Apache Spark: Usage and Roadmap in Hadoop
Download as PPTX, PDF9 likes4,389 views

Spark will replace MapReduce as the standard execution engine for Hadoop. Spark is faster than MapReduce for iterative jobs and can be used for batch processing, streaming, machine learning, and graph processing workloads. Cloudera is leading the effort to integrate Spark with Hadoop and make it enterprise ready through initiatives like the One Platform initiative to unify Spark and Hadoop for management, security, scale, and streaming capabilities.

















Apache Spark: Usage and Roadmap in Hadoop
- 1. 1© Cloudera, Inc. All rights reserved. Apache Spark: Usage and Roadmap in Hadoop Jai Ranganathan
- 2. 2© Cloudera, Inc. All rights reserved. Spark will replace MapReduce To become the standard execution engine for Hadoop
- 3. 3© Cloudera, Inc. All rights reserved. The Future of Data Processing on Hadoop Spark complemented by specialized fit-for-purpose engines General Data Processing w/Spark Fast Batch Processing, Machine Learning, and Stream Processing Analytic Database w/Impala Low-Latency Massively Concurrent Queries Full-Text Search w/Solr Querying textual data On-Disk Processing w/MapReduce Jobs at extreme scale and extremely disk IO intensive Shared: • Data Storage • Metadata • Resource Management • Administration • Security • Governance
- 4. 4© Cloudera, Inc. All rights reserved. Cloudera Leading the Spark Movement 2013 2014 2015 2016 Identified Spark’s early potential Ships and Supports Spark with CDH 4.4 Spark on YARN integration Announces initiative to make Spark the standard execution engine Launches first Spark training Added security integration Cloudera engineers publish O’Reilly Spark book Leading effort to further performance, usability, and enterprise-readiness
- 5. 5© Cloudera, Inc. All rights reserved. Community Initiative: Spark Supersedes MapReduce Stage 1 • Crunch on Spark • Search on Spark Stage 2 • Hive on Spark (beta) • Spark on HBase (beta) Stage 3 • Pig on Spark (alpha) • Sqoop on Spark Community development to port components to Spark:
- 6. 6© Cloudera, Inc. All rights reserved. Cloudera Customer Use Cases Core Spark Spark Streaming • Portfolio Risk Analysis • ETL Pipeline Speed-Up • 20+ years of stock dataFinancial Services Health • Identify disease-causing genes in the full human genome • Calculate Jaccard scores on health care data sets ERP • Optical Character Recognition and Bill Classification • Trend analysis • Document classification (LDA) • Fraud analyticsData Services 1010 • Online Fraud Detection Financial Services Health • Incident Prediction for Sepsis Retail • Online Recommendation Systems • Real-Time Inventory Management Ad Tech • Real-Time Ad Performance Analysis
- 7. 7© Cloudera, Inc. All rights reserved. Apache Spark Flexible, in-memory data processing for Hadoop Easy Development Flexible Extensible API Fast Batch & Stream Processing • Rich APIs for Scala, Java, and Python • Interactive shell • APIs for different types of workloads: • Batch • Streaming • Machine Learning • Graph • In-Memory processing and caching
- 8. 8© Cloudera, Inc. All rights reserved. The Spark Ecosystem & Hadoop Hadoop Integration • Spark-on-YARN integration • Shares data, metadata, administration, security, & governance STORAGE HDFS, HBase RESOURCE MANAGEMENT YARN Spark Impala MR Others Spark Streamin g MLlib SparkSQL GraphX Data- frames SparkR
- 9. 9© Cloudera, Inc. All rights reserved. Logistic Regression Performance (Data Fits in Memory) 0 500 1000 1500 2000 2500 3000 3500 4000 1 5 10 20 30 RunningTime(s) # of Iterations MapReduce Spark 110 s/iteration First iteration = 80s Further iterations 1s due to caching
- 10. 10© Cloudera, Inc. All rights reserved. Apache Spark Streaming What is it? • Run continuous processing of data using Spark’s core API • Extends Spark concepts to fault-tolerant, transformable streams • Adds “rolling window” operations • Example: Compute rolling averages or counts for data over last five minutes Benefits: • Reuse knowledge and code in both contexts • Same programming paradigm for streaming and batch • Simplicity of development • High-level API with automatic DAG generation • Excellent throughput • Scale easily to support large volumes of data ingest • Combine elements like MLlib and Oryx into streaming applications Common Use Cases: • “On-the-fly” ETL as data is ingested into Hadoop/HDFS • Detect anomalous behavior and trigger alerts • Continuous reporting of summary metrics for incoming data
- 11. 11© Cloudera, Inc. All rights reserved. Spark Streaming Architectures Data Sources Ingest Integration Layer • Flume • Kafka Spark Stream Processing Data Prep Aggregation / Scoring HDFS Spark Long-Term Analytics/ Model Building HBase Real-Time Result Serving
- 12. 12© Cloudera, Inc. All rights reserved. SparkSQL + Dataframes Machine Learning Applications • Goal: • Spark/Java Developers and Data Scientists can inline SQL into Spark apps • Designed for: • Ease of development for Spark developers • Handful of concurrent Spark jobs • Strengths: • Ease of embedding SQL into Java or Scala applications • SQL for common functionality in developer flow (eg. aggregations, filters, samples)
- 13. 13© Cloudera, Inc. All rights reserved. Execution Pipeline SQL AST Logical Plan Optimized Logical Plan Logical Plan Physical Plans CBO Selected Plan RDDsRDDsRDDs Dataframes
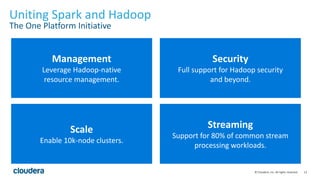
- 14. 14© Cloudera, Inc. All rights reserved. Uniting Spark and Hadoop The One Platform Initiative Management Leverage Hadoop-native resource management. Security Full support for Hadoop security and beyond. Scale Enable 10k-node clusters. Streaming Support for 80% of common stream processing workloads.
- 15. 15© Cloudera, Inc. All rights reserved. Management Security Scale Streaming • Spark on YARN Integration • HBase integration • Improved metrics for monitoring/troubleshooting • Dynamic Resource Allocation • Spark on YARN: • Container resizing • Dynamic Resource Allocation for Streaming • Simplified resource configuration • Improved WebUI for debugging • Improved metrics for visibility into resource utilization • Smart auto-tuning of job parameters • Kerberos Integration • HDFS Sync (Sentry) • Secure data at rest • Secure data over the wire • Audit/Lineage (Navigator) • Spark PCI compliance • Integration with Intel’s advanced encryption libraries • Enable column and view level security • Revamp Scheduler handling of node failure • Sort based shuffle improvements • Task Scheduling based on HDFS data locality and caching • Scheduler improvements for performance at scale • Stress test at scale with mixed multi-tenant workloads • HDFS DDM Integration • Dynamic resource utilization & prioritization • Scale Spark History Server for 1000s of jobs • Zero Data Loss with Spark Streaming Resilience • Flume integration • Kafka integration • SQL semantics for expressing streaming jobs (Business Users) • New streaming specific API extensions • Streaming application management (pause, update, redeploy) via CM • Optimized state updates: efficient point lookups and delta updates Detailed Roadmap: One Platform Initiative = Completed Work = Planned Future Work
- 16. 16© Cloudera, Inc. All rights reserved. Spark Resources • Learn Spark • O’Reilly Advanced Analytics with Spark eBook (written by Clouderans) • Cloudera Developer Blog • cloudera.com/spark • Get Trained • Cloudera Spark Training • Try it Out • Cloudera Live Spark Tutorial
- 17. 17© Cloudera, Inc. All rights reserved. Try It With Cloudera Live cloudera.com/live Featuring tutorials on: CDH
- 18. 18© Cloudera, Inc. All rights reserved. Thank You Jairam Ranganathan [email protected]