Big Data Hadoop Local and Public Cloud (Amazon EMR)
8 likes2,106 views

The document outlines a hands-on workshop on running Hadoop on Amazon Elastic MapReduce (EMR). It provides instructions on setting up an AWS account and necessary services like S3 and EC2. It then guides attendees on writing a word count MapReduce program, packaging it into a JAR file, and running it on EMR. The document shares examples and code for performing common analytics tasks like aggregation, group-by operations, and frequency distributions using MapReduce on Hadoop.

























![Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 27
Wordcount (HelloWord in Hadoop)
38. public static void main(String[] args) throws Exception {
39. JobConf conf = new JobConf(WordCount.class);
40. conf.setJobName("wordcount");
41.
42. conf.setOutputKeyClass(Text.class);
43. conf.setOutputValueClass(IntWritable.class);
44.
45. conf.setMapperClass(Map.class);
46.
47. conf.setReducerClass(Reduce.class);
48.
49. conf.setInputFormat(TextInputFormat.class);
50. conf.setOutputFormat(TextOutputFormat.class);
51.
52. FileInputFormat.setInputPaths(conf, new Path(args[0]));
53. FileOutputFormat.setOutputPath(conf, new Path(args[1]));
54.
55. JobClient.runJob(conf);
57. }
58. }
59.](https://image.slidesharecdn.com/01bigdatahadoophandson2daysv3amazon-130715023540-phpapp01/85/Big-Data-Hadoop-Local-and-Public-Cloud-Amazon-EMR-27-320.jpg)















![Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 43
package analysis;
import java.io.IOException;
import java.util.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
import org.apache.hadoop.conf.*;
public class WebLogMessageSizeAggregator {
public static final Pattern httplogPattern = Pattern
.compile("([^s]+) - - [(.+)] "([^s]+) (/[^s]*) HTTP/[^s]+"
[^s]+ ([0-9]+)");
public static class AMapper extends MapReduceBase implements Mapper<LongWritable,
Text, Text, IntWritable> {
WebLogMessageSizeAggregator.java](https://image.slidesharecdn.com/01bigdatahadoophandson2daysv3amazon-130715023540-phpapp01/85/Big-Data-Hadoop-Local-and-Public-Cloud-Amazon-EMR-43-320.jpg)


![Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 46
output.collect(new Text("Mean"), new IntWritable((int) tot / count));
output.collect(new Text("Max"), new IntWritable(max));
output.collect(new Text("Min"), new IntWritable(min));
}
}
public static void main(String[] args) throws Exception {
JobConf job = new JobConf(WebLogMessageSizeAggregator.class);
job.setJarByClass(WebLogMessageSizeAggregator.class);
job.setMapperClass(AMapper.class);
job.setReducerClass(AReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
JobClient.runJob(job);
}
}
WebLogMessageSizeAggregator.java](https://image.slidesharecdn.com/01bigdatahadoophandson2daysv3amazon-130715023540-phpapp01/85/Big-Data-Hadoop-Local-and-Public-Cloud-Amazon-EMR-46-320.jpg)


![Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 49
public class WeblogHitsByLinkProcessor {
public static final Pattern httplogPattern = Pattern
.compile("([^s]+) - - [(.+)] "([^s]+) (/[^s]*) HTTP/[^s]+"
[^s]+ ([0-9]+)");
public static class AMapper extends MapReduceBase implements Mapper<LongWritable,
Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text,
IntWritable> output,Reporter reporter) throws IOException {
Matcher matcher = httplogPattern.matcher(value.toString());
if (matcher.matches()) {
String linkUrl = matcher.group(4);
word.set(linkUrl);
output.collect(word, one);
}
}
}
WeblogHitsByLinkProcessor.java](https://image.slidesharecdn.com/01bigdatahadoophandson2daysv3amazon-130715023540-phpapp01/85/Big-Data-Hadoop-Local-and-Public-Cloud-Amazon-EMR-49-320.jpg)



![Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 53
public class WeblogFrequencyDistributionProcessor {
public static final Pattern httplogPattern = Pattern.compile("([^s]+) - - [(.
+)] "([^s]+) (/[^s]*) HTTP/[^s]+" [^s]+ ([0-9]+)");
public static class AMapper extends MapReduceBase implements Mapper<LongWritable,
Text, Text, IntWritable> {
public void map(LongWritable key, Text value, OutputCollector<Text,
IntWritable> output,Reporter reporter) throws IOException {
String[] tokens = value.toString().split("s");
output.collect(new Text(tokens[0]),new
IntWritable(Integer.parseInt(tokens[1])));
}
}
WeblogFrequencyDistributionProcessor.java](https://image.slidesharecdn.com/01bigdatahadoophandson2daysv3amazon-130715023540-phpapp01/85/Big-Data-Hadoop-Local-and-Public-Cloud-Amazon-EMR-53-320.jpg)




Big Data Hadoop Local and Public Cloud (Amazon EMR)
- 1. Danairat T., 2013, [email protected] Data Hadoop – Hands On Workshop 1 Big Data Hadoop Local and Public Cloud Hands On Workshop Dr.Thanachart Numnonda [email protected] Danairat T. Certified Java Programmer, TOGAF – Silver [email protected], +66-81-559-1446
- 2. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 2 Hands-On: Running Hadoop on Amazon Elastic MapReduce
- 3. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 3 Architecture Overview of Amazon EMR
- 4. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 4 Creating an AWS account
- 5. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 5 Signing up for the necessary services ● Simple Storage Service (S3) ● Elastic Compute Cloud (EC2) ● Elastic MapReduce (EMR) Caution! This costs real money!
- 6. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 6 Creating Amazon EC2 Instance
- 7. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 7 Creating Amazon S3 bucket
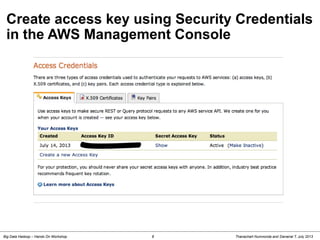
- 8. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 8 Create access key using Security Credentials in the AWS Management Console
- 9. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 9
- 10. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 10 Creating a new Job Flow in EMR
- 11. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 11
- 12. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 12
- 13. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 13
- 14. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 14
- 15. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 15
- 16. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 16
- 17. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 17
- 18. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 18 View Result from the S3 bucket
- 19. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 19 Lecture: Understanding Map Reduce Processing Client Name Node Job Tracker Data Node Task Tracker Data Node Task Tracker Data Node Task Tracker Map Reduce
- 20. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 20 MapReduce Framework map: (K1, V1) -> list(K2, V2)) reduce: (K2, list(V2)) -> list(K3, V3)
- 21. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 21 MapReduce Processing – The Data flow 1. InputFormat, InputSplits, RecordReader 2. Mapper - your focus is here 3. Partition, Shuffle & Sort 4. Reducer - your focus is here 5. OutputFormat, RecordWriter
- 22. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 22 How does the MapReduce work? Output in a list of (Key, List of Values) in the intermediate file Sorting Partitioning Output in a list of (Key, Value) in the intermediate file InputSplit RecordReader RecordWriter
- 23. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 23 How does the MapReduce work? Sorting Partitioning Combining Car, 2 Car, 2 Bear, {1,1} Car, {2,1} River, {1,1} Deer, {1,1} Output in a list of (Key, List of Values) in the intermediate file Output in a list of (Key, Value) in the intermediate file InputSplit RecordReader RecordWriter
- 24. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 24 Hands-On: Writing you own Map Reduce Program
- 25. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 25 Wordcount (HelloWord in Hadoop) 1. package org.myorg; 2. 3. import java.io.IOException; 4. import java.util.*; 5. 6. import org.apache.hadoop.fs.Path; 7. import org.apache.hadoop.conf.*; 8. import org.apache.hadoop.io.*; 9. import org.apache.hadoop.mapred.*; 10. import org.apache.hadoop.util.*; 11. 12. public class WordCount { 13. 14. public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { 15. private final static IntWritable one = new IntWritable(1); 16. private Text word = new Text(); 17. 18. public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { 19. String line = value.toString(); 20. StringTokenizer tokenizer = new StringTokenizer(line); 21. while (tokenizer.hasMoreTokens()) { 22. word.set(tokenizer.nextToken()); 23. output.collect(word, one); 24. } 25. } 26. }
- 26. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 26 Wordcount (HelloWord in Hadoop) 27. 28. public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { 29. public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { 30. int sum = 0; 31. while (values.hasNext()) { 32. sum += values.next().get(); 33. } 34. output.collect(key, new IntWritable(sum)); 35. } 36. } 37.
- 27. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 27 Wordcount (HelloWord in Hadoop) 38. public static void main(String[] args) throws Exception { 39. JobConf conf = new JobConf(WordCount.class); 40. conf.setJobName("wordcount"); 41. 42. conf.setOutputKeyClass(Text.class); 43. conf.setOutputValueClass(IntWritable.class); 44. 45. conf.setMapperClass(Map.class); 46. 47. conf.setReducerClass(Reduce.class); 48. 49. conf.setInputFormat(TextInputFormat.class); 50. conf.setOutputFormat(TextOutputFormat.class); 51. 52. FileInputFormat.setInputPaths(conf, new Path(args[0])); 53. FileOutputFormat.setOutputPath(conf, new Path(args[1])); 54. 55. JobClient.runJob(conf); 57. } 58. } 59.
- 28. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 28 Hands-On: Packaging Map Reduce and Deploying to Hadoop Runtime Environment
- 29. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 29 Packaging Map Reduce Program Usage Assuming HADOOP_HOME is the root of the installation and HADOOP_VERSION is the Hadoop version installed, compile WordCount.java and create a jar: $ mkdir /home/hduser/wordcount_classes $ cd /home/hduser $ javac -classpath /usr/local/hadoop/hadoop-core-0.20.205.0.jar -d wordcount_classes WordCount.java $ jar -cvf ./wordcount.jar -C wordcount_classes/ . $ hadoop jar ./wordcount.jar org.myorg.WordCount /input/* /output/wordcount_output_dir Output: ……. $ hadoop dfs -cat /output/wordcount_output_dir/part-00000
- 30. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 30 Hands-On: Running WordCount.jar on Amazon EMR
- 31. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 31 Upload .jar file and input file to Amazon S3 1. Select <yourbucket> in Amazon S3 service 2. Create folder : applications 3. Upload wordcount.jar to the applications folder 4. Create another folder: input 5. Upload input_test.txt to the input folder
- 32. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 32 Running a new Job Flow in EMR
- 33. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 33 Input JAR Location and Arguments
- 34. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 34
- 35. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 35
- 36. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 36
- 37. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 37
- 38. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 38 View the Result
- 39. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 39 Hands-On: Analytics Using MapReduce
- 40. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 40 Three Analytic MapReduce Examples 1. Simple analytics using MapReduce 2. Performing Group-By using MapReduce 3. Calculating frequency distributions and sorting using MapReduce
- 41. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 41 NASA weblog dataset available from http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html is a real-life dataset collected using the requests received by NASA web servers. Download the weblog dataset from ftp://ita.ee.lbl.gov/traces/NASA_ access_log_Jul95.gz and unzip it. We call the extracted folder as DATA_DIR. $ hadoopdfs -mkdir /data $ hadoopdfs -put <DATA_DIR>/NASA_access_log_Jul95 /data/input1 Preparing Example Data
- 42. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 42 Aggregative values (for example, Mean, Max, Min, standard deviation, and so on) provide the basic analytics about a dataset.. Simple analytics using MapReduce Source: Hadoop MapReduce CookBook
- 43. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 43 package analysis; import java.io.IOException; import java.util.*; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; import org.apache.hadoop.util.*; import org.apache.hadoop.conf.*; public class WebLogMessageSizeAggregator { public static final Pattern httplogPattern = Pattern .compile("([^s]+) - - [(.+)] "([^s]+) (/[^s]*) HTTP/[^s]+" [^s]+ ([0-9]+)"); public static class AMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { WebLogMessageSizeAggregator.java
- 44. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 44 public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException { Matcher matcher = httplogPattern.matcher(value.toString()); if (matcher.matches()) { int size = Integer.parseInt(matcher.group(5)); output.collect(new Text("msgSize"), new IntWritable(size)); } } } WebLogMessageSizeAggregator.java
- 45. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 45 public static class AReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException { double tot = 0; int count = 0; int min = Integer.MAX_VALUE; int max = 0; while (values.hasNext()) { int value = values.next().get(); tot = tot + value; count++; if (value < min) { min = value; } if (value > max) { max = value; } } WebLogMessageSizeAggregator.java
- 46. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 46 output.collect(new Text("Mean"), new IntWritable((int) tot / count)); output.collect(new Text("Max"), new IntWritable(max)); output.collect(new Text("Min"), new IntWritable(min)); } } public static void main(String[] args) throws Exception { JobConf job = new JobConf(WebLogMessageSizeAggregator.class); job.setJarByClass(WebLogMessageSizeAggregator.class); job.setMapperClass(AMapper.class); job.setReducerClass(AReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); JobClient.runJob(job); } } WebLogMessageSizeAggregator.java
- 47. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 47 Compile, Build JAR, Submit Job, Review Result $ cd /home/hduser $ javac -classpath /usr/local/hadoop/hadoop-core-0.20.205.0.jar -d WebLog WebLogMessageSizeAggregator.java $ jar -cvf ./weblog.jar -C WebLog . $ hadoop jar ./weblog.jar analysis.WebLogMessageSizeAggregator /data/* /output/result_weblog Output: ...... $ hadoop dfs -cat /output/result_weblog/part-00000
- 48. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 48 A MapReduce to group data into simple groups and calculate the analytics for each group. Performing Group-By using MapReduce Source: Hadoop MapReduce CookBook
- 49. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 49 public class WeblogHitsByLinkProcessor { public static final Pattern httplogPattern = Pattern .compile("([^s]+) - - [(.+)] "([^s]+) (/[^s]*) HTTP/[^s]+" [^s]+ ([0-9]+)"); public static class AMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException { Matcher matcher = httplogPattern.matcher(value.toString()); if (matcher.matches()) { String linkUrl = matcher.group(4); word.set(linkUrl); output.collect(word, one); } } } WeblogHitsByLinkProcessor.java
- 50. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 50 public static class AReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } result.set(sum); output.collect(key, result); } } WeblogHitsByLinkProcessor.java
- 51. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 51 Compile, Build JAR, Submit Job, Review Result $ cd /home/hduser $ javac -classpath /usr/local/hadoop/hadoop-core-0.20.205.0.jar -d WebLogHit WeblogHitsByLinkProcessor.java $ jar -cvf ./webloghit.jar -C WebLogHit . $ hadoop jar ./webloghit.jar analysis.WeblogHitsByLinkProcessor /data/* /output/result_webloghit Output: ...... $ hadoop dfs -cat /output/result_webloghit/part-00000
- 52. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 52 Frequency distribution is the number of hits received by each URL sorted in the Ascending order, by the number hits received by a URL. We have already calculated the number of hits inthe previous program. Calculating frequency distributions and sorting using MapReduce Source: Hadoop MapReduce CookBook
- 53. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 53 public class WeblogFrequencyDistributionProcessor { public static final Pattern httplogPattern = Pattern.compile("([^s]+) - - [(. +)] "([^s]+) (/[^s]*) HTTP/[^s]+" [^s]+ ([0-9]+)"); public static class AMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException { String[] tokens = value.toString().split("s"); output.collect(new Text(tokens[0]),new IntWritable(Integer.parseInt(tokens[1]))); } } WeblogFrequencyDistributionProcessor.java
- 54. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 54 /** * <p>Reduce function receives all the values that has the same key as the input, and it output the key * and the number of occurrences of the key as the output.</p> */ public static class AReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException { if(values.hasNext()){ output.collect(key, values.next()); } } } WeblogFrequencyDistributionProcessor.java
- 55. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 55 Compile, Build JAR, Submit Job, Review Result $ cd /home/hduser $ javac -classpath /usr/local/hadoop/hadoop-core-0.20.205.0.jar -d WebLogFreq WWeblogFrequencyDistributionProcessor.java $ jar -cvf ./weblogfreq.jar -C WebLogFreq . $ hadoop jar ./weblogfreq.jar analysis.WeblogFrequencyDistributionProcessor /output/result_webloghit/* /output/result_weblogfreq Output: ...... $ hadoop dfs -cat /output/result_weblogfreq/part-00000
- 56. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 56 Exercise: Runming the analytic programs on Amazon EMR.
- 57. Thanachart Numnonda and Danairat T, July 2013Big Data Hadoop – Hands On Workshop 57 Thank you