Automatic generation of platform architectures using open cl and fpga roadmap
Download as ppt, pdf0 likes260 views

This document discusses using OpenCL to automatically generate platform architectures for FPGAs. It introduces FPGAs and their architecture, then discusses how OpenCL can be used as a hardware description language. The Silicon OpenCL (SOpenCL) tool flow is presented, which takes an unmodified OpenCL application and converts it into an FPGA system design with hardware and software components. Key steps in SOpenCL include code transformations, granularity management, and architectural synthesis to generate customized FPGA accelerators from OpenCL kernels. Monte Carlo simulations are provided as an example of an application that could exploit multiple levels of parallelism on FPGAs using this approach.













![18-19/7/2013 MATENVMED Plenary Meeting
OpenCL Simple Example
__kernel void vadd(
__global int* a,
__global int* b,
__global int* c) {
int idx= get_global_id(0);
c[idx] = a[idx] + b[idx];
}
• OpenCL kernel describes the computation of a work-
item
• Finest parallelism granularity
• e.g. add two integer vectors (N=1)
void add(int* a,
int* b,
int* c) {
for (int idx=0; idx<sizeof(a); idx++)
c[idx] = a[idx] + b[idx];
}
C code OpenCL kernel code
Run-time call
Used to differentiate execution
for each work-item
17](https://image.slidesharecdn.com/automaticgenerationofplatformarchitecturesusingopenclandfpgaroadmap-130727023227-phpapp01/85/Automatic-generation-of-platform-architectures-using-open-cl-and-fpga-roadmap-17-320.jpg)



![18-19/7/2013 MATENVMED Plenary Meeting
Serialization of Work Items
__kernel void vadd(…) {
int idx = get_global_id(0);
c[idx] = a[idx] + b[idx];
}
__kernel void Vadd(…) {
int idx;
for( i = 0; i < get_local_size(2); i++)
for( j = 0; j < get_local_size(1); j++)
for( k = 0; k < get_local_size(0); k++)
{
idx = get_item_gid(0);
c[idx] = a[idx] + b[idx];
}
}
OpenCL
code
C code
22
idx = (global_id2(0) + i) * Grid_Width * Grid_Height +
(global_id1(0) + j) * Grid_Width +
(global_id0(0) + k);](https://image.slidesharecdn.com/automaticgenerationofplatformarchitecturesusingopenclandfpgaroadmap-130727023227-phpapp01/85/Automatic-generation-of-platform-architectures-using-open-cl-and-fpga-roadmap-22-320.jpg)


































More Related Content
What's hot (20)
Viewers also liked (19)

















Similar to Automatic generation of platform architectures using open cl and fpga roadmap (20)




















Recently uploaded (20)




















Automatic generation of platform architectures using open cl and fpga roadmap
- 1. Automatic generation of platform architectures using OpenCL FPGA roadmap Department of Electrical and Computer Engineering University of Thessaly Volos, Greece Nikolaos Bellas
- 2. What is an FPGA? • Field Programmable Gate Array (FPGA) is the best known example of Reconfigurable Logic • Hardware can be modified post chip fabrication • Tailor the Hardware to the application – Fixed logic processors (CPUs/GPUs) only modify their software (via programming) • FPGAs can offer superior performance, performance/power, or performance/cost compared to CPUs and GPUs. 2
- 3. FPGA architecture • A generic island-style FPGA fabric • Configurable Logic Blocks (CLB) and Programmable Switch Matrices (PSM) • Bitstream configures functionality of each CLB and interconnection between logic blocks 3
- 4. The Xilinx Slice • Xilinx slice features – LUTs – MUXF5, MUXF6, MUXF7, MUXF8 (only the F5 and F6 MUX are shown in this diagram) – Carry Logic – MULT_ANDs – Sequential Elements •Detailed Structure
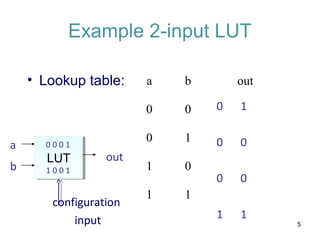
- 5. LUTLUT Example 2-input LUT • Lookup table: a b out 0 0 0 1 1 0 1 1 a b out 0 0 0 1 0 0 0 1 1 0 0 1 1 0 0 1 5 configuration input
- 6. Modern FPGA architecture Xilinx Virtex family 6 •Columns of on-chips SRAMs, hard IP cores (PPC 405), and •DSP slices (Multiply-Accumulate) units
- 7. FPGA discussion • Advantages – Potential for (near) optimal performance for a given application – Various forms of parallelisms can be exploited • Disadvantages – Programmable mainly at the hardware level using Hardware Description Languages (BUT, this can change) – Lower clock frequency (200-300 MHz) compared to CPUs (~ 3GHz) and GPUs (~1.5 GHz) 7
- 8. MATENVMED Silicon OpenCL: Automatic generation of platform architectures using OpenCL 8
- 9. 18-19/7/2013 MATENVMED Plenary Meeting Introduction • Automatic generation of hardware at the research forefront in the last 10 years. • Variety of High Level Programming Models: C/C++, C-like Languages, MATLAB • Obstacles: – Parallelism Extraction for larger applications – Extensive Compiler Transformations & Optimizations • Parallel Programming Models to the Rescue: – CUDA, OpenCL. 9
- 10. 18-19/7/2013 MATENVMED Plenary Meeting Motivation • Parallel programming models are for reconfigurable platforms. • A major shift of Computing industry toward many-core computing systems. • Reconfigurable fabrics bear a strong resemblance to many core systems. 10
- 11. 18-19/7/2013 MATENVMED Plenary Meeting Vision • Provide the tools and methodology to enable the large pool of software developers and domain experts, who do not necessarily have expertise on hardware design, to architect whole accelerator-based systems – Borrowed from advances in massively parallel programming models 11 FPGA PCIexpress GPU CPU PCIexpress
- 12. 18-19/7/2013 MATENVMED Plenary Meeting Silicon OpenCL • Silicon-OpenCL “SOpenCL”. • A tool flow to convert an unmodified OpenCL application into a SoC design with HW/SW components.
- 13. 18-19/7/2013 Contribution • Architectural Synthesis methodology: – Code Transformations. – Architectural Template. 13MATENVMED Plenary Meeting
- 14. 18-19/7/2013 MATENVMED Plenary Meeting OpenCL for Heterogeneous Systems • OpenCL (Open Computing Language) : A unified programming model aims at letting a programmer write a portable program once and deploy it on any heterogeneous system with CPUs and GPUs. • Became an important industry standard after release due to substantial industry support. 14
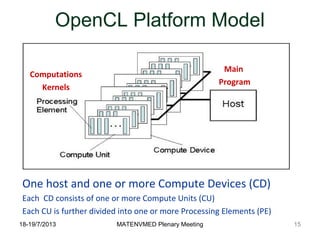
- 15. 18-19/7/2013 MATENVMED Plenary Meeting OpenCL Platform Model One host and one or more Compute Devices (CD) Each CD consists of one or more Compute Units (CU) Each CU is further divided into one or more Processing Elements (PE) 15 Main Program Computations Kernels
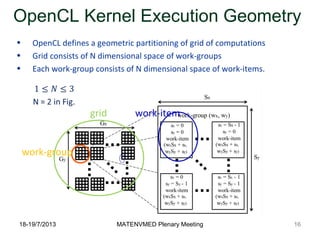
- 16. 18-19/7/2013 MATENVMED Plenary Meeting OpenCL Kernel Execution Geometry • OpenCL defines a geometric partitioning of grid of computations • Grid consists of N dimensional space of work-groups • Each work-group consists of N dimensional space of work-items. work-group grid work-item 16
- 17. 18-19/7/2013 MATENVMED Plenary Meeting OpenCL Simple Example __kernel void vadd( __global int* a, __global int* b, __global int* c) { int idx= get_global_id(0); c[idx] = a[idx] + b[idx]; } • OpenCL kernel describes the computation of a work- item • Finest parallelism granularity • e.g. add two integer vectors (N=1) void add(int* a, int* b, int* c) { for (int idx=0; idx<sizeof(a); idx++) c[idx] = a[idx] + b[idx]; } C code OpenCL kernel code Run-time call Used to differentiate execution for each work-item 17
- 18. 18-19/7/2013 MATENVMED Plenary Meeting Why OpenCL as an HDL? • OpenCL exposes parallelism at the finest granularity – Allows easy hardware generation at different levels of granularity – One accelerator per work-item, one accelerator per work- group, one accelerator per multiple work-groups, etc. • OpenCL exposes data communication – Critical to transfer and stage data across platforms • We target unmodified OpenCL to enable hardware design to software engineers – No need for hardware/architectural expertise 18
- 19. 18-19/7/2013 MATENVMED Plenary Meeting SOpenCL Tool Flow
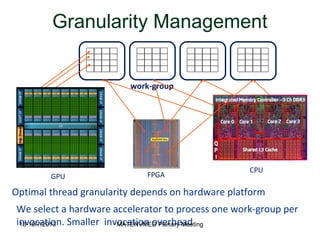
- 20. Granularity Management work-group FPGA Optimal thread granularity depends on hardware platform GPU CPU We select a hardware accelerator to process one work-group per invocation. Smaller invocation overhead18-19/7/2013 MATENVMED Plenary Meeting
- 21. 18-19/7/2013 MATENVMED Plenary Meeting Granularity Coarsening Work-item thread Work-group thread
- 22. 18-19/7/2013 MATENVMED Plenary Meeting Serialization of Work Items __kernel void vadd(…) { int idx = get_global_id(0); c[idx] = a[idx] + b[idx]; } __kernel void Vadd(…) { int idx; for( i = 0; i < get_local_size(2); i++) for( j = 0; j < get_local_size(1); j++) for( k = 0; k < get_local_size(0); k++) { idx = get_item_gid(0); c[idx] = a[idx] + b[idx]; } } OpenCL code C code 22 idx = (global_id2(0) + i) * Grid_Width * Grid_Height + (global_id1(0) + j) * Grid_Width + (global_id0(0) + k);
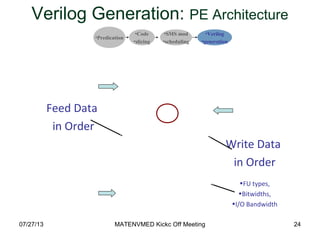
- 23. 18-19/7/2013 MATENVMED Plenary Meeting Architectural Synthesis • Exploit available parallelism and application specific features. • Apply a series of transformations to generate customized hardware accelerators. 23 • Uses LLVM Compiler Infrastructure. • Generate synthesizable Verilog & Test bench.
- 24. Feed Data in Order Write Data in Order •FU types, •Bitwidths, •I/O Bandwidth 2407/27/13 Verilog Generation: PE Architecture •Predication •Code •slicing •SMS mod •scheduling •Verilog •generation MATENVMED Kickc Off Meeting
- 26. FPGA Implementation • Our plan is to use the same code base (e.g. OpenCL) to explore different architectures – OpenCL used for multicore CPU, GPU, FPGA (SOpenCL) • Fast exploration based on area, performance and power requirements 18-19/7/2013 MATENVMED Plenary Meeting
- 27. FPGA Implementation • Monte-Carlo simulations can exploit multi-level parallelism of FPGAs – Multiple MC simulations per point – Multiple points simultaneously – Double precision Trigonometric, Log, Additions, Multiplications functions for each walk – FP operations with double precision are not FPGAs strong point, but still SOpenCL can handle it. 18-19/7/2013 MATENVMED Plenary Meeting
Editor's Notes
- #2: My thesis title is using a parallel programming model for architectural synthesis. I will talk about how we used a parallel programming model, particularly OpenCL programming model for architectural synthesis.
- #10: The problem of architectural synthesis commonly know as high level synthesis concerns the automatic generation of hardware accelerators systems from high level programming languages. There have been intensive research efforts in the last few years to extend (mainly) sequential programming languages like C/C++, etc. to serve as hardware description languages and replace the likes of Verilog/VHDL. Using sequential languages presents some formidable challenges like (without going into much details): Parallelism extraction which is extremely difficult in sequential languages like C. Previous researches proposed a variety of language extensions and compiler directives to help expose parallelism. Others used restricted set of C. On the other hand parallel programming models like CUDA and OpenCL provides semantics that expose parallelism and data movement, features necessary for successful architectural synthesis
- #11: So, there is an obvious lack of parallel programming models that could be used to describe an application and map it on reconfigurable platforms More important, The computing industry is moving toward many core computing systems with unified programming models. Parallel programming model are very suitable for reconfigurable platforms programming because of the strong resemblance between distributed logic cells of reconfigurable fabric and many core architectures.
- #12: Our vision is to exploit parallel programming models and develop tools and methodologies that enable software engineers and parallel programmers to build a complete system based on hardware accelerators without the need for hardware design expertise, with a language from their own domain without any changes or modifications.
- #13: The work of this research is developed as part of the Silicon OpenCL tool. Silicon OpenCL converts an unmodified OpenCL application into a system on chip with software and hardware Components. The tool flow converts an OpenCL kernel which represents the computational part in OpenCL applications into a hardware accelerator by first transforming the OpenCL kernel into an intermediate C function then the Hardware generation back end developed in this research converts the C function into RTL Verilog describing a hardware accelerator. The backend also generates Testbench for simulation and verification purposes.
- #14: In The hardware generation backend we propose a variety of Transformations and Optimizations. Most importantly Code Slicing and Code customization. We propose an architectural template that supports complex and imperfect loop nests. Moreover, the architectural template decouples and overlaps data movement and data computations as we will see shortly. Another important feature of the architecture template, is its support of asynchronous execution model to parallelize the execution multiple components in the accelerator.
- #15: OpenCL ( Open Computing Language ) presents a framework for writing programs that execute across heterogeneous platforms consisting of CPUs , GPUs , and other processors. OpenCL 1.0 out late 2008 Vision: write one portable application and execute in any processor or collection of processors. Strong industry support and drivers out for NVIDIA, Intel, AMD/ATI, IBM (Cell) chipsets etc.
- #16: OpenCL adapts a generic multicore computing model. The model of OpenCL consists of a host connected to one or more compute devices . A compute device is divided into one or more compute units (CUs) which are further divided into one or more processing elements (PEs). Computations on a device occur within the processing elements. In this platform model, an OpenCL application consists of a host program and computational kernels. The host program runs on the Host initialize compute devices and submits kernels for executions. A computational kernel executes on the processing elements.
- #17: When a kernel is submitted for execution by the host, a geometric grid encompassing all computations is defined. Grids consist of work-groups which further decomposed into work items, where a work item is the finest computation granularity and represents the work load of a single kernel. Work-groups are assigned a unique work-group ID, and each work item is assigned a unique ID within the work group. Combining the work group ID and the work item ID produces a unique global ID for each work item. work-item executes the same code but the specific execution pathway through the code and the data operated upon can vary per work-item. Work groups are independent and can run in parallel. The work-items in a given work-group execute concurrently on the compute elements of a single compute unit. It is important to know that it’s the responsibility of the programmer to define the geometry of the grid and work groups. Which means explicitly exposing the parallelism in the application.
- #18: Consider a simple example of OpenCL kernel code : add two vectors. Important point: OpenCL code describes the computation of a work-item The C code to the left is equivalent to the OpenCL code to the right. Only the code for one loop iteration is needed (in this case 1 loop iteration = 1 work-item) Notice that the specific data processed depends on the work-item global-id (found by a run-time library call) This is how work-items execute the same code base, but differentiate (at run-time) their dynamic execution path and data structures they process
- #19: The questions is: why would a developer use OpenCL as a hardware design language? 1) OpenCL expresses explicitly parallelism at the level of a work-item Multiple work-items can execute in parallel by default Easier to coarsen parallelism (e.g. at the work-group level) by selecting multiple work-items Therefore, the designer/compiler has freedom to select an accelerator at various levels of granularity: from a single work-item to a work-group to a grid. 2) Exposure of data communication facilitates data movement, staging between accelerators and memory hierarchies. Sequential languages lack semantics for all that. 3) The third reason is that using unmodified OpenCL we open up platform design to the larger pool of software engineers/design experts. No need for hardware/architectural expertise. Ride the wave of parallel programming.
- #20: So lets see how Silicon OpenCL do its Job
- #21: The first concern we have to deal with is the computations granularity we should assign to a hardware accelerator. On modern GPUs with hundred of light weight cores, a work item executes on a single core as a thread. A Chip Multiprocessor (e.g. from Intel) has fewer, more complex cores a thread executing in such a core may be a collection of work-items (may be a work-group) In the FPGA case, the jury is still out. In SOpenCL, we coarsen parallelism granularity by invoking an accelerator to execute a work-group. This reduces overhead per invocation. However, this is by no means the only answer to this problem. A lot of work in performance and area estimation is currently done to determine the best granularity for hardware accelerators for each application. The front end of Silicon OpenCL handles the task of coarsening the granularity of an OpenCL kernel and generating a C function represents the workload of a single work-group
- #23: The first step is logical thread serialization . Work-items inside a work-group can be executed in any sequence, provided that no synchronization operation is present inside a kernel function. Based on this observation, we serialize the execution of work-items by enclosing the instructions in the body of a kernel function into a triple nested loop , given that the maximum number of dimensions in the abstract index space within a workgroup is three. The nested loop we get has the following property: all iterations can execute in parallel and out of order.
- #24: The hardware generator uses LLVM (Low Level Virtual Machine), an open-source compiler infrastructure, to perform a series of optimizations and generate synthesizable Verilog (including the testbench). Note that the decoupling of front- and back-ends allows for Silicon OpenCL to tackle C code, and not only OpenCL. The following slides present the details of the back-end of the compiler
- #25: The PE architecture consists of a datapath executes the computation kernel, and a streaming unit that handle address generation for input and output streaming kernels. Also the streaming unit feeds data in order to the data path and write back data in order by allocating separate aligning units. The streaming unit allocates an optional cache that the tool allocates if it detects potentials for temporal and spatial locality. I want to emphasize that this is just a footprint according to which all accelerators are generated. The number, type, bitwidth of functional units are application dependent and are configurable.