Simple, Modular and Extensible Big Data Platform Concept
4 likes2,063 views

Few slides outlining a simple, modular and extensible big data platform concept, leveraging the growing ecosystem.














































Ad
More Related Content
What's hot (20)
Similar to Simple, Modular and Extensible Big Data Platform Concept (20)


















Ad
Recently uploaded (20)




















Ad
Simple, Modular and Extensible Big Data Platform Concept
- 1. Beyond the Big Elephant Satish Mohan
- 2. Data Big data ecosystem is evolving and changing rapidly. • Data grows faster than Moore’s law • massive, unstructured, and dirty • don’t always know what questions to answer • Driving architectural transition • scale up -> scale out • compute, network, storage 0 2 4 6 8 10 12 14 2010 2011 2012 2013 2014 2015 Moore's Law Overall Data
- 3. Growing Landscape Databases / Data warehousing Dremel Hadoop Data Analysis & Platforms Operational Big Data search Business Intelligence Data Mining jHepWork Social Corona Graphs Document Store Raven DB KeyValue Multimodel Object databases Picolisp XML Databses Grid Solutions Multidimensional Multivalue database Data aggregation Created by: www.bigdata-startups.com
- 4. Growing Landscape Databases / Data warehousing Dremel Hadoop Data Analysis & Platforms Operational Big Data search Business Intelligence Data Mining jHepWork Social Corona Graphs Document Store Raven DB KeyValue Multimodel Object databases Picolisp XML Databses Grid Solutions Multidimensional Multivalue database Data aggregation Created by: www.bigdata-startups.com A major driver of IT spending • $232 billion in spending through 2016 (Gartner) • $3.6 billion injected into startups focused on big data (2013) ! ! ! Wikibon big data market distribution ! ! ! ! Services 44% Software 19% Hardware 37% http://wikibon.org/wiki/v/Big_Data_Vendor_Revenue_and_Market_Forecast_2012-2017
- 5. Ecosystem Challenges • Building a working data processing environment has become a challenging and highly complex task. • Exponential growth of the frameworks, standard libraries and transient dependencies • Constant flow of new features, bug fixes, and other changes are almost a disaster • Struggle to convert early experiments into a scalable environment for managing data (however big) !
- 6. Ecosystem Challenges • Extract business value from diverse data sources and new data types • Deeper analytics requires users to build complex pipelines involving ML algorithms • Apache Mahout on Hadoop • 25 production quality algorithms • only 8-9 can scale over large data sets • New use-cases require integration beyond Hadoop
- 7. Apache Hadoop • The de-facto standard for data processing is rarely, if ever, used in isolation. • input comes from other frameworks • output get consumed by other frameworks • Good for batch processing and data-parallel processing • Beyond Hadoop Map-Reduce • real-time computation and programming models • multiple topologies, mixed workloads, multi-tenancy • reduced latency between batch and end-use services
- 8. Hadoop Ecosystem - Technology Partnerships Jan 2013 Data, Datameer Hadoop software distribution ties into Active Directory, Microsoft's System Center, and Microsoft virtualization technologies to simplify deployment and management.
- 9. Platform Goals An integrated infrastructure that allows emerging technologies to take advantage of our existing ecosystem and keep pace with end use cases • Consistent, compact and flexible means of integrating, deploying and managing containerised big data applications, services and frameworks • Unification of data computation models: batch, interactive, and streaming. • Efficient resource isolation and sharing models that allow multiple services and frameworks to leverage resources across shared pools on demand • Simple, Modular and Extensible
- 10. Key Elements Resource Manager Unified Framework Applications / Frameworks / Services DistributedStorage AbstractAPIs
- 11. Platform - Core Applications / Services / Frameworks Unified Framework Distributed Storage SPARK AbstractAPIs RedHatStorage Resource Manager MESOS SharkSQL Streaming Core Partner Community
- 12. Platform - Extend through Partnerships Applications / Services / Frameworks Unified Framework Distributed Storage SPARK AbstractAPIs RedHatStorage HDFS Tachyon MapR Resource Manager MESOS YARN SharkSQL Streaming GraphX MLlib BlinkDB Hadoop Hive Storm MPI Marathon Chronos Core Partner Community
- 13. Perfection is not the immediate goal. Abstraction is what we need
- 14. Backup Slides
- 15. Mesos - mesos.apache.org An abstracted scheduler/executor layer, to receive/consume resource offers and thus perform tasks or run services, atop a distributed file system (RHS by default) • Fault-tolerant replicated master using ZooKeeper • Scalability to 10,000s of nodes • Isolation between tasks with Linux Containers • Multi-resource scheduling (memory and CPU aware) • Java, Python and C++ APIs • scalability to 10,000s of nodes • Primarily written in C++ ! ! Resource Manager
- 16. Spark - spark.incubator.apache.org Unified framework for large scale data processing. • Fast and expressive framework interoperable with Apache Hadoop • Key idea: RDDs “resilient distributed datasets” that can automatically be rebuilt on failure • Keep large working sets in memory • Fault tolerance mechanism based on “lineage” • Unifies batch, streaming, interactive computational models • In-memory cluster computing framework for applications that reuse working sets of data • Iterative algorithms: machine learning, graph processing, optimization • Interactive data mining: order of magnitude faster than disk-based tools ! • Powerful APIs in Scala, Python, Java • Interactive shell ! Unified Framework Streaming Interactive Batch Unified Framework
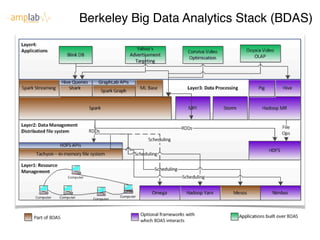
- 17. Berkeley Big Data Analytics Stack (BDAS) 7 Berkeley Big-data Analytics Stack (BDAS) 7 Berkeley Big-data Analytics Stack (BD y Big-data Analytics Stack (BDAS) 7 Berkeley Big-data Analy