで、クラスタ全体で 分散処理が行われる アプリ開発者が記述した処理内容をタスクに分解するのはスケジューラの役割 ワーカノード Driver (スケジューラ) Executorにタスクを割り当てる クラスタ
- 31. 31© 2020 NTT DATA Corporation Executor クラスタで分散処理が行われる全体像 ワーカノード Executor タスク タスク ・・・ ワーカノード上で動作するExecutorプロセスが「タスク」を処理することで、クラスタ全体で 分散処理が行われる アプリ開発者が記述した処理内容をタスクに分解するのはスケジューラの役割 ワーカノード Driver (スケジューラ) 複数のExecutor / スロットで、 ワーカノード単体でも並列処理 スロット スロット Executorにタスクを割り当てる クラスタ
- 32. 32© 2020 NTT DATA Corporation RDDレベルの一連のデータフローは「ジョブ」と呼ばれる処理単位として扱われる ジョブの中からひとまとまりの処理として扱える範囲を切り出し、「ステージ」と呼ばれる処理 単位を生成する(「ひとまとまりの処理」がどのように定義されるかは後述) 処理内容からタスクが生成されるまでの流れ RDD 加工 加工加工 ステージ RDD RDD ・・・RDD ロード 保存 ジョブ
- 33. 33© 2020 NTT DATA Corporation 処理内容からタスクが生成されるまでの流れ 各ステージが処理するデータを分割したものをパーティションと呼ぶ ステージ パーティション
- 34. 34© 2020 NTT DATA Corporation 処理内容からタスクが生成されるまでの流れ 中間データ 各ステージが処理するデータを分割したものをパーティションと呼ぶ ステージ パーティション 最終的な処理結果
- 35. 35© 2020 NTT DATA Corporation 処理内容からタスクが生成されるまでの流れ タスク タスク タスク タスク タスク タスク タスク タスク タスク タスク タスク 中間データ 各ステージが処理するデータを分割したものをパーティションと呼ぶ 各パーティションはタスクで手分けして処理される ステージ パーティション 最終的な処理結果
- 36. 36© 2020 NTT DATA Corporation パーティションの作られ方 タスク タスク タスク タスク タスク タスク タスク タスク タスク タスク タスク • データソースの種類によって パーティション数が決まる • 例えばHDFSの場合は各タスクに ブロックサイズ程度のデータが 割り当たるように分割される • 中間データを処理するステージでは、 APIに渡すパラメータや設定で パーティション数が決まる • Spark SQLではデフォルトで 200パーティション
- 37. 37© 2020 NTT DATA Corporation シャッフル 集約処理やジョインなど、特定のキーを持つレコードをまとめて処理する必要がある場合は、 レコードの配置換えが必要。この配置換えを「シャッフル」と呼ぶ シャッフルはExecutor間の多対多のネットワーク通信で実現される したがってシャッフルが必要な処理までは「ひとまとまりの処理」を行うタスクとして単一 のExecutor上で処理可能 タスク タスク タスク タスク タスク タスク タスク タスク タスク タスク タスク シャッフル
- 38. Apache Spark 3.0
- 39. 39© 2020 NTT DATA Corporation Apache Spark 3.0 2020年6月に、Apache Spark 3.0がリリースされた およそ4年ぶりのメジャーバージョンリリース
- 40. 40© 2020 NTT DATA Corporation Apache Spark 3.0 2020年6月に、Apache Spark 3.0がリリースされた およそ4年ぶりのメジャーバージョンリリース データ分析を支えるアップデート Accelerator Aware Scheduling Pythonの型推論機能を利用したPandas UDF APIのリデザイン 新たに32個のビルトイン関数がSpark SQLに追加された
- 41. 41© 2020 NTT DATA Corporation Apache Spark 3.0 2020年6月に、Apache Spark 3.0がリリースされた およそ4年ぶりのメジャーバージョンリリース データ分析を支えるアップデート Accelerator Aware Scheduling Pythonの型推論機能を利用したPandas UDF APIのリデザイン 新たに32個のビルトイン関数がSpark SQLに追加された Spark SQLはより賢くなった Adaptive Query Execution (AQE) Dynamic Partition Pruning
- 42. 42© 2020 NTT DATA Corporation Apache Spark 3.0 2020年6月に、Apache Spark 3.0がリリースされた およそ4年ぶりのメジャーバージョンリリース データ分析を支えるアップデート Accelerator Aware Scheduling Pythonの型推論機能を利用したPandas UDF APIのリデザイン 新たに32個のビルトイン関数がSpark SQLに追加された Spark SQLはより賢くなった Adaptive Query Execution (AQE) Dynamic Partition Pruning Sparkを拡張する仕組みも導入された プラグイン ユーザ定義メトリクス ほかにもまだまだ
- 43. 43© 2020 NTT DATA Corporation Apache Spark 3.0 2020年6月に、Apache Spark 3.0がリリースされた およそ4年ぶりのメジャーバージョンリリース データ分析を支えるアップデート Accelerator Aware Scheduling Pythonの型推論機能を利用したPandas UDF APIのリデザイン 新たに32個のビルトイン関数がSpark SQLに追加された Spark SQLはより賢くなった Adaptive Query Execution (AQE) Dynamic Partition Pruning Sparkを拡張する仕組みも導入された プラグイン ユーザ定義メトリクス ほかにもまだまだ
- 45. 45© 2020 NTT DATA Corporation Accelarator Aware Schedulingとは GPUやFPGAなどのアクセラレータを、複数のタスク間で効率的にシェアできるようスケ ジューリングする仕組み Project Hydrogenと呼ばれる、AI関連のワークロードを指向した取り組みのひとつ AI関連のワークロードではGPUを活用することが当たり前になってきていることが、この取り 組みの背景 DLフレームワークをSpark向けに開発する場合、Spark内部からGPUなどのアクセ ラレータを扱える必要がある これまではGPUなどのアクセラレータを想定した作りになっていなかった
- 46. 46© 2020 NTT DATA Corporation これまでのSparkはアクセラレータの割り当て制御が不十分 YARNやKubernetes(K8S)などは既にGPUをサポートしているはずでは? YARNやK8SがGPUの割り当てを制御するのはコンテナやPodの単位 コンテナ/Pod単位ではGPUが適切に分離される ワーカノードに搭載 されているGPU NodeManager/Workerは、 GPUプールの中から要求され た数のGPUを割り当ててコン テナ/Podを起動 割り当てられている最 中のGPUは、他のコン テナやPodに割り当て られたり、アクセスされ ないように制御される Executor GPU GPU ワーカノード GPU GPU GPU GPU
- 47. 47© 2020 NTT DATA Corporation これまでのSparkはアクセラレータの割り当て制御が不十分 SparkではExecutorプロセスがコンテナやPod内で動作するが、Executorの中で更に 複数のタスクがスロット分だけ並列で実行される YARNやK8Sはコンテナ/Podの中身については関知しないので、タスクに対して GPUをどのように割り当てるかは制御できない Executor GPU GPUなどのアクセラレータはタスクに対して割り 当てが制御されていないため、競合や無駄が 生じる可能性がある ワーカノード タスクA GPU タスクB
- 48. 48© 2020 NTT DATA Corporation Accelerator Aware Schedulingによるアクセラレータの効率的なシェア Executorにどれだけアクセラレータを割り当てるかだけではなく、タスクに対して割り当てる 数を設定できる タスクのスケジューリングは、要求する種類/数のアクセラレータを満足するスロットに対して 行われる タスクに割り当てられたアクセ ラレータは他のタスクからアクセ スされないように分離される ワーカノード Executor GPU タスクA GPU タスクB GPU GPU
- 50. 50© 2020 NTT DATA Corporation Spark SQLのオプティマイザの進化の歴史 Spark 1.x ルールベース Spark 2.x ルールベース + コストベース
- 51. 51© 2020 NTT DATA Corporation Spark SQLのオプティマイザの進化の歴史 Spark 1.x ルールベース Spark 2.x ルールベース + コストベース Spark 3.x ルールベース + コストベース + ランタイムベース 処理の途中で得られた、推定ではない実際の情報をもとに、 適応的に実行プランの最適化が行われるようになった
- 52. Adaptive Query Execution ① パーティション数の自動調整
- 53. 53© 2020 NTT DATA Corporation パーティションの作られ方 (再掲) タスク タスク タスク タスク タスク タスク タスク タスク タスク タスク タスク • データソースの種類によって パーティション数が決まる • 例えばHDFSの場合は各タスクに ブロックサイズ程度のデータが 割り当たるように分割される • 中間データを処理するステージでは、 APIに渡すパラメータや設定で パーティション数が決まる • Spark SQLではデフォルトで 200パーティション
- 54. 54© 2020 NTT DATA Corporation AQE:シャッフル後のパーティション数の自動調整 適切なパーティション数はデータのサイズや分布、処理内容に依存するため、 多すぎると計算リソースの無駄遣いになり、少なすぎるとOOMになりがち AQEを有効にすると、設定されたパーティション数が多すぎる場合に、自動的にシュリンクし てくれる Scan Filter Shuffle (パーティション数200) Coalesce (パーティション数5) Sort Scan Filter Shuffle (パーティション数200) Sort
- 56. 56© 2020 NTT DATA Corporation Sort Merge JoinとBroadcast Hash Join Spark SQLでは、テーブル同士のジョインが必要な場合、物理プラン作成時に具体的な ジョインアルゴリズムを決定する。 典型的に選択されるアルゴリズムはSort Merge JoinとBroadcast Hash Join Sort Merge Join 選択されるものの中ではオーソドックスなジョインアルゴリズム テーブルをソートした後に、双方のテーブルのレコードを比較しながらジョイン ソート時にシャッフルが必要 Broadcast Hash Join 片方のテーブルがメモリに乗り切る程度に小さい場合に、あらかじめ全Executorに 小さいテーブルを配り、キー/バリューのハッシュテーブルを作る ジョイン実行時は、もう片方のテーブルのレコードをハッシュテーブルと突合する 従来は処理対象のテーブルのサイズ(≠読み込んだデータサイズ)が小さい場合やヒン ト句からBroadcast Hash Joinが選択された
- 57. 57© 2020 NTT DATA Corporation AQE: ジョインアルゴリズムの変更 Scan + Filter Sort Merge Join Scan 対象のデータサイズは100GB 実際に読んだのは 10MB Sort Sort
- 58. 58© 2020 NTT DATA Corporation AQE: ジョインアルゴリズムの変更 Scan + Filter Sort Merge Join Scan Scan + Filter Broadcast Hash Join Scan 対象のデータサイズは100GB 実際に読んだのは 10MB Sort Sort 実行時に判明したデータサイズに基づいて、 Broadcast Hash Joinに変更
- 60. 60© 2020 NTT DATA Corporation Sort Merge Join時のキーの偏りで処理全体が長期化 B A B A B A 各タスクに割り当てられたテーブル内 のレコード(ジョインキーごとに色分け) Sort Merge Join 特定のキーを持つレコードが偏っており、当 該キーのレコードを処理するタスクに処理全 体が引きずられる(分散処理の意味がない) タスク1 タスク2 タスク3 タスク4 タスク5 タスク6 タスク7 タスク8 テーブルBの処理 テーブルAの処理 シャッフルでキー ごとにレコードを 再分配
- 61. 61© 2020 NTT DATA Corporation AQE: Skew Join A B B A B A B A B A タスク9 タスク10 タスク1 タスク2 タスク3 タスク4 タスク5 テーブルBの処理 テーブルAの処理 タスク6 タスク7 タスク8 Skew Join • 偏りのあるパーティ ションを、大体均等 なサイズになるように 分割する • もう片方のテーブルの レコードはマージして 複製する
- 63. 63© 2020 NTT DATA Corporation 従来からのPartition Pruning Join Scan + Partition Pruning パーティションニングされた 大きなテーブルt1 p=1 2 3 Scan SELECT t1.id, t2,key FROM t1 JOIN t2 ON t1.key = t2.key WHERE t1.p < 2 パーティションニングされて いないテーブルt2 WHERE句の条件にマッチ するパーティションが、クエリ から静的に決まる
- 64. 64© 2020 NTT DATA Corporation 従来からのPartition Pruningが利かないケース Join Scan パーティションニングされた 大きなテーブルt1 Filter p=1 2 3 Scan SELECT t1.id, t2,key FROM t1 JOIN t2 ON t1.key = t2.key AND t2.id < 2 パーティションニングされて いないテーブルt2 クエリからは、どのパーティションに 絞れるか判断できないため、全 パーティションを読む必要がある t2.id < 2 p=1 2 3
- 65. 65© 2020 NTT DATA Corporation 従来からのPartition Pruningが利かないケース Join Scan パーティションニングされた 大きなテーブルt1 Filter p=1 2 3 Scan SELECT t1.id, t2,key FROM t1 JOIN t2 ON t1.key = t2.key AND t2.id < 2 パーティションニングされて いないテーブルt2 クエリからは、どのパーティションに 絞れるか判断できないため、全 パーティションを読む必要がある t2.id < 2 フィルタされた結果 残ったのはt2.p=1と3 のレコードだとすると p=1 2 3
- 66. 66© 2020 NTT DATA Corporation 従来からのPartition Pruningが利かないケース Join Scan パーティションニングされた 大きなテーブルt1 Filter p=1 2 3 Scan SELECT t1.id, t2,key FROM t1 JOIN t2 ON t1.key = t2.key AND t2.id < 2 パーティションニングされて いないテーブルt2 クエリからは、どのパーティションに 絞れるか判断できないため、全 パーティションを読む必要がある t2.id < 2 フィルタされた結果 残ったのはt2.p=1と3 のレコードだとすると p=1 2 3 t1.p=2のレコードはジョ インに不要なので、本 来読まなくてよかった
- 67. 67© 2020 NTT DATA Corporation サブクエリでフィルタリングすることで、Partition Pruningを利かせる (論理プラン) Join Scan パーティションニングされた 大きなテーブルt1 Filter p=1 2 3 Scan SELECT t1.id, t2,key FROM t1 JOIN t2 ON t1.key = t2.key AND t2.id < 2 パーティションニングされて いないテーブルt2 t2.id < 2 Filter クエリエンジンによって、論理プランに 挿入されたサブクエリによるフィルタ t1.p in ( SELECT t2.p FROM t2 WHERE t2.id < 2)
- 68. 68© 2020 NTT DATA Corporation サブクエリでフィルタリングすることで、Partition Pruningを利かせる (物理プラン) Join パーティションニングされた 大きなテーブルt1 Filter p=1 2 3 Scan SELECT t1.id, t2,key FROM t1 JOIN t2 ON t1.key = t2.key AND t2.id < 2 パーティションニングされて いないテーブルt2 t2.id < 2 物理プラン作成時にはScan時にフィル タのサブクエリが実行され、その結果をも とにPartition Pruningが適用される t1.p in ( SELECT t2.p FROM t2 WHERE t2.id < 2) Scan p=1 3
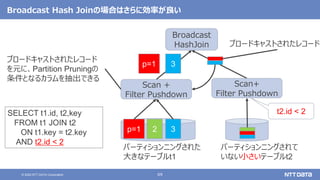
- 69. 69© 2020 NTT DATA Corporation Broadcast Hash Joinの場合はさらに効率が良い Broadcast HashJoin パーティションニングされた 大きなテーブルt1 p=1 2 3 Scan+ Filter Pushdown SELECT t1.id, t2,key FROM t1 JOIN t2 ON t1.key = t2.key AND t2.id < 2 パーティションニングされて いない小さいテーブルt2 t2.id < 2 Scan + Filter Pushdown ブロードキャストされたレコード p=1 3 ブロードキャストされたレコード を元に、Partition Pruningの 条件となるカラムを抽出できる
- 70. 70© 2020 NTT DATA Corporation その他にも注目のアップデートが盛り沢山 このほか主要なアップデートはリリースノートで要チェック https://spark.apache.org/releases/spark-release-3-0-0.html
- 71. まとめ
- 72. 72© 2020 NTT DATA Corporation まとめ Sparkの基本 Sparkは大量のデータを現実的な時間で処理するためのOSS並列分散処理系 巨大なデータセットをテーブルのようなデータ構造に抽象化して処理を記述できる 様々な用途に利用できるコンポーネントが同梱されている 昨今はSpark SQLがSparkの中心的なコンポーネント • シンプルに処理が記述できる • 最適化を施してくれる Spark 3.0のアップデート GPUやFPGAといったアクセラレータが効率的に扱えるようになった Spark SQLのクエリエンジンがより賢くなった(AQE) • パーティション数の自動調整 • ジョインアルゴリズムの適応的な選択 • Skew Join 複雑なクエリでも、Partition Pruningが利くようになった
- 73. © 2020 NTT DATA Corporation本資料に記載されている会社名、商品名、又はサービス名は、各社の登録商標又は商標です。