
























![map(func) Return a new distributed dataset formed
by passing each element of the source
through a function func.
flatMap(func) Similar to map, but each input item can be
mapped to 0 or more output items (so func
should return a Seq rather than a single
item).
reduceByKey(func, [numTasks]) When called on a dataset of (K, V) pairs,
returns a dataset of (K, V) pairs where the
values for each key are aggregated using
the given reduce function func, which must
be of type (V,V) => V.
groupByKey([numTasks]) When called on a dataset of (K, V) pairs,
returns a dataset of (K, Iterable<V>) pairs.
Transformations](https://image.slidesharecdn.com/bigdataopensourcecloudmunzkammermann-171006055136/85/Java-One-2017-Open-Source-Big-Data-in-the-Cloud-Hadoop-M-R-Hive-Spark-and-Kafka-27-320.jpg)




![Word Count and Histogram
munz & more #32
res =
t.flatMap(lambda line: line.split(" "))
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a + b)
res.takeOrdered(5, key = lambda x: -x[1])](https://image.slidesharecdn.com/bigdataopensourcecloudmunzkammermann-171006055136/85/Java-One-2017-Open-Source-Big-Data-in-the-Cloud-Hadoop-M-R-Hive-Spark-and-Kafka-32-320.jpg)



















Java One 2017: Open Source Big Data in the Cloud: Hadoop, M/R, Hive, Spark and Kafka
- 1. Open Source Big Data in OPC Edelweiss Kammermann Frank MunzJava One 2017
- 2. munz & more #2
- 3. © IT Convergence 2016. All rights reserved.
- 4. © IT Convergence 2016. All rights reserved. About Me à Computer Engineer, BI and Data Integration Specialist à Over 20 years of Consulting and Project Management experience in Oracle technology. à Co-founder and Vice President of Uruguayan Oracle User Group (UYOUG) à Director of Community of LAOUC à Head of BI Team CMS at ITConvergence à Writer and frequent speaker at international conferences: à Collaborate, OTN Tour LA, UKOUG Tech & Apps, OOW, Rittman Mead BI Forum à Oracle ACE Director
- 5. © IT Convergence 2016. All rights reserved. Uruguay
- 6. 6 Dr. Frank Munz •Founded munz & more in 2007 •17 years Oracle Middleware, Cloud, and Distributed Computing •Consulting and High-End Training •Wrote two Oracle WLS and one Cloud book
- 8. #1 Hadoop
- 9. © IT Convergence 2016. All rights reserved. What is Big Data? à Volume: The high amount of data à Variety: The wide range of different data formats and schemas. Unstructured and semi-structured data à Velocity: The speed which data is created or consumed à Oracle added another V in this definition à Value: Data has intrinsic value—but it must be discovered.
- 10. © IT Convergence 2016. All rights reserved. What is Oracle Big Data Cloud Compute Edition? à Big Data Platform that integrates Oracle Big Data solution with Open Source tools à Fully Elastic à Integrated with Other Paas Services as Database Cloud Service, MySQL Cloud Service, Event Hub Cloud Service à Access, Data and Network Security à REST access to all the funcitonality
- 11. © IT Convergence 2016. All rights reserved. Big Data Cloud Service – Compute Edition (BDCS-CE)
- 12. © IT Convergence 2016. All rights reserved. BDCS-CE Notebook: Interactive Analysis à Apache Zeppelin Notebook (version0.7) to interactively work with data
- 13. © IT Convergence 2016. All rights reserved. What is Hadoop? à An open source software platform for distributed storage and processing à Manage huge volumes of unstructured data à Parallel processing of large data set à Highly scalable à Fault-tolerant à Two main components: à HDFS: Hadoop Distributed File System for storing information à MapReduce: programming framework that process information
- 14. © IT Convergence 2016. All rights reserved. Hadoop Components: HFDS à Stores the data on the cluster à Namenode: block registry à DataNode: block containers themselves (Datanode) à HDFS cartoon by Mvarshney
- 15. © IT Convergence 2016. All rights reserved. Hadoop Components: MapReduce à Retrieves data from HDFS à A MapReduce program is composed by à Map() method: performs filtering and sorting of the <key, value> inputs à Reduce() method: summarize the <key,value> pairs provided by the Mappers à Code can be written in many languages (Perl, Python, Java etc)
- 16. © IT Convergence 2016. All rights reserved. MapReduce Example
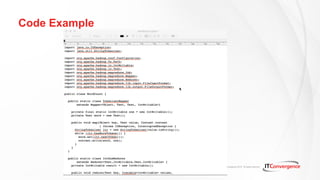
- 17. © IT Convergence 2016. All rights reserved. Code Example
- 18. © IT Convergence 2016. All rights reserved. Code Example
- 19. © IT Convergence 2016. All rights reserved. #2 Hive
- 20. © IT Convergence 2016. All rights reserved. What is Hive? à An open source data warehouse software on top of Apache Hadoop à Analyze and query data stored in HDFS à Structure the data into tables à Tools for simple ETL à SQL- like queries (HiveQL) à Procedural language with HPL-SQL à Metadata storage in a RDBMS
- 21. © IT Convergence 2016. All rights reserved. Hadoop & Hive Demo
- 22. #3 Spark
- 23. Revisited: Map Reduce I/O munz & more #23 Source: Hadoop Application Architecture Book
- 24. Spark • Orders of magnitude(s) faster than M/R • Higher level Scala, Java or Python API • Standalone, in Hadoop, or Mesos • Principle: Run an operation on all data -> ”Spark is the new MapReduce” • See also: Apache Storm, etc • Uses RDDs, or Dataframes, or Datasets munz & more #24 https://stackoverflow.com/questions/31508083/difference-between- dataframe-in-spark-2-0-i-e-datasetrow-and-rdd-in-spark https://www.usenix.org/system/files/conference/nsdi12/nsdi12-final138.pdf
- 25. RDDs Resilient Distributed Datasets Where do they come from? Collection of data grouped into named columns. Supports text, JSON, Apache Parquet, sequence. Read in HDFS, Local FS, S3, Hbase Parallelize existing Collection Transform other RDD -> RDDs are immutable
- 26. Lazy Evaluation munz & more #26 Nothing is executed Execution Transformations: map(), flatMap(), reduceByKey(), groupByKey() Actions: collect(), count(), first(), takeOrdered(), saveAsTextFile(), … http://spark.apache.org/docs/2.1.1/programming-guide.html
- 27. map(func) Return a new distributed dataset formed by passing each element of the source through a function func. flatMap(func) Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). reduceByKey(func, [numTasks]) When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. groupByKey([numTasks]) When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs. Transformations
- 30. Spark Demo munz & more #30
- 31. Apache Zeppelin Notebook munz & more #31
- 32. Word Count and Histogram munz & more #32 res = t.flatMap(lambda line: line.split(" ")) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b) res.takeOrdered(5, key = lambda x: -x[1])
- 33. Zeppelin Notebooks munz & more #33
- 34. Big Data Compute Service CE munz & more #34
- 35. #4 Kafka
- 36. Kafka Partitioned, replicated commit log munz & more #36 0 1 2 3 4 … n Immutable log: Messages with offset Producer Consumer A Consumer B https://www.quora.com/Kafka-writes-every-message-to-broker-disk-Still-performance-wise-it- is-better-than-some-of-the-in-memory-message-storing-message-queues-Why-is-that
- 37. Broker1 Broker2 Broker3 Topic A (1) Topic A (2) Topic A (3) Partition / Leader Repl A (1) Repl A (2) Repl A (3) Producer Replication / Follower Zoo- keeper Zoo- keeper Zoo- keeper State / HA
- 38. https://www.confluent.io/blog/publishing-apache-kafka-new-york-times/ - 1 topic - 1 partition - Contains every article published since 1851 - Multiple producers / consumers Example for Stream / Table Duality
- 39. Kafka Clients SDKs Connect Streams - OOTB: Java, Scala - Confluent: Python, C, C++ Confluent: - HDFS sink, - JDBC source, - S3 sink - Elastic search sink - Plugin .jar file - JDBC: Change data capture (CDC) - Real-time data ingestion - Microservices - KSQL: SQL streaming engine for streaming ETL, anomaly detection, monitoring - .jar file runs anywhere High / low level Kafka API Configuration only Integrate external Systems Data in Motion Stream / Table duality REST - Language agnostic - Easy for mobile apps - Easy to tunnel through FW etc. Lightweight
- 40. Oracle Event Hub Cloud Service • PaaS: Managed Kafka 0.10.2 • Two deployment modes – Basic (Broker and ZK on 1 node) – Recommended (distributed) • REST Proxy – Separate sever(s) running REST Proxy munz & more #40
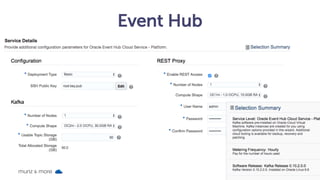
- 41. Event Hub munz & more #41
- 42. Event Hub Service munz & more #42
- 43. Ports You must open ports to allow access for external clients • Kafka Broker (from OPC connect string) • Zookeeper with port 2181 munz & more #43
- 44. Scaling munz & more #44 horizontal (up)vertical
- 45. Event Hub REST Interface munz & more #45 https://129.151.91.31:1080/restproxy/topics/a12345orderTopic Service = Topic
- 46. Interesting to Know • Event Hub topics are prefixed with ID domain • With Kafka CLI topics with ID Domain can be created • Topics without ID domain are not shown in OPC console 46
- 47. #5 Conclusion
- 48. TL;DR #bigData #openSource #OPC OpenSource: entry point to Oracle Big Data world / Low(er) setup times / Check for resource usage & limits in Big Data OPC / BDCS-CE: managed Hadoop, Hive, Spark + Event hub: Kafka / Attend a hands-on workshop! / Next level: Oracle Big Data tools @EdelweissK @FrankMunz
- 49. www.linkedin.com/in/frankmunz/ www.munzandmore.com/blog facebook.com/cloudcomputingbook facebook.com/weblogicbook @frankmunz youtube.com/weblogicbook -> more than 50 web casts Don’t be shy J
- 51. 3 Membership Tiers • Oracle ACE Director • Oracle ACE • Oracle ACE Associate bit.ly/OracleACEProgram 500+ Technical Experts Helping Peers Globally Connect: Nominate yourself or someone you know: acenomination.oracle.com @oracleace Facebook.com/oracleaces [email protected]
- 52. Sign up for Free Trial http://cloud.oracle.com