


![© 2025 NTT DATA Group Corporation 4
普段の業務 [高度OSSサポート] とは
⚫ Hadoop/Spark/Kafkaなどの
高難易度なプロダクトのサポートを提供
⚫ OSS活動やプロジェクト支援を実施するとともに、中長期的なサポートを提供している
⚫ Hadoop/Spark/Bigtop などのコミッタも在籍
高度OSSサポート
• ミドルウェア等をソースコードレベルで理解/調査
できる実力があるからこそ課題が解決できる
• 技術の方向性にも影響を持つ
• 世の中では提供仕切れていない「長期サポート」「高度サ
ポート」を提供しているケースもある
• 10年間安心して使える、なども支えている
高い技術力
安心・安全の実績](https://image.slidesharecdn.com/apachesparkkubernetesnumaosc2025tokyospringnttdata-250226101201-761bd657/85/Apache-Spark-Kubernetes-NUMA-Open-Source-Conference-2025-Tokyo-Spring-4-320.jpg)




























































Ad
More Related Content
What's hot (20)
Similar to Apache Sparkに対するKubernetesのNUMAノードを意識したリソース割り当ての性能効果 (Open Source Conference 2025 Tokyo/Spring 発表資料) (20)


















Ad
More from NTT DATA Technology & Innovation (20)




















Ad
Apache Sparkに対するKubernetesのNUMAノードを意識したリソース割り当ての性能効果 (Open Source Conference 2025 Tokyo/Spring 発表資料)
- 1. © 2025 NTT DATA Group Corporation Open Source Conference 2025 Tokyo/Spring Apache Sparkに対する KubernetesのNUMAノードを意識した リソース割り当ての性能効果 2025年2月21日 株式会社NTTデータグループ 技術革新統括本部 Innovation技術部 小茶 健一
- 2. © 2025 NTT DATA Group Corporation 2 自己紹介 小茶 健一(こちゃ けんいち) <所属> NTTデータグループ 技術革新統括本部 Innovation技術部 高度OSSサポート担当 <経歴> 2009年 日本ヒューレット・パッカード入社。主にテレコム向けのSIに従事。低レイ テンシの求められるシステムでNUMAアーキテクチャを意識したチューニングを経験。 また、システムのクラウドネイティブ化でKubernetes導入を支援した。 2023年 NTTデータグループ入社。Apache Spark、Hadoopを使用するプロ ジェクトの技術支援や、OSSのサポート業務に従事。
- 3. © 2025 NTT DATA Group Corporation 再度改めて Apache Sparkに対する KubernetesのNUMAノードを意識した リソース割り当ての性能効果
- 4. © 2025 NTT DATA Group Corporation 4 普段の業務 [高度OSSサポート] とは ⚫ Hadoop/Spark/Kafkaなどの 高難易度なプロダクトのサポートを提供 ⚫ OSS活動やプロジェクト支援を実施するとともに、中長期的なサポートを提供している ⚫ Hadoop/Spark/Bigtop などのコミッタも在籍 高度OSSサポート • ミドルウェア等をソースコードレベルで理解/調査 できる実力があるからこそ課題が解決できる • 技術の方向性にも影響を持つ • 世の中では提供仕切れていない「長期サポート」「高度サ ポート」を提供しているケースもある • 10年間安心して使える、なども支えている 高い技術力 安心・安全の実績
- 5. © 2025 NTT DATA Group Corporation 5 目次 1. NUMAアーキテクチャ 2. Kubernetes 3. Spark 4. KubernetesとSpark 5. 性能評価
- 6. © 2025 NTT DATA Group Corporation 6 1 NUMAアーキテクチャ
- 7. © 2025 NTT DATA Group Corporation 7 NUMAアーキテクチャ • 共有メモリ型のマルチプロセッサシステムにおけるのアーキテクチャの1つ • NUMA=Non-uniform Memory access(不均等メモリーアクセス) • CPUとメモリの組み合わせをNode(ノード)と呼ぶ • アクセスするCPUとメモリの位置関係からlocal access(ローカルアクセス)とremote access(リモートアクセ ス)に分かれる NUMA Node 0 CPU 0 CPU 1 CPU 3 CPU 2 Local Memory GPU 0 NIC 0 NUMA Node 1 CPU 5 CPU 4 CPU 6 CPU 7 Local Memory GPU 1 NIC 1 Interconnect PICe PICe
- 8. © 2025 NTT DATA Group Corporation 8 NUMAアーキテクチャ Local access • 同一Node上のCPUからメモリにアクセスするケース • 高速アクセス NUMA Node 0 CPU 0 CPU 1 CPU 3 CPU 2 Local Memory GPU 0 NIC 0 NUMA Node 1 CPU 5 CPU 4 CPU 6 CPU 7 Local Memory GPU 1 NIC 1 Interconnect PICe PICe
- 9. © 2025 NTT DATA Group Corporation 9 NUMAアーキテクチャ Remote access • 別々のNode上のCPUからメモリにアクセスするケース • local accessと比較して低速 • Interconnect(Bus)の速度に依存してレイテンシーが発生 NUMA Node 0 CPU 0 CPU 1 CPU 3 CPU 2 Local Memory GPU 0 NIC 0 NUMA Node 1 CPU 5 CPU 4 CPU 6 CPU 7 Local Memory GPU 1 NIC 1 Interconnect PICe PICe アプリケーションの特性によっては、NUMAの構成(NUMA Topology(トポロジー))を意識した割当てが必要になることも ・マシンラーニング ・テレコム ・データ分析 など
- 10. © 2025 NTT DATA Group Corporation 10 NUMA Nodeのリソース割当 CPU Pinning • Pinning(ピニング)はVMにどのCPUを割り当てるか指定する • 下図の例のVM1はNodeを跨いでCPUが割り当てられているため、起動するプロセスでどのCPUを使うか考慮が 必要 VM1 NUMA Node 0 CPU 0 CPU 1 CPU 3 CPU 2 Local Memory GPU 0 NIC 0 NUMA Node 1 CPU 5 CPU 4 CPU 6 CPU 7 Local Memory GPU 1 NIC 1 Interconnect PICe PICe VM2
- 11. © 2025 NTT DATA Group Corporation 11 NUMA Nodeのリソース割当 CPU Affinity • Affinity(アフィニティー)はプロセスにどのCPUを割り当てるか指定する • 下図の例ではProcess 1はNode 0、Process 2はNode 1のCPUを使用するよう指定 VM1 NUMA Node 0 CPU 0 CPU 1 CPU 3 CPU 2 Local Memory GPU 0 NIC 0 NUMA Node 1 CPU 5 CPU 4 CPU 6 CPU 7 Local Memory GPU 1 NIC 1 Interconnect PICe PICe Process 1 Process 2 CPU 4 CPU 0 CPU 1
- 12. © 2025 NTT DATA Group Corporation 12 NUMA Nodeの確認 • 搭載されているNUMA Nodeの確認できるコマンド • numactl • lscpu • lstopo lstopo --of ascii lscpu numactl -H
- 13. © 2025 NTT DATA Group Corporation 13 NUMAの統計情報 numastat • numastatコマンドで、NUMA Node毎のプロセス、OSのメモリー統計(割り当てヒットやミス)を確認 できる • 今回特に見たいのは以下の2項目 • local_node: 同一Node上のプロセスに正常に割り当てられたメモリのページ数 (local access) • other_node: 別Node上のプロセスに正常に割り当てられたメモリのページ数 (remote access)
- 14. © 2025 NTT DATA Group Corporation 14 2 Kubernetes
- 15. © 2025 NTT DATA Group Corporation 15 Kubernetes • オープンソースのコンテナオーケストレーションシステム • Pod(Container)のデプロイ、スケーリングなどを管理 • 役割に応じて大きく2つのサーバに分かれる • Control Plane: クラスタの全体管理を行う管理サーバ • kube-api-server: Kubernetes APIを公開するControl Planeのフロントエンド • etcd: Kubernetesクラスタの状態(Podの配置状況など)を保存するkey-value store • kube-scheduler: Podのスケジューラ • kube-contoroller-manager: 様々なcontrollerを実行するプロセス • controller: NodeやPodの起動、停止などのイベントに対する処理(再起動するなど)を行う • Node: Podを起動するサーバ群(NUMA Nodeの”Node”とは別物) • kubelet: containerの起動、停止の制御を行う • NUMA Topologyを意識したリソース割り当てはここに実装されている • kube-proxy: KubernetesのServiceを実行するネットワークプロキシ • Container runtime: containerの起動、停止を行う Control Plane etcd scheduler contoroller manager kube-api-server Node 1 kubelet kube- proxy CRI Pod Pod Node 2 kubelet kube- proxy CRI Pod
- 16. © 2025 NTT DATA Group Corporation 16 Kubernetesのリソース管理機能 • Kubernetesのリソース管理機能(Manager)は、リソース種別毎と、これらを統合的に管理するものに分別される • 全てのManagerがkubeletのサブコンポーネントとして実装されている • リソース種別毎のManager • CPU Manager • CPUを排他的に特定のContainerに割り当てることで、該当のContainerがCPUを独占できるようにする • Memory Manager • 保証されたメモリ(とヒュージページ)の割り当てを提供する • Linuxカーネルはベストエフォートでメモリを同一Node上に配置する • しかしこれは保証されたものではないため、Memory Managerによって保証している • Device Manager • GPUなどベンダー固有のデバイスの割り当てを可能にする • 統合管理のManager • Topology Manager • リソース種別毎のManagerから提供される各リソースの空き状況から、NUMA Topologyの観点で最適なリソース割り当てを決定する • リソース種別毎にManagerが独立していたことで、NUMA Nodeに跨ってリソースが割り当てられ、パフォーマンス劣化を引き起こす課題に対する解決策と して実装された
- 17. © 2025 NTT DATA Group Corporation 17 リソース管理機能のリリース時期 リリース時期 K8s Version コンポーネント Beta / GA 2018/03 1.10 Device Manager / CPU Manager Beta 2020/03 1.18 Topology Manager Beta 2021/08 1.22 Memory Manager Beta 2022/12 1.26 Device Manager / CPU Manager GA 2023/04 1.27 Topology Manager GA 2024/12 1.32 Memory Manager GA
- 18. © 2025 NTT DATA Group Corporation 18 Topology Manager Policy kubeletのtopologyManagerPolicy設定でリソースの割り当てとPodの起動(失敗)のポリシーを選択できる policy名 policy none • 何も行わない(Topology Managerが存在しないのと同じ) • default best-effort • できる限り単一のNUMA Node(Node)に割り当てを行う • 単一Nodeに割り当てができない場合でもPodを起動する restricted • 単一Nodeに割り当てができない場合はPodの起動に失敗する • ただし、単一Nodeで要件を絶対に満たせない場合は、複数Nodeのリソースが割り当てられる (single-numa-nodeとの違い) • 例:2 Nodeあり、Node毎に1セット、合計2セットのGPUを持つ場合 • GPUを2セット要求した場合は、Nodeを跨ってGPUが割り当てられる single-numa-node • 単一Nodeに割り当てが可能な場合のみPodを起動する • 一番制限が厳しい
- 19. © 2025 NTT DATA Group Corporation 19 Podのresources設定 • Topology Manager Policyを適用してPodを起動するには、以下のAND条件を満たす必要がある • Guaranteed QoS classの基準を満たすresources設定がされている • CPUを占有する値である • Guaranteed QoS classの基準は、Pod内の全てのContainerについて以下のAND条件が満たされる場合 • cpuとメモリそれぞれlimitsとrequestsが指定されている • limitsとrequestsの値が同じ • CPUを占有する値はInteger、または1000mの倍数である場合 pec: containers: - name: sample-container image: alpine resources: limits: cpu: 2 ← Integer memory: 200Mi requests: cpu: 2 ← Integer memory: 200Mi
- 20. © 2025 NTT DATA Group Corporation 20 リソース割り当ての流れ 1. Podの受付段階でkubeletからTopology ManagerのAdmit()メソッドを呼び出す 2. Topology Managerは、各HintProvider(CPU Manager、Memory Manager、Device Manager)のGetToplogyHints()を呼び出す 3. 各HintProviderが選択可能なNUMA Nodeの組み合わせのHintをbit mask形式で返す • 例として、{01}の場合 • Node 0は選択可 (1) • Node 1は選択不可(0) 4. Topology Managerが集めたHintをMergeした結果を元にリソースを割り当てるNUMA Nodeを決定する 1. 例としてCPU、MemoryのHintが以下だった場合、bit maskのAnd条件を満たす{01}(= NUMA Node 0)を採用(※) • CPU: {01}, {10}, {11} • Memory: {01}, {11} 5. Topology Managerが各HintProviderにAllocate()を要求し、リソースを割り当てる 6. Topology Managerがkubeletに Podの受付可否を返す kubelet Topology Manager 1. Admit() 2. GetTopologyHints() 3. Hint HintProviders HintProviders HintProviders 5. Allocate() 6. Admit or not 4. Merge ※{11}もAnd条件を満たすが、 Nodeを跨ぐため不採用
- 21. © 2025 NTT DATA Group Corporation 21 3 Apache Spark
- 22. © 2025 NTT DATA Group Corporation 22 Apache Spark • オープンソースの大規模分散データ処理の統合エンジン • 大規模データとこれに対する複雑な処理を分割し、サーバリソースに割り当てる • これを並列で処理することで100GB単位、TB単位の単体のサーバでは扱うことの難しい大規模データを扱えるようにする • 役割に応じて大きく2つのプロセスに分かれる • Driver • ユーザが実装した、あるデータに対して処理を行い、結果を得るまでの一連の流れ(Job)の実行を制御する • Executorの起動、停止や、分割したデータと処理の1単位(Task)をExcecutorに割り当てる • この実装したプログラムをDriver programと呼ぶ • Executor • Driverから受け取ったTaskを実行する Worker Node Executor Task Task Driver Worker Node Executor Task Task
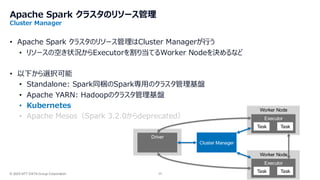
- 23. © 2025 NTT DATA Group Corporation 23 Apache Spark クラスタのリソース管理 Cluster Manager • Apache Spark クラスタのリソース管理はCluster Managerが行う • リソースの空き状況からExecutorを割り当てるWorker Nodeを決めるなど • 以下から選択可能 • Standalone: Spark同梱のSpark専用のクラスタ管理基盤 • Apache YARN: Hadoopのクラスタ管理基盤 • Kubernetes • Apache Mesos(Spark 3.2.0からdeprecated) Worker Node Executor Task Task Driver Worker Node Executor Task Task Cluster Manager
- 24. © 2025 NTT DATA Group Corporation 24 4 KubernetesとSpark
- 25. © 2025 NTT DATA Group Corporation 25 SparkをKubernetesで実行する方法 • SparkをKuberenetesで実行する方法は大きく2つ • spark-submit コマンド実行 • Spark Operatorの利用 • spark-submitコマンド • Spark同梱のdriver program実行用シェルスクリプト • “--master <master-url>” オプションの <master-url>でCluster Managerを選択する • Kubernetesの場合は以下 • k8s://<HOST>:<PORT> ※<HOST>:<PORT>は、kube-api-serverのアドレスとポート • Spark Operator (今回はこちらを利用) • Spark用に用意されたKubernetesのOperatorパターン • 通常のKubernetesリソースと同じように、YAMLファイルにリソースを定義して、kubectlコマンドでデプロイする • 元々Googleが開発したオープンソース • 2024年4月にKubeflowコミュニティへの移管がアナウンスされ、現在はKubeflowで管理
- 26. © 2025 NTT DATA Group Corporation 26 YAMLファイルの例 Spark Operator利用時の YAMLファイルの例 apiVersion: sparkoperator.k8s.io/v1beta2 kind: SparkApplication ← Spark Operatorのリソース metadata: name: spark-pi namespace: default spec: type: Scala mode: cluster image: spark:3.5.2 mainClass: org.apache.spark.examples.SparkPi mainApplicationFile:"/opt/spark/examples/jars/spark-examples_2.12-3.1.1.jar" ↑ driver programのパス arguments: - "5000" sparkVersion: "3.5.2" restartPolicy: type: Never driver: ← Driverの定義 labels: version: 3.5.2 cores: 2 coreLimit: 2 ← Guaranteed QoS classの基準を満たす値 memory: "512m" serviceAccount: spark-operator-spark executor: ← Executorの定義 labels: version: 3.5.2 instances: 5 ← 起動するExecutorの数 cores: 10 coreLimit: 10 ← Guaranteed QoS classの基準を満たす値 memory: "2G"
- 27. © 2025 NTT DATA Group Corporation 27 5 性能評価
- 28. © 2025 NTT DATA Group Corporation 28 観点 • KubernetesのTopology ManagerによるNUMA Nodeを考慮したリソース割り当てについて、 以下の観点で効果を確認 • Topology Manager Polocyは以下の2パターンで実施 • none • single-numa-node 観点 内容 Spark Jobの実行時間 • Jobの実行開始から終了までに要した時間 NUMA Node統計 • local accessとremote accessの割合 • numastatのlocal_node、other_nodeの値
- 29. © 2025 NTT DATA Group Corporation 29 環境 マシンリソース AWS EC2のc5.18xlarge インスタンスを使用 項目 リソース NUMA Node数 2 1Nodeの論理Core数(物理Core数) 36(18) 1Nodeのメモリ容量 約68GB
- 30. © 2025 NTT DATA Group Corporation 30 環境 Executorリソース 項目 リソース cores 10 memory 15g instances 6
- 31. © 2025 NTT DATA Group Corporation 31 環境 構成 簡易的にKubernetesクラスタを構築できるMicroK8sを利用した、シングルノードクラスタを環境として利用 EC2 c5.18xlarge Ubuntu 24.04 MicroK8s OpenEBS Addon(StorageClass) MinIO Addon(Object Storage) 処理用データ Kubeflow Spark Operator Driver Executor Executor Calico Addon(Network) Executor Executor Executor driver program Executor
- 32. © 2025 NTT DATA Group Corporation 32 Job • 実行するJobは、ある程度の処理時間になることだけを目的としたもの • データは以下のオープンデータを利用 • https://www.kaggle.com/datasets/ofurkancoban/discogs-datasets-january-2025
- 33. © 2025 NTT DATA Group Corporation 33 結果 • remote accessの大幅な減少が確認できた • 実行したJobが小さいこともあり、実行時間に対する効果は見られず 観点 Topology Manager Polocy none single-numa-node Spark Jobの実行時間 9分10秒 9分7秒 NUMA Node統計 • remote accessの割合: 約1.6% • local_node: 202,761 MB • other_node: 3,290 MB • remote accessの割合: 0.008% • local_node: 192,461 MB • other_node: 16 MB
- 34. © 2025 NTT DATA Group Corporation 34 まとめ • KubernetesのTopology Managerのリソース割り当て機能を活用し、NUMAアーキテクチャにおけ るremote accessの削減ができる • 低レイテンシーが求められるKubernetes上のアプリケーションにおいては、検討の対象として考えて良さ そう