Big data 101 for beginners riga dev days
1 like•326 views

This document provides an overview and introduction to big data concepts for a new project in 2017. It discusses distributed systems theories like time ordering, latency, failure modes, and consensus protocols. It also covers data sharding and replication techniques. The document explains the CAP theorem and how it relates to consistency and availability. Finally, it discusses different distributed systems architectures like master/slave versus masterless designs.














































































Big data 101 for beginners riga dev days
- 1. BIG DATA 101, FOUNDATIONAL KNOWLEDGE FOR A NEW PROJECT IN 2017 @doanduyhai Technical Advocate @ Datastax Apache Zeppelin™ Committer @doanduyhai1
- 2. Who Am I ? Duy Hai DOAN Technical Advocate @ Datastax • talks, meetups, confs • open-source devs (Achilles, Zeppelin,…) • OSS Cassandra point of contact ☞ [email protected] ☞ @doanduyhai Apache Zeppelin™ committer @doanduyhai2
- 3. Agenda 1) Distributed systems theories & properties 2) Data sharding , replication 3) CAP theorem 4) Distributed systems architecture: master/slave vs masterless @doanduyhai3
- 5. Time There is no absolute time in theory (even with atomic clocks!) Time-drift is unavoidable • unless you provide atomic clock to each server • unless you’re Google NTP is your friend ☞ configure it properly ! @doanduyhai5
- 6. Ordering of operations How to order operations ? What does before/after mean ? • when clock is not 100% reliable • when operations occur on multiple machines … • … that live in multiple continents (1000s km distance) @doanduyhai6
- 7. Ordering of operations Local/relative ordering is possible Global ordering ? • either execute all operations on single machine (☞ master) • or ensure time is perfectly synchronized on all machines executing the operations (really feasible ?) @doanduyhai7
- 8. Known algorithms Lamport clock • algorithm for message sender • algorithm for message receiver • partial ordering between a pair of (sender, receiver) is possible @doanduyhai8 time = time+1; time_stamp = time; send(Message, time_stamp); (message, time_stamp) = receive(); time = max(time_stamp, time)+1;
- 10. Latency Def: time interval between request & response. Latency is composed of • network delay: router/switch delay + physical medium delay • OS delay (negligible) • time to process the query by the target (disk access, computation …) @doanduyhai10
- 11. Latency Speed of light physics • ≈ 300 000 km/s in the void • ≈ 197 000 km/s in fiber optic cable (due to refraction indice) London – New York bird flight distance ≈ 5500km è 28ms for a one way trip Conclusion: a ping between London – New York cannot take less than 56ms @doanduyhai11
- 12. @doanduyhai12 "The mean latency is below 10ms" Database vendor X ✔︎ ✘︎
- 13. @doanduyhai13 "The mean latency is below 10ms" Database vendor X ✔︎ ✘︎
- 14. Failure modes • Byzantine failure: same input, different outputs à application bug !!! • Performance failure: response correct but arrives too late • Omission failure: special case of performance failure, no response (timeout) • Crash failure: self-explanatory, server stops responding Byzantine failure à value issue Other failures à timing issue @doanduyhai14
- 15. Failure Root causes • Hardware: disk, CPU, … • Software: packet lost, process crash, OS crash … • Workload-specific: flushing huge file to SAN (🙀) • JVM-related: long GC pause Defining failure is hard @doanduyhai15
- 16. @doanduyhai16 "A server fails when it does not respond to one or multiple request(s) in a timely manner" Usual meaning of failure
- 17. Failure detection Timely manner ☞ timeout! Failure detector: • heart beat: binary state, (up/down), too simple • exponential backoff with threshold: better model • phi accrual detector: advanced model using statictics @doanduyhai17
- 18. Distributed consensus protocols Since time is unreliable, global ordering is hard to achieve & failure is hard to detect ... ... how different machines can agree on a single value ? Important properties: • validity: the agreed value must have been proposed by some process • termination: at least one non-faulty process eventually decides • agreement: all processes agree on the same value @doanduyhai18
- 19. Distributed consensus protocols 2-phases commit • termination KO: the protocol can be blocked if coordinator fails 3-phases commit • agreement KO: in case of network partition, possibility of inconsistent state Paxos, RAFT & Zab (Zookeeper) • OK: satisfies 3 requirements • QUORUM-based: requires a strict majority of copies/replicas to be alive @doanduyhai19
- 20. Data sharding & replication @doanduyhai20
- 21. Data Sharding Why sharding ? • scalability: map logical shard to physical hardware (machines/racks,...) • divide & conquer: each shard represents the DB at a smaller scale How to shard ? • user-defined algorithm: user chooses the sharding algorithm & the target columns on which applies the algorithm. • fixed algorithm: the DB imposes the sharding algorithm. The user decides only on which columns to apply the algorithm. Ex: user_id @doanduyhai21
- 22. Data Sharding Example of user-defined sharding • user data with sharding key == user_id, sharding algo == MD5 🙂 @doanduyhai22 18 24 17 19 22 0 5 10 15 20 25 30 0-19 20-39 40-59 60-79 80-99 Dataownershipin% Shards MD5 Data Distribution
- 23. Data Sharding Example of user-defined sharding • user data with sharding key == email, sharding algo == take 1st letter 😱 @doanduyhai23 19 32 27 15 5 2 0 5 10 15 20 25 30 35 a - c e - h m - p q - t u - x y - z Dataownershipin% Shards 1st letter Data Distribution
- 24. Data Sharding Example of fixed sharding algo Murmur3 • user data with sharding key == user_id or whatever key 😎 @doanduyhai24 19 23 18 19 21 0 5 10 15 20 25 0-19 20-39 40-59 60-79 80-99 Dataownershipin% Shards Murmur3 Data Distribution
- 25. @doanduyhai25 "With Murmur3 we are guaranteed to have even data distribution" ✔︎ ✘︎
- 26. @doanduyhai26 "With Murmur3 we are guaranteed to have even data distribution" ✔︎ ✘︎
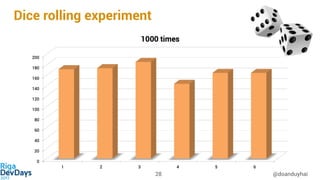
- 30. Dice rolling experiment @doanduyhai30 It’s all about statistics !
- 31. Data Sharding Trade-off Logical sharding (with ordering) • can lead to hotspots & imbalance in data distribution • but allows range queries • WHERE sharding_key >= xxx AND sharding_key <= yyy Hash-based sharding • guarantees uniform distribution (with sufficient distinct shard key values) • range queries not possible, only point queries • WHERE sharding_key >= xxx AND sharding_key <= yyy • WHERE sharding_key == zzz @doanduyhai31
- 32. Data Sharding and Rebalancing For some category of NoSQL solutions • range queries is mandatory à hotspots not avoidable !!! • mainly K/V databases, some wide columns databases too Rebalancy is necessary • sometimes automated process • sometimes manual admin process 😭 • resource-intensive operation (CPU, disk I/O + network) à impact live production traffic @doanduyhai32
- 33. Data Replication How ? By having multiple copies Type of replicas • symetric: no role, each replica is similar to others • asymetric: "master/slave" style. All operations (read/write) should go through a single server Replica definition • symetric: 1 replica == 1 copies. 3 replicas == 3 copies in total • asymetric: 1 replica == 1 slave copy. Total copies = master + replica(s) @doanduyhai33
- 34. Data Replication @doanduyhai34 Client Replica1 Replica2 Replica3 Symetric replicas, write operations Parallel dispatch
- 35. Data Replication @doanduyhai35 Client Replica1 Replica2 Replica3 Symetric replicas, read operations
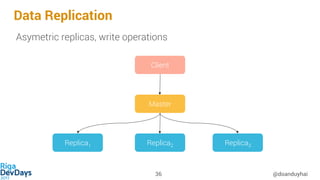
- 36. Data Replication @doanduyhai36 Master Replica1 Replica2 Replica3 Client Asymetric replicas, write operations
- 37. Data Replication @doanduyhai37 Master Replica1 Replica2 Replica3 Client Asymetric replicas, read operations
- 38. Data Replication @doanduyhai38 Master Replica1 Replica2 Replica3 Client Asymetric replicas, read operations BOTTLENECK !!!
- 39. Data Replication @doanduyhai39 Master Replica1 Replica2 Replica3 Client Asymetric replicas, read operations from slaves ✘
- 40. Data Replication @doanduyhai40 Master Replica Asymetric replicas, common write failure scenarios ✘ Message lost (network) àMaster never receives ack à KO Master Replica ✘ Write dropped (overload) àMaster never receives ack à KO Master Replica ✘ Replica crashed right away àMaster never receives ack à KO
- 41. Data Replication @doanduyhai41 Master Replica Asymetric replicas, tricky write failure scenarios ✘ Ack lost (network) àMaster never receives ack à KO !!!! Master Replica ✘ Replica crashes AFTER sending ACK but before flushing data to disk àMaster receives ack à OK ?
- 42. CAP Theorem @doanduyhai42 Pick 2 out of 3
- 43. CAP theorem @doanduyhai43 Conjecture by Brewer, formalized later in a paper (2002): The CAP theorem states that any networked shared-data system can have at most two of three desirable properties • consistency (C): equivalent to having a single up-to-date copy of the data • high availability (A): of that data (for updates) • and tolerance to network partitions (P)
- 45. CAP theorem revised (2012) @doanduyhai45 You cannot choose not to be partition-tolerance Choice is not that binary: • in the absence of partition, you can tend toward CA • if when partition occurs, choose your side (C or A) ☞ tunable consistency
- 46. What is Consistency ? @doanduyhai46 Meaning is different from the C of ACID Read Uncommited Read Commited Cursor Stability Repeatable Read Eventual Consistency Read Your Write Pipelined RAM Causal Snapshot Isolation Linearizability Serializability Without coordination Requires coordination
- 47. Consistency with some CP (supposedly) system @doanduyhai47 Some DB
- 48. Consistency with some AP system @doanduyhai48 Cassandra tunable consistency Read Uncommited Read Commited Cursor Stability Repeatable Read Eventual Consistency Read Your Write Pipelined RAM Causal Snapshot Isolation Linearizability Serializability Without coordination Requires coordination Consistency Level ONE
- 49. Consistency with some AP system @doanduyhai49 Cassandra tunable consistency Read Uncommited Read Commited Cursor Stability Repeatable Read Eventual Consistency Read Your Write Pipelined RAM Causal Snapshot Isolation Linearizability Serializability Without coordination Requires coordination Consistency Level QUORUM
- 50. Consistency with some AP system @doanduyhai50 Cassandra tunable consistency Read Uncommited Read Commited Cursor Stability Repeatable Read Eventual Consistency Read Your Write Pipelined RAM Causal Snapshot Isolation Linearizability Serializability Without coordination Requires coordination LightWeight Transaction Single partition writes are linearizable
- 51. What is availability ? @doanduyhai51 Ability to: • Read in the case of failure ? • Write in the case of failure ? Brewer definition: high availability of the data (for updates)
- 52. Real world example @doanduyhai52 Cassandra claims to be highly available, is it true ? Some marketing slide even claims continous availability (100% uptime), is it true ?
- 53. Network partition scenario with Cassandra @doanduyhai53 C* C* C* C* C*C* C* C* C* C* C* C* C* Read/Write at Consistency level ONE ✔︎
- 54. Network partition scenario with Cassandra @doanduyhai54 C* C* C* C* C*C* C* C* C* C* C* C* C* Read/Write at Consistency level ONE ✘︎
- 55. So how can it be highly available ??? @doanduyhai55 C* C* C* C* C*C* C* C* C* C* C* C* C* Read/Write at Consistency level ONE C* C* C* C* C*C* C* C* C* C* C* C* C* US DataCenter EU DataCenter ✘ Datacenter-aware load balancing strategy at driver level
- 57. Pure master/slave architecture @doanduyhai57 Single server for all writes, read can be done on master or any slave Advantages • operations can be serialized • easy to reason about • pre-aggregation is possible Drawbacks • cannot scale on write (read can be scaled) • single point of failure (SPOF)
- 58. Master/slave SPOF @doanduyhai58 Write request MASTER SLAVE1 SLAVE2 SLAVE3
- 59. Multi-master/slave layout @doanduyhai59 Write request MASTER1 SLAVE11 SLAVE12 SLAVE13 Shard1 MASTER2 SLAVE21 SLAVE22 SLAVE23 Shard2 … Proxy layer
- 60. @doanduyhai60 "Failure of a shard-master is not a problem because it takes less than 10ms to elect a slave into a master" Wrong Objection Rhetoric
- 61. The wrong objection rhetoric @doanduyhai61 How long does it take to detect that a shard-master has failed ? • heart-beat is not used because too simple • so usually after a timeout, after some successive retries Timeout is usually in tens of seconds • you cannot write during this time period
- 62. Multi-master/slave architecture @doanduyhai62 Distribute data between shards. One master per shard Advantages • operations can still be serialized in a single shard • easy to reason about in a single shard • no more big SPOF Drawbacks • consistent only in a single shard (unless global lock) • multiple small points of failure (SPOF inside a shard) • global pre-aggregation is no longer possible
- 63. Fake masterless/shared-nothing architecture @doanduyhai63 In reality, multi-master architecture … … but branded as shared-nothing/masterless architecture
- 66. As of May 2017 Official doc @doanduyhai66 Censored
- 67. As of May 2017 Technical overview doc @doanduyhai67
- 68. As of May 2017 Technical overview doc @doanduyhai68 Remember this ?
- 69. @doanduyhai69 Beware of marketing! Shared-nothing architecture Masterless architecture Primary-shard == hidden master
- 70. Masterless architecture @doanduyhai70 No master, every node has equal role ☞ how to manage consistency then if there is no master ? ☞ which replica has the right value of my data ? Some data-structures to the rescue: • vector clock • CRDT (Convergent Replicated Data Type)
- 71. Masterless architecture @doanduyhai71 C* C* C* C* C*C* C* C* C* C* Client sending request C* C* C* Notion of coordinator • just a network proxy ! • what if the coordinator dies ??? coordinator replica replica replica
- 72. Masterless architecture @doanduyhai72 C* C* C* C* C*C* C* C* C* C* Client sending request C* C* C* Anyone can be coordinator !!! new coordinator replica replica replica
- 73. CRDT @doanduyhai73 Riak • Registers • Counters • Sets • Maps • … Cassandra only proposes LWW-register (Last Write Win) • based on write timestamp
- 74. Timestamp, again … @doanduyhai74 But didn’t we say that timestamp not really reliable ? Why not implement pure CRDTs ? Why choose LWW-registered ? • because last-write-win is still the most "intuitive" • because conflict resolution with other CRDT is the user responsibility • because one should not be required to have a PhD in CS to use Cassandra
- 75. Example of write conflict with Cassandra @doanduyhai75 C* C* C* C* C*C* C* C* C* C* UPDATE users SET age=32 WHERE id=1 C* C* C* Local time 10:00:01.050 age=32 @ 10:00:01.050 age=32 @ 10:00:01.050 age=32 @ 10:00:01.050
- 76. Example of write conflict with Cassandra @doanduyhai76 C* C* C* C* C*C* C* C* C* C* UPDATE users SET age=33 WHERE id=1 C* C* C* Local time 10:00:01.020 age=32 @ 10:00:01.050 age=33 @ 10:00:01.020 age=32 @ 10:00:01.050 age=33 @ 10:00:01.020 age=32 @ 10:00:01.050 age=33 @ 10:00:01.020
- 77. Example of write conflict with Cassandra @doanduyhai77 C* C* C* C* C*C* C* C* C* C* UPDATE users SET age=33 WHERE id=1 C* C* C* Local time 10:00:01.020 age=32 @ 10:00:01.050 age=33 @ 10:00:01.020 age=32 @ 10:00:01.050 age=33 @ 10:00:01.020 age=32 @ 10:00:01.050 age=33 @ 10:00:01.020
- 78. Example of write conflict @doanduyhai78 How can we cope with this ? • It’s functionally rare to have a update on the same column by differents clients at atmost same time (few millisecs apart) • can also force timestamp at client-side (but need to synchronize clients now …) • can always use LightWeight Transaction to guarantee linearizability UPDATE user SET age = 33 WHERE id = 1 IF age = 32
- 79. Masterless architecture @doanduyhai79 Advantages • no SPOF • no failover procedure • can achieve 0 downtime with correct tuning Drawbacks • hard to reason about • require some knowledge about distributed systems • pre-aggregation possible