


































































Ad
More Related Content
What's hot (20)
Viewers also liked (6)




Ad
Similar to BI Publisher 11g : Data Model Design document (20)




















Ad
Recently uploaded (20)




















BI Publisher 11g : Data Model Design document
- 1. Oracle BI Publisher Online Training www.adivaconsulting.com What is DataModel? Datamodel is BI Publisher Report Component, which contain a set of instructions to retrieve the structured data to generate BI Publisher Report. Data models reside as separate objects in the catalog. It extracts the data from single or multiple sources. It can transform the data during the Extraction process using Formula columns, Summary columns. To build a data model, you use the data model editor. Components of a Data Model • Data set A data set contains the logic to retrieve data from a single data source. A data set can retrieve data from a variety of data sources (for example, a database, an existing data file, a Web service call to another application, or a URL/URI to an external data provider). A data model can have multiple data sets from multiple sources. • Event triggers A trigger checks for an event. When the event occurs the trigger runs the PL/SQL code associated with it. The data model editor supports before data and after data triggers. Event triggers consist of a call to execute a set of functions defined in a PL/SQL package stored in an Oracle database. • Flexfields A flexfield is a structure specific to Oracle Applications. The data model editor supports retrieving data from flexfield structures defined in your Oracle Application database tables. • Lists of values A list of values is a menu of values from which report consumers can select parameter values to pass to the report. • Parameters
- 2. Oracle BI Publisher Online Training www.adivaconsulting.com A parameter is a variable whose value can be set at runtime. The data model editor supports several parameter types. • Bursting Definitions Bursting is a process of splitting data into blocks, generating documents for each data block, and delivering the documents to one or more destinations. A single bursting definition provides the instructions for splitting the report data, generating the document, and delivering the output to its specified destinations. Features of the Data Model Editor • Link data — Define master-detail links between data sets to build a hierarchical data model. • Aggregate data — Create group level totals and subtotals. • Transform data — Modify source data to conform to business terms and reporting requirements. • Create calculations — Compute data values that are required for your report that are not available in the underlying data sources. Data Source Options SQL queries submitted against Oracle BI Server, an Oracle database, or other supported databases Microsoft Excel spreadsheet data sources Multidimensional (MDX) queries against an OLAP data source Oracle BI Analyses Existing XML data files View objects created using Oracle Application Development Framework (ADF) HTTP XML feeds off the Web Web services
- 3. Oracle BI Publisher Online Training www.adivaconsulting.com Overview for Creating a Data Model The Data Model Editor is designed with a component pane on the left and work pane on the right. Selecting a component on the left pane launches the appropriate fields for the component in the work
- 4. Oracle BI Publisher Online Training www.adivaconsulting.com area. Data Model Properties Enter the following properties for the data model: Description: Description about the Data Model. Default Data Source — Select the data source from the list. Data models can include multiple data sets from one or more data sources. The default data source you select here is presented as the default for each new data set you define Oracle DB Default Package — If you define a query against an Oracle database, then you can include before or after data triggers (event triggers) in your data model. Event triggers make use of PL/SQL packages to execute RDBMS level functions. For data models that include event triggers or a PL/SQL group filter, you must enter a default PL/SQL package here. The package must exist on the default data source.
- 5. Oracle BI Publisher Online Training www.adivaconsulting.com Database Fetch Size — Sets the number of rows fetched at a time through the JDBC connection. Enable Scalable Mode — processing large data sets requires the use of large amounts of RAM. To prevent running out of memory, activate scalable mode for the data engine. In scalable mode, the data engine takes advantage of disk space when it processes the data. Backup Data Source — If you have set up a backup database for this data source, select Enable Backup Connection to enable the option; then select when you want BI Publisher to use the backup. XML Output Options These options define characteristics of the XML data structure. Note that any changes to these options can impact layouts that are built on the data model. • Include Parameter Tags — If you define parameters for your data model, select this box to include the parameter values in the XML output file • Include Empty Tags for Null Elements — Select this box to include elements with null values in your output XML data. • Include Group List Tag —Select this box to include the rowset tags in your output XML data. If you include the group list tags, then the group list appears as another hierarchy within your data. • XML Tag Display — Select whether to generate the XML data tags in upper case, in lower case, or to preserve the definition you supplied in the data structure. Attachments to the Data Model
- 6. Oracle BI Publisher Online Training www.adivaconsulting.com • Attaching Sample Data - The sample data is used by BI Publisher's layout editing tools. The Data Model Editor provides an option to generate and attach the sample data • Attaching Schema - The Data Model Editor enables you to attach sample schema to the data model definition. The schema file is not used by BI Publisher, but can be attached for developer reference. • Data Files - If you have uploaded a local Microsoft Excel file as a data source for this report, the file displays here Creating Data Sets 1.0 On the component pane of the data model editor click Data Sets
- 7. Oracle BI Publisher Online Training www.adivaconsulting.com Select the data set type from the list. For this exercise, select the “SQL Query” Data Set type.
- 8. Oracle BI Publisher Online Training www.adivaconsulting.com Provide the Name and Select the Data Source from the drop down list. The Data Sources are defiend through “Administration =>DataSource=>JDBC Connection” UI
- 9. Oracle BI Publisher Online Training www.adivaconsulting.com The SQL Query can by typed directly on SQL Query pane or it can be designed using Query Builder Tool. Click the “Query Builder” button to invoke the Query Builder Tool. Press the save button and we get the auto generated SQL query. The Query Builder Tool can be use to design simple and complex query but a experienced SQL query writer prefer to write query manually using SLQ PLUS, Toad or any other tool
- 10. Oracle BI Publisher Online Training www.adivaconsulting.com Press OK to save the data set. Save the data model by clicking the Save button. Select the proper folder and appropriate name for Data Model.
- 11. Oracle BI Publisher Online Training www.adivaconsulting.com Click on XML icon on top left panel and view and verify the Sample XML Data. It the Data Model is not saved, it will ask to save the Data Model first Click the Run button to view sample XML Data or Return button to back to Data Model designer. Check the following options from upper left corner Export XML : option allows to export the sample xml data to file System. Exported XML required by World Template Builder for RTF template design.
- 12. Oracle BI Publisher Online Training www.adivaconsulting.com Save As Sample Data : Option allows to save the Sample XML data within Data Model. This is mandatory step. It is required by Report Designer to create Report Definition. Get Data Engine Log : Option provide the Data Engine log for debugging purpose. The log level can be set through Enterprise Manager (em) console. Structuring Data Select the Data Sets from the Data Model Navigator. The left pane display with three tabs.
- 13. Oracle BI Publisher Online Training www.adivaconsulting.com Diagram : Diagram tab represent the visual representation and their relationship of Data Set Components. Structure : In Structure tab, there are two section. XML View and Business View. XML View drive the XML tags in XML output. We can update the XML tag with more meaning full name. Due to performance reason, it is recommended to have short XML tag name. The Sorting under XML View allow to set the Sorting order. ‘Value if Null’ allows to set the value if the column values is null in data source. The Business View allows setting the Tag description. As this description is use in Report Layout design, it is recommended to set the description relevant to business. Save the data model changes and review the XML Ouput. The XML Output reflects the changes you made for XML Structure. Export this XML to file system and save as Sample XML as well. We will use this XML for Report / Layout design.
- 14. Oracle BI Publisher Online Training www.adivaconsulting.com
- 15. Oracle BI Publisher Online Training www.adivaconsulting.com Code: The Code section display the actual Data Model code. The Data Model stored as XML in BI Publisher repository. This is read only and just for informative purpose.
- 16. Oracle BI Publisher Online Training www.adivaconsulting.com Adding Parameters and List of Values Adding parameters to data model allows user to filter the report data. BI Publisher supports following types of parameters. Text: Allows user to enter text string. Menu: User can select the values from a List of Values (LOV). The LOV can be bases on fixed values or based on SQL query that fetch the data against pre-defined data source. Date : User can pick the date as parameter from Date Picker (Calender). Select the Parameters node from the Data Model Navigator and click the + icon to create new parameter. Adding new Text Parameter. Add a parameter P_ORDER_ID to filter the Report based on Order ID. Select the Parameter type as Text. Set the Display Label, this will be display on Report Viewer and Scheduler Parameter UI. Test the new added parameter through Data Model viewer by clicking get XML icon.
- 17. Oracle BI Publisher Online Training www.adivaconsulting.com Adding new Date Parameter Add another parameter P_ORDER_DATE to filter Report Data based on Order Date. Select the Parameter type and data type as date. Leave the default date format to set as per your requirement. Date From and Date To can be set to restrict the date between 2 specific dates. Test the new date parameter through Data Model viewer
- 18. Oracle BI Publisher Online Training www.adivaconsulting.com Adding Menu type Parameter Parameter Menu type is based on List of Value. Before creating the lets create the List of Value. The LOV can be based on fixed data or based on SQL query. To define a SQL query based LOV, select the List of Values node from Data Model Navigator and click the + icon from right side pane. Set the name, select the type as SQL Query and select the data source where this query will execute. Either use the query builder to define query or write the query directly to SQL Query pane. In this example, first column ‘name’ is label and the second column id passed as value to underlying parameter.
- 19. Oracle BI Publisher Online Training www.adivaconsulting.com To define a fixed data based LOV, select the List of Values node from Data Model Navigator and click the + icon from right side pane. Set the name, select the type as Fixed Data. The Data Source will be null in this case. Add the new row by clicking + icon from the lower right fixed data section.
- 20. Oracle BI Publisher Online Training www.adivaconsulting.com To add a parameter as menu type, select the type as ‘Menu’ from drop down. Set the Display label and select the right LOV. Leave the other options value as default.
- 21. Oracle BI Publisher Online Training www.adivaconsulting.com Test the new menu parameter through Data Model viewer Set the parameter list of value as Customer_FIX_LOV and test it.
- 22. Oracle BI Publisher Online Training www.adivaconsulting.com At this point, you can select the parameters values but these parameters do not have any impact on data as we are not using these parameters in our query. Modify the SQL query to filter the data based on these parameters. Navigate to Orders data set in data model navigator and click the ‘Edit Data set’ Update the SQL query to include the Customer Name column and WHERE clause filter the data based on the parameters. Parameters P_ORDER_DATE, P_ORDER_ID and P_CUSTOMER set as bind variables in SQL query.
- 23. Oracle BI Publisher Online Training www.adivaconsulting.com Enter the Order ID and review the data and different parameter values and review the xml output.
- 24. Oracle BI Publisher Online Training www.adivaconsulting.com Working with Multiple Data Sets Make a copy of OrderDM as OrderDetailDM by Clicking the ‘Save As’ icon. Add a new SQL Data set using following SQL query for the Order Items data.
- 25. Oracle BI Publisher Online Training www.adivaconsulting.com Update the Group G1 => ORDERITEM from the structure tab. Navigate to structure tab and click the output section to view the XML Structure. There is no relationship between ORDERS and ORDERITEM Groups in XML. These are Multipart Unrelated Data Sets.
- 26. Oracle BI Publisher Online Training www.adivaconsulting.com In real time scenario, we often need a master detail or parent child relationship between two data sets. This relationship defined through data link between two data sets, where one dataset defined as master/parent and other as details/child data set and this is referred as Multipart Related Data Sets. There are two ways to define data link. Elements Level Link and Group Level Link Element Level Links: The element level link creates the join on columns of one query to column of other query. This is preferred option of defining the master details relationship. In this example, Orders is master and OrderItems is detail data set. Both are linked with OrderID. There are multiple Orders items for a given Order. Select click the >> icon on ORDER_ID element of ORDERS Dataset. This will open the action windows. Click on Create Link action, This will popup the Create Link box, select the ORDER_ID1 element from the list and click OK to complete the operation.
- 27. Oracle BI Publisher Online Training www.adivaconsulting.com This will create data link on OrderID column between Orders and OrderItems. Hover the mouse on icon to view the relationship. Navigate to structure tab and click the output section to view the XML Structure. The OrderItem appears one level down the Orders.
- 28. Oracle BI Publisher Online Training www.adivaconsulting.com View the sample XML to verify the master detail relationship. There are multiple ORDERITM nodes for one ORDER node.
- 29. Oracle BI Publisher Online Training www.adivaconsulting.com Creating Subgroups This is another way to regroup the data at higher level or add the required hierarchy to flat data. Look into sql query from Orders data set. It lists out the orders for the Customers. There is 1.M relationship between Customers and Orders. Lets add the higher group on Customer level but before this we need to add proper order by clause to sort the data on CUSTOMER_ID AND ORDER_ID.
- 30. Oracle BI Publisher Online Training www.adivaconsulting.com Select the ORDER data set from the Diagram pane and click the icon at CUSTOMER_ID element level. Click the Group by action link form the action popup. This will add a new Group with CUSTOMER_ID element at higher level. Click the icon at NAME element level, from the action menu, click on Move selected element to Parent Group.
- 31. Oracle BI Publisher Online Training www.adivaconsulting.com This moves the Customer Name to Customer Group. Update the Tag name from the Structure tab to make it more readable. Observe the new hierarchy. There three level. =>CUSTOMERS, == ORDER ====== ORDERITEM
- 32. Oracle BI Publisher Online Training www.adivaconsulting.com Generate the Sample XML and review the hierarchy in Browser. . Adding Group Filters Filters conditionally restrict the data from the XML output. BI Publisher data model supports two types of filters, Expression Filter and PL/SQL filters.. Expression Filter : It is an expression based on predefined function. A true value allows adding the group to output.
- 33. Oracle BI Publisher Online Training www.adivaconsulting.com Lets add a expression filter on ORDER group to include only those Orders which has order value >= 50000 Save the data model and view the Sample XML. It only include the Orders with order_total >= 50000. PL/SQL Filter: PL/SQL filter is the PL/SQL function , defined in Default PL/SQL package. Before using the function to define filter, we must specify the PL/SQL Package as the Oracle DB Default Package in the data model properties.
- 34. Oracle BI Publisher Online Training www.adivaconsulting.com Select the PL/SQL expression from the Filter dialog box and write the PL/SQL function in expression editor. Working with Functions Data Model provided 3 types of functions. Element-level functions, Group-level functions and Global-level functions Element level function: Element level functions are similar to row level function in SQL. These can be defined by adding expression using expression builder. Let’s add a new element at Order Items level to calculate the line amount total using following expression. Line amount can be calculated by multiplying quantity to Unit Price at Order Item level. Open the action menu from at data set level and click the ‘Add Element by Expression’ link and set the above expression. Set the name, alias and display name accordingly. To create an expression, we can write expression directly on expression pane or select the available element from the left side and press the icon to add the element in expression. Same way select the required operators from the Operators list available at the bottom of the expression builder. The expression builder also provide a set of built-in common function like MIN, MAX, AVG,SUM, ABS and many more. Click the icon to view and select these functions.
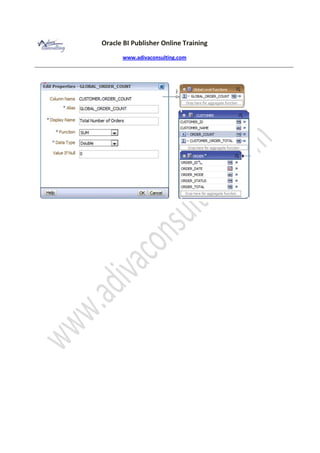
- 35. Oracle BI Publisher Online Training www.adivaconsulting.com Once complete the expression, validate the expression using Validate Expression button and make sure there is no syntax error. Save the data model and view the sample XML and make sure LINE_TOTAL element is there in ORFERITEMS XML node. Group level function: Als are also know as aggregate function. These are required to define summary functions like AVG, SUM, MIN, MAX which operates on a set of rows from child groups. In order to add aggregate function, select and drag the source Element from child group to parent group where we want to define the group function / summary function. Lets add group function NO_OF_ORDERS to CUSTOMER dataset. NO_OF_ORDERS is the total number of orders for a given customer and can be calculated by counting all the ORDER_ID for that customer. Drag the ORDER_ID element from ORDER group and drop to ‘Drop here for aggregate function’ section of CUSTOMER group. This creates a new Function Element CS_1 within CUSTOMER group.
- 36. Oracle BI Publisher Online Training www.adivaconsulting.com Click the icon from at CS_1 element. This lists out available aggregate functions. Select the Count function from the list. Click the icon from the same level and select the Properties from the action menu. Update the function properties. Pay attention on following 2 properties. Value If Null: update this property with a value which you want if the calculate value is null. Do Not Reset: by default, the aggregate element value reset to 0 for every new Customer. There are requirement, where we do not want to reset the aggregate element value, we check this check box. One of the examples is calculating running totals. Add another aggregate function CSUTOMER_ORDER_TOTAL. Follow the same steps and this time select Summary function from the available function list. Set the display name as Customer Order Total. The other property remains same as last time.
- 37. Oracle BI Publisher Online Training www.adivaconsulting.com Save the data model and review the sample XML for Customer ‘Meenakshi Mason’. These 2 new aggregate elements should appear under CUSTOMER node. Observe the position of aggregate elements. Aggregate elements always added at the end of the group. Global level function: Global level function is similar to Group level function except it defined at the outermost level. Let’s add TOTAL_ORDERS function at Global level. There are 2 ways to define this. We can use either ORDER.ORDER_ID as source and select the count function or CUSTOMER.ORDER_COUNT aggregate element to use the SUM function to achieve the same. Let’s try the second approach.
- 38. Oracle BI Publisher Online Training www.adivaconsulting.com