Big Data com Python
12 likes14,511 views

Python Workshop on-line at Mutirao Python on-line via pycursos.com https://www.youtube.com/watch?feature=player_embedded&v=DFh6l-h6-gw








































































![Examples
Relational Join in MapReduce: Reduce Phase
5/15/13 Bill Howe, UW 18
key=999999999, values=[(Employee, Sue, 999999999),
(Department, 999999999, Accounts)]
key=777777777, values=[(Employee, Tony, 777777777),
(Department, 777777777, Sales),
(Department, 777777777, Marketing)]
Sue, 999999999, 999999999, Accounts
Tony, 777777777, 777777777, Sales
Tony, 777777777, 777777777, Marketing](https://image.slidesharecdn.com/bigdata-130618225124-phpapp02/85/Big-Data-com-Python-76-320.jpg)



![Examples
Matrix Multiply in MapReduce
C = A X B
A has dimensions L,M
B has dimensions M,N
• In the map phase:
– for each element (i,j) of A, emit ((i,k), A[i,j]) for k in 1..N
– for each element (j,k) of B, emit ((i,k), B[j,k]) for i in 1..L
• In the reduce phase, emit
– key = (i,k)
– value = Sumj (A[i,j] * B[j,k])
5/15/13 Bill Howe, Data Science, Autumn 2012 21](https://image.slidesharecdn.com/bigdata-130618225124-phpapp02/85/Big-Data-com-Python-80-320.jpg)
















![Exemplo de MapReduce
from mrjob.job import MRJob
import re
WORD_RE = re.compile(r"[w']+")
class MRWordFreqCount(MRJob):
def mapper(self, _, line):
for word in WORD_RE.findall(line):
yield (word.lower(), 1)
def reducer(self, word, counts):
yield (word, sum(counts))
if __name__ == '__main__':
MRWordFreqCount().run()](https://image.slidesharecdn.com/bigdata-130618225124-phpapp02/85/Big-Data-com-Python-98-320.jpg)









![Atepassar Recommendations
http://atepassar.com
marcel;jonas,maria,jose,amanda
maria;carol,fabiola,amanda,marcel
amanda;paula,patricia,maria,marcel
carol;maria,jose,patricia
fabiola;maria
paula;fabio,amanda
patricia;amanda,carol
jose;marcel,carol
jonas;marcel,fabio
fabio;jonas,paula
carla
"marcel" [["carol", 2], ["fabio", 1], ["fabiola", 1], ["patricia", 1], ["paula", 1]]
"maria" [["jose", 2], ["patricia", 2], ["jonas", 1], ["paula", 1]]
"patricia" [["maria", 2], ["jose", 1], ["marcel", 1], ["paula", 1]]
"paula" [["jonas", 1], ["marcel", 1], ["maria", 1], ["patricia", 1]]
"amanda" [["carol", 2], ["fabio", 1], ["fabiola", 1], ["jonas", 1], ["jose", 1]]
"carol" [["amanda", 2], ["marcel", 2], ["fabiola", 1]]
"fabio" [["amanda", 1], ["marcel", 1]]
"fabiola" [["amanda", 1], ["carol", 1], ["marcel", 1]]
"jonas" [["amanda", 1], ["jose", 1], ["maria", 1], ["paula", 1]]
"jose" [["maria", 2], ["amanda", 1], ["jonas", 1], ["patricia", 1]]
$python friends_recommender.py - r emr --num-ec2-instances 5 facebook_data.csv > output.dat](https://image.slidesharecdn.com/bigdata-130618225124-phpapp02/85/Big-Data-com-Python-109-320.jpg)
![Atepassar Recommendations
http://atepassar.com
marcel;jonas,maria,jose,amanda
maria;carol,fabiola,amanda,marcel
amanda;paula,patricia,maria,marcel
carol;maria,jose,patricia
fabiola;maria
paula;fabio,amanda
patricia;amanda,carol
jose;marcel,carol
jonas;marcel,fabio
fabio;jonas,paula
carla
"marcel" [["carol", 2], ["fabio", 1], ["fabiola", 1], ["patricia", 1], ["paula", 1]]
"maria" [["jose", 2], ["patricia", 2], ["jonas", 1], ["paula", 1]]
"patricia" [["maria", 2], ["jose", 1], ["marcel", 1], ["paula", 1]]
"paula" [["jonas", 1], ["marcel", 1], ["maria", 1], ["patricia", 1]]
"amanda" [["carol", 2], ["fabio", 1], ["fabiola", 1], ["jonas", 1], ["jose", 1]]
"carol" [["amanda", 2], ["marcel", 2], ["fabiola", 1]]
"fabio" [["amanda", 1], ["marcel", 1]]
"fabiola" [["amanda", 1], ["carol", 1], ["marcel", 1]]
"jonas" [["amanda", 1], ["jose", 1], ["maria", 1], ["paula", 1]]
"jose" [["maria", 2], ["amanda", 1], ["jonas", 1], ["patricia", 1]]
$python friends_recommender.py - r emr --num-ec2-instances 5 facebook_data.csv > output.dat
marcel;jonas,maria,jose,amanda
carol;maria,jose,patricia
fabio;jonas,paula
...](https://image.slidesharecdn.com/bigdata-130618225124-phpapp02/85/Big-Data-com-Python-110-320.jpg)





![Projetos interessantes
http://api.mongodb.org/python/2.0/examples/
map_reduce.html
Python & MongoDb
MongoDb - Banco de Dados Não relacional (NoSQL)
Possui suporte nativo built-in para fazer MapReduce.
Escrever o código em JS e não é muito legível e fica preso ao
Mongo ...
>>> reduce = Code("function (key, values) {"
... " var total = 0;"
... " for (var i = 0; i < values.length; i++) {"
... " total += values[i];"
... " }"
... " return total;"
... "}")](https://image.slidesharecdn.com/bigdata-130618225124-phpapp02/85/Big-Data-com-Python-116-320.jpg)















































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Big Data com Python (20)




















Ad
More from Marcel Caraciolo (20)




















Recently uploaded (20)




















Big Data com Python
- 1. BigData with Python A gentle and simple introduction Marcel Caraciolo @marcelcaraciolo Developer, Cientist, contributor to the Crab recsys project, works with Python for 6 years, interested at mobile, education, machine learning and dataaaaa! Recife, Brazil - http://aimotion.blogspot.com
- 2. https://class.coursera.org/datasci-001/ Disclaimer Alguns slides foram retirados das apts do curso de Bill Howe - Introduction to Data Science
- 3. About me Co-founder of Crab - Python recsys library Cientist Chief at Atepassar, e-learning social network Co-Founder and Instructor of PyCursos, teaching Python on-line Co-Founder of Pingmind, on-line infrastructure for MOOC’s Interested at Python, mobile, e-learning and machine learning!
- 4. What is BigData ?
- 5. Big Data “Big Data is any data that is expensive to manage and hard to extract value from.” Michael Franklin Thomas M. Siebel Professor of Computer Science Director of the Algorithms, Machines and People Lab University of Berkeley
- 6. Big Data Erik Larson, 1989, Harper’s magazine “The keepers of big data say they do it for the consumer’s benefit. But data have a way of being used for purposes other than originally intended.”
- 8. Challenges Volume the size of the data Velocity the latency of data processing relative to the growing demand for interactivity Variety the diversity of sources, formats, quality, structures
- 10. Where does big data comes from ? “data exhaust” from customers new and pervasive sensors the ability to “keep everything”
- 12. Where does big data comes from ? photo in public domain
- 13. Where does big data comes from ? 4/28/13 Bill Howe, UW 11
- 17. Scalability
- 18. What does Scalable mean ? Operationally: In the past: Works even if data doesn’t fit in main memory Now: Can make use of 1000s of cheap computers Algorithmically: In the past: If you have N data items, you must do no more than Nm operations -- polynomial time algorithms Now: If you have N data items, you must do no more than Nm/k operations, for some large k -- “polynomial time algorithms must be parallelized” Soon: If you have N data items, you should do no more than N * log(N) operations
- 19. Example Given a set of DNA sequences, find all sequences equal to GATTACGATATTA .
- 21. TACCTGCCGTAA = GATTACGATATTA? GATTACGATATTA time = 0 No. Time = 0
- 22. Time = 1 CCCCCAATGAC = GATTACGATATTA? GATTACGATATTA time = 1 No.
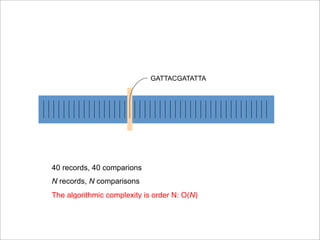
- 23. Time = 17 GATTACGATATTA contains GATTACGATATTA? GATTACGATATTA time = 17 Yes! Send it to the output.
- 24. GATTACGATATTA 40 records, 40 comparions N records, N comparisons The algorithmic complexity is order N: O(N)
- 25. GATTACGATATTA AAAATCCTGCA AAACGCCTGCA TTTACGTCAA TTTTCGTAATT What if we sort the sequences? What if we sort the sequences ?
- 26. CTGTACACAACCT < GATTACGATATTA GATTACGATATTA No match. Skip to 75% mark Start at the 50% mark time = 0 0% 100% CTGTACACAACCT Time = 0
- 27. GGATACACATTTA > GATTACGATATTA GATTACGATATTA No match. 0% 100% GGATACACATTTA
- 28. GATATTTTAAGC < GATTACGATATTA GATTACGATATTA No match. Skip back to 68.75% mark 0% 100% GATATTTTAAGC
- 29. GATTACGATATTA = GATTACGATATTA GATTACGATATTA 0% 100% Match! Walk through the records until we fail to match.
- 30. GATTACGATATTA 0% 100% How many comparisons did we do? 40 records, only 4 comparisons N records, log(N) comparisons This algorithm is O(log(N)) Far better scalability
- 31. Relational Databases Relational Databases • Databases are good at Needle in Haystack problems: – Extracting small results from big datasets – Transparently provide old style scalability – Your query will always* finish, regardless of dataset size. – Indexes are easily built and automatically used when appropriate CREATE INDEX seq_idx ON sequence(seq); SELECT seq FROM sequence WHERE seq = GATTACGATATTA ;
- 32. Example New task: Read Trimming Given a set of DNA sequences, trim the final n bps of each sequence Generate a new dataset
- 34. TACCTGCCGTAA becomes TACCT time = 0 Time = 0
- 35. Time = 1 CCCCCAATGAC becomes CCCCC time = 1
- 36. Time = 17 GATTACGATATTA becomes GATTA time = 17
- 37. Can we use an index? No. We have to touch every record no matter what. The task is fundamentally O(N) Can we do any better?
- 39. Time = 0
- 40. Time = 1
- 41. Time = 2
- 42. Time = 3
- 43. Time = 7 time = 7 How much time did this take? 7 cycles 40 records, 6 workers O(N/k) time = 7 How much time did this ta 7 cycles 40 records, 6 workers O(N/k)
- 44. Schematic of a Parallel “Read Trimming” Task You are given short “reads”: genomic sequences about 35-75 characters each Distribute the reads among k computers f f f f f f f is a function to trim a read; apply it to every item Now we have a big distributed set of trimmed reads Schematic of a Parallel “Read Trimming” Task You are given short “reads”: genomic sequences about 35-75 characters each Distribute the reads among k computers f f f f f f f is a function to trim a read; apply it to every item Now we have a big distributed set of trimmed reads Schematic of a Parallel “Read Trimming” Task You are given short “reads”: genomic sequences about 35-75 characters each Distribute the reads among k computers f f f f f f f is a function to trim a read; apply it to every item Now we have a big distributed set of trimmed reads Schematic of a Parallel “Read Trimming” Task You are given short “reads”: genomic sequences about 35-75 characters each Distribute the reads among k computers f f f f f f f is a function to trim a read; apply it to every item Now we have a big distributed set of trimmed reads
- 45. You are given TIFF images Distribute the images among k computers f f f f f f f is a function to convert TIFF to PNG; apply it to every item Now we have a big distributed set of converted images New Task: Convert 405k TIFF images to PNG http://open.blogs.nytimes.com/2008/05/21/the-new-york-times-archives-amazon-web-services-timesmachine/ Convert 405k TIFF images to PNG
- 46. You have sets of parameters for thousands of small simulations Divide the parameter sets among k computers f f f f f f f is runs the simulation and produces some output; apply it to every item Now we have a big distributed set of simulation results New Task: Run thousands of simulations http://escience.washington.edu/get-help-now/dave-williams-simulating-muscle-dynamics-cloud Run thousands of simulations
- 47. You have millions of documents Distribute the documents among k computers f f f f f f f finds the most common word in a single document Now we have a big distributed list of (doc_id, word) pairs Find the most common word in each document Find the most common word in each document
- 48. Consider a slightly more general program to compute the word frequency of every word in a singe documentConsider a slightly more general program to compute the word frequency of every word in a single document Abridged Declaration of Independence A Declaration By the Representatives of the United States of America, in General Congress Assembled. When in the course of human events it becomes necessary for a people to advance from that subordination in which they have hitherto remained, and to assume among powers of the earth the equal and independent station to which the laws of nature and of nature's god entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the change. We hold these truths to be self-evident; that all men are created equal and independent; that from that equal creation they derive rights inherent and inalienable, among which are the preservation of life, and liberty, and the pursuit of happiness; that to secure these ends, governments are instituted among men, deriving their just power from the consent of the governed; that whenever any form of government shall become destructive of these ends, it is the right of the people to alter or to abolish it, and to institute new government, laying it's foundation on such principles and organizing it's power in such form, as to them shall seem most likely to effect their safety and happiness. Prudence indeed will dictate that governments long established should not be changed for light and transient causes: and accordingly all experience hath shewn that mankind are more disposed to suffer while evils are sufferable, than to right themselves by abolishing the forms to which they are accustomed. But when a long train of abuses and usurpations, begun at a distinguished period, and pursuing invariably the same object, evinces a design to reduce them to arbitrary power, it is their right, it is their duty, to throw off such government and to provide new guards for future security. Such has been the patient sufferings of the colonies; and such is now the necessity which constrains them to expunge their former systems of government. the history of his present majesty is a history of unremitting injuries and usurpations, among which no one fact stands single or solitary to contradict the uniform tenor of the rest, all of which have in direct object the establishment of an absolute tyranny over these states. To prove this, let facts be submitted to a candid world, for the truth of which we pledge a faith yet unsullied by falsehood. (people, 2) (government, 6) (assume, 1) (history, 2) …
- 49. You have millions of documents Distribute the documents among k computers f f f f f f For each document f returns a set of (word, freq) pairs Compute the word frequency of 5M documents Now we have a big distributed list of sets of word freqs.
- 50. There’s a pattern... There’s a pattern here…. • A function that maps a read to a trimmed read • A function that maps a TIFF image to a PNG image • A function that maps a set of parameters to a simulation result • A function that maps a document to its most common word • A function that maps a document to a histogram of word frequencies
- 51. What if we want to compute the word frequency across all documents? US Constitution Declaration of Independence Articles of Confederation (people, 78) (government, 123) (assume, 23) (history, 38) …
- 52. You have millions of documents Distribute the documents among k computers map map map map map map For each document, return a set of (word, freq) pairs Compute the word frequency across 5M documents Now what? • But we don’t want a bunch of little histograms – we want one big histogram. • How can we make sure that a single computer has access to every occurrence of a given word regardless of which document it appeared in? Compute the word frequency across 5M docs
- 53. Compute the word frequency across 5M docs Distribute the documents among k computers map map map map map map For each document, return a set of (word, freq) pairs Now we have a big distributed list of sets of word freqs. reduce reduce reduce reduce Now just count the occurrences of each word 44 3 We have our distributed histogram Compute the word frequency across 5M documents
- 54. Compute the word frequency across 5M docs 5/15/13 Bill Howe, eScience Institute 11 Some distributed algorithm… Map (Shuffle) Reduce
- 55. Compute the word frequency across 5M docs 5/15/13 Bill Howe, eScience Institute 12 MapReduce Programming Model • Input & Output: each a set of key/value pairs • Programmer specifies two functions: – Processes input key/value pair – Produces set of intermediate pairs – Combines all intermediate values for a particular key – Produces a set of merged output values (usually just one) map (in_key, in_value) -> list(out_key, intermediate_value) reduce (out_key, list(intermediate_value)) -> list(out_value) Inspired by primitives from functional programming languages such as Lisp, Scheme, and Haskell slide source: Google, Inc.
- 56. Compute the word frequency across 5M docs 5/15/13 Bill Howe, eScience Institute 13 Example: What does this do? map(String input_key, String input_value): // input_key: document name // input_value: document contents for each word w in input_value: EmitIntermediate(w, 1); reduce(String output_key, Iterator intermediate_values): // output_key: word // output_values: ???? int result = 0; for each v in intermediate_values: result += v; Emit(result); slide source: Google, Inc.
- 57. Example 3/12/09 Bill Howe, eScience Institute 14 Abridged Declaration of Independence A Declaration By the Representatives of the United States of America, in General Congress Assembled. When in the course of human events it becomes necessary for a people to advance from that subordination in which they have hitherto remained, and to assume among powers of the earth the equal and independent station to which the laws of nature and of nature's god entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the change. We hold these truths to be self-evident; that all men are created equal and independent; that from that equal creation they derive rights inherent and inalienable, among which are the preservation of life, and liberty, and the pursuit of happiness; that to secure these ends, governments are instituted among men, deriving their just power from the consent of the governed; that whenever any form of government shall become destructive of these ends, it is the right of the people to alter or to abolish it, and to institute new government, laying it's foundation on such principles and organizing it's power in such form, as to them shall seem most likely to effect their safety and happiness. Prudence indeed will dictate that governments long established should not be changed for light and transient causes: and accordingly all experience hath shewn that mankind are more disposed to suffer while evils are sufferable, than to right themselves by abolishing the forms to which they are accustomed. But when a long train of abuses and usurpations, begun at a distinguished period, and pursuing invariably the same object, evinces a design to reduce them to arbitrary power, it is their right, it is their duty, to throw off such government and to provide new guards for future security. Such has been the patient sufferings of the colonies; and such is now the necessity which constrains them to expunge their former systems of government. the history of his present majesty is a history of unremitting injuries and usurpations, among which no one fact stands single or solitary to contradict the uniform tenor of the rest, all of which have in direct object the establishment of an absolute tyranny over these states. To prove this, let facts be submitted to a candid world, for the truth of which we pledge a faith yet unsullied by falsehood. Example: Document Processing
- 58. Word length histogram example 3/12/09 Bill Howe, eScience Institute 14 Abridged Declaration of Independence A Declaration By the Representatives of the United States of America, in General Congress Assembled. When in the course of human events it becomes necessary for a people to advance from that subordination in which they have hitherto remained, and to assume among powers of the earth the equal and independent station to which the laws of nature and of nature's god entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the change. We hold these truths to be self-evident; that all men are created equal and independent; that from that equal creation they derive rights inherent and inalienable, among which are the preservation of life, and liberty, and the pursuit of happiness; that to secure these ends, governments are instituted among men, deriving their just power from the consent of the governed; that whenever any form of government shall become destructive of these ends, it is the right of the people to alter or to abolish it, and to institute new government, laying it's foundation on such principles and organizing it's power in such form, as to them shall seem most likely to effect their safety and happiness. Prudence indeed will dictate that governments long established should not be changed for light and transient causes: and accordingly all experience hath shewn that mankind are more disposed to suffer while evils are sufferable, than to right themselves by abolishing the forms to which they are accustomed. But when a long train of abuses and usurpations, begun at a distinguished period, and pursuing invariably the same object, evinces a design to reduce them to arbitrary power, it is their right, it is their duty, to throw off such government and to provide new guards for future security. Such has been the patient sufferings of the colonies; and such is now the necessity which constrains them to expunge their former systems of government. the history of his present majesty is a history of unremitting injuries and usurpations, among which no one fact stands single or solitary to contradict the uniform tenor of the rest, all of which have in direct object the establishment of an absolute tyranny over these states. To prove this, let facts be submitted to a candid world, for the truth of which we pledge a faith yet unsullied by falsehood. Example: Document Processing 3/12/09 Bill Howe, eScience Institute 15 Abridged Declaration of Independence A Declaration By the Representatives of the United States of America, in General Congress Assembled. When in the course of human events it becomes necessary for a people to advance from that subordination in which they have hitherto remained, and to assume among powers of the earth the equal and independent station to which the laws of nature and of nature's god entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the change. We hold these truths to be self-evident; that all men are created equal and independent; that from that equal creation they derive rights inherent and inalienable, among which are the preservation of life, and liberty, and the pursuit of happiness; that to secure these ends, governments are instituted among men, deriving their just power from the consent of the governed; that whenever any form of government shall become destructive of these ends, it is the right of the people to alter or to abolish it, and to institute new government, laying it's foundation on such principles and organizing it's power in such form, as to them shall seem most likely to effect their safety and happiness. Prudence indeed will dictate that governments long established should not be changed for light and transient causes: and accordingly all experience hath shewn that mankind are more disposed to suffer while evils are sufferable, than to right themselves by abolishing the forms to which they are accustomed. But when a long train of abuses and usurpations, begun at a distinguished period, and pursuing invariably the same object, evinces a design to reduce them to arbitrary power, it is their right, it is their duty, to throw off such government and to provide new guards for future security. Such has been the patient sufferings of the colonies; and such is now the necessity which constrains them to expunge their former systems of government. the history of his present majesty is a history of unremitting injuries and usurpations, among which no one fact stands single or solitary to contradict the uniform tenor of the rest, all of which have in direct object the establishment of an absolute tyranny over these states. To prove this, let facts be submitted to a candid world, for the truth of which we pledge a faith yet unsullied by falsehood. Example: Word length histogram How many big , medium , and small words are used?
- 59. Word length histogram example Abridged Declaration of Independence A Declaration By the Representatives of the United States of America, in General Congress Assembled. When in the course of human events it becomes necessary for a people to advance from that subordination in which they have hitherto remained, and to assume among powers of the earth the equal and independent station to which the laws of nature and of nature's god entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the change. We hold these truths to be self-evident; that all men are created equal and independent; that from that equal creation they derive rights inherent and inalienable, among which are the preservation of life, and liberty, and the pursuit of happiness; that to secure these ends, governments are instituted among men, deriving their just power from the consent of the governed; that whenever any form of government shall become destructive of these ends, it is the right of the people to alter or to abolish it, and to institute new government, laying it's foundation on such principles and organizing it's power in such form, as to them shall seem most likely to effect their safety and happiness. Prudence indeed will dictate that governments long established should not be changed for light and transient causes: and accordingly all experience hath shewn that mankind are more disposed to suffer while evils are sufferable, than to right themselves by abolishing the forms to which they are accustomed. But when a long train of abuses and usurpations, begun at a distinguished period, and pursuing invariably the same object, evinces a design to reduce them to arbitrary power, it is their right, it is their duty, to throw off such government and to provide new guards for future security. Such has been the patient sufferings of the colonies; and such is now the necessity which constrains them to expunge their former systems of government. the history of his present majesty is a history of unremitting injuries and usurpations, among which no one fact stands single or solitary to contradict the uniform tenor of the rest, all of which have in direct object the establishment of an absolute tyranny over these states. To prove this, let facts be submitted to a candid world, for the truth of which we pledge a faith yet unsullied by falsehood. Big = Yellow = 10+ letters Medium = Red = 5..9 letters Small = Blue = 2..4 letters Tiny = Pink = 1 letter Example: Word length histogram
- 60. Word length histogram example Abridged Declaration of Independence A Declaration By the Representatives of the United States of America, in General Congress Assembled. When in the course of human events it becomes necessary for a people to advance from that subordination in which they have hitherto remained, and to assume among powers of the earth the equal and independent station to which the laws of nature and of nature's god entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the change. We hold these truths to be self-evident; that all men are created equal and independent; that from that equal creation they derive rights inherent and inalienable, among which are the preservation of life, and liberty, and the pursuit of happiness; that to secure these ends, governments are instituted among men, deriving their just power from the consent of the governed; that whenever any form of government shall become destructive of these ends, it is the right of the people to alter or to abolish it, and to institute new government, laying it's foundation on such principles and organizing it's power in such form, as to them shall seem most likely to effect their safety and happiness. Prudence indeed will dictate that governments long established should not be changed for light and transient causes: and accordingly all experience hath shewn that mankind are more disposed to suffer while evils are sufferable, than to right themselves by abolishing the forms to which they are accustomed. But when a long train of abuses and usurpations, begun at a distinguished period, and pursuing invariably the same object, evinces a design to reduce them to arbitrary power, it is their right, it is their duty, to throw off such government and to provide new guards for future security. Such has been the patient sufferings of the colonies; and such is now the necessity which constrains them to expunge their former systems of government. the history of his present majesty is a history of unremitting injuries and usurpations, among which no one fact stands single or solitary to contradict the uniform tenor of the rest, all of which have in direct object the establishment of an absolute tyranny over these states. To prove this, let facts be submitted to a candid world, for the truth of which we pledge a faith yet unsullied by falsehood. Split the document into chunks and process each chunk on a different computer Chunk 1 Chunk 2 Example: Word length histogram
- 61. Word length histogram example (yellow, 20) (red, 71) (blue, 93) (pink, 6 ) Abridged Declaration of Independence A Declaration By the Representatives of the United States of America, in General Congress Assembled. When in the course of human events it becomes necessary for a people to advance from that subordination in which they have hitherto remained, and to assume among powers of the earth the equal and independent station to which the laws of nature and of nature's god entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the change. We hold these truths to be self-evident; that all men are created equal and independent; that from that equal creation they derive rights inherent and inalienable, among which are the preservation of life, and liberty, and the pursuit of happiness; that to secure these ends, governments are instituted among men, deriving their just power from the consent of the governed; that whenever any form of government shall become destructive of these ends, it is the right of the people to alter or to abolish it, and to institute new government, laying it's foundation on such principles and organizing it's power in such form, as to them shall seem most likely to effect their safety and happiness. Prudence indeed will dictate that governments long established should not be changed for light and transient causes: and accordingly all experience hath shewn that mankind are more disposed to suffer while evils are sufferable, than to right themselves by abolishing the forms to which they are accustomed. But when a long train of abuses and usurpations, begun at a distinguished period, and pursuing invariably the same object, evinces a design to reduce them to arbitrary power, it is their right, it is their duty, to throw off such government and to provide new guards for future security. Such has been the patient sufferings of the colonies; and such is now the necessity which constrains them to expunge their former systems of government. the history of his present majesty is a history of unremitting injuries and usurpations, among which no one fact stands single or solitary to contradict the uniform tenor of the rest, all of which have in direct object the establishment of an absolute tyranny over these states. To prove this, let facts be submitted to a candid world, for the truth of which we pledge a faith yet unsullied by falsehood. Map Task 1 (204 words) Map Task 2 (190 words) (key, value) (yellow, 17) (red, 77) (blue, 107) (pink, 3) Example: Word length histogram
- 62. Word length histogram example 3/12/09 Bill Howe, eScience Institute 19 (yellow, 17) (red, 77) (blue, 107) (pink, 3) (yellow, 20) (red, 71) (blue, 93) (pink, 6 ) Reduce tasks (yellow, 17) (yellow, 20) (red, 77) (red, 71) (blue, 93) (blue, 107) (pink, 6) (pink, 3) Example: Word length histogram A Declaration By the Representatives of the United States of America, in General Congress Assembled. When in the course of human events it becomes necessary for a people to advance from that subordination in which they have hitherto remained, and to assume among powers of the earth the equal and independent station to which the laws of nature and of nature's god entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the change. We hold these truths to be self-evident; that all men are created equal and independent; that from that equal creation they derive rights inherent and inalienable, among which are the preservation of life, and liberty, and the pursuit of happiness; that to secure these ends, governments are instituted among men, deriving their just power from the consent of the governed; that whenever any form of government shall become destructive of these ends, it is the right of the people to alter or to abolish it, and to institute new government, laying it's foundation on such principles and organizing it's power in such form, as to them shall seem most likely to effect their safety and happiness. Prudence indeed will dictate that governments long established should not be changed for light and transient causes: and accordingly all experience hath shewn that mankind are more disposed to suffer while evils are sufferable, than to right themselves by abolishing the forms to which they are accustomed. But when a long train of abuses and usurpations, begun at a distinguished period, and pursuing invariably the same object, evinces a design to reduce them to arbitrary power, it is their right, it is their duty, to throw off such government and to provide new guards for future security. Such has been the patient sufferings of the colonies; and such is now the necessity which constrains them to expunge their former systems of government. the history of his present majesty is a history of unremitting injuries and usurpations, among which no one fact stands single or solitary to contradict the uniform tenor of the rest, all of which have in direct object the establishment of an absolute tyranny over these states. To prove this, let facts be submitted to a candid world, for the truth of which we pledge a faith yet unsullied by falsehood. Map task 1 Map task 2 Shuffle step (yellow, 37) (red, 148) (blue, 200) (pink, 9)
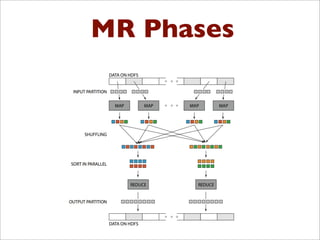
- 63. MR Phases !"#$%&'(")$*+&,& MR Phases • Each Map and Reduce task has multiple phases:
- 64. MR Phases MAP REDUCE (w1,1) (w2,1) (w1,1) … (w1,1) (w2,1) … (did1,v1) (did2,v2) (did3,v3) . . . . (w1, (1,1,1,…,1)) (w2, (1,1,…)) (w3,(1…)) … … … … (w1, 25) (w2, 77) (w3, 12) … … … … Shuffle !"#$%&'()%"**$"(+%,&-.$/%% 012%3',%45+,%+$3)%6&78%9:;%
- 65. MR Phases Hadoop in One Slide src: Huy Vo, NYU Poly
- 66. Taxonomy of Parallel Architectures 5/15/13 Bill Howe, eScience Institute 22 Taxonomy of Parallel Architectures Easiest to program, but $$$$ Scales to 1000s of computers
- 67. 5/15/13 Bill Howe, UW 32
- 68. 5/15/13 Bill Howe, UW 25
- 69. 5/15/13 Bill Howe, eScience Institute 26 Large-Scale Data Processing • Many tasks process big data, produce big data • Want to use hundreds or thousands of CPUs – ... but this needs to be easy – Parallel databases exist, but they are expensive, difficult to set up, and do not necessarily scale to hundreds of nodes. • MapReduce is a lightweight framework, providing: – Automatic parallelization and distribution – Fault-tolerance – I/O scheduling – Status and monitoring
- 70. 5/15/13 Bill Howe, eScience Institute 35 MapReduce Contemporaries • Dryad (Microsoft) – Relational Algebra • Pig (Yahoo) – Near Relational Algebra over MapReduce • HIVE (Facebook) – SQL over MapReduce • Cascading – Relational Algebra • Clustera – U of Wisconsin • Hbase – Indexing on HDFS MapReduce Contemporaries
- 71. Talk is cheap, Show me the code
- 72. Examples More Examples: Build an Inverted Index 5/15/13 Bill Howe, UW 14 Input: tweet1, (“I love pancakes for breakfast”) tweet2, (“I dislike pancakes”) tweet3, (“What should I eat for breakfast?”) tweet4, (“I love to eat”) Desired output: “pancakes”, (tweet1, tweet2) “breakfast”, (tweet1, tweet3) “eat”, (tweet3, tweet4) “love”, (tweet1, tweet4) …
- 73. Examples More Examples: Relational Join 5/15/13 Bill Howe, UW 15 Name SSN Sue 999999999 Tony 777777777 EmpSSN DepName 999999999 Accounts 777777777 Sales 777777777 Marketing Emplyee ⨝ Assigned Departments Employee Assigned Departments Name SSN EmpSSN DepName Sue 999999999 999999999 Accounts Tony 777777777 777777777 Sales Tony 777777777 777777777 Marketing
- 74. Examples Relational Join in MapReduce: Before Map Phase 5/15/13 Bill Howe, UW 16 Name SSN Sue 999999999 Tony 777777777 EmpSSN DepName 999999999 Accounts 777777777 Sales 777777777 Marketing Employee Assigned Departments Key idea: Lump all the tuples together into one dataset Employee, Sue, 999999999 Employee, Tony, 777777777 Department, 999999999, Accounts Department, 777777777, Sales Department, 777777777, Marketing What is this for?
- 75. Examples Relational Join in MapReduce: Map Phase 5/15/13 Bill Howe, UW 17 Employee, Sue, 999999999 Employee, Tony, 777777777 Department, 999999999, Accounts Department, 777777777, Sales Department, 777777777, Marketing key=999999999, value=(Employee, Sue, 999999999) key=777777777, value=(Employee, Tony, 777777777) key=999999999, value=(Department, 999999999, Accounts) key=777777777, value=(Department, 777777777, Sales) key=777777777, value=(Department, 777777777, Marketing) why do we use this as the key?
- 76. Examples Relational Join in MapReduce: Reduce Phase 5/15/13 Bill Howe, UW 18 key=999999999, values=[(Employee, Sue, 999999999), (Department, 999999999, Accounts)] key=777777777, values=[(Employee, Tony, 777777777), (Department, 777777777, Sales), (Department, 777777777, Marketing)] Sue, 999999999, 999999999, Accounts Tony, 777777777, 777777777, Sales Tony, 777777777, 777777777, Marketing
- 77. Examples Relational Join in MapReduce, again 5/15/13 Bill Howe, Data Science, Autumn 2012 19 Order(orderid, account, date) 1, aaa, d1 2, aaa, d2 3, bbb, d3 LineItem(orderid, itemid, qty) 1, 10, 1 1, 20, 3 2, 10, 5 2, 50, 100 3, 20, 1tagged with relation name Order 1, aaa, d1 ! 1 : “Order”, (1,aaa,d1) 2, aaa, d2 ! 2 : “Order”, (2,aaa,d2) 3, bbb, d3 ! 3 : “Order”, (3,bbb,d3) Line 1, 10, 1 ! 1 : “Line”, (1, 10, 1) 1, 20, 3 ! 1 : “Line”, (1, 20, 3) 2, 10, 5 ! 2 : “Line”, (2, 10, 5) 2, 50, 100 ! 2 : “Line”, (2, 50, 100) 3, 20, 1 ! 3 : “Line”, (3, 20, 1) Map Reducer for key 1 “Order”, (1,aaa,d1) “Line”, (1, 10, 1) “Line”, (1, 20, 3) (1, aaa, d1, 1, 10, 1) (1, aaa, d1, 1, 20, 3)
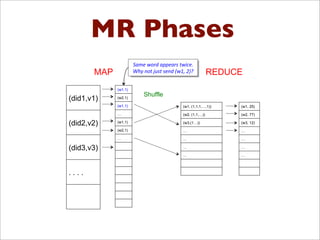
- 78. ExamplesSimple Social Network Analysis: Count Friends Jim, Sue Sue, Jim Lin, Joe Joe, Lin Jim, Kai Kai, Jim Jim, Lin Lin, Jim Input Desired Output Jim, 3 Lin, 2 Sue, 1 Kai, 1 Joe, 1 Jim, 1 Sue, 1 Lin, 1 Joe, 1 Jim, 1 Kai, 1 Jim, 1 Lin, 1 MAP REDUCE Jim, (1, 1, 1) Lin, (1, 1) Sue, (1) Kai, (1) Joe, (1) SHUFFLE
- 79. Examples Matrix Multiplication !" #" $" %&" '" &" %#" !" !" %&" $" #" %#" %&" (" $" X = !" %)" &#" $"
- 80. Examples Matrix Multiply in MapReduce C = A X B A has dimensions L,M B has dimensions M,N • In the map phase: – for each element (i,j) of A, emit ((i,k), A[i,j]) for k in 1..N – for each element (j,k) of B, emit ((i,k), B[j,k]) for i in 1..L • In the reduce phase, emit – key = (i,k) – value = Sumj (A[i,j] * B[j,k]) 5/15/13 Bill Howe, Data Science, Autumn 2012 21
- 81. Examples AB X A B = • One reducer per output cell
- 82. Meeting Hadoop
- 83. Cluster Computing • Large number of commodity servers, connected by high speed, commodity network • Rack: holds a small number of servers • Data center: holds many racks !"#$%&'(#))%'&*"&+!" #$%&'()*+(",-(+./0"123145"67$%8('"1",-(+./09":;1;<"/0=>4"" /?"#@0@0A"/?"#$99@B("C$8$9(89;"D>"E$F$'$G$0"$0)"H==G$0"" ),,(-.,(/0123,(456,7852(9,:3;-,(
- 84. Cluster Computing • Massive parallelism: – 100s, or 1000s, or 10000s servers – Many hours • Failure: – If medium-time-between-failure is 1 year – Then 10000 servers have one failure / hour 24slide src: Dan Suciu and Magda Balazinska
- 85. Distributed File System (DFS) • For very large files: TBs, PBs • Each file is partitioned into chunks, typically 64MB • Each chunk is replicated several times (!3), on different racks, for fault tolerance • Implementations: – Google’s DFS: GFS, proprietary – Hadoop’s DFS: HDFS, open source 25slide src: Dan Suciu and Magda Balazinska
- 86. Hadoop
- 92. !"#$$%&'($)*)+',&-& !"#$%& '#()%*+,%-!./0& 12+34#& !56%& 758& 96:;& <;;=%%(%:& 0>;;(& /?+@%& A;B5%& C25::&
- 98. Exemplo de MapReduce from mrjob.job import MRJob import re WORD_RE = re.compile(r"[w']+") class MRWordFreqCount(MRJob): def mapper(self, _, line): for word in WORD_RE.findall(line): yield (word.lower(), 1) def reducer(self, word, counts): yield (word, sum(counts)) if __name__ == '__main__': MRWordFreqCount().run()
- 99. Projeto MrJob Criado pela Equipe de Engenharia doYelp Totalmente Open-Source Todo em Python Utiliza Map-Reduce para Processamento Permite rodar tanto no Amazon EMR como no Hadoop
- 100. Objetivos do MrJobs Se você quer aprender MapReduce, ele é para você Se você tem um problema cavalar e precisa de muito processamento e não está afim de mexer em Hadoop Se você já tem um cluster Hadoop e quer rodar scripts Python Se você quer migrar seu código Python do Hadoop para o EMR Se você não quer escrever Python (Impossível!), não é para você!
- 101. Passos importantes sudo easy_install mrjob
- 102. Vamos a uma demo... Texto da posse de Obama em 2009.
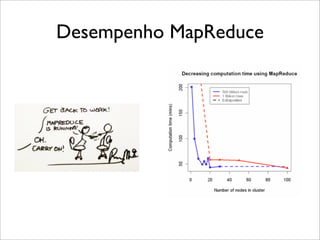
- 103. Desempenho MapReduce
- 105. Distributed Computing with mrJob https://github.com/Yelp/mrjob Elsayed et al: Pairwise Document Similarity in Large Collections with MapReduce
- 106. Distributed Computing with mrJob https://github.com/Yelp/mrjob Elsayed et al: Pairwise Document Similarity in Large Collections with MapReduce
- 107. Atepassar Recommendations http://atepassar.com Problema: Como recomendar novos amigos ?
- 109. Atepassar Recommendations http://atepassar.com marcel;jonas,maria,jose,amanda maria;carol,fabiola,amanda,marcel amanda;paula,patricia,maria,marcel carol;maria,jose,patricia fabiola;maria paula;fabio,amanda patricia;amanda,carol jose;marcel,carol jonas;marcel,fabio fabio;jonas,paula carla "marcel" [["carol", 2], ["fabio", 1], ["fabiola", 1], ["patricia", 1], ["paula", 1]] "maria" [["jose", 2], ["patricia", 2], ["jonas", 1], ["paula", 1]] "patricia" [["maria", 2], ["jose", 1], ["marcel", 1], ["paula", 1]] "paula" [["jonas", 1], ["marcel", 1], ["maria", 1], ["patricia", 1]] "amanda" [["carol", 2], ["fabio", 1], ["fabiola", 1], ["jonas", 1], ["jose", 1]] "carol" [["amanda", 2], ["marcel", 2], ["fabiola", 1]] "fabio" [["amanda", 1], ["marcel", 1]] "fabiola" [["amanda", 1], ["carol", 1], ["marcel", 1]] "jonas" [["amanda", 1], ["jose", 1], ["maria", 1], ["paula", 1]] "jose" [["maria", 2], ["amanda", 1], ["jonas", 1], ["patricia", 1]] $python friends_recommender.py - r emr --num-ec2-instances 5 facebook_data.csv > output.dat
- 110. Atepassar Recommendations http://atepassar.com marcel;jonas,maria,jose,amanda maria;carol,fabiola,amanda,marcel amanda;paula,patricia,maria,marcel carol;maria,jose,patricia fabiola;maria paula;fabio,amanda patricia;amanda,carol jose;marcel,carol jonas;marcel,fabio fabio;jonas,paula carla "marcel" [["carol", 2], ["fabio", 1], ["fabiola", 1], ["patricia", 1], ["paula", 1]] "maria" [["jose", 2], ["patricia", 2], ["jonas", 1], ["paula", 1]] "patricia" [["maria", 2], ["jose", 1], ["marcel", 1], ["paula", 1]] "paula" [["jonas", 1], ["marcel", 1], ["maria", 1], ["patricia", 1]] "amanda" [["carol", 2], ["fabio", 1], ["fabiola", 1], ["jonas", 1], ["jose", 1]] "carol" [["amanda", 2], ["marcel", 2], ["fabiola", 1]] "fabio" [["amanda", 1], ["marcel", 1]] "fabiola" [["amanda", 1], ["carol", 1], ["marcel", 1]] "jonas" [["amanda", 1], ["jose", 1], ["maria", 1], ["paula", 1]] "jose" [["maria", 2], ["amanda", 1], ["jonas", 1], ["patricia", 1]] $python friends_recommender.py - r emr --num-ec2-instances 5 facebook_data.csv > output.dat marcel;jonas,maria,jose,amanda carol;maria,jose,patricia fabio;jonas,paula ...
- 111. Atepassar Recommendations http://atepassar.com fsim(u,i) = w1 f1(u,i) + w2 f2(u,i) + b, https://gist.github.com/3970945#file_atepassar_recommender.py
- 112. Atepassar Recommendations http://atepassar.com Celery - para agendamento dos jobs coletores e executores. mrJob - para mapreduce e acesso ao Hadoop MongoDb - para armazenamento das recomendações Boto - acesso aos files do S3.
- 113. A melhor parte!
- 114. Projetos interessantes Estrutura de dados para manipulação rápida - slicing - indexing - subseting Handling missing data Agregações, Séries Temporais Pandas: a data analysis library for Python, poised to give R a run for its money… http://pandas.pydata.org/
- 115. Projetos interessantes Outro framework para computação distribuída com Python com MapReduce. Criado pelo Instituto Nokia. Backend dele é escrito em Erlang (funcional, concorrente e bem escalável!) Não utiliza o FileSystem mais usado HDFS e sim um novo padrão por eles (DDFS). http://discoproject.org/
- 116. Projetos interessantes http://api.mongodb.org/python/2.0/examples/ map_reduce.html Python & MongoDb MongoDb - Banco de Dados Não relacional (NoSQL) Possui suporte nativo built-in para fazer MapReduce. Escrever o código em JS e não é muito legível e fica preso ao Mongo ... >>> reduce = Code("function (key, values) {" ... " var total = 0;" ... " for (var i = 0; i < values.length; i++) {" ... " total += values[i];" ... " }" ... " return total;" ... "}")
- 117. Projetos interessantes https://github.com/klbostee/dumbo/wiki/Short-tutorial Dumbo Uma das primeiras bibliotecas em cima do MapReduce e Python. Complicado para começar e está desatualizada :(
- 118. Projetos interessantes Um wrapper em Python em cima do Hadoop para computação distribuída. http://pydoop.sourceforge.net/docs/index.html Legal, mas dá um trabalho para configurar.
- 119. Projetos interessantes Mapreduce com Python na Google AppEngine https://developers.google.com/appengine/docs/python/ dataprocessing/ Ainda experimental e fica “preso” à plataforma AppEngine.
- 120. Projetos interessantes Algoritmos de aprendizagem de máquina Supervisionados & Não supervisionados Pré-processamento, extração de dados Avaliação de classificadores, Pipeline, seleção de atributos. http://scikit-learn.org/stable/
- 121. Projetos interessantes Processamento de linguagem natural Várias ferramentas para tokenização, pos tagging, named entity recognition, classificadores, etc. Vários corpus disponíveis! http://nltk.org/
- 122. Projetos interessantes Processamento de linguagem natural Várias ferramentas para tokenização, pos tagging, named entity recognition, classificadores, etc. Vários corpus disponíveis! http://nltk.org/ Fiquem de olho... Pipeline for distributed Natural Language Processing, made in Python https://github.com/NAMD/pypln
- 123. Projetos interessantes Our Project’s Home Page http://muricoca.github.com/crab
- 124. Future Releases Planned Release 0.13 New home for python-recsys: https://github.com/python-recsys/crab Planned Release 0.14 Support to Item-Based Recommenders using MapReduce with MrJob New commiters: vinnigracindo, ocelma, fcurella
- 125. Join us! 1. Read our Wiki Page https://github.com/muricoca/crab/wiki/Developer-Resources 2. Check out our current sprints and open issues https://github.com/muricoca/crab/issues 3. Forks, Pull Requests mandatory 4. Join us at irc.freenode.net #muricoca or at our discussion list http://groups.google.com/group/scikit-crab
- 127. Livros recomendados
- 133. BigData with Python A gentle and simple introduction Marcel Caraciolo @marcelcaraciolo Developer, Cientist, contributor to the Crab recsys project, works with Python for 6 years, interested at mobile, education, machine learning and dataaaaa! Recife, Brazil - http://aimotion.blogspot.com