







































































































![Questions? tiny.cloudera.com/app-arch-questions
Nested Writing Example in Spark
{
"id": "0001",
"type": "donut",
"name": "Cake",
"ppu": 0.55,
"batters":
{
"batter":
[
{ "id": "1001", "type": "Regular" },
{ "id": "1002", "type": "Chocolate" },
{ "id": "1003", "type": "Blueberry" },
{ "id": "1004", "type": "Devil's Food" }
]
},
"topping":
[
{ "id": "5001", "type": "None" },
{ "id": "5002", "type": "Glazed" },
{ "id": "5005", "type": "Sugar" },
{ "id": "5007", "type": "Powdered Sugar" },
{ "id": "5006", "type": "Chocolate with Sprinkles" }
]](https://image.slidesharecdn.com/haatutorialstratasingapore2016v2-161205094441/85/Architecting-next-generation-big-data-platform-108-320.jpg)







![Questions? tiny.cloudera.com/app-arch-questions
HBase: Row Key Example
def generateRowKey(customerTrans: CustomerTran, numOfSalts:Int): Array[Byte] = {
val salt = StringUtils.leftPad(
Math.abs(customerTrans.customerId.hashCode % numOfSalts).toString, 4, "0")
Bytes.toBytes(salt + ":" +
customerTrans.customerId + ":" +
StringUtils.leftPad(customerTrans.eventTimeStamp.toString, 11, "0") + ":trans:" +
customerTrans.transId)
}](https://image.slidesharecdn.com/haatutorialstratasingapore2016v2-161205094441/85/Architecting-next-generation-big-data-platform-116-320.jpg)




















![Questions? tiny.cloudera.com/app-arch-questions
Don’t believe me?
import org.mortbay.jetty.Server
import org.mortbay.jetty.servlet.{Context, ServletHolder}
…
val server = new Server(port)
val sh = new ServletHolder(classOf[ServletContainer])
sh.setInitParameter("com.sun.jersey.config.property.resourceConfigClass",
"com.sun.jersey.api.core.PackagesResourceConfig")
sh.setInitParameter("com.sun.jersey.config.property.packages",
"com.hadooparchitecturebook.taxi360.server.hbase")
sh.setInitParameter("com.sun.jersey.api.json.POJOMappingFeature", "true”)
val context = new Context(server, "/", Context.SESSIONS)
context.addServlet(sh, "/*”)
server.start()
server.join()](https://image.slidesharecdn.com/haatutorialstratasingapore2016v2-161205094441/85/Architecting-next-generation-big-data-platform-138-320.jpg)
![Questions? tiny.cloudera.com/app-arch-questions
Then, write a ServiceLayer
@GET
@Path("vender/{venderId}/timeline")
@Produces(Array(MediaType.APPLICATION_JSON))
def getTripTimeLine (@PathParam("venderId") venderId:String,
@QueryParam("startTime") startTime:String = Long.MinValue.toString,
@QueryParam("endTime") endTime:String = Long.MaxValue.toString):
Array[NyTaxiYellowTrip] = {](https://image.slidesharecdn.com/haatutorialstratasingapore2016v2-161205094441/85/Architecting-next-generation-big-data-platform-139-320.jpg)






















































Ad
More Related Content
What's hot (20)
Viewers also liked (19)

















Ad
Similar to Architecting next generation big data platform (20)




















Ad
Recently uploaded (20)




















Architecting next generation big data platform
- 1. Hadoop Application Architectures: Architecting a Next Generation Data Platform Strata + Hadoop World, Singapore 2016 tiny.cloudera.com/app-arch-singapore tiny.cloudera.com/app-arch-questions Mark Grover | @mark_grover Ted Malaska | @ted_malaska Jonathan Seidman | @jseidman
- 2. Questions? tiny.cloudera.com/app-arch-questions Logistics ▪ Break at 10:30 – 11:00 AM ▪ Questions at the end of each section ▪ Slides at tiny.cloudera.com/app-arch-singapore ▪ Code at https://github.com/hadooparchitecturebook/Taxi360
- 3. Questions? tiny.cloudera.com/app-arch-questions About the book ▪ @hadooparchbook ▪ hadooparchitecturebook.com ▪ github.com/hadooparchitecturebook ▪ slideshare.com/hadooparchbook
- 4. Questions? tiny.cloudera.com/app-arch-questions About the presenters ▪ Technical Group Architect at Blizzard Entertainment ▪ Previously Principal Solutions Architect at Cloudera, lead architect at FINRA ▪ Contributor to Apache Hadoop, HBase, Flume, Avro, Pig, Spark, YARN, Sqoop, Kudu, Kafka Ted Malaska
- 5. Questions? tiny.cloudera.com/app-arch-questions About the presenters ▪ Partner Software Engineer at Cloudera ▪ Contributor to Apache Sqoop. ▪ Previously Technical Lead on the big data team at Orbitz, co-founder of the Chicago Hadoop User Group and Chicago Big Data Jonathan Seidman
- 6. Questions? tiny.cloudera.com/app-arch-questions About the presenters ▪ Software Engineer on Spark at Cloudera ▪ Committer on Apache Bigtop, PMC member on Apache Sentry(incubating) ▪ Contributor to Apache Spark, Hadoop, Hive, Sqoop, Pig, Flume Mark Grover
- 7. Case Study Overview Internet of Things and Entity 360
- 10. Questions? tiny.cloudera.com/app-arch-questions Entity (Taxi) 360 View Geo-location/ Traffic Data Customer Data Maintenance Data Other Data Sources Streaming Vehicle Data
- 11. Questions? tiny.cloudera.com/app-arch-questions What Makes Hadoop a Fit? Data Sources Extract Transform Load The early days…
- 12. Questions? tiny.cloudera.com/app-arch-questions What Makes Hadoop a Fit? SERVERS MARTS EDWS DOCUMENTS STORAGE SEARCH ARCHIVE ERP, CRM, RDBMS, MACHINES FILES, IMAGES, VIDEOS, LOGS, CLICKSTREAMS EXTERNAL DATA SOURCES Today…
- 13. Questions? tiny.cloudera.com/app-arch-questions Enabling a Range of New Use Cases… Fraud Detection Market Transactions Internet of Things Network Security
- 14. Questions? tiny.cloudera.com/app-arch-questions Hadoop Challenges Kafka StreamsKafka Connect Kafka
- 15. Questions? tiny.cloudera.com/app-arch-questions Challenges - Architectural Considerations ▪ Reliable and scalable ingress of multiple data types and sources: - High volume event data? Batch data? ▪ Reliable and scalable storage to support multiple workloads and access patterns - Historical data? Real-time search? Analytics ▪ Processing engines (for background processing): - Stream processing? Batch processing? ▪ Data Modeling - Modeling data for real-time random access? Analytic access? Batch access?
- 17. Questions? tiny.cloudera.com/app-arch-questions Requirements ▪ Allow users (technical and non-technical) to analyze and visualize data…
- 18. Questions? tiny.cloudera.com/app-arch-questions Requirements ▪ Provide analysts with query capabilities via a standard interface…
- 19. Questions? tiny.cloudera.com/app-arch-questions Requirements ▪ Provide developers the ability to perform batch processing on historical data…
- 20. Questions? tiny.cloudera.com/app-arch-questions Requirements ▪ To support all this, we need: - Reliable ingestion of streaming and batch data. - Ability to perform transformations on streaming data in flight. - Ability to perform sophisticated processing of historical data.
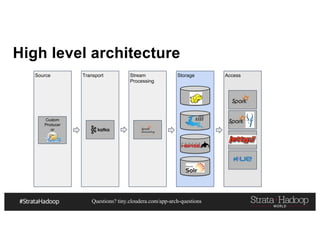
- 22. Questions? tiny.cloudera.com/app-arch-questions High level architecture Source Transport Stream Processing Storage Access Data Producer Pub-Sub Processing & Ingestion Engine Nested Tables Indexed Cube Relational Tables Entity Time Series Lookup Batch Processing SQL NRT REST NRT Dashboard
- 24. Questions? tiny.cloudera.com/app-arch-questions But wait! What about batch data?
- 26. Questions? tiny.cloudera.com/app-arch-questions High level architecture Source Transport Stream Processing Storage Access Data Producer Pub-Sub Processing & Ingestion Engine Nested Tables Indexed Cube Relational Tables Entity Time Series Lookup Batch Processing SQL NRT REST NRT Dashboard
- 27. Questions? tiny.cloudera.com/app-arch-questions Buffering Data ▪ What do we mean by “buffering” and why do we need it? event,event,event,event,event,event… This is bad!
- 28. Questions? tiny.cloudera.com/app-arch-questions Buffering Data – Message Brokers Publisher Publisher Publisher Message Queue Subscriber Subscriber Subscriber
- 29. Questions? tiny.cloudera.com/app-arch-questions High level architecture Source Transport Stream Processing Storage Access Custom Producer or Processing & Ingestion Engine Nested Tables Indexed Cube Relational Tables Entity Time Series Lookup Batch Processing SQL NRT Rest NRT Dashboard
- 30. Questions? tiny.cloudera.com/app-arch-questions Buffering Data – Flume vs. Kafka ▪ Flume – well integrated with Hadoop. - Great choice when ingesting data into HDFS. - Can support simple transformations. - Less coding. ▪ But… - Interface between Kafka and the streaming layer is already well defined. - Transformations are done in the stream processing layer. - We need a more general purpose system at this layer.
- 32. Questions? tiny.cloudera.com/app-arch-questions What is Kafka? ▪ It’s like a message queue, right? - Actually, it’s a “distributed commit log”. 0 1 2 3 4 5 6 7 8 Data Source Data Consumer A Data Consumer B
- 33. Questions? tiny.cloudera.com/app-arch-questions Topics and Partitions ▪ Messages are organized into topics, and each topic is split into partitions. - Each partition is an immutable, time-sequenced log of messages on disk. - Note that time ordering is guaranteed within, but not across, partitions. 0 1 2 3 4 5 6 7 8 0 1 2 3 4 5 6 7 8 0 1 2 3 4 5 6 7 8 Partition 0 Partition 1 Partition 2 Data Source Topic
- 34. Questions? tiny.cloudera.com/app-arch-questions Kafka Background (Physical) ProducersProducersProducers BrockerBrockerBroker ConsumersConsumersConsumers ZooKeeperZooKeeperZooKeeper
- 35. Questions? tiny.cloudera.com/app-arch-questions Consumers Kafka In Our Architecture Taxi Trip Data Producer Kafka taxi-trip-input Topic Stream Processing (Analytic) Stream Processing (Lookup) Stream Processing (Search) Stream Processing (Long Term)
- 36. Questions? tiny.cloudera.com/app-arch-questions Input Events CMT,2009-01-05 08:31:55,2009-01-05 8:37:50,1,0.90000000000000002,-73.977936999999997, 40.745919000000001,,,- 73.983609000000001,40.755051000000002,Credit,5.2999999999999998,0,,0.79000000000000004,0,6.0 899999999999999 vendor_name,Trip_Pickup_DateTime,Trip_Dropoff_DateTime,Passenger_Count,Trip_Distance, Start_Lon,Start_Lat,Rate_Code,store_and_forward,End_Lon,End_Lat,Payment_Type,Fare_Amt, surcharge,mta_tax,Tip_Amt,Tolls_Amt,Total_Amt
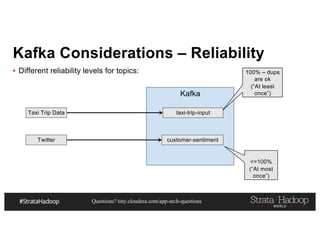
- 37. Questions? tiny.cloudera.com/app-arch-questions Kafka Considerations – Reliability ▪ Different reliability levels for topics: Taxi Trip Data Kafka taxi-trip-input Twitter customer-sentiment 100% – dups are ok (“At least once”) <=100% (“At most once”)
- 38. Questions? tiny.cloudera.com/app-arch-questions Kafka Considerations – Reliability ▪ But remember there are tradeoffs…
- 39. Questions? tiny.cloudera.com/app-arch-questions Kafka Reliability – Replication Producer Broker Partition1 Partition2 Partition3 Leader
- 40. Questions? tiny.cloudera.com/app-arch-questions Kafka Reliability – Replication Producer Broker Partition1 Partition2 Partition3
- 41. Questions? tiny.cloudera.com/app-arch-questions Kafka Reliability – Replication Producer Broker Partition1 Partition2 Partition3 Broker Partition1 Partition2 Partition3 Leader
- 42. Questions? tiny.cloudera.com/app-arch-questions Kafka Reliability– Replication Producer Broker Partition1 Partition2 Partition3 Broker Partition1 Partition2 Partition3 Leader Leader
- 43. Questions? tiny.cloudera.com/app-arch-questions Kafka Reliability – Replication Producer Broker Partition1 Partition2 Partition3 Broker Partition1 Partition2 Partition3 Broker Partition1 Partition2 Partition3 Leader
- 44. Questions? tiny.cloudera.com/app-arch-questions Kafka Reliability – Replication ▪ So how does this relate to our application? kafka-topics --zookeeper ZKHOST:ZKPORT –partition 2 --replication-factor 3 --create --topic taxi-trip-input kafka-topics --zookeeper ZKHOST:ZKPORT –partition 2 --replication-factor 1 --create –topic customer-sentiment
- 45. Questions? tiny.cloudera.com/app-arch-questions Kafka Reliability – Producers Taxi Trip Data Kafka taxi_trip_input Partition 1 Partition 2 Partition 3 Topic B Partition 1 Partition 2 Partition 3 Message failure? Producer Resend message acks=all
- 46. Questions? tiny.cloudera.com/app-arch-questions Kafka Reliability – Producers ▪ What about duplicates? Taxi Trip Data Kafka taxi_trip_input Partition 1 Partition 2 Partition 3 Topic B Partition 1 Partition 2 Partition 3 Producer ID Message 1000 2009-01-04 03:02:00,1,2.629,... 1001 2009-01-04 03:38:00,3,4.549… 1001 2009-01-04 03:38:00,3,4.549…
- 47. Questions? tiny.cloudera.com/app-arch-questions Kafka Scaling – Partitions Producer Kafka taxi-trip-input Partition 1 Partition 2 Partition 3 Consumer Group Consumer Consumer Consumer
- 48. Questions? tiny.cloudera.com/app-arch-questions Kafka Scaling – Partitions Producer Kafka taxi-trip-input Partition 1 Partition 2 Partition 3 Consumer Group Consumer Consumer Consumer Partition 4 Partition 5 Consumer Consumer Higher throughput Higher throughput More resources (memory) More resources (file handles) Producer
- 49. Questions? tiny.cloudera.com/app-arch-questions Kafka Scaling – Partitions
- 50. Questions? tiny.cloudera.com/app-arch-questions Custom Partitioning 0 1 2 0 1 2 3 4 5 6 7 8 0 1 2 3 4 5 Producer 0 1 2 0 1 2 3 4 5 6 7 8 0 1 2 3 4 5 Producer 3 4 5 6 7 6 7 Partitioner
- 51. Questions? tiny.cloudera.com/app-arch-questions Kafka Scaling – Producers Producer Kafka taxi-trip-input Partition 1 Partition 2 Partition 3 Consumer Group Consumer Consumer Consumer Partition 4 Partition 5 Consumer Consumer Producer
- 52. Questions? tiny.cloudera.com/app-arch-questions Guarding Against Message Loss ▪ Producer – What happens if the producer loses connection to Kafka and the buffer overflows? - Consider a producer side buffer (e.g. Flume). ▪ Source – What happens if events are lost before getting sent to producer? - Once again use some kind of buffer to provide sufficient retention of data.
- 54. Questions? tiny.cloudera.com/app-arch-questions High level architecture Source Transport Stream Processing Storage Access Custom Producer or Processing & Ingestion Engine Nested Tables Indexed Cube Relational Tables Entity Time Series Lookup Batch Processing SQL NRT REST NRT Dashboard
- 55. Questions? tiny.cloudera.com/app-arch-questions Streaming agenda ▪ What do we mean by streaming? ▪ Streaming use-cases ▪ Streaming semantics ▪ Which streaming engine to choose? ▪ Streaming in our use-case
- 56. What do we mean by streaming?
- 57. Questions? tiny.cloudera.com/app-arch-questions What do we mean by streaming? Constant low milliseconds & under Low milliseconds to seconds, delay in case of failures 10s of seconds or more, re-run in case of failures Real-time Near real-time Batch
- 58. Questions? tiny.cloudera.com/app-arch-questions What do we mean by streaming? Constant low milliseconds & under Low milliseconds to seconds, delay in case of failures 10s of seconds or more, re-run in case of failures Real-time Near real-time Batch
- 59. Questions? tiny.cloudera.com/app-arch-questions But, there’s no free lunch Constant low milliseconds & under Low milliseconds to seconds, delay in case of failures 10s of seconds or more, re-run in case of failures Real-time Near real-time Batch “Difficult” architectures, lower latency “Easier” architectures, higher latency
- 61. Questions? tiny.cloudera.com/app-arch-questions Streaming Use-cases ▪ Ingestion (most relevant in our use-case) ▪ Simple transformations - Decision (e.g. anomaly detection) - Enrichment (e.g. add a state based on zipcode) ▪ Advanced usage - Machine Learning - Windowing
- 62. Questions? tiny.cloudera.com/app-arch-questions #1 - Simple ingestion Buffer Event e Stream Processing Long term storage Event e
- 63. Questions? tiny.cloudera.com/app-arch-questions #2 - Enrichment Buffer Event e Stream Processing Storage Event e’ e’ = enriched event e Context store
- 64. Questions? tiny.cloudera.com/app-arch-questions #2 - Decision Buffer Event e Stream Processing Storage Event e’ e’ = e + decision Rules
- 65. Questions? tiny.cloudera.com/app-arch-questions #3 – Advanced usage Buffer Event e Stream Processing Storage Event e’ e’ = aggregation or windowed aggregation Model
- 66. Questions? tiny.cloudera.com/app-arch-questions #1 – Simple Ingestion 1. Zero transformation - No transformation, plain ingest - Keep the original format – SequenceFile, Text, etc. - Allows to store data that may have errors in the schema 2. Format transformation - Simply change the format of the field - To a structured format, say, Avro, for example - Can do schema validation 3. Atomic transformation - Mask a credit card number
- 67. Questions? tiny.cloudera.com/app-arch-questions #2 - Enrichment Buffer Event e Stream Processing Storage Event e’ e’ = enriched event e Context store Need to store the context somewhere
- 68. Questions? tiny.cloudera.com/app-arch-questions Where to store the context? 1. Locally Broadcast Cached Dim Data - Local to Process (On Heap, Off Heap) - Local to Node (Off Process) 2. Partitioned Cache - Shuffle to move new data to partitioned cache 3. External Fetch Data (e.g. HBase, Memcached)
- 69. Questions? tiny.cloudera.com/app-arch-questions #1a - Locally broadcast cached data Could be On heap or Off heap
- 70. Questions? tiny.cloudera.com/app-arch-questions #1b - Off process cached data Data is cached on the node, outside of process. Potentially in an external system like Rocks DB
- 71. Questions? tiny.cloudera.com/app-arch-questions #2 - Partitioned cache data Data is partitioned based on field(s) and then cached
- 72. Questions? tiny.cloudera.com/app-arch-questions #3 - External fetch Data fetched from external system
- 75. Questions? tiny.cloudera.com/app-arch-questions Delivery Types ▪ At most once - Not good for many cases - Only where performance/SLA is more important than accuracy ▪ Exactly once - Expensive to achieve but desirable ▪ At least once - Easiest to achieve
- 76. Questions? tiny.cloudera.com/app-arch-questions Semantics of our architecture Source System 1 Destination systemSource System 2 Source System 3 Ingest Extract Streaming engine Push Message broker
- 77. Questions? tiny.cloudera.com/app-arch-questions Classification of storage systems ▪ File based - S3 - HDFS ▪ NoSQL - HBase - Cassandra ▪ Document based - Search ▪ NoSQL-SQL - Kudu
- 78. Questions? tiny.cloudera.com/app-arch-questions Classification of storage systems ▪ File based - S3 - HDFS ▪ NoSQL - HBase - Cassandra ▪ Document based - Search ▪ NoSQL-SQL - Kudu De-duplication at file level Semantics at key/record level
- 79. Which streaming engine to choose?
- 80. Questions? tiny.cloudera.com/app-arch-questions High level architecture Source Transport Stream Processing Storage Access Custom Producer or Processing & Ingestion Engine Nested Tables Indexed Cube Relational Tables Entity Time Series Lookup Batch Processing SQL NRT REST NRT Dashboard Apache Beam Kafka Streams
- 81. Questions? tiny.cloudera.com/app-arch-questions Spark Streaming ▪ Micro batch based architecture ▪ Allows stateful transformations ▪ Feature rich - Windowing - Sessionization - ML - SQL (Structured Streaming)
- 82. Questions? tiny.cloudera.com/app-arch-questions Spark Streaming DStream DStream DStream Single Pass Source Receiver RDD Source Receiver RDD RDD Filter Count Print Source Receiver RDD RDD RDD Single Pass Filter Count Print First Batc h Second Batch
- 83. Questions? tiny.cloudera.com/app-arch-questions DStream DStream DStream Single Pass Source Receiver RDD Source Receiver RDD RDD Filter Count Print Source Receiver RDD partitions RDD Parition RDD Single Pass Filter Count Pre-first Batch First Batc h Second Batch Stateful RDD 1 Print Stateful RDD 2 Stateful RDD 1 Spark Streaming
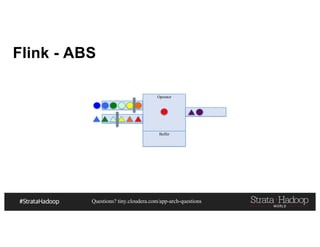
- 84. Questions? tiny.cloudera.com/app-arch-questions Flink ▪ True “streaming” system, but not as feature rich as Spark ▪ Much better event time handling ▪ Good built-in backpressure support ▪ Allows stateful transformations ▪ Lower Latency - No Micro Batching - Asynchronous Barrier Snapshotting (ABS)
- 85. Questions? tiny.cloudera.com/app-arch-questions Flink - ABS Operator Buffer
- 86. Questions? tiny.cloudera.com/app-arch-questions Operator Buffer Operator Buffer Flink - ABS Barrier 1A Hit Barrier 1B Still Behind
- 87. Questions? tiny.cloudera.com/app-arch-questions Operator Buffer Flink - ABS Both Barriers Hit Operator Buffer Barrier 1A Hit Barrier 1B Still Behind
- 88. Questions? tiny.cloudera.com/app-arch-questions Operator Buffer Flink - ABS Both Barriers Hit Operator Buffer Barrier is combined and can move on Buffer can be flushed out
- 89. Questions? tiny.cloudera.com/app-arch-questions Storm ▪ Old school ▪ Didn’t manage state – had to use Trident ▪ No good support for batch processing
- 90. Questions? tiny.cloudera.com/app-arch-questions Samza ▪ Good integration with Kafka ▪ Doesn’t support batch ▪ Forked by Kafka Streams
- 91. Questions? tiny.cloudera.com/app-arch-questions Flume ▪ Well integrated with the Hadoop ecosystem ▪ Allowed interceptors (for simple transformations) ▪ Supports buffering - Memory - File - Kafka ▪ But no real fault-tolerance ▪ No state management
- 92. Questions? tiny.cloudera.com/app-arch-questions Others ▪ Apache Apex ▪ Kafka Streams ▪ Heron
- 93. Questions? tiny.cloudera.com/app-arch-questions Apache Beam ▪ Abstraction on top of Streaming Engines ▪ Best support for Google Dataflow
- 94. Streaming in our use- case
- 95. Questions? tiny.cloudera.com/app-arch-questions Spark Streaming ▪ We chose Spark Streaming because: - Same execution engine for batch and streaming - Similar code for batch and streaming - Support for security, kafka integration - Thriving community - We don’t have low millisecond requirements
- 96. Questions? tiny.cloudera.com/app-arch-questions High level architecture Source Transport Stream Processing Storage Access Custom Producer or Nested Tables Indexed Cube Relational Tables Entity Time Series Lookup Batch Processing SQL NRT REST NRT Dashboard
- 98. Questions? tiny.cloudera.com/app-arch-questions High level architecture Source Transport Stream Processing Storage Access Custom Producer or Nested Tables Indexed Cube Relational Tables Entity Time Series Lookup Batch Processing SQL NRT REST NRT Dashboard
- 99. Data Modeling
- 100. Questions? tiny.cloudera.com/app-arch-questions Structured Landing Zones Hive Relational Model Kudu/HDFS Hive Nested Model HDFS Aggregations Kudu HBase Entity Time Series Solr Traditional SQL Optimized for nested Structures like JSON Optimized Storing and mutating aggregates Optimized Entity 360 and time base access Optimized faceted charts and reverse index look ups
- 101. Questions? tiny.cloudera.com/app-arch-questions Relational ▪ Everyone knows it ▪ Simple ▪ Very painful to do large Join ▪ May lead to customers making bad queries ▪ Easier to mutate
- 102. Questions? tiny.cloudera.com/app-arch-questions Kudu Data Models ▪ Entity Summary Tables - Quick update and access of aggregate of Entity Stats ▪ Event Tables - Number of Partitioning strategies - Partition by Entity - Partition by Hash on time
- 103. Questions? tiny.cloudera.com/app-arch-questions Kudu: Table Creation Example CREATE EXTERNAL TABLE ny_taxi_trip ( vender_id STRING, tpep_pickup_datetime TIMESTAMP, tpep_dropoff_datetime TIMESTAMP, passenger_count INT, trip_distance DOUBLE, pickup_longitude DOUBLE, pickup_latitude DOUBLE, rate_code_id STRING, store_and_fwd_flag STRING, dropoff_longitude DOUBLE, dropoff_latitude DOUBLE, payment_type STRING, fare_amount DOUBLE, extra DOUBLE, mta_tax DOUBLE, improvement_surcharge DOUBLE, tip_amount DOUBLE, tolls_amount DOUBLE, total_amount DOUBLE ) STORED AS PARQUET LOCATION 'usr/root/hive/ny_taxi_trip';
- 104. Questions? tiny.cloudera.com/app-arch-questions Kudu: Data Population SparkStreamingTaxiTripToKudu.scala
- 105. Questions? tiny.cloudera.com/app-arch-questions Kudu: REST API KuduServiceLayer.scala
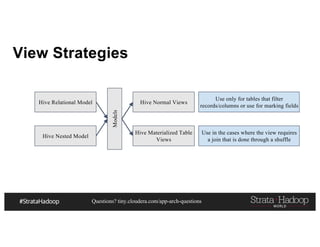
- 106. Questions? tiny.cloudera.com/app-arch-questions View Strategies Hive Relational Model Hive Nested Model Models Hive Normal Views Hive Materialized Table Views Use in the cases where the view requires a join that is done through a shuffle Use only for tables that filter records/columns or use for marking fields
- 107. Questions? tiny.cloudera.com/app-arch-questions Nested ▪ Less Space than Denormalization ▪ Still have tables but the cost of joins is all but gone ▪ Also great for cartesian joins - N x M vs N + M ▪ Not really supported yet with Kudu or HBase with SQL
- 108. Questions? tiny.cloudera.com/app-arch-questions Nested Writing Example in Spark { "id": "0001", "type": "donut", "name": "Cake", "ppu": 0.55, "batters": { "batter": [ { "id": "1001", "type": "Regular" }, { "id": "1002", "type": "Chocolate" }, { "id": "1003", "type": "Blueberry" }, { "id": "1004", "type": "Devil's Food" } ] }, "topping": [ { "id": "5001", "type": "None" }, { "id": "5002", "type": "Glazed" }, { "id": "5005", "type": "Sugar" }, { "id": "5007", "type": "Powdered Sugar" }, { "id": "5006", "type": "Chocolate with Sprinkles" } ]
- 109. Questions? tiny.cloudera.com/app-arch-questions Nested Writing Example in Spark val jsonDF = hiveContext.read.json(jsonRDD) jsonDF.write.parquet("./parquet") hiveContext.createExternalTable("jsonNestedTable", "./parquet")
- 110. Questions? tiny.cloudera.com/app-arch-questions Nested: Taxi Example KuduToNestedHDFS.scala
- 111. Questions? tiny.cloudera.com/app-arch-questions Entity Centric Time Series ▪ Partition by Entity ID ▪ Order by Time ▪ Allows for free windowing ▪ Allows for fetching of single time window of single entity at web scale
- 112. Questions? tiny.cloudera.com/app-arch-questions HBase Entity Time Series Cust-A, 10 Cust-A, 20 Cust-A, 40 Cust-C, 10 Cust-C, 20 Cust-C, 30 Cust-C, 40 Cust-B, 10 Cust-B, 20 Cust-B, 30 Cust-B, 40 Cust-F, 20 Cust-F, 30 Cust-F, 40 Cust-D, 10 Cust-D, 20 Cust-D, 40 Cust-G, 10 Cust-G, 20 Cust-G, 30 Cust-G, 40
- 113. Questions? tiny.cloudera.com/app-arch-questions HBase Entity Time Series Cust-A, 10 Cust-A, 20 Cust-A, 40 Cust-C, 10 Cust-C, 20 Cust-C, 30 Cust-C, 40 Cust-B, 10 Cust-B, 20 Cust-B, 30 Cust-B, 40 Cust-F, 20 Cust-F, 30 Cust-F, 40 Cust-D, 10 Cust-D, 20 Cust-D, 40 Cust-G, 10 Cust-G, 20 Cust-G, 30 Cust-G, 40 Rest Call Short Scan
- 114. Questions? tiny.cloudera.com/app-arch-questions HBase Entity Time Series Cust-A, 10 Cust-A, 20 Cust-A, 40 Cust-C, 10 Cust-C, 20 Cust-C, 30 Cust-C, 40 Cust-B, 10 Cust-B, 20 Cust-B, 30 Cust-B, 40 Cust-F, 20 Cust-F, 30 Cust-F, 40 Cust-D, 10 Cust-D, 20 Cust-D, 40 Cust-G, 10 Cust-G, 20 Cust-G, 30 Cust-G, 40 Mapper Mapper Mapper
- 115. Questions? tiny.cloudera.com/app-arch-questions HBase Entity Time Series Cust-A, 10 Cust-A, 20 Cust-A, 40 Cust-C, 10 Cust-C, 20 Cust-C, 30 Cust-C, 40 Cust-B, 10 Cust-B, 20 Cust-B, 30 Cust-B, 40 Cust-F, 20 Cust-F, 30 Cust-F, 40 Cust-D, 10 Cust-D, 20 Cust-D, 40 Cust-G, 10 Cust-G, 20 Cust-G, 30 Cust-G, 40 Mapper Mapper Mapper
- 116. Questions? tiny.cloudera.com/app-arch-questions HBase: Row Key Example def generateRowKey(customerTrans: CustomerTran, numOfSalts:Int): Array[Byte] = { val salt = StringUtils.leftPad( Math.abs(customerTrans.customerId.hashCode % numOfSalts).toString, 4, "0") Bytes.toBytes(salt + ":" + customerTrans.customerId + ":" + StringUtils.leftPad(customerTrans.eventTimeStamp.toString, 11, "0") + ":trans:" + customerTrans.transId) }
- 117. Questions? tiny.cloudera.com/app-arch-questions HBase: Population Example SparkStreamingTaxiTripToHBase.scala
- 118. Questions? tiny.cloudera.com/app-arch-questions HBase: REST Example HBaseServiceLayer.scala
- 119. Questions? tiny.cloudera.com/app-arch-questions Solr: Data Model ▪ Think of it like a cube on a object type - In our case a taxi trip - Allows for rollups and aggregations from object’s point of view - Think of objects as immutable - Try to find time based events - May design more than one object type
- 120. Questions? tiny.cloudera.com/app-arch-questions Solr Details 1 Trip:101 1 2 Trip:102 1 3 Trip:103 1 ID Document Live 4 Trip:104 1 5 Trip:105 1 ID Field Value Documents 1 Cash 1,3 2 Credit 2 3 Debit 4,5
- 121. Questions? tiny.cloudera.com/app-arch-questions Single Value Aggregations ▪ Get Array Lengths ID Field Value Documents 1 Cash 1,3 2 Credit 2 3 Debit 4,5
- 122. Questions? tiny.cloudera.com/app-arch-questions Multi Value Aggregations ▪ Ordered Merge Join - Think like a zipper - Scans - No Lookups ▪ Top N from both sides - Leaving the rest to other ▪ Indexes distributed ▪ No need to read document data 1 4 5 7 8 9 10 14 16 2 3 6 11 12 13 15 17 18 1 2 3 6 7 8 10 15 18 Cash Credit Vender A 4 5 9 11 12 13 14 16 17Vender B
- 123. Questions? tiny.cloudera.com/app-arch-questions Solr: Population Example SparkStreamingTaxiTripToSolR.scala
- 124. Questions? tiny.cloudera.com/app-arch-questions Storage High level architecture Source Transport Stream Processing Access Custom Producer or
- 126. Questions? tiny.cloudera.com/app-arch-questions High level architecture Source Transport Stream Processing Storage Access Custom Producer or Nested Tables Indexed Cube Relational Tables Entity Time Series Lookup Batch Processing SQL NRT REST NRT Dashboard
- 127. Questions? tiny.cloudera.com/app-arch-questions Why have batch processing? ▪ When you need a larger context - Say, to train a model ▪ Complex periodic job that does something - Convert data to a nested structure for reduced number of shuffles ▪ In our use-case, - Kudu -> HDFS Nested is batch processing - KMeans calculation is also in bash
- 128. Questions? tiny.cloudera.com/app-arch-questions Batch processing options ▪ Spark (+ MLlib) ▪ MapReduce (+ Mahout) ▪ Flink (+ Flink ML)
- 129. Questions? tiny.cloudera.com/app-arch-questions Spark ▪ Pretty popular ▪ Much faster than MapReduce ▪ Thriving community
- 131. Questions? tiny.cloudera.com/app-arch-questions Flink ▪ Pretty popular ▪ Batch is a special case of Streaming ▪ Developing community
- 132. Questions? tiny.cloudera.com/app-arch-questions In our use-case ▪ We chose Spark - We were using Spark Streaming anyways - Similar code between Spark and Spark Streaming - Thriving community
- 134. Questions? tiny.cloudera.com/app-arch-questions High level architecture Source Transport Stream Processing Storage Access Custom Producer or Nested Tables Indexed Cube Relational Tables Entity Time Series Lookup Batch Processing SQL NRT REST NRT Dashboard
- 135. Questions? tiny.cloudera.com/app-arch-questions Types of data access ▪ REST server/APIs for querying entities and aggregates ▪ UI for displaying search facets ▪ SQL engine
- 137. Questions? tiny.cloudera.com/app-arch-questions Why have REST server? ▪ Tired of business people telling us how to access data ▪ Serves as an interface between the data engineers and business folks ▪ Lets business folks decide access patterns ▪ Engineers to optimize those patterns ▪ Brownie points from your boss ▪ And, it’s not that difficult to write!
- 138. Questions? tiny.cloudera.com/app-arch-questions Don’t believe me? import org.mortbay.jetty.Server import org.mortbay.jetty.servlet.{Context, ServletHolder} … val server = new Server(port) val sh = new ServletHolder(classOf[ServletContainer]) sh.setInitParameter("com.sun.jersey.config.property.resourceConfigClass", "com.sun.jersey.api.core.PackagesResourceConfig") sh.setInitParameter("com.sun.jersey.config.property.packages", "com.hadooparchitecturebook.taxi360.server.hbase") sh.setInitParameter("com.sun.jersey.api.json.POJOMappingFeature", "true”) val context = new Context(server, "/", Context.SESSIONS) context.addServlet(sh, "/*”) server.start() server.join()
- 139. Questions? tiny.cloudera.com/app-arch-questions Then, write a ServiceLayer @GET @Path("vender/{venderId}/timeline") @Produces(Array(MediaType.APPLICATION_JSON)) def getTripTimeLine (@PathParam("venderId") venderId:String, @QueryParam("startTime") startTime:String = Long.MinValue.toString, @QueryParam("endTime") endTime:String = Long.MaxValue.toString): Array[NyTaxiYellowTrip] = {
- 140. Questions? tiny.cloudera.com/app-arch-questions Use REST! Say no to business people! ▪ Access data like so: http://<serverURL>:8080/vender/{venderId}/timeline
- 141. UI Considerations
- 142. Questions? tiny.cloudera.com/app-arch-questions UI requirements Something that can ▪ Represent search results really well ▪ Integrates with Apache Solr on Hadoop
- 143. Questions? tiny.cloudera.com/app-arch-questions UI options ▪ Hue ▪ Banana ▪ Kibana
- 144. Questions? tiny.cloudera.com/app-arch-questions We choose Hue ▪ Because it’s included ▪ Please look at the others
- 146. Questions? tiny.cloudera.com/app-arch-questions SQL engine criteria ▪ Low latency SQL access ▪ Allows for high concurrency ▪ JDBC/ODBC integration ▪ Capable of large scale aggregation ▪ Optionally integrates with Kudu for real-time updates to SQL tables
- 147. Questions? tiny.cloudera.com/app-arch-questions Apache Hive ▪ Good JDBC integration ▪ Not really low latency, even when using Tez ▪ Doesn’t integrate with Kudu ▪ Can run at MR, Spark, or Tez
- 148. Questions? tiny.cloudera.com/app-arch-questions Presto ▪ Low latency SQL engine from Facebook ▪ Provides JDBC/ODBC access ▪ Is only in-memory, large aggregations can lead to OOM errors ▪ Doesn’t integrate with Kudu
- 149. Questions? tiny.cloudera.com/app-arch-questions Apache Impala ▪ Low latency SQL access ▪ Provides JDBC/ODBC access ▪ Excellent concurrency support ▪ Integrates with Kudu for real-time SQL
- 150. Questions? tiny.cloudera.com/app-arch-questions Apache Drill ▪ Similar in architecture to Impala ▪ Provides JDBC/ODBC access ▪ Doesn’t integrate with Kudu
- 151. Questions? tiny.cloudera.com/app-arch-questions Spark SQL ▪ Builds on top of Spark ▪ JDBC/ODBC access only via Spark Thrift Server - Doesn’t scale well with larger number of concurrent users - Doesn’t fully provide secure access.
- 152. Questions? tiny.cloudera.com/app-arch-questions We choose ▪ Spark SQL ▪ Impala
- 154. Questions? tiny.cloudera.com/app-arch-questions High level architecture Source Transport Stream Processing Storage Access Custom Producer Processing & Ingestion Engine Nested Tables Indexed Cube Relational Tables Entity Time Series Lookup Batch Processing SQL NRT Rest NRT Dashboard
- 155. Questions? tiny.cloudera.com/app-arch-questions High level architecture Source Transport Stream Processing Storage Access Custom Producer or Nested Tables Indexed Cube Relational Tables Entity Time Series Lookup Batch Processing SQL NRT REST NRT Dashboard
- 156. Questions? tiny.cloudera.com/app-arch-questions Storage High level architecture Source Transport Stream Processing Custom Producer or Access Batch Processing SQL NRT REST NRT Dashboard
- 157. Questions? tiny.cloudera.com/app-arch-questions Access High level architecture Source Transport Stream Processing Storage Custom Producer or
- 158. Questions? tiny.cloudera.com/app-arch-questions High level architecture Source Transport Stream Processing Storage Access Custom Producer or
- 159. Demo!
- 160. Questions? tiny.cloudera.com/app-arch-questions High Level of the Demo Design Producer Kafka Topic Foo Partition 1 Partition 2 Partition 3 Spark Streaming Kudu Spark Streaming HBase Spark Streaming Solr Spark Streaming HDFS Kudu HBase Solr HDFS SQL REST REST Hue SQL
- 161. Where else to find us?
- 162. Questions? tiny.cloudera.com/app-arch-questions Other Sessions ▪ Ask Us Anything session (all) – Wednesday, 2:35 PM ▪ Top Five Mistakes When Writing Spark Applications (Mark/Ted) – Wednesday, 11:15 AM ▪ Storage designs done right equal faster processing and access (Ted) – Wednesday, 4:15 PM
- 163. Thank you! @hadooparchbook tiny.cloudera.com/app-arch-singapore Jonathan Seidman | @jseidman Ted Malaska | @ted_malaska Mark Grover | @mark_grover