Bank of China Tech Talk 2: Introduction to Streaming Data and Stream Processing with Apache Kafka
0 likes233 views

Watch the webcast here: https://videos.confluent.io/watch/yaWXJTKELvUGfPx9cnmhZ8 Speaker: Kenneth Cheung






















































































Ad
More Related Content
What's hot (20)
Similar to Bank of China Tech Talk 2: Introduction to Streaming Data and Stream Processing with Apache Kafka (20)


















Ad
More from confluent (20)




















Ad
Recently uploaded (20)




















Bank of China Tech Talk 2: Introduction to Streaming Data and Stream Processing with Apache Kafka
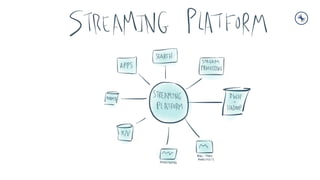
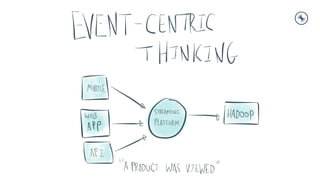
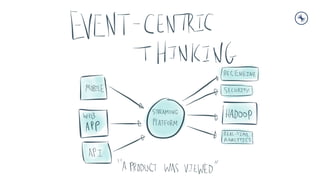
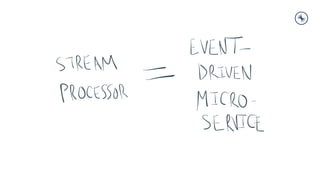
- 1. Tech Talk #2 Introduction to Streaming Data and Stream Processing with Apache Kafka Kenneth Cheung Sr. Solutions Engineer, Greater China Kenneth@confluent.io
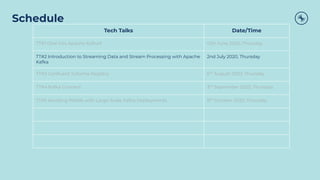
- 2. Schedule Tech Talks Date/Time TT#1 Dive into Apache Kafka® 12th June 2020, Thursday TT#2 Introduction to Streaming Data and Stream Processing with Apache Kafka 2nd July 2020, Thursday TT#3 Confluent Schema Registry 6th August 2020, Thursday TT#4 Kafka Connect 3rd September 2020, Thursday TT#5 Avoiding Pitfalls with Large-Scale Kafka Deployments 8th October 2020, Thursday
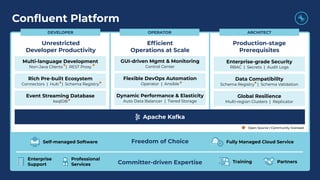
- 70. Confluent Platform Dynamic Performance & Elasticity Auto Data Balancer | Tiered Storage Flexible DevOps Automation Operator | Ansible GUI-driven Mgmt & Monitoring Control Center Efficient Operations at Scale Freedom of Choice Committer-driven Expertise Event Streaming Database ksqlDB Rich Pre-built Ecosystem Connectors | Hub | Schema Registry Multi-language Development Non-Java Clients | REST Proxy Global Resilience Multi-region Clusters | Replicator Data Compatibility Schema Registry | Schema Validation Enterprise-grade Security RBAC | Secrets | Audit Logs ARCHITECTOPERATORDEVELOPER Open Source | Community licensed Unrestricted Developer Productivity Production-stage Prerequisites Fully Managed Cloud ServiceSelf-managed Software Training Partners Enterprise Support Professional Services Apache Kafka
- 72. 72 • Apache Kafka Stream Processing Book Bundle • Online Talks • Confluent Platform Datasheet • Streaming Use Cases Financial Services https://events.confluent.io/confluentandbankofchinahktecht Confluent Resources
- 73. Interacting with Confluent 73 Join the Confluent Slack Channel https://launchpass.com/confluentcommunity Local meetups https://www.confluent.io/community/ KafkaSummit 2020 Aug 24 - 25 https://kafka-summit.org/
- 74. Project Metamorphosis Unveiling the next-gen event streaming platform Listen to replay and Sign up for updates cnfl.io/pm Jay Kreps Co-founder and CEO Confluent
- 75. Schedule Tech Talks Date/Time TT#1 Dive into Apache Kafka® 12th June 2020, Thursday TT#2 Introduction to Streaming Data and Stream Processing with Apache Kafka 2nd July 2020, Thursday TT#3 Confluent Schema Registry 6th August 2020, Thursday TT#4 Kafka Connect 3rd September 2020, Thursday TT#5 Avoiding Pitfalls with Large-Scale Kafka Deployments 8th October 2020, Thursday