Big Data and Hadoop Ecosystem
3 likes3,034 views

Big data and Hadoop are introduced as ways to handle the increasing volume, variety, and velocity of data. Hadoop evolved as a solution to process large amounts of unstructured and semi-structured data across distributed systems in a cost-effective way using commodity hardware. It provides scalable and parallel processing via MapReduce and HDFS distributed file system that stores data across clusters and provides redundancy and failover. Key Hadoop projects include HDFS, MapReduce, HBase, Hive, Pig and Zookeeper.























































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Big Data and Hadoop Ecosystem (20)




















Ad
Recently uploaded (20)




















Big Data and Hadoop Ecosystem
- 1. Big Data and Hadoop Presenter Rajkumar Singh http://rajkrrsingh.blogspot.com/ http://in.linkedin.com/in/rajkrrsingh
- 2. Big Data and Hadoop Introduction Volume Variety Velocity Facebook Google Plus Twitter LinkedIn Stock Exchange Healthcare Telecom Structured,SemiStructured,unstructured Facebook Stock Exchange Healthcare Telecom Mobile Devices GPS Security Infrastructure
- 3. The Problem e.g. Stock Market
- 4. The Solution (Hadoop Evolution) Traditional Approach
- 5. GB->TB->PB--ZB so the processing with RDBMS is Impossible
- 6. Challenges In Big data • Storage -- PB • Processing – In a timely manner • Variety of data -- S/SS/US • Cost
- 7. To overcome Big Data Challenges Hadoop evolves • Cost Effective – Commodity HW • Big Cluster – (1000 Nodes) --- Provides Storage n Processing • Parallel Processing – Map reduce • Big Storage – Memory per node * no of Nodes / RF • Fail over mechanism – Automatic Failover • Data Distribution • Map Reduce Framework • Moving Code to data • Heterogeneous Hardware System (IBM,HP,AIX,Oracle Machine of any memory and CPU configuration) • Scalable
- 9. What is Hadoop • Java Framework to Process erroneous amount of data Hadoop Core • HDFS • Programming Construct (Map Reduce)
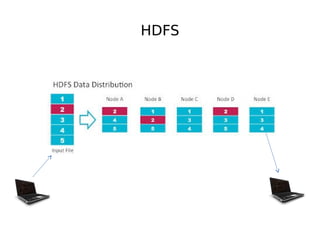
- 10. HDFS
- 12. Hadoop Ecosystem
- 13. Hadoop Sub-Projects • Hadoop Common: The common utilities that support the other Hadoop subprojects. • Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data. • Hadoop MapReduce: A software framework for distributed processing of large data sets on compute clusters. Other Hadoop-related projects at Apache include: • Avro™: A data serialization system. • Cassandra™: A scalable multi-master database with no single points of failure. • Chukwa™: A data collection system for managing large distributed systems. • HBase™: A scalable, distributed database that supports structured data storage for large tables. • Hive™: A data warehouse infrastructure that provides data summarization and ad hoc querying. • Mahout™: A Scalable machine learning and data mining library. • Pig™: A high-level data-flow language and execution framework for parallel computation. • ZooKeeper™: A high-performance coordination service for distributed applications.
- 14. HDFS 250 GB DFS 250 GB 1 TB File 250 GB Based on GFS 250 GB
- 15. HDFS : Use Cases • Very large file. • Reading/Streaming Data Access. Read data in large volume Write once and Read frequent • Expensive Hardware. • Low latency Access. • Lots of small files • Parallel write/ Arbitrary Read
- 16. HDFS Building Blocks Default Block Size 64MB 128MB 1GB file = 1024 MB/128 MB = 8 Blocks For Small File Size 100 MB File < Block Size (128 MB) : Optimize for storage = 1 Block of HDFS of size 100 MB
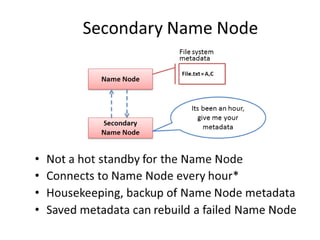
- 17. HDFS Daemon Services • Name Node • Secondary Name Node • Data Node GFS (Master/Slave Architecture)
- 18. HDFS Write File 1: D1,D2,D4 File 2: D1,D2,D3 128 MB RF = 3 D1 D1,D2,D4 D2 D3 D4
- 22. HDFS File System Commands
- 25. HDFS Federation
- 27. Copying Data from one Cluster to another Cluster UAT Cluster Prod Cluster Parallel copying using distcp hadoop distcp hdfs://uat:54311/user/rajkrrsingh/input hdfs://prod:54311/user/rajkrrsingh/input