Apache Spark Tutorial
16 likes1,884 views

The document is a tutorial on scalable data analytics using Apache Spark, highlighting its capability as a cluster computing platform that supports real-time data processing and SQL queries. It covers the architecture of Spark, including its core components like the Spark Core, Spark SQL, and Machine Learning libraries, and provides insights into the roles and workflows of data scientists. Various practical instructions are provided for downloading Spark, initializing applications, and performing data operations using Resilient Distributed Datasets (RDDs) and pair RDDs.







































![Creating Pair RDDs
• Use a map() function that returns key/value pairs.
•pairs = lines.map(lambda x: (x.split(“ ”)[0], x))](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-40-320.jpg)
![Transformations on Pair
RDDs
• Let the rdd be [(1,2),(3,4),(3,6)]
• reduceByKey(func) combines values with the same key.
•>>> rdd.reduceByKey(lambda x,y: x+y) —> [(1,2),(3,10)]
•groupByKey() group values with the same key.
•>>> rdd.groupByKey() —> [(1,[2]),(3,[4,6])]](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-41-320.jpg)


![Transformations on Pair
RDDs
•join() performs an inner join between two RDDs.
•let rdd1 be [(1,2),(3,4),(3,6)] and rdd2 be [(3,9)].
•>>> rdd1.join(rdd2) —> [(3,(4,9)),(3,(6,9))]](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-44-320.jpg)

![Pair RDDs are still RDDs
• Given that pairs is an RDD with the key being an
integer:
•>>> filteredRDD = pairs.filter(lambda x: x[0]>5)](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-46-320.jpg)

![Lets identify the top words
•>>> sc.textFile("README.md")
.flatMap(lambda x: x.split(" "))
.map(lambda x: (x.lower(),1))
.reduceByKey(lambda x,y: x+y)
.map(lambda x: (x[1],x[0]))
.sortByKey(ascending=False)
.take(5)](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-48-320.jpg)

![Per key aggregation
•>>> aggregateRDD = rdd.mapValues(lambda x: (x,
1)).reduceByKey(lambda x, y: x[0]+y[0], x[1]+y[1])](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-50-320.jpg)
![Grouping data
• On an RDD consisting of keys of type K and values of
type V, we get back an RDD of type [K, Iterable[V]].
• >>> rdd.groupByKey()
• We can group data from multiple RDDs using cogroup().
• Given two RDDs sharing the same key type K, with the
respective value types asV and W, the resulting RDD is
of type [K, (Iterable[V], Iterable[W])].
• >>> rdd1.cogroup(rdd2)](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-51-320.jpg)

![Joins
•>>> rdd1,rdd2=[(‘A',1),('B',2),('C',1)],[('A',3),('C',2),('D',
4)]
•>>> rdd1,rdd2=sc.parallelize(rdd1),sc.parallelize(rdd2)
•>>> rdd1.leftOuterJoin(rdd2).collect()
[('A', (1, 3)), ('C', (1, 2)), ('B', (2, None))]
•>>> rdd1.rightOuterJoin(rdd2).collect()
[('A', (1, 3)), ('C', (1, 2)), ('D', (None, 4))]](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-53-320.jpg)

![Actions on pair RDDs
•>>> rdd1=[(‘A',1),('B',2),('C',1)]
•>>> rdd1.collectAsMap()
{'A': 1, 'B': 2, 'C': 1}
•>>> rdd1.countByKey()[‘A’]
1](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-55-320.jpg)


![Accumulators
•>>> inputfile = sc.textFile(inputFile)
• ## Lets create an Accumulator[Int] initialized to 0
•>>> blankLines = sc.accumulator(0)](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-58-320.jpg)

















![MappingYahoo’s click data
•>>> import math
•>>> rdd = sc.textFile("yahoo_keywords_bids_clicks")
.map(lambda line: (line.split("t")[3],
(float(line.split(“t")[-2]),float(line.split("t")
[-1]))))
•>>> rdd =
rdd.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1]))
.mapValues(lambda x: 1 if (x[1]/x[0])>0 else 0)](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-76-320.jpg)


![flatMapping
•>>> keyphrases0 = rdd.filter(lambda x: x[1]==0)
•>>> keyphrases1 = rdd.filter(lambda x: x[1]==1)
•>>> rdd0 =
keyphrases0.flatMap(lambda x: [(e,1) for e in x[0].split()])
•>>> rdd1 =
keyphrases1.flatMap(lambda x: [(e,1) for e in x[0].split()])
•>>> iR = keyphrases0.count()
•>>> R = keyphrases1.count()](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-79-320.jpg)




![Joining to compute ct
•>>> ct_rdd = t_rdd0.join(t_rdd1).mapValues(lambda x:
math.log(x[1]/x[0]))](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-84-320.jpg)

![Measuring the accuracy of
clickiness prediction
•>>> def accuracy(rdd, cts, threshold):
csv_rdd = rdd.map(lambda x: (x[0],x[1],sum([
cts.value[t] for t in x[0].split() if t in cts.value])))
results = csv_rdd.map(lambda x:
(x[1] == (1 if x[2] > threshold else 0),1))
.reduceByKey(lambda x,y: x+y).collect()
print float(results[1][1]) /
(results[0][1]+results[1][1])
•>>> accuracy(rdd,cts,10)
•>>> accuracy(rdd,cts,-10)](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-86-320.jpg)










![Working with Row objects
• In Python, you access the ith row element using row[i] or
using the column name as row.column_name.
•>>> topterms.map(lambda row: row.Keyword)](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-98-320.jpg)


![Converting an RDD to a
SchemaRDD
• First create an RDD of Row objects and then call
inferSchema() on it.
•>>> rdd = sc.parallelize([Row(name=“hero”,
favouritecoffee=“industrial blend”)])
•>>> srdd = hiveCtx.inferSchema(rdd)
•>>> srdd.registerTempTable(“myschemardd”)](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-101-320.jpg)
![Working with nested data
•>>> a = [{'name': 'mickey'}, {'name': 'pluto', 'knows':
{'friends': ['mickey',‘donald']}}]
•>>> rdd = sc.parallelize(a)
•>>> rdd.map(lambda x:
json.dumps(x)).saveAsTextFile(“test")
•>>> srdd = sqlContext.jsonFile(“test")](https://image.slidesharecdn.com/mysparktutorial-151211040107/85/Apache-Spark-Tutorial-102-320.jpg)



















Apache Spark Tutorial
- 1. Tutorial: Scalable Data Analytics using Apache Spark Dr.Ahmet Bulut @kral http://www.linkedin.com/in/ahmetbulut
- 3. Cluster Computing • Apache Spark is a cluster computing platform designed to be fast and general-purpose. • Running computational tasks across many worker machines, or a computing cluster.
- 4. Unified Computing • In Spark, you can write one application that uses machine learning to classify data in real time as it is ingested from streaming sources. • Simultaneously, analysts can query the resulting data, also in real time, via SQL (e.g., to join the data with unstructured log-files). • More sophisticated data engineers and data scientists can access the same data via the Python shell for ad hoc analysis.
- 5. Spark Stack
- 6. Spark Core • Spark core:“computational engine” that is responsible for scheduling, distributing, and monitoring applications consisting of many computational tasks on a computing cluster.
- 7. Spark Stack • Spark Core: the basic functionality of Spark, including components for task scheduling, memory management, fault recovery, interacting with storage systems, and more. • Spark SQL: Spark’s package for working with structured data. • Spark Streaming: Spark component that enables processing of live streams of data.
- 8. Spark Stack • MLlib: library containing common machine learning (ML) functionality including classification, regression, clustering, and collaborative filtering, as well as supporting functionality such as model evaluation and data import. • GraphX: library for manipulating graphs (e.g., a social network’s friend graph) and performing graph-parallel computations. • Cluster Managers: Standalone Scheduler,Apache Mesos, HadoopYARN.
- 9. “Data Scientist: a person, who is better at statistics than a computer engineer, and better at computer engineering than a statistician.” I do not believe in this new job role. Data Science is embracing all stakeholders.
- 10. Data Scientists of Spark age • Data scientists use their skills to analyze data with the goal of answering a question or discovering insights. • Data science workflow involves ad hoc analysis. • Data scientists use interactive shells (vs. building complex applications) for seeing the results to their queries and for writing snippets of code quickly.
- 11. Data Scientists of Spark age • Spark’s speed and simple APIs shine for data science, and its built-in libraries mean that many useful algorithms are available out of the box.
- 12. Storage Layer • Spark can create distributed datasets from any file stored in the Hadoop distributed filesystem (HDFS) or other storage systems supported by the Hadoop APIs (including your local filesystem,Amazon S3, Cassandra, Hive, HBase, etc.). • Spark does not require Hadoop; it simply has support for storage systems implementing the Hadoop APIs. • Spark supports text files, SequenceFiles, Avro, Parquet, and any other Hadoop InputFormat.
- 13. Downloading Spark • The first step to using Spark is to download and unpack it. • For a recent precompiled released version of Spark. • Visit http://spark.apache.org/downloads.html • Select the package type of “Pre-built for Hadoop 2.4 and later,” and click “Direct Download.” • This will download a compressed TAR file, or tarball, called spark-1.2.0-bin-hadoop2.4.tgz.
- 14. Directory structure • README.md Contains short instructions for getting started with Spark. • bin Contains executable files that can be used to interact with Spark in various ways.
- 15. Directory structure • core, streaming, python, ... Contains the source code of major components of the Spark project. • examples Contains some helpful Spark standalone jobs that you can look at and run to learn about the Spark API.
- 16. PySpark • The first step is to open up one of Spark’s shells.To open the Python version of the Spark shell, which we also refer to as the PySpark Shell, go into your Spark directory and type: $ bin/pyspark
- 17. Logging verbosity • You can control the verbosity of the logging, create a file in the conf directory called log4j.properties. • To make the logging less verbose, make a copy of conf/ log4j.properties.template called conf/log4j.properties and find the following line: log4j.rootCategory=INFO, console Then lower the log level to log4j.rootCategory=WARN, console
- 18. IPython • IPython is an enhanced Python shell that offers features such as tab completion. Instructions for installing it is at http://ipython.org. • You can use IPython with Spark by setting the IPYTHON environment variable to 1: IPYTHON=1 ./bin/pyspark
- 19. IPython • To use the IPython Notebook, which is a web-browser- based version of IPython, use IPYTHON_OPTS="notebook" ./bin/pyspark • On Windows, set the variable and run the shell as follows: set IPYTHON=1 binpyspark
- 20. Script #1 •# Create an RDD >>> lines = sc.textFile("README.md") •# Count the number of items in the RDD >>> lines.count() •# Show the first item in the RDD >>> lines.first()
- 21. Resilient Distributed Dataset • The variable lines is an RDD: Resilient Distributed Dataset. • on RDDs, you can run parallel operations.
- 22. Intro to Core Spark Concepts • Every Spark application consists of a driver program that launches various parallel operations on a cluster. • Spark Shell is a driver program itself. • Driver programs access Spark through SparkContext object, which represents a connection to a computing cluster. • In the Spark shell, the context is automatically created as the variable sc.
- 23. Architecture
- 24. Intro to Core Spark Concepts • Driver programs manage a number of nodes called executors. • For example, running the count() on a cluster would translate into different nodes counting the different ranges of the input file.
- 25. Script #2 •>>> lines = sc.textFile(“README.md”) •>>> pythonLines = lines.filter(lambda line:“Python” in line) •>>> pythonLines.first()
- 26. Standalone applications • Apart from running interactively, Spark can be linked into standalone applications in either Python, Scala, or Java. • The main difference is that you need to initialize your own SparkContext. • How to py it: Write your applications as Python scripts as you normally do, but to run them with cluster aware logic, use spark-submit script.
- 27. Standalone applications •$ bin/spark-submit my_script.py • The spark-submit script sets up the environment for Spark’s Python API to function by including Spark dependencies.
- 28. Initializing Spark in Python • # Excerpt from your driver program from pyspark import SparkConf, SparkContext conf = SparkConf().setMaster(“local”).setAppName(“My App”) sc = SparkContext(conf=conf)
- 29. Operations
- 30. Operations on RDDs • Transformations and Actions. • Transformations construct a new RDD from a previous one. • “Filtering data that matches a predicate” is an example transformation.
- 31. Transformations • Let’s create an RDD that holds strings containing the word Python. •>>> pythonLines = lines.filter(lambda line:“Python” in line)
- 32. Actions • Actions compute a result based on an RDD. • They can return the result to the driver, or to an external storage system (e.g., HDFS). •>>> pythonLines.first()
- 33. Transformations & Actions • You can create RDDs at any time using transformations. • But, Spark will materialize them once they are used in an action. • This is a lazy approach to RDD creation.
- 34. Lazy … • Assume that you want to work with a Big Data file. • But you are only interested in the lines that contain Python. • were Spark to load and save all the lines in the file as soon as sc.textFile(…) is called, it would waste storage space. • Therefore, Spark chooses to see all transformations first, and then compute the result to an action.
- 35. Persistence of RDDs • RDDs are re-computed each time you run an action on them. • In order to re-use an RDD in multiple actions, you can ask Spark to persist it using RDD.persist().
- 36. Resilience of RDDs • Once computed, RDD is materialized in memory. • Persistence to disk is also possible. • Persistence is optional, and not a default behavior.The reason is that if you are not going to re-use an RDD, there is no point in wasting storage space by persisting it. • The ability to re-compute is what makes RDDs resilient to node failures.
- 37. Pair RDDs
- 38. Working with Key/Value Pairs • Most often you ETL your data into a key/value format. • Key/value RDDs let you count up reviews for each product, group together data with the same key, group together two different RDDs.
- 39. Pair RDD • RDDs containing key/value pairs are called pair RDDs. • Pair RDDs are a useful building block in many programs as they expose operations that allow you to act on each key in parallel or regroup data across the network. • For example, pair RDDs have a reduceByKey() method that can aggregate data separately for each key. • join() method merges two RDDs together by grouping elements with the same key.
- 40. Creating Pair RDDs • Use a map() function that returns key/value pairs. •pairs = lines.map(lambda x: (x.split(“ ”)[0], x))
- 41. Transformations on Pair RDDs • Let the rdd be [(1,2),(3,4),(3,6)] • reduceByKey(func) combines values with the same key. •>>> rdd.reduceByKey(lambda x,y: x+y) —> [(1,2),(3,10)] •groupByKey() group values with the same key. •>>> rdd.groupByKey() —> [(1,[2]),(3,[4,6])]
- 42. Transformations on Pair RDDs • mapValues(func) applies a function to each value of a pair RDD without changing the key. •>>> rdd.mapValues(lambda x: x+1) •keys() returns an rdd of just the keys. •>>> rdd.keys() •values() returns an rdd of just the values. •>>> rdd.values()
- 43. Transformations on Pair RDDs • sortByKey() returns an rdd, which has the same contents as the original rdd, but sorted by its keys. •>>> rdd.sortByKey()
- 44. Transformations on Pair RDDs •join() performs an inner join between two RDDs. •let rdd1 be [(1,2),(3,4),(3,6)] and rdd2 be [(3,9)]. •>>> rdd1.join(rdd2) —> [(3,(4,9)),(3,(6,9))]
- 45. Pair RDDs are still RDDs you can also filter by value! try.
- 46. Pair RDDs are still RDDs • Given that pairs is an RDD with the key being an integer: •>>> filteredRDD = pairs.filter(lambda x: x[0]>5)
- 47. Lets do a word count •>>> rdd = sc.textFile(“README.md”) •>>> words = rdd.flatMap(lambda x: x.split(“ ”)) •>>> result = words.map(lambda x: (x,1)).reduceByKey(lambda x,y: x+y)
- 48. Lets identify the top words •>>> sc.textFile("README.md") .flatMap(lambda x: x.split(" ")) .map(lambda x: (x.lower(),1)) .reduceByKey(lambda x,y: x+y) .map(lambda x: (x[1],x[0])) .sortByKey(ascending=False) .take(5)
- 50. Per key aggregation •>>> aggregateRDD = rdd.mapValues(lambda x: (x, 1)).reduceByKey(lambda x, y: x[0]+y[0], x[1]+y[1])
- 51. Grouping data • On an RDD consisting of keys of type K and values of type V, we get back an RDD of type [K, Iterable[V]]. • >>> rdd.groupByKey() • We can group data from multiple RDDs using cogroup(). • Given two RDDs sharing the same key type K, with the respective value types asV and W, the resulting RDD is of type [K, (Iterable[V], Iterable[W])]. • >>> rdd1.cogroup(rdd2)
- 52. Joins • There are two types of joins as inner joins and outer joins. • Inner joins require a key to be present in both RDDs. There is a join() call. • Outer joins do not require a key to be present in both RDDs.There is a leftOuterJoin() and rightOuterJoin(). None is used as the value for the RDD which has the key missing.
- 53. Joins •>>> rdd1,rdd2=[(‘A',1),('B',2),('C',1)],[('A',3),('C',2),('D', 4)] •>>> rdd1,rdd2=sc.parallelize(rdd1),sc.parallelize(rdd2) •>>> rdd1.leftOuterJoin(rdd2).collect() [('A', (1, 3)), ('C', (1, 2)), ('B', (2, None))] •>>> rdd1.rightOuterJoin(rdd2).collect() [('A', (1, 3)), ('C', (1, 2)), ('D', (None, 4))]
- 54. Sorting data • We can sort an RDD with Key/Value pairs provided that there is an ordering defined on the key. • Once we sorted our data, subsequent calls, e.g., collect(), return ordered data. •>>> rdd.sortByKey(ascending=True, numPartitions=None, keyfunc=lambda x: str(x))
- 55. Actions on pair RDDs •>>> rdd1=[(‘A',1),('B',2),('C',1)] •>>> rdd1.collectAsMap() {'A': 1, 'B': 2, 'C': 1} •>>> rdd1.countByKey()[‘A’] 1
- 57. Accumulators • Accumulators are shared variables. • They are used to aggregate values from worker nodes back to the driver program. • One of the most common uses of accumulators is to count events that occur during job execution for debugging purposes.
- 58. Accumulators •>>> inputfile = sc.textFile(inputFile) • ## Lets create an Accumulator[Int] initialized to 0 •>>> blankLines = sc.accumulator(0)
- 59. Accumulators •>>> def parseOutAndCount(line): # Make the global variable accessible global blankLines if (line == ""): blankLines += 1 return line.split(" ") •>>> rdd = inputfile.flatMap(parseOutAndCount) • Do an action so that the workers do real work! •>>> rdd.saveAsTextFile(outputDir + "/xyz") •>>> blankLines.value
- 60. Accumulators & Fault Tolerance • Spark automatically deals with failed or slow machines by re-executing failed or slow tasks. • For example, if the node running a partition of a map() operation crashes, Spark will rerun it on another node. • If the node does not crash but is simply much slower than other nodes, Spark can preemptively launch a “speculative” copy of the task on another node, and take its result instead if that finishes earlier.
- 61. Accumulators & Fault Tolerance • Even if no nodes fail, Spark may have to rerun a task to rebuild a cached value that falls out of memory. “The net result is therefore that the same function may run multiple times on the same data depending on what happens on the cluster.”
- 62. Accumulators & Fault Tolerance • For accumulators used in actions, Spark applies each task’s update to each accumulator only once. • For accumulators used in RDD transformations instead of actions, this guarantee does not exist. • Bottomline: use accumulators only in actions.
- 63. BroadcastVariables • Spark’s second type of shared variable, broadcast variables, allows the program to efficiently send a large, read-only value to all the worker nodes for use in one or more Spark operations. • Use it if your application needs to send a large, read- only lookup table or a large feature vector in a machine learning algorithm to all the nodes.
- 64. Yahoo SEM Click Data • Dataset:Yahoo’s Search Marketing Advertiser Bid- Impression-Click data, version 1.0 • 77,850,272 rows, 8.1GB in total. • Data fields: 0 day 1 anonymized account_id 2 rank 3 anonymized keyphrase (list of anonymized keywords) 4 avg bid 5 impressions 6 clicks
- 65. Sample data rows 1 08bade48-1081-488f-b459-6c75d75312ae 2 2affa525151b6c51 79021a2e2c836c1a 327e089362aac70c fca90e7f73f3c8ef af26d27737af376a 100.0 2.0 0.0 29 08bade48-1081-488f-b459-6c75d75312ae 3 769ed4a87b5010f4 3d4b990abb0867c8 cd74a8342d25d090 ab9f74ae002e80ff af26d27737af376a 100.0 1.0 0.0 29 08bade48-1081-488f-b459-6c75d75312ae 2 769ed4a87b5010f4 3d4b990abb0867c8 cd74a8342d25d090 ab9f74ae002e80ff af26d27737af376a 100.0 1.0 0.0 11 08bade48-1081-488f-b459-6c75d75312ae 1 769ed4a87b5010f4 3d4b990abb0867c8 cd74a8342d25d090 ab9f74ae002e80ff af26d27737af376a 100.0 2.0 0.0 76 08bade48-1081-488f-b459-6c75d75312ae 2 769ed4a87b5010f4 3d4b990abb0867c8 cd74a8342d25d090 ab9f74ae002e80ff af26d27737af376a 100.0 1.0 0.0 48 08bade48-1081-488f-b459-6c75d75312ae 3 2affa525151b6c51 79021a2e2c836c1a 327e089362aac70c fca90e7f73f3c8ef af26d27737af376a 100.0 2.0 0.0 97 08bade48-1081-488f-b459-6c75d75312ae 2 2affa525151b6c51 79021a2e2c836c1a 327e089362aac70c fca90e7f73f3c8ef af26d27737af376a 100.0 1.0 0.0 123 08bade48-1081-488f-b459-6c75d75312ae 5 769ed4a87b5010f4 3d4b990abb0867c8 cd74a8342d25d090 ab9f74ae002e80ff af26d27737af376a 100.0 1.0 0.0 119 08bade48-1081-488f-b459-6c75d75312ae 3 2affa525151b6c51 79021a2e2c836c1a 327e089362aac70c fca90e7f73f3c8ef af26d27737af376a 100.0 1.0 0.0 73 08bade48-1081-488f-b459-6c75d75312ae 1 2affa525151b6c51 79021a2e2c836c1a 327e089362aac70c fca90e7f73f3c8ef af26d27737af376a 100.0 1.0 0.0 • Primary key: date, account_id, rank and keyphrase. • Average bid, impressions and clicks information is aggregated over the primary key.
- 66. Feeling clicky? keyphrase impressions clicks iphone 6 plus for cheap 100 2 new samsung tablet 10 1 iphone 5 refurbished 2 0 learn how to program for iphone 200 0
- 67. Getting Clicks = Popularity • Click Through Rate (CTR) = ————————— # of impressions • If CTR > 0, it is a popular keyphrase. • If CTR == 0, it is an unpopular keyphrase. # of clicks
- 68. Keyphrase = {terms} • Given keyphrase “iphone 6 plus for cheap”, its terms are: iphone 6 plus for cheap
- 69. Contingency table Keyphrases got clicks no clicks Total term t present s n-s n term t absent S-s (N-S)-(n-s) N-n Total S N-S N
- 70. Clickiness of a term • For the term presence to click reception contingency table shown previously, we can compute a given term t’s clickiness value ct as follows: • ct = log —————————— (n-s+0.5)/(N-n-S+s+0.5) (s+0.5)/(S-s+0.5)
- 71. Clickiness of a keyphrase • Given a keyphrase K that consists of terms t1 t2 … tn, its clickiness can be computed by summing up the clickiness of the terms present in it. • That is, cK = ct1 + ct2 + … + ctn
- 72. Feeling clicky? keyphrase impressions clicks clickiness iphone 6 plus for cheap 100 2 1 new samsung tablet 10 1 1 iphone 5 refurbished 2 0 0 learn how to program for iphone 200 0 0
- 73. Clickiness of iphone Keyphrases got clicks no clicks Total term iphone present 1 2 3 term iphone absent 1 0 1 Total 2 2 4
- 74. Clickiness of iphone ciphone = log ——————— (2+0.5)/(0+0.5) (1+0.5)/(1+0.5)
- 75. • Given keyphrases and their clickiness k1 = t12 t23 … t99 1 k2 = t19 t201 … t1 0 k3 = t1 t2 … t101 1 … … kn = t1 t2 … t101 1 Mapping
- 76. MappingYahoo’s click data •>>> import math •>>> rdd = sc.textFile("yahoo_keywords_bids_clicks") .map(lambda line: (line.split("t")[3], (float(line.split(“t")[-2]),float(line.split("t") [-1])))) •>>> rdd = rdd.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])) .mapValues(lambda x: 1 if (x[1]/x[0])>0 else 0)
- 77. • Given keyphrases and their clickiness k1 = t12 t23 … t99 1 k2 = t19 t201 … t1 0 k3 = t1 t2 … t101 1 … … kn = t1 t2 … t101 1 flatMapping (t19, 0), (t201, 0),…, (t1, 0) flatMap it to
- 78. • Given keyphrases and their clickiness k1 = t12 t23 … t99 1 k2 = t19 t201 … t1 0 k3 = t1 t2 … t101 1 … … kn = t1 t2 … t101 1 flatMapping (t19, 0), (t201, 0),…, (t1, 0) flatMap it to (t1, 1), (t2, 1),…, (t101, 1) flatMap it to
- 79. flatMapping •>>> keyphrases0 = rdd.filter(lambda x: x[1]==0) •>>> keyphrases1 = rdd.filter(lambda x: x[1]==1) •>>> rdd0 = keyphrases0.flatMap(lambda x: [(e,1) for e in x[0].split()]) •>>> rdd1 = keyphrases1.flatMap(lambda x: [(e,1) for e in x[0].split()]) •>>> iR = keyphrases0.count() •>>> R = keyphrases1.count()
- 80. Reducing (t1, 19) (t12, 19) (t101, 19) … … (t1, 200) (t12, 11) (t101, 1) … … rdd0 rdd1
- 81. Reducing by Key and MappingValues •>>> t_rdd0 = rdd0.reduceByKey(lambda x,y: x +y).mapValues(lambda x: (x+0.5)/(iR-x+0.5)) •>>> t_rdd1 = rdd1.reduceByKey(lambda x,y: x +y).mapValues(lambda x: (x+0.5)/(R-x+0.5))
- 82. MappingValues (t1, some float value) (t12, some float value) (t101, some float value) … … (t1, some float value) (t12, some float value) (t101, some float value) … … t_rdd0 t_rdd1
- 83. Joining to compute ct (t1, some float value) (t12, some float value) (t101, some float value) … … (t1, some float value) (t12, some float value) (t101, some float value) … … t_rdd0 t_rdd1
- 84. Joining to compute ct •>>> ct_rdd = t_rdd0.join(t_rdd1).mapValues(lambda x: math.log(x[1]/x[0]))
- 85. Broadcasting to all workers the look-up table ct •>>> cts = sc.broadcast(dict(ct_rdd.collect()))
- 86. Measuring the accuracy of clickiness prediction •>>> def accuracy(rdd, cts, threshold): csv_rdd = rdd.map(lambda x: (x[0],x[1],sum([ cts.value[t] for t in x[0].split() if t in cts.value]))) results = csv_rdd.map(lambda x: (x[1] == (1 if x[2] > threshold else 0),1)) .reduceByKey(lambda x,y: x+y).collect() print float(results[1][1]) / (results[0][1]+results[1][1]) •>>> accuracy(rdd,cts,10) •>>> accuracy(rdd,cts,-10)
- 87. Spark SQL
- 88. Spark SQL • Spark’s interface to work with structured and semistructured data. • Structured data is any data that has a schema, i.e., a know set of fields for each record.
- 89. Spark SQL • Spark SQL can load data from a variety of structured sources (e.g., JSON, Hive and Parquet). • Spark SQL lets you query the data using SQL both inside a Spark program and from external tools that connect to Spark SQL through standard database connectors (JDBC/ODBC), such as business intelligence tools like Tableau. • You can join RDDs and SQL Tables using Spark SQL.
- 90. Spark SQL • Spark SQL provides a special type of RDD called SchemaRDD. • A SchemaRDD is an RDD of Row objects, each representing a record. • A SchemaRDD knows the schema of its rows. • You can run SQL queries on SchemaRDDs. • You can create SchemaRDD from external data sources, from the result of queries, or from regular RDDs.
- 91. Spark SQL
- 92. Spark SQL • Spark SQL can be used via SQLContext or HiveContext. • SQLContext supports a subset of Spark SQL functionality excluding Hive support. • Use HiveContext. • If you have an existing Hive installation, you need to copy your hive-site.xml to Spark’s configuration directory.
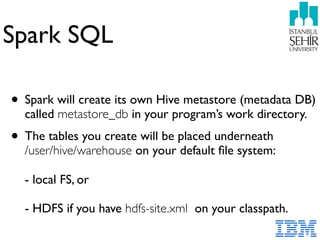
- 93. Spark SQL • Spark will create its own Hive metastore (metadata DB) called metastore_db in your program’s work directory. • The tables you create will be placed underneath /user/hive/warehouse on your default file system: - local FS, or - HDFS if you have hdfs-site.xml on your classpath.
- 94. Creating a HiveContext • >>> ## Assuming that sc is our SparkContext •>>> from pyspark.sql import HiveContext, Row •>>> hiveCtx = HiveContext(sc)
- 95. Basic Query Example • ## Assume that we have an input JSON file. •>>> rdd=hiveCtx.jsonFile(“reviews_Books.json”) •>>> rdd.registerTempTable(“reviews”) •>>> topterms = hiveCtx.sql(“SELECT * FROM reviews LIMIT 10").collect()
- 96. SchemaRDD • Both loading data and executing queries return a SchemaRDD. • A SchemaRDD is an RDD composed of Row objects with additional schema information of the types in each column. • Row objects are wrappers around arrays of basic types (e.g., integers and strings). • In most recent Spark versions, SchemaRDD is renamed to DataFrame.
- 97. SchemaRDD • A SchemaRDD is also an RDD, and you can run regular RDD transformations (e.g., map(), and filter()) on them as well. • You can register any SchemaRDD as a temporary table to query it a via hiveCtx.sql.
- 98. Working with Row objects • In Python, you access the ith row element using row[i] or using the column name as row.column_name. •>>> topterms.map(lambda row: row.Keyword)
- 99. Caching • If you expect to run multiple tasks or queries agains the same data, you can cache it. •>>> hiveCtx.cacheTable(“mysearchterms”) • When caching a table, Spark SQL represents the data in an in-memory columnar format. • The cached table will be destroyed once the driver exits.
- 100. Printing schema •>>> rdd=hiveCtx.jsonFile(“reviews_Books.json”) •>>> rdd.printSchema()
- 101. Converting an RDD to a SchemaRDD • First create an RDD of Row objects and then call inferSchema() on it. •>>> rdd = sc.parallelize([Row(name=“hero”, favouritecoffee=“industrial blend”)]) •>>> srdd = hiveCtx.inferSchema(rdd) •>>> srdd.registerTempTable(“myschemardd”)
- 102. Working with nested data •>>> a = [{'name': 'mickey'}, {'name': 'pluto', 'knows': {'friends': ['mickey',‘donald']}}] •>>> rdd = sc.parallelize(a) •>>> rdd.map(lambda x: json.dumps(x)).saveAsTextFile(“test") •>>> srdd = sqlContext.jsonFile(“test")
- 103. Working with nested data • >>> srdd.printSchema() root |-- knows: struct (nullable = true) | |-- friends: array (nullable = true) | | |-- element: string (containsNull = true) |-- name: string (nullable = true)
- 104. Working with nested data •>>> srdd.registerTempTable("test") • >>> sqlContext.sql("SELECT knows.friends FROM test").collect()
- 105. MLlib
- 106. MLlib • Spark’s library of machine learning functions. • The design philosophy is simple: - Invoke ML algorithms on RDDs.
- 107. Learning in a nutshell
- 108. Learning in a nutshell
- 109. Learning in a nutshell
- 110. Text Classification • Step 1. Start with an RDD of strings representing your messages. • Step 2. Run one of MLlib’s feature extraction algorithms to convert text into numerical features (suitable for learning algorithms).The result is an RDD of vectors. • Step 3. Call a classification algorithm (e.g., logistic regression) on the RDD of vectors.The result is a model.
- 111. Text Classification • Step 4.You can evaluate the model on a test set. • Step 5.You can use the model for point shooting. Given a new data sample, you can classify it using the model.
- 112. System requirements • MLlib requires gfortran runtime library for your OS. • MLlib needs NumPy.
- 113. Spam Classification •>>> from pyspark.mllib.regression import LabeledPoint •>>> from pyspark.mllib.feature import HashingTF •>>> from pyspark.mllib.classification import LogisticRegressionWithSGD •>>> spamRows = sc.textFile(“spam.txt”) •>>> hamRows = sc.textFile(“ham.txt”)
- 114. Spam Classification • ### for mapping emails to vectors of 10000 features. •>>> tf = HashingTF(numFeatures=10000)
- 115. Spam Classification • ## Feature Extraction, email —> word features •>>> spamFeatures = spamRows.map(lambda email: tf.transform(email.split(“ ”))) •>>> hamFeatures = hamRows.map(lambda email: tf.transform(email.split(“ ”)))
- 116. Spam Classification • ### Label feature vectors •>>> spamExamples = spamFeatures.map(lambda features: LabeledPoint(1, features)) •>>> hamExamples = hamFeatures.map(lambda features: LabeledPoint(0, features))
- 117. Spam Classification •>>> trainingData = spamExamples.union(hamExamples) • ### Since learning via Logistic Regression is iterative •>>> trainingData.cache()
- 118. Spam Classification •>>> model = LogisticRegressionWithSGD.train(trainingData)
- 119. Spam Classification • ### Lets test it! •>>> posTest = tf.transform(“O M G GET cheap stuff”.split(“ ”)) •>>> negTest = tf.transform(“Enjoy Spark on Machine Learning”.split(“ ”)) •>>> print model.predict(posTest) •>>> print model.predict(negTest)
- 120. Data Types • MLlib contains a few specific data types located in pyspark.mllib. •Vector : a mathematical vector (sparse or dense). •LabeledPoint : a pair of feature vector and its label. •Rating : a rating of a product by a user. • Various Model classes : the resulting model from training. It has a predict() function for ad-hoc querying.
- 121. Spark it!