Big Data Analytics
Download as PPTX, PDF51 likes37,819 views

Slide from general lecturing "Big Data Analytics: Engage with Your Customer" at Muhammadiyah Jakarta University
![[BIG] DATA ANALYTICS
ENGAGE WITH YOUR CUSTOMER
PREPARED BY GHULAM I](https://image.slidesharecdn.com/bigdataanalytics-160222125954/85/Big-Data-Analytics-1-320.jpg)

![WHAT’S IN THIS SLIDE
[BIG] DATA ANALYTICS
Intro & Data Trends
Challenges
Tech Approach
Big Data Tools
Type of Analytics
Tools
Analytics Lifecycle
Use Cases (Sentiment Analysis)
What’s Trending
Where to Start
Methodology](https://image.slidesharecdn.com/bigdataanalytics-160222125954/85/Big-Data-Analytics-3-320.jpg)

![DATA VS BIG DATA
Big data is just data with:
More volume
Faster data generation (velocity)
Multiple data format (variety)
World's data volume to grow 40% per year
& 50 times by 2020 [1]
Data coming from various human & machine
activity
[1] http://e27.co/worlds-data-volume-to-grow-40-per-year-50-times-by-2020-aureus-20150115-2/](https://image.slidesharecdn.com/bigdataanalytics-160222125954/85/Big-Data-Analytics-5-320.jpg)






























![DATA EXPLORATION
Finding top words
tweets.select("text").rdd.
flatMap(x => x(0).toString.toLowerCase.
split(“[^A-Za-z0-9]+")).
map(x => (x,1)).
filter(x => x._1.length >= 3).
reduceByKey(_+_).
map(_.swap).
sortByKey(false).
map(_.swap).
take(20).foreach(println)](https://image.slidesharecdn.com/bigdataanalytics-160222125954/85/Big-Data-Analytics-37-320.jpg)
![DATA EXPLORATION
Finding top words with stop word exclusion
val stop_words = sc.textFile("/user/ghulam/stopwords.txt")
val bc_stop = sc.broadcast(stop_words.collect)
tweets.select("text").rdd.
flatMap(x => x(0).toString.toLowerCase.split("[^A-Za-z0-9]+")).
map(x => (x,1)).
filter(x => x._1.length > 3 & !bc_stop.value.contains(x._1)).
reduceByKey(_+_).
map(_.swap).sortByKey(false).map(_.swap).
take(20).foreach(println)](https://image.slidesharecdn.com/bigdataanalytics-160222125954/85/Big-Data-Analytics-38-320.jpg)
![DATA EXPLORATION
Words Chain (Market Basket Analysis)
import org.apache.spark.mllib.fpm.FPGrowth
val stop_words = sc.broadcast(sc.textFile("/user/hadoop-
user/ghulam/stopwords.txt").collect)
val tweets = sqlContext.jsonFile("/user/flume/tweets/2015/09/01/*/*")
val trx = tweets.select("text").rdd.
filter(!_(0).toString.toLowerCase.contains("ini 20 finalis aplikasi")).
filter(!_(0).toString.toLowerCase.contains("telkomsel jaring 20 devel")).
filter(!_(0).toString.toLowerCase.contains("[jual")).
filter(!_(0).toString.toLowerCase.contains("lelang acc")).
filter(!_(0).toString.toLowerCase.matches(".*theme.*line.*")).
filter(!_(0).toString.toLowerCase.matches(".*fol.*back.*")).
filter(!_(0).toString.toLowerCase.matches(".*favorite.*digital.*")).
filter(!_(0).toString.toLowerCase.startsWith("rt @")).
map(x => x(0).toString.toLowerCase.split("[^A-Za-z0-9]+").filter(x =>
x.length > 3 & !stop_words.value.contains(x)).distinct)
val fpg = new FPGrowth().setMinSupport(0.01).setNumPartitions(10)
val model = fpg.run(trx)
model.freqItemsets.filter(x => x.items.length >= 3).take(20).foreach {
itemset =>
println(itemset.items.mkString("[", ",", "]") + ", " + itemset.freq)
}](https://image.slidesharecdn.com/bigdataanalytics-160222125954/85/Big-Data-Analytics-39-320.jpg)









![[BIG] DATA SOURCES
Social media platform. Most of social media provided some API to
fetch the data from there. Twitter and Facebook is the most common
example
KDNuggets (http://www.kdnuggets.com/datasets/index.html)
Kaggle (https://www.kaggle.com/)
Portal Data Indonesia (http://data.go.id/)
Your WhatsApp group conversation](https://image.slidesharecdn.com/bigdataanalytics-160222125954/85/Big-Data-Analytics-49-320.jpg)

































Ad
More Related Content
What's hot (20)
Similar to Big Data Analytics (20)


















Ad
Recently uploaded (20)




















Ad
Big Data Analytics
- 1. [BIG] DATA ANALYTICS ENGAGE WITH YOUR CUSTOMER PREPARED BY GHULAM I
- 2. ABOUT ME Currently work in Telkomsel as senior data analyst 8 years professional experience with 4 years in big data and predictive analytics field in telecommunication industry Bachelor from Computer Science, Gadjah Mada University & get master degree from Magister of Information Technology, Universitas Indonesia Lecturer in Muhammadiyah Jakarta University https://id.linkedin.com/pub/ghulam-imaduddin/32/a21/507 [email protected]
- 3. WHAT’S IN THIS SLIDE [BIG] DATA ANALYTICS Intro & Data Trends Challenges Tech Approach Big Data Tools Type of Analytics Tools Analytics Lifecycle Use Cases (Sentiment Analysis) What’s Trending Where to Start Methodology
- 4. THE WORLD OF DATA Source: http://www.cision.com/us/2012/10/big-data-and-big-analytics/
- 5. DATA VS BIG DATA Big data is just data with: More volume Faster data generation (velocity) Multiple data format (variety) World's data volume to grow 40% per year & 50 times by 2020 [1] Data coming from various human & machine activity [1] http://e27.co/worlds-data-volume-to-grow-40-per-year-50-times-by-2020-aureus-20150115-2/
- 6. CHALLENGES More data = more storage space More storage = more money to spend (RDBMS server needs very costly storage) Data coming faster Speed up data processing or we’ll have backlog Needs to handle various data structure How do we put JSON data format in standard RDBMS? Hey, we also have XML format from other sources Other system give us compressed data in gzip format Agile business requirement. On initial discussion, they only need 10 information, now they ask for 25? Can we do that? We only put that 10 in our database Our standard ETL process can’t handle this
- 7. STORAGE COST In Terms of storage cost, Hadoop has lower comparing to standard RDBMS. Hadoop provides highly scalable storage and process with fraction of the EDW Cost
- 8. STORAGE & COMPUTE TOGETHER The Hadoop WayThe Old Way • Hard to scale • Network is a bottleneck • Only handles relational data • Difficult to add new fields & data types Expensive, Special purpose, “Reliable” Servers Expensive Licensed Software Network Data Storage (SAN, NAS) Compute (RDBMS, EDW) • Scales out forever • No bottlenecks • Easy to ingest any data • Agile data access Commodity “Unreliable” Servers Hybrid Open Source Software Compute (CPU) Memory Storage (Disk) z z Source: Cloudera Presentation Deck by Amr Awadallah
- 9. MAP REDUCE APPROACH Process data in parallel way using distributed algorithm on a cluster Map procedure performs filtering and sorting data locally Reduce procedure performs a summary operation (count, sum, average, etc.)
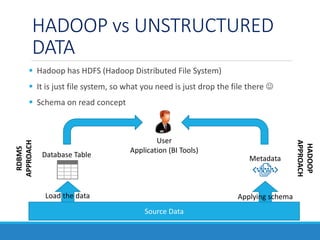
- 10. HADOOP vs UNSTRUCTURED DATA Hadoop has HDFS (Hadoop Distributed File System) It is just file system, so what you need is just drop the file there Schema on read concept Source Data Database Table Load the data Metadata Applying schema User Application (BI Tools) RDBMS APPROACH HADOOP APPROACH
- 11. HIVE The Apache Hive ™ data warehouse software facilitates querying and managing large datasets residing in distributed storage. With Hive you can write the schema for the data in HDFS Hive provide many library that enable you to read various data type like XML, JSON, or even compressed format You can create your own data parser with Java language Hive support SQL language to read from your data Hive will convert your SQL into Java MapReduce code, and run it in cluster
- 12. Apache spark is fast and general engine for large-scale data processing Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk You can write spark application in Java, Scala, Python, or R Spark support library to run SQL, streaming, and complex analysis like graph computation and machine learning https://spark.apache.org/
- 13. ANALYTICS
- 14. ANALYTICS IS IN YOUR BLOOD Do you realize that you do analytics everyday? I need to go to campus faster! Hmm.. Looking at the sky today, I think it’ll be rain Based on my mid term and assignment score, I need to get at least 80 in my final exam to pass this course I stalked her social media. I think she is single because most of her post only about food :p
- 15. DESCRIPTIVE & PREDICTIVE Descriptive statistics is the term given to the analysis of data that helps describe, show or summarize data in a meaningful way such that, for example, patterns might emerge from the data. In Information System Design course, most of the student get C grade (11 people). There is 4 people get A, 7 get B, 7 get D, and 7 get E Fulan only post his activity on Facebook at weekend Predictive analytics is the branch of data mining concerned with the prediction of future probabilities and trends. The central element of predictive analytics is the predictor, a variable that can be measured for an individual or other entity to predict future behavior. Fulan should be has a job. Because he always left home at 7 in the morning and get back at 6 afternoon
- 16. PREDICTIVE ANALYTICS There is 2 types of predictive analytics: ◦ Supervised Supervised analytics is when we know the truth about something in the past Example: we have historical weather data. The temperature, humidity, cloud density and weather type (rain, cloudy, or sunny). Then we can predict today weather based on temp, humidity, and cloud density today Machine learning to be used: Regression, decision tree, SVM, ANN, etc. ◦ Unsupervised Unsupervised is when we don’t know the truth about something in the past. The result is segment that we need to interpret Example: We want to do segmentation over the student based on the historical exam score, attendance, and late history
- 17. APPLYING THE CONTEXTSource Raw&unstructured Location Socmed data, Complaint, Survey URL access CDRDevice info IMEI & TAC Point Of Interest, sentiment library, socmed buzzer, website category ContextDerived Information Commute pattern Hangout location Idols Political view Pain point Community leader Family member Communication spending
- 18. ANALYTICS LIFECYCLE - Defining target variable - Splitting data for training and validating the model - Defining analysis time frame for training and validation - Correlation analysis and variable selection - Selecting right data mining algorithm - Do validation by measuring accuracy, sensitivity, and model lift - Data mining and modeling is an iterative process Data Mining & Modeling - Define variables to support hypothesis - Cleaning & transforming the data - Create longitudinal data/trend data - Ingesting additional data if needed - Build analytical data mart - Gathering problem information - Defining the goal to solve the problem - Defining expected output - Defining hypothesis - Defining analysis methodology - Measuring the business value Data Understanding Business Understanding
- 19. ANALYTICS LIFECYCLE - Create monitoring process for model evaluation - Evaluate the model based on real-world result - Monitor and evaluate the business impact Model Monitoring - Define the model scoring period - Integrate model result with execution system (campaign system, CRM, etc) - Create operational process that timely, consistent, and efficient Model Operationalization - Describe the importance of each variable - Visualize overall model by creating decision tree for example - Define business action based on the model result Model Interpretation Analytics and modeling is an iterative process. Data model will become obsolete and need to evolve to accommodate changes in behavior
- 20. BUILDING THE METHODOLOGY Analysis Domain • What is the analysis domain? Is it for male only? Is it for housewife or worker? Your “customer” segment has different behavior Type of Analysis • Do we need only descriptive analysis? Or we need to go with predictive analysis? Supervised or Unsupervised? • Do we need to build unsupervised clustering/segmentation for this analysis? Define Analysis Time Window • What time window of data we need for behavior observation? • What is the prediction time window? • Is there any seasonal event on that time window?
- 21. ANALYTICS TOOLS Microsoft Excel. Very powerful tools to do statistical data manipulation, pivoting, even doing simple prediction SQL is just the language. Your data lying in database? SQL will help to filter, aggregate and extract your data RapidMiner provide built-in RDBMS connector, parser for common data format (csv, xml), data manipulation, and many machine learning algorithm. We can also create our own library. Latest version of RapidMiner can connect to Hadoop and do more complex analysis like text mining. Free version is available (community edition) KNIME. Known as a powerful tools to do predictive analytics. Overall function is similar to RapidMiner. Latest version of KNIME can connect to Hadoop and do more complex analysis such as text mining. Free version is available Tableau is one of the famous tools to build visualization on top of the data. Tableau also powerful to create interactive dashboard. Free version is available with some limitation QlikView. Similar to Tableau, QlikView designed to enable data analyst to develop a dashboard or just simple visualization on top of the data. Free version is available
- 22. SAMPLE USE CASE #1 SENTIMENT ANALYSIS ON TWITTER DATA
- 23. BACKGROUND Objective Measuring customer sentiment over big tree telecommunication provider in Indonesia (Telkomsel, XL, Indosat) Metric Measuring NPS (Net Promotor Score) for each operator using twitter data. NPS calculated as percentage of positive tweets minus percentage of negative tweets. Putra, B. P. (2015). Analisis Sentimen Layanan Telekomunikasi pada Pengguna Media Sosial Twitter. Jakarta: Universitas Indonesia
- 24. WORKFLOW - Generate word vector using machine learning algorithm based on training dataset - Using SVM and C4.5 - The result is 2 different model - Select the best model by comparing the accuracy Data Modeling - Deduplication - Convert to lower case - Tokenization - Filter stop word Data Preparation - Label some sample for training dataset - This part done with crowdsourcing Data Labeling - Create twitter crawler with python and twitter API - Run the crawler with selected keyword, parse, and store to RDBMS - Collection for tweet generated in April 2015 Data Collection
- 25. WORKFLOW - Aggregate scoring result by telco provider to get count of positive tweets and negative tweets - Calculate the NPS for each telco provider - Visualize the result as a bar chart NPS Calculation - Using best model, score the rest dataset - Scoring result is a label (positive/negative/ neutral) for each tweet Data Scoring
- 26. DATA COLLECTION We run the crawler 3 times, one time for each operator. We only search tweets containing some keywords Parse the json result using json parser library embedded in python 2.7, form it as CSV (comma separated value) Load the csv into database (we use MySQL in this experiment) • Telepon • SMS • Internet • Jaringan • Telkomsel • Indosat • XL
- 27. DATA LABELING The objective is to build the ground truth Using crowdsourcing approach. We build online questionnaire and ask people to define each tweets if it is negative, positive, or neutral We label 100 tweets by ourselves as a validated tweets for questionnaire validation We put 20 tweets for each questionnaire. 5 tweets for Indosat, 5 for XL, 5 for Telkomsel, and the rest 5 is random validated tweets If 4 out of 5 validated tweets answered correctly, then we flag a questionnaire as a valid questionnaire This approach used to eliminate the answer submitted by people who do it randomly
- 28. DATA PREPARATION Deduplication process is to remove duplicated tweets Tokenization is a process to split a sentence into words. This should be done because the model will generate the word vector instead of sentence.
- 29. DATA PREPARATION Filtering stop words. We eliminate non useful word (word that doesn’t reflect to positive or negative means)
- 30. TOOLS USED Data preparation modeling done with RapidMiner software RapidMiner has text analysis function and procedure. We can found procedure to do tokenize, convert case, deduplication, and filter stop word RapidMiner also has SVM and C4.5 algorithm to do modeling
- 31. MODEL ACCURACY Model accuracy measurement done by confusion matrix In this experiment, we found that SVM performs better than C4.5 𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = (𝑇𝑃 + 𝑇𝑁) (𝑇𝑃 + 𝐹𝑃 + 𝑇𝑁 + 𝐹𝑁)
- 32. NPS Result After we do aggregation for scored dataset, we found that Indosat has higher NPS than the others. Telco % Promoters % Detractors NPS Indosat 37% 14% 23% Telkomsel 30% 27% 3% XL 19% 37% -18%
- 33. SAMPLE USE CASE #2 SIMPLE DESCRIPTIVE ANALYTICS USING HADOOP AND SPARK
- 34. BACKGROUND This is the demonstration how to use Apache Spark to extract some information from twitter data Twitter data collected with some crawler made with python language, and store as it is (JSON formatted data)
- 35. DATA EXPLORATION Load JSON data to memory val tweets = sqlContext.jsonFile("/user/flume/tweets/2015/09/01/*/*") Looking the data schema, and select useful field only tweets.printSchema
- 36. DATA EXPLORATION Finding top 10 users based on tweet count tweets. select("user.screen_name"). rdd.map(x => (x(0).toString,1)). reduceByKey(_+_). map(_.swap). sortByKey(false). map(_.swap). take(10). foreach(println)
- 37. DATA EXPLORATION Finding top words tweets.select("text").rdd. flatMap(x => x(0).toString.toLowerCase. split(“[^A-Za-z0-9]+")). map(x => (x,1)). filter(x => x._1.length >= 3). reduceByKey(_+_). map(_.swap). sortByKey(false). map(_.swap). take(20).foreach(println)
- 38. DATA EXPLORATION Finding top words with stop word exclusion val stop_words = sc.textFile("/user/ghulam/stopwords.txt") val bc_stop = sc.broadcast(stop_words.collect) tweets.select("text").rdd. flatMap(x => x(0).toString.toLowerCase.split("[^A-Za-z0-9]+")). map(x => (x,1)). filter(x => x._1.length > 3 & !bc_stop.value.contains(x._1)). reduceByKey(_+_). map(_.swap).sortByKey(false).map(_.swap). take(20).foreach(println)
- 39. DATA EXPLORATION Words Chain (Market Basket Analysis) import org.apache.spark.mllib.fpm.FPGrowth val stop_words = sc.broadcast(sc.textFile("/user/hadoop- user/ghulam/stopwords.txt").collect) val tweets = sqlContext.jsonFile("/user/flume/tweets/2015/09/01/*/*") val trx = tweets.select("text").rdd. filter(!_(0).toString.toLowerCase.contains("ini 20 finalis aplikasi")). filter(!_(0).toString.toLowerCase.contains("telkomsel jaring 20 devel")). filter(!_(0).toString.toLowerCase.contains("[jual")). filter(!_(0).toString.toLowerCase.contains("lelang acc")). filter(!_(0).toString.toLowerCase.matches(".*theme.*line.*")). filter(!_(0).toString.toLowerCase.matches(".*fol.*back.*")). filter(!_(0).toString.toLowerCase.matches(".*favorite.*digital.*")). filter(!_(0).toString.toLowerCase.startsWith("rt @")). map(x => x(0).toString.toLowerCase.split("[^A-Za-z0-9]+").filter(x => x.length > 3 & !stop_words.value.contains(x)).distinct) val fpg = new FPGrowth().setMinSupport(0.01).setNumPartitions(10) val model = fpg.run(trx) model.freqItemsets.filter(x => x.items.length >= 3).take(20).foreach { itemset => println(itemset.items.mkString("[", ",", "]") + ", " + itemset.freq) }
- 40. WORLD TRENDS
- 41. 2015 HYPE CYCLE Big data related things in top of hype curve: • Advanced analytics • IoT • Machine Learning
- 42. DATA SCIENTIST Data scientist/analyst is one of the sexy and emerging job in the market
- 45. WHERE TO START LETS GET OUR HAND DIRTY
- 47. SKILLS NEEDED Business Acumen In terms of data science, being able to discern which problems are important to solve for the business is critical, in addition to identifying new ways the business should be leveraging its data. Python, Scala, and SQL SQL skills is a must! Python and Scala also become a common language to do data processing, along with Java, Perl, or C/C++ Hadoop Platform It is heavily preferred in many cases. Having experience with Hive or Pig is also a strong selling point. Familiarity with cloud tools such as Amazon S3 can also be beneficial. SAS or R or other predictive analytics tools In-depth knowledge of at least one of these analytical tools, for data science R is generally preferred. Along with this, statistical knowledge also important
- 48. SKILLS NEEDED Intellectual curiosity Curiosity to dig deeper into data and solving a problem by finding a root cause of it Communication & Presentation Companies searching for a strong data scientist are looking for someone who can clearly and fluently translate their technical findings to a non-technical team. A data scientist must enable the business to make decisions by arming them with quantified insights Summarized from http://www.kdnuggets.com/2014/11/9-must-have-skills-data-scientist.html
- 49. [BIG] DATA SOURCES Social media platform. Most of social media provided some API to fetch the data from there. Twitter and Facebook is the most common example KDNuggets (http://www.kdnuggets.com/datasets/index.html) Kaggle (https://www.kaggle.com/) Portal Data Indonesia (http://data.go.id/) Your WhatsApp group conversation
- 50. ONLINE TUTORIAL Coursera (https://www.coursera.org/) DataQuest (https://www.dataquest.io/) Udacity (https://www.udacity.com/) TutorialsPoint (http://www.tutorialspoint.com/) Youtube, RapidMiner Channel (https://www.youtube.com/user/RapidIVideos) Youtube KNIME TV (https://www.youtube.com/user/KNIMETV) Cloudera Quickstart VM (http://www.cloudera.com/content/www/en- us/documentation/enterprise/latest/topics/cloudera_quickstart_vm.html) Hortonworks Sandbox VM (http://hortonworks.com/products/hortonworks-sandbox/) Apache Spark Page (https://spark.apache.org/examples.html)
- 51. PREPARE YOURSELF TO SURF THE DATA ERA!
- 52. Question?