Best practices and lessons learnt from Running Apache NiFi at Renault

No real-time insight without real-time data ingestion. No real-time data ingestion without NiFi ! Apache NiFi is an integrated platform for data flow management at entreprise level, enabling companies to securely acquire, process and analyze disparate sources of information (sensors, logs, files, etc) in real-time. NiFi helps data engineers accelerate the development of data flows thanks to its UI and a large number of powerful off-the-shelf processors. However, with great power comes great responsibilities. Behind the simplicity of NiFi, best practices must absolutely be respected in order to scale data flows in production & prevent sneaky situations. In this joint presentation, Hortonworks and Renault, a French car manufacturer, will present lessons learnt from real world projects using Apache NiFi. We will present NiFi design patterns to achieve high level performance and reliability at scale as well as the process to put in place around the technology for data flow governance. We will also show how these best practices can be implemented in practical use cases and scenarios. Speakers Kamelia Benchekroun, Data Lake Squad Lead, Renault Group Abdelkrim Hadjidj, Solution Engineer, Hortonworks
















![18
Reduce cloud communication cost by 50%
Tag Data Decoding with NiFi
ExecuteScript Processor
Raw Data out of sensor : ff1401aa
Decoded Data out of sensor : [{"data":{"battery":3.6007,"temperature":20}}]](https://image.slidesharecdn.com/bestpracticesandlessonslearntfromrunningnifiatrenault-180427230703/85/Best-practices-and-lessons-learnt-from-Running-Apache-NiFi-at-Renault-18-320.jpg)













![32
Let’s consider a simple data flow
Public class Project {
private int foo(int x) {
//do something with x -> y
return y;
}
public static void main(String [] args) {
//some code
try {
BufferedReader bufferRead = new
BufferedReader ...;
String data =bufferRead.readLine(
data = foo(data);
System.out.println(data);
} catch ...
}
}](https://image.slidesharecdn.com/bestpracticesandlessonslearntfromrunningnifiatrenault-180427230703/85/Best-practices-and-lessons-learnt-from-Running-Apache-NiFi-at-Renault-32-320.jpg)















































More Related Content
What's hot (20)
Similar to Best practices and lessons learnt from Running Apache NiFi at Renault (20)


















More from DataWorks Summit (20)



















Recently uploaded (20)




















Best practices and lessons learnt from Running Apache NiFi at Renault
- 1. Best practices and lessons learnt from Running NiFi at Renault Kamelia Benchekroun- Big Data Architect Renault Abdelkrim Hadjidj - Solution Engineer Hortonworks
- 2. 2 Agenda The NiFi journey at at Renault Best practices for running NiFi in production Lessons learnt at Renault Questions & answers
- 3. 3 The NiFi journey at Renault
- 4. 4 About Us Platform Design Deploy and Automate Capture and Analyze Raw Logs and Machine Data Improve Reliability Speed Operations Monitor and React Datalake Squad Activities The Datalake Squad: • A passionate Team who work really hard to deliver solutions and services and empower Data Initiatives at Renault Datalake Platform Metrics: 450 Connected Users 30 Data Initiatives and use cases 8000 Daily Queries 3500 Service Requests 300TB Efficient Storage
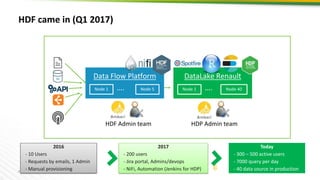
- 5. 5 Data Lake at Renault – the beginning of the story CFT HDP Admin team DataLake Renault Node 1 …. Node 16 June 2016 - 10 Users - Requests by emails, 1 Admin - Manual provisioning NFS-GWExports
- 7. 7 HDF came in (Q1 2017) Data Flow Platform Node 1 …. Node 5 HDF Admin team HDP Admin team DataLake Renault Node 1 …. Node 40 2016 - 10 Users - Requests by emails, 1 Admin - Manual provisioning 2017 - 200 users - Jira portal, Admins/devops - NiFi, Automation (Jenkins for HDP) Today - 300 – 500 active users - 7000 query per day - 40 data source in production
- 8. 8 Transit Zone RAW Zone DATA SOURCES Data Lake Data Engineers (DL)NIFI Other Zones Data Ingestion Process Data + Triggers HDFS / KAFKA Mail to admin if critical isssues Technical metrics to AMS Other Zones Other Zones
- 10. 10 Dev to prod testing /tmp/devp/${DESTINATION} S2S Dev Prod
- 11. 11 NiFi Value for Renault 90% of data ingestion since2016 One Platform for all data sources : Files, DBs, API, Brokers, etc. Offload CFT 100 active data flows, + 2000 processors in production,. Accelerate time to insights, use case development and improve monitoring and governance Also used export data from Data Lake to other systems/sites/Cloud Enables new use cases connected plants, package tracking, IoT
- 13. 13 Packaging Traceability POC: 2500 Packages running in the Loop – 1 package lost = 800 € (= IPhone) If the solution is generalized : 600k package 2016 Status – 400 K€ packaging re-investment due to packaging losses 2017 Status – 100 K€ cardboard in January Test Expectations: – Reduce cardboard costs and packaging losses – Test LoRa technology in an industrial context and Renault activities – Validate operational added Value of LoRa technology UMCD Pitesti Meca UVD Pitesti (Dacia) Bursa Nissan Sunderland NMUK Maubeuge (MCA) Cross dock (Hungaria) Nissan Barcelone NMISA Douai
- 14. 14 Example flow Pitesti -> Barcelona (full) – 3 transports/week – 1 truck each time – Lead Time : 6 days NMUK -> Pitesti (Empty) – once a week – 1 truck each time – Lead Time : 6 days – Cross Dock in Strančice (Tchek Rep.)
- 15. 15 Use case scope NETWORK & SECURITY SENSORS IOT PLATEFORME OBJECT VISUALISATION MÉTIER INTELLIGENCE IOT PLATEFORME DATA VISUALISATION Connect Collect Innovate Drive Analyse Objenious Manual Treatment 2017 Objenious Manual Treatment S1 2018 Renault IT (DLK + DFP) Objenious S2 2018 Renault IT (DLK + DFP + IS integration + Analytics) Telecom WTB Renault IT (DLK + DFP + IS integration + Analytics) Sensor Not in Scope of Objenious offer
- 16. 16 Renault Data Centers Access Control List or Certificates Architecture 1 Remote Process Group over Proxy POST HTTP LISTEN HTTP OUTPUT PORT (Passerelle)
- 17. 17 Renault Data Centers Architecture 2 Remote Process Group over Proxy OUTPUT PORT MQTT AMQP Websocket… POST HTTPs LISTEN HTTPs Or Any other Operator (Worldwide) (Passerelle) IOT Platform - Device management/provisioning - Network & Security
- 18. 18 Reduce cloud communication cost by 50% Tag Data Decoding with NiFi ExecuteScript Processor Raw Data out of sensor : ff1401aa Decoded Data out of sensor : [{"data":{"battery":3.6007,"temperature":20}}]
- 19. 19 Architecture + Cloud ingestion Data Flow Platform Node 1 …. Node 3 HDF Admin team HDP Admin team DataLake Renault Node 1 …. Node 40 Data Flow Platform Node 1 Node 2 S2S outbound
- 21. 21 Connected plants MiNiFi Source 1 Source 2 FTP MQTT Source 3 OPCUA Aggregation server Collect, processing, ingestion OPCUA JMS, Kafka, MQTT, WebSocket, * S2S (http, security, HA) HDFS, Hive, Solr, Hbase, etc JMS Other sources / protocols D A T A I N M O T I O N D A T A A T R E S T Facility Level Plant Level Corporate Level Governance &Integration Security Operations Data Access Data Management
- 22. 22 Overview of Plant Assembly Factory UC
- 23. 23 Sensors Full HDF use case (NiFi, Kafka and Storm)
- 24. 24 Connected plants Site To Site Demo with MQTTool from Hand to Data Lake ! Handy, MQTT Broker, NiFi ConsumeMQTT to Kafka, NIFI consume Kafka to ElasticSearch and Hive…
- 25. 25 Screwing tools valladolid data analysis
- 26. 26 Data Flow Platform Node 1 …. Node 3 HDF Admin team HDP Admin team DataLake Renault Node 1 …. Node 40 Data Flow Platform Node 1 Node 2 S2S outbound DFP Usine - ---------- HDF Flow Mgmt – X coeursN o d e 1 N o d e X …. DFP Usine - ---------- HDF Flow Mgmt – X coeursN o d e 1 N o d e X …. Data Flow Platform Node 1 Node 2 S2S Connected plants Architecture + Connected plants
- 27. 27 Best practices for running NiFi in production
- 29. 29 Typical NiFi Production Cluster Logical View
- 30. 30 Sizing considerations There are baselines for NiFi sizing but NiFi is like a “programming language” !! NiFi resources usage depends on used processors but it’s always IO intensive – Use different disks / volumes for the three repositories : flow file, content & provenance – For content repository, it’s recommended to have multiple mount points – For content and provenance repositories, SSD can provide the best performances – Heap sizing depends on the use case and used processors – Depending on the workload, we can scale vertically or horizontally Default settings are only for getting started. Tune based on your use case. – Thread pool size : Maximum Timer Driven Thread Count – Timeouts: nifi.cluster.node.connection/read.timeout, nifi.zookeeper.connect/session.timeout – Pluggable modules: WAL Provenance Repository
- 32. 32 Let’s consider a simple data flow Public class Project { private int foo(int x) { //do something with x -> y return y; } public static void main(String [] args) { //some code try { BufferedReader bufferRead = new BufferedReader ...; String data =bufferRead.readLine( data = foo(data); System.out.println(data); } catch ... } }
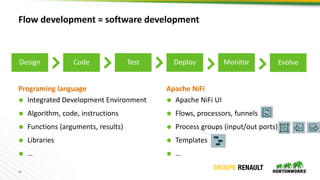
- 33. 33 Flow development = software development Integrated Development Environment Algorithm, code, instructions Functions (arguments, results) Libraries … Apache NiFi UI Flows, processors, funnels Process groups (input/out ports) Templates … Programing language Apache NiFi Design Code Test Deploy Monitor Evolve
- 34. 34 General guideline Use separate environments No flows at root level: use a PG per department, BL, project, etc Break your flow into process groups Use a naming convention, use comments (labels, comments) Use variable when possible Organize your projects into three PGs: ingestion, test & monitoring Performance, security and SLA Easy to secure, everything in NiFi is attached to a PG, heritage d Easy to test, update & version Very useful for development/monitoring. Ideally use unique names Promotion (dev > test > prod), update NiFi can generate data for TDD (Test Driven Dev), can collect/parse logs for BAM (Business App Monitoring) Principle Benefits
- 37. 37 Know & use NiFi Design Patterns Fan IN/OUT List & Fetch Attributes promotion Extract, Update Attribute Throttling ControlRate, expiration Funneling RPG, RouteOnAttribute Error loops Relations, Counters etc
- 38. 38 FDLC: Flow Development LifeCycle NiFi Cluster Node 1 Node x Tests cluster Registry .. NiFi Cluster Node 1 Node x Production cluster Registry .. NiFi Cluster Node 1 Node x Dev cluster Registry .. Dev Ops chain NiFi CLI, NipyAPI, Jenkins 1- push new flow version 2- get new version of the flow 3 & 6 - automated testing / promotion (naming convention, scheduling, variable replacement) 4- push new flow version 5- get new version of the flow 7- push new flow version
- 39. 39 Monitoring
- 40. 40 NiFi Monitoring Is NiFi service running correctly? Monitor global system metrics such as threads, JVM, disk, etc Monitor global flow metrics such as number of flow files sent, received or queued, processors stopped, etc Solutions – NiFi UI – Reporting tasks – Ambari – Grafana Are a particular flow running correctly? Monitor per application (flow, PG, processor) metrics such as number of flow files, data size, queues, back pressure, etc Solution – S2S Reporting tasks – Custom flow developments (integrate monitoring and reporting in the application logic) Service monitoring Applications (Flow) monitoring
- 41. 41 NiFi UI for service monitoring
- 42. 42 Tools available for service monitoring Bootstrap notifier: send notification when the NiFi starts, stops or died unexpectedly – Email/HTTP notification services Use reporting tasks: export metrics to your monitoring solution – AmbariReportingTask (global, process group) – MonitorDiskUsage (Flowfile, content, provenance repositories) – MonitorMemory Also, monitor inactivity – NiFi has a built-in MonitorActivity processor – To be used with the S2SBulletinReportingTask – You can use InvokeHTTP to call the reporting Rest API
- 43. 43 How to achieve granular monitoring? Integrate your monitoring logic in the flow design – Count data (lines, tables, events, etc) – Extract business metadata from data (table names, project name, source directory, etc) Handle different types of errors (connection, format, schema, etc) Send extracted KPI to brokers, dashboards, API, files, etc Monitoring Driven Development (MDD) NIFInception: NiFi can export metrics to to another cluster or to itself Bulletins provide information on errors Status provide metrics on usage These reports become data and we can use the power of NiFi to extract our KPI Naming convention is key S2S reporting tasks
- 44. 44 PutHDFS UpdateAttribute Monitoring Driven Development PutHiveQL PutElasticSearch UpdateAttribute … …
- 45. 45 NiFInception architecture NiFi Cluster Node 1 Node y Production cluster S2S Bulletins S2S Status Other applications Monitoring Alerting • Generate status and bulletins • Send them through S2S to a local input port • Ingest bulletin and status reports • Parse reports (JSON) and extract useful KPI • Send KPI to a dashboard tool (AMS, Elastic, etc) • Use a broker for alerting (Kafka) • Can ingest logs from other systems or application
- 46. 46 NiFInception architecture 2 NiFi Cluster Node 1 Node x Production cluster NiFi Cluster Node 1 Node y Monitoring cluster S2S Bulletins S2S Status Other applications Monitoring Alerting • Ingest data • Generate status and bulletins • Send them through S2S to a remote cluster • Ingest bulletin and status reports • Parse reports (JSON) and extract useful KPI • Send KPI to a dashboard tool (AMS, Elastic, etc) • Use a broker for alerting (Kafka) • Can ingest logs from other systems or application
- 48. 48 Recommendations from day to day life High availability means several weeks to validate before Go live Use Ranger authorizations instead of NIFI build in ACL management Too much « if then do else »: do the data flow and do not offload other processing solutions S2S : Minimize the number of RPG and self-RPG. Use attributes and routing. Put hive via Two redundant processors Discuss with DBA to better handle impacts (Views VS Tables, Open Sockets ..etc). Backup flowfile.xml.gz (users.xml et autorizations.xml) using NiFi itself.
- 49. 49 Recommendations from day to day life Success flag can be done trough counters instead of InvokHTTP In case of CIFS, do not forget to use AUTO MOUNT for NFS client side on NiFi Servers. Check ‘0’ size before transmitting into HDFS (especially for IoT use case). Configure a TIMER for when we use FAILURE redirections to avoid back-pressure scenario. Build separate clusters for separate use cases (Real Time with SSD, Batch, etc …) CA PKI very useful for internal communications, no need to wait Security teams answers but need security skills (SSL) .
- 50. 50 Questions
Editor's Notes
- #6: Only files and DB via Sqoop && CFT
- #8: MSG and API Ingestions, Use a dedicated servers and bandwith and separate from the compute, simplified FW rules, and better credentials administration, one point of monitoring…
- #9: Expliquer la Zone de Transit Cas le plus courant : ORC file
- #11: ${Destination} étant dans l’update attribut prévue avant le S2S. Bien que nos devellopeur aujourdhui l’utilisent tèrs rarement, les flux de capture étant réalisé par la SQUAD qui assure l’opérationel.
- #12: CDC actif avec NIFI pour une source MySQL, Etude en cours pour Oracle et DB2
- #31: if it’s foreseen to have millions of flow files being processed by NiFi at one point in time, the heap size should be adjusted accordingly. A common value is to set the heap size to 8GB and it is usually not recommended to exceed 16GB unless very specific processors are used requiring a lot of memory. Since there is no resource isolation in NiFi, it’s important not to set this value too high in order to ensure that sufficient resources are available for the operating system and the other running processes. It is usually recommended to set this value to 2 or 3 times the number of available cores on the NiFi host. Increasing the value to a higher number should only be performed if there is a need for it (NiFi UI shows that the maximum number of threads is constantly used), and if a strict monitoring of the host is performed to ensure correct CPU/load metrics. the "nifi.cluster.node.connection.timeout" and "nifi.cluster.node.read.timeout" properties in nifi.properties) are set to 5 seconds. This is fine for a "getting started" type of cluster. However, when processing large numbers of FlowFiles, the JVM's garbage collection can sometimes cause some fairly lengthy pauses. This could cause timeouts. It is recommended to increase that to 10-15 seconds or more. the "nifi.zookeeper.connect.timeout" and "nifi.zookeeper.session.timeout" default to 3 seconds, as this is what the ZooKeeper default is. However, in case ZooKeeper is very busy being used by multiple components it could create timeouts which would cause the Primary Node and Cluster Coordinator to change frequently. Changing the value to 10 seconds is recommended.
- #34: If you need to success in your NiFi projects, you really need to consider NiFi flow like software development Your code or your algorithm is a set of instructions just like your flows are a set of processor. You can have if else statments with routing processor, you can have for or while loops with update attributes, you can have catch statment with error relations When you build your flow you divide it into process groups like you use functions in your code. This make your applications easier to understand, maintain, and debug You can have templates for repetitive things like libraries that you build and use accross your projects
- #35: Controller services should be local within the Process Group, not in the root or parent process group. All Flows should be contained within a child process group For larger flows, develop several smaller flows that can be discretely tested, and then combine them into composites using input/output or S2S ports Use Variable Registry for attributes that vary between environments Updating only a part is useful for RT system where data flow continuosly
- #36: Manque Variable