Big data on Azure for Architects
5 likes803 views

This document discusses big data concepts like volume, velocity, and variety of data. It introduces NoSQL databases as an alternative to relational databases for big data that does not require data cleansing or schema definition. Hadoop is presented as a framework for distributed storage and processing of large datasets across clusters of commodity hardware. Key Hadoop components like HDFS, MapReduce, Hive, Pig and YARN are described at a high level. The document also discusses using Azure services like Azure Storage, HDInsight and Stream Analytics with Hadoop.







































































































































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Big data on Azure for Architects (20)




















Ad
More from Tomasz Kopacz (17)

















Recently uploaded (20)




















Big data on Azure for Architects
- 1. 60 min
- 3. Data Complexity: Variety and Velocity Terabytes (1012) Gigabytes (109) Megabytes (106) Petabytes (1015) Exabyte (1018)
- 6. Reduces NoSQL: • No cleansing! • No ETL! • No load! • Analyze the data where it lands! Store now, question later RDBMS Data Arrives Derive a schema Cleanse the data Transform the data Load the data SQL Queries 1 2 3 4 5 6 Data Arrives Application Program 1 2 HOW?? IF I DON’T KNOW THE STRUCTURE?
- 16. Distributed Storage (HDFS) Query (Hive) Distributed Processing (MapReduce) DataIntegration (ODBC/SQOOP/REST) EventPipeline (EventHub/ Flume) Legend Red = Core Hadoop Blue = Data processing Gray= Microsoft integration points and value adds Orange = Data Movement Green = Packages YARN
- 17. Name Node de Data Node HDFS API DFS (1 Data Node per Worker Role) and Compute Cluster / VM Azure Storage (WASB) Benefits: Data reuse and sharing Data storage cost Elastic scale-out Geo-replication … Data Node Most important Benefit: Data are INDEPENDENT from cluster And WASB is FAST…
- 21. SOSP Paper - Windows Azure Storage: A Highly Available Cloud Storage Service with Strong Consistency http://nasuni.com Report link is here
- 22. M Extent Nodes (EN) Paxos Front End Layer FE Incoming Write Request M M Partition Server Partition Server Partition Server Partition Server Partition Master FE FE FE FE Lock Service Ack Partition Layer Stream Layer
- 23. Account Name Container Name Blob Name aaaa aaaa aaaaa …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. …….. zzzz zzzz zzzzz Storage Stamp Partition Server Partition Server Account Name Container Name Blob Name richard videos tennis ……… ……… ……… ……… ……… ……… zzzz zzzz zzzzz Account Name Container Name Blob Name harry pictures sunset ……… ……… ……… ……… ……… ……… richard videos soccer Partition Server Partition Master Front-End Server PS 2 PS 3 PS 1 A-H: PS1 H’-R: PS2 R’-Z: PS3 A-H: PS1 H’-R: PS2 R’-Z: PS3 Partition Map Blob Index Partition Map Account Name Container Name Blob Name aaaa aaaa aaaaa ……… ……… ……… ……… ……… ……… harry pictures sunrise A-H R’-ZH’-R
- 27. • Programming framework (library and runtime) for analyzing datasets stored in HDFS • Composed of user-supplied Map and Reduce functions: • Map() - subdivide and conquer • Reduce() - combine and reduce cardinality ……… Do work() Do work() Do work()
- 30. context.write(word, one); context.write(key, new IntWritable(sum)); wasb:///example/data/gutenberg/davinci.txt wasb:///example/data/WordCountOutput Start-AzureHDInsightJob Get-AzureStorageBlob Run in PS
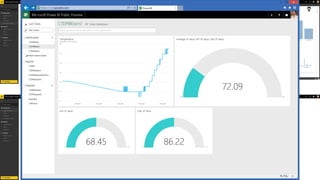
- 36. • It’s important to check that the results generated by queries are realistic, valid, and useful for better RoI • Automate tasks in a repeatable solution, and run the solution from a remote computer rather than directly from the cluster server desktop. • There’s a huge range of tools that you can use with Hadoop, and choosing the most appropriate can be difficult. • If you decide to use a resource-intensive application such as HBase or Storm, you should consider running it on a separate cluster.
- 37. Data-flow platform to transform and analyze HDFS data Scripting – No Java Needed! Focus on semantics, not on implementation Extensible through user defined functions and methods Pigs Eat Anything Pig can operate on data whether it has metadata or not. Pigs Live Anywhere Pig is not tied to one particular parallel framework. Pigs Are Domestic Animals Pig is designed to be easily controlled. Complex tasks involving interrelated data transformations can be simplified and encoded as data flow sequences. Pig programs accomplish huge tasks, but they are easy to write and maintain. Pigs Fly Pig processes data quickly. The system automatically optimizes execution of Pig jobs, so the user can focus on semantics.
- 39. LOGS = LOAD 'wasb:///example/data/sample.log'; LEVELS = foreach LOGS generate REGEX_EXTRACT($0, '(TRACE|DEBUG|INFO|WARN|ERROR|FATAL)', 1) as LOGLEVEL; FILTEREDLEVELS = FILTER LEVELS by LOGLEVEL is not null; GROUPEDLEVELS = GROUP FILTEREDLEVELS by LOGLEVEL; FREQUENCIES = foreach GROUPEDLEVELS generate group as LOGLEVEL, COUNT(FILTEREDLEVELS.LOGLEVEL) as COUNT; RESULT = order FREQUENCIES by COUNT desc; DUMP RESULT; STORE RESULT INTO 'tkR1'
- 43. Check result in PS
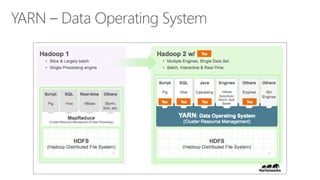
- 44. Hadoop 2.0
- 58. What is Machine Learning (ML) Solve extremely hard problems Extract more value from Big Data Drive a shift in business analytics
- 59. Business Knowledge Data Preparation Modelling Evaluation Data Understanding Idea Data Publish Machine Learning Process Model Based on the CRISP-DM Model
- 68. Volume,batchprocessing Events, Real Time processing
- 70. Relay Queue Topic Notification Hub Event Hub NAT and Firewall Traversal Service Request/Response Services Unbuffered with TCP Throttling. Hybrid Connection Transactional Cloud AMQP/HTTP Broker High-Scale, High-Reliability Messaging Sessions, Scheduled Delivery, etc. Transactional Message Distribution Up to 2000 subscriptions per Topic Up to 2K/100K filter rules per subscription High-scale notification distribution Most mobile push notification services Millions of notification targets EVENTS, MASSIVE SCALE
- 71. Event Producers > 1M Producers > 1GB/sec Aggregate Throughput Partitions Direct PartitionKey Hash Throughput Units: • 1 ≤ TUs ≤ Partition Count • TU: 1 MB/s writes, 2 MB/s reads • We pay for TU AMQP 1.0 Credit-based flow control Client-side cursors Offset by Id or Timestamp
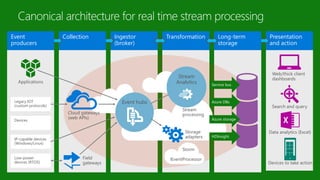
- 72. Ingestor (broker) Collection Presentation and action Event producers Transformation Long-term storage Event hubs Storage adapters Stream processingCloud gateways (web APIs) Field gateways Applications Legacy IOT (custom protocols) Devices IP-capable devices (Windows/Linux) Low-power devices (RTOS) Search and query Data analytics (Excel) Web/thick client dashboards Service bus Azure DBs Azure storage HDInsight Stream Analytics Devices to take action Storm IEventProcessor
- 81. Daughter jumping in garage Me with compressed (cold) air Me with small dryer
- 86. * Tick tuples scheme is Storm’s built-in mechanism for generating tuples and sending them to each bolt in the topology at specified intervals. Worth to check: https://storm.apache.org/apidocs/backtype/storm/topology/TopologyBuilder.BoltGetter.html
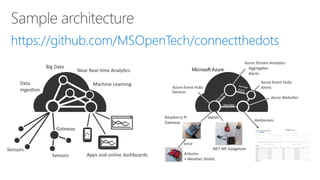
- 102. Compute Visualisation Orchestration Storage Service bus Event Hub Data Factory Power BI Stream Analytics HD Insight Machine Learning Virtual Machines Table Storage Blob Storage SQL Azure Document DB Feeds IoT Data Sources Near real time analysisData Journeys Azure
- 103. Compute Visualisation Orchestration Storage Service bus Event Hub Data Factory Power BI Stream Analytics HD Insight Machine Learning Virtual Machines Table Storage Blob Storage SQL Azure Document DB Feeds IoT Data Sources Near real time analysisPredictive Analytics Azure
- 104. Compute Visualisation Orchestration Storage Service bus Event Hub Data Factory Power BI Stream Analytics HD Insight Machine Learning Virtual Machines Table Storage Blob Storage SQL Azure Document DB Feeds IoT Data Sources Near real time analysisNear real time analysis Azure
- 105. Compute Visualisation Orchestration Storage Service bus Event Hub Data Factory Power BI Stream Analytics HD Insight Machine Learning Virtual Machines Table Storage Blob Storage SQL Azure Document DB Feeds IoT Data Sources Near real time analysisBig Data Azure
- 106. Compute Visualisation Orchestration Storage Service bus Event Hub Data Factory Power BI Stream Analytics HD Insight Machine Learning Virtual Machines Table Storage Blob Storage SQL Azure Document DB Feeds IoT Data Sources Near real time analysis“Traditional” BI Azure
- 108. [email protected]
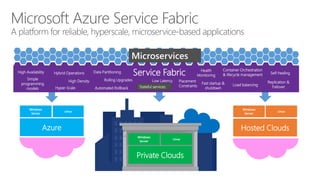
- 110. Azure Windows Server Linux Hosted Clouds Windows Server Linux Service Fabric Private Clouds Windows Server Linux High Availability Hyper-Scale Hybrid Operations High Density Microservices Rolling Upgrades Stateful services Low Latency Fast startup & shutdown Container Orchestration & lifecycle management Replication & Failover Simple programming models Load balancing Self-healingData Partitioning Automated Rollback Health Monitoring Placement Constraints