







![The ZooKeeper Data Model (ZDM)
• Hierarchal name space
• Each node is called as a ZNode
• Every ZNode has data (given as byte[])
and can optionally have children
• ZNode paths:
• Canonical, absolute, slash-separated
• No relative references
• Names can have Unicode characters
• ZNode maintain stat structure](https://image.slidesharecdn.com/apachezookeeperseminartrinhvietdung032016-160331013715/85/Apache-zookeeper-seminar_trinh_viet_dung_03_2016-9-320.jpg)













![References
[1]. Apache ZooKeeper, http://zookeeper.apache.org
[2]. Introduction to Apache ZooKeeper,
http://www.slideshare.net/sauravhaloi
[3]. Saurav Haloi, Apache Zookeeper Essentials, 2015](https://image.slidesharecdn.com/apachezookeeperseminartrinhvietdung032016-160331013715/85/Apache-zookeeper-seminar_trinh_viet_dung_03_2016-24-320.jpg)
































Ad
More Related Content
What's hot (20)
Viewers also liked (16)














Ad
Similar to Apache zookeeper seminar_trinh_viet_dung_03_2016 (20)






![Paul Dix [InfluxData] | InfluxDays Opening Keynote | InfluxDays Virtual Exper...](https://cdn.slidesharecdn.com/ss_thumbnails/2020-11-10influxdays-introducinginfluxdbiox-201110182839-thumbnail.jpg?width=560&fit=bounds)













Ad
Recently uploaded (20)




















Apache zookeeper seminar_trinh_viet_dung_03_2016
- 1. APACHE ZOOKEEPER Viet-Dung TRINH (Bill), 03/2016 Saltlux – Vietnam Development Center
- 2. Agenda • Overview • The ZooKeeper Service • The ZooKeeper Data Model • Recipes
- 3. Overview – What is ZooKeeper? • An open source, high-performance coordination service for distributed application. • Exposes common services in simple interface: • Naming • Configuration management • Locks & synchronization • Groups services • Build your own on it for specific needs
- 4. Overview – Who uses ZooKeeper? • Companies: • Yahoo! • Zynga • Rackspace • Linkedlin • Netflix, and many more… • Projects: • Apache Map/Reduce (Yarn) • Apache HBase • Apache Kafka • Apache Storm • Neo4j, and many more…
- 5. Overview – ZooKeeper Use Cases • Configuration Management • Cluster member nodes bootstrapping configuration from a centralized source in unattended way • Distributed Cluster Management • Node join / leave • Node statuses in real time • Naming service – e.g. DNS • Distributed synchronization – locks, barriers, queues • Leader election in a distributed system
- 6. The ZooKeeper Service (ZKS) • ZooKeeper Service is replicated over a set of machines • All machines store a copy of the data (in-memory) • A leader is elected on service startup • Clients only connect to a single ZooKeeper server and maintain a TCP connection
- 7. The ZKS - Sessions • Before executing any request, client must establish a session with service • All operations client summits to service are associated to a session • Client initially connects to any server in ensemble, and only to single server. • Session offer order guarantees – requests in session are executed in FIFO order
- 8. The ZKS – Session States and Lifetime • Main possible states: CONNECTING, CONNECTED, CLOSED, NOT_CONNECTED
- 9. The ZooKeeper Data Model (ZDM) • Hierarchal name space • Each node is called as a ZNode • Every ZNode has data (given as byte[]) and can optionally have children • ZNode paths: • Canonical, absolute, slash-separated • No relative references • Names can have Unicode characters • ZNode maintain stat structure
- 10. ZDM - Versions • Eash Znode has version number, is incremented every time its data changes • setData and delete take version as input, operation succeeds only if client’s version is equal to server’s one
- 11. ZDM – ZNodes – Stat Structure • The Stat structure for each znode in ZooKeeper is made up of the following fields: • czxid • mzxid • pzxid • ctime • mtime • dataVersion • cversion • aclVersion • ephemeralOwner • dataLength • numChildren
- 12. ZDM – Types of ZNode • Persistent ZNode • Have lifetime in ZooKeeper’s namespace until they’re explicitly deleted (can be deleted by delete API call) • Ephemeral ZNode • Is deleted by ZooKeeper service when the creating client’s session ends • Can also be explicitly deleted • Are not allowed to have children • Sequential Znode • Is assigned a sequence number by ZooKeeper as a part of name during creation • Sequence number is integer (4bytes) with format of 10 digits with 0 padding. E.g. /path/to/znode-0000000001
- 13. ZDM – Znode Operations
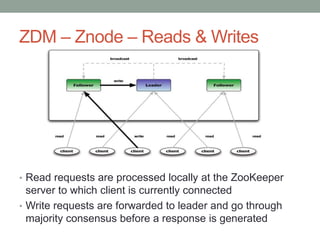
- 14. ZDM – Znode – Reads & Writes • Read requests are processed locally at the ZooKeeper server to which client is currently connected • Write requests are forwarded to leader and go through majority consensus before a response is generated
- 15. ZDM – Consistency Guarantees • Sequential Consistency • Atomicity • Single System Image • Reliability • Timeliness (Eventual Consistency)
- 16. ZDM - Watches • A watch event is one-time trigger, sent to client that set watch, which occurs when data for which watch was set changes. • Watches allow clients to get notifications when a znode changes in any way (NodeChildrenChanged, NodeCreated, NodeDataChanged,NodeDeleted) • All of read operations – getData(), getChildren(), exists() – have option of setting watch • ZooKeeper Guarantees about Watches: • Watches are ordered, order of watch events corresponds to the order of the updates • A client will see a watch event for znode it is watching before seeing the new data that corresponds to that znode
- 17. ZDM – Watches (cont)
- 18. ZDM – Access Control List • ZooKeeper uses ACLs to control access to its znodes • ACLs are made up of pairs of (scheme:id, permission) • Build-in ACL schemes • world: has single id, anyone • auth: doesn’t use any id, represents any authenticated user • digest: use a username:password • host: use the client host name as ACL id identity • ip: use the client host IP as ACL id identity • ACL Permissions: • CREATE • READ • WRITE • DELETE • ADMIN • E.g. (ip:192.168.0.0/16, READ)
- 19. Recipe #1: Queue • A distributed queue is very common data structure used in distributed systems. • Producer: generate / create new items and put them into queue • Consumer: remove items from queue and process them • Addition and removal of items follow ordering of FIFO
- 20. Recipe #1: Queue (cont) • A ZNode will be designated to hold a queue instance, queue-znode • All queue items are stored as znodes under queue-znode • Producers add an item to queue by creating znode under queue-znode • Consumers retrieve items by getting and then deleting a child from queue-znode QUEUE-ZNODE : “queue instance” |-- QUEUE-0000000001 : “item1” |-- QUEUE-0000000002 : “item2” |-- QUEUE-0000000003 : “item3”
- 21. Recipe #1: Queue (cont) • Let /_QUEUE_ represent top-level znode, is called queue- znode • Producer put something into queue by creating a SEQUENCE_EPHEMERAL znode with name “queue-N”, N is monotonically increasing number create (“queue-”, SEQUENCE_EPHEMARAL) • Consumer process getChildren() call on queue-znode with watch event set to true M = getChildren(/_QUEUE_, true) • Client picks up items from list and continues processing until reaching the end of the list, and then check again • The algorithm continues until get_children() returns empty list
- 22. Recipe #2: Group Membership • A persistent Znode /membership represent the root of the group in ZooKeeper tree • Any client that joins the cluster creates ephemeral znode under /membership to locate memberships in tree and set a watch on /membership • When another node joins or leaves the cluster, this node gets a notification and becomes aware of the change in group membership
- 23. Recipe #2: Group Membership (cont) • Let /_MEMBERSHIP_ represent root of group membership • Client joining the group create ephemeral nodes under root • All members of group will register for watch events on /_MEMBERSHIP, thereby being aware of other members in group L = getChildren(“/_MEMBERSHIP”, true) • When new client joins group, all other members are notified • Similarly, a client leaves due to failure or otherwise, ZooKeeper automatically delete node, trigger event • Live members know which node joined or left by looking at the list of children L
- 24. References [1]. Apache ZooKeeper, http://zookeeper.apache.org [2]. Introduction to Apache ZooKeeper, http://www.slideshare.net/sauravhaloi [3]. Saurav Haloi, Apache Zookeeper Essentials, 2015
- 25. Questions?
- 26. Thank You!
Editor's Notes
- #6: Centralized and highly reliable (simple) data registry Unattended = without the owner present
- #7: - Each server maintains an in-core database, which represents the entire state of the ZooKeeper namespace. To ensure that updates are durable, and thus recoverable in the event of a server crash, updates are logged to a local disk. Also, the writes are serialized to the disk before they are applied to the in-memory database
- #8: - (3) The client initially connects to any server in the ensemble, and only to a single server. It uses a TCP connection to communicate with the server, but the session may be moved to a different server if the client has not heard from its current server for some time. Moving a session to a different server is handled transparently by the ZooKeeper client library - (4)
- #9: - A session starts at the NOT_CONNECTED state and transitions to CONNECTING (arrow 1) with the initialization of the ZooKeeper client. - Normally, the connection to a ZooKeeper server succeeds and the session transitions to CONNECTED (arrow 2). - When the client loses its connection to the ZooKeeper server or doesn’t hear from the server, it transitions back to CONNECTING (arrow 3) and tries to find another ZooKeeper server. If it is able to find another server or to reconnect to the original server, it transitions back to CONNECTED once the server confirms that the session is still valid. - Otherwise, it declares the session expired and transitions to CLOSED (arrow 4). - The application can also explicitly close the session (arrows 4 and 5)
- #11: - Each znode has a version number associated with it that is incremented every time its data changes
- #12: Zxid: Each change will have a unique zxid and if zxid1 is smaller than zxid2 then zxid1 happened before zxid2. zxid is 64-bit integer = 32bits EPOCH and 32bits COUNTER Czxid: The zxid of the change that caused this znode to be created Mzxid: The zxid of the change that last modified this znode Pzxid: This is the transaction ID for a znode change that pertains to adding or removing children Ctime: The time in milliseconds from epoch when this znode was created Mtime: The time in milliseconds from epoch when this znode was last modified dataVersion: The number of changes to the data of this znode cVersion: The number of changes to the children of this znode aclversion: The number of changes to the ACL of this znode ephemeralOwner: The session id of the owner of this znode if the znode is an ephemeral node. If it is not an ephemeral node, it will be zero dataLength: The length of the data field of this znode numChildren: The number of children of this znode
- #13: ZNode's type is set at its creation time (1) Persistent znodes are useful for storing data that needs to be highly available and accessible by all the components of a distributed application. For example, an application can store the configuration data in a persistent znode. The data as well as the znode will exist even if the creator client dies (2) An end to a client's session can happen because of disconnection due to a client crash or explicit termination of the connection The concept of ephemeral znodes can be used to build distributed applications where the components need to know the state of the other constituent components or resources. For example, a distributed group membership service can be implemented by using ephemeral znodes. The property of ephemeral nodes getting deleted when the creator client's session ends can be used as an analogue of a node that is joining or leaving a distributed cluster. Using the membership service, any node is able discover the members of the group at any particular time.
- #15: READ requests such as exists(), getData(), and getChildren() are processed locally by the ZooKeeper server where the client is connected. This makes the read operations very fast in ZooKeeper WRITE or update requests such as create(), delete(), and setData() are forwarded to the leader in the ensemble. The leader carries out the client request as a transaction. This transaction is similar to the concept of a transaction in a database management system A ZooKeeper transaction also comprises all the steps required to successfully execute the request as a single work unit, and the updates are applied atomically
- #16: - Sequential Consistency: Updates from a client will be applied in the order that they were sent - Atomicity: Updates either succeed or fail -- there are no partial results - Single System Image: A client sees the same view of the service regardless of the ZK server it connects to. - Reliability: Updates persists once applied, till overwritten by some clients. If a client gets a successful return code, the update will have been applied - Timeliness: The clients’ view of the system is guaranteed to be up-to-date within a certain time bound. (Eventual Consistency)
- #19: CREATE: you can create a child node READ: you can get data from a node and list its children. WRITE: you can set data for a node DELETE: you can delete a child node ADMIN: you can set permissions world has a single id, anyone, that represents anyone. auth doesn't use any id, represents any authenticated user. digest uses a username:password string to generate MD5 hash which is then used as an ACL ID identity. Authentication is done by sending the username:password in clear text. When used in the ACL the expression will be the username:base64 encoded SHA1 password digest. host uses the client host name as an ACL ID identity. The ACL expression is a hostname suffix. For example, the ACL expression host:corp.com matches the ids host:host1.corp.com and host:host2.corp.com, but not host:host1.store.com. ip uses the client host IP as an ACL ID identity. The ACL expression is of the form addr/bits where the most significant bits of addr are matched against the most significant bits of the client host IP
- #21: The FIFO order of the items is maintained using sequential property of znode provided by ZooKeeper. When a producer process creates a znode for a queue item, it sets the sequential flag. This lets ZooKeeper append the znode name with a monotonically increasing sequence number as the suffix. ZooKeeper guarantees that the sequence numbers are applied in order and are not reused. The consumer process processes the items in the correct order by looking at the sequence number of the znode.