Пайплайн машинного обучения на Apache Spark / Павел Клеменков (Rambler&Co)
Download as PPTX, PDF3 likes1,429 views

Документ описывает процесс создания и эксплуатации пайплайна машинного обучения на Apache Spark, включая проблемы с качеством данных и их обработкой. Обсуждаются различные компоненты архитектуры, такие как HDFS, Hive и Kafka, и предоставляются советы по оптимизации выполнения задач в Spark. Автор делится примерами решения проблем и оптимизации процесса в контексте использования таких библиотек, как Vowpal Wabbit и XGBoost.







































![Pandas vs Spark Dataframe
import pandas as pd
!hive -e "select * from
users" > dt.csv
df = pd.read_csv("dt.csv")
counts = df[df.age > 30]
.groupby("sex")
.count()
from pyspark.sql import
HiveContext
ctx = HiveContext(sc)
df = ctx.sql("select * from
users")
counts = df[df.age > 30]
.groupby("sex")
.count()](https://image.slidesharecdn.com/8-161111204834/85/Apache-Spark-Rambler-Co-40-320.jpg)



























![class SparkXGBoostClassifier(SparkSklearnClassifier):
def predict_proba(self, df):
rdd = df.map(self._create_dataset)
df = rdd.toDF()[['uid', 'feature']]
v_model = df._sc.broadcast(self.model)
res = df.rdd.mapPartitionsWithIndex(
partial(apply_model, v_model=v_model))
return res](https://image.slidesharecdn.com/8-161111204834/85/Apache-Spark-Rambler-Co-69-320.jpg)


Пайплайн машинного обучения на Apache Spark / Павел Клеменков (Rambler&Co)
- 1. Пайплайн машинного обучения на Apache Spark Павел Клеменков, Rambler&Co [email protected]
- 2. Remember when Rambler used to be a search engine? Pepperidge Farm remembers
- 5. Мотивационный пример • Обучили модель CTR (PySpark, vowpal wabbit • Предикт ~= baseline CTR • Закинули модель в сервис (Vert.X, VW JNI) • Предикт != baseline CTR • В чем дело? • Из-за sparse-формата, потерялись некоторые фичи
- 6. Что хотим от математика-программиста? • Качественные эксперименты быстро • Доведение эксперимента до продакшена • Поддержка и багфиксы
- 7. WTF is this shit?!
- 8. All my code works! And I didn’t break the build!
- 9. Качественный эксперимент быстро • Знакомое окружение • Все новое и крутое • Витрина фич
- 10. Эксперимент в продакшене • Простое тестирование • Окружение как на продакшене • Автоматизация
- 11. Эксплуатация и багфиксы • Простой и наглядный мониторинг • Адресные оповещения • Доступная отладка
- 14. You got a problem with that?!
- 15. +
- 29. Со стриммингом одни проблемы (
- 30. Diagnostic Messages for this Task: Error: java.lang.RuntimeException: Hive Runtime Error while closing operators SELECT TRANSFORM(*) USING 'python script.py' FROM table;
- 31. И даже тесты не помогут…
- 32. INSERT OVERWRITE TABLE predict SELECT TRANSFORM(line) FROM features_table USING 'umworld_caller.py apply -f model.vw' AS uid, probabilities;
- 33. Traceback (most recent call last) ----> uid, probabilities = '0000000149C7211B6A53058C0942A001 1.3752,- 0.37520000000149BBA4BF2CC10CD6043D1401 1.3752,- 0.3752' ValueError: too many values to unpack
- 34. Очень долго готовить данные
- 35. Типичный алгоритм эксперимента • Выгрузить сэмпл из Hive • Сконвертировать в Pandas • Поиграть с данными • Понять, что чего-то не хватает • Выгрузить другой сэмпл из Hive…
- 38. Почему ?
- 39. It is in-memory and there is a Python API!
- 40. Pandas vs Spark Dataframe import pandas as pd !hive -e "select * from users" > dt.csv df = pd.read_csv("dt.csv") counts = df[df.age > 30] .groupby("sex") .count() from pyspark.sql import HiveContext ctx = HiveContext(sc) df = ctx.sql("select * from users") counts = df[df.age > 30] .groupby("sex") .count()
- 42. А на самом деле…
- 43. SPARK-15139 PySPark TreeEnsemble missing methods SPARK-18177 Add missing ‘subsamplingRate’ of pyspark GBTClassifier SPARK-17025 Cannot persist PySpark ML Pipeline model that includes custom Transformer SPARK-15194 Add Python ML API for MultivariateGaussian
- 47. Driver SparkContext Cluster Manager Worker Node Executor Cache Task Task Worker Node Executor Cache Task Task
- 48. Урок №1 При запуске задачи необходимо явно указывать требуемые ресурсы. Это сильно упрощает жизнь
- 49. Урок №2 При запуске задачи необходимо явно указывать требуемые ресурсы. Это сильно усложняет жизнь
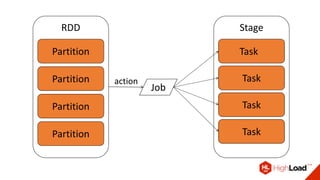
- 50. Narrow (no shuffle): • map • flatMap • filter • sample Wide (shuffle): • sortByKey • reduceByKey • groupByKey • join
- 55. • RDD – низкоуровневый API без оптимизаций • DataFrame – это Spark SQL • Catalyst – оптимизатор запросов • Tungsten Execution Backend
- 56. Урок №4 Используя DataFrame можно меньше париться про оптимизацию вычислений
- 57. Урок №5 При чтении из Hive, Spark создает партиции по числу бакетов таблицы
- 58. Use XGBoost, Luke © Unknown Kaggler
- 59. Почему мы не используем Spark.ML?
- 60. Причина №1 • Vowpal Wabbit и XGBoost в старом пайплайне • Новый код для напилки фич
- 61. Причина №2 SPARK-14374 PySpark ml GBTClassifier, Regressor support export/import (Resolved: 15/Apr/16) SPARK-13034 PySpark ml.classification support export/import (Resolved: 16/Mar/16)
- 62. Причина №3Качествонаобучении Объем обучающей выборки
- 63. Но мы верили, что все изменится :)
- 64. Поэтому поддержали API Spark.ML from pyspark.ml.pipeline import Transformer class BaseTransformer(Transformer): def __init__(self, day=None) def fit(self, df) def _transform(self, df) def load(self, timestamp) def save(self, timestamp)
- 66. Урок №6 При работе с PySpark overhead есть не только у самого Python, но и на перегонку объектов в/из JVM
- 67. Урок №7 Для сериализации используется cloudpickle, а он не всемогущ
- 68. Talk is cheap. Show me the code!
- 69. class SparkXGBoostClassifier(SparkSklearnClassifier): def predict_proba(self, df): rdd = df.map(self._create_dataset) df = rdd.toDF()[['uid', 'feature']] v_model = df._sc.broadcast(self.model) res = df.rdd.mapPartitionsWithIndex( partial(apply_model, v_model=v_model)) return res
- 70. Timing (100 executors – 8gb, 2 vcores) Подзадача Время Загрузить и сджойнить фичи 0:08:49 Сконвертировать трейн в Pandas 0:07:43 Настройка модели 0:01:44 Вычисление качества 0:04:44 Применение модели 0:46:07 Сконвертировать вероятность в ответ 0:02:24 Итого 1:13:05
- 71. Those, who ask questions. You da real MVP!