Big Data Discovery
9 likes4,919 views

Oracle Big Data Discovery working together with Cloudera Hadoop is the fastest way to ingest and understand data. Powerful data transformation capabilities mean that data can quickly be prepared for consumption by the extended organisation.












































































Ad
More Related Content
What's hot (20)
Similar to Big Data Discovery (20)


















Ad
More from Harald Erb (12)












Ad
Recently uploaded (20)




















Big Data Discovery
- 1. Copyright © 2015, Oracle and/or its affiliates. All rights reserved.
- 2. Copyright © 2015, Oracle and/or its affiliates. All rights reserved.Copyright © 2015, Oracle and/or its affiliates. All rights reserved. | Big Data Discovery Relevante Informationen im Daten-Meer identifizieren und nutzbar machen Harald Erb Oracle Business Analytics OPITZ CONSULTING inspire|IT - Konferenz Frankfurt/Main, 11. Mai 2015
- 3. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. » Harald Erb » Principal Sales Consultant » Business Analytics Architecture Domain Lead - DE/CH Cluster » Kontakt +49 (0)6103 397-403 » [email protected] Referent
- 4. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Safe Harbor Statement The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any contract. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described for Oracle’s products remains at the sole discretion of Oracle. Safe Harbor Statement The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any contract. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described for Oracle’s products remains at the sole discretion of Oracle. 4
- 5. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 5
- 6. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 6 They ‘Reframe’ Challenges Looking at them from new perspectives and multiple angles They Sprint They work at pace - researching, testing and evaluating current ideas while generating new ones They Appreciate That Failure Can Be Good and are not afraid of new ideas They Convert Data Into Value They invest heavily in analyzing their own data and data from external sources to establish patterns and un-noticed opportunities Characteristics of Digital Business Leaders
- 7. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Data-driven Decisions 7 Identify(business)question Become clear about all aspects of the decision to be taken or the problem to be solved. Try to identify alternatives to your percep- tion Verifyearlierfindings Find out who has investi- gated such or a similar problem in the past and the approach that has been taken Designofasolutionmodel Formulate a detailled hypothesis how specific variables might influence the result of the chosen model Gatherallnecessarydata Analysethedata Present&implementresults Gather all available information about the variables of your hypo- thesis. The relevance of a dataset might address your business question directly or needs to be derived Apply a statistical model and evaluate the correctness of the approach. Repeat this procedure until the right method has been identified. Frame the results obtained in a compre- hensible story. This kind of presentation intends to motivate decision makers and relevant stake-holders to take action Non-Analysts & Executives: should take a closer look on steps 1 and 6 of the analysis process if they plan to make use of statistical analysis. Data Science + Knowledge Discovery Adopted from Thomas H. Davenport, Harvard Business Manager 2013
- 8. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 8 Vertical and Horizontal Data Science Skills Data Warehouse HorizontalVertical Deep technical skills Eigenvalues, Lasso-related regressions Experts in Bayesian networks, R Support Vector Machine Hadoop, NoSQL, Data Modeling, DW Cross-discipline knowledge Machine Learning & Statistics Visualization skills Domain expertise Storytelling experts Programming experience Aware of pitfalls & rules of thumb The Specialist The Unicorn Look for the individual Unicorn or build a Data Science Team?
- 9. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Enabling Data-driven Innovations in Organizations 9 Perf. Mgmt. Knowledge Discovery Dynamic Dashboards and Reports Volume and Fixed Reporting Knowledge Driven Business Process Executive: Decisions effecting strategy and direction Business Analysts: Day-to-Day performance of a business unit Information Consumer: Reporting on individual transactions Automated Process: Decisions effecting execution of an indiv. transactions Insight Data Scientists: Information analysis to meet strategic goals BICC Analytical Competence Center (ACC) » Separate group reporting to CxO. not part of a Business Intelligence Competence Center (BICC) » Mission: broadening the adoption of Analytics across the organization » Skilled resource pool of Data Scientists, Statisticians and Business Experts » Data-driven approach (not development-driven) with privileged access to enterprise data sources » Group will be assigned to projects for a limited time ACC
- 10. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 10 Information Management – Conceptual View Discovery Lab Innovation Discovery Output Events & Data Actionable Events Event Engine Data Reservoir Data Factory Enterprise Information Store Business Intelligence Actionable Information Actionable Insights Data Streams Execution Structured Enterprise Data Other Data Line of governance Source: Oracle White Paper “Information Management and Big Data – A Reference Architecture” ACC BICC
- 11. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. » Event Engine: Components which process data in-flight to identify actionable events and then determine next-best- action based on decision context and event profile data and persist in a durable storage system. » Data Reservoir: Economical, scale-out storage and parallel processing for data which does not have stringent requirements for formalisation or modelling. Typically manifested as a Hadoop cluster or staging area in a relational database. » Data Factory: Management and orchestration of data into and between the Data Reservoir and Enterprise Information Store as well as the rapid provisioning of data into the Discovery Lab for agile discovery. » Enterprise Information Store: Large scale formalised and modelled business critical data store, typically manifested by an (Enterprise) Data Warehouse. When combined with a Data Reservoir, these form a Big Data Management System. » Reporting: BI tools and infrastructure components for timely and accurate reporting. » Discovery Lab: A set of data stores, processing engines, and analysis tools separate from the everyday processing of data to facilitate the discovery of new knowledge of value to the business. This includes the ability to provision new data into the Discovery Lab from outside the architecture. » Execution: Flow of data for execution are tasks which support and inform daily operations » Innovation: Flow of data for innovation are tasks which drive new insights back to the business » Arranging solutions on either side of this division (as shown by the red line) helps inform system requirements for security, governance, and timeliness. Information Management – Conceptual View 11 Source: Oracle White Paper “Information Management and Big Data – A Reference Architecture”
- 12. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Discovery Lab: Design Pattern » Iterative development approach – data oriented NOT development oriented » Small group of highly skilled individuals (aka “Data Scientists” or a team organized as an Analytical Competence Center, ACC) with privileged access to enterprise data sources » Specific focus on identifying commercial value for exploitation » Wide range of tools and techniques applied » Typically separate infrastructure but could also be unified Reservoir if resource managed effectively » Data provisioned through Data Factory or own ETL processes ACC 12
- 13. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 13 Discovery Lab: Activity Cycles
- 14. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Discovery Lab: Data Provisioning 14 Analysis Processing & Delivery Discovery Lab & Development Environment Data Science (Primary Toolset) Statistics Tools Data & Text Mining Tools Faceted Query Tools Programming & Scripting Data Modelling Tools Query & Search Tools Pre-Built Intelligence Assets Intelligence Analysis Tools Ad Hoc Query & Analysis Tools OLAP Tools Forecasting & Simulation Tools Reporting Tools Virtualisation& InformationServices Data Factory flow ACC may quickly develop new reporting through mashups from any available internal and external sources and may used advanced analytical tools for innovative analysis Data Quality & Profiling Graphical rendering tools Dashboards & Reports Scorecards Charts & Graphs Sandbox – Project 3 Sandbox – Project 2 Sandbox – Project 1 Data store Analytical Processing General BI flow 1 2 The majority of BI development activity will be from existing sources – performed by the BICC developing new reports to existing or new channels Raw Data ACC BICC
- 15. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Need To Get Analytic Value Fast 15 Tool Complexity » Early Hadoop tools only for experts » Existing BI tools not designed for Hadoop » Emerging solutions lack broad capabilities 80% effort typically spent on evaluating and preparing data Data Uncertainty » Not familiar and overwhelming » Potential value not obvious » Requires significant manipulation Overly dependent on scarce and highly skilled resources
- 16. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Oracle Big Data Discovery 16
- 17. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 17 Oracle Big Data Discovery: The Visual Face of Hadoop find explore transform discover share
- 18. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Oracle Big Data Discovery: Components 18 Oracle Big Data Discovery Workloads Hadoop Cluster (Oracle Big Data Appliance or Commodity Hardware with Cloudera CDH 5.) BDD node data node data node data node data node name node Data Processing, Workflow & Monitoring • Profiling: catalog entry creation, data type & language detection, schema configuration • Sampling: dgraph (index) file creation • Transforms: >100 functions • Enrichments: location (geo), text (cleanup, sentiment, entity, key-phrase, whitelist tagging) Self-Service Provisioning & Data Transfer • Personal Data: Upload CSV and XLS to HDFS In-Memory Discovery Indexes • DGraph: Search, Guided Navigation, Analytics Studio • Web UI: Find, Explore, Transform, Discover, Share Hadoop 2.x Filesystem (HDFS) Workload Mgmt (YARN) Metadata (HCatalog) Other Hadoop Workloads MapReduce Spark Hive Pig Oracle Big Data SQL (Oracle Big Data Appliance only)
- 19. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Oracle Big Data Discovery: Deployment Example 19 Diagram adopted from RittmannMead, Blog, 2015
- 20. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 20 Oracle Big Data Discovery: Preparation of Data Sources Have to be created as Hive Tables and registered in the Hive Metastore Hive Table definition for fixed-width or delimited files Hive Table with a standard Regex SerDe (“Serializer-Deserializer”) to map more complex file structures by using Regular Expressions into regular table columns Hive Table using a custom developed SerDe to map nested file structures of a JSON file into regular table columns
- 21. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Big Data Discovery Upload of XLS und CSV files and automatic Hive Table creation HUE (Hadoop User Experience) Upload of various file formats, table creation wizzards, web-based Hive Query Client 21 Oracle Big Data Discovery: Preparation of Data Sources There are multiple ways to get new Data Sets loaded… Hive Command Line Interface is similar to the MySQL command line
- 22. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Oracle Big Data Discovery: Preparation of Data Sources 22 …or by using your favorite Data Integration / ETL Tool Oracle Data Integrator 12.1.3 with Advanced Big Data Option (Supporting HDFS, Hive, HBase, Scoop, Pig, Spark) IKM SQL to Hive- HBase-File (SQOOP) IKM File-Hive To Oracle (OLH, OSCH) File (FS/HDFS) IKM File To Hive (Load Data) Any RDBMS Oracle DB Any RDBMS IKM File-Hive to SQL (SQOOP) IKM Hive Transform IKM Hive Control Append Hive Hive HBase Hive Hive HBase LKM HBase to Hive IKM Hive to HBase
- 23. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 23 Data Processing Workflow including Profiling and Enrichment Oracle Big Data Discovery: Data Ingestion 1M of 100M Diagram Source: RittmannMead Blog, 2015
- 24. Copyright © 2015, Oracle and/or its affiliates. All rights reserved.Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 24 Demonstration Oracle Big Data Discovery Oracle Big Data Discovery Demonstration
- 25. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Catalog 25 » Access a rich, interactive catalog of all data in Hadoop » Familiar search and guided navigation for ease of use » See data set summaries, user annotation and recommendations » Provision personal and enterprise data to Hadoop via self- service
- 26. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Explore 26 » Visualize all attributes by type » Sort attributes by information potential » Assess attribute statistics, data quality and outliers » Use scratch pad to uncover correlations between attributes
- 27. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 2727 » Intuitive, user driven data wrangling » Extensive library of powerful data transformations and enrichments » Preview results, undo, commit and replay transforms » Test on sample data then apply to full data set in Hadoop Transform
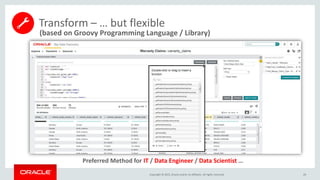
- 28. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 28 Preferred method for the Business Analyst Transform – User friendly…
- 29. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 29 (based on Groovy Programming Language / Library) Preferred Method for IT / Data Engineer / Data Scientist … Transform – … but flexible
- 30. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 30 » Join and blend data for deeper perspectives » Easy usage - compose project pages via drag and drop » Use powerful search and guided navigation to ask questions » See new patterns in rich, interactive data visualizations Discover
- 31. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 31 » Share projects, bookmarks and snapshots with others » Build galleries and tell big data stories » Collaborate and iterate as a team » Publish blended data to HDFS for leverage in other tools Share
- 32. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 32 Data Discovery & Analytics Lifecycle Typical Effort
- 33. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 33 Data Discovery & Analytics Lifecycle More Time left for Analysis and Interpretation of Results
- 34. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Analytics: More Data Variety available – Better Results 34 Example: Marketing Campaigns Getting „lift“ on responders Data Mining-based prediction results with Response Modelling including hundreds of input variables like: Naïve Guess or Random 1000 Population Size (% of Total Cases) %ofPositiveResponders Model with 20 variables Model with 75 variables Model with 250 variables » Demographic data » Purchase POS transactional data » Polystructured data, text & comments » Spatial location data » Long term vs. recent historical behaviour » Web visits » Sensor data » … 100
- 35. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Oracle R Enterprise (ORE) » Allows distributed processing of huge data volumes » Benefits from DB features, e.g. Security and SQL access » R Studio = GUI for Data Analysts 35 Oracle Data Mining (ODM) » Implemented in the Oracle Database kernel » Direct access via PL/SQL API and SQL operators » Oracle Data Miner GUI embedded in SQL Developer Oracle Advanced Analytics Native SQL Data Mining/Analytic Functions + High-performance R Integration
- 36. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 36 Monetizing New Insights
- 37. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Discovery Lab: End of Research Phase or Project Oracle Advanced Analytics Oracle Big Data Discovery Apply statistical & predictive models No Data Movement; Bring algorithms to the data Utilize Oracle R and Data Mining for Massive Computing Scalability on Hadoop or Oracle Integrated with SQL and BI tools Find data for analytics & data science projects Explore the shape and quality of the data Transform data for analytics Discover and visualize insights in data sets Share insights with analysts and downstream systems Share Insight Interpret & Evaluate Select, Prepare & Transform
- 38. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Documention of Analyis Steps Providing a clear view on probabilities 38 Storytelling / Infographics Discovery Lab: Explanation & Validation of the Results Individuals of the Analytical Competence Center need to frame the results obtained in a comprehensible story. This kind of presentation intends to motivate decision makers and relevant stake-holders to take action Result of 1000 simulations of a $100 million investment in a new factory: Estimation expects an annual return of 20% over a 10-year lifespan, but the risk to loose invested money is still 8%Big Data Discovery – Gallery feature documents all discovery steps taken to achieve new insights Example of individually created Infographics explaining key findings of new insights
- 39. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 39 Discovery and monetising steps have different requirements Making Sense from Diverse Data… Research & Development » Unbounded discovery » Self-Service sandbox » Wide toolset » Agile methods Promotion to Data-driven Services » Commercial exploitation » Narrower toolset » Integration to operations » Non-functional requirements » Code standardisation & governance
- 40. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Productize, Secure & Govern Experiment, Prototype & Collaborate Data Reservoir Polystructured Data Data Warehouse Oracle 12c Database StructuredData Oracle Big Data Discovery Oracle Big Data SQL Hadoop (HDFS) Oracle R for Hadoop Oracle Advanced Analytics (Data Mining, Oracle R Enterprise) Tables in Hadoop Tables in DB SQL join In-Memory Appliance Oracle BI Foundation Suite (ROLAP/MOLAP, Mobile,…) Oracle SQL Queries Exalytics Exadata Big Data Appliance … with an Unified Information Management Architecture Experiment, Prototype, Collaborate » Quickly find, explore, transform, analyze and share discoveries in Big Data Discovery » Publish results to the Hadoop Distributed File System (HDFS) » Use to build predictive models with Oracle R for Hadoop Productize, Secure, Govern » Connect published HDFS files to secure Oracle DB using Oracle Big Data SQL » No data movement required » Seamlessly extends existing DWH and BI investments with non- traditional data in Hadoop 40
- 41. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 41 Example Actionable Information: Enterprise Business Intelligence Self-service BI across all Data Sources Personalized access from everywhere
- 42. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 42 Actionable Insights: Predictive Business Intelligence Oracle Business Intelligence: Dashboards, Alerts,... » Understandable prediction results, Self-service BI » Making analysis results available to every business user, i.e. potential cross-selling effects to responsible Buyers » Operated by Business Analysts / BICC, etc. Oracle 12c In-Database Mining / Statistics » Operationalize Data Mining Models as part of Oracle BI Dashboards, calculated on-the-fly » Available query types: Classification & regression (incl. Multi-target problems), clustering, anomaly detection, feature extraction Predictive Query Example SELECT cust_income_level, cust_id , ROUND(probanom,2) AS probanom , ROUND(pctrank,3)*100 AS pctrank FROM (SELECT cust_id, cust_income_level, probanom , PERCENT_RANK() OVER (PARTITION BY cust_income_level ORDER BY probanom DESC) AS pctrank FROM (SELECT cust_id, cust_income_level , PREDICTION_PROBABILITY(OF ANOMALY,0 USING *) OVER (PARTITION BY cust_income_level) AS probanom FROM customers ) ) WHERE pctrank <= .05 ORDER BY cust_income_level, probanom DESC; Example (1/2)
- 43. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 43 Actionable Insights: Forward-looking Applications Example: Oracle Human Capital Management: »Includes Oracle Advanced Analytics factory-installed Predictive Analytics: »Employees likely to leave & predicted performance »Top reasons, expected behavior »Real-time "What if?" analysis Example (2/2)
- 44. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 44 Actionable Events: Intelligent Customer Experience iBeacons » Bluetooth Low Energy (BLE) » Optimized for small bursts of data. » Impressive battery Life » Ideal for sensors Requirements – Find purchase pattern from data of shopper’s purchase history – Leverage all the data, including real-time context from Beacon, CRM data, purchase history data, to improve the relevance of the offer – Leverage predictive models to alleviate the reliance on the rule based models – Being able to understand customer’s feedback on Beacon marketing Example (1/2)
- 45. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Actionable Events: Intelligent Customer Experience Solution Architecture Analysis and Offering Decision Engine Unstructured Text Analysis (VOC analysis) Rule Based Statistical Model-based Modeling Processing Real Time Offering Qualitative indices Text Mining Data Dictionary Text Analysis Collection Batch collection Real Time Collection Web Crawling Open API Storage and processing Utilization ETL TreatmentStore Hadoop File Reduce Map HDFS Datafile#1 HDFS Datafile#2 HDFS Datafile#n HDFS NoSQL DB Transaction (Key-Value) Stores Big Data Connectors Mobile Apps Unstructured Data Visualization Coupon Mileage ….. New information Keywords Visualization Search Vigan Visualization Dash Board Mobile Real Time Formal & Informal Integration Source system Other internal and external systems Beacon Time Phone Number Distance Beacon MAC Customer ….. Martial Status Customer Type Customer ID ….. Num of Children Occupation Gender Purchase Amount Product Customer ID ….. Quantity Date Smart App Web VOC SNS ODS DW Advanced Analytics on Purchase Pattern Example (2/2)
- 46. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. Actionable Events: Intelligent Customer Experience Solution Architecture – Product View Analysis and Offering Decision Engine Unstructured Text Analysis (VOC analysis) Rule Based Statistical Model-based Modeling Self-Learning Real Time Offering Qualitative indices Text Mining Data Dictionary Text Analysis Collection Batch collection Real Time Collection Web Crawling Open API Storage and processing Utilization ETL TreatmentStore Hadoop File Reduce Map HDFS Datafile#1 HDFS Datafile#2 HDFS Datafile#n HDFS NoSQL DB Transaction (Key-Value) Stores Big Data Connectors Mobile Apps Unstructured Data Visualization Coupon Mileage ….. New information Keywords Visualization Search Vigan Visualization Dash Board Mobile Real Time Formal & Informal Integration Source system Other internal and external systems Beacon Time Phone Number Distance Beacon MAC Customer ….. Martial Status Customer Type Customer ID ….. Num of Children Occupation Gender Purchase Amount Product Customer ID ….. Quantity Date Smart App Web VOC SNS ODS DW Advanced Analytics on Purchase Pattern Oracle Big Data Appliance Oracle Event Processing Endeca Information Discovery Oracle Advanced Analytics OracleDatabase Oracle Big Data Connectors Oracle Data Integrator Oracle Golden Gate Oracle Data Integrator Example (2/2)
- 47. Copyright © 2015, Oracle and/or its affiliates. All rights reserved. 47