Associative Memory using NN (Soft Computing)
0 likes140 views

These slides are made by Late. Prof. R C Chakraborty, he was the visiting faculty at JUET, Guna. I am associated with him.




![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - AM description
1.1 Description of Associative Memory
An associative memory is a content-addressable structure that allows,
the recall of data, based on the degree of similarity between the
input pattern and the patterns stored in memory.
• Example : Associative Memory
The figure below shows a memory containing names of several people.
If the given memory is content-addressable,
Then using the erroneous string "Crhistpher Columbos" as key is
sufficient to retrieve the correct name "Christopher Colombus."
In this sense, this type of memory is robust and fault-tolerant, because
this type of memory exhibits some form of error-correction capability.
Fig. A content-addressable memory, Input and Output
Note : An associative memory is accessed by its content, opposed
to an explicit address in the traditional computer memory system.
The memory allows the recall of information based on partial knowledge
of its contents.
[Continued in next slide]
05
Alex Graham Bell
Thomas Edison
Christopher Columbus
Albert Einstein
Charles Darwin
Blaise Pascal
Marco Polo
Neil Armstrong
Sigmund Freud
Crhistpher Columbos Christopher Columbus](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-5-320.jpg)
![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - AM description
[Continued from previous slide]
■ Associative memory is a system that associates two patterns (X, Y)
such that when one is encountered, the other can be recalled.
The associative memory are of two types : auto-associative memory
and hetero-associative memory.
Auto-associative memory
Consider, y[1], y[2], y[3], . . . . . y[M], be the number of stored
pattern vectors and let y(m) be the components of these vectors,
representing features extracted from the patterns. The auto-associative
memory will output a pattern vector y(m) when inputting a noisy or
incomplete version of y(m).
Hetero-associative memory
Here the memory function is more general. Consider, we have a
number of key-response pairs {c(1), y(1)}, {c(2), y(2)}, . . . . . . ,
{c(M), y(M)}. The hetero-associative memory will output a pattern
vector y(m) if a noisy or incomplete verson of the c(m) is given.
■ Neural networks are used to implement associative memory models.
The well-known neural associative memory models are :
ƒ Linear associater is the simplest artificial neural associative
memory.
ƒ Hopfield model and Bidirectional Associative Memory (BAM)
are the other popular ANN models used as associative memories.
These models follow different neural network architectures to
memorize information.
06](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-6-320.jpg)








![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - AM models
• Linear Associator Model (two layers)
It is a feed-forward type network where the output is produced in a
single feed-forward computation. The model consists of two layers
of processing units, one serving as the input layer while the other as
the output layer. The inputs are directly connected to the outputs,
via a series of weights. The links carrying weights connect every input
to every output. The sum of the products of the weights and the
inputs is calculated in each neuron node. The network architecture
of the linear associator is as shown below.
Fig. Linear associator model
− all n input units are connected to all m output units via connection
weight matrix W = [wij]n x m where wij denotes the strength
of the unidirectional connection from the i th
input unit to the j th
output unit.
− the connection weight matrix stores the p different associated
pattern pairs {(Xk, Yk) | k = 1, 2, ..., p} .
− building an associative memory is constructing the connection
weight matrix W such that when an input pattern is presented,
then the stored pattern associated with the input pattern is retrieved.
[Continued in next slide]
16
w21
w11
w12
wn2
wn1
w1m
w2m
wnm
w22
y1
x1
y2
Ym
x2
Xn
inputs outputs
weights wij
neurons](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-16-320.jpg)
![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - AM models
[Continued from previous slide]
− Encoding : The process of constructing the connection weight matrix
is called encoding. During encoding the weight values of correlation
matrix Wk for an associated pattern pair (Xk, Yk) are computed as:
(wij)k = (xi)k (yj)k where
(xi)k is the i th
component of pattern Xk for i = 1, 2, ..., m, and
(yj)k is the j
th
component of pattern Yk for j = 1, 2, ..., n.
− Weight matrix : Construction of weight matrix W is accomplished
by summing those individual correlation matrices Wk, ie, W = α Wk
where α is the constant of proportionality, for normalizing, usually
set to 1/p to store p different associated pattern pairs.
− Decoding : After memorization, the network can be used for retrieval;
the process of retrieving a stored pattern, is called decoding;
given an input pattern X, the decoding or retrieving is accomplished
by computing, first the net Input as input j = xi w i j where
input j stands for the weighted sum of the input or activation value of
node j , for j = 1, 2, . . , n. and xi is the i
th
component of pattern Xk ,
and then determine the units Output using a bipolar output function:
+1 if input j ≥ θ j
Y j =
- 1 other wise
where θ j is the threshold value of output neuron j .
Note: The output units behave like linear threshold units; that compute
a weighted sum of the input and produces a -1 or +1 depending
whether the weighted sum is below or above a certain threshold value.
− Performance : The input pattern may contain errors and noise, or an
incomplete version of some previously encoded pattern. When such
corrupt input pattern is presented, the network will retrieve the stored
pattern that is closest to actual input pattern. Therefore, the linear
associator is robust and fault tolerant. The presence of noise or error
results in a mere decrease rather than total degradation in the
performance of the network.
17
Σ
k=1
p
Σ
j=1
m](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-17-320.jpg)
![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - AM models
• Auto-associative Memory Model - Hopfield model (single layer)
Auto-associative memory means patterns rather than associated
pattern pairs, are stored in memory. Hopfield model is one-layer
unidirectional auto-associative memory.
Hopfield network alternate view
Fig. Hopfield model with four units
− the model consists, a single layer of processing elements where each
unit is connected to every other unit in the network but not to itself.
− connection weight between or from neuron j to i is given by a
number wij. The collection of all such numbers are represented
by the weight matrix W which is square and symmetric, ie, w i j = w j i
for i, j = 1, 2, . . . . . , m.
− each unit has an external input I which leads to a modification
in the computation of the net input to the units as
input j = xi w i j + I j for j = 1, 2, . . ., m.
and xi is the i th
component of pattern Xk
− each unit acts as both input and output unit. Like linear associator,
a single associated pattern pair is stored by computing the weight
matrix as Wk = Yk where XK = YK
[Continued in next slide]
18
Σ
i=1
m
X
T
k
Σ1
Σ4
Σ3
Σ2
I
inputs
V
outputs
connection
weights wij
neurons
W14
W13
W24 W34
W23 W43
W12
W21 W31
W32 W42
W41
I1 I2 I3 I4
Σ1 Σ2 Σ3 Σ4
V1 V2 V3 V4](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-18-320.jpg)
![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - AM models
[Continued from previous slide]
− Weight Matrix : Construction of weight matrix W is accomplished by
summing those individual correlation matrices, ie, W = α Wk where
α is the constant of proportionality, for normalizing, usually set to 1/p
to store p different associated pattern pairs. Since the Hopfield
model is an auto-associative memory model, it is the patterns
rather than associated pattern pairs, are stored in memory.
− Decoding : After memorization, the network can be used for retrieval;
the process of retrieving a stored pattern, is called decoding; given an
input pattern X, the decoding or retrieving is accomplished by
computing, first the net Input as input j = xi w i j where input j
stands for the weighted sum of the input or activation value of node j ,
for j = 1, 2, ..., n. and xi is the i th
component of pattern Xk , and
then determine the units Output using a bipolar output function:
+1 if input j ≥ θ j
Y j =
- 1 other wise
where θ j is the threshold value of output neuron j .
Note: The output units behave like linear threshold units; that compute a
weighted sum of the input and produces a -1 or +1 depending whether the
weighted sum is below or above a certain threshold value.
Decoding in the Hopfield model is achieved by a collective and recursive
relaxation search for a stored pattern given an initial stimulus pattern.
Given an input pattern X, decoding is accomplished by computing the
net input to the units and determining the output of those units using
the output function to produce the pattern X'. The pattern X' is then fed
back to the units as an input pattern to produce the pattern X''. The
pattern X'' is again fed back to the units to produce the pattern X'''.
The process is repeated until the network stabilizes on a stored pattern
where further computations do not change the output of the units.
In the next section, the working of an auto-correlator : how to store
patterns, recall a pattern from the stored patterns and how to
recognize a noisy pattern are explained.
19
Σ
k=1
p
Σ
j=1
m](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-19-320.jpg)


![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - AM – auto correlator
• How to Store Patterns : Example
Consider the three bipolar patterns A1 , A2, A3 to be stored as
an auto-correlator.
A1 = (-1, 1 , -1 , 1 )
A2 = ( 1, 1 , 1 , -1 )
A3 = (-1, -1 , -1 , 1 )
Note that the outer product of two vectors U and V is
Thus, the outer products of each of these three A1 , A2, A3 bipolar
patterns are
Therefore the connection matrix is
=
This is how the patterns are stored .
22
[A1 ]
T
4x1 [A1 ] 1x4
1 -1 1 -1
-1 1 -1 1
1 -1 1 -1
-1 1 -1 1
=
j
i
[A2 ]
T
4x1 [A2 ] 1x4
1 1 1 -1
1 1 1 -1
1 1 1 -1
-1 -1 -1 1
=
j
i
[A3 ]
T
4x1 [A3 ] 1x4
1 1 1 -1
1 1 1 -1
1 1 1 -1
-1 -1 -1 1
=
j
i
=
U V V
UT =
U1
U2
U3
U4
V1 V2 V3
U1V1 U1V2 U1V3
U2V1 U2V2 U2V3
U3V1 U3V2 U3V3
U4V1 U4V2 U4V3
=
Σ
i=1
3
[Ai ]
T
4x1 [Ai ] 1x4
3 1 3 -3
1 3 1 -1
3 1 3 -3
-3 -1 -3 3
T = [t i j ] =
i
j](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-22-320.jpg)
![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - AM – auto correlator
• Retrieve a Pattern from the Stored Patterns (ref. previous slide)
The previous slide shows the connection matrix T of the three
bipolar patterns A1 , A2, A3 stored as
T = [t i j ] = =
and one of the three stored pattern is A2 = ( 1, 1 , 1 , -1 )
ai
− Retrieve or recall of this pattern A2 from the three stored patterns.
− The recall equation is
= ƒ (ai t i j , ) for ∀j = 1 , 2 , . . . , p
Computation for the recall equation A2 yields α = ∑ ai t i j and
then find β
Therefore = ƒ (ai t i j , ) for ∀j = 1 , 2 , . . . , p is ƒ (α , β )
= ƒ (10 , 1)
= ƒ (6 , 1)
= ƒ (10 , 1)
= ƒ (-1 , -1)
The values of β is the vector pattern ( 1, 1 , 1 , -1 ) which is A2 .
This is how to retrieve or recall a pattern from the stored patterns.
Similarly, retrieval of vector pattern A3 as
( , , , , ) = ( -1, -1 , -1 , 1 ) = A3
23
a
new
j a
old
j
i = 1 2 3 4 α β
α = ∑ ai t i , j=1 1x3 + 1x1 + 1x3 + -1x-3 = 10 1
α = ∑ ai t i , j=2 1x1 + 1x3 + 1x1 + -1x-1 = 6 1
α = ∑ ai t i , j=3 1x3 + 1x1 + 1x3 + -1x-3 = 10 1
α = ∑ ai t i , j=4 1x-3 + 1x-1 + 1x-3 + -1x3 = -1 -1
a
new
1
a
new
2
a
new
3
a
new
4
a
new
j a
old
j
a
new
1 a
new
2 a
new
3 a
new
4
Σ
i=1
3
[Ai ]
T
4x1 [Ai ] 1x4
3 1 3 -3
1 3 1 -1
3 1 3 -3
-3 -1 -3 3
j
i](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-23-320.jpg)


![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - Bidirectional hetero AM
4.1 Bidirectional Associative Memory (BAM) Operations
BAM is a two-layer nonlinear neural network.
Denote one layer as field A with elements Ai and the other layer
as field B with elements Bi.
The basic coding procedure of the discrete BAM is as follows.
Consider N training pairs { (A1 , B1) , (A2 , B2), . . , (Ai , Bi), . . (AN , BN) }
where Ai = (ai1 , ai2 , . . . , ain) and Bi = (bi1 , bi2 , . . . , bip) and
aij , bij are either in ON or OFF state.
− in binary mode , ON = 1 and OFF = 0 and
in bipolar mode, ON = 1 and OFF = -1
− the original correlation matrix of the BAM is M0 = [ ] [ ]
where Xi = (xi1 , xi2 , . . . , xin) and Yi = (yi1 , yi2 , . . . , yip)
and xij(yij) is the bipolar form of aij(bij)
The energy function E for the pair (α , β ) and correlation matrix M is
E = - α M
With this background, the decoding processes, means the operations
to retrieve nearest pattern pairs, and the addition and deletion of
the pattern pairs are illustrated in the next few slides.
26
Σ
i=1
N
X
T
i Yi
β
T](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-26-320.jpg)





![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - Bidirectional hetero AM
[Continued from previous slide]
Let the pair (X2 , Y2 ) be recalled.
X2 = ( -1 1 1 1 -1 -1 1 1 1 ) Y2 = ( 1 -1 -1 -1 -1 -1 -1 -1 1 )
Start with α = X2, and hope to retrieve the associated pair Y2 .
The calculations for the retrieval of Y2 yield :
α M = ( 5 -19 -13 -5 1 1 -5 -13 13 )
Φ (α M) = ( 1 -1 -1 -1 1 1 -1 -1 1 ) = β'
β' = ( -11 11 5 5 -11 -11 11 5 5 )
Φ (β' ) = ( -1 1 1 1 -1 -1 1 1 1 ) = α'
α' M = ( 5 -19 -13 -5 1 1 -5 -13 13 )
Φ (α' M) = ( 1 -1 -1 -1 1 1 -1 -1 1 ) = β"
= β'
Here β" = β' . Hence the cycle terminates with
αF = α' = ( -1 1 1 1 -1 -1 1 1 1 ) = X2
βF = β' = ( 1 -1 -1 -1 1 1 -1 -1 1 ) ≠ Y2
But β' is not Y2 . Thus the vector pair (X2 , Y2) is not recalled correctly
by Kosko's decoding process.
( Continued in next slide )
32
M
T
M
T](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-32-320.jpg)
![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - Bidirectional hetero AM
[Continued from previous slide]
Check with Energy Function : Compute the energy functions
for the coordinates of pair (X2 , Y2) , the energy E2 = - X2 M = -71
for the coordinates of pair (αF , βF) , the energy EF = - αF M = -75
However, the coordinates of pair (X2 , Y2) is not at its local
minimum can be shown by evaluating the energy E at a point which
is "one Hamming distance" way from Y2 . To do this consider a point
= ( 1 -1 -1 -1 1 -1 -1 -1 1 )
where the fifth component -1 of Y2 has been changed to 1. Now
E = - X2 M = - 73
which is lower than E2 confirming the hypothesis that (X2 , Y2) is not
at its local minimum of E.
Note : The correlation matrix M used by Kosko does not guarantee
that the energy of a training pair is at its local minimum. Therefore , a
pair Pi can be recalled if and only if this pair is at a local minimum
of the energy surface.
33
Y2
T
βF
T
Y2
'
Y2
′ T](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-33-320.jpg)


![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - Bidirectional hetero AM
[Continued from previous slide]
Now give α = X2, and see that the corresponding pattern pair β = Y2
is correctly recalled as shown below.
α M = ( 14 -28 -22 -14 -8 -8 -14 -22 22 )
Φ (α M) = ( 1 -1 -1 -1 -1 -1 -1 -1 1 ) = β'
β' = ( -16 16 18 18 -16 -16 16 18 18 )
Φ (β' ) = ( -1 1 1 1 -1 -1 1 1 1 ) = α'
α' M = ( 14 -28 -22 -14 -8 -8 -14 -22 23 )
Φ (α' M) = ( 1 -1 -1 -1 1 1 -1 -1 1 ) = β"
Here β" = β' . Hence the cycle terminates with
αF = α' = ( -1 1 1 1 -1 -1 1 1 1 ) = X2
βF = β' = ( 1 -1 -1 -1 1 1 -1 -1 1 ) = Y2
Thus, (X2 , Y2 ) is correctly recalled, using augmented correlation
matrix M . But, it is not possible to recall (X1 , Y1) using the same
matrix M as shown in the next slide.
( Continued in next slide )
36
M
T
M
T](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-36-320.jpg)
![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - Bidirectional hetero AM
[Continued from previous slide]
Note : The previous slide showed that the pattern pair (X2 , Y2 ) is correctly
recalled, using augmented correlation matrix
M = + 2 +
but then the same matrix M can not recall correctly the other
pattern pair (X1 , Y1 ) as shown below.
X1 = ( 1 -1 -1 1 1 1 -1 -1 -1 ) Y1 = ( 1 1 1 -1 -1 -1 -1 1 -1 )
Let α = X1 and to retrieve the associated pair Y1 the calculation shows
α M = ( -6 24 22 6 4 4 6 22 -22 )
Φ (α M) = ( -1 1 1 1 1 1 1 1 -1 ) = β'
β' = ( 16 -16 -18 -18 16 16 -16 -18 -18 )
Φ (β' ) = ( 1 -1 -1 -1 1 1 -1 -1 -1 ) = α'
α' M = ( -14 28 22 14 8 8 14 22 -22 )
Φ (α' M) = ( -1 1 1 1 1 1 1 1 -1 ) = β"
Here β" = β' . Hence the cycle terminates with
αF = α' = ( 1 -1 -1 -1 1 1 -1 -1 -1 ) = X1
βF = β' = ( -1 1 1 1 1 1 1 1 -1 ) ≠ Y1
Thus, the pattern pair (X1 , Y1 ) is not correctly recalled, using augmented
correlation matrix M.
To tackle this problem, the correlation matrix M needs to be further
augmented by multiple training of (X1 , Y1 ) as shown in the next slide.
( Continued in next slide )
37
X1
T
Y1 X2
T
Y2 X3
T
Y3
M
T
M
T](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-37-320.jpg)
![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - Bidirectional hetero AM
[Continued from previous slide]
The previous slide shows that pattern pair (X1 , Y1) cannot be recalled
under the same augmentation matrix M that is able to recall (X2 , Y2).
However, this problem can be solved by multiple training of (X1 , Y1)
which yields a further change in M to values by defining
M = 2 + 2 +
-1 5 3 1 -1 -1 1 3 -3
1 -5 -3 -1 1 1 -1 -3 3
-1 -3 -5 1 -1 -1 1 -5 5
5 -1 1 -5 -3 -3 -5 1 -1
-1 5 3 1 -1 -1 1 3 -3
-1 5 3 1 -1 -1 1 3 -3
1 -5 -3 -1 1 1 -1 -3 3
-1 -3 -5 1 -1 -1 1 -5 5
-1 -3 -5 1 -1 -1 1 -5 5
Now observe in the next slide that all three pairs can be correctly recalled.
( Continued in next slide )
38
=
X1
T
Y1 X2
T
Y2 X3
T
Y3](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-38-320.jpg)
![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - Bidirectional hetero AM
[ Continued from previous slide ]
Recall of pattern pair (X1 , Y1 )
X1 = ( 1 -1 -1 1 1 1 -1 -1 -1 ) Y1 = ( 1 1 1 -1 -1 -1 -1 1 -1 )
Let α = X1 and to retrieve the associated pair Y1 the calculation shows
α M = ( 3 33 31 -3 -5 -5 -3 31 -31 )
Φ (α M) = ( 1 1 1 -1 -1 -1 -1 1 -1 ) = β'
(β' ) = ( 13 -13 -19 23 13 13 -13 -19 -19 )
Φ (β' ) = ( 1 -1 -1 1 1 1 -1 -1 -1 ) = α'
α' M = ( 3 33 31 -3 -5 -5 -3 31 -31 )
Φ (α' M) = ( 1 1 1 -1 -1 -1 -1 1 -1 ) = β"
Here β" = β' . Hence the cycle terminates with
αF = α' = ( 1 -1 -1 1 1 1 -1 -1 -1 ) = X1
βF = β' = ( 1 1 1 -1 -1 -1 -1 1 -1 ) = Y1
Thus, the pattern pair (X1 , Y1 ) is correctly recalled
Recall of pattern pair (X2 , Y2 )
X2 = ( -1 1 1 1 -1 -1 1 1 1 ) Y2 = ( 1 -1 -1 -1 -1 -1 -1 -1 1 )
Let α = X2 and to retrieve the associated pair Y2 the calculation shows
α M = ( 7 -35 -29 -7 -1 -1 -7 -29 29 )
Φ (α M) = ( 1 -1 -1 -1 -1 -1 -1 -1 1 ) = β'
(β' ) = ( -15 15 17 19 -15 -15 15 17 17 )
Φ (β' ) = ( -1 1 1 1 -1 -1 1 1 1 ) = α'
α' M = ( 7 -35 -29 -7 -1 -1 -7 -29 29 )
Φ (α' M) = ( 1 -1 -1 -1 -1 -1 -1 -1 1 ) = β"
Here β" = β' . Hence the cycle terminates with
αF = α' = ( -1 1 1 1 -1 -1 1 1 1 ) = X2
βF = β' = ( 1 -1 -1 -1 -1 -1 -1 -1 1 ) = Y2
Thus, the pattern pair (X2 , Y2 ) is correctly recalled
Recall of pattern pair (X3 , Y3 )
X3 = ( 1 -1 1 -1 1 1 -1 1 1 ) Y3 = ( -1 1 -1 1 -1 -1 1 0 1 )
Let α = X3 and to retrieve the associated pair Y3 the calculation shows
α M = ( -13 17 -1 13 -5 -5 13 -1 1 )
Φ (α M) = ( -1 1 -1 1 -1 -1 1 -1 1 ) = β'
(β' ) = ( 11 -11 27 -63 11 11 -11 27 27 )
Φ (β' ) = ( 1 -1 1 -1 1 1 -1 1 1 ) = α'
α' M = ( -13 17 -1 13 -5 -5 13 -1 1 )
Φ (α' M) = ( -1 1 -1 1 -1 -1 1 -1 1 ) = β"
Here β" = β' . Hence the cycle terminates with
αF = α' = ( 1 -1 1 -1 1 1 -1 1 1 ) = X3
βF = β' = ( -1 1 -1 1 -1 -1 1 0 1 ) = Y3
Thus, the pattern pair (X3 , Y3 ) is correctly recalled
( Continued in next slide )
39
M
T
M
T
M
T
M
T
M
T
M
T](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-39-320.jpg)
![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - Bidirectional hetero AM
[Continued from previous slide]
Thus, the multiple training encoding strategy ensures the correct recall
of a pair for a suitable augmentation of M . The generalization of the
correlation matrix, for the correct recall of all training pairs, is written as
M = qi where qi 's are +ve real numbers.
This modified correlation matrix is called generalized correlation matrix.
Using one and same augmentation matrix M, it is possible to recall all
the training pattern pairs .
40
Σ
i=1
N
Xi
T
Yi](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-40-320.jpg)
![R
C
C
h
a
k
r
a
b
o
r
t
y
,
w
w
w
.
m
y
r
e
a
d
e
r
s
.
i
n
f
o
SC - Bidirectional hetero AM
• Algorithm (for the Multiple training encoding strategy)
To summarize the complete process of multiple training encoding an
algorithm is given below.
Algorithm Mul_Tr_Encode ( N , , , ) where
N : Number of stored patterns set
, : the bipolar pattern pairs
= ( , , . . . . , ) where = ( , , . . . )
= ( , , . . . . , ) where = ( , , . . . )
: is the weight vector (q1 , q2 , . . . . , qN )
Step 1 Initialize correlation matrix M to null matrix M ← [0]
Step 2 Compute the correlation matrix M as
For i ← 1 to N
M ← M ⊕ [ qi ∗ Transpose ( ) ⊗ ( ) end
(symbols ⊕ matrix addition, ⊗ matrix multiplication, and
∗ scalar multiplication)
Step 3 Read input bipolar pattern
Step 4 Compute A_M where A_M ← ⊗ M
Step 5 Apply threshold function Φ to A_M to get
ie ← Φ ( A_M )
where Φ is defined as Φ (F) = G = g1 , g2, . . . . , gn
Step 6 Output is the associated pattern pair
end
41
Xi
¯ Yi
¯
Xi
¯ Yi
¯
X
¯ X2
¯
X1
¯ XN
¯ Xi
¯ x i 1 x i 2
x i n
Y2
¯
Y1
¯ YN
¯ Yj
¯ x j 1 x j 2
x j n
Y
¯
q
¯
Xi
¯ Xi
¯
Ā
Ā
B'
¯
B'
¯
B'
¯
qi
¯](https://image.slidesharecdn.com/04associativememory-240405042121-d3942bf6/85/Associative-Memory-using-NN-Soft-Computing-41-320.jpg)































Ad
More Related Content
What's hot (20)
Similar to Associative Memory using NN (Soft Computing) (20)






![1.1 core programming [understand computer storage and data types]](https://cdn.slidesharecdn.com/ss_thumbnails/1-1coreprogrammingunderstandcomputerstorageanddatatypes-110330031933-phpapp02-thumbnail.jpg?width=560&fit=bounds)











Ad
More from Amit Kumar Rathi (20)




















Ad
Recently uploaded (20)




















Associative Memory using NN (Soft Computing)
- 1. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o Associative Memory : Soft Computing Course Lecture 21 – 24, notes, slides www.myreaders.info/ , RC Chakraborty, e-mail [email protected] , Dec. 01, 2010 http://www.myreaders.info/html/soft_computing.html Associative Memory Soft Computing www.myreaders.info Return to Website Associative Memory (AM), topics : Description, content address- ability, working, classes of AM : auto and hetero, AM related terms - encoding or memorization, retrieval or recollection, errors and noise, performance measure - memory capacity and content- addressability. Associative memory models : network architectures - linear associator, Hopfield model and bi-directional model (BAM). Auto-associative memory (auto-correlators) : how to store patterns ? how to retrieve patterns? recognition of noisy patterns. Bi-directional hetero-associative memory (hetero-correlators) : BAM operations - retrieve the nearest pair, addition and deletion of pattern pairs, energy function for BAM - working of Kosko's BAM, incorrect recall of pattern, multiple training encoding strategy – augmentation matrix, generalized correlation matrix and algorithm.
- 2. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o Associative Memory Soft Computing Topics (Lectures 21, 22, 23, 24 4 hours) Slides 1. Associative Memory (AM) Description Content addressability; Working of AM; AM Classes : auto and hetero; AM related terms - encoding or memorization, retrieval or recollection, errors and noise; Performance measure - memory capacity and content-addressability. 03-12 2. Associative Memory Models AM Classes – auto and hetero; AM Models; Network architectures - Linear associator, Hopfield model and Bi-directional model (BAM). 13-20 3. Auto-associative Memory (auto-correlators) How to store patterns? How to retrieve patterns? Recognition of noisy patterns. 21-24 4. Bi-directional Hetero-associative Memory (hetero-correlators) BAM operations - retrieve the nearest pair, Addition and deletion of pattern pairs; Energy function for BAM - working of Kosko's BAM, incorrect recall of pattern; Multiple training encoding strategy – augmentation matrix, generalized correlation matrix and algorithm . 25-41 5. References 42 02
- 3. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o Associative Memory What is Associative Memory ? • An associative memory is a content-addressable structure that maps a set of input patterns to a set of output patterns. • A content-addressable structure is a type of memory that allows the recall of data based on the degree of similarity between the input pattern and the patterns stored in memory. • There are two types of associative memory : auto-associative and hetero-associative. • An auto-associative memory retrieves a previously stored pattern that most closely resembles the current pattern. • In a hetero-associative memory, the retrieved pattern is in general, different from the input pattern not only in content but possibly also in type and format. • Neural networks are used to implement these associative memory models called NAM (Neural associative memory). 03
- 4. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM description 1. Associative Memory An associative memory is a content-addressable structure that maps a set of input patterns to a set of output patterns. A content-addressable structure refers to a memory organization where the memory is accessed by its content as opposed to an explicit address in the traditional computer memory system. The associative memory are of two types : auto-associative and hetero-associative. ƒ An auto-associative memory retrieves a previously stored pattern that most closely resembles the current pattern. ƒ In hetero-associative memory, the retrieved pattern is in general different from the input pattern not only in content but possibly also in type and format. 04
- 5. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM description 1.1 Description of Associative Memory An associative memory is a content-addressable structure that allows, the recall of data, based on the degree of similarity between the input pattern and the patterns stored in memory. • Example : Associative Memory The figure below shows a memory containing names of several people. If the given memory is content-addressable, Then using the erroneous string "Crhistpher Columbos" as key is sufficient to retrieve the correct name "Christopher Colombus." In this sense, this type of memory is robust and fault-tolerant, because this type of memory exhibits some form of error-correction capability. Fig. A content-addressable memory, Input and Output Note : An associative memory is accessed by its content, opposed to an explicit address in the traditional computer memory system. The memory allows the recall of information based on partial knowledge of its contents. [Continued in next slide] 05 Alex Graham Bell Thomas Edison Christopher Columbus Albert Einstein Charles Darwin Blaise Pascal Marco Polo Neil Armstrong Sigmund Freud Crhistpher Columbos Christopher Columbus
- 6. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM description [Continued from previous slide] ■ Associative memory is a system that associates two patterns (X, Y) such that when one is encountered, the other can be recalled. The associative memory are of two types : auto-associative memory and hetero-associative memory. Auto-associative memory Consider, y[1], y[2], y[3], . . . . . y[M], be the number of stored pattern vectors and let y(m) be the components of these vectors, representing features extracted from the patterns. The auto-associative memory will output a pattern vector y(m) when inputting a noisy or incomplete version of y(m). Hetero-associative memory Here the memory function is more general. Consider, we have a number of key-response pairs {c(1), y(1)}, {c(2), y(2)}, . . . . . . , {c(M), y(M)}. The hetero-associative memory will output a pattern vector y(m) if a noisy or incomplete verson of the c(m) is given. ■ Neural networks are used to implement associative memory models. The well-known neural associative memory models are : ƒ Linear associater is the simplest artificial neural associative memory. ƒ Hopfield model and Bidirectional Associative Memory (BAM) are the other popular ANN models used as associative memories. These models follow different neural network architectures to memorize information. 06
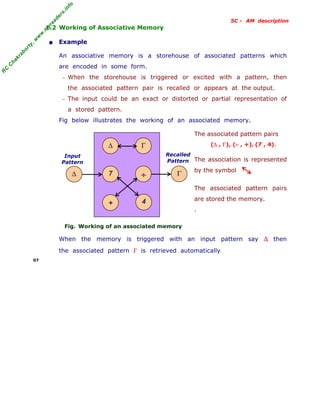
- 7. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM description 1.2 Working of Associative Memory • Example An associative memory is a storehouse of associated patterns which are encoded in some form. − When the storehouse is triggered or excited with a pattern, then the associated pattern pair is recalled or appears at the output. − The input could be an exact or distorted or partial representation of a stored pattern. Fig below illustrates the working of an associated memory. Fig. Working of an associated memory The associated pattern pairs (∆ , Γ), (÷ , +), (7 , 4). The association is represented by the symbol The associated pattern pairs are stored the memory. . When the memory is triggered with an input pattern say ∆ then the associated pattern Γ is retrieved automatically. 07 Input Pattern Recalled Pattern ∆ + 7 ÷ 4 Γ ∆ Γ
- 8. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM description 1.3 Associative Memory - Classes As stated before, there are two classes of associative memory: ƒ auto-associative and ƒ hetero-associative memory. An auto-associative memory, also known as auto-associative correlator, is used to retrieve a previously stored pattern that most closely resembles the current pattern; A hetero-associative memory, also known as hetero-associative correlator, is used to retrieve pattern in general, different from the input pattern not only in content but possibly also different in type and format. Examples Hetero-associative memory Auto-associative memory Fig. Hetero and Auto Associative memory Correlators 08 Input pattern presented Recall of associated pattern Recall of perfect pattern Presented distorted pattern
- 9. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM description 1.4 Related Terms Here explained : Encoding or memorization, Retrieval or recollection, Errors and Noise, Memory capacity and Content-addressability. • Encoding or memorization Building an associative memory means, constructing a connection weight matrix W such that when an input pattern is presented, and the stored pattern associated with the input pattern is retrieved. This process of constructing the connection weight matrix is called encoding. During encoding, for an associated pattern pair (Xk, Yk) , the weight values of the correlation matrix Wk are computed as (wij)k = (xi)k (yj)k , where (xi)k represents the i th component of pattern Xk , and (yj)k represents the j th component of pattern Yk for i = 1, 2, . . . , m and j = 1, 2, . . . , n. Constructing of the connection weight matrix W is accomplished by summing up the individual correlation matrices Wk , i.e., W = α Wk where α is the proportionality or normalizing constant. 09 Σ k=1 p
- 10. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM description • Retrieval or recollection After memorization, the process of retrieving a stored pattern, given an input pattern, is called decoding. Given an input pattern X, the decoding or recollection is accomplished by: first compute the net input to the output units using input j = xi w i j where input j is weighted sum of the input or activation value of node j , for j = 1, 2, ..., n. then determine the units output using a bipolar output function: +1 if input j ≥ θ j Y j = - 1 other wise where θ j is the threshold value of output neuron j . 10 Σ j=1 m
- 11. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM description • Errors and noise The input pattern may contain errors and noise, or may be an incomplete version of some previously encoded pattern. When a corrupted input pattern is presented, the network will retrieve the stored pattern that is closest to actual input pattern. The presence of noise or errors results only in a mere decrease rather than total degradation in the performance of the network. Thus, associative memories are robust and fault tolerant because of many processing elements performing highly parallel and distributed computations. 11
- 12. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM description • Performance Measures The memory capacity and content-addressability are the measures of associative memory performance for correct retrieval. These two performance measures are related to each other. Memory capacity refers to the maximum number of associated pattern pairs that can be stored and correctly retrieved. Content-addressability is the ability of the network to retrieve the correct stored pattern. If input patterns are mutually orthogonal - perfect retrieval is possible. If the stored input patterns are not mutually orthogonal - non-perfect retrieval can happen due to crosstalk among the patterns. 12
- 13. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM models 2. Associative Memory Models An associative memory is a system which stores mappings of specific input representations to specific output representations. − An associative memory "associates" two patterns such that when one is encountered, the other can be reliably recalled. − Most associative memory implementations are realized as connectionist networks. The simplest associative memory model is Linear associator, which is a feed-forward type of network. It has very low memory capacity and therefore not much used. The popular models are Hopfield Model and Bi-directional Associative Memory (BAM) model. The Network Architecture of these models are presented in this section. 13
- 14. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM models 2.1 Associative Memory Models The simplest and among the first studied associative memory models is Linear associator. It is a feed-forward type of network where the output is produced in a single feed-forward computation. It can be used as an auto-associator as well as a hetero-associator, but it possesses a very low memory capacity and therefore not much used. The popular associative memory models are Hopfield Model and Bi-directional Associative Memory (BAM) model. − The Hopfield model is an auto-associative memory, proposed by John Hopfield in 1982. It is an ensemble of simple processing units that have a fairly complex collective computational abilities and behavior. The Hopfield model computes its output recursively in time until the system becomes stable. Hopfield networks are designed using bipolar units and a learning procedure. − The Bi-directional associative memory (BAM) model is similar to linear associator, but the connections are bi-directional and therefore allows forward and backward flow of information between the layers. The BAM model can perform both auto-associative and hetero-associative recall of stored information. The network architecture of these three models are described in the next few slides. 14
- 15. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM models 2.2 Network Architectures of AM Models The neural associative memory models follow different neural network architectures to memorize information. The network architectures are either single layer or two layers . ƒ The Linear associator model, is a feed forward type network, consists, two layers of processing units, one serving as the input layer while the other as the output layer. ƒ The Hopfield model, is a single layer of processing elements where each unit is connected to every other unit in the network other than itself. ƒ The Bi-directional associative memory (BAM) model is similar to that of linear associator but the connections are bidirectional. In this section, the neural network architectures of these models and the construction of the corresponding connection weight matrix W of the associative memory are illustrated. 15
- 16. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM models • Linear Associator Model (two layers) It is a feed-forward type network where the output is produced in a single feed-forward computation. The model consists of two layers of processing units, one serving as the input layer while the other as the output layer. The inputs are directly connected to the outputs, via a series of weights. The links carrying weights connect every input to every output. The sum of the products of the weights and the inputs is calculated in each neuron node. The network architecture of the linear associator is as shown below. Fig. Linear associator model − all n input units are connected to all m output units via connection weight matrix W = [wij]n x m where wij denotes the strength of the unidirectional connection from the i th input unit to the j th output unit. − the connection weight matrix stores the p different associated pattern pairs {(Xk, Yk) | k = 1, 2, ..., p} . − building an associative memory is constructing the connection weight matrix W such that when an input pattern is presented, then the stored pattern associated with the input pattern is retrieved. [Continued in next slide] 16 w21 w11 w12 wn2 wn1 w1m w2m wnm w22 y1 x1 y2 Ym x2 Xn inputs outputs weights wij neurons
- 17. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM models [Continued from previous slide] − Encoding : The process of constructing the connection weight matrix is called encoding. During encoding the weight values of correlation matrix Wk for an associated pattern pair (Xk, Yk) are computed as: (wij)k = (xi)k (yj)k where (xi)k is the i th component of pattern Xk for i = 1, 2, ..., m, and (yj)k is the j th component of pattern Yk for j = 1, 2, ..., n. − Weight matrix : Construction of weight matrix W is accomplished by summing those individual correlation matrices Wk, ie, W = α Wk where α is the constant of proportionality, for normalizing, usually set to 1/p to store p different associated pattern pairs. − Decoding : After memorization, the network can be used for retrieval; the process of retrieving a stored pattern, is called decoding; given an input pattern X, the decoding or retrieving is accomplished by computing, first the net Input as input j = xi w i j where input j stands for the weighted sum of the input or activation value of node j , for j = 1, 2, . . , n. and xi is the i th component of pattern Xk , and then determine the units Output using a bipolar output function: +1 if input j ≥ θ j Y j = - 1 other wise where θ j is the threshold value of output neuron j . Note: The output units behave like linear threshold units; that compute a weighted sum of the input and produces a -1 or +1 depending whether the weighted sum is below or above a certain threshold value. − Performance : The input pattern may contain errors and noise, or an incomplete version of some previously encoded pattern. When such corrupt input pattern is presented, the network will retrieve the stored pattern that is closest to actual input pattern. Therefore, the linear associator is robust and fault tolerant. The presence of noise or error results in a mere decrease rather than total degradation in the performance of the network. 17 Σ k=1 p Σ j=1 m
- 18. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM models • Auto-associative Memory Model - Hopfield model (single layer) Auto-associative memory means patterns rather than associated pattern pairs, are stored in memory. Hopfield model is one-layer unidirectional auto-associative memory. Hopfield network alternate view Fig. Hopfield model with four units − the model consists, a single layer of processing elements where each unit is connected to every other unit in the network but not to itself. − connection weight between or from neuron j to i is given by a number wij. The collection of all such numbers are represented by the weight matrix W which is square and symmetric, ie, w i j = w j i for i, j = 1, 2, . . . . . , m. − each unit has an external input I which leads to a modification in the computation of the net input to the units as input j = xi w i j + I j for j = 1, 2, . . ., m. and xi is the i th component of pattern Xk − each unit acts as both input and output unit. Like linear associator, a single associated pattern pair is stored by computing the weight matrix as Wk = Yk where XK = YK [Continued in next slide] 18 Σ i=1 m X T k Σ1 Σ4 Σ3 Σ2 I inputs V outputs connection weights wij neurons W14 W13 W24 W34 W23 W43 W12 W21 W31 W32 W42 W41 I1 I2 I3 I4 Σ1 Σ2 Σ3 Σ4 V1 V2 V3 V4
- 19. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM models [Continued from previous slide] − Weight Matrix : Construction of weight matrix W is accomplished by summing those individual correlation matrices, ie, W = α Wk where α is the constant of proportionality, for normalizing, usually set to 1/p to store p different associated pattern pairs. Since the Hopfield model is an auto-associative memory model, it is the patterns rather than associated pattern pairs, are stored in memory. − Decoding : After memorization, the network can be used for retrieval; the process of retrieving a stored pattern, is called decoding; given an input pattern X, the decoding or retrieving is accomplished by computing, first the net Input as input j = xi w i j where input j stands for the weighted sum of the input or activation value of node j , for j = 1, 2, ..., n. and xi is the i th component of pattern Xk , and then determine the units Output using a bipolar output function: +1 if input j ≥ θ j Y j = - 1 other wise where θ j is the threshold value of output neuron j . Note: The output units behave like linear threshold units; that compute a weighted sum of the input and produces a -1 or +1 depending whether the weighted sum is below or above a certain threshold value. Decoding in the Hopfield model is achieved by a collective and recursive relaxation search for a stored pattern given an initial stimulus pattern. Given an input pattern X, decoding is accomplished by computing the net input to the units and determining the output of those units using the output function to produce the pattern X'. The pattern X' is then fed back to the units as an input pattern to produce the pattern X''. The pattern X'' is again fed back to the units to produce the pattern X'''. The process is repeated until the network stabilizes on a stored pattern where further computations do not change the output of the units. In the next section, the working of an auto-correlator : how to store patterns, recall a pattern from the stored patterns and how to recognize a noisy pattern are explained. 19 Σ k=1 p Σ j=1 m
- 20. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM models • Bidirectional Associative Memory (two-layer) Kosko (1988) extended the Hopfield model, which is single layer, by incorporating an additional layer to perform recurrent auto-associations as well as hetero-associations on the stored memories. The network structure of the bidirectional associative memory model is similar to that of the linear associator but the connections are bidirectional; i.e., wij = wji , for i = 1, 2, . . . , n and j = 1, 2, . . . , m. Fig. Bidirectional Associative Memory model − In the bidirectional associative memory, a single associated pattern pair is stored by computing the weight matrix as Wk = Yk . − the construction of the connection weight matrix W, to store p different associated pattern pairs simultaneously, is accomplished by summing up the individual correlation matrices Wk , i.e., W = α Wk where α is the proportionality or normalizing constant. 20 w21 w11 w12 wn2 wn1 w1m w2m wnm w22 y1 x1 y2 Ym x2 Xn inputs outputs weights wij neurons neurons X T k Σ k=1 p
- 21. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM – auto correlator 3. Auto-associative Memory (auto-correlators) In the previous section, the structure of the Hopfield model has been explained. It is an auto-associative memory model which means patterns, rather than associated pattern pairs, are stored in memory. In this section, the working of an auto-associative memory (auto-correlator) is illustrated using some examples. Working of an auto-correlator : − how to store the patterns, − how to retrieve / recall a pattern from the stored patterns, and − how to recognize a noisy pattern 21
- 22. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM – auto correlator • How to Store Patterns : Example Consider the three bipolar patterns A1 , A2, A3 to be stored as an auto-correlator. A1 = (-1, 1 , -1 , 1 ) A2 = ( 1, 1 , 1 , -1 ) A3 = (-1, -1 , -1 , 1 ) Note that the outer product of two vectors U and V is Thus, the outer products of each of these three A1 , A2, A3 bipolar patterns are Therefore the connection matrix is = This is how the patterns are stored . 22 [A1 ] T 4x1 [A1 ] 1x4 1 -1 1 -1 -1 1 -1 1 1 -1 1 -1 -1 1 -1 1 = j i [A2 ] T 4x1 [A2 ] 1x4 1 1 1 -1 1 1 1 -1 1 1 1 -1 -1 -1 -1 1 = j i [A3 ] T 4x1 [A3 ] 1x4 1 1 1 -1 1 1 1 -1 1 1 1 -1 -1 -1 -1 1 = j i = U V V UT = U1 U2 U3 U4 V1 V2 V3 U1V1 U1V2 U1V3 U2V1 U2V2 U2V3 U3V1 U3V2 U3V3 U4V1 U4V2 U4V3 = Σ i=1 3 [Ai ] T 4x1 [Ai ] 1x4 3 1 3 -3 1 3 1 -1 3 1 3 -3 -3 -1 -3 3 T = [t i j ] = i j
- 23. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM – auto correlator • Retrieve a Pattern from the Stored Patterns (ref. previous slide) The previous slide shows the connection matrix T of the three bipolar patterns A1 , A2, A3 stored as T = [t i j ] = = and one of the three stored pattern is A2 = ( 1, 1 , 1 , -1 ) ai − Retrieve or recall of this pattern A2 from the three stored patterns. − The recall equation is = ƒ (ai t i j , ) for ∀j = 1 , 2 , . . . , p Computation for the recall equation A2 yields α = ∑ ai t i j and then find β Therefore = ƒ (ai t i j , ) for ∀j = 1 , 2 , . . . , p is ƒ (α , β ) = ƒ (10 , 1) = ƒ (6 , 1) = ƒ (10 , 1) = ƒ (-1 , -1) The values of β is the vector pattern ( 1, 1 , 1 , -1 ) which is A2 . This is how to retrieve or recall a pattern from the stored patterns. Similarly, retrieval of vector pattern A3 as ( , , , , ) = ( -1, -1 , -1 , 1 ) = A3 23 a new j a old j i = 1 2 3 4 α β α = ∑ ai t i , j=1 1x3 + 1x1 + 1x3 + -1x-3 = 10 1 α = ∑ ai t i , j=2 1x1 + 1x3 + 1x1 + -1x-1 = 6 1 α = ∑ ai t i , j=3 1x3 + 1x1 + 1x3 + -1x-3 = 10 1 α = ∑ ai t i , j=4 1x-3 + 1x-1 + 1x-3 + -1x3 = -1 -1 a new 1 a new 2 a new 3 a new 4 a new j a old j a new 1 a new 2 a new 3 a new 4 Σ i=1 3 [Ai ] T 4x1 [Ai ] 1x4 3 1 3 -3 1 3 1 -1 3 1 3 -3 -3 -1 -3 3 j i
- 24. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - AM – auto correlator • Recognition of Noisy Patterns (ref. previous slide) Consider a vector A' = ( 1, 1 , 1 , 1 ) which is a noisy presentation of one among the stored patterns. − find the proximity of the noisy vector to the stored patterns using Hamming distance measure. − note that the Hamming distance (HD) of a vector X from Y, where X = (x1 , x2 , . . . , xn) and Y = ( y1, y2 , . . . , yn) is given by HD (x , y) = | (xi - yi ) | The HDs of A' from each of the stored patterns A1 , A2, A3 are HD (A' , A1) = ∑ |(x1 - y1 )|, |(x2 - y2)|, |(x3 - y3 )|, |(x4 - y4 )| = ∑ |(1 - (-1))|, |(1 - 1)|, |(1 - (-1) )|, |(1 - 1)| = 4 HD (A' , A2) = 2 HD (A' , A3) = 6 Therefore the vector A' is closest to A2 and so resembles it. In other words the vector A' is a noisy version of vector A2. Computation of recall equation using vector A' yields : Therefore = ƒ (ai t i j , ) for ∀j = 1 , 2 , . . . , p is ƒ (α , β ) = ƒ (4 , 1) = ƒ (4 , 1) = ƒ (4 , 1) = ƒ (-4 , -1) The values of β is the vector pattern ( 1, 1 , 1 , -1 ) which is A2 . Note : In presence of noise or in case of partial representation of vectors, an autocorrelator results in the refinement of the pattern or removal of noise to retrieve the closest matching stored pattern. 24 Σ i=1 m i = 1 2 3 4 α β α = ∑ ai t i , j=1 1x3 + 1x1 + 1x3 + 1x-3 = 4 1 α = ∑ ai t i , j=2 1x1 + 1x3 + 1x1 + 1x-1 = 4 1 α = ∑ ai t i , j=3 1x3 + 1x1 + 1x3 + 1x-3 = 4 1 α = ∑ ai t i , j=4 1x-3 + 1x-1 + 1x-3 + 1x3 = -4 -1 a new 1 a new 2 a new 3 a new 4 a new j a old j
- 25. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM 4. Bidirectional Hetero-associative Memory The Hopfield one-layer unidirectional auto-associators have been discussed in previous section. Kosko (1987) extended this network to two-layer bidirectional structure called Bidirectional Associative Memory (BAM) which can achieve hetero-association. The important performance attributes of the BAM is its ability to recall stored pairs particularly in the presence of noise. Definition : If the associated pattern pairs (X, Y) are different and if the model recalls a pattern Y given a pattern X or vice-versa, then it is termed as hetero-associative memory. This section illustrates the bidirectional associative memory : ƒ Operations (retrieval, addition and deletion) , ƒ Energy Function (Kosko's correlation matrix, incorrect recall of pattern), ƒ Multiple training encoding strategy (Wang's generalized correlation matrix). 25
- 26. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM 4.1 Bidirectional Associative Memory (BAM) Operations BAM is a two-layer nonlinear neural network. Denote one layer as field A with elements Ai and the other layer as field B with elements Bi. The basic coding procedure of the discrete BAM is as follows. Consider N training pairs { (A1 , B1) , (A2 , B2), . . , (Ai , Bi), . . (AN , BN) } where Ai = (ai1 , ai2 , . . . , ain) and Bi = (bi1 , bi2 , . . . , bip) and aij , bij are either in ON or OFF state. − in binary mode , ON = 1 and OFF = 0 and in bipolar mode, ON = 1 and OFF = -1 − the original correlation matrix of the BAM is M0 = [ ] [ ] where Xi = (xi1 , xi2 , . . . , xin) and Yi = (yi1 , yi2 , . . . , yip) and xij(yij) is the bipolar form of aij(bij) The energy function E for the pair (α , β ) and correlation matrix M is E = - α M With this background, the decoding processes, means the operations to retrieve nearest pattern pairs, and the addition and deletion of the pattern pairs are illustrated in the next few slides. 26 Σ i=1 N X T i Yi β T
- 27. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM • Retrieve the Nearest of a Pattern Pair, given any pair (ref : previous slide) Example Retrieve the nearest of (Ai , Bi) pattern pair, given any pair (α , β ) . The methods and the equations for retrieve are : − start with an initial condition which is any given pattern pair (α , β ), − determine a finite sequence of pattern pairs (α' , β' ) , (α" , β" ) . . . . until an equilibrium point (αf , βf ) is reached, where β' = Φ (α M ) and α' = Φ ( β' ) β" = Φ (α' M ) and α" =Φ ( β'' ) Φ (F) = G = g1 , g2 , . . . . , gr , F = ( f1 , f2 , . . . . , fr ) M is correlation matrix 1 if f i > 0 0 (binary) gi = , f i < 0 -1 (bipolar) previous g i , f i = 0 Kosko has proved that this process will converge for any correlation matrix M. 27 M T M T
- 28. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM • Addition and Deletion of Pattern Pairs Given a set of pattern pairs (Xi , Yi) , for i = 1 , 2, . . . , n and a set of correlation matrix M : − a new pair (X' , Y') can be added or − an existing pair (Xj , Yj) can be deleted from the memory model. Addition : add a new pair (X' , Y') , to existing correlation matrix M , them the new correlation matrix Mnew is given by Mnew = + + . . . . + + Deletion : subtract the matrix corresponding to an existing pair (Xj , Yj) from the correlation matrix M , them the new correlation matrix Mnew is given by Mnew = M - ( ) Note : The addition and deletion of information is similar to the functioning of the system as a human memory exhibiting learning and forgetfulness. 28 X1 T Y1 X1 T Y1 Xn T Yn X' T Y' Xj T Yj
- 29. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM 4.2 Energy Function for BAM Note : A system that changes with time is a dynamic system. There are two types of dynamics in a neural network. During training phase it iteratively update weights and during production phase it asymptotically converges to the solution patterns. State is a collection of qualitative and qualitative items that characterize the system e.g., weights, data flows. The Energy function (or Lyapunov function) is a bounded function of the system state that decreases with time and the system solution is the minimum energy. Let a pair (A , B) defines the state of a BAM. − to store a pattern, the value of the energy function for that pattern has to occupy a minimum point in the energy landscape. − also adding a new patterns must not destroy the previously stored patterns. The stability of a BAM can be proved by identifying the energy function E with each state (A , B) . − For auto-associative memory : the energy function is E(A) = - AM − For bidirecional hetero associative memory : the energy function is E(A, B) = - AM ; for a particular case A = B , it corresponds to Hopfield auto-associative function. We wish to retrieve the nearest of (Ai , Bi) pair, when any (α , β ) pair is presented as initial condition to BAM. The neurons change their states until a bidirectional stable state (Af , Bf) is reached. Kosko has shown that such stable state is reached for any matrix M when it corresponds to local minimum of the energy function. Each cycle of decoding lowers the energy E if the energy function for any point (α , β ) is given by If the energy evaluated using coordinates of the pair (Ai , Bi) does not constitute a local minimum, then the point cannot be recalled, even though one starts with α = Ai. Thus Kosko's encoding method does not ensure that the stored pairs are at a local minimum. 29 A T B T E = α M β T E = Ai M Bi T
- 30. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM • Example : Kosko's BAM for Retrieval of Associated Pair The working of Kosko's BAM for retrieval of associated pair. Start with X3, and hope to retrieve the associated pair Y3 . Consider N = 3 pattern pairs (A1 , B1 ) , (A2 , B2 ) , (A3 , B3 ) given by A1 = ( 1 0 0 0 0 1 ) B1 = ( 1 1 0 0 0 ) A2 = ( 0 1 1 0 0 0 ) B2 = ( 1 0 1 0 0 ) A3 = ( 0 0 1 0 1 1 ) B3 = ( 0 1 1 1 0 ) Convert these three binary pattern to bipolar form replacing 0s by -1s. X1 = ( 1 -1 -1 -1 -1 1 ) Y1 = ( 1 1 -1 -1 -1 ) X2 = ( -1 1 1 -1 -1 -1 ) Y2 = ( 1 -1 1 -1 -1 ) X3 = ( -1 -1 1 -1 1 1 ) Y3 = ( -1 1 1 1 -1 ) The correlation matrix M is calculated as 6x5 matrix 1 1 -3 -1 1 1 -3 1 -1 1 -1 -1 3 1 -1 M = + + = -1 -1 -1 1 3 -3 1 1 3 1 -1 3 -1 1 -1 Suppose we start with α = X3, and we hope to retrieve the associated pair Y3 . The calculations for the retrieval of Y3 yield : α M = ( -1 -1 1 -1 1 1 ) ( M ) = ( -6 6 6 6 -6 ) Φ (α M) = β' = ( -1 1 1 1 -1 ) β' = ( -5 -5 5 -3 7 5 ) Φ (β' ) = ( -1 -1 1 -1 1 1 ) = α' α' M = ( -1 -1 1 -1 1 1 ) M = ( -6 6 6 6 -6 ) Φ (α' M) = β" = ( -1 1 1 1 1 -1 ) = β' This retrieved patern β' is same as Y3 . Hence, (αf , βf) = (X3 , Y3 ) is correctly recalled, a desired result . 30 X1 T Y1 X2 T Y2 X3 T Y3 M T M T
- 31. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM • Example : Incorrect Recall by Kosko's BAM The Working of incorrect recall by Kosko's BAM. Start with X2, and hope to retrieve the associated pair Y2 . Consider N = 3 pattern pairs (A1 , B1 ) , (A2 , B2 ) , (A3 , B3 ) given by A1 = ( 1 0 0 1 1 1 0 0 0 ) B1 = ( 1 1 1 0 0 0 0 1 0 ) A2 = ( 0 1 1 1 0 0 1 1 1 ) B2 = ( 1 0 0 0 0 0 0 0 1 ) A3 = ( 1 0 1 0 1 1 0 1 1 ) B3 = ( 0 1 0 1 0 0 1 0 1 ) Convert these three binary pattern to bipolar form replacing 0s by -1s. X1 = ( 1 -1 -1 1 1 1 -1 -1 -1 ) Y1 = ( 1 1 1 -1 -1 -1 -1 1 -1 ) X2 = ( -1 1 1 1 -1 -1 1 1 1 ) Y2 = ( 1 -1 -1 -1 -1 -1 -1 -1 1 ) X3 = ( 1 -1 1 -1 1 1 -1 1 1 ) Y3 = ( -1 1 -1 1 -1 -1 1 0 1 ) The correlation matrix M is calculated as 9 x 9 matrix M = + + -1 3 1 1 -1 -1 1 1 -1 1 -3 -1 -1 1 1 -1 -1 1 -1 -1 -3 1 -1 -1 1 -3 3 3 -1 1 -3 -1 -1 -3 1 -1 -1 3 1 1 -1 -1 1 1 -1 -1 3 1 1 -1 -1 1 1 -1 1 -3 -1 -1 1 1 -1 -1 1 -1 -1 -3 1 -1 -1 1 -3 3 -1 -1 -3 1 -1 -1 1 -3 3 (Continued in next slide) 31 = X1 T Y1 X2 T Y2 X3 T Y3
- 32. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM [Continued from previous slide] Let the pair (X2 , Y2 ) be recalled. X2 = ( -1 1 1 1 -1 -1 1 1 1 ) Y2 = ( 1 -1 -1 -1 -1 -1 -1 -1 1 ) Start with α = X2, and hope to retrieve the associated pair Y2 . The calculations for the retrieval of Y2 yield : α M = ( 5 -19 -13 -5 1 1 -5 -13 13 ) Φ (α M) = ( 1 -1 -1 -1 1 1 -1 -1 1 ) = β' β' = ( -11 11 5 5 -11 -11 11 5 5 ) Φ (β' ) = ( -1 1 1 1 -1 -1 1 1 1 ) = α' α' M = ( 5 -19 -13 -5 1 1 -5 -13 13 ) Φ (α' M) = ( 1 -1 -1 -1 1 1 -1 -1 1 ) = β" = β' Here β" = β' . Hence the cycle terminates with αF = α' = ( -1 1 1 1 -1 -1 1 1 1 ) = X2 βF = β' = ( 1 -1 -1 -1 1 1 -1 -1 1 ) ≠ Y2 But β' is not Y2 . Thus the vector pair (X2 , Y2) is not recalled correctly by Kosko's decoding process. ( Continued in next slide ) 32 M T M T
- 33. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM [Continued from previous slide] Check with Energy Function : Compute the energy functions for the coordinates of pair (X2 , Y2) , the energy E2 = - X2 M = -71 for the coordinates of pair (αF , βF) , the energy EF = - αF M = -75 However, the coordinates of pair (X2 , Y2) is not at its local minimum can be shown by evaluating the energy E at a point which is "one Hamming distance" way from Y2 . To do this consider a point = ( 1 -1 -1 -1 1 -1 -1 -1 1 ) where the fifth component -1 of Y2 has been changed to 1. Now E = - X2 M = - 73 which is lower than E2 confirming the hypothesis that (X2 , Y2) is not at its local minimum of E. Note : The correlation matrix M used by Kosko does not guarantee that the energy of a training pair is at its local minimum. Therefore , a pair Pi can be recalled if and only if this pair is at a local minimum of the energy surface. 33 Y2 T βF T Y2 ' Y2 ′ T
- 34. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM 4.3 Multiple Training Encoding Strategy Note : (Ref. example in previous section). Kosko extended the unidirectional auto-associative to bidirectional associative processes, using correlation matrix M = Σ computed from the pattern pairs. The system proceeds to retrieve the nearest pair given any pair (α , β ), with the help of recall equations. However, Kosko's encoding method does not ensure that the stored pairs are at local minimum and hence, results in incorrect recall. Wang and other's, introduced multiple training encoding strategy which ensures the correct recall of pattern pairs. This encoding strategy is an enhancement / generalization of Kosko's encoding strategy. The Wang's generalized correlation matrix is M = Σ qi where qi is viewed as pair weight for as positive real numbers. It denotes the minimum number of times for using a pattern pair (Xi , Yi) for training to guarantee recall of that pair. To recover a pair (Ai , Bi) using multiple training of order q, let us augment or supplement matrix M with a matrix P defined as P = (q – 1) where (Xi , Yi) are the bipolar form of (Ai , Bi). The augmentation implies adding (q - 1) more pairs located at (Ai , Bi) to the existing correlation matrix. As a result the energy E' can reduced to an arbitrarily low value by a suitable choice of q. This also ensures that the energy at (Ai , Bi) does not exceed at points which are one Hamming distance away from this location. The new value of the energy function E evaluated at (Ai , Bi) then becomes E' (Ai , Bi) = – Ai M – (q – 1) Ai The next few slides explains the step-by-step implementation of Multiple training encoding strategy for the recall of three pattern pairs (X1 , Y1 ) , (X1 , Y1 ) , (X1 , Y1 ) using one and same augmentation matrix M . Also an algorithm to summarize the complete process of multiple training encoding is given. 34 Xi T Yi Xi T Yi Xi T Yi Xi T Yi Bi T Xi T Yi Bi T
- 35. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM • Example : Multiple Training Encoding Strategy The working of multiple training encoding strategy which ensures the correct recall of pattern pairs. Consider N = 3 pattern pairs (A1 , B1 ) , (A2 , B2 ) , (A3 , B3 ) given by A1 = ( 1 0 0 1 1 1 0 0 0 ) B1 = ( 1 1 1 0 0 0 0 1 0 ) A2 = ( 0 1 1 1 0 0 1 1 1 ) B2 = ( 1 0 0 0 0 0 0 0 1 ) A3 = ( 1 0 1 0 1 1 0 1 1 ) B3 = ( 0 1 0 1 0 0 1 0 1 ) Convert these three binary pattern to bipolar form replacing 0s by -1s. X1 = ( 1 -1 -1 1 1 1 -1 -1 -1 ) Y1 = ( 1 1 1 -1 -1 -1 -1 1 -1 ) X2 = ( -1 1 1 1 -1 -1 1 1 1 ) Y2 = ( 1 -1 -1 -1 -1 -1 -1 -1 1 ) X3 = ( 1 -1 1 -1 1 1 -1 1 1 ) Y3 = ( -1 1 -1 1 -1 -1 1 0 1 ) Let the pair (X2 , Y2) be recalled. X2 = ( -1 1 1 1 -1 -1 1 1 1 ) Y2 = ( 1 -1 -1 -1 -1 -1 -1 -1 1 ) Choose q=2, so that P = , the augmented correlation matrix M becomes M = + 2 + 4 2 2 0 0 2 2 -2 2 -4 -2 -2 0 0 -2 -2 2 0 -2 -4 0 -2 -2 0 -4 4 4 -2 0 -4 -2 -2 -4 0 0 -2 4 2 2 0 0 2 2 -2 -2 4 2 2 0 0 2 2 -2 2 -4 -2 -2 0 0 -2 -2 2 0 -2 -4 0 -2 -2 0 -4 4 0 -2 -4 0 -2 -2 0 -4 4 ( Continued in next slide ) 35 X1 T Y1 X2 T Y2 X3 T Y3 X2 T Y2 =
- 36. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM [Continued from previous slide] Now give α = X2, and see that the corresponding pattern pair β = Y2 is correctly recalled as shown below. α M = ( 14 -28 -22 -14 -8 -8 -14 -22 22 ) Φ (α M) = ( 1 -1 -1 -1 -1 -1 -1 -1 1 ) = β' β' = ( -16 16 18 18 -16 -16 16 18 18 ) Φ (β' ) = ( -1 1 1 1 -1 -1 1 1 1 ) = α' α' M = ( 14 -28 -22 -14 -8 -8 -14 -22 23 ) Φ (α' M) = ( 1 -1 -1 -1 1 1 -1 -1 1 ) = β" Here β" = β' . Hence the cycle terminates with αF = α' = ( -1 1 1 1 -1 -1 1 1 1 ) = X2 βF = β' = ( 1 -1 -1 -1 1 1 -1 -1 1 ) = Y2 Thus, (X2 , Y2 ) is correctly recalled, using augmented correlation matrix M . But, it is not possible to recall (X1 , Y1) using the same matrix M as shown in the next slide. ( Continued in next slide ) 36 M T M T
- 37. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM [Continued from previous slide] Note : The previous slide showed that the pattern pair (X2 , Y2 ) is correctly recalled, using augmented correlation matrix M = + 2 + but then the same matrix M can not recall correctly the other pattern pair (X1 , Y1 ) as shown below. X1 = ( 1 -1 -1 1 1 1 -1 -1 -1 ) Y1 = ( 1 1 1 -1 -1 -1 -1 1 -1 ) Let α = X1 and to retrieve the associated pair Y1 the calculation shows α M = ( -6 24 22 6 4 4 6 22 -22 ) Φ (α M) = ( -1 1 1 1 1 1 1 1 -1 ) = β' β' = ( 16 -16 -18 -18 16 16 -16 -18 -18 ) Φ (β' ) = ( 1 -1 -1 -1 1 1 -1 -1 -1 ) = α' α' M = ( -14 28 22 14 8 8 14 22 -22 ) Φ (α' M) = ( -1 1 1 1 1 1 1 1 -1 ) = β" Here β" = β' . Hence the cycle terminates with αF = α' = ( 1 -1 -1 -1 1 1 -1 -1 -1 ) = X1 βF = β' = ( -1 1 1 1 1 1 1 1 -1 ) ≠ Y1 Thus, the pattern pair (X1 , Y1 ) is not correctly recalled, using augmented correlation matrix M. To tackle this problem, the correlation matrix M needs to be further augmented by multiple training of (X1 , Y1 ) as shown in the next slide. ( Continued in next slide ) 37 X1 T Y1 X2 T Y2 X3 T Y3 M T M T
- 38. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM [Continued from previous slide] The previous slide shows that pattern pair (X1 , Y1) cannot be recalled under the same augmentation matrix M that is able to recall (X2 , Y2). However, this problem can be solved by multiple training of (X1 , Y1) which yields a further change in M to values by defining M = 2 + 2 + -1 5 3 1 -1 -1 1 3 -3 1 -5 -3 -1 1 1 -1 -3 3 -1 -3 -5 1 -1 -1 1 -5 5 5 -1 1 -5 -3 -3 -5 1 -1 -1 5 3 1 -1 -1 1 3 -3 -1 5 3 1 -1 -1 1 3 -3 1 -5 -3 -1 1 1 -1 -3 3 -1 -3 -5 1 -1 -1 1 -5 5 -1 -3 -5 1 -1 -1 1 -5 5 Now observe in the next slide that all three pairs can be correctly recalled. ( Continued in next slide ) 38 = X1 T Y1 X2 T Y2 X3 T Y3
- 39. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM [ Continued from previous slide ] Recall of pattern pair (X1 , Y1 ) X1 = ( 1 -1 -1 1 1 1 -1 -1 -1 ) Y1 = ( 1 1 1 -1 -1 -1 -1 1 -1 ) Let α = X1 and to retrieve the associated pair Y1 the calculation shows α M = ( 3 33 31 -3 -5 -5 -3 31 -31 ) Φ (α M) = ( 1 1 1 -1 -1 -1 -1 1 -1 ) = β' (β' ) = ( 13 -13 -19 23 13 13 -13 -19 -19 ) Φ (β' ) = ( 1 -1 -1 1 1 1 -1 -1 -1 ) = α' α' M = ( 3 33 31 -3 -5 -5 -3 31 -31 ) Φ (α' M) = ( 1 1 1 -1 -1 -1 -1 1 -1 ) = β" Here β" = β' . Hence the cycle terminates with αF = α' = ( 1 -1 -1 1 1 1 -1 -1 -1 ) = X1 βF = β' = ( 1 1 1 -1 -1 -1 -1 1 -1 ) = Y1 Thus, the pattern pair (X1 , Y1 ) is correctly recalled Recall of pattern pair (X2 , Y2 ) X2 = ( -1 1 1 1 -1 -1 1 1 1 ) Y2 = ( 1 -1 -1 -1 -1 -1 -1 -1 1 ) Let α = X2 and to retrieve the associated pair Y2 the calculation shows α M = ( 7 -35 -29 -7 -1 -1 -7 -29 29 ) Φ (α M) = ( 1 -1 -1 -1 -1 -1 -1 -1 1 ) = β' (β' ) = ( -15 15 17 19 -15 -15 15 17 17 ) Φ (β' ) = ( -1 1 1 1 -1 -1 1 1 1 ) = α' α' M = ( 7 -35 -29 -7 -1 -1 -7 -29 29 ) Φ (α' M) = ( 1 -1 -1 -1 -1 -1 -1 -1 1 ) = β" Here β" = β' . Hence the cycle terminates with αF = α' = ( -1 1 1 1 -1 -1 1 1 1 ) = X2 βF = β' = ( 1 -1 -1 -1 -1 -1 -1 -1 1 ) = Y2 Thus, the pattern pair (X2 , Y2 ) is correctly recalled Recall of pattern pair (X3 , Y3 ) X3 = ( 1 -1 1 -1 1 1 -1 1 1 ) Y3 = ( -1 1 -1 1 -1 -1 1 0 1 ) Let α = X3 and to retrieve the associated pair Y3 the calculation shows α M = ( -13 17 -1 13 -5 -5 13 -1 1 ) Φ (α M) = ( -1 1 -1 1 -1 -1 1 -1 1 ) = β' (β' ) = ( 11 -11 27 -63 11 11 -11 27 27 ) Φ (β' ) = ( 1 -1 1 -1 1 1 -1 1 1 ) = α' α' M = ( -13 17 -1 13 -5 -5 13 -1 1 ) Φ (α' M) = ( -1 1 -1 1 -1 -1 1 -1 1 ) = β" Here β" = β' . Hence the cycle terminates with αF = α' = ( 1 -1 1 -1 1 1 -1 1 1 ) = X3 βF = β' = ( -1 1 -1 1 -1 -1 1 0 1 ) = Y3 Thus, the pattern pair (X3 , Y3 ) is correctly recalled ( Continued in next slide ) 39 M T M T M T M T M T M T
- 40. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM [Continued from previous slide] Thus, the multiple training encoding strategy ensures the correct recall of a pair for a suitable augmentation of M . The generalization of the correlation matrix, for the correct recall of all training pairs, is written as M = qi where qi 's are +ve real numbers. This modified correlation matrix is called generalized correlation matrix. Using one and same augmentation matrix M, it is possible to recall all the training pattern pairs . 40 Σ i=1 N Xi T Yi
- 41. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC - Bidirectional hetero AM • Algorithm (for the Multiple training encoding strategy) To summarize the complete process of multiple training encoding an algorithm is given below. Algorithm Mul_Tr_Encode ( N , , , ) where N : Number of stored patterns set , : the bipolar pattern pairs = ( , , . . . . , ) where = ( , , . . . ) = ( , , . . . . , ) where = ( , , . . . ) : is the weight vector (q1 , q2 , . . . . , qN ) Step 1 Initialize correlation matrix M to null matrix M ← [0] Step 2 Compute the correlation matrix M as For i ← 1 to N M ← M ⊕ [ qi ∗ Transpose ( ) ⊗ ( ) end (symbols ⊕ matrix addition, ⊗ matrix multiplication, and ∗ scalar multiplication) Step 3 Read input bipolar pattern Step 4 Compute A_M where A_M ← ⊗ M Step 5 Apply threshold function Φ to A_M to get ie ← Φ ( A_M ) where Φ is defined as Φ (F) = G = g1 , g2, . . . . , gn Step 6 Output is the associated pattern pair end 41 Xi ¯ Yi ¯ Xi ¯ Yi ¯ X ¯ X2 ¯ X1 ¯ XN ¯ Xi ¯ x i 1 x i 2 x i n Y2 ¯ Y1 ¯ YN ¯ Yj ¯ x j 1 x j 2 x j n Y ¯ q ¯ Xi ¯ Xi ¯ Ā Ā B' ¯ B' ¯ B' ¯ qi ¯
- 42. R C C h a k r a b o r t y , w w w . m y r e a d e r s . i n f o SC – AM References 5. References : Textbooks 1. "Neural Network, Fuzzy Logic, and Genetic Algorithms - Synthesis and Applications", by S. Rajasekaran and G.A. Vijayalaksmi Pai, (2005), Prentice Hall, Chapter 4, page 87-116. 2. "Elements of Artificial Neural Networks", by Kishan Mehrotra, Chilukuri K. Mohan and Sanjay Ranka, (1996), MIT Press, Chapter 6, page 217-263. 3. "Fundamentals of Neural Networks: Architecture, Algorithms and Applications", by Laurene V. Fausett, (1993), Prentice Hall, Chapter 3, page 101-152. 4. "Neural Network Design", by Martin T. Hagan, Howard B. Demuth and Mark Hudson Beale, ( 1996) , PWS Publ. Company, Chapter 13, page 13-1 to 13-37. 5. "An Introduction to Neural Networks", by James A. Anderson, (1997), MIT Press, Chapter 6-7, page 143-208. 6. Related documents from open source, mainly internet. An exhaustive list is being prepared for inclusion at a later date. 42