บทความ Big Data จากบล็อก thanachart.org
13 likes5,055 views

รวมรวมบทความด้าน Big Data ของดร.ธนชาติ นุ่มนนท์ ที่เขียนตั้งแต่ปั 2556 จนถึงปัจจุบัน

























![CHAPTER 4
การคาดการณ์แนวโน้มของ Big
Data
เม่ือวานน้ีทาง IMC Institute จัดงานฟรีสัมมนาร่วมกับ Computerlogy
ภายใต้หัวข้อ Big Data: From Data to Business Insight โดยมีผู้เข้าร่วม
สัมมนาประมาณ 100 คน หัวข้อท่ีผมไปบรรยายในงานสัมมนาน้ีคือ
Forecast of Big Data Trends เพ่ือให้ผู้เข้าร่วมสัมมนาทราบถึงแนวโน้ม
ของ Big Data โดยมี Slide ท่ีใช้ในการบรรยายดังน้ี
[slideshare id=38628120&w=427&h=356&style=border: 1px
solid #CCC; border-width: 1px; margin-bottom: 5px; max-width:
100%;&sc=no]
Forecast of Big Data Trends from IMC Institute](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-27-320.jpg)






![รูปท่ี 1 Hadoop Lifecycle [Source: Rackspace]
การแก้ปัญหาในเร่ืองการจัดหา Server อาจทำาได้โดยการใช้ระบบ
Public Cloud ซ่ึงก็จะเป็นการลดค่่าใช้จ่ายขององค์กร ท้ังน้ีรูปแบบของ
การใช้ Hadoop บน Public Cloud มีสองแบบคือ
1. ติดต้ัง Hadoop Cluster โดยใช้ Virtual Server ในระบบ Public
IaaS Cloud อย่าง Amazon Web Services (AWS) หรือ
Microsoft Azure กรณีน้ีจะใช้ในกรณีท่ีเราจะต้องการนำา Hadoop
มาใช้ในการเก็บข้อมูลขนาดใหญ่โดยใช้ HDFS และใช้ในการ
วิเคราะห์ข่้อมูลโดยใช้เคร่ืองมืออย่าง MapReduce, Hive, Pig
2. การใช้บริการ Hadoop as a Service ของ Public Cloud
Provider ท่ีได้ติดต้ังระบบ Hadoop ไว้แล้ว และเราต้องการใช้ระบบ
ท่ีมีอยู่เช่น MapReduce, Hive, Pig มาใช้ในการวิเคราะห์ข้อมูล ท้ังน้ี
ข้อมูลท่ีจะนำามาวิเคราะห์อาจอยู่ในองค์กรเราหรือเก็บไว้ท่ีอ่ืน
การใช้ Public Cloud ในกรณีท่ี 1 ถ้ามีข้อมูลขนาดใหญ่มาก ก็อาจจะมี
ค่าใช้จ่ายท่ีสูง ย่ิงถ้ามีจุดประสงค์เพ่ือท่ีจะใช้ในการเก็บข้อมูลแบบ
Unstructure ก็ดูอาจไม่คุ้มค่านัก แต่ก็มีข้อดีท่ีมีระบบ Hadoop Cluster
ท่ีติดต้ังเองและไม่ต้องใช้ร่วมกับคนอ่ืน ผู้เขียนเองเคยทดลองติดต้ังระบบ
แบบน้ีโดยใช้ Azure HDInsight และทดลองติดต้ัง Hadoop CloudEra
26 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-34-320.jpg)




















![หลายๆท่ี และเป็นระบบท่ีเป็น Horizontal Scale ท่ีรันบนเคร่ือง
commodity server จำานวนมาก Hadoop Project เร่ิมต้นโดย Doug
Cutting และ Mike Cafarella ท่ีเป็นทีมงานของบริษัท Yahoo ซ่ึงต่อมาก็มี
บริษัทอ่ืนๆนำาไปใช้กันอย่างมากท้ัง eBay, Facebook และ Amazon รวม
ถึงมีบริษัทหลายๆรายท่ีนำามา Hadoop มาทำา Commercial
Distribution อาทิเช่น Cloudera, MapR, IBM Infoshphere
BigInsight, Hortonwork หรือ Amazon Elastic Map Reduce
รูปท่ี 1: Hadoop Environment [Source: Hadoop in Practice; Alex
Holmes]
Hadoop เวอร์ช่ันแรกจะมีองค์ประกอบหลักสองส่วนคือ
• HDFS (Hadoop Distribution File System) ท่ีทำาหน้าท่ีเป็นส่วนเก็บ
ข้อมูลซ่ึงจะเก็บข้อมูลขนาดใหญ่ท่ีจะแบ่งเป็นไฟล์ย่อยขนาดใหญ่เก็บลง
ใน Data Node จำานวนมาก โดยจะมี Master Node ท่ีทำาหน้าท่ีระบุ
ตำาแหน่งของข้อมูลท่ีเก็บใน Data node
• Map/Reduce จะเป็นส่วนประมวลผลข้อมูล ท่ีนักพัฒนาสามารถเขียน
โปรแกรมโดยใช้ภาษาจาวามาวิเคราะห์ข้อมูลในรูปแบบของฟังก์ชันการ
Map และ Reduce ได้ โดยระบบก็จะกระจาย Task ไปรันแบบ Parallel
บนเคร่ืองหลายๆเคร่ือง
48 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-56-320.jpg)

![รูปท่ี 2: Hadoop Architecture [Source: Hadoop in Practice; Alex
Holmes]
Hadoop Ecosystem
ระบบ Hadoop เองจะมีองค์ประกอบหลักอยู่แค่สองส่วนคือ HDFS และ
Map/Reduce ซ่ึงค่อนข้างจะไม่สะดวกกับผู้ใช้งานท่ีมีความต้องการอ่ืนๆ
เช่น การประมวลผลโดยใช้ภาษา SQL การเขียนหรืออ่านข้อมูลแบบ
Random access หรือการถ่ายโอนข้อมูลจากท่ีอ่ืนๆ จึงมีการพัฒนาโปร
เจ็คอ่ืนๆท่ีมาทำางานร่วมกับ Hadoop เพ่ือให้ได้ประสิทธิภาพดีย่ิงข้ึน ดัง
แสดงตัวอย่างในรูปท่ี 3 ซ่ึงมีเคร่ืองมือท่ีสำาคัญดังน้ี
50 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-58-320.jpg)
![รูปท่ี 3: Hadoop Ecosystem [Source: Big Data Analytics with
Hadoop: Phillippe Julio]
• Hive เป็นเคร่ืองมือสำาหรับผู้ต้องการสืบค้น (Query) ข้อมูลท่ีเก็บใน
HDFS ด้วยภาษาลักษณะ SQL แทนท่ีจะต้องมาเขียนโปรแกรม Map/
Reduce โดย Hive จะทำาหน้าท่ีในการแปล SQL like ให้มาเป็น Map/
Reduce แล้วก็ทำาการรันแบบ Batch
• Pig เป็นเคร่ืองมือคล้ายๆกับ Hive ท่ีช่วยให้ประมวลผลข้อมูลโดยไม่
ต้องเขียนโปรแกรม Map/Reduce ซ่ึง Pig จะใช้โปรแกรมภาษา script
ง่ายๆท่ีเรียกว่า Pig Latin แทน โดย Pigเหมาะกับการทำา ETL สำาหรับ
การแปลงข้อมูลในรูปแบบต่างๆเช่น JSON
• Sqoop เป็นเคร่ืองมือในการถ่ายโอนข้อมูลระหว่างฐานข้อมูลท่ีอยู่
รูปแบบ Table บน RDBMS อย่าง SQL server, Oracle หรือ MySQL
กับข้อมูลบน HDFS ของ Hadoop
• Flume เป็นเคร่ืองมือในการดึงข้อมูลจากระบบอ่ืนๆแบบ Realtime เข้า
สู่ HDFS เช่นการดึง Log จาก Web Server การดึงข้อมูลเหล่าน้ีจะต้อง
มีการติดต้ัง Agent ท่ีเคร่ือง Server
HADOOP ECOSYSTEM สำาหรับการพัฒนา BIG DATA 51](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-59-320.jpg)
![• HBase เป็นเคร่ืองมือท่ีจะทำาให้ Hadoop สามารถอ่านและเขียนข้อมูล
แบบ Realtime Random Access ได้โดยจะทำาให้เป็น BigTable ท่ีเก็บ
ข้อมูลได้ไม่จำากัด row หรือ column ซ่ึง HBase ก็จะเป็นเสมือนการ
ทำาให้ Hadoop เป็น NoSQL Database
• Oozie เป็นเคร่ืองมือในการทำา Work]ow จะช่วยให้เราเอาคำาส่ัง
ประมวลผลต่างๆของระบบ Hadoop เช่น Map/Reduce, Hive หรือ
Pig มาเช่ือมต่อกันในรูปของ Work]ow ได้
• Hue ย่อมาจากคำาว่า Hadoop User Experience เป็นเคร่ืองมือช่วย
ทำา User interface ของ Hadoop ให้ใช้งานได้ง่ายข้ึนกว่าการต้องใช้
command line
• Mahout เป็นเคร่ืองมือของ Data Scientist ท่ีต้องการทำาPredictive
Analytics ข้อมูลบน Hadoop โดยใช้ภาษาจาวา ท้ังน้ี Mahout
สามารถใช้ Algorithm ท่ีเป็น Recommender, Classication และ
Clustering ได้
Hadoop 2.0
Hadoop เวอร์ช่ันแรกมีข้อจำากัดหลายประการอาทิเช่น ระบบการสำารอง
ของ Secondary Master เป็นแบบ Passive และไม่สามารถทำา Multiple
Master ได้จึงจำากัดเคร่ือง Slave ไว้ไม่เกิน 4,000 เคร่ือง และขัอสำาคัญการ
ประมวลผลต้องใช้ Map/Reduce ท่ีเป็นแบบ Batch ดังน้ันจึงมีการพัฒนา
Hadoop 2.0 ท่ีจะลดข้อจำากัดต่างๆ Hadoop เวอร์ช่ันน้ีจะมี
สถาปัตยกรรมดังรูปท่ี 4 โดยมีการนำา Data Opeating System ท่ีเรียกว่า
YARN (Yet Another Resource Negotiator) เข้ามา
52 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-60-320.jpg)



![รูปท่ี 1 ทักษะของ Data Scientist
[source 1=”<a” href=”http://www.edureka.co/data-science”
2=”2=”target=”_blank”>www.edureka.in/data-science</a>””
language=”:”][/source]
จริงๆแล้วการทำา Predictive Analytics ไม่ใช่เร่ืองใหม่ แต่การคาด
การณ์ต่างๆจะมีความแม่นยำาและใก้ลเคียงกับความจริงมากข้ึนถ้ามีข้อมูล
จำานวนมากข้ึน ดังน้ันเทคโนโลยี Big Data จึงทำาให้การคาดการณ์ต่างๆ
แม่นยำาข้ึน และการมีข้อมูลขนาดใหญ่จะมีประโยชน์มากย่ิงข้ึนถ้าเรา
สามารถทำา Predictive Analytics ซ่ึงเราจะเห็นได้ว่ากรณีน้ีมีความแตก
ต่างกันกับ Business Intelligence (BI)
• BI คือการดู Business Insight เพ่ือให้ทราบว่าข้อมูลท่ีผ่านมาเป็น
อย่างไร โดยนำาเสนอในมุมมองต่างๆ ท้ังในรูปแบบของรายงาน กราฟ
หรือ Dashboard
• Predictive Analytics คือการคาดการณ์อนาคตโดยใช้โมเดล
คณิตศาสตร์ท่ีต้องใช้ข้อมูลจำานวนมากและอาจจะมาจากหลายแหล่ง
56 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-64-320.jpg)
![รูปท่ี 2 เคร่ืองมือและเทคโนโลยีของ Data Science
[source 1=”<a” href=”http://www.edureka.co/data-science”
2=”2=”target=”_blank”>www.edureka.in/data-science</a>””
language=”:”][/source]
เทคโนโลยี Big Data ทำาให้ Data Scentist มีเคร่ืองมือท่ีหลากหลาย
ข้ึน ท้ังในการเก็บข้อมูลเช่น RDBMS ในรูปแบบเดิม หรือ NoSQL อย่าง
MongoDB หรือ unstructure storage อย่าง Hadoop HDFS ท้ัง
เคร่ืองมือในการถ่ายโอนข้อมูลอย่าง Sqoop หรือ Flume และเคร่ืองมือ
หรือภาษาในการวิเคราะห์ข้อมูลอย่าง Java, R, Mahout และเน่ืองจาก
ข้อมูลในปัจจุบันส่วนใหญ่เป็น unstructure data ก็เลยทำาให้ Hadoop
กลายเป็นเคร่ืองมือท่ีน่าสนใจท่ีสุดของ Big Data เพราะนอกจากสามารถท่ี
จะเก็บข้อมูลขนาดใหญ่ได้แล้ว ยังมีเคร่ืองมือท่ีช่วยในการวิเคราะห์ข้อมูลท่ี
หลากหลาย
DATA SCIENTIST กับเทคโนโลยี BIG DATA: HADOOP,
MAPREDUCE, R และ MAHOUT
57](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-65-320.jpg)
![รูปท่ี 3 หน้าท่ีของ Data Science
[source 1=”<a” href=”http://www.edureka.co/data-science”
2=”2=”target=”_blank”>www.edureka.in/data-science</a>””
language=”:”][/source]
สุดท้ายเพ่ือให้เข้าใจว่า Data Scientist ทำาอะไรจากเทคโนโลยีต่างๆท่ีมี
อยู่ ลองพิจารณาดูรูปท่ี 3 จะเห็นว่าจะมีการกล่าวถึงเทคโนโลยีต่างๆ เช่น
เคร่ืองมือในการรวบรวมข้อมูลท่ีทำา ETL เคร่ืองมือในการเก็บข้อมูลอย่าง
Hadoop เคร่ืองมือในการวิเคราะห์ข้อมูลอย่าง R, Hive, Pig, Java,
Mahout เคร่ืองมือในการแสดงผลอย่าง Dashboard, Web App และ
เคร่ืองมือในการพยากรณ์ข้อมูลท่ีทำา Machine Learning จากรูปจะเห็น
ได้ว่าบทบาทของ Data Scientist จะคาบเก่ียวกับบทบาทของ Data
Architecture/Management และ Analytics โดย Data Sceintist จะ
ต้องใช้เคร่ืองมือต่างๆท้ัง Hadoop, R, MapReduce หรือ Mahout ใน
การวืเคราะห์ข้อมูล รวมถึงมีการใช้ Algorithm สำาหรับ Machine
Learning
• R เป๋็นภาษาท่ีสามารถใช้ในการวิเคราะห์ข้อมูลได้
• Mahout เป็นเคร่ืองมือท่ีใช้ในการวิเคราะห์ Large Scale Data บน
Hadoop โดย Mahout จะมี Library สำาหรับ Predictive Analytics
สามด้านคือ Recommender, Clustering และ Classication
การพัฒนาหรือหา Data Scientist คงไม่ใช่ง่าย และไม่สามารถทำาได้โดย
ระยะเวลาอันส้ัน จากข้อมูลการสำารวจส่วนใหญ่ก็จะต้องเป็นท่ีมีพ้ืนฐานทาง
58 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-66-320.jpg)







![NoSQL, NewSQL หรือ Hadoop เข้ามาใช้ ตัวอย่างเช่นทุกวันน้ีบริษัท
ผู้ให้บริการมือถือท่ีต้องเก็บ CDR (Call Detail Record) ท่ีมีข้อมูลหลาย
TB ต่อวันทำาให้ไม่สามารถเก็บไว้ใน RDBMS ได้ในระยะเวลานานได้ จึง
ต้องมีการนำาเทคโนโลยีอย่าง Hadoop มาเพ่ือให้สามารถเก็บข้อมูลได้
นานข้ึน และนำาข้อมูลระยะยาวมาวิเคราะห์ได้
• Hadoop คือเคร่ืองมือในกำรทำำ Big Data ข้อเท็จจริงคือว่า Big Data
จะต้องมีการบริหารข้อมูลขนาดใหญ่ในหลายรูปแบบ Hadoop ก็เป็น
เพียงเคร่ืองมือหน่ึงท่ีน่าสนใจถ้าต้องการเก็บ unstructure data ขนาด
ใหญ่ท่ีเก็บข้อมูลได้เป็น PetaByte และสามารถท่ีจะใช้ร่วมกับ RDBMS
และ EDW (Enterprise Data Warehouse) นอกจากต้นทุนในการเก็บ
ข้อมูลจะต่ำากว่ามากดังแสดงในรูปท่ี 1 ทำาให้ Hadoop เป็นเทคโนโลยืีท่ี
น่าสนใจมากถ้าเราต้องการทำา Big Data แต่ Hadoop ก็จะไม่ได้มาแทน
ท่ีเทคโนโลยีการเก็บข้อมูลแบบเดิมเช่น RDBMS และ EDW
รูปท่ี 1 ราคาเปรียบการเก็บข้อมูลต่อ TB โดยใช้เทคโนโลยีต่าง [Source:
Monetizing Big Data at Telecom Service Providers]
• Strucure Data ในองค์กรเพียงพอต่อกำรทำำ Big Data ข้อมูลในปัจจ
บันมีแนวโน้มท่ีจะเป็น unstructure data มากกว่า structure data
66 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-74-320.jpg)








![รูปท่ี 2 Big Data Strategy Temple [Source: Big Data: Understanding
How Data Powers Big Business]
จาก Template น้ีจะเห็นได้ว่า เราควรจะเร่ิมจากการกำาหนด Business
Initiatives ของการจะนำาข้อมูลมาใช้ จากน้ันคงต้องพิจารณาว่าอะไรคือ
ผลลัพธ์ท่ีคาดว่าจะได้และอะไรคือปัจจัยสู่ความสำาเร็จ จากน้ันถึงจะกำาหนด
งาน (Task) ท่ีต้องทำา และระบุถึงข้อมูลท่ีจะนำามาใช้
ซ่ึงเม่ือเรากำาหนดกลยุทธ์ทางด้าน Big Data โดยเร่ิมจากมุมมองธุรกิจ
เช่นน้ีแล้ว เราค่อยมาคำานึงถึงเทคโนโลยีท่ีจะต้องนำามาใช้งาน จากรูปท่ี 3
จะเห็นได้ว่า เทคโนโลยีแต่ละแบบจะมีความเหมาะสมกับข้อมูลท่ีแตกต่าง
กัน เช่น
การวางกลยุทธ์ด้าน BIG DATA ขององค์กรและ TECHNOLOGY ด้าน
DATA ต่างๆ
75](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-83-320.jpg)
![รูปท่ี 3 เปรียบเทียบเทคโนโลยีการเก็บข้อมูลแบบต่างๆ [Source: Amazon
Web Services]
• Traditional Database คือเทคโนโลยีฐานข้อมูล SQL แบบเดิมสำาหรับ
ข้อมูลท่ีเป็น structure ในระดับ GByte ถึง TByte และมีความเร็วใน
การประมวลผลไม่มากนัก
• MPP Database คือเทคโนโลยีสำาหรับข้อมูลขนาดใหญ่หลาย TByte ท่ี
เป็น structure โดยมีความสามารถในการประมวลผลข้อมูลขนาดใหญ่
ได้อย่างรวดเร็ว ตัวอย่างของ MPP มีอาทิเช่น Oracle Exadata. SAP
HANA, Amazon Redshift หรือ Datawarehouse อย่าง Teredata
หรือ Greenplum
• NoSQLคือเทคโนโลยีในการเก็บข้อมูล semi-structure ขนาดใหญ่
โดยไม่ได้ใช้คำาส่ังในการประมวลผลท่ีเป็น SQL ต้วอย่างเช่น mongo
DB, Cassendra หรือ Dynamo DB
• Hadoop คือเทคโนโลยีในการเก็บข้อมูลท่ีเป็น unstructure ซ่ึง
สามารถจะเก็บข้อมูลขนาดใหญ่ได้เป็น PByte
องค์กรจะต้องเตรียมโครงสร้างพ้ืนฐานเพ่ือท่ีจะรองรับ Big Dataโดยจะต้อง
ใช้เทคโนโลยีเหล่าน้ีผสมผสานกัน องค์กรคงยังต้องมี SQL Database แต่
76 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-84-320.jpg)




![จะมา และเราจำาเป็นต้องสร้างบุคลากรทางด้านน้ี โดยผมเน้นเร่ืองของ
เทคโนโลยี Hadoop ท่ีสามารถเก็บ Unstructure Data ได้มหาศาล ช่วง
เวลาสองปีทาง IMC Institute ก็ได้อบรมคนไปหลายร้อยคน และก็ได้ช่วย
ทำาให้คนเข้าใจเทคโนโลยีน้ีมากข้ึน
กระแส Big Data กำาลังมาอย่างแน่นอน เพราะตอนน้ีจำานวน Devices
ท่ัวโลกมีหลายพันล้าน คนใช้อินเตอร์เน็ตมีมากข้ึน มีการใช้ Social
Network มีมากข้ึน และเร่ืองของ Internet of Things กำาลังมา ส่ิงต่างๆ
เหล่าน้ีล้วนแต่มีการสร้างข้อมูลใหม่ๆอยู่ตลอดเวลา จำานวนข้อมูลมากข้ึน
ทุกวันและมีข้อมูลท่ีเป็น Unstructure จำานวนมาก จึงมีความจำาเป็นต้องหา
เทคโนโลยีใหม่ๆมาใช้ในการเก็บและวิเคราะห์ข้อมูล ผมเช่ือว่าในปี 2015 น้ี
เร่ืองของ Big Data Analytics จะมีความสำาคัญมากข้ึน เพราะธุรกิจต่างๆ
จะมีการแข่งขันกันมากข้ึน ใครก็ตามท่ีสามารถจะนำาข้อมูลขนาดใหญ่มา
วิเคราะห์ได้คนน้ันจะได้เปรียบเหนือคู่แข่ง Big Data transform Business
ภาพโครงสร้างพ้ืนฐานข้อมูล (Information Infrastructure) ใน
อนาคตขององค์กรจะเปล่ียนแปลงไปเพราะขนาดข้อมูลท่ีใหญ่ข้ึน และชนิด
ข้อมูลท่ีหลากหลาย เราน่าจะเป็นโครงสร้างท่ีใช้เทตโนโลยีต่างๆมากข้ึนดัง
ตัวอย่างในรูป
รูปตัวอย่าง Information Infrastructure ขององค์กร
[source 1=”KARMAsphere” language=”:”][/source]
ปี 2015 จะเป็นปีเร่ิมต้นของ BIG DATA ANALYTICS 81](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-89-320.jpg)



![วันจะมีขนาดหลาย TB ซ่ึงถ้าสามารถนำามาวิเคราะห์ได้จะได้ข้อมูลท่ีเป็น
ประโยชน์มากมาย อาทิเช่นการวางแผนการติดต้ังเครือข่าย การวิเคราะห์
การใช้งาน การลดการย้ายค่าย ตัวอย่างการนำา Big Data มาใช้งานทาง
ด้านน้ีมีดังตารางข้างล่างน้ี
ตัวอย่างการนำา Big Data มาใช้งานทางอุตสาหกรรม
Telecommunication [Source: Monetizing Big Data at Telecom
Service Providers]
2) Banking/Insurance: อุตสาหกรรมการเงินการธนาคาร ก็เป็นอีก
กลุ่มท่ีมีข้อมูลขนาดใหญ่ และ Transaction ต่อวันมีจำานวนมหาศาล ย่ิงมี
การใช้งาน Internet/Mobile Banking มากข้ึน ก็ย่ิงทำาให้มีจำานวน
Transaction สูงข้ึน Big Data สามารถนำามาใช้เพ่ือลดความเส่ียงต่อการ
ฉ้อโกงได้การชำาระเงิน, หรือช่วยในการประเมินความเส่ียงของลูกค้าท่ีมา
กู้ยืมเงิน, หรือช่วยในการประเมินอัตราค่าบริการประกันภัยของลูกค้าแต่ละ
ราย หรือช่วยในการแบ่งกลุ่มลูกค้า (Customer Segmentation) ตัวอย่าง
ของการนำา Big Data มาใช้งานทางด้านน้ีมีดังตารางข้างล่างน้ี
BIG DATA USE CASES: ในอุตสาหกรรมต่างๆ 85](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-93-320.jpg)
![ตัวอย่างการนำา Big Data มาใช้งานทางอุตสาหกรรม Finance [Source:
IDC Financial Insights]
3) Retails: อุตสาหกรรมค้าปลีกโดยเฉพาะอย่างย่ิงการขายของทางe-
Commerce มีความจำาเป็นอย่างย่ิงท่ีต้องนำา Big Data เข้ามาช่วยในการ
วิเคราะห์ข้อมูลต่างๆ อาทิเช่น การทำา Customer Segmentation, การ
นำาเสนอสินค้าให้กับลูกค้า (Next Product to Buy), การศึกษาพฤติกรรม
ลูกค้า หรือแม้แต่ใช้ในการกำาหนดราคาสินค้า (Pricing Optimization)
เราจะเห็นว่าผู้ค้าปลีกหลายใหญ่ๆต่างก็พยายามจะเก็บข้อมูลการบริโภค
ของลูกค้า เพ่ือนำาข้อมูลเหล่าน้ีมาวิเคราะห์ ย่ิงเป็น E-Commerce ราย
ใหญ่ๆอย่าง Amazon หรือ eBay ก็ยังมีความสามารถท่ีจะไปดึงข้อมูล
ภายนอกอาทิเช่นจาก social media มาวิเคราะห์ความต้องการของลูกค้า
ได้ ตัวอย่างของการนำา Big Data มาใช้งานทางด้านน้ีมีดังตารางข้างล่างน้ี
86 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-94-320.jpg)
![ตัวอย่างการนำา Big Data มาใช้งานทางอุตสาหกรรม Retails [Source:
www.crmsearch.com]
นอกจากน้ี ยังมีการนำา Big Data มาใช้ในอุตสาหกรรมอาทิเช่น งานภาค
รัฐบาล (Government), งานด้านวิทยาศาสตร์, งานด้านส่ือ (Media) ซ่ึง
สามารถสรุปตัวอย่างได้ดังรูปข้างล่างน้ี
ตัวอย่างการนำา Big Data มาใช้งานทางอุตสาหกรรมต่างๆ [Source: Big
Data Analytics with Hadoop: Phillippe Julio]
ตัวอย่างต่างๆท่ีพูดถึงวันน้ี เป็นการเกร่ินนำา แต่ผมจะเขียนกรณีศึกษา
ทางด้านน้ีบางกรณีเพ่ิอให้เข้าใจเทคโนโลยี และเทคนิคท่ีเขาใช้ว่า ทำาได้
อย่างไรในบทความต่อๆไป
ธนชาติ นุ่มนนท์
IMC Institute
BIG DATA USE CASES: ในอุตสาหกรรมต่างๆ 87](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-95-320.jpg)












![จากการทำางานด้านน้ีในช่วงสองเดือนท่ีผ่านมา ทำาให้ได้ประส[การณ์และ
ข้อมูลใหม่ๆพอควร โดยเฉพาะประสบการณ์การติดต้ัง Hadoop หรือ
NoSQL บน Public Cloud ซ่ึงข้อดีของการใช้ Public Cloud คือเราไม่
ต้องจัดหา Server ขนาดใหญ่จำานวนมาก และสามารถ Provision ระบบ
ได้อย่างรวดเร็ว แต่มีข้อเสียคือค่าใช้จ่ายระยะยาวจะแพงกว่าการจัดหา
Server เอง และถ้ามีข้อมูลจำานวนมากท่ีต้อง Transfer ไปอาจไม่เหมาะสม
เพราะจะเกิดความล่าช้า นอกจากน้ียังอาจมีปัญหาเร่ืองความปลอดภัยของ
ข้อมูล
แต่การใช้ Public Cloud จะเหมาะมากกับการใช้งานเพ่ือเรียนรู้ หรือการ
ทำา Development หรือ Test Environment นอกจากน้ียังมีบางกรณีท่ี
การใช้ Public Cloud มาทำา Big Data Analytics อาจมีความเหมาะสม
กว่าการจัดหา Server ขนาดใหญ่มาใช้งานเอง อาทิเช่น
• กรณีท่ีระบบปัจจุบันขององค์กรทำางานอยู่บน Public Cloud อยู่แล้ว
อาทิเช่นมีระบบ Web Application ท่ีรันอยู่บน Azure หรือมีระบบอยู่
Salesforce.com
• กรณีท่ีข้อมูลท่ีต้องการวิเคราะห์ส่วนใหญ่เป็นข้อมูลภายนอกท่ีอยู่บน
Cloud เช่นการวิเคราะห์ข้อมูลจาก Facebook ท่ีการนำาข้อมูลขนาด
ใหญ่เหล่าน้ันกลับมาเก็บไว้ภายในจะทำาให้เปลืองเน้ือท่ีและล่าช้าในการ
โอนย้ายข้อมูล
• กรณีท่ีมีโครงการเฉพาะด้านในการวิเคราะห์ข้อมูลขนาดใหญ่เพียงคร้ัง
คราว ซ่ึงไม่คุ้มค่ากับการลงทุนจัดหาเคร่ืองมาใช้เอง
[slideshare id=45780994&doc=f6lut6yaq3imouoa1moi-
signature-77ce298b6caf34571b21943912199c3dcaec64e6ce35768146f3141c
gate01]
การใช้ Public Cloud สำาหรับการวิเคราะห์ข้อมูลโดยใช้ Hadoop หรือ
NoSQL มีสองรูปแบบคือ
1) กำรใช้ Virtual Server ในการติดต้ัง Middleware อาทิเช่นการ
ใช้ EC2 ของ AWS หรือ Compute Engine ของ Google Cloud มา
ลงซอฟต์แวร์ ข้อดีของวิธีการน้ีคือเราสามารถเลือกซอฟต์แวร์มาติดต้ังได้
เสมือนกับเราจัดหา Server มาเอง และสามารถควบคุมการติดต้ังได้ ท่ีผ่าน
มาผมได้เขียนแบบฝึกหัดท่ีติดต้ังระบบแบบน้ีอยู่หลายแบบฝึกหัดดังน้ี
100 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-108-320.jpg)




![การสร้างมาตราฐาน Open Data Platform เพ่ือให้เทคโนโลยีต่างๆท่ีมี
vendor หลายรายทำาอยู่ให้มีมาตราฐานเดียวกัน เพ่ือสร้าง competibility
โดยในเบ้ืองต้นเน้นอยู่ท่ีสองเทคโนโลยีหลักคือ Hadoop และ Ambari ท่ี
เป็น open source สำาหรับการบริหารจัดการ Hadoop Cluster
งาน Summit น้ีมีหัวข้อทางด้าน Business ท่ีพูดถึงการนำา Hadoop มา
ใช้งานในหลายๆองค์กรและหลายคลัสเตอร์ท้ังกลุ่ม Bank, Telecom,
Energy, Transportaion และ Retails โดยมีการพูดถึงเคร่ืองมือใน
วิเคราะห์ข้อมูลเพ่ือทำา BI มากมายท้ัง Tabular, Pentaho, SAP หรือ SAS
และก็ยังเน้นการถึงเทคโนโลยีในการทำา Data Analytics อย่าง Spark หรือ
Mahout งานน้ีมี sesion ในการบรรยายพูดเทคโนโลยีสำาหรับ Hadoop 2
อย่าง YARN, Tez, Storm, Hive, Pig, Spark, Solr, Kafka, Lambda.
และอ่ืนๆ โดยมีหัวข้อต่างท่ีน่าสนใจอาทิเช่น
• 5 Ways Hadoop Is Changing The World And 2 Ways It Will
Change Yours
• Unlocking Hadoop’s Potential
• Hadoop in the Enterprise
• Design Patterns for Real Time Streaming Data Analytics
• Making the Case for Hadoop in a Large Enterprise
• Hive Now Sparks
• Storm as an ETL Engine to Hadoop
• Hadoop YARN: Past, Present and Future
• Hadoop in the Cloud – Common Architectural Patterns
• Driving Enterprise Data Governance for Big Data systems
through Apache Falcon
• Oozie or Easy: Managing Hadoop Work]ows the EASY Way
ข้อมูลในงานท้ังหมดน้ีผมจะนำามาบรรยายสรุปในงานฟรีสัมมนา Thailand
Hadoop User Group คร้ังท่ี 3 ท่ีทาง IMC institute ต้ังใจจะจัดร่วมกับ
สำานักงานรัฐบาลอิเล็กทรอนิกส์ (EGA) ในปลายเดือนพฤษภาคม
ธนชาติ นุ่มนนท์
งานประชุม HADOOP SUMMIT 2015 105](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-113-320.jpg)








![• เอกสารการติดต้ัง Amazon EMR Cluster
จากการทดลองติดต้ังใช้งาน Cluster ต่างๆ ขอเปรียบเทียบดังน้ี
• Apache Hadoop Distribution: มีข้อเด่นคือเป็น Opensource
และไม่ต้องห่วงเร่ือง License การใช้งานแต่มีข้อจำากัดคือเราต้องบริหาร
จัดการ Distribution ต่างๆของ Hadoop เอง ซ่ึงบางคร้ังอาจจะเจอ
ปัญหาเร่ือง Bug หรือ Con]ict ระหว่าง version ตัวอย่างเช่น Flume
1.5 อาจจะต้องปรับบางไฟล์เพ่ือให้ทำางานกับ Hadoop 2.7 ได้ นอกจาก
น้ีข้ันตอนในการติดต้ังต่างๆจะยากกว่า Distribution ต่างๆ
• Hortonworks สามารถติดต้ังได้โดยง่ายแต่ผู้ใช้ต้องจัดการลง SSH
ในแต่ Server เอง ข้อดีอีกอย่างคือมี โปรแกรมบริหาร Cluster ทีเป็น
Opensource ท่ีช่ือ Ambari ทำาให้เพ่ิมหรือลด Server ได้โดยง่าย
• Cloudera น่าจะเป็น Distribution ทีติดต้ังได้ง่ายท่ีสุดท่ีผมได้ทดลอง
มา ข้อดีอีกอย่างคืมีโปรแกรม Hue ท่ีช่วยทำา Web GUI สำาหรับผู้
ต้องการใช้งาน Hadoop ส่วนโปรแกรมจัดการ Cluster คือ Cloudera
Manager น้ันอาจผูกติดกับบริษัท Cloudera ไปหน่อย
114 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-122-320.jpg)





















![รูปท่ี 1: Architecture สำาหรับ Fraud Detection
จาก Architecture น้ีมีประเด็นท่ีน่าสนใจคือ
Storage: เลือกใช้ HDFS สำาหรับเก็บข้อมูลท่ีดึงมาจาก Network และ
ต้องการประมวลผลแบบ Batch และเลือก HBase สำาหรับการเก็บ Proile
ของ Network ท่ีต้องการอ่านและเขียนอย่างรวดเร็ว นอกจากน้ียังมีการ
พูดถึง Kudu ว่าน่าจะเป็นเทคโนโลยีใหม่ท่ีอาจเหมาะกับการเก็บข้อมูลท่ี
Google ค้นคิดข้ึนมาท่ีผสมระหว่าง HDFS และ HBase ดังรูปท่ี 2
รูปท่ี 2 Kudu
Ingestion: มี Work]ow ในการดึงข้อมูลจาก Network Devices ดัง
รูป โดยข้ันตอนแรกดึงข้อมูลมาเก็บใน Queue โดยใช้ Kafka และใช้
Flume ทำาหน้าท่ีเป็น Event Handler จัดการเลือกเฉพาะข้อมูลท่ีน่าสงสัย
รูปท่ี 3 Ingestion WorkFow
Processing: ในการประมวลผลข้อมูลมีได้หลายวิธีดังรูปท่ี 4 แต่ในใน
กรณีของ Streaming เลือกใช้ Spark Streaming ส่วนกรณีของ Batch
Processing เลือกใช้ Spark สำาหรับการทำา Machine Learning, Impala
136 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-144-320.jpg)




















![รูปท่ี 1 Data Lake Components [Source: Building the Enterprise
Data Lake: A look at architecture, Mark Madsen]
รูปท่ี 2 หลักการของ Data Lake
ความแตกต่างระหว่าง Data Lake เม่ือเทียบกับ Data WareHouse ท่ี
สำาคัญมีดังน้ี
• Data Lake จะเก็บข้อมูลท้ังหมด
• Data Lake สนับสนุนข้อมูลทุกชนิดไม่แค่ข้อมูลแบบ Structure
• Data Lake มีเพ่ือให้ผู้ใช้ทุกประเภทสามารถใช้งานได้
• Data Lake สามารถติดต้ังได้ง่ายและเปล่ียแปลงได้เร็ว
• Data Lake จะประมวลและวิเคราะห์ข้อมูลได้รวดเร็วกว่า
ซ่ึงทาง AWS ก็สรุปความแตกต่างระหว่าง Data Lake และ Data
WareHouse ไว้ดังรูปท่ี 3
DATA LAKE: REDEFINE DATA WAREHOUSE 157](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-165-320.jpg)





![CHAPTER 34
การฝึกงานแบบ Big Data School
ของ IMC Institute ปิดเทอมน้ี
วันก่อนน้องท่ีสนิทท่านหน่ึงเอารายการทีวีดูให้รู้ ตอน “โรงเรียนฝึกคนหัวใจ
เพชร” เป็นโรงเรียนฝึกเด็กช่างไม้ในญ่ีปุ่น สอนเด็กให้แกร่ง อดทน มีวินัย
และใช้สมอง เห็นความยากลำาบากในการเรียนกว่าจะออกมาเป็นช่างไม้ท่ี
เก่งและมีคุณภาพ น้องถามว่าเราทำาโรงเรียนพัฒนา Developer อย่างน้ีใน
เมืองไทยไหม เราคุยกันว่าอยากจะทำาแต่ก็ยังไม่ได้ลงมือทำาอะไรมากนัก
[youtube https://www.youtube.com/watch?v=hpyh7HF3eog]
พฤษภาคมน้ีผมกำาลังย้ายออฟฟิทของ IMC Institute ไปอยู่ตึกสกุลไทย
แถวสุริวงศ์เราคงมีพ้ืนท่ีกว่างข้ึน มีห้องฝึกอบรมท่ีพร้อมจะรองรับผู้เรียนได้
จำานวนหน่ึง การอบรมส่วนใหญ่ของ IMC Institute ยังคงอยู่ข้างนอก แต่
ห้องอบรมน้ีผมได้บอกกับทีมงานว่าเราใช้งานเพ่ือสังคม งาน CSR งาน
อบรมฟรีราคาถูกมากท่ีน่ีเลยไม่ว่าจะเป็นงาน Big Data Challenge, Big
Data User Group, Train the trainers ตลอดจนกิจกรรมอ่ืนๆท่ีเราคง
สามารถทำาอะไรได้มากข้ึน
ผมก็เลยเร่ิมคิดถึงการฝึกคน ผมอาจจะยังไม่สามารถทำาโรงเรียนฝึก
Developer หัวใจเพชรได้ทันที แต่ก็นึกข้ึนมาว่าวันน้ีเราหา Developer
เก่งๆได้ยากโดยคนท่ีจะซ่ือสัตย์และต้ังใจทำางานให้กับหน่วยงาน ไม่ใช่แค่
คิดหวังจะร่ำารวย นอกเหนือจากมีความรู้ ก็ต้องอดทนและมีจริยธรรมท่ีดี เรา
มาฝึกงานเขาไหม? อาจเป็นช่วงเวลาส้ันๆ 2-3 เดือน พอฝึกงานเสร็จมาเขา
จะกลับไปเรียนต่อหรือไปทำางานท่ีไหนก็ตามอย่างน้อยเราก็ได้สร้าง](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-171-320.jpg)







![CHAPTER 36
Big Data กับการใช้งานในภาครัฐ
และอุตสาหกรรมอ่ืนๆ
การนำาข้อมูลขนาดใหญ่ไปใช้งานจริงๆ ยังมีไม่มากนัก ท้ังน้ีด้วยข้อจำากัดใน
เร่ืองของเทคโนโลยีและจำานวนบุคลากรท่ีมีความสามารถ ซ่ึงทางสมาคม
PIKOM ของมาเลเซียได้ทำารายงานเร่ือง Global Business Services
Outlook Report 2015 ช้ีให้เห็นผลกระทบของเทคโนโลยีด้าน Big Data
ในประเทศกลุ่ม APAC และอุตสาหกรรมต่างๆ โดยสรุปมาเป็นตารางดังน้ี
ตำรำงท่ี 11 ระดับผลกระทบของเทคโนโลยี Big Data [แหล่งข้อมูลจาก
PIKOM]
ซ่ึงจะเห็นได้ว่ากลุ่มอุตสาหกรรมท่ีมีผลกระทบต่อการประยุกต์ใช้เทคโนโลยี
Big Data อย่างมากคือ อุตสาหกรรมด้านการเงินการธนาคาร (BFSI) ด้าน](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-179-320.jpg)












![แต่ถ้าต้องการทดลองหรือใช้เพ่ือทำา Development โดยผ่าน Hadoop
Sandbox ก็จะแนะนำาให้ใช้ Cloudera Quickstart ซ่ึงผมเองก็ใช้ตัวน้ีใน
การอบรม ดังตัวอย่างเอกสารอบรมของผมดังน้ี >> Big data processing
using Cloudera Quickstart
สุดท้ายผมมี Slide ทีนักฝึกงานของ IMC Institute ได้ทำาข้ึนเพ่ือ
เปรียบเทียบ Hadoop Distribution ต่างๆดังน้ี
• Hortonworks >> https://docs.google.com/presentation/d/
1U6sQSAyQMzFg9Dq9ZLIt_2E_a-6q3kyScMtJV9V2g2g/
edit?usp=sharing
• MapR >> https://docs.google.com/presentation/d/10I-
YWfSVlhsGbt5NCQbnAy8nws3zFU_wWBZwo4C]nQ/
edit?usp=sharing
• Cloudera >> https://docs.google.com/presentation/d/
1Wbi6Q1sGWEjUwXzbsewQBqZ3mFAfA51EbtMLluMKB4I/
edit?ts=57621459#slide=id.g14f5cc73fc_22_8
• Pure Apache Hadoop
◦ Pure Hadoop Original Apache Hadoop Series
>> https://docs.google.com/presentation/d/
1ujHiqi1ZnKRkaN03k0f9UazJiVpR-LDQt4Pno_Xi-pU/
edit#slide=id.g14f6b587f9_1_327
Apache hadoop cluster on Docker:
>> https://docs.google.com/presentation/d/
171diV930LZb4J_GkXfdbhsx4zB5BbVHrFTYZSUMR5Vw/
edit?ts=575e207c#slide=id.g14f01e49ed_0_240
Original Apache Hadoop 2.7.1 Multi-node Cluster
Installation
>> https://docs.google.com/presentation/d/
1ghTF6Medv_szeEh1lwoupOj5u11c7GB4R7-
ธนชาติ นุ่มมนท์
IMC Institute
184 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-192-320.jpg)






![ต่างๆท้ัง Hive, Impala, Flume, Sqoop, Kafka, Cloudera Manager,
Amabari และให้เขียนข้อสรุปเปรียบเทียบ Big Data ต่างๆ
19-24 มิถุนายน เรียนรู้ Apache Spark และการทำา Big Data
Analytics โดยใช้ Spark Python, Spark Scala, Spark SQL และ Spark
Streaming
26 มิถุนายน – 1 กรกฎาคม เรียนรู้ Machine Learning การใช้
เคร่ืองมือและภาษาต่างๆอาทิเช่น , MLLib และ Azure Machine
Learning และติวการสอบ CCA Spark and Hadoop Developer Exam
3-27 กรกฎาคม ทำา Mini-Project
28 กรกฎาคม นำาเสนอ Mini-Project และปิดการฝึกงาน
ท้ังน้ีการอบรมเชิงฝึกงานคร้ังน้ีไม่มีค่าใช้จ่ายใดๆ ซ่ึงทางสถาบันคาดว่า
ผู้ท่ีผ่านการอบรมจะเป็นผู้ท่ีเข้าใจหลักการและเทคโนโลยีด้าน Big Data
พร้อมท้ังสามารถทำาด้าน Data Science ได้ โดยทางสถาบันจะมีการสอบ
และวัดผลสัมฤทธ์ิของการฝึกงาน และทางสถาบันจะออกใบรับรองว่าผ่าน
การฝึกงาน และผู้ท่ีผ่านหากต้องการไปฝึกงานหรือทำาสหกิจศึกษา การทำา
โครงการเพ่ิมเติมระหว่างเรียน ทางสถาบันจะติดต่อและให้การรับรองให้
พร้อมกันน้ีนักศึกษาท่ีทำาคะแนนสอบจากการทดลองสอบ CCA Spark and
Hadoop Developer Exam สูงสุดสามอันดับแรกทางสถาบันจะออกค่าใช้
จ่ายการสอบจริงให้มูลค่ารายละ $295 เพ่ือให้ได้ประกาศนียบัตร ท้ังน้ีผู้เข้า
อบรมไม่มีอะไรต้องผูกมัดกับทางสถาบัน และทางสถาบันยินดีประสาน
ติดต่อกับบริษัทอ่ืนๆเพ่ือไปทำางานด้าน Big Data ต่อไป
สำาหรับคุณสมบัติผู้ท่ีจะเข้ารับการอบรมน้ีมีดังน้ี
• กำาลังศึกษาหรือสำาเร็จการศึกษาในระดับปริญญาตรีสาขาวิศวกรรม
คอมพิวเตอร์ วิทยากรคอมพิวเตอร์ หรือเทคโนโลยีสารสนเทศ [ถ้าเป็น
นักศึกษาปี 4 ท่ีกำาลังจบการศึกษาจะได้รับการพิจารณาก่อน]
• มีความต้ังใจจะเข้าฝึกงานจริงจัง อาจเป็นส่วนหน่ึงของการจบการศึกษา
หรือไม่ก็ได้
• สามารถเข้าฝึกงานได้ต้ังแต่วันจันทร์-ศุกร์ เวลา เวลา 8.30 – 17.30 น.
• ต้องเข้ามาฝึกงานทุกวันตามข้อตกลงและต้องมีเวลาเข้าฝึกงานไม่น้อย
กว่า 95%
ผู้ท่ีมีความสนใจการอบรมน้ีสามารถดูรายละเอียดเพ่ิมเติมได้ท่ี www.
BIG DATA SCHOOL: การอบรม ON THE JOB TRAINING สำาหรับ
นักศึกษารุ่นท่ีสอง
191](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-199-320.jpg)




















![ดังน้ันจึงไม่แปลกใจท่ีหน่วยงานจำานวนมากไม่สามารถท่ีจะลงทุน
โครงสร้างพ้ืนฐานเร่ืองของ Big Data Platform ได้ เน่ืองด้วยค่าใช้จ่าย
ท่ีสูง และอาจคำานวณหาผลตอบแทนในการลงทุนลำาบาก รวมถึงอาจหา
Business case ค่อนข้างยาก ข้อสำาคัญการลงทุน Hadoop อาจพบว่าส่วน
ใหญ่ก็คือการรวบรวมข้อมูลมาใส่ลงใน Data Lake มากกว่าการใช้ CPU
ในการประมวลผลผ่าน Processing Tools อย่าง Hive, Spark, Impala
เพราะนานๆคร้ังจะทำาการประมวลผลท่ี และบางคร้ังหากต้องการประมวล
ผลก็จะพบว่าความเร็วหรือจำานวน CPU ไม่พอ จึงอาจเกิดคำาถามข้ึนมาว่า
เราต้องลงทุนโครงสร้างพ้ืนฐานจำานวนหลายสิบล้านบาทเพียงเพียงเพ่ือใช้
ในการเก็บช้อมูลท่ีเป็น archieve จะคุ้มค่าหรือไม่
รูปท่ี 3 ค่าใช้จ่ายการทำา Hadoop Cluster จำานวน 18 เคร่ือง [ข้อมูลจาก
https://blogs.oracle.com]
แนวทางท่ีดีสำาหรับการลงทุนโครงการ Big Data คือการใช้บริการ
Public Cloud ดังท่ีผมเคยเขียนไว้ในบทความ “Big Data as a Service
แนวทางการทำาโครงการ Big Data ท่ีไม่ต้องลงทุนโครงสร้างพ้ืนฐาน” ท้ังน้ี
เราจะแยกส่วนการเก็บข้อมูลขนาดใหญ่ท่ีเป็น Data Lake ไว้ใน Cloud
Storage อาทิเช่นการใช้ Google Cloud Storage, AWS S3 หรือ
Microsoft Azure Blob มาแทนท่ีการใช้ Hadoop HDFS ซ่ึงจะเป็นการ
ประหยัดค่าใช้จ่ายกว่าการลงทุน Hadoop Cluster มากและก็มีความ
เสถียรของระบบท่ีดีกว่า นอกจากองค์กรก็ยังลดค่าใช้จ่ายในการบริหาร
จัดการและดูแลระบบ ซ่ึงจะถูกกว่าการลงทุน Hadoop Cluster หลายสิบ
เท่า โดยอาจมีค่าใช้จ่ายเพียงการเก็บข้อมูลเดือนหน่ึงหลักเพียงหม่ืนบาท
ในการเก็บข้อมูลเป็น Terabyte ท้ังน้ีข้อมูลท่ีนำามาเก็บบน Cloud
212 THANACHART](https://image.slidesharecdn.com/bigdatathanachart-180402071008/85/Big-Data-thanachart-org-220-320.jpg)




















































![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=560&fit=bounds)





Ad
More Related Content
What's hot (20)
Similar to บทความ Big Data จากบล็อก thanachart.org (20)


















Ad
More from IMC Institute (20)




















Ad
บทความ Big Data จากบล็อก thanachart.org
- 2. บทความ Big Data จากบล็อก thanachart.org Copyright © thanachart. All Rights Reserved.
- 3. Contents บทนำา vii 1. Big Data และเทคโนโลยี Hadoop กับการพัฒนา องค์กรด้านการวิเคราะห์ข้อมูล 1 2. เทคโนโลยี Big Data: Hadoop, NoSQL, NewSQL และ MPP 7 3. Open Government Data กับการปฎิรูปประเทศ ไทย 11 4. การคาดการณ์แนวโน้มของ Big Data 19 5. Big Data on Cloud ตอนท่ี 1: Hadoop as a Service 25 6. Big Data Analytics กับความต้องการ Data Scientist ตำาแหน่งงานท่ีน่าสนใจในปัจจุบัน 31 7. Big Data on Cloud ตอนท่ี 2: BI/Analytics as a Service 37 8. Online Courseware และหนังสือ Big Data ท่ีน่า อ่าน 43 9. Hadoop Ecosystem สำาหรับการพัฒนา Big Data 47
- 4. 10. Data Scientist กับเทคโนโลยี Big Data: Hadoop, MapReduce, R และ Mahout 55 11. ความพร้อมด้าน Big Data ของบ้านเรา คงต้องให้ ระยะเวลาอีกพักหน่ึง 61 12. ความเข้าใจผิดบางประการเก่ียวกับ Big Data 65 13. IMC Institute ปรับปรุงหลักสูตรด้าน Big Data ในปี หน้า เพ่ือสร้างคนไอที 69 14. การวางกลยุทธ์ด้าน Big Data ขององค์กรและ Technology ด้าน Data ต่างๆ 73 15. ปี 2015 จะเป็นปีเร่ิมต้นของ Big Data Analytics 79 16. Big Data Use Cases: ในอุตสาหกรรมต่างๆ 83 17. อนาคตของเทคโนโลยีฐานข้อมูล (The Future of the Database) 89 18. กลยุทธ์ Big Data สำาหรับประเทศไทย 93 19. Big Data บน Public Cloud 99 20. งานประชุม Hadoop Summit 2015 103 21. เอกสารการอบรม Big Data Certication Course (ตอนท่ี 1) 107 22. การติดต้ังและเปรียบเทียบ Hadoop Distribution ต่างๆ 111 23. โครงการ Big Data กับความจำาเป็นต่อการลงทุนด้าน เทคโนโลยี 117 24. เทคโนโลยีสำาหรับ Big Data: Storage และ Analytics 121 25. Azure HDInsight หน่ึงในกลยุทธ์ท่ีเปล่ียนไปของ Microsoft (มี Link เอกสารการอบรม) 127
- 5. 26. Big Data Technology ต่างๆ: Storage และ Analytics 131 27. Hadoop Application Architecture 135 28. การพัฒนาบุคลากรสำาหรับงานทางด้าน Big Data 139 29. การประมวลผล Big Data ควรใช้เทคโนโลยีไหนดี? 143 30. Hadoop Distribution ต่างๆสำาหรับการทดลอง ใช้งาน 147 31. ความต้องการบุคลากรทางด้าน Big Data 151 32. Data Lake: Redene Data WareHouse 155 33. IMC Institute ให้ทุนอบรม Big Data Certication 120 ชม.สองทุน 159 34. การฝึกงานแบบ Big Data School ของ IMC Institute ปิดเทอมน้ี 163 35. Big Data School กับการติดต้ัง Hadoop Distributions 167 36. Big Data กับการใช้งานในภาครัฐและอุตสาหกรรม อ่ืนๆ 171 37. Slide สำาหรับการเรียนรู้ Big Data Hadoop ของ IMC Institute 177 38. Hortonworks เทียบกับ Hadoop Distribution อ่ืนๆ 181 39. Big Data School: การอบรม On the Job Training สำาหรับนักศึกษารุ่นท่ีสอง 187 40. Big Data เพ่ือสร้าง Digital Disruption ในองค์กร (ตอนท่ี 1) 193 41. Big Data เพ่ือสร้าง Digital Disruption ในองค์กร (ตอนท่ี 2) 197
- 6. 42. ระดับการวัดความสามารถในการนำา Big Data ไปใช้ ในองค์กร 201 43. Big Data as a Service แนวทางการทำาโครงการ Big Data ท่ีไม่ต้องลงทุนโครงสร้างพ้ืนฐาน 205 44. การทำาโครงการ Big Data อย่างรวดเร็ว ควรเร่ิม อย่างไร 209 45. การอบรม Big Data และกิจกรรมด้านน้ีของ IMC Institute ในปี 2018 215 46. Big data ต้องเร่ิมต้นจากการวิเคราะห์ Transactional data ไม่ใช่เล่นกับ summary data 219 47. Mini Project ในหลักสูตร Big data certication 225 48. จะทำา Big Data ต้องเร่ิมต้นท่ีทำา Data Lake 229
- 7. บทนำา ผมเร่ิมเล่นและสอน Hadoop ซ่ึงเป็นเทคโนโลยีหน่ึงในการทำา Big Data ต้ังแต่ปี 2556 และก็ลงมือปฎิบัติอย่างต่อเน่ืองโดยได้ใช้เทคโนโลยีต่างๆ ของ Big Data ได้ทำาการติดต้ัง Hadoop Cluster ท้ัง Apache Hadoop, Cloudera, Hortonworks และ MapR ตลอดจนการใช้เคร่ืองมือวิเคาระห์ ข้อมูลและจัดการข้อมูลต่างๆอาทิเช่น MapReduce, Hive, Pig, Impala, Spark, Mahout, KafKa, Sqoop หรือ Flume รวมถึงการใช้ Big Data as a Service ในหลากหลายแพลตฟอร์มต้ังแค่ AWS, Azure หรือ Google Cloud นอกจากการอ่านหนังสือ ศึกษาด้วยตัวเอง การเข้าเรียนหลักสูตรต่างๆ การเข้าไปฟังสัมมนา Hadoop summit ในต่างประเทศหลายๆท่ี แล้วผม ก็ยังมีโอกาสในการทำางานท่ีปรึกษาด้าน Big Data Consultant รวมถึง ติดต้ังระบบและวิเคราะห์ข้อมูลขนาดใหญ่ให้กับหลายๆหน่วยงาน ตลอดจน หน้าท่ีการงานท่ีผมเป็นผู้บริหารและบอร์ดบริษัทหลายๆแห่งรวมท้ังธนาคาร ทำาให้เข้าใจโครงการ Big Data และมุมมองของผู้บริหารได้บ้าง จากประสบการณ์ท่ีผมสอนคนในด้าน Big Data เป็นพันๆคนโดยเฉพาะ การสอนภาคปฎิบัติ จัดโครงการประกวด ไปบรรยายให้ท้ังกลุ่มผู้บริหาร และผู้ปฎิบัติงาน จัดหลักสูตรและสัมมนาด้านน้ีให้กับ IMC Institute จำานวนมาก รวมถึง’มีโอกาสได้พูดคุยกับผู้บริหารบ่อยคร้ัง ก็เลยได้นำา ประสบการณ์และความรู้ด้าน Big Data มาเขียนลงในบล็อก thanachart. org บ่อยๆ ผมเลยถือโอกาสรวบรวมบทความต่างๆท่ีเคยเขียนเร่ือง Big Data ต้ังแต่ 5 ปีท่ีแล้วลงมาในหนังสือเล่มน้ี ธนชาติ นุ่มนนท์
- 9. CHAPTER 1 Big Data และเทคโนโลยี Hadoop กับการพัฒนาองค์กรด้านการ วิเคราะห์ข้อมูล แนะนำำ Big Data Big Data เป็นอีกหัวข้อหน่ึงท่ีเร่ิมมีการกล่าวถึงกันอย่างกว้างขวาง ซ่ึงถ้า เราดูจาก Google Trends ก็จะเห็นได้ว่าท่ัวโลกก็เร่ิมให้ความสนใจในการ ค้นคำาว่า Big Data ตีคู่มากับคำาว่า Cloud Computing แล้ว ส่วนหน่ึง ก็อาจเป็นเพราะว่าข้อมูลในโลกของอินเตอร์เน็ตเร่ืมมีเยอะข้ึน โดยเฉพาะ ข้อมูลจาก Social Network ท่ีผู้คนต่างเข้ามาอัพเดทข้อมูลตลอดเวลา นอกจากน้ีราคาของ Storage ก็ถูกลงทำาให้คนเร่ิมท่ีจะเก็บข้อมูลเยอะข้ึน เร่ือยๆ ซ่ึงทาง EMC/IDC ได้ทำาตาดการณ์ว่าในปี 2015 จะมีข้อมูลดิจิตอล รวมกันประมาณ 7,910 ExaBytes หลายๆคนยังเข้าใจว่า Big Data คือการท่ีมีข้อมูลดิจิตอลขนาดมหาศาล
- 10. แต่จริงๆแล้วเรามักจะนิยามความหมายของ Big Data ด้วยคำาย่อว่า 3V คือ Volume, Velocity และ Variety • Volume: คือมืจำานวนข้อมูลมากเกินกว่าระบบฐานข้อมูลแบบเดิมๆจะ สามารถท่ีจะจัดการได้ • Velocity: คือข้อมูลจะมีการเปล่ียนแปลงอย่างรวดเร็ว เช่นข้อมูลจาก Social Media ข้อมูลการซ้ือขาย ข้อมูล Transaction การเงินหรือการ ใช้โทรศัพท์ หรือข้อมูลจาก Sensor • Variety: คือข้อมูลจะมีหลากหลายรูปแบบท้ัง Structure และ Unstructure ซ่ึงอาจจะอยู่ในรูปท้ัง RDBMS, text, XML, JSON หรือ Image ดังน้ันการจัดการ Big Data จึงจำาเป็นต้องใช้ระบบการเก็บข้อมูลหรือการ ประมวลในรูปแบบอ่ืนๆท่ีอาจไม่ใช้เพียงแค่ฐานข้อมูล RDBMS แบบเดิมๆ ซ่ึงหากเราพิจารณา Ecosystems ของ Big Data เราจะสามารถจะเห็นได้ ว่ามีความเก่ียวข้องกับโครงสร้างพ้ืนฐานไอทีหลายๆด้านดังรูป เทคโนโลยี Hadoop ซอฟต์แวร์ท่ีสำาคัญตัวหน่ึงท่ีมีการนำามาใช้กันมาในระบบ Big Data คือ Hadoop เพราะ Hadoop เป็น Open Source Technology ท่ีจะทำาหน้าท่ี 2 THANACHART
- 11. เป็น Distributed Storage ท่ีสามารถเก็บข้อมูลขนาดใหญ่ท่ีเป็น Unstructure และนำามาประมวลผลได้ โดยองค์ประกอบหลักๆของ Hadoop จะประกอบด้วย Hadoop Dustributed File System (HDFS) ท่ีทำาหน่้าท่ีเป็น Storage และ MapReduce ท่ีใช้ในการพัฒนาโปรแกรม ประมวลผล ท้ังน้ีโครงสร้างด้าน Hardware ของ Hadoop จะใช้เคร่ือง Commodity Server จำานวนมากต่อเป็น Cluster กัน ในปัจจุบันหลายๆองค์กรจะใช้ Hadoop Technology ในการพัฒนา Big Data อาทิเช่น Facebook, Yahoo และ Twitter โดยจะมีเคร่ือง Server 9yh’c9j 5 -1,000 เคร่ือง ท้ังน้ีข้ึนอยู่กับขนาดข้อมูล นอกจากน้ี Technology Vendor ต่างๆอาทิเช่น Oracle, IBM, EMC หรือแม้แต่ Microsoft ต่างก็นำา Hadoop มาใช้ในเทคโนโลยีของตัวเองในการ พัฒนาผลิตภัณฑ์ทางด้าน Big Data ท้ังน้ี Hadoop จะไม่ได้นำามาแทนท่ีระบบฐานข้อมูลเดิมแต่เป็นการ ใช้งานร่วมกันท้ัง Database แบบเดิมท่ีเป็น Structure Data และการนำา Unstructure Data ขององค์กรท่ีอาจเก็บไว้ในระบบอย่าง Hadoop เข้า มาพิจารณาร่วมกับข้อมูลอ่ืนๆภายนอกเช่น Facebook แล้วนำามาวิเคราะห์ ข้อมูลโดยใช้เคร่ืองมืออย่าง Business Intelligence ดังรูป BIG DATA และเทคโนโลยี HADOOP กับการพัฒนาองค์กรด้านการ วิเคราะห์ข้อมูล 3
- 12. ซ่ึงจากการสำารวจของ Unisphere Research เม่ือพฤษภาคม 2013 พบว่าอุตสาหกรรมท่ีมีความสนใจจะพัฒนาเร่ือง Big Data เป็นอันดับต้นๆ คือ อุตสาหกรรมค้าปลีก อุตสาหกรรมธนาคารและประกันภัย อุตสาหกรรม โทรคมนาคม ซ่ึงใช้ในการวิเคราะห์ลูกค้าและข้อมูลการตลาด นอกจากน้ี หลายหน่วยงานก็มีการนำาข้อมูลด้าน Social Media มาทำาการวิเคราะห์ เพ่ือหาข้อมูลต่างๆ การพัฒนา Big Data ท่ีสำาคัญประการหน่ึงก็คือการปรับปรุงโครงสร้าง ระบบไอทีขององค์กรด้านข้อมูล (Information Infrastucture) รวมถึง การพัฒนาบุคลากรให้เข้าใจถึงเทคโนโลยีด้าน Big Data ใหม่ๆอย่าง Hadoop หรือ in-Momery Database และต้องมีการวางแผนในการนำา ข้อมูลท้ัง Structure และ Unstructure จากภายในและภายนอกองค์กร มาใช้งาน รวมถึงการท่ีจะต้องหาผู้เช่ียวชาญทางด้านข้อมูลท่ีเป็น Data Scientist มาร่วมทำางาน กำรพัฒนำองค์ควำมรู้ด้ำน Big Data ของสถำบัน IMC IMC Institute ให้ความสำาคัญกับเทคโนโลยี Big Data โดยท่ีผ่านมาได้ เปิดหลักสูตรอบรมในหลายหลักสูตรจำานวนผู้เรียนรวมกันมากกว่า 100 โดยมีหลักสูตรท่ีน่าสนใจคือ • Big Data using Hadoop Workshop • Big Data on Public Cloud Computing 4 THANACHART
- 13. • Big Data Programming using Java Technology โดยในวันท่ี 18 ตุลาคมน้ี ทางสถาบัน IMC จะเปิดหลักสูตร Big Data on Public Cloud Computing ซ่ึงเป็นการสอนหลักการของ Big Data ท่ี สามารถใช้งานได้จริงกับ Public Cloud อย่าง Amazon Web Services ซ่ึงผู้เรียนจะได้ศึกษาการพัฒนา Big Data ท้ังส่วนท่ีเป็น Map/Reduce, Hive, Pig และ HBase รวมถึงการนำาข้อมูลขนาดใหญ่เข้า Amazon S3 อน่ึงเม่ือเร็วๆน้ี ทางสถาบัน IMC ได้จัดสัมมนาหัวข้อ Business Intelligence in a Big Data World ร่วมกับ Oracle และ PwC โดยมี หัวข้อท่ีน่าสนใจหลายๆเร่ือง ซ่ึงสามารถท่ีจะดู Slide งานสัมมนาน้ีได้ดังน้ี • Big Data: Winning in the Digital World; Dr. Thanachart Numnonda https://dl.dropboxusercontent.com/u/ 12655380/BigDataThanachart.pdf • Big Data Hadoop: Introduction Session; Mr. Danairat Thanabodithammachari https://dl.dropboxusercontent.com/u/12655380/ BigDataDanairat.pdf • Business Intelligence for Success and Case Study; Ms. Pirata Phakdeesattayaphong (PwC) https://dl.dropboxusercontent.com/u/12655380/ BigDataPwC.pdf • How Big Data Information Discovery Provides Valuable Insights, Ms. Tidaporn Santimanawong (Oracle) https://dl.dropboxusercontent.com/u/12655380/ BigDataTida.pdf ธนชาติ นุ่มมนท์ IMC Institute ตุลาคม 2556 BIG DATA และเทคโนโลยี HADOOP กับการพัฒนาองค์กรด้านการ วิเคราะห์ข้อมูล 5
- 15. CHAPTER 2 เทคโนโลยี Big Data: Hadoop, NoSQL, NewSQL และ MPP ผมเคยเขียนบล็อกอธิบายความหมายของ Big Data และได้บอกว่า ความหมาย Big Data ไม่ได้มีความหมายแค่ข้อมูลมันใหญ่ แต่เรากำาลังพูด ถึงเทอม 3V คือ Volume, Velocity และ Variety ซ่ึงจะทำาให้เราไม่ สามารถท่ีจะใช้เทคโนโลยีฐานข้อมูลแบบเดิมวิเคราะห์ข้อมูลได้ท้ังหมด และ อาจต้องพิจารณาเทคโนโลยีใหม่ๆเช่น Hadoop เข้ามาใช้งานในองค์กร (เน้ือหาสำาหรับบล็อก Big Data และเทคโนโลยี Hadoop กับการพัฒนา องค์กรด้านการวิเคราะห์ข้อมูล สามารถดูได้ท่ี tinyurl.com/pa2av55) แต่ถ้าพูดถึงเทคโนโลยีสำาหรับ Big Data แล้วเราอาจเห็นเทคโนโลยี ใหม่ๆอีกหลายอย่างท่ีอาจแบ่งออกได้เป็น 4 กลุ่มดังรูป • Hadoop คือเทคโนโลยีท่ีรองรับ Unstructure Data ท่ีมีขนาดใหญ่ หลาย PetaByte ซ่ึง Hadoop เป็นเทคโนโลยี Opensource และมี vendor หลายรายนำาไปเผยแพร่ต่อเช่น MapR หรือ CloudEra • NoSQL คือเทคโนโลยืีท่ีเน้นเก็บข้อมูลขนาดใหญ่ท่ีไม่ใช่ RDBMS แต่จะ เน้นการเขียนและอ่านข้อมูลมากกว่าการใช้คำาส่ังในการค้นหาท่ีซับซ้อน จึงไม่ได้มีการใช้ภาษา SQL ในระบบฐานข้อมูลแบบน้ี ตัวอย่างของ ซอฟต์แวร์ท่ีใช้เทคโนโลยีน้ีคือ MongoDB, GraphDB, BerkeleyDB และ CouchDB • NewSQL คือฐานข้อมูล RDBMS แบบใหม่ท่ีต้องการจะรองรับข้อมูล
- 16. ขนาดใหญ่ให้ได้เหมือนกับ NoSQL ซ่ึงบางส่วนก็อาจนำา Cloud Comuputing มาใช้เช่น Amazon RDS หรือ SQL Azure แต่ก็มี ตัวอย่างซอฟต์แวร์ฐานข้อมูลอีกหลายตัวท่ีสามารถรองรับข้อมูลจำานวน มากได้เช่น MySQL Cluster หรือ VoltDB • MPP หรือ Massively Parallel Processing คือระบบท่ีสามารถ ประมวลข้อมูลขนาดใหญ่โดยใช้เทคโนโลยีแบบคู่ขนานได้อย่างรวดเร็ว ซ่ึงอาจเป็นเทคโนโลยีพวก Datawarehouse หรือ Applicance ของ อาทิเช่น Oracle Exadata, Netezza หรือ Greenplum และหากพิจารณาเทคโนโลยีต่างๆในด้าน Big Data เราจะพบว่ามี เทคโนโลยีต่างๆมากมายดังรูป โดย Hadoop อาจเป็นเทคโนโลยีท่ีนำาหน้า รายอ่ืนๆ ในแง่ของการเป็นระบบสำาหรับเก็บและวิเคราะห์ Unstructure Data ขนาดใหญ่ 8 THANACHART
- 17. ดังน้ันเราจะเห็นได้ว่าการจะพัฒนา Big Data ในองค์กรจำาเป็นจะต้องมี การพัฒนาระบบโครงสร้างด้านข้อมูล (Information Infrastructure) ซ่ึง ต้องมีเทคโนโลยีหลายๆด้าน โดยไม่ได้มีเพียงแค่ Hadoop และก็ไม่ได้ เป็นการนำาเทคโนโลยีใหม่มาแทนระบบเดิม ซ่ึงเราอาจเห็นตัวอย่างของ เทคโนโลยีต่างๆดังรูป ท่ีจะเห็นว่ามีการนำาเทคโนโลยีท่ีหลากหลายมาใช้ท้ัง RDBMS, NoSQL, Hadoop, MPP และ BI เทคโนโลยี BIG DATA: HADOOP, NOSQL, NEWSQL และ MPP 9
- 18. ธนชาติ นุ่มนนท์ IMC Institute มีนาคม 2557 10 THANACHART
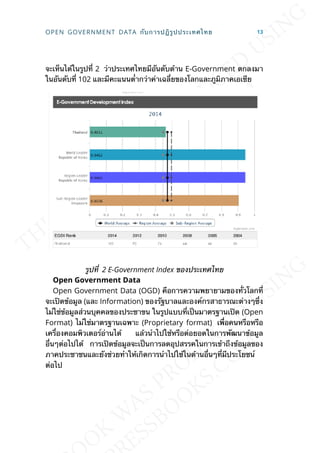
- 19. CHAPTER 3 Open Government Data กับการ ปฎิรูปประเทศไทย กระแสการปฎิรูปประเทศไทยมีการพูดถึงกันอย่างต่อเน่ืองต้ังแต่เร่ิมมีการ ชุมนุมของกปปส.จนกระท่ังเกิดการรัฐประหารของคสช.และกำาลังจะมีการ ต้ังสภาปฎิรูปข้ึน โดยต้ังเป้าหมายท่ีจะปฎิรูปไว้ 11 ด้าน ซ่ึงส่วนหน่ึงก็จะ เน้นถึงปัญหาท่ีเกิดจากการทุจริตคอร์รัปช่ันในบ้านเราท่ีเป็นรากฐานของ ปัญหาต่างๆ หลายๆคนมองว่าการแก้ปัญหาคอร์รัปช่ันเป็นเร่ืองยากและ ต้องใช้เวลา ในแง่ของคนไอทีเรามองว่าการนำาเทคโนโลยีสารสนเทศเข้ามา ใช้ในการทำางานจะมีส่วนช่วยในการสร้างธรรมภิบาลในการบริหารประเทศ โดยเฉพาะเร่ืองของ “Open Data” แต่เม่ือไปพิจารณาโครงสร้างการปฎิ รูปท่ีวางแผนไว้ท้ัง 11 ด้านจะเห็นได้ว่าเราไม่มีการพูดถึงเร่ืองไอทีเลยท้ังๆ ท่ีเป็นหน่ึงในเร่ืองท่ีสำาคัญท่ีสุดในการตรวจสอบการทำางานของภาครัฐ UN E-Government Index หากเราได้ศึกษาการสำารวจด้าน E-Government ขององค์การ สหประชาชาติท่ีทำากันมาอย่างต่อเน่ืองต้ังแต่ปี 2001 จากรายงาน United Nation E-Government Survey ท่ีออกมาทุกสองปี เราจะเห็นได้ว่าบริบท ของการสำารวจ เปล่ียนแปลงไปตามเทคโนโลยีและการสร้างธรรมาบิบาล รวมถึงพิจารณาการมีส่วนรวมของภาคประชาชนดังแสดงในรูปท่ี 1 ท่ีเรา จะเห็นได้ว่าในคร้ังแรกปี 2001 E-Government อาจจะเน้นเร่ืองของการ พัฒนาเว็บไซต์ของภาครัฐ แล้วเปล่ียนมาเน้นในเร่ืองของการใช้ Social Media ของภาครัฐในปี 2004/2006 และกลายมาเป็นเร่ืองของ Cloud
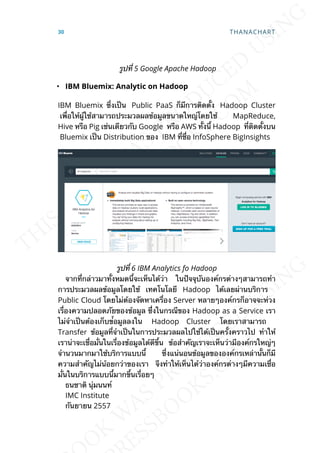
- 20. Computing/Smartphone ในปี 2010 และรายงานล่าสุดการสำารวจจะ เน้นเร่ืองของ Open Government Data/Linked Data รูปท่ี 1 การสำารวจ UN E-Government Survey ผลการสำารวจด้าน E-Government ขององค์การสหประชาชาติก็จะ สอดคล้องกับดัชนีความโปร่งใสของประเทศ ซ่ึงเราจะพบว่าประเทศท่ีมี อัตราการคอร์รัปช่ันน้อยก็จะมีอันดับ E-Government ท่ีสูง ซ่ึงการสำารวจ ล่าสุดในปี 2014 ก็จะเน้นเร่ือง Big Data และ Open Government Data และพบว่าประเทศท่ีมีการเปิดข้อมูลในภาครัฐก็จะมีคะแนนค่อนข้างสูง โดย ประเทศเกาหลีใต้ก็มีอันดับท่ีหน่ึงอย่างต่อเน่ืองมาสามสมัยท้ังน้ีเพราะ ประเทศเขาได้ปรับระบบ E-Government มาตลอดเพ่ือเน้นให้เกิดการ ทำางานภาครัฐท่ีรวดเร็วและโปร่งใส ส่วนประเทศไทยเราจะพบว่าอันดับด้าน E-Government ของเราตกลงมาตลอด ส่วนหน่ึงไม่ใช่แค่เร่ืองของการนำา เทคโนโลยีมาใช้ในภาครัฐ แต่เป็นเพราะดัชนีการคอร์รัปช่ันของประเทศสูง ข้ึน ก็ทำาให้การนำาเทคโนโลยีเข้ามาใช้เพ่ือให้เกิดความโปร่งใสเป็นไปได้ ยาก เพราะผู้บริหารประเทศก็ย่อมไม่อยากให้เกิดการตรวจสอบโดยง่า เรา 12 THANACHART
- 21. จะเห็นได้ในรูปท่ี 2 ว่าประเทศไทยมีอันดับด้าน E-Government ตกลงมา ในอันดับท่ี 102 และมีคะแนนต่ำากว่าค่าเฉล่ียของโลกและภูมิภาคเอเซีย รูปท่ี 2 E-Government Index ของประเทศไทย Open Government Data Open Government Data (OGD) คือการความพยายามของท่ัวโลกท่ี จะเปิดข้อมูล (และ Information) ของรัฐบาลและองค์กรสาธารณะต่างๆซ่ึง ไม่ใช่ข้อมูลส่วนบุคคลของประชาขน ในรูปแบบท่ีเป็นมาตรฐานเปิด (Open Format) ไม่ใช่มาตรฐานเฉพาะ (Proprietary format) เพ่ือคนหรือหรือ เคร่ืองคอมพิวเตอร์อ่านได้ แล้วนำาไปใช้หรือต่อยอดในการพัฒนาข้อมูล อ่ืนๆต่อไปได้ การเปิดข้อมูลจะเป็นการลดอุปสรรคในการเข้าถึงข้อมูลของ ภาคประชาชนและยังช่วยทำาให้เกิดการนำาไปใช้ในด้านอ่ืนๆท่ีมีประโยชน์ ต่อไป OPEN GOVERNMENT DATA กับการปฎิรูปประเทศไทย 13
- 22. รูปท่ี 3 เว็บไซต์ data.un.org ในปัจจุบันมีหลายๆประเทศและองค์กรท่ีพยายามสร้าง Open Data อาทิเช่นองค์การสหประชาชาติได้สร้าง Portal ท่ีช่ือ data.un.org หรือทาง สหราชอาณาจักรก็มีเว็บไซต์อย่าง data.gov.uk ท่ีมีข้อมูลของภาครัฐด้าน ต่างๆรวมถึงข้อมูลการใช้จ่ายของภาครัฐ และก็มีการนำาข้อมูลไปพัฒนา Application ต่างๆถึง 300 กว่า App ประเทศในเอเซียหลายๆประเทศ ท้ังญ่ีปุ่น เกาหลีใต้ และสิงคโปร์ต่างก็พัฒนา Portal สำาหรับ Open Data หลายประเทศก็ได้ออกกฎหมายให้มีการเปิดข้อมูลภาครัฐให้เป็นมาตรฐาน ท่ีคนอ่ืนๆอ่านได้ ทางสหรัฐอเมริกาโดยประธานาธิบดีโอบามาก็ได้ประกาศ นโยบาย Open Data เม่ือเดือนพฤษภาคม 2013 และมีการประกาศเร่ือง Data Act ในเดือนพฤษภาคม 2014 14 THANACHART
- 23. รูปท่ี 4 เว็บไซต์ data.gov.uk หลักการของ OGD จะมี 8 ด้านดังน้ี • Completeness ข้อมูลภาครัฐท้ังหมดท่ีไม่เก่ียวข้องกับข้อมูลส่วนบุคคล หรือความม่ันคงจะต้องถูกเปิด • Primacy ข้อมูลท่ีจะถูกเปิดจะเป็นรูปแบบเดียวกับท่ีถูกเก็บไว้ โดยไม่มี การปรับปรุงและแก้ไขก่อนเปิด • Timeliness ข้อมูลจะถูกเปิดโดยทันทีทันใด • Ease of Physical and Electronic Access ข้อมูลถูกเปิดเพ่ือให้ผู้ใช้ท่ี หลากหลายและมีจุดประสงค์ต่างกัน • Machine readability ข้อมูลจะต้องอยู่ในรูปแบบท่ีนำาไปประมวลผลได้ โดยอัตโนมัติ • Non-discrimination ทุกคนสามารถนำาข้อมูลไปใช้่ได้ โดยไม่ต้องมี การลงทะเบียนผู้ใช้ • Open formats ข้อมูลต้องเป็นมาตรฐานท่ีเปิด • Licensing ข้อมูลจะต้องไม่มีปัญหาเร่ืองลิขสิทธ์ิในการใช้งาน ประโยชน์ของ Open Government Data การทำา OGD นอกเหนือจากการสร้างความโปร่งใสและทำาให้เกิด ธรรมาภิบาลในการบริหารงานภาครัฐ เพราะข้อมูลของภาครัฐในด้านต่างๆ OPEN GOVERNMENT DATA กับการปฎิรูปประเทศไทย 15
- 24. เช่น การจัดซ้ือจัดจ้าง การใช้จ่ายเงินงบประมาณ ถูกเปิดเผยออกมาแล้ว ยัง ทำาให้เกิดประโยชน์ในด้านอ่ืนๆอีกดังแสดงในรูปท่ี 5 คือการช่วยทำาให้ บริการของรัฐดีข้ึนอาทิเช่น การเปิดเผยข้อมูลจราจรทำาให้เกิดบริการ สาธารณะท่ีดีข้ึน การเปิดเผยข้อมูลอาชญกรรมก็จะช่วยลดปัญหาต่างๆ ดัง แสดงตัวอย่างของการสร้าง Mobile App ท่ีเป็นประโยชน์จากการเปิด ข้อมูลในประเทศอังกฤษดังแสดงในรูปท่ี 6 รูปท่ี 5 ประโยชน์ของการทำา Open Government Data 16 THANACHART
- 25. รูปท่ี 6 ตัวอย่างการบริการภาครัฐท่ีดีข้ึนจาก OGD ของสหราชอาณาจักร นอกจากน้ี OGD ยังทำาเกิดธุรกิจต่างๆข้ึนมากมายและเป็นประโยชน์ต่อ สังคม โดยมีรายงานระบุว่าการทำา OGD ในกลุ่มประเทศยุโรปทำาให้เกิด มูลค่าทางเศรษฐกิจสูงถึง 4 หม่ืนล้านยูโรต่อปี การเปิดข้อมูลพยากรณ์ อากาศในสหรัฐอเมริกาทำาให้เกิดบริษัทใหม่ๆถึง 400 บริษัทและมีการ ว่าจ้างงานใหม่ถึง 4,000 ตำาแหน่ง สำาหรับประเทศสเปนการเปิดข้อมูล ทำาให้เกิดธุรกิจถึง 600 ล้านยูโรและตำาแหน่งงานใหม่มากกว่า 500 ตำาแหน่ง ล่าสุดการเลือกต้ังประธาธิบดีในประเทศอินโดนีเซีย ทางคณะกรรมการ การเลือกต้ังของเขาได้เปิดข้อมูลการนับคะแนน ทำาให้เกิดการเลือกต้ังท่ี โปร่งใสย่ิงข้ึนและเกิดปรากฎการณ์ท่ีเรียกว่า Crowdsourcing ท่ีภาค ประชาชนจากท่ีต่างๆมาร่วมกันตรวจสอบและนับคะแนนการเลือกต้ัง บทสรุป จากท่ีกล่าวมาท้ังหมดจะเห็นได้ว่า ถ้าเราจะปฎิรูปประเทศไทย และให้ เกิดความโปร่งใส แล้วยังได้บริการภาครัฐท่ีดีข้ึน รวมถึงประโยชน์เชิงธุรกิจ ถึงเวลาแล้วท่ีเราจะต้องผลักดันให้เกิดกฎหมาย Open Government Data ท่ีสอดคล้องกับหลักการท้ัง 8 ข้อของการเปิดข้อมูลภาครัฐ ธนชาติ นุ่มนนท์ OPEN GOVERNMENT DATA กับการปฎิรูปประเทศไทย 17
- 26. IMC Institute สิงหาคม 2557 18 THANACHART
- 27. CHAPTER 4 การคาดการณ์แนวโน้มของ Big Data เม่ือวานน้ีทาง IMC Institute จัดงานฟรีสัมมนาร่วมกับ Computerlogy ภายใต้หัวข้อ Big Data: From Data to Business Insight โดยมีผู้เข้าร่วม สัมมนาประมาณ 100 คน หัวข้อท่ีผมไปบรรยายในงานสัมมนาน้ีคือ Forecast of Big Data Trends เพ่ือให้ผู้เข้าร่วมสัมมนาทราบถึงแนวโน้ม ของ Big Data โดยมี Slide ท่ีใช้ในการบรรยายดังน้ี [slideshare id=38628120&w=427&h=356&style=border: 1px solid #CCC; border-width: 1px; margin-bottom: 5px; max-width: 100%;&sc=no] Forecast of Big Data Trends from IMC Institute
- 28. การบรรยายเร่ิมต้นโดยการบรรยายหลักการของ Big Data ท้ังน้ีเพราะ หลายๆคนยังเข้าใจผิดคิดว่า Big Data คือการท่ีมีข้อมูลดิจิตอลขนาด มหาศาล แต่จริงๆแล้วเรามักจะนิยามความหมายของ Big Data ด้วยคำาย่อ ว่า 3V คือ Volume, Velocity และ Variety • Volume: คือมืจำานวนข้อมูลมากเกินกว่าระบบฐานข้อมูลแบบเดิมๆจะ สามารถท่ีจะจัดการได้ • Velocity: คือข้อมูลจะมีการเปล่ียนแปลงอย่างรวดเร็ว เช่นข้อมูลจาก Social Media ข้อมูลการซ้ือขาย ข้อมูล Transaction การเงินหรือการ ใช้โทรศัพท์ หรือข้อมูลจาก Sensor • Variety: คือข้อมูลจะมีหลากหลายรูปแบบท้ัง Structure และ 20 THANACHART
- 29. Unstructure ซ่ึงอาจจะอยู่ในรูปท้ัง RDBMS, text, XML, JSON หรือ Image ดังน้ันการจัดการ Big Data จึงจำาเป็นต้องใช้ระบบการเก็บข้อมูลหรือการ ประมวลในรูปแบบอ่ืนๆท่ีอาจไม่ใช่เพียงแค่ฐานข้อมูล RDBMS แบบเดิมๆ ซ่ึงเทคโนโลยีท่ีนำามาใช้ในปัจจุบันมีท้ัง Hadoop, NoSQL, NewSQL และ MPP เราจึงเห็นได้ว่า แนวโน้มการลงทุนไอทีขององค์กรต่างๆจึงมีการ ลงทุนเพ่ือปรับปรุง Information Infrastructure มากข้ึน เพ่ือให้รองรับ กับการใช้งานด้าน Big Data คราวน้ีมาถึงการคาดการณ์แนวโน้มของ Big Data ท่ีผมได้รวบรวมมา จากแหล่งต่างๆ ผมได้สรุปมา 10 เร่ืองดังน้ี 1) Hadoop will gain in stature ตลาด Hadoop ซ่ึงเป็นซอฟต์แวร์ Open Source ท่ีใช้ในการเก็บและ ประมวลผลข้อมูลแบบ Unstructure ขนาดใหญ่จะโตข้ึนเร่ือยๆ โดย องค์กรต่างๆจะมีการลงทุนเพ่ือใช้งาน Hadoop คู่กับฐานข้อมูล RDBMS แบบเดิม และ NoSQL โดยทาง IDC ระบุว่าในปี 2012 มีการลงทุนด้าน ซอฟต์แวร์ Hadoop สูงถึง $209 ล้านเหรียญสหรัฐหรือคิดเป็น 11% ของ มูลค่าตลาดด้าน Big Data 2) SQL holds biggest promise for Big Data องค์กรส่วนใหญ่ยังใช้ภาษา SQL ในการประมวลผล สังเกตุได้จากการ ลงทุนทางเทคโนโลยีด้าน Big Data ร้อยละ 64 ขององค์กรก็ยังเป็นการ จัดหาฐานข้อมูล RDBMS แบบเดิม มีเพียง 28% ท่ีจัดหา Hadoop/ MapReduce ส่วนหน่ึงก็เป็นเพราะภาษาท่ีใช้ในการประมวลผลข้อมูลของ Hadoop ยังเป็น MapReduce ซ่ึงยากต่อการพัฒนา จึงทำาให้ผู้พัฒนา OpenSource ของ Hadoop ต้องพัฒนาเคร่ืองมือใหม่ๆอย่าง Hive, Impala หรือ Jaql เพ่ือให้ผู้ใช้สามารถใช้ภาษา SQL ได้ ทำาให้เป็นโอกาส ท่ีดีสำาหรับผู้ท่ีต้องการประมวลผล Big Data ท่ีจะสามารถประมวลผลได้ ง่ายและรวดเร็วข้ึน 3) Big Data vendor consolidation begins ในปัจจุบันเรามีผู้ผลิตซอฟต์แวร์ ฮาร์ดแวร์และผู้ให้บริการ Big Data อยู่ หลายราย โดยเฉพาะผู้ท่ีทำาด้าน Hadoop มีคนนำา Open Source ตัวน้ีมา พัฒนาต่อยอดหลายรายและทำาเป็นหลาย distribution จนเป็นเร่ืองยากท่ี ผู้ใช้จะเลือก distribution ท่ีเหมาะสม การคาดการณ์เร่ืองหน่ึงคือเราอาจ เห็นจำานวนผู้ผลิตซอฟต์แวร์เหล่าน้ีน้อยลง จะเหลือเพียงไม่ก่ีราย รายเล็กๆ การคาดการณ์แนวโน้มของ BIG DATA 21
- 30. ท่ีน่าสนใจอย่าง CloudEra ก็จะต้องมาแข่งกับบริษัทใหญ่ๆอย่าง Microsoft หรือ IBM 4) Internet of things grow การเข้ามาของอุปกรณ์ท่ีเป็น Internet of Things เช่น Wearable Devices, Smart TV จะทำาให้ข้อมูลโตข้ึนเร่ือยๆ โดยมีการคาดการณ์ว่า ภายในปี 2017 จำานวน Internet of Things จะแซงหน้าจำานวนรวมของ PC, Smartphone และ Tablet 5) More data warehouses will deploy enterprise data hubs Data warehouses จะมีการติดต้ัง Enterprise Data Hubs โดยเป็น การรวบรวมข้อมูลจากแหล่งต่างๆท้ังภายในและภายนอกองค์กร โดยจะมี รูปแบบข้อมูลท่ีหลากหลายท้ังเป็น Structure และ Unstructure โดยจะ มีการใช้เทคโนโลยี Hadoop ท่ีประหยัดค่าใช้จ่ายกว่าเทคโนโลยีอ่ืนมาทำา หน้าท่ีเป็น Data Hub และช่วยทำาหน้าท่ี O`Load ETL ข้อมูลท่ีไม่สำาคัญ มากใน Data Warehouse 6) Business intelligence (BI) will be embedded on smart systems การคาดการณ์อีกเร่ืองหน่ึงคือแนวโน้มท่ีเราจะเห็นอุปกรณ์หรือระบบ ต่างๆมีระบบ Business Intelligence (BI) ฝ่ังอยู่ในระบบ เช่นระบบการ ขายต่อไปเซลล์ขายสินค้าอาจสามารถท่ีจะดูข้อมูลและวิเคราะห์ลูกค้าผ่านอุ ปกรณมือถือได้เลยโดยเลยโปรแกรม BI ผ่าน Cloud Services 7) Less relational SQL, more NoSQL เน่ืองจากข้อมูลจะมีความหลากหลายมากข้ึน ดังน้ันการวิเคราะห์ข้อมูลท่ี เป็นโครงสร้างแบบเดิมโดยใช้ภาษา SQL จึงอาจไม่เพียงพอ ทำาให้ เทคโนโลยีท่ีเป็น NoSQL หรือท่ีเรียกว่า Not Only SQL จะเข้ามาใช้ร่วม กับฐานข้อมูล RDBMS แบบเดิม โดยเราจะเร่ิมเห็นซอฟต์แวร์ใหม่ๆเหล่าน้ี อาทิเช่น MongoDB ถูกนำามาใช้มากข้ึน 8) Hadoop will shift to real-time processing Hadoop เวอร์ช่ัน 1.x จะมีข้อจำากัดในเร่ือง Namenode ทำาให้ขยาย ขนาดเกิน 4,000 เคร่ืองไม่ได้ และมีข้อจำากัดในเร่ืองการประมวลผลข้อมูล บน HDFS ท่ีเป็น MapReduce ท่ีต้องรันแบบ Batch ไม่ใช่ Realtime แต่ใน Hadoop เวอร์ช่ัน 2.x ได้มีการปรับปรุงนำา Data Operating System อย่าง YARN เข้ามาทำาให้รูปแบบประมวลมีมากกว่า 22 THANACHART
- 31. MapReduce โดยสามารถใช้ NoSQL หรือ Stream อย่าง Python ท่ี เป็น Realtime ได้ 9) Big Data as a Service (BDaaS) ประเด็นสำาคัญหน่ึงในการประมวลผลข้อมูล Big Data คือการลงทุนจัด หาเคร่ืองคอมพิวเตอร์ Server จำานวนมากเข้าใช้งาน ซ่ึงต้องลงทุนสูงและ อาจไม่คุ้มค่า จึงเร่ิมมีการให้บริการการประมวลผลบน Cloud Service มากข้ึน ตัวอย่างเช่นการใช้ Hadoop บน Cloud ท่ีในปัจจุบันมีผู้ให้บริการ รายหลายอาทิเช่น Amazon EMR, Microsoft Azure HDInsight, IBM Bluemix และ Qubole 10) External data is as important as internal data ในปัจจุบันองค์กรจะมีข้อมูลท่ีต้องนำามาพิจารณามากข้ึน โดยจำาเป็นจะ ต้องให้ความสำาคัญกับข้อมูลจากภายนอกองค์กร อาทิเช่นข้อมูลจาก Social Media พอๆกับการให้ความสำาคัญกับข้อมูลในองค์กร เพ่ือนำาข้อมูล ต่างๆเหล่าน้ีมาวิเคราะห์เชิงธุรกิจ สุดท้ายคงต้องจบท่ีว่าทาง IMC Institute และ Computerlog ยังมี หลักสูตรอบรมเร่ือง Big Data ใหกับผู้บริหารในวันท่ี 1-2 ตุลาคมน้ีเร่ือง Big Data in Action for Senior Management ซึงผู้สนใจสามารถเข้าไป ดูรายละเอียดได้ท่ี www.imcinstitute.com/bigdatamgmt ธนชำติ นุ่มนนท์ IMC Institute การคาดการณ์แนวโน้มของ BIG DATA 23
- 33. CHAPTER 5 Big Data on Cloud ตอนท่ี 1: Hadoop as a Service Hadoop เป็นเทคโนโลยีทางด้าน Big Data ท่ีน่าสนใจเพราะสามารถท่ีจะ เก็บข้อมูลท่ีเป็น Unstructure จำานวนเป็น PetaByte ได้ ซ่ึงในทางทฤษฎี การศึกษาการติดต้ังระบบ Hadoop และการนำามา Hadoop มาใช้ในการ วิเคราะห์ข้อมูลโดยใช้โปรแกรมอย่าง MapReduce หรือใช้เทคโนโลยี ต่างๆอย่าง Hive, Pig, Scoop หรือ HBase เป็นเร่ืองไม่ยากนัก แต่ใน ทางปฎิบัติปัญหาสำาคัญท่ีองค์กรจะพบในการติดต้ัง Hadoop Big Data ก็ คือการหาเคร่ือง Server จำานวนมากมาเพ่ือติดต้ังระบบ Hadoop Cluster จำานวนต้ังแต่ 5 เคร่ืองไปจนเป็นร้อยเป็นพันเคร่ือง
- 34. รูปท่ี 1 Hadoop Lifecycle [Source: Rackspace] การแก้ปัญหาในเร่ืองการจัดหา Server อาจทำาได้โดยการใช้ระบบ Public Cloud ซ่ึงก็จะเป็นการลดค่่าใช้จ่ายขององค์กร ท้ังน้ีรูปแบบของ การใช้ Hadoop บน Public Cloud มีสองแบบคือ 1. ติดต้ัง Hadoop Cluster โดยใช้ Virtual Server ในระบบ Public IaaS Cloud อย่าง Amazon Web Services (AWS) หรือ Microsoft Azure กรณีน้ีจะใช้ในกรณีท่ีเราจะต้องการนำา Hadoop มาใช้ในการเก็บข้อมูลขนาดใหญ่โดยใช้ HDFS และใช้ในการ วิเคราะห์ข่้อมูลโดยใช้เคร่ืองมืออย่าง MapReduce, Hive, Pig 2. การใช้บริการ Hadoop as a Service ของ Public Cloud Provider ท่ีได้ติดต้ังระบบ Hadoop ไว้แล้ว และเราต้องการใช้ระบบ ท่ีมีอยู่เช่น MapReduce, Hive, Pig มาใช้ในการวิเคราะห์ข้อมูล ท้ังน้ี ข้อมูลท่ีจะนำามาวิเคราะห์อาจอยู่ในองค์กรเราหรือเก็บไว้ท่ีอ่ืน การใช้ Public Cloud ในกรณีท่ี 1 ถ้ามีข้อมูลขนาดใหญ่มาก ก็อาจจะมี ค่าใช้จ่ายท่ีสูง ย่ิงถ้ามีจุดประสงค์เพ่ือท่ีจะใช้ในการเก็บข้อมูลแบบ Unstructure ก็ดูอาจไม่คุ้มค่านัก แต่ก็มีข้อดีท่ีมีระบบ Hadoop Cluster ท่ีติดต้ังเองและไม่ต้องใช้ร่วมกับคนอ่ืน ผู้เขียนเองเคยทดลองติดต้ังระบบ แบบน้ีโดยใช้ Azure HDInsight และทดลองติดต้ัง Hadoop CloudEra 26 THANACHART
- 35. Distribution ลงใน AWS EC2 และล่าสุดทดลองติดต้ัง Apache Hadoop Cluster 4 เคร่ืองลงบน AWS EC2 สำาหรับกรณีท่ี 2 น่าจะเหมาะกับผู้ต้องการวิเคราะห์ข้อมูลขนาดใหญ่เช่น ข้อมูลท่ีเป็น Text หรือ ข้อมูลจาก Social Media โดยใช้่เทคโนโลยี Hadoop โดยไม่ต้องการลงทุนซ้ือเคร่ือง Server และก็ไม่ได้เน้นท่ีจะใช้ Hadoop Cluster ในการเก็บข้อมูลอย่างถาวร ในปัจจุบันมีผู้ให้บริการ Cloud Computing อยู่่หลายรายท่ีให้บริการ Hadoop as a Service โดย จะคิดค่าบริการตามระยะเวลาท่ีใช้ในการประมวลผล และอาจรวมถึงขนาด ของข้อมูล การใช้ Bandwidth ตัวอย่างของผู้ให้บริการมีดังน้ี • Amazon Elastic Map Reduce เป็นบริการ Hadoop Cluster ของ AWS ท่ีผู้ใช้บริการสามารถท่ีจะเลือก ขนาดของ Cluster หรือภาษาท่ีจะใช้การวิเคราะห์ข้อมูลเช่น Java สำาหรับ MapReduce หรือ Python สำาหรับ Streaming และ Hive, Pig ผู้เขียน เองเคยใช้ AWS EMR ในการวิเคราะห์ข้อมูลดยการ Transfer ข้อมูลผ่าน Amazon S3 ก็สะดวกและใช้งานง่าย ท้ังน้ี Hadoop Distribution ท่ีลง บน EMR ผู้ใช้สามารถเลือกได้ระหว่าง Amazon หรือ MapR Distribution รูปท่ี 2 ตัวอย่างการใช้ Amazon EMR • Rackspace Cloud Big Data Platform Rackspace หน่ึงในผู้นำาด้าน Public IaaS Cloud มีบริการท่ีเรียกว่า Hadoop as a Service เพ่ือให้ผู้ใช้สามารถท่ีจะส่งข้อมูลมาประมวลผลได้ โดยได้ร่วมมือกับ Hortonworks ในการติดต้ัง Distribution ของ Hadoop BIG DATA ON CLOUD ตอนท่ี 1: HADOOP AS A SERVICE 27
- 36. รูปท่ี 3 Rackspace Big Data • Qubole Qubole เป็นผู้ให้บริการ Hadoop as a Service โดยเฉพาะ ซ่ึงทางบริษัท น้ีติดต้ัง Hadoop Cluster บนเคร่ือง Server ของ AWS และ Google Compute Engine คิดค่าบริการ Data Service ในการวิเคราะห์ข้อมูลท้ัง แบบเหมาจ่ายรายเดือน (เร่ิมต้ังแต่ $5,900 ต่อเดือน) และตามการใช้งาน ($0.11 ต่อ Computing Hour และ $0.22 ต่อ import/export) 28 THANACHART
- 37. รูปท่ี 4 Qubole.com • Google Cloud Platform Google มีระบบ Apache Hadoop ท่ีรันอยู่บน Google Cloud ให้ผู้ใช้ สามารถประมวลข้อมูลโดยใช้ MapReduce, Hadoop Streaming, Hive หรือ Pig ท่ีเก็บอยู่บน Google Cloud Storage ได้ โดยคิดค่าใช้จ่ายตาม ปริมาณการใช้งาน BIG DATA ON CLOUD ตอนท่ี 1: HADOOP AS A SERVICE 29
- 38. รูปท่ี 5 Google Apache Hadoop • IBM Bluemix: Analytic on Hadoop IBM Bluemix ซ่ึงเป็น Public PaaS ก็มีการติดต้ัง Hadoop Cluster เพ่ือให้ผู้ใช้สามารถประมวลผลข้อมูลขนาดใหญ่โดยใช้ MapReduce, Hive หรือ Pig เช่นเดียวกับ Google หรือ AWS ท้ังน้ี Hadoop ท่ีติดต้ังบน Bluemix เป็น Distribution ของ IBM ท่ีช่ือ InfoSphere BigInsights รูปท่ี 6 IBM Analytics fo Hadoop จากท่ีกล่าวมาท้ังหมดน้ีจะเห็นได้ว่า ในปัจจุบันองค์กรต่างๆสามารถทำา การประมวลผลข้อมูลโดยใช้ เทคโนโลยี Hadoop ได้เลยผ่านบริการ Public Cloud โดยไม่ต้องจัดหาเคร่ือง Server หลายๆองค์กรก็อาจจะห่วง เร่ืองความปลอดภัยของข้อมูล ซี่ึงในกรณีของ Hadoop as a Service เรา ไม่จำาเป็นต้องเก็บข้่อมูลลงใน Hadoop Cluster โดยเราสามารถ Transfer ข้อมูลท่ีจำาเป็นในการประมวลผลไปใช้ได้เป็นคร้ังคราวไป ทำาให้ เราน่าจะเช่ือม่ันในเร่ืองข้อมูลได้ดีข้ึน ข้อสำาคัญเราจะเห็นว่ามีองค์กรใหญ่ๆ จำานวนมากมาใช้บริการแบบน้ี ซ่ึงแน่นอนข้อมูลขององค์กรเหล่าน้ันก็มี ความสำาคัญไม่น้อยกว่าของเรา จึงทำาให้เห็นได้ว่าองค์กรต่างๆมีความเช่ือ ม่ันในบริการแบบน้ีมากข้ึนเร่ือยๆ ธนชาติ นุ่มนนท์ IMC Institute กันยายน 2557 30 THANACHART
- 39. CHAPTER 6 Big Data Analytics กับความ ต้องการ Data Scientist ตำาแหน่ง งานท่ีน่าสนใจในปัจจุบัน ช่วงเดือนท่ีผ่านมาผมมีโอกาสได้บรรยายและพูดคุยกับคนไอทีจำานวนมาก เร่ือง Big Data พอพูดถึงปัญหาเร่ืองการขาดบุคลากรด้าน Data Scientist ดูเหมือนหลายๆคนไม่เข้าใจว่าตำาแหน่งงานน้ีทำาอะไร บ้างก็บอก ว่าองค์กรมี Business Intelligence (BI) Analyst ท่ีเช่ียวชาญอยู่แล้ว บ้าง ก็บอกว่าองค์กรมีโปรแกรมเมอร์ท่ีเก่งด้านการพัฒนาโปรแกรมอย่าง MapReduce บน Hadoop อยู่มาก น้ันละคือ Data Scientist พอเม่ือ วันก่อนได้อ่านบทความของ ดร.อธิป อัศวานันท์ ผู้บริหารของ True และ รองประธานกรรมการธุรกิจเทคโนโลยีสารสนเทศและการส่ือสาร หอการค้า ไทย เร่ือง “ความเข้าใจท่ีผิดๆ เก่ียวกับ Big Data และ Analytics (1)” ย่ิง ทำาให้เห็นสอดคล้องกับท่านว่า บ้านเรากำาลังเข้าใจเร่ืองน้ีผิดกันไปใหญ่ เพ่ือความเข้าใจเก่ียวกับงานทางด้าน Data Scientist คงจะขอเร่ิมจาก ความหมายของ Big Data ซ่ึงเคยให้ความหมายไปหลายคร้ังว่า โลกใน ปัจจุบันกำาลังเผชิญกับข้อมูลขนาดใหญ่ (Volume) หลากหลายรูปแบบ (Variety) ท่ีมีการเปล่ียนแปลงอย่างรวดเร็ว (Velocity) ดังน้ันการจะได้ ประโยชน์จากข้อมูลแบบน้ีจำาเป็นจะต้องหาเคร่ืองมือใหม่ๆมาใช้งานเช่น Hadoop, NoSQL หรือ NewSQL ซ่ึงการทำา Big Data ก็มีระดับของ Maturity Level ดังแสดงในรูปท่ี 1 ข้ึนอยู่กับว่าเราจะการนำาข้อมูลมาใช้
- 40. แบบใด โดยระดับต้่นๆก็จะเป็นการทำา Business Monitor หรือข้ันต่อมา ก็อาจเป็นการทำา Business Insight ท่ีต้องใช้ BI ไปจนถึงระดับอย่าง Business Optimization ท่ีต้องมีการทำา Analytics ดังน้ันการทำา Big Data ในระดับต้นก็อาจไม่มีด้าน Analytic มากนักแต่ก็จะไม่ได้ประโยชน์ จากข้อมูลเท่าท่ีควร เพราะการคาดการณ์อนาคตได้จากข้อมูลมหาศาลคือ ความได้เปรียบเหนือคู่แข่ง รูปท่ี 1 Big Data Maturity Level จากหนังสือ Big Data: Understanding How Data Powers Big Business คราวน้ีก็อาจเร่ิมมีคำาถามว่า Business Insight ท่ีใช้ BI Analyst และ Business Optimization ท่ีใช้ Data Scientist มีความต่างกันอย่างไร เพ่ือความเข้าใจในการวิเคราะห์ท้ังสองส่วนน้ีลองพิจารณาดูรูปท่ี 2 เราจะ เห็นว่าท้ังสองกรณีเป็นการวิเคราะห์ข้อมูล แต่กรณีของ BI จะเป็นการ วิเคราะห์ข้อมูลท่ีมีอยู่เพ่ือมาดูสถานภาพปัจจุบันดูข้อมูลท่ีผ่านมา อาจเอา นักสถิติมาวิเคราะห์ข้อมูล เขียนกราฟในมิติต่างๆ เพ่ือทำาให้เราเข้าใจข้อมูล ได้ดีข้ึนซ่ึงก็จะมีประโยชน์ในระดับหน่ึง แต่เม่ือพูดถึง Data Scientist คือ การวิเคราะห์ข้อมูลท่ีเป็นการคาดการณ์ส่ิงท่ีน่าจะเกิดข้ึนจากข้อมูลในอดีต จำานวนมากท่ีมีอยู่เช่น การคาดการณ์สินค้าท่ีผู้ใช้จะซ้ือ การคาดการณ์การ ตลาด การพยากรณ์เหตุการณ์ต่างๆทางวิทยาศาสตร์ ส่ิงเหล่าน้ีคือ Predictive Analytic ท่ีต้องการนักวิจัยทีมีความรู้ด้าน Algorithm อย่าง เช่น Machine Learning เป็นอย่างดี 32 THANACHART
- 41. รูปท่ี 2 ความแตกต่างระหว่าง BI และ Data Scientist จากหนังสือ Big Data: Understanding How Data Powers Big Business ผมเองเคยทำาวิจัยปริญญาเอกและเขียนบทความเร่ือง Optimal Power Dispatch in Multinode Electricity Market Using Genetic Algorithm ซ่ึง เป็นการคาดการณ์การผลิตไฟฟ้าโดยใช้ทฤษฎีอย่าง Genetic Algorithm ซ่ึงต้องใช้โมเดลคณิตศาสตร์ในการคาดการณ์อนาคต ท่ีเป็นเร่ืองค่อนข้าง ยาก แม้วันน้ีผมจะเป็นนักไอทีท่ีเล่นเคร่ืองมือ Big Data หลายตัวไม่ว่าจะ เป็น Hadoop การพัฒนาโปรแกรมอย่าง Map Reduce, Hive หรือ Big แต่ก็ไม่กล้าท่ีจะเรียกตัวเองว่าเป็น Data Scientist เพราะแม้จะมีความรู้ ด้าน Predictive Algorithm มาบ้างแต่ก็ล้ามือมานานและวันน้ีไม่ใช้ คณิตศาสตร์มากแบบเดิมแล้ว เพ่ือให้เข้าใจเร่ืองความแตกต่างเด่ียวกับ BI และ Data Scientist มาก ข้ึน ผมขอยกตัวอย่างในกรณีท่ีมีข้อมูลการขายของร้านบน E-Commerce ของเราอยู่ ถ้าเรามีคำาถามอย่างเช่น • ยอดขายสินค้าเราในเดือน หรือไตรมาสท่ีผ่านมาเป็นอย่างไร BIG DATA ANALYTICS กับความต้องการ DATA SCIENTIST ตำาแหน่งงานท่ีน่าสนใจในปัจจุบัน 33
- 42. • ผู้ซ้ือสินค้ามีอายุเฉล่ียเท่าไร เพศอะไร • ผู้ท่ีเข้าเย่ียมชมเว็บไซต์มีค่าเฉล่ียการซ้ือจริงเท่าไร การวิเคราะห์ข้อมูลเหล่าน้ีคือ BI เราอาจใช้นักสถิติมาวิเคราะห์ มาเขียน กราฟ หรือถ้าข้อมูลเป็นแบบ unstructure ท่ีอยู่บน Hadoop เราก็อาจให้ Programmer เขียนโปรแกรม MapReduce มาวิเคราะห์ได้ คราวน้ีถ้าคำาถามเราเปล่ียนไปเป็นแบบการคาดการณ์อนาคต อาทิเช่น • ผู้ซ้ือคนน้ีควรจะซ้ือสินค้าอะไรในอนาคต (Next Thing to Buy) • เราควรส่ังสินค้าอะไรมาขายเพ่ิมเติม • ยอดขายในไตรมาสหน้าน่าจะประมาณการเท่าไร คำาถามแบบน้ี คนท่ีเป็น BI หรือ Programmer ท่ัวไป คงจะให้คำาตอบไม่ ได้ เพราะจะต้องถามว่าแล้วฉันจะรู้ได้อย่างไร การจะหาคำาตอบเหล่าน้ีได้น้ี คนท่ีจะวิเคราะห์ต้องมีความรู้ด้าน Predictive Analytic หรือ Machine Learning ต้องรู้ว่าจะเอาข้อมูลอะไรมาวิเคราะห์และต้องใช้ Algorithm อะไร ซ่ึงคนท่ีไม่ได้ศึกษาทางด้านน้ีย่อมไม่เข้าใจและทำาไม่ได้โดยง่าย ปัจจุบันผมกำาลังให้คำาปรึกษานักศึกษาปริญญาโทคนหน่ีึงเร่ืองของ Big Data Analytic นอกจากให้ศึกษาการติดต้ัง Hadoop การพัฒนา โปรแกรมอย่าง MapReduce หรือ Hive แล้ว ผมต้องให้เขาศึกษา Machine Learning และเครืองมืออย่าง Apache Mahout เพ่ือท่ีจะทำา Predictive Analytic ในการคาดการณ์ข้อมูลในอนาคต และพอมาอ่าน หนังสืออย่าง Mahout ท่ีจะพูดถึงโมเดลทางคณิตศาสตร์ด้าน Classication อย่าง Hidden Markov Models คนท่ีล้างานวิจัยด้าน คณิตศาสตร์อย่างผมมานานก็เร่ิมงง หลายๆท่านอาจแปลกใจว่า แล้วบริษัทใหญ่ๆท่ัวโลก เขาหา Data Scientist มาจากไหน ผลสำารวจของ NewVantage Partner เม่ือปี2013 ก็ระบุว่าตำาแหน่งน้ีหายากมาก 6% บอกว่าไม่มีทางท่ีจะหาได้ 60% บอกว่า หายากมาก และส่วนมากก็จะต้องหาคนท่ีจบปริญญาเอกด้านคณิตศาสตร์ หรืออาจต้องดึงตัวมาจากบริษัทใหญ่ๆอย่าง Facebook หรือ Google ดังน้ันจึงมีการบอกกันว่าตำาแหน่งงาน Data Scientist ในปัจจุบันเป็นงาน ท่ีดีมากให้เงินเดือนสูงๆ และหาคนได้ยากมาก ผมเคยได้ยินว่าบริษัทอย่าง 34 THANACHART
- 43. Singtel ของสิงคโปร์หา Data Scientist มาโดยการดึงคนจบปริญญาเอก ด้านคณิตศาสตร์จากยุโรปตะวันออก รูปท่ี 3 Big Data Talent Survey สุดท้ายหลายคนก็ต้ังคำาถามว่า ถ้าเราไม่มี Data Scientist เราจะทำา Big Data ได้ไหม จริงๆเราก็คงทำาได้ละครับในมุมของ Business Insight แต่ ถ้าจะเป็นมุมของ Analytic ท่ีต้องการ Predictive Analytic ก็คงจะเหน่ือย หน่อยครับอาจต้องหาคนไปศึกษาโมเดลคณิตศาสตร์และ Algorithm เหล่าน้ี แต่ยังไงเราก็ควรต้องเร่ิมต้น ผมเองวันน้ีก็เน้นในการจัดอบรมสร่้าง IT Prefessional ด้าน Big Data โดยเน้นเทคโนโลยีอย่าง Hadoop และ หวังว่าในอนาคตจะมี Data Scientist ท่ีเก่งๆจำานวนมากข้ึน ธนชาติ นุ่มนนท์ IMC Institute ตุลาคม 2557 BIG DATA ANALYTICS กับความต้องการ DATA SCIENTIST ตำาแหน่งงานท่ีน่าสนใจในปัจจุบัน 35
- 45. CHAPTER 7 Big Data on Cloud ตอนท่ี 2: BI/ Analytics as a Service เม่ือเดือนก่อนผมเขียนบทความเร่ือง การคาดการณ์แนวโน้มของ Big Data โดยคาดการณ์ด้านๆต่างไว้ 10 เร่ือง และได้กล่าวถึงเร่ือง Big Data as a Service (BDaaS) ไว้ โดยเช่ือว่าจะมีการให้ความสำาคัญกับการทำา Big Data บน Cloud มากข้ึน ซ่ึงมีการคาดการณ์ว่ามูลค่าการตลาดของ Big Data ในปี 2021 จะสูงถึง 88 พันล้านเหรียญสหรัฐและถ้าคิดมูลค่า Big Data as a Service ว่าจะมีมูลค่าประมาณ 35% ของตลาดก็จะทำาให้มี มูลค่าสูงถึง 30 พันล้านเหรียญสหรัฐ และผมได้แสดงแผนภาพของ BDaaS ท่ีเร่ิมพูดถึง as a Service อ่ืนๆ นอกเหนือจากคำาว่า IaaS, PaaS และ SaaS ท่ีเราคุ้นเคยกันดี ดังรูปท่ี 1
- 46. รูปท่ี 1 Big Data as a Service จากจะรูปจะเห็นว่า BDaaS จะมีบริการอย่าง Compute as a Service เช่น EC2 บน Amazon Web Services (AWS) หรือ Storage as a Service เช่น S3 บน AWS หรือบริการอย่าง Data as a Service อาทิเช่น • Database as a Service อย่าง SQL Server บน Azure หรือ RDS บน AWS หรือ • NoSQL as a Service เช่น Mongo DB บน Bluemix หรือ Heroku • Hadoop as a Service อย่าง Amazon EMR, Microsoft Azure HDInsight, Rackspace Cloud Big Data Platform, IBM Bluemix และ Qubole (ผมเองก็ได้เขียนบทความเร่ือง “Big Data on Cloud: Hadoop as a Service “) คราวน้ีพอมาถึงเร่ืองสุดท้าย Analytics as a Service ก็เร่ิมมีประเด็นข้ึน มาบ้างเพราะหลายๆคนไม่เข้าใจความแตกต่างระหว่าง Big Data, Business intelligence และ Analytics พอดีได้อ่านบทความของดร. อธิป อัศวานันท์ รองประธานกรรมการธุรกิจเทคโนโลยีสารสนเทศและการ ส่ือสาร หอการค้าไทย เร่ือง “ความเข้าใจท่ีผิดๆ เก่ียวกับ Big Data และ Analytics (1)” ก็ย่ิงทำาให้เห็นสอดคล้องกับท่านว่าคนไทยยังไม่เข้าใจเร่ือง น้ีดี คิดไปว่า Programmer หรือ BI Analyst จะสามารถเป็น Data 38 THANACHART
- 47. Scientist ทำาเร่ือง Analytics ได้ ผมเลยได้เขียนบทความเร่ือง “Big Data Analytics กับความต้องการ Data Scientist ตำาแหน่งงานท่ีน่าสนใจใน ปัจจุบัน” เพ่ือย้ำาให้เห็นว่าอะไรคือคำาว่า Analytics และต่่างกับ BI อย่างไร ตัวผมเองเรียนปริญญาโทและเอกมาทางด้าน Electrical and Electronic Engineering สมัยน้ันจำาได้ว่ามีเพ่ือนหลายๆคนทำา วิทยานิพนธ์ทางด้าน Neural Networks ซ่ึงก็เป็นคณิตศาสตร์โมเดลด้าน Analytics แบบหน่ึง และปีท้ายๆของการเรียนปริญญาเอกและการทำาวิจัย หลังจากจบปริญญาเอกก็ต้องมาจัับเร่ือง Analytics กับเขาบ้าง ตอนน้ันทำา เร่ือง Parallel Genetic Algorithm เพ่ือคาดการณ์ราคาจำาหน่ายไฟฟ้า ของ Spot Market ท่ีโรงไฟฟ้าใน New Zealand ต้องแข่งขันกัน การเรียน ปริญญาเอกท่ีใช้เวลาหลายปี ดูวุ่นวายกับโมเดลคณิตศาสตร์ และ Algorithm ทำาให้บางคร้ังก็ท้อ และถามตัวเองหลายคร้ังว่า เรามาทำาอะไร เสียเวลาอยู่หลายๆปีกับการคำานวณอะไร ขณะท่ีเพ่ือนๆหลายคนจบออกมา ก็มีความก้าวหน้าทางการงานไปประกอบอาชีพแล้ว พอจบมาสอนหนังสือ นักศิึกษาอีกสิบกว่าปี ก็ได้ใช้โมเดลคณิตศาสตร์เหล่าน้ีอีกน้อยมาก จนลืม เร่ืองเหล่าน้ีไป มาวันน้ีพอคำาว่า Big Data Analytics กำาลังเข้ามา และได้มีโอกาสให้ คำาปรึกษาอาจารย์และนักศึกษา รวมถึงให้คำาปรึกษาบริษัทต่างๆด่้าน Big Data ทำาให้เร่ิมเห็นคุณค่าของส่ิงท่ีได้เรียนมา และเร่ิมเข้าใจว่าอะไรคือ ประโยชน์ของการเรียนรู้ Predictive Analytics และน่าจะเป็นประโยชน์ใน อนาคตไม่มากก็น้อย ซ่ึงก็จะช่วยทำาให้เราเข้าใจการวิเคราะห์ข้อมูลใน อนาคตได้ดีข้ึนซ่่ึงเป็นการใช้ Big Data ให้ได้ประโยชน์มากข้ึน ถ้าเรามาพิจารณา Product ทางด้าน BI and Analytics จะพบว่ามี รายงานของ Gartner เม่ือเดือนกุมภาพันธ์ปีน้ีเร่ือง Magic Quadrant for Business Intelligence and Analytics Platforms ท่ีวิเคราะห์ Product ทางด้านน้ี ซ่ึงทาง Gartner จะพิจารณา Product จากคุณลักษณะต่างๆ อาทิเช่น ความสามารถในการทำา Report, Dashboard, Interactive visualization หรือการพิจารณาว่ามีความสามารถด้าน advanced analytics เช่น forecasting algorithms หรือดูความสามารถในการท่ี เช่ือมโยงกับข้อมูล Big Data อ่ืนๆอย่าง Hadoop ซ่ึงผลการวิเคราะห์จะ พบว่า Product หลายๆตัวก็จะมีความสามารถท่ีแตกต่างกันและไม่ได้มี feature ท่ีทำาได้ทุกด้าน โดย Gartner ได้สรุปรูปของ Magic Quadrant ดังน้ี BIG DATA ON CLOUD ตอนท่ี 2: BI/ANALYTICS AS A SERVICE 39
- 48. รูปท่ี 2 Gartner’s Magic Quadrant for Business Intelligence and Analytics Platforms เม่ือพูดถึงความแตกต่างระหว่าง BI กับ Predictive Analytics และ Product ต่างๆท่ีกล่าวมาแล้ว เราอาจจะเร่ิมเห็นความแตกต่างระหว่าง BI as a Service และ Analytics as a Service ซ่ึงในปัจจุบันบริการบน Cloud ส่วนใหญ่จะระบุว่าเป็น BI as a Service ตัวอย่างเช่น • Jaspersoft BI for AWS • SAP BusinessObjects BI on Demand • BIME • Birst 40 THANACHART
- 49. รูปท่ี 3 BIME: BI as a Service BI as a Service บน Cloud เหล่าน้ีโดยมากจะสามารถวิเคราะห์ข้อมูล จาก Data ท่ีมาจากแหล่งต่างๆได้ บางตัวก็อาจสนับสนุน Big Data ท่ีเป็น unstructure หรือบางตัวก็จะมี Analytics Engine ท่ี Embedded เข้ามา และทำาให้เราใช้ Algorithm วิเคราะห์และคาดการณ์ข้อมูลได้ก่อนท่ีจะใช้ เคร่ืองมืออย่าง BI ในการท่ีจะทำา Report/ Dashboard หรือทำา Visualization ในมุมมองต่างๆ อาทิเช่น Birst ดังแสดงให้เห็นในรูป รูปท่ี 4 Birst Data Sheet BIG DATA ON CLOUD ตอนท่ี 2: BI/ANALYTICS AS A SERVICE 41
- 50. รูปท่ี 5 IBM Watson Analytics แต่เม่ือมาดู Analytics บน Cloud ส่วนใหญ่ก็ยังไม่ได้มี Analytics Algorithm ท่ีชาญฉลาดมากนัก แต่ก็อาจช่วยลดความจำาเป็นของความ ต้องการ Data Scientist ไปได้บ้าง เพราะอาจใช้เคร่ืองมือเหล่าน้ีเข้ามา ช่วยได้ แต่ท่ีน่าสนใจและกำาลังเป็นเร่ืองท่ีน่าจับตามองก็คือการเปิดตัวของ IBM Watson Analytics ซ่ึงเป็น ระบบคอมพิวเตอร์ Articial Intelligent ของ IBM ท่ีจะให้บริการบน Cloud ในเดือนพฤศจิกายนน้ี และ ก็น่าจะเป็น Analytics as a Service บน Cloud ท่ีแท้จรืงตัวหน่ึง ซ่ึงจะ เปล่ียนโลกของการวิเคราะห์ Big Data ไปอย่างมาก และเคร่ืองมือเหล่าน้ี อาจเข้ามาช่วยแทนท่ีความต้องการหา Data Scientist ในอนาคตไปได้ ธนชาติ นุ่มนนท์ IMC Institute ตุลาคม 2557 42 THANACHART
- 51. CHAPTER 8 Online Courseware และหนังสือ Big Data ท่ีน่าอ่าน ผมเร่ิมสนใจเร่ือง Big Data มาได้ซักพักหน่ึง และโชคดีท่ีมีโอกาสได้อ่าน หนังสือหลายเล่ม เรียนรู้ท้ังจาก Online Courseware ต่างๆท้ังท่ีฟรีและ เสียเงิน จริงๆท่านหน่ึงท่ีต้องขอบคุณอย่างมากคือ คุณดนัยรัฐ ธนบดี ธรรมจารี จาก Oracle ท่ีได้มาช่วยสอนและแนะนำาการติดต้ัง Hadoop ทำาให้ผมได้เร่ิมลงมือปฎิบัติในเร่ืองของ Big Data มากข้ึนไม่ใช่แค่อ่านแต่ หนังสือ ซ่ึงก็ได้ศึกษา Hadoop และ Big Data มาอย่างต่อเน่ือง ท้ังการใช้ เคร่ืองมือต่าง การใช้ Big Data as a Service บน Cloud เช่น Amazon Elastic Map Reduce การเรียนรู้ภาษาหรือ Tool ต่างๆเช่น Hive, Pig, HBase, Hue หรือ Mahout รวมถึงการอ่านหนังสืออีกหลายสิบเล่ม ลอง มาดูกันครับว่ามีแหล่งข้อมูลไหนบ้างครับสำาหรับการศึกษา Big Data และ Hadoop Online Courseware มีเว็บไซต์ดีๆหลายอันท่ีสอนเร่ือง Big Data โดยเฉพาะเร่ืองของ Hadoop อาทิเช่น • www.bigdatauniversity.com : ซ่ึงเป็นเว็บไซต์การเรียนรู้ Big Data ของ IBM จะมี Courseware ดีๆอยู่หลายหลักสูตรท่ีมีท้ัง Slide เสียง บรรยาย และ Hand-on Lab อาทิเช่น Big Data Fundamentals, Hadoop Fundamentals หรือ Course ท่ีเรียนรู้เคร่ืองมือบางอย่าง
- 52. เช่น Moving Data into Hadoop แต่อย่างไรก็ตาม Hand-on Lab ใน courseware เหล่าน้ีจะผูกอยู่กับ IBM Infosphere BigInsight • Cloudera Online Training: Cloudera เป็นบริษัทท่ีเด่นท่ีสุดบริษัท หน่ึงในการทำา Hadoop Distribution ส่วนหน่ึงก็เป็นเพราะว่าคนท่ีเร่ิม คิดโปรเจ็ค Hadoop อยู่ท่ีบริษัทน้ี Cloudera จะมี Online Courseware ดีๆหลายตัว อาทิเช่น Introduction to Hadoop and MapReduce นอกจากน้ียังมี Hand-on Training ซ่ึงใช้เคร่ืองมือของ Cloudera Live ท่ีอยู่บน Cloud ให้สามารถฝึกและเรียนรู้การใช้ เคร่ืองมือต่างๆอย่าง Pig หรือ Hive ได้ • Simplilearn: ในปัจจุบันมี Courseware ท่ีผู้เรียนสามารถจ่ายเงินเรียน Online ได้หลายๆหลักสูตร ผมเองเคยเรียนหลักสูตรของ Simplilearn ท่ีค่าเรียนประมาณร้อยกว่าเหรียญ เน้ือหาก็ดีพอควรสำาหรับผู้สนใจ เร่ิีมต้่นการทำา Big Data โดยใช้ Hadoop พร้อมท้ังมีแบบฝึกหัดให้ทำา หนังสือด้ำน Big Data มีหนังสือหลายเล่มมากท่ีเก่ียวข้องกับ Big Data ท่ีผมมีโอกาสอ่าน ท่ีได้ อ่านหลายเล่มเป็นเพราะผมเป็นสมาชิก Safari Book Online ทำาให้ สามารถค้นหนังสือมาอ่านได้จำานวนมาก แต่บางเล่มก็ซ้ือมาอ่านใน Kindle หนังสือต่างๆท่ีผมอยากแนะนำามีดังน้ี 44 THANACHART
- 53. Big Data: Understanding How Data Powers Big Business หนังสือเล่มน้ีเหมาะกับผู้บริหารท่ีต้องการทำาความเข้าใจเก่ียวกับ Big Data ซ่ึงไม่ได้ต้องการลงด้านเทคนิคมากนัก หนังสือเล่มน้ีจะให้คำาตอบ ความหมายของ Big Data ผลกระทบต่อธุรกิจ การวางแผนกลยุทธ์ Big Data สำาหรับองค์กร การกำาหนดทีมงาน และการวางแผนต่างๆ นับเป็น หนังสือท่ีดีมากสำาหรับผู้บริหารท่ีต้องการทำาความเข้าใจและวางแผน Big Data ขององค์กร Big Data Analytics: Turning Big Data into Big Money: เป็น หนังสืออีกเล่มสำาหรับผู้บริหาร โดยจะกล่าวถึงความหมายของ Big Data พูดถึง Business Case การสร้าง Big Data Team การหา Big Data Source และอ่ืนๆ ผมว่าหนังสือเล่มน้ีอ่านง่ายกว่าเล่มแรก แต่เล่มแรกจะมี ทฤษฎีและ template ต่างๆ ให้เรานำาไปใช้ได้ดีกว่า Planning for Big Data: หนังสืออีกเล่มหน่ึงท่ีเป็นการกล่าวถึง Big Data ในลักษณะ High Level หนังสือออกมาเม่ือปี 2012 ซ่ึงน่าจะอิงกับ Microsoft พอสมควร แต่ข้อดีคือเป็นหนังสือท่ีสามารถหาอ่านได้ฟรีทาง Amazon Kindle ในหนังสือจะพูดถึงความหมายของ Big Data, Apache Hadoop, Big Data Market Survey, Big Data in the Cloud และจะมี บทหน่ึงพูดถึง Microsoft’s Plan for Big Data Hadoop Real-World Solutions Cookbook: หนังสือเล่มน้ีเหมาะ ONLINE COURSEWARE และหนังสือ BIG DATA ท่ีน่าอ่าน 45
- 54. สำาหรับนักไอทีท่ีต้องการเรียน Hadoop และโปรแกรมอ่ืนๆท่ีเก่ียวข้องของ Hadoop จะมีบทท่ีแนะนำา Hadoop และองค์ประกอบอ่ืนๆเช่น HDFS, MapReduce, Hive และ Pig หนังสือเล่มน้ีจะมีเน้ือหาท่ีดีในการแนะนำาการ เขียนโปรแกรม MapReduce โดยใช้ภาษา Java และมีตัวอย่างทีดีในการ เขียนโปรแกรมโดยเฉพาะในบทท่ี 6 ท่ีว่าด้วยเร่ือง Big Data Analysis Hadoop in Practice: หนังสือด่้านเทคนิคอีกเล่มหน่ึงท่ีค่อนข้างจะ ละเอียด และอาจจะอ่านยากกว่าเล่มก่อนหน้าน้ี เหมาะสำาหรับ Programmer ท่ีเข้าใจ command line ของ Linux เน้ือหาข้างในละเอียด มาก จุดเด่นของหนังสือเล่มน้ีคือส่วนท่ี 4 ท่ีกล่าวถึง Data Science และจะ มีบทท่ีพูดถึง Algorithm ตัวอย่างการใช้ R และ Mahout Hadoop: The DeDnitive Guide: หนังสืออีกเล่มท่ีแนะนำา Hadoop หนังสือเล่มน้ีจะแนะนำาซอฟต์แวร์ต่างๆของ Hadoop ไว้ได้ครอบคลุม ท้ังหมดต้ังแต่ Hive, Pig, Sqoop, HBase หรือ Zookeeper รวมถึงพูดถึง การติดต้ัง Hadoop Cluster เล่มน้ีเหมาะสำาหรับ Administor ท่ีต้องการ ติดต้ังและเข้าใจ Hadoop แต่ก็มีการกล่าวถึงการโปรแกรม MapReduce อยู่หลายบทเหมือนกัน Programming Hive: หนังสือเล่มน้ีสำาหรับผู้สนใจจะใช้คำาส่ังคล้าย SQL บน Hadoop เพ่ือท่ีจะสืบค้นข้อมูล Unstructure โดยใช้โปรแกรม Hive หนังสือเหมาะกับผู้ท่ีสนใจเล่น Hive อย่างจริงจัง เพราะมีหลาย ละเอียดค่อนข้างมากต้ังแต่ Data Types การใช้ภาษา Hive QL ผมเองได้ แค่อ่านผ่านๆเพราะไม่ได้ต้องการเจาะลึกการใช้ Hive Mahout in Action: หนังสือน้ีเหมาะกับ Data Scientist ท่ีต้องการ พัฒนา Scalable Machine Learning โดยใช้ Mahout ท่ีรันอยู่บน Hadoop หนังสือเล่มน้ีจะอ่านยากมากเพราะจะเต็มไปด้วยสูตร คณิตศาสตร์ต่างๆและโปรแกรมภาษาจาวาโดยใช้ Mahout หนังสือจะ กล่าวถึงการทำา Preditive Analysis สามเร่ืองท่ี Mahout สามารถทำาได้ คือ Recommendation, Classication และ Clustering ธนชาติ นุ่มนนท์ IMC Institute ตุลาคม 2557 46 THANACHART
- 55. CHAPTER 9 Hadoop Ecosystem สำาหรับการ พัฒนา Big Data เม่ือพูดถึง Big Data นอกเหนือจากข้อมูลจะมีขนาดใหญ่ข้ึนแล้ว รูปแบบ ของข้อมูลในอนาคตส่วนใหญ่ก็จะเป็น Unstructure และข้อมูลก็จะเพ่ิมข้ึน อย่างรวดเร็ว ตามท่ีเรานิยามคุณลักษณะของ Big Data ด้วย 3V: Volume, Variety และ Velocity ดังน้ันเคร่ืองมือในการท่ีจะทำา Big Data ก็จะต้อง เปล่ียนไปจากท่ีเราเคยใช้ RDBMS ท่ีเป็น SQL คนก็เร่ิมต้องหาเคร่ืองมือ อ่ืนๆท่ีจะจัดการกับข้อมูลจำานวนมากได้อย่าง NewSQL เช่น MySQL Cluster, Amazon RDS หรือ Azure SQL หรือเคร่ืองมือท่ีเป็น NoSQL อย่าง MongoDB หรือ Cassandra และเคร่ืองมืออย่าง Hadoop ท่ีใช้ สำาหรับจัดการ Unstructure Data ท่ีเป็น PetaByte Hadoop เป็นหน่ึงในเคร่ืองมือ Big Data ท่ีได้รับความสนใจอย่างกว้าง เพราะสามารถท่ีจะจัดการข้อมูล Unstructure ขนาดใหญ่ได้ เช่นข้อมูลท่ี เป็น Text File, XML หรือ JSON ผมเองเจอไฟล์ท่ีเป็น Web Crawl อยู่ ในรูปแบบของไฟล์ Web ARChive (WARC) ซ่ึงเป็น Text ขนาดใหญ่ขนาด หลายร้อย TeraByte ซ่ึงแน่นอนการจัดการข้อมูลแบบน้ีต้องหาเคร่ืองมือท่ี เหมาะสม และ Hadoop ก็คือเคร่ืองมือท่ีผมเลือกใช้ Hadoop Project Hadoop เป็น Open source Project ของ Apache สำาหรับการเก็บ และบริหารข้อมูลขนาดใหญ่ Hadoop เขียนด้วยโปรแกรมภาษาจาวา มี ความสามารถในการทำา Fault Tourarent เพราะจะเก็บข้อมูลซ้ำากันใน
- 56. หลายๆท่ี และเป็นระบบท่ีเป็น Horizontal Scale ท่ีรันบนเคร่ือง commodity server จำานวนมาก Hadoop Project เร่ิมต้นโดย Doug Cutting และ Mike Cafarella ท่ีเป็นทีมงานของบริษัท Yahoo ซ่ึงต่อมาก็มี บริษัทอ่ืนๆนำาไปใช้กันอย่างมากท้ัง eBay, Facebook และ Amazon รวม ถึงมีบริษัทหลายๆรายท่ีนำามา Hadoop มาทำา Commercial Distribution อาทิเช่น Cloudera, MapR, IBM Infoshphere BigInsight, Hortonwork หรือ Amazon Elastic Map Reduce รูปท่ี 1: Hadoop Environment [Source: Hadoop in Practice; Alex Holmes] Hadoop เวอร์ช่ันแรกจะมีองค์ประกอบหลักสองส่วนคือ • HDFS (Hadoop Distribution File System) ท่ีทำาหน้าท่ีเป็นส่วนเก็บ ข้อมูลซ่ึงจะเก็บข้อมูลขนาดใหญ่ท่ีจะแบ่งเป็นไฟล์ย่อยขนาดใหญ่เก็บลง ใน Data Node จำานวนมาก โดยจะมี Master Node ท่ีทำาหน้าท่ีระบุ ตำาแหน่งของข้อมูลท่ีเก็บใน Data node • Map/Reduce จะเป็นส่วนประมวลผลข้อมูล ท่ีนักพัฒนาสามารถเขียน โปรแกรมโดยใช้ภาษาจาวามาวิเคราะห์ข้อมูลในรูปแบบของฟังก์ชันการ Map และ Reduce ได้ โดยระบบก็จะกระจาย Task ไปรันแบบ Parallel บนเคร่ืองหลายๆเคร่ือง 48 THANACHART
- 57. ข้อมูลท่ีเก็บอยู่ใน HDFS จะไม่ใช่รูปแบบ Table อย่างท่ีเก็บในฐานข้อมูล RDBMS จะเหมาะกับการเก็บข้อมูลขนาดใหญ่มากท่ีไม่ต้องมีการ เปล่ียนแปลง และไม่สามารถอ่านหรือเขียนข้อมูลแบบ Random Access ได้ ส่วนการประมวลผลแบบ Map/Reduce ก็ไม่ใช่ realtime Online แบบ SQL ของ RDBMS แต่จะเป็นแบบ Batch O^lne ใช้เวลาพอสมควรข้ึนอยู่ กับขนาดข้อมูล สถาปัตยกรรมฮาร์ดแวร์ของระบบ Hadoop จะประกอบด้วยเคร่ือง Server จำานวนมาก โดยจะมีเคร่ืองหน่ึงทำาหน้าท่ีเป็น Master และจะมี เคร่ืองลูกอีกจำานวนมากทำาหน้าท่ีเป็น Slave โดยปกติ Hadoop จะกำาหนด ให้ข้อมูลท่ีเก็บในเคร่ือง Slave มีการเก็บข้อมูลซ้ำากันสามแห่ง ดังน้ันเคร่ือง Slave ควรจะมีอย่างน้อยสามเคร่ือง ส่วนเคร่ือง Master ก็จะทำาหน้าท่ีหลัก ในการระบุตำาแหน่งของข้อมูลและ Task ท่ีกระจายในการประมวลผลของ Map/Reduce ดังน้ันเคร่ือง Master จึงมีความสำาคัญอย่างมาก และต้อง มีเคร่ือง Secondary Master ในการท่ีจะสำารองไว้ในกรณีเคร่ือง Master ตายไป ดังน้ันระบบ Hadoop โดยท่ัวไปจะเร่ิมต้นท่ีเคร่ือง Server 5 เคร่ือง สำาหรับ Master หน่ึงเคร่ือง, Secondary Master หน่ึงเคร่ือง และ Slave สามเคร่ือง โดยหากต้องการเก็บข้อมูลมากข้ึนหรือต้องการประมวลผล ข้อมูลให้เร็วข้ึนก็ต้องเพ่ิมจำานวนเคร่ือง Slave ให้มากข้ึน ท้ังน้ีขนาดของ ข้อมูลท่ีเก็บได้ก็จะข้ึนอยู่กับขนาดความจุข้อมูลของเคร่ือง Slave รวมกัน หารด้วยจำานวนข้อมูลท่ีต้องการเก็บซ้ำา (default คือ 3) ซ่ึงการเก็บข้อมูล จำานวนเป็น Petabyte ได้ก็ต้องมีเคร่ืองเป็นจำานวนมากกว่าร้อยเคร่ือง โดย ปัจจุบัน Yahoo เป็น site ท่ีมี Hadoop Cluster ใหญ่ท่ีสุด โดยมีเคร่ือง จำานวนถึง 40,000 เคร่ือง HADOOP ECOSYSTEM สำาหรับการพัฒนา BIG DATA 49
- 58. รูปท่ี 2: Hadoop Architecture [Source: Hadoop in Practice; Alex Holmes] Hadoop Ecosystem ระบบ Hadoop เองจะมีองค์ประกอบหลักอยู่แค่สองส่วนคือ HDFS และ Map/Reduce ซ่ึงค่อนข้างจะไม่สะดวกกับผู้ใช้งานท่ีมีความต้องการอ่ืนๆ เช่น การประมวลผลโดยใช้ภาษา SQL การเขียนหรืออ่านข้อมูลแบบ Random access หรือการถ่ายโอนข้อมูลจากท่ีอ่ืนๆ จึงมีการพัฒนาโปร เจ็คอ่ืนๆท่ีมาทำางานร่วมกับ Hadoop เพ่ือให้ได้ประสิทธิภาพดีย่ิงข้ึน ดัง แสดงตัวอย่างในรูปท่ี 3 ซ่ึงมีเคร่ืองมือท่ีสำาคัญดังน้ี 50 THANACHART
- 59. รูปท่ี 3: Hadoop Ecosystem [Source: Big Data Analytics with Hadoop: Phillippe Julio] • Hive เป็นเคร่ืองมือสำาหรับผู้ต้องการสืบค้น (Query) ข้อมูลท่ีเก็บใน HDFS ด้วยภาษาลักษณะ SQL แทนท่ีจะต้องมาเขียนโปรแกรม Map/ Reduce โดย Hive จะทำาหน้าท่ีในการแปล SQL like ให้มาเป็น Map/ Reduce แล้วก็ทำาการรันแบบ Batch • Pig เป็นเคร่ืองมือคล้ายๆกับ Hive ท่ีช่วยให้ประมวลผลข้อมูลโดยไม่ ต้องเขียนโปรแกรม Map/Reduce ซ่ึง Pig จะใช้โปรแกรมภาษา script ง่ายๆท่ีเรียกว่า Pig Latin แทน โดย Pigเหมาะกับการทำา ETL สำาหรับ การแปลงข้อมูลในรูปแบบต่างๆเช่น JSON • Sqoop เป็นเคร่ืองมือในการถ่ายโอนข้อมูลระหว่างฐานข้อมูลท่ีอยู่ รูปแบบ Table บน RDBMS อย่าง SQL server, Oracle หรือ MySQL กับข้อมูลบน HDFS ของ Hadoop • Flume เป็นเคร่ืองมือในการดึงข้อมูลจากระบบอ่ืนๆแบบ Realtime เข้า สู่ HDFS เช่นการดึง Log จาก Web Server การดึงข้อมูลเหล่าน้ีจะต้อง มีการติดต้ัง Agent ท่ีเคร่ือง Server HADOOP ECOSYSTEM สำาหรับการพัฒนา BIG DATA 51
- 60. • HBase เป็นเคร่ืองมือท่ีจะทำาให้ Hadoop สามารถอ่านและเขียนข้อมูล แบบ Realtime Random Access ได้โดยจะทำาให้เป็น BigTable ท่ีเก็บ ข้อมูลได้ไม่จำากัด row หรือ column ซ่ึง HBase ก็จะเป็นเสมือนการ ทำาให้ Hadoop เป็น NoSQL Database • Oozie เป็นเคร่ืองมือในการทำา Work]ow จะช่วยให้เราเอาคำาส่ัง ประมวลผลต่างๆของระบบ Hadoop เช่น Map/Reduce, Hive หรือ Pig มาเช่ือมต่อกันในรูปของ Work]ow ได้ • Hue ย่อมาจากคำาว่า Hadoop User Experience เป็นเคร่ืองมือช่วย ทำา User interface ของ Hadoop ให้ใช้งานได้ง่ายข้ึนกว่าการต้องใช้ command line • Mahout เป็นเคร่ืองมือของ Data Scientist ท่ีต้องการทำาPredictive Analytics ข้อมูลบน Hadoop โดยใช้ภาษาจาวา ท้ังน้ี Mahout สามารถใช้ Algorithm ท่ีเป็น Recommender, Classication และ Clustering ได้ Hadoop 2.0 Hadoop เวอร์ช่ันแรกมีข้อจำากัดหลายประการอาทิเช่น ระบบการสำารอง ของ Secondary Master เป็นแบบ Passive และไม่สามารถทำา Multiple Master ได้จึงจำากัดเคร่ือง Slave ไว้ไม่เกิน 4,000 เคร่ือง และขัอสำาคัญการ ประมวลผลต้องใช้ Map/Reduce ท่ีเป็นแบบ Batch ดังน้ันจึงมีการพัฒนา Hadoop 2.0 ท่ีจะลดข้อจำากัดต่างๆ Hadoop เวอร์ช่ันน้ีจะมี สถาปัตยกรรมดังรูปท่ี 4 โดยมีการนำา Data Opeating System ท่ีเรียกว่า YARN (Yet Another Resource Negotiator) เข้ามา 52 THANACHART
- 61. รูปท่ี 4 : Hadoop 2.0 เราจะเห็นได้ว่าการมี YARN ทำาให้เรามีวิธีการประมวลผลท่ีหลากหลาย ข้ึน ท้ังแบบ Batch อย่างเดิมท่ีใช้ Map/Reduce หรือผ่าน Hive และก็เป็น Realtime ท่ีใช้ Streaming หรือ MPI รวมถึงสามารถขยายจำานวนเคร่ือง Slave ได้จำานวนมาก ในปัจจุบันม่ี Hadoop Distribution หลายตัวรวม ท้ังท่ีเป็นผู้ให้บริการบน Cloud แบบ Hadoop as a Service ท่ีใช้ Hadoop 2.0 จึงทำาให้โอกาสการใช้งานของ Hadoop ในอนาคตจะขยายตัวมากข้ึน เร่ือยๆ ธนชาติ นุ่มนนท์ IMC Institute ตุลาคม 2557 HADOOP ECOSYSTEM สำาหรับการพัฒนา BIG DATA 53
- 63. CHAPTER 10 Data Scientist กับเทคโนโลยี Big Data: Hadoop, MapReduce, R และ Mahout ได้เขียนเร่ือง Data Scientist ไปหลายคร้ัง (เช่น Big Data Analytics กับ ความต้องการ Data Scientist ตำาแหน่งงานท่ีน่าสนใจในปัจจุบัน) และก็ได้ หยิบยกบทความของ ดร.อธิป อัศวานันท์ เร่ือง “ความเข้าใจท่ีผิดๆ เก่ียวกับ Big Data และ Analytics ท้ังตอนท่ี 1 และ ตอนท่ี 2” มาให้อ่านกัน ก็หวัง ว่าเราคงเร่ิมมีความเข้าใจมากข้ึนระหว่าง Programmer, BI Analyst และ Data Scientist ท่ีผมพยายามบอกว่า Data Scentist ต้องมีความรู้ทาง ด้านคณิตศาสตร์และ Predictive Algorithm คนท่ีจะเป็น Data Scientist จะต้องมีความสามารถอยู่ในสามด้านก็คือ 1) Programming กล่าวคือจะต้องมีทักษะการโปรแกรมท่ีดีเช่นสามารถ เขียนโปรแกรมอย่าง Map/Reduce, R หรือ Hive ได้ 2) มีความรู้ด้าน Math และ Statistics คือจะต้องเข้าใจการรวบรวมและวิเคราะห์ข้อมูล มี ความเข้าใจเร่ือง Algorithm โดยเฉพาะด้าน Predictive Analytics สำาหรับทำา Machine Learning ได้ และ 3) ต้องมีความเข้าใจเร่ืองธุรกิจท่ี จะมาวิเคราะห์ข้อมูล เพ่ือจะได้ทราบว่ารูปแบบของข้อมูลเป็นอย่างไร หรือ จะต้องการข้อมูลใดสำาหรับการวิเคราะห์และการคาดการณ์ ซ่ึงทักษะเหล่าน้ี ได้สรุปรวมไว้ในรูปท่ี 1
- 64. รูปท่ี 1 ทักษะของ Data Scientist [source 1=”<a” href=”http://www.edureka.co/data-science” 2=”2=”target=”_blank”>www.edureka.in/data-science</a>”” language=”:”][/source] จริงๆแล้วการทำา Predictive Analytics ไม่ใช่เร่ืองใหม่ แต่การคาด การณ์ต่างๆจะมีความแม่นยำาและใก้ลเคียงกับความจริงมากข้ึนถ้ามีข้อมูล จำานวนมากข้ึน ดังน้ันเทคโนโลยี Big Data จึงทำาให้การคาดการณ์ต่างๆ แม่นยำาข้ึน และการมีข้อมูลขนาดใหญ่จะมีประโยชน์มากย่ิงข้ึนถ้าเรา สามารถทำา Predictive Analytics ซ่ึงเราจะเห็นได้ว่ากรณีน้ีมีความแตก ต่างกันกับ Business Intelligence (BI) • BI คือการดู Business Insight เพ่ือให้ทราบว่าข้อมูลท่ีผ่านมาเป็น อย่างไร โดยนำาเสนอในมุมมองต่างๆ ท้ังในรูปแบบของรายงาน กราฟ หรือ Dashboard • Predictive Analytics คือการคาดการณ์อนาคตโดยใช้โมเดล คณิตศาสตร์ท่ีต้องใช้ข้อมูลจำานวนมากและอาจจะมาจากหลายแหล่ง 56 THANACHART
- 65. รูปท่ี 2 เคร่ืองมือและเทคโนโลยีของ Data Science [source 1=”<a” href=”http://www.edureka.co/data-science” 2=”2=”target=”_blank”>www.edureka.in/data-science</a>”” language=”:”][/source] เทคโนโลยี Big Data ทำาให้ Data Scentist มีเคร่ืองมือท่ีหลากหลาย ข้ึน ท้ังในการเก็บข้อมูลเช่น RDBMS ในรูปแบบเดิม หรือ NoSQL อย่าง MongoDB หรือ unstructure storage อย่าง Hadoop HDFS ท้ัง เคร่ืองมือในการถ่ายโอนข้อมูลอย่าง Sqoop หรือ Flume และเคร่ืองมือ หรือภาษาในการวิเคราะห์ข้อมูลอย่าง Java, R, Mahout และเน่ืองจาก ข้อมูลในปัจจุบันส่วนใหญ่เป็น unstructure data ก็เลยทำาให้ Hadoop กลายเป็นเคร่ืองมือท่ีน่าสนใจท่ีสุดของ Big Data เพราะนอกจากสามารถท่ี จะเก็บข้อมูลขนาดใหญ่ได้แล้ว ยังมีเคร่ืองมือท่ีช่วยในการวิเคราะห์ข้อมูลท่ี หลากหลาย DATA SCIENTIST กับเทคโนโลยี BIG DATA: HADOOP, MAPREDUCE, R และ MAHOUT 57
- 66. รูปท่ี 3 หน้าท่ีของ Data Science [source 1=”<a” href=”http://www.edureka.co/data-science” 2=”2=”target=”_blank”>www.edureka.in/data-science</a>”” language=”:”][/source] สุดท้ายเพ่ือให้เข้าใจว่า Data Scientist ทำาอะไรจากเทคโนโลยีต่างๆท่ีมี อยู่ ลองพิจารณาดูรูปท่ี 3 จะเห็นว่าจะมีการกล่าวถึงเทคโนโลยีต่างๆ เช่น เคร่ืองมือในการรวบรวมข้อมูลท่ีทำา ETL เคร่ืองมือในการเก็บข้อมูลอย่าง Hadoop เคร่ืองมือในการวิเคราะห์ข้อมูลอย่าง R, Hive, Pig, Java, Mahout เคร่ืองมือในการแสดงผลอย่าง Dashboard, Web App และ เคร่ืองมือในการพยากรณ์ข้อมูลท่ีทำา Machine Learning จากรูปจะเห็น ได้ว่าบทบาทของ Data Scientist จะคาบเก่ียวกับบทบาทของ Data Architecture/Management และ Analytics โดย Data Sceintist จะ ต้องใช้เคร่ืองมือต่างๆท้ัง Hadoop, R, MapReduce หรือ Mahout ใน การวืเคราะห์ข้อมูล รวมถึงมีการใช้ Algorithm สำาหรับ Machine Learning • R เป๋็นภาษาท่ีสามารถใช้ในการวิเคราะห์ข้อมูลได้ • Mahout เป็นเคร่ืองมือท่ีใช้ในการวิเคราะห์ Large Scale Data บน Hadoop โดย Mahout จะมี Library สำาหรับ Predictive Analytics สามด้านคือ Recommender, Clustering และ Classication การพัฒนาหรือหา Data Scientist คงไม่ใช่ง่าย และไม่สามารถทำาได้โดย ระยะเวลาอันส้ัน จากข้อมูลการสำารวจส่วนใหญ่ก็จะต้องเป็นท่ีมีพ้ืนฐานทาง 58 THANACHART
- 67. คณิตศาสตร์อย่างดี โลกของ Big Data กำาลังมา ตรงน้ีน่าจะเป็นโอกาสอัน ดีของนักคณิตศาสตร์ และจำาเป็นอย่างย่ิงท่ีบ้านเราจะต้องเร่งพัฒนาคนทาง ด้านน้ี แต่อย่ามองว่าเป็นเร่ืองง่าย เพราะการเรียนคณิตศาสตร์ไม่ได้ทำากัน ได้เพียงสัปดาห์เดียว การจะเรียนปริญญาเอกก็ต้องใช้เวลาเป็นปีๆ ดังน้ัน การท่ีจะสร้าง Data Scentist ทีดีก็ต้องบ่มเพราะเป็นปีๆเช่นกัน ธนชาติ นุ่มนนท์ IMC Institute ตุลาคม 2557 DATA SCIENTIST กับเทคโนโลยี BIG DATA: HADOOP, MAPREDUCE, R และ MAHOUT 59
- 69. CHAPTER 11 ความพร้อมด้าน Big Data ของบ้าน เรา คงต้องให้ระยะเวลาอีกพักหน่ึง Big Data เป็นเทคโนโลยีท่ีถูกกล่าวขานกันมากท่ีสุดในช่วง 1-2 ปีน้ี Big Data ไม่ใช่เร่ืองท่ีพูดกันเฉพาะวงการไอทีแต่มีการพูดถึงกันมากในทุกภาค ส่วนอุตสาหกรรมท้ังด้านการตลาด ภาคการค้าขาย ภาคสาธารณสุข วงการวิทยาศาสตร์ ภาครัฐบาล หรือแม้แต่ภาคการเงินการธนาคาร หลายๆคนกล่าวกันการเข้ามาของ Big Data จะทำาให้เรามีข้อมูลท่ีดีข้ึน สามารถคาดการณ์ข้อมูลแม่นยำาย่ิงข้ึน และเม่ือเห็นโลกของ Social Network ท่ีโตข้ึนอย่างรวดเร็ว หลายคนก็คิดว่าน่าจะเป็นโอกาสท่ีดีของ Big Data บางคนพยายามจะบอกว่า Big Data ของประเทศไทยกำาลังจะ โตข้ึนมากจะมีการใช้กันมากมายเพราะเรามีการใช้อินเตอร์เน็ตแบะ Social Media มากข้ึน และบ้างก็เข้าใจว่าบ้านเราพร้อมและอยู่แนวหน้าทางด้าน Big Data ในฐานะท่ีผมอยู่ในภาคอุตสาหกรรมและเก่ียวข้องการภาคการ ศึกษาโดยตรงในการพัฒนาบุคลากร และได้เร่ิมสนใจเร่ือง Big Data อย่าง จริงจังในช่วงสองปีท่ีผ่านมา อาจเห็นแย้งในเร่ืองน้ี จึงขอให้เหตุผลประกอบ ว่าทำาไมบ้านเรายังต้องพัฒนาเร่ือง Big Data อีกมากก่อนจะพร้อมท่ีแข่งขัน กับท่ีอ่ืนๆได้ดังน้ี กำรขำดควำมเข้ำใจเร่ือง Big Data คนจำานวนมากยังไม่เข้าใจว่า Big Data คืออะไร หลายๆคนก็ไปแปล ตรงๆว่าคือข้อมูลใหญ่ซ่ึงส่วนหน่ึงก็ไม่ผิดอะไร ผมเคยเขียนบทความ หลายๆคร้ังแล้วเร่ืองความหมายของ Big Data จึงไม่อยากกล่าวซ้ำาอีก แต่
- 70. ส่ิงสำาคัญคือ Big Data คือการมองอนาคตท่ีจะเปล่ียนแปลงรูปแบบของ การจัดการข้อมูล แผนกไอทีจะต้องพร้อมท่ีจะบริหารจัดการกับข้อมูลแบบ ผสม (Hybrid Data) ท่ีจะมีท้ัง structure data และ unstructure data รวมถึงความสามารถในการท่ีนำา Dark Data ซ่ึงเป็นข้อมูลท่ีเราเก็บไว้แต่ ไม่เคยนำามาใช้ประโยชน์ มาสร้างประโยชน์ให้กับหน่วยงาน นอกจากน้ีบาง คร้ังเรายังไม่เข้าใจถึงประโยชน์ของ Big Data ท่ีได้จากการทำา Predictive Analytics ซ่ึงมันแตกต่างกับการทำา Business Intelligence ท่ีเราเคยทำา กัน และการทำา Big Data Analytics ต้องการบุคลากรท่ีเป็น Data Scientist ไม่ใช่เฉพาะ Programmer หรือ Business Analytist ความ เข้าใจคาดเคล่ือนเก่ียวกับ Big Data ทำาให้องค์กรขาดการเตรียมพร้อม เก่ียวกับเร่ืองน้ี และเข้าใจผิดคิดว่าโครงสร้างข้อมูลในปัจจุบันรองรับแล้ว ขาดการเตรียมพร้อมด้านบุคลากรท้ังทางด้านไอทีและนักวิเคราะห์ข้อมูล ขำดข้อมูลขนำดใหญ่ ข้อมูลส่วนใหญ่ในบ้านเรายังเป็นข้อมูลแบบปิดยังไม่มีการทำา Open Data กันมากเท่าไร และข้อมูลท่ีมีอยู่ส่วนมากก็เป็นเพียง structure data ขนาดท่ีแนวโน้มของ Big Data ระบุว่าข้อมูลเกือบ 80% จะเป็น unstructure data ขณะท่ีข้อมูลท่ีเก็บอยู่ในบ้านเราจะมีเพียงเล็กน้อย หน่วยงานท่ีจะมีข้อมูลมากกว่า 10 TB ก็หาค่อนข้างยาก หน่วยงานท่ีมี ข้อมูลมากๆก็จะเป็นข้อมูล Transaction ของลูกค้าเช่น CDR ของบริษัท ด้าน Telecom เรายังไม่มีผู้ให้บริการท่ีให้ข้อมูล unstructure เช่น Web Crawler, Social Network ท่ีให้เราดึงข้อมูลขนาดใหญ่มาวิเคราะห์ได้ แต่ การจะใช้ประโยชน์จาก Big Data ได้อย่างเต็มท่ีส่วนหน่ึงก็คือการต้องนำา ข้อมูลภายนอกองค์กร (External Data) เหล่าน้ีมาช่วยในการวิเคราะห์ คาดการณ์ต่างๆ เราจะเห็นได้ว่าเราสามารถไปดึงข้อมูลจากต่างประเทศท่ี เป็น unstructure หรือ semi-structure ขนาดใหญ่เช่น ข้อมูล Twitter หรือข้อมูลจากYelp มาได้ หรือแม้แต่ข้อมูลจาก Web Crawler ท่ีมีขนาด มากกว่า 500 TB ก็ยังมีให้บริการ ขณะท่ีบ้านเราไม่มีบริการข้อมูลเหล่าน้ี การทำา Big Data ให้ได้ประโยชน์อย่างเต็มท่ี ต้องมีข้อมูลขนาดใหญ่ๆท่ีว่า แต่บ้านเรายังขาดอยู่ คงต้องใช้เวลาอีกหลายปีจึงจะได้ข้อมูลท่ีดีข้ึน ขำดบุคลำกรด้ำน Big Data ปัญหาน้ีถ้าพูดไปเป็นเป็นคลาสสิคในวงการไอที ไม่ว่าเทคโนโลยีใหม่ อะไรเข้ามาบ้านเรามักจะขาดคนไม่ว่าจะเป็นด้าน Mobile Developer, Cloud Computing Expert หรือ Enterprise Architect แต่ปัญหาการ 62 THANACHART
- 71. ขาดบุคลากรด้าน Big Data เป็นปัญหาท่ัวโลก เพราะสำานักวิจัย Gartner คาดการณ์ว่าจะมีความต้องการบุคลากรด้านน้ีท่ัวโลกถึง 4.4 ล้านตำาแหน่ง ในปี 2015 และเป็นตำาแหน่งงานท่ึสหรัฐอเมริกาถึง 1.9 ล้านตำาแหน่ง แต่ ปรากฎว่าจะมีเพียง 1/3 เท่าน้ันท่ีหาบุคลากีท่ีมีทักษะตรงกับท่ีต้องการได้ งานทางด้าน Big Data หน่ึงตำาแหน่งจะสร้างงานตำาแหน่งอ่ืนๆนอกกลุ่มไอ ทีได้ถึงสามตำาแหน่ง การขาดแคลนบุคลากรทางด้านน้ีทำาให้หน่วยงานต้อง เร่งพัฒนาบุคลากรและหาวิธีการดึงดูดบุคลากรเข้ามาในหน่วยงาน เทคโนโลยี Big Data ต้องการบุคลากรท่ีมีทักษะใหม่ๆในการบริหารจัดการ ข้อมูลท่ีกำาลังเปล่ียนแปลง ต้องรู้ถึงการใช้เทคโนโลยีใหม่ๆ และต้องการ บุคลากรท่ีมีความสามารถในการวิเคราะห์ข้อมูลและคาดการณ์เร่ืองต่างๆ ได้ ซ่ึงบ้านเรายังขาดบุคลากรเหล่าน้ีอีกมาก ขำดเทคโนโลยีสำำหรับโครงสร้ำงข้อมูลแบบใหม่ การเข้ามาของ Big Data ทำาให้หน่วยงานจะต้องลงทุนโครงสร้างพ้ืนฐาน ด้านข้อมูลเพ่ิมเติม ฐานข้อมูลแบบ RDBMS เดิมไม่สามารถจะรองรับ unstructure data ได้ ทาง Gartner เองก็ระบุว่า 75% ของ Data Warehouse ในปัจจุบันจะไม่สามารถรองรับข้อมูลในเร่ืองของ Velocity และ Variety ได้ การเข้ามาของ unstructure data ขนาดใหญ่ทำาให้หน่วย งานต้องนำาเทคโนโลยีใหม่อย่าง Hadoop หรือ No SQL เข้ามาใช้ โดย Hadoop ก็เป็นหน่ึงในเทคโนโลยีท่ีน่าสนใจท่ีสุดสำาหรับเก็บข้อมูลหลาย ร้อย TB ซ่ึงจากการสำารวจองค์กร 86% ท่ัวโลกก็ยังไม่สามารถบริหาร จัดการข้อมูลได้อย่างเหมาะสม นอกจากน้ีองค์กรก็อาจต้องลงทุนทางด้าน BI & Analytics Tool เพ่ือจะได้ประโยชน์จากการใช้ข้อมูลต่างๆท้ังแบบ Structure และ unstructure ท่ีอยู่ภายในและภายนอกองค์กร ซ่ึงใน ปัจจุบันมีหน่วยงานเพียง 13% ท่ีมีเคร่ืองมือแบะสามารถทำา Predictive Analytics ได้ จากท่ีกล่าวมาท้ังหมดน้ี จะเห็นว่าการประยุกต์ใช้ Big Data เป็นเร่ืองท่ี ยากและซับซ้อนกว่าท่ีเราคิด และเป็นเร่ืองท่ีท้าทายสำาหรับองค์กรต่างๆท่ัว โลก แม้จะบอกว่าบ้านเรายังไม่พร้อม แต่เช่ือว่าถ้าเราต้ังใจทำากันจริงๆ ปรับ ความเข้าใจ สร้างข้อมูลให้มากข้ึน พัฒนาบุคลากร และพัฒนาโครงสร้าง พ้ืนฐานด้านข้อมูล บ้านเราแข่งกับเขาได้แน่ ธนชาติ นุ่มนนท์ IMC institute ตุลาคม 2557 ความพร้อมด้าน BIG DATA ของบ้านเรา คงต้องให้ระยะเวลาอีกพักหน่ึง 63
- 73. CHAPTER 12 ความเข้าใจผิดบางประการเก่ียวกับ Big Data ผมเคยเขียนบทความเร่ือง ความเข้าใจผิดบางประการเก่ียวกับ Coud Computing มาระยะหลังผมได้ศึกษาเร่ือง Big Data มากข้ึน มีโอกาสได้ไป บรรยายและให้คำาปรึกษาเก่ียวกับเร่ืองน้ีในหลายๆท่ี ก็เลยพบว่าหลายๆคน มีความเข้าใจคาดเคล่ือนเก่ียวกับ Big Data เช่นเดียวกัน วันน้ีจึงขอ รวบรวมมาสรุปความเข้าใจผิดบางประการเก่ียวกับ Big Data ดังน้ี • Big Data คือข้อมูลขนำดใหญ่ หลายๆคนแปลคำาว่า Big Data แบบ ตรงตัวแล้วสรุปเอาตรงเลยว่า Big Data ก็คือข้อมูลท่ีมีขนาดใหญ่ ซ่ึง จริงๆแล้วก็มีส่วนถูกอยู่บ้าง แต่ความหมายของ Big Data ประกอบด้วย 3 องค์ประกอบคือ Volume ข้อมูลมีขนาดใหญ่ Velocity ข้อมูล เปล่ียนแปลงไปอย่างรวดเร็ว และ Variety ข้อมูลมีหลากหลายรูปแบบ ท้ัง structure และ unstructure จากองค์ประกอบท้ังสามน้ีทำาให้เราไม่ สามารถท่ีจะใช้วิธีการจัดการข้อมูลในปัจจุบันมาใช้ได้ หากต้องการได้ ประโยชน์จาก Big Data อย่างแท้จริง • Big Data สำมำรถบริหำรจัดกำรได้โดยใช้ฐำนข้อมูล RDBMS แบบ เดิม จริงๆแล้วเวลาเราพูดถึง Big Data ข้อมูลจะมีขนาดใหญ่มากหลาย ร้อย TeraByte หรืออาจเป็น PetaByte และก็มีท้ังแบบ Structure หรือ unstructure ทำาให้เราจำาเป็นต้องปรับปรุงโครงสร้างเทคโนโลยี ด้านข้อมูล (Information Infrastructure) โดยนำาเทคโนโลยีใหม่เช่น
- 74. NoSQL, NewSQL หรือ Hadoop เข้ามาใช้ ตัวอย่างเช่นทุกวันน้ีบริษัท ผู้ให้บริการมือถือท่ีต้องเก็บ CDR (Call Detail Record) ท่ีมีข้อมูลหลาย TB ต่อวันทำาให้ไม่สามารถเก็บไว้ใน RDBMS ได้ในระยะเวลานานได้ จึง ต้องมีการนำาเทคโนโลยีอย่าง Hadoop มาเพ่ือให้สามารถเก็บข้อมูลได้ นานข้ึน และนำาข้อมูลระยะยาวมาวิเคราะห์ได้ • Hadoop คือเคร่ืองมือในกำรทำำ Big Data ข้อเท็จจริงคือว่า Big Data จะต้องมีการบริหารข้อมูลขนาดใหญ่ในหลายรูปแบบ Hadoop ก็เป็น เพียงเคร่ืองมือหน่ึงท่ีน่าสนใจถ้าต้องการเก็บ unstructure data ขนาด ใหญ่ท่ีเก็บข้อมูลได้เป็น PetaByte และสามารถท่ีจะใช้ร่วมกับ RDBMS และ EDW (Enterprise Data Warehouse) นอกจากต้นทุนในการเก็บ ข้อมูลจะต่ำากว่ามากดังแสดงในรูปท่ี 1 ทำาให้ Hadoop เป็นเทคโนโลยืีท่ี น่าสนใจมากถ้าเราต้องการทำา Big Data แต่ Hadoop ก็จะไม่ได้มาแทน ท่ีเทคโนโลยีการเก็บข้อมูลแบบเดิมเช่น RDBMS และ EDW รูปท่ี 1 ราคาเปรียบการเก็บข้อมูลต่อ TB โดยใช้เทคโนโลยีต่าง [Source: Monetizing Big Data at Telecom Service Providers] • Strucure Data ในองค์กรเพียงพอต่อกำรทำำ Big Data ข้อมูลในปัจจ บันมีแนวโน้มท่ีจะเป็น unstructure data มากกว่า structure data 66 THANACHART
- 75. โดยมีการประมาณการว่า 85% ของข้อมูลท้ังหมดคือ unstructure data ท่ีอาจเป็นข้อมูลท่ีเป็น text, รูปภาพ, อีเมล์, social media หรือ semistructure data อย่าง JSON และ XML ดังน้ันหากองค์กรต้องการ จะได้ประโยชน์จาก Big Data ก็ต้องมีการนำา unstructure data มาใช้ และอาจต้องให้ความสำาคัญข้อมูลภายนอกองค์กรพอๆกับข้อมูลท่ีเก็บไว้ ในองค์กร • Big Data คือกำรนำำข้อมูลมำเก็บและแสดงผลแบบ BI จริงๆแล้ว คุณค่าของการทำา Big Data คือการนำาข้อมูลจำานวนมหาศาลมา วิเคราะห์คาดการณ์อนาคต (predictive analytics) ท่ีไม่ใช่เพียงแค่ การทำา static report ท่ีเป็นการนำาข้อมูลในอดีตมาประมวลผลและสรุป ในมิติต่างๆท่ีเราจะเน้นในการทำา Business Intelligence • Data Scientist ก็คือ Business Analyst งานสองอาชีพน้ีแตกต่าง กันมากเพราะ Data Scientist คือผู้ท่ีจะนำาข้อมูลมาทำา Predictive Analytics จึงต้องมีความรู้ด้านคณิตศาสตร์ท่ีเป็นโมเดลคณิตศาสตร์ใน การวิเคราะห์อัลกอริทึม มีความรู้ด้านการพัฒนาโปรแกรม และมีความรู้ ในธุรกิจท่ีจะวิเคราะห์ข้อมูล ขณะท่ี Business Analyst อาจเป็นนักสถิติ หรือทีมงานท่ีสามารถนำาข้อมูลในอดีตมาประมวลผลในหลายมิติ แล้ว สามารถทำาเป็นรายงาน หรือรูปภาพกราฟฟิกต่างๆได้ • Predictive Analytics ต้องทำำกับ BigData เท่ำน้ัน จริงๆแลัวการทำา Predictive Analytics สามารถจะใช้กับข้อมูลใดๆก็ได้ และเป็นการเน้น เร่ืองของ Algorithm ท่ีมาคาดการณ์ในด้านต่างๆ แต่การมีข้อมูลในการ มาวิเคราะห์ท่ีมีขนาดใหญ่ก็จะมีคาดแม่นย้ำาในการคาดการณ์ท่ีดีข้ึน เหมือนระบบ e-commerce ท่ีเม่ือมีจำานวนลูกค้ามาซ้ือสินค้ามากข้ึนก็ สามารถท่ีจะดูพฤติกรรมการซ้ือของกลุ่มคนท่ีใกล้เคียงกันได้ และ สามารถแนะนำาสินค้าท่ีน่าจtซ้ือต่อไป (Next Thing to Buy) ได้ดีย่ิงข้ึน • Hadoop เป็นเร่ืองยำกจะต้องเขียนโปรแกรมภำษำจำวำในกำรประมวล ผลและทำำงำนแบบ Batch เท่ำน้ัน เร่ืองน้ีอาจถูกต้องถ้ากล่าวถึง Hadoop 1.0 แต่ก็มีการพัฒนาภาษาคล้าย SQL อย่าง Hive QL, Impala มาทำาให้ประมวลผลได้ง่ายข้ึนโดยไม่ต้องเขียนโปรแกรม และถ้า พูดถึงเวอร์ช่ัน 2.x ในปัจจุบัน Hadoop ได้พัฒนาไปมาก ทำาให้เรา ความเข้าใจผิดบางประการเก่ียวกับ BIG DATA 67
- 76. สามารถท่ีจะประมวลผลแบบ Realtime หรือใช้โปรแกรมภาษาอย่างอ่ืน เช่น Python มาช่วยประมวลผลได้ ธนชาติ นุ่มนนท์ IMC Institute พฤศจิกายน 2557 68 THANACHART
- 77. CHAPTER 13 IMC Institute ปรับปรุงหลักสูตร ด้าน Big Data ในปีหน้า เพ่ือสร้าง คนไอที IMC Institute เปืดมาได้สองปี นอกเหนือจากงานด่้าน IT Market Research และ IT Consult งานหลักอีกด้านท่ีทางสถาบันทำาคือการจัดฝึก อบรมเพ่ือพัฒนาบุคลากรด้านไอที ท่ีพยายามสร้างความแตกต่างด้วยการ เน้นเร่ืองของ Emerging Technology ซ่ึงด้านหน่ึงท่ีเราทำาการอบรมคือ Big Data ในรอบสองปีท่ีผ่านมาเราเปิดอบรมหลักสูตรต่างๆ ต้ังแต่ Introduction to Big Data, Hadoop, Business Intelligence, Big Data Strategy ท่ีเราทำาการอบรมท้ังกลุ่มคนท่ีเป็นคนไอที คนดูแลระบบ นักพัฒนาโปรแกรม ผู้บริหารด้านไอที ร่วมถึงทำาโครงการ Train the trainers และบางคร้ังเราก็ร่วมกับพันธมิตรอย่าง Oracle หรือ Computerlogy ในการจัดฟรีสัมมนาให้ความรู้ด้าน Big Data ให้กับคน ท่ัวไป ผมพยายามทำาข้อมูลมาดูตัวเลขเฉพาะกลุ่มคนท่ีเราอบรมหลักสูตรต้ังแต่ หน่ึงวันข้ึนไปในหลักสูตรท่ีเก่ียวข้องกับ Big Data มีถึง 633 คน โดยวิชา ท่ีมีคนมาอบรมมากท่ีสุดก็คือ Big Data Using Hadoop ตามมาด้วย Business Intelligence Design and Process นอกจากน้ีเรายังมีการ อบรมอาจารย์สถาบันอุดมศึกษาต่างๆจำานวน 28 คนเพ่ือให้ทราบเร่ือง
- 78. Cloud Computing และ Big Data รวมท้ังมีการทำา in-House ในหน่วย งานต่างๆท้ังท่ีเป็นสถาบันการเงิน และผู้ให้บริการโทรศัพท์เคล่ือนท่ี รูปท่ี 1 จำานวนผู้อบรมหลักสูตรด้าน Big Data กับ IMC Institute Big Data เป็นเทคโนโลยีท่ีทุกหน่วยงานจะมองข้ามไปไม่ได้ และธุรกิจ จะต้องให้ความสำาคัญกับเร่ืองน้ี หน่วยงานท่ีสามารถเอาข้อมูลมาวิเคราะห์ และใช้ Big Data ในการทำา Predictive Analytics จะได้เปรียบเหนือคู่แข่ง แต่อย่างไรก็ตามบ้านเรายังขาดคนทางด้านน้ีอีกมาก ในปีหน้าทาง IMC Institute ก็จะให้ความสำาคัญกับการอบรมทางด้านน้ีโดยจะเน้นการ ปรับปรุงหลักสูตรให้มีคุณภาพให้ดีย่ิงข้ึนดังน้ี • เชิญวิทยากรท่ีเช่ียวชาญทางด้าน Big Data มาร่วมกับทางสถาบันมาก ข้ึน • ใช้ระบบ Virtual Server บน Public Cloud อย่าง Amazon Web Services ในการอบรม เพ่ือให้ผู้อบรมสามารถฝึกการสร้าง Big Data Cluster ได้จริง • เปิดการอบรมด้าน Data Scientist เพ่ือให้คนไอทีเข้าใจการทำา Predictive Analytics • เปิดการอบรมสำาหรับผู้บริหารเพ่ือให้เข้าใจการวางแผนกลยุทธ์ด้าน Big Data • สนับสนุนการอบรมบุคลากรในสถาบันอุดมศึกษา เพ่ือจะได้ช่วยกันสร้าง บุคลากรด้านน้ี ซ่ึงในปีหน้าทาง IMC Institute จะเปืดหลักสูตรต่างๆทางด้าน Big Data ดังน้ี 70 THANACHART
- 79. • Train the Trainers: Cloud Computing & Big Data Workshop: หลักสูตร 5 วันน้ีทาง IMC Institute เน้นจัดอบรมให้กับอาจารย์ใน สถาบันอุดมศึกษา เพ่ือจะเตรียมหลักสูตรให้สอดคล้องกับ Emerging Technology ทางด้าน Cloud และ Big Data โดยเก็บค่าอบรม 5,500 บาท • Big Data Certication Course: หลักสูตร 120 ช่ัวโมง เรีิยนทุกวัน พฤหัสบดีเย็นและวันเสาร์ท้ังวัน เป็นเวลา 4 เดือน เร่ิมต้ังแต่กลางเดือน มีนาคม เป็นหลักสูตรท่ีต้องการพัฒนาคนไอทีีให้เข้าใจเร่ือง Big Data การใช้เคร่ืองมือต่างๆท้ัง NoSQL, Hadoop, R, Mahout และเรียนรู้ เร่ืองของ BI กับ Data Scientist • Big Data in Actions for Senior Management: หลักสูตรสำาหรับผู้ บริหาร ท่ีต้องการเข้าใจเร่ือง Big Data การวางแผนกลยุทธ์ทางด้าน Big Data รวมถึงการเรียนรู้เทคโนโลยีต่างๆท่ีเก่ียวข้องกับ Big Data • Introduction to Data Scientist: หลักสูตรสอนหลักการของ Data Science โดยจะอบรมด้าน Machine Learning พร้อมการใช้ R และ Mahout • Business Intelligence Design and Process: หลักสูตรด้าน BI ของ สถาบันท่ีจะสอนให้รู้จักการวิเคราะห์ข้อมูล การทำา Data Mining และ การใช้ Data Warehouse • Big Data using Hadoop Workshop: หลักสูตรน้ีสอนการติดต้ัง Hadoop และแนะนำา Hadoop Eco-System โดยจะมีการติดต้ังบน Local Machine และสร้าง Hadoop Cluster จากระบบจริงบน Cloud พร้อมท้ังเรียนการใช้งาน Big Data as a Service บน Cloud • Big Data Programming using Hadoop for Developers: หลักสูตรการพัฒนาโปรแกรมสำาหรับ Big Data บน Hadoop โดยใช้ Map/Reduce, Hive, Pig และปฎิบัติจริงกับ Hadoop Cluster บน Amazon EMR ก็หวังว่าหลักสูตรต่างๆของ IMC Institute จะเป็นประโยชน์ต่อการ พัฒนาคนอุตสาหกรรมไอที เพ่ือสามารถแข่งขันในด้าน Emerging Technology ได้ ธนชาติ นุ่มนนท์ IMC INSTITUTE ปรับปรุงหลักสูตรด้าน BIG DATA ในปีหน้า เพ่ือสร้าง คนไอที 71
- 80. IMC Institute พฤศจิกายน 2557 72 THANACHART
- 81. CHAPTER 14 การวางกลยุทธ์ด้าน Big Data ของ องค์กรและ Technology ด้าน Data ต่างๆ Big Data คือแนวโน้มของเทคโนโลยีไอทีท่ีสำาคัญท่ีทุกองค์กรต้องให้ ความสำาคัญเพ่ือนำาข้อมูลมาสร้างศักยภาพในการดำาเนินธุรกิจ ปัจจัยท่ี เก่ียวข้องกับด้าน Big Data จะมีสามด้านคือ • Data Source องค์กรจะต้องคำานึงถึงข้อมูลท่ีจะมีความหลากหลายมาก ข้ึน ข้อมูลท่ีจะนำามาใช้จะมีท้ัง structure และ unstructure ซ่ึงใน อนาคตข้อมูลกว่า 85% จะเป็นแบบ unstructure นอกจากน้ีองค์กรก็ อาจจะต้องมีการนำาข้อมูลภายนอกองค์กรมาใช้เช่นข้อมูลจาก Social Networks. หรือข้อมูลจากคู่ค้า (partner) ซ่ึงทาง Gartner เองก็ช้ีให้ เห็นว่าแนวโน้มท่ีองค์กรต่างๆจะนำาข้อมูลมาใช้งานเม่ือเทียบกับข้อมูลท่ีมี อยู่ท้ังหมดมีสัดส่วนจำานวนน้อยลงเร่ือยๆดังแสดงในรูปท่ี 1
- 82. รูปท่ี 1 สัดส่วนของข้อมูลท่ีจะมีการนำามาใช้วิเคระห์เม่ือเทียบกับข้อมูล ท้ังหมด • Information Infrastructure องค์กรจำาเป็นจะต้องมีการโครงสร้าง พ้ืนฐานด้านข้อมูลเพ่ือให้รองรับข้อมูลท่ีเป็น Big Data ซ่ึงนอกจากฐาน ข้อมูลแบบเดิมท่ีเป็น SQL แล้ว อาจต้องนำาเทคโนโลยีใหม่ๆอย่าง Hadoop, NoSQL หรือ MPP เข้ามาใช้ในองค์กร ซ่ึงผมเองเคยเขียน บทความแนะนำาเทคโนฌลยีต่างๆไว้คร่าวๆในเร่ือง เทคโนโลยี Big Data: Hadoop, NoSQL, NewSQL และ MPP • Analysis องค์กรประกอบสำาคัญอีกเร่ืองคือ การนำาข้อมูลท่ีเป็น Big Data มาประมวลผลและวิเคราะห์เพ่ือเพ่ิมประสิทธิภาพในการทำางาน ซ่ึง อาจเป็นการทำา Business Intelligence หรือ Predictive Analytics ตามท่ีผมเคยเขียนในบทความเร่ือง Big Data Analytics กับความ ต้องการ Data Scientist ตำาแหน่งงานท่ีน่าสนใจในปัจจุบัน ส่ิงแรกองค์กรควรคำานึงถึงในการทำา Big Data คือมองกลยุทธ์ทางธุรกิจว่า ต้องการอะไรไม่ใช่เร่ืองของเทคโนโลยี เม่ือทราบวัตถุประสงค์ทางธุรกิจ แล้วทีมทางด้านไอทีก็คงต้องมาพิจารณาดูว่ามี Data Source อะไรท่ีต้อง ใช้ และต้องใช้เทคโนโลยีอะไรเพ่ือให้บรรลุวัตถุประสงค์ เพ่ือให้เห็นภาพของ การวางกลยุทธ์ด้าน Big Data ผมขอยกตัวอย่าง Template ท่ีผมนำามา จากหนังสือเร่ือง Big Data: Understanding How Data Powers Big Business 74 THANACHART
- 83. รูปท่ี 2 Big Data Strategy Temple [Source: Big Data: Understanding How Data Powers Big Business] จาก Template น้ีจะเห็นได้ว่า เราควรจะเร่ิมจากการกำาหนด Business Initiatives ของการจะนำาข้อมูลมาใช้ จากน้ันคงต้องพิจารณาว่าอะไรคือ ผลลัพธ์ท่ีคาดว่าจะได้และอะไรคือปัจจัยสู่ความสำาเร็จ จากน้ันถึงจะกำาหนด งาน (Task) ท่ีต้องทำา และระบุถึงข้อมูลท่ีจะนำามาใช้ ซ่ึงเม่ือเรากำาหนดกลยุทธ์ทางด้าน Big Data โดยเร่ิมจากมุมมองธุรกิจ เช่นน้ีแล้ว เราค่อยมาคำานึงถึงเทคโนโลยีท่ีจะต้องนำามาใช้งาน จากรูปท่ี 3 จะเห็นได้ว่า เทคโนโลยีแต่ละแบบจะมีความเหมาะสมกับข้อมูลท่ีแตกต่าง กัน เช่น การวางกลยุทธ์ด้าน BIG DATA ขององค์กรและ TECHNOLOGY ด้าน DATA ต่างๆ 75
- 84. รูปท่ี 3 เปรียบเทียบเทคโนโลยีการเก็บข้อมูลแบบต่างๆ [Source: Amazon Web Services] • Traditional Database คือเทคโนโลยีฐานข้อมูล SQL แบบเดิมสำาหรับ ข้อมูลท่ีเป็น structure ในระดับ GByte ถึง TByte และมีความเร็วใน การประมวลผลไม่มากนัก • MPP Database คือเทคโนโลยีสำาหรับข้อมูลขนาดใหญ่หลาย TByte ท่ี เป็น structure โดยมีความสามารถในการประมวลผลข้อมูลขนาดใหญ่ ได้อย่างรวดเร็ว ตัวอย่างของ MPP มีอาทิเช่น Oracle Exadata. SAP HANA, Amazon Redshift หรือ Datawarehouse อย่าง Teredata หรือ Greenplum • NoSQLคือเทคโนโลยีในการเก็บข้อมูล semi-structure ขนาดใหญ่ โดยไม่ได้ใช้คำาส่ังในการประมวลผลท่ีเป็น SQL ต้วอย่างเช่น mongo DB, Cassendra หรือ Dynamo DB • Hadoop คือเทคโนโลยีในการเก็บข้อมูลท่ีเป็น unstructure ซ่ึง สามารถจะเก็บข้อมูลขนาดใหญ่ได้เป็น PByte องค์กรจะต้องเตรียมโครงสร้างพ้ืนฐานเพ่ือท่ีจะรองรับ Big Dataโดยจะต้อง ใช้เทคโนโลยีเหล่าน้ีผสมผสานกัน องค์กรคงยังต้องมี SQL Database แต่ 76 THANACHART
- 85. ขนาดเดียวกันอาจต้องมี Hadoop สำาหรับเก็บข้อมูลขนาดใหญ่ท่ีเป็น unstructure และอาจต้องมี MPP Database ท่ีอาจเป็น DatawareHouse หรือ Large Scale Database อย่าง Oracle ExaData ในปีหน้าทาง IMC Institute จะมุ่งเน้นเร่ือง Big Data มากข้ึน ซ่ึงนออก เหนือจากการเปิดหลักสูตรต่างๆในด้าน Big Data อพ่ือพัฒนาบุคลากรแล้ว (ดูบทความIMC Institute ปรับปรุงหลักสูตรด้าน Big Data ในปีหน้า เพ่ือ สร้างคนไอที) ยังได้ร่วมมือกับบริษัทต่างประเทศท่ีเช่ียวชาญในด้าน Big Data คือ Cosmos Technology และ Xentio ในการท่ีจะวางแผนกลยุทธ์ และทำาโครงการด้าน Big Data ให้กับองค์กรต่างๆในประเทศไทย ซ่ึงถ้า ท่านใดสนใจก็สามารถจะติดต่อมายัง IMC Institute ได้ ธนชาติ นุ่มนนท์ IMC Institute ธันวาคม 2557 การวางกลยุทธ์ด้าน BIG DATA ขององค์กรและ TECHNOLOGY ด้าน DATA ต่างๆ 77
- 87. CHAPTER 15 ปี 2015 จะเป็นปีเร่ิมต้นของ Big Data Analytics เผลอแป๊ปเดียวก็ผ่านไปอีกปีแล้ว เวลามันช่างผ่านไปอย่างรวดเร็ว บางคร้ัง ก็นึกเสียดายบางช่วงเวลาท่ีคิดว่าเราน่าจะทำาอะไรได้ดีกว่าน้ี แต่ส่ิงท่ีผ่าน ไปแล้วมันก็คงต้องปล่อยให้มันผ่านไป เราแก้ไขอดีตไม่ได้แต่เราสามารถท่ี
- 88. จะทำาให้อนาคตดีข้ึนได้ ในฐานะของคนไอทีเกือบ 20 ปีท่ีผ่านมา เทคโนโลยี มันมีการเปล่ียนแปลงตลอด ถ้าใครอยู่น่ิงไปจมอยู่กับอดีตไม่มองถึง เทคโนโลยีท่ีเปล่ียนแปลงก็จะลำาบาก บางคร้ังก็อดสงสัยไม่ได้ว่าคนอาชีพ อ่ืนเขาต้องเรียนรู้อะไรใหม่ๆมากมายตลอดเวลาเช่นน้ีไหมและต้องไล่ล่ากับ อนาคตเพ่ือให้อยู่รอดในวิชาชีพอย่างคนไอทีหรือเปล่า 20 ปีท่ีผ่านมาเราเห็นการเปล่ียนแปลงตลอดเวลา ผมเองก็ต้องคอย เรียนรู้และก้าวให้ทันกับส่ิงใหม่ๆเสมอ คงไม่ต้องบอกว่าผมเรียนรู้ คอมพิวเตอร์มาจากยุคเจาะบัตรด้วยภาษา Fortarn IV ต้องมาใช้ไมโคร คอมพิวเตอร์ยุคท่ียังไม่มี Harddisk เช่ือครับมีคนในอุตสาหกรรมหลายคน ในปัจจุบันทีมาจากยุคเก่ากว่าผมอีก แต่ผมอยากตัดบทไปถึงแค่สิบห้าปี ก่อน จำาได้ว่าตอนน้ันภาษา Java กำาลังเข้ามา ผมเองก็ต้องขนขวายเสียเงิน ทองไปเรียนและสอบ Certiied Java Programmer พอยุค Web Server/App Server มาก็ต้องมาน่ังศึกษา Java EE มาเรียน Enterprise Application ทำาให้เข้าใจ IT Architecture มากข้ึน พอยุค Smart Mobile รุ่นแรกเข้ามาเม่ือสิบปีก่อนก็ต้องมาเรียนรู้ Java ME เขียนโปรแกรมบน Nokia 7650 และไปอบรมคนท่ัวประเทศ พอถัดมาคนมาพูดถึง Web Services ก็ต้องมาเรียนกันใหม่ มามองเร่ือง Cross Platform และก็ต้องพูดถึง Application Programming Interfaces (APIs) แล้วก็ต้องมาว่ากันถึงเร่ืองของ Service Oriented Architecture (SOA) และก็เร่ิมมอง Programming Language ท่ีหลาย หลายข้ึน ไม่ว่าจะเป็น Python, Ruby และก็ต้องดู Web Framework ต่างๆ จะเห็นได้ว่าคนไอทีแทบไม่เคยได้ต้องหยุดเรียนรู้ส่ิงใหม่ๆ ห้าปีก่อนพอเร่ือง Cloud Computing เข้ามา ผมก็เป็นคนแรกๆในบ้าน เราท่ีไปบรรยายเร่ืองน้ี และทดลองเล่น Cloud Platform ต่างๆท้ัง IaaS, SaaS และ PaaS พยายามจะบอกกับหลายๆคนว่าวันน้ีไอทีต้องไป Cloud และตอนน้ันก็เป็น ผอ. Software Park ก็พยายามจัดสัมมนาและร่วมกลุ่ม พันธมิตรทางด้าน Cloud Computing เพ่ือช้ีให้เห็นว่า Cloud Computing transforms IT และอุตสาหกรรมซอฟต์แวร์จะต้องข้ึน Cloud ในยุคท่ีผม เป็นผอ. Software Park นอกจาก Cloud แล้วก็จะพูดถึงเร่ือง Mobile เพราะเช่ือว่า Devices กำาลังจะเปล่ียนสู่ยุคของ Smartphone/Tablet จน มีคนแซวผมว่าหน้าผมคือ Cloud and Mobile ทันทีท่ีผมก่อต้ัง IMC Institute เม่ือสองปีท่ีก่อน ผมเร่ิมท่ีจะจัดอบรม Big Data และพยายามจะจัดสัมมนาด้านน้ีมากข้ึนเพราะผมเช่ือว่าเร่ืองน้ีกำาลัง 80 THANACHART
- 89. จะมา และเราจำาเป็นต้องสร้างบุคลากรทางด้านน้ี โดยผมเน้นเร่ืองของ เทคโนโลยี Hadoop ท่ีสามารถเก็บ Unstructure Data ได้มหาศาล ช่วง เวลาสองปีทาง IMC Institute ก็ได้อบรมคนไปหลายร้อยคน และก็ได้ช่วย ทำาให้คนเข้าใจเทคโนโลยีน้ีมากข้ึน กระแส Big Data กำาลังมาอย่างแน่นอน เพราะตอนน้ีจำานวน Devices ท่ัวโลกมีหลายพันล้าน คนใช้อินเตอร์เน็ตมีมากข้ึน มีการใช้ Social Network มีมากข้ึน และเร่ืองของ Internet of Things กำาลังมา ส่ิงต่างๆ เหล่าน้ีล้วนแต่มีการสร้างข้อมูลใหม่ๆอยู่ตลอดเวลา จำานวนข้อมูลมากข้ึน ทุกวันและมีข้อมูลท่ีเป็น Unstructure จำานวนมาก จึงมีความจำาเป็นต้องหา เทคโนโลยีใหม่ๆมาใช้ในการเก็บและวิเคราะห์ข้อมูล ผมเช่ือว่าในปี 2015 น้ี เร่ืองของ Big Data Analytics จะมีความสำาคัญมากข้ึน เพราะธุรกิจต่างๆ จะมีการแข่งขันกันมากข้ึน ใครก็ตามท่ีสามารถจะนำาข้อมูลขนาดใหญ่มา วิเคราะห์ได้คนน้ันจะได้เปรียบเหนือคู่แข่ง Big Data transform Business ภาพโครงสร้างพ้ืนฐานข้อมูล (Information Infrastructure) ใน อนาคตขององค์กรจะเปล่ียนแปลงไปเพราะขนาดข้อมูลท่ีใหญ่ข้ึน และชนิด ข้อมูลท่ีหลากหลาย เราน่าจะเป็นโครงสร้างท่ีใช้เทตโนโลยีต่างๆมากข้ึนดัง ตัวอย่างในรูป รูปตัวอย่าง Information Infrastructure ขององค์กร [source 1=”KARMAsphere” language=”:”][/source] ปี 2015 จะเป็นปีเร่ิมต้นของ BIG DATA ANALYTICS 81
- 90. ปี 2015 เราควรจะต้องเตรียมพร้อมอย่างไรบ้างกับเร่ืองของ Big Data Analytics 1) องค์กรต้องมี Big Data Strategy: ฝ่ังธุรกิจและไอทีคงต้องมาร่วม กันในการวางแผนท่ีจะนำาข้อมูลมาใช้ในการสร้างความสามารถในการ แข่งขัน เพ่ือให้เข้าใจและคาดการณ์ข้อมูลลูกค้า สินค้า หรือคู่แข่งได้ดีข้ึน โดยต้องสามารถท่ีจะใช้ข้อมูลจากข้ัน Business Intelligence ไปสู่ Predictive Analytics 2) องค์กรต้องมีกำรวำงแผนด้ำน Information Infrastructure ใหม่: ข้อมูลในอนาคตจะมีขนาดใหญ่มาก การจะวางโครงสร้างพ้ืนฐาน ข้อมูลขององค์กรให้ข้ึนกับ Database หรือ Enterprise Datawarehouse (EDW) แต่อย่างเดียวคงไม่สามารถเป็นไปได้ เพราะค่า ใช้จะสูงมาก คงต้องเร่ิมพิจารณาเทคโนโลยีอย่าง Hadoop หรือ NoSQL ด้วย 3) องค์กรต้องเร่งพัฒนำบุคลำกรด้ำนข้อมูล: เทคโนโลยีด้านน้ีจะเปล่ียน ไปมาก องค์กรจำาเป็นต้องพัฒนาบุคลากรท้ังท่ีจะเป็น Chief Data O^ce, Data Architecture, IT Profeession, BI Analysis และ Data Scientist ครับเราคงต้องเร่ิมท่ีจะต้องเตรียมพร้อมเข้าสู่ยุคของ Big Data Analytics กันแล้ว ธนชาติ นุ่มนนท์ IMC Institute มกราคม 2558 82 THANACHART
- 91. CHAPTER 16 Big Data Use Cases: ใน อุตสาหกรรมต่างๆ Big Data เป็นเร่ืองท่ีกำาลังอยู่ในความสนใจอย่างมาก เม่ือพูดถึงเร่ืองน้ี ความสำาคัญไม่ได้อยู่เพียงแค่จะใช้เทคโนโลยีใหม่อย่างไร หรือจะเก็บข้อมูล อย่างไร แต่เป็นเร่ืองของการนำาข้อมูลมาวิเคราะห์ทำาให้ เกิดประโยชน์ทาง ธุรกิจอย่างไี โดยเฉพาะเร่ืองของการทำา Analytics เพราะการมีข้อมูลขนาด ใหญ่ย่อมทำาให้การคาดการณ์ต่างๆมีความแม่นยำาข้ึน ซ่ึงเม่ือมีการพูดถึง การประยุกต์ใช้งาน Big Data บางท่านก็อาจนึกในด้านการหาข้อมูลของ ลูกค้าหรือสินค้า เราลองมาดูว่า Big Data สามารถนำามาทำาอะไรได้บ้างดัง ตัวอย่างในรูปข้างล่างของ IBM ท่ีพูดถึงประโยชน์สำาหรับกลุ่มคนหรือส่วน งานต่างๆดังน้ี
- 92. • Branch Management: Big Data สามารถช่วยระบุได้ว่าสินค้าใด หรือสาขาใดขายดีท่ีสุด • Relationship Management: Big Data สามารถวิเคราะห์ความเส่ียง และคาดการณ์รายได้จากลูกค้าเม่ือเรานำาเสนอสินค้าใหม่ๆได้ • Marketing: Big Data สามารถช่วยทำาให้เรานำาเสนอสินค้าให้ตรงกับ กลุ่มลูกค้าในเวลาท่ีเหมาะสม • Payment: Big Data สามารถช่วยตรวจจับและป้องกันการฉ้อโกงการ ชำาระเงินออนไลน์ • Executive Leader: Big Data สามารถช่วยให้ผู้บริหารมีข้อมูลท่ี ถูกต้องในการตัดสินใจ ในช่วงเวลาต่างๆ • Risk and Finance: สามารถช่วยทำาให้การปฎิบัติตามกฎเกณฑ์ต่างๆข งอธุรกิจไปได้ด้วยย่ิงข้ึน เพราะจะช่วยลดความเส่ียง ในแง่ของการนำา Big Data มาใช้ในอุตสาหกรรมต่างๆ เราอาจยกตัวอย่าง การใช้งานได้ดังน้ี 1) Telecommunication: อุตสาหกรรมกลุ่มน้ีน่าจะมีข้อมูลท่ีเป็น Big Data จริงๆ เพราะมีจำานวนลูกค้าท่ีผู้ใช้บริการโทรศัพท์อยู่เป็นหลักสิบล้าน และในแต่ละวันจะมีข้อมูลท่ีเป็น Transaction จากการใช้โทรศัพท์จำานวน มาก ข้อมูล CDR (Call Detail Record) ของผู้ให้บริการโทรศัพท์ในแต่ละ 84 THANACHART
- 93. วันจะมีขนาดหลาย TB ซ่ึงถ้าสามารถนำามาวิเคราะห์ได้จะได้ข้อมูลท่ีเป็น ประโยชน์มากมาย อาทิเช่นการวางแผนการติดต้ังเครือข่าย การวิเคราะห์ การใช้งาน การลดการย้ายค่าย ตัวอย่างการนำา Big Data มาใช้งานทาง ด้านน้ีมีดังตารางข้างล่างน้ี ตัวอย่างการนำา Big Data มาใช้งานทางอุตสาหกรรม Telecommunication [Source: Monetizing Big Data at Telecom Service Providers] 2) Banking/Insurance: อุตสาหกรรมการเงินการธนาคาร ก็เป็นอีก กลุ่มท่ีมีข้อมูลขนาดใหญ่ และ Transaction ต่อวันมีจำานวนมหาศาล ย่ิงมี การใช้งาน Internet/Mobile Banking มากข้ึน ก็ย่ิงทำาให้มีจำานวน Transaction สูงข้ึน Big Data สามารถนำามาใช้เพ่ือลดความเส่ียงต่อการ ฉ้อโกงได้การชำาระเงิน, หรือช่วยในการประเมินความเส่ียงของลูกค้าท่ีมา กู้ยืมเงิน, หรือช่วยในการประเมินอัตราค่าบริการประกันภัยของลูกค้าแต่ละ ราย หรือช่วยในการแบ่งกลุ่มลูกค้า (Customer Segmentation) ตัวอย่าง ของการนำา Big Data มาใช้งานทางด้านน้ีมีดังตารางข้างล่างน้ี BIG DATA USE CASES: ในอุตสาหกรรมต่างๆ 85
- 94. ตัวอย่างการนำา Big Data มาใช้งานทางอุตสาหกรรม Finance [Source: IDC Financial Insights] 3) Retails: อุตสาหกรรมค้าปลีกโดยเฉพาะอย่างย่ิงการขายของทางe- Commerce มีความจำาเป็นอย่างย่ิงท่ีต้องนำา Big Data เข้ามาช่วยในการ วิเคราะห์ข้อมูลต่างๆ อาทิเช่น การทำา Customer Segmentation, การ นำาเสนอสินค้าให้กับลูกค้า (Next Product to Buy), การศึกษาพฤติกรรม ลูกค้า หรือแม้แต่ใช้ในการกำาหนดราคาสินค้า (Pricing Optimization) เราจะเห็นว่าผู้ค้าปลีกหลายใหญ่ๆต่างก็พยายามจะเก็บข้อมูลการบริโภค ของลูกค้า เพ่ือนำาข้อมูลเหล่าน้ีมาวิเคราะห์ ย่ิงเป็น E-Commerce ราย ใหญ่ๆอย่าง Amazon หรือ eBay ก็ยังมีความสามารถท่ีจะไปดึงข้อมูล ภายนอกอาทิเช่นจาก social media มาวิเคราะห์ความต้องการของลูกค้า ได้ ตัวอย่างของการนำา Big Data มาใช้งานทางด้านน้ีมีดังตารางข้างล่างน้ี 86 THANACHART
- 95. ตัวอย่างการนำา Big Data มาใช้งานทางอุตสาหกรรม Retails [Source: www.crmsearch.com] นอกจากน้ี ยังมีการนำา Big Data มาใช้ในอุตสาหกรรมอาทิเช่น งานภาค รัฐบาล (Government), งานด้านวิทยาศาสตร์, งานด้านส่ือ (Media) ซ่ึง สามารถสรุปตัวอย่างได้ดังรูปข้างล่างน้ี ตัวอย่างการนำา Big Data มาใช้งานทางอุตสาหกรรมต่างๆ [Source: Big Data Analytics with Hadoop: Phillippe Julio] ตัวอย่างต่างๆท่ีพูดถึงวันน้ี เป็นการเกร่ินนำา แต่ผมจะเขียนกรณีศึกษา ทางด้านน้ีบางกรณีเพ่ิอให้เข้าใจเทคโนโลยี และเทคนิคท่ีเขาใช้ว่า ทำาได้ อย่างไรในบทความต่อๆไป ธนชาติ นุ่มนนท์ IMC Institute BIG DATA USE CASES: ในอุตสาหกรรมต่างๆ 87
- 97. CHAPTER 17 อนาคตของเทคโนโลยีฐานข้อมูล (The Future of the Database) วันก่อนได้เห็น Infographic ตามรูปข้างล่างน้ีท่ีช่ือว่า The Future of the Database ของ Robin Puro ท่ีโพสต์ใน Wired Information Insights ผมว่าเป็นรูปท่ีเล่าประวัติและคาดการณ์อนาคตของเทคโนโลยี ด้านการเก็บข้อมูลได้เป็นอย่างดี ในรูปเล่าให้เห็นต้ังแต่เทคโนโลยีเก็บข้อมูลในยุคเร่ิมต้นในทศวรรษ 1960 แต่ก็จะเน้นให้เห็นถึงในยุคทศวรรษ 1970 ซ่ึงเป็นยุคเร่ิมต้นของ เทคโนโลยีด้าน Relational Database (RDBMS) ทุกคนก็จะเร่ิมให้ความ สนใจกับเทคโนโลยีการเก็บข้อมูลท่ีใช้ภาษา SQL ระบบจะเป็นแบบ Scale Up คือหาเคร่ืองคอมพิวเตอร์ขนาดใหญ่เข้ามาช่วยในการเก็บข้อมูล จึง เขียนในรูปว่าเป็น Single Instance Relational Database เราจะเห็น โซลูช่ันของ Vendor หลายใหญ่อย่าง Oracle ท่ีเป็น Commerical Database ตัวเแรก, IBM ท่ีใช้ DB2 หรือ SyBase ในปลายยุค 1970 และช่วง 1980 ก็มีความพยายามทีจะทำา Entity Relational Database และ Object Oriented Database เพ่ือท่ีจะ มาแทนท่ี RDBMS แต่ก็ไม่ประสบความสำาเร็จและก็หยุดการพัฒนาไป จากรูป Infographic เราก็จะเห็นว่า มีอีกเทคโนโลยีท่ีเข้ามาในปลายยุค 1980 ก็คือ Dataware House เพ่ือท่ีจะรวบรวมข้อมูลจากฐานข้อมูล จำานวนมาก ส่วนหน่ึงก็ทำาหน้าท่ีเป็น ETL ของฐานข้อมูลต่างๆ ซ่ึง
- 98. Dataware House ก็เป็นระบบขนาดใหญ่ท่ีเป็นเทคโนโลยีแบบ Distributed ท่ีจะเร่ิมใช้ Server หลายๆตัว แต่ก็ยังเป็น SQL โดยมี Vendor อย่าง Teredata เป็นผู้ผลิตโซลูช่ันทางด้านน้ี พอเข้าสู่ยุคของอินเตอร์เน็ตบูมในช่วงปลายทศวรรษ 1990 ข้อมูลเร่ิมมี จำานวนมากข้ึน การจะใช้ Server ขนาดใหญ่เพียงเคร่ืองเดียวเก็บข้อมูลก็ เร่ิมจะมีปัญหา และต้องใช้ทรัพยากรเช่น CPU หน่วยความจำา หรือ Storage มากข้ึน การทำาวิเคราะห์ข้อมูลอย่างการทำา Business Intelligence หรือ Analytics ก็เร่ิมมีมากกว่าการใช้ Transactional Database ดังน้ันพอข้ึนในยุคทศวรรษ 2000 ก็เร่ิมท่ีจะมีเทคโนโลยีใหม่ๆท่ีจะเก็บ ข้อมูลใหญ่ๆได้อย่าง Distrubuted SQL ท่ีใช้เคร่ือง Server หลายๆ เคร่ืองอย่าง Clustrix หรือ NuoDB และก็ Dataware House ใหม่ๆท่ี เป็นสถาปัตยกรรมแบบ MPP (Massively Palallel Processing) เช่น ของ Netezza, Microsoft, Oracle หรือ IBM มีเทคโนโลยีอย่าง NoSQL ท่ีไม่ได้เป็น RDBMS และสามารถเก็บข้อมูลขนาดใหญ่ได้เช่น Google BigTable, MongoDB และ Cassandra และในปลายยุค 2000 ก็มี เทคโนโลยีใหม่อย่าง Hadoop ท่ีสามารถเก็บข้อมูลท่ีเป็นแบบ unstructure ได้เป็นจำานวนนับ Petabyte มาในยุคปัจจุบันท่ีกำาลังเข้าสู่ Big Data ข้อมูลเร่ิมมีขนาดใหญ่ มี หลากหลายรูปแบบไม่ใช่เฉพาะ structure และข้อมูลเปล่ียนแปลงอย่าง รวดเร็ว (3V: Volume, Variety, Velocity) ทำาให้การใช้เทคโนโลยีท่ีเป็น SQL แบบ Scale Up มีราคาท่ีแพงข้ึนในขณะท่ีระบบแบบ Scale Out ท่ีเป็น Distributed SQL จะช่วยทำาให้เก็บข้อมูลได้มากข้ึน และสามารถวิเคราะห์ ข้อมูลแบบ Real-Time ตามความต้องการของธุรกิจได้ และก็เร่ิมมีการนำา เทคโนโลยีใหม่ท่ีเป็น MPP มาใช้ใน Distributed SQL รวมถึงโซลูช่ันใหม่ๆ อย่าง SAP HANA ท่ีเป็น in-Memoery Database หรือ Oracle ExaData นอกจากน้ีเราก็ยังเห็นการพัฒนาการของเทคโนโลยีอย่าง Hadoop ท่ีมีการใช้ภาษาใหม่อย่าง Hive, Pig หรือการพัฒนา Hadoop เวอร์ช่ัน 2 ท่ีมีเทคโนโลนีอย่าง YARN ท่ีช่วยทำาให้ประมวลผลแบบ Real- time ได้ สุดท้ายในอนาคต แนวโน้มของ Database ก็จะมี Platform หลักๆอยู่ สำมตัวท่ีจะรองรับข้อมูลหลำยหลำยท่ีมีขนำดใหญ่คือ NoSQL, Hadoop และ Distributed SQL ท้ังน้ี Single Instance SQL จะมีปัญหาเร่ืองการ 90 THANACHART
- 99. Scale Up เพ่ือรองรับข้อมูลขนาดใหญ่และ Dataware House เองถ้าจะนำา มาใช่ในการทำา Analytics ก็จะถูกแทนท่ีด้วย Distributed SQL ท่ีสามารถ นำามาใช้ประมวลผลแบบ Real-time ได้ ธนชาติ นุ่มมนท์ IMC Institute มกราคม 2558 อนาคตของเทคโนโลยีฐานข้อมูล (THE FUTURE OF THE DATABASE) 91
- 101. CHAPTER 18 กลยุทธ์ Big Data สำาหรับประเทศ ไทย สัปดาห์ท่ีผ่านมา IMC Institute จัดแถลงข่าวเร่ือง Big Data Trends โดยผมได้ช้ีให้เห็นว่าในช่วง 2-3 ปีน้ีเราจะเห็นถึง Mega-Trends ทางด้าน ไอทีอยู่ 3 อย่างคือ
- 102. รูปท่ี 1 IT Mega Trends 2015 • Internet of Things อุปกรณ์ในการเช่ือมต่ออินเตอร์เน็ตจะไม่จำากัด อยู่แค่ เคร่ืองพีซี Smartphone หรือ Tablet แต่จะรวมไปถึงอุปกรณ์ ต่างๆต้ังแต่นาฬิกา, wearable technology, เคร่ืองใช้ไฟฟ้า และ ส่ิงของต่างๆ ซ่ึงมีการคาดการณ์ว่าจะมีอุปกรณ์เหล่าน้ีถึง 50,000 ล้าน ช้ินในปี 2020 • Cloud Computing ระบบการประมวลผลจะข้ึนบนอินเตอร์เน็ตมาจาก ท่ีใดก็ได้ และข้อมูลจะตามเราไปทุกท่ี ทุกเวลา และทุกอุปกรณ์ • Big Data เม่ือมีอุปกรณ์ต่ออินเตอร์เน็ตมากข้ึน ข้อมูลก็จะมากข้ึน จะมี หลายรูปแบบ และเพ่ิมข้ึนอย่างรวดเร็ว มีการคาดการณ์ว่าจะมีข้อมูล มากถึง 35 ZByte ในปี 2025 ดังน้ันต่อไปใครท่ีสามารถนำาข้อมูล มหาศาลเหล่าน้ีมาวิเคราะห์ได้ก็จะได้เปรียบเหนือคู่แข่ง กระแสเร่ือง Big Data เป็นเร่ืองท่ีเราหลีกเล่ียงไม่ได้ เพราะ Big Data ไม่ใช่ แค่เร่ืองของไอที ไม่ใช่แค่มองเร่ืองของการเก็บข้อมูล แต่เป็นเร่ืองของทาง ด้านธุรกิจและผู้ใช้ท่ีจะมองวิธีการในการนำาข้อมูลมาวิเคราะห์และคาด การณ์ต่างๆเพ่ือให้ได้ประโยชน์ จึงไม่แปลกใจท่ีเห็นบริษัท E-Commerce รายใหญ่ๆในโลกสามารถวิเคราะห์ข้อมูลคาดการณ์นำาเสนอขายสินค้าให้ กับลูกค้าได้ ธนาคารบางแห่งสามารถใช้ Big Data มาช่วยในการวิเคราะห์ เครดิตของลูกค้าท่ีจะขอสินเช่ือ หรือแม้แต่บริษัทผู้ให้บริการมือถือก็ สามารถใช้ Big Data มาช่วยในการแบ่งกลุ่มลูกค้า (Customer Segmentation) IDC ได้คาดการณ์มูลค่าตลาดของ Big Data ในปี 2014 ว่าสูงถึง 16.1 พันล้านเหรียญสหรัฐ และคาดการณ์ตลาดของ Big Data ในภูมิภาคเอเซีย แปซิฟิกโดยไม่รวมประเทศญ่ีปุ่นในปีน้ีไว้ท่ี 1.61 พันล้านเหรียญสหรัฐ ซ่ึง โตกว่าปีท่ีแล้วถึง 34.7% นอกจากน้ียังมีการคาดการณ์จากบริษัทวิจัยอย่าง Researchbeam ระบุว่ามูลค่าตลาดของ Hadoop หน่ึงในเทคโนโลยีท่ีใช้ ในการทำา Big Data จะโตจาก 1.5 พันล้านเหรียญสหรัฐในปี 2012 เป็น 50.2 พันล้านเหรียญสหรัฐในปี 2020 แต่ปัญหาท่ีหน่วยงานต่างๆจะเจอในเร่ืองของ Big Data คือการขาด บุคลากรและขาดข้อมูล Gartner เองระบุว่าในปีน้ีจะมีตำาแหน่งงานท่ี เก่ียวข้องกับ Big Data ท่ัวโลกถึง 4.4 ล้านตำาแหน่ง แต่คงสามารถท่ีจะหา 94 THANACHART
- 103. คนเข้าทำางานได้เพียง 1 ใน 3 ของตำาแหน่งงาน และทาง IDC ก็ระบุถึง ตำาแหน่งงานทางด้าน Analytics ในสหรัฐอเมริกาว่าจะมีถึงสองแสน ตำาแหน่งในปี 2018 นอกจากน้ียังพบว่าในปัจจุบันองค์กรใหญ่ๆเกือบ 70% ต้องซ้ือข้อมูลจากภายนอกมาวิเคราะห์และคาดว่าในปี 2019 ทุกองค์กร ใหญ่ๆคงต้องซ้ือข้อมูล เร่ือง Big Data ก็เป็นเร่ืองท่ีประเทศใน ASEAN ให้ความสำาคัญ รัฐบาล สิงคโปร์ต้ังเป้าต้ังแต่ปลายปี 2013 ว่าจะเป็นฮับทางด้านน้ีโดยเฉพาะการ ทำา Big Data Analytics โดยมีการต้ัง Big Data Innovation Center ส่วนทางนายกรัฐมนตรีของมาเลเซีย Najib Razak ก็ได้ประกาศนโยบาย Big Data Analytics (BDA)ในปลายปี 2014 โดยวางแผนการทำา Pilot Project ในปีน้ี 4 เร่ือง และวางแผนระยะยาว 7 ปีดังรูป รูปท่ี 2 แผนด้าน Big Data Analytics ของประเทศมาเลเซียเร่ิมต้นปี 2014 สำาหรับประเทศไทยผมคิดว่าเราคงต้องมีนโยบายอยู่สามด้านตามรูปท่ี 3 (ต้องขอขอบคุณ PostToday ทีวาดภาพกราฟฟิกน้ีสรุปให้) 1. ภำครัฐและเอกชน ◦ Big Data ยังเป็นตลาดใหม่มีการแข่งขันไม่สูงนัก (Blue Ocean) ทุกองค์กรท้ังภาครัฐและเอกชนต้องรีบวางกลยุทธ์เร่ืองน้ีโดยเร็ว มิ ฉะน้ันแล้วเราจะเสียเปรียบคู่แข่งเชิงธุรกิจ ◦ Big Data จะช่วยสร้างความได้เปรียบทางธุรกิจให้กับคู่แข่งใน ภูมิภาค ต้องเอาเร่ืองน้ีเดินควบคู่กับนโยบาย Digital Economy กลยุทธ์ BIG DATA สำาหรับประเทศไทย 95
- 104. ◦ เร่ืองข้อมูลจะเป็นเร่ืองจำาเป็น จึงต้องเร่งส่งเสริมให้มีการทำา Open Data เพ่ือให้เกิดการต่อ ยอดนำาข้อมูลไปใช้งาน 2. เทคโนโลยี ◦ เทคโนโลยีด้านน้ีจะมีการลงทุนท่ีค่อนข้างสูง ภาครัฐเองควรจะ ส่งเสริมให้มีการใช้ทรัพยากรร่วมกัน เพ่ือลดค่าใช้จ่ายในการลงทุน ด้าน Hardware/Software ◦ การต้ัง Cloud Platform สำาหรับ Big Data Technology เช่น Hadoop as a Service เป็นเร่ืองจำาเป็น ภาครัฐอาจต้องหาหน่วย งานเช่น สำานักงานรัฐบาลอิเล็กทรอนิกส์ (สรอ.) มาช่วยดำาเนินงาน หน่วยงานในภาครัฐหรือบริษัทขนาดกลางและเล็กจะได้สามารถ ใช้งานได้โดยมีค่าบริการท่ีถูกลง 3. กำรพัฒนำบุคลำกร ◦ ต้องเร่งพัฒนาบุคลากรทางด้านน้ี โดยเฉพาะผู้ท่ีจะมีความ เช่ียวชาญด้านการวิเคราะห์ข้อมูล ◦ ระยะเร่ิมต้นอาจต้องนำาผู้เช่ียวชาญจากต่างประเทศมาทำา Pilot Project ในลักษณะ On the job training 96 THANACHART
- 105. รูปท่ี 3 ข้อเสนอแนะกลยุทธ์ Big Data สำาหรับประเทศไทย Big Data คือเร่ืองใหม่และไม่ใช่เร่ืองแค่ไอที ตอน Cloud Computing เข้ามาประเทศเราก็ช้าไปและตกขบวนไปแล้ว แม้ Cloud กลายเป็น มาตรฐานในปัจจุบัน แต่ทุกวันน้ียังมีอุตสาหกรรมไอทีหรือซอฟต์แวร์ไทย จำานวนมากยังไม่เข้าใจเร่ือง Cloud ดีพอ ถ้าเราช้าไปเร่ือง Big Data งวดน้ี จะไม่ใช่แค่ตกขบวนไอทีแต่เผลอๆจะตกขบวนทางธุรกิจแข่งกับเขาในโลก ดิจิทัลท่ีเปล่ียนไปไม่ได้ ธนชาติ นุ่มนนท์ IMC Institute มกราคม 2558 กลยุทธ์ BIG DATA สำาหรับประเทศไทย 97
- 107. CHAPTER 19 Big Data บน Public Cloud ผมไม่ได้เขียนบล็อกมาสองเดือนกว่า เพราะยุ่งอยู่กับการศึกษาเร่ือง Big Data เตรียมการสอนและเปิดหลักสูตรใหม่ๆอาทิเช่น • เปิดหลักสูตร Big Data Certication จำานวน 120 ช่ัวโมงท่ีมีผู้เข้าร่วม อบรมกว่า30 คน • เปิดหลักสูตร Introduction to Data Science เม่ือต้นเดือนเมษายน ก็ เน้นสอนเร่ืองของ Hadoop, R และ Mahout ในการทำา Machine Learning รุ่นแรกมีคนเช้ามาเรียน 20 กว่าท่าน • ปรับปรุงเน้ือหาหลักสูตร Big Data using Hadoop Workshop โดยมี การนำา Cloud Virtual Server ของ AWS มาใช้ในการอบรม และเปิด อบรมรุ่นแรกของปีน้ีเม่ือปลายเดือนมีนาคม มีคนอบรม 30 คน • ปรับปรุงเน้ือหา Big Data Programming using Hadoop for Developer โดยมีการเน้นการใช้ Cluster ขนาดใหญ่บน Amazon EMR มากข้ึน และเปิดอบรมไปเม่ือเดือนกุมภาพันธ์ • จัดฟรีสัมมนา Big Data User Group แก่บุคคลท่ัวไปเพ่ือให้เข้าใจเร่ือง Big Data Analytics โดยจัดไปเม่ือต้นเดือนมีนาคม • เปิด Hadoop Big Data Challenge เพ่ือคนท่ัวไปสามารถมาทดลอง วิเคราะห์ข้อมูลขนาดใหญ่บน Hadoop Cluster ท่ีรันอยู่บน AWS จำานวนกว่า 40 vCPU
- 108. จากการทำางานด้านน้ีในช่วงสองเดือนท่ีผ่านมา ทำาให้ได้ประส[การณ์และ ข้อมูลใหม่ๆพอควร โดยเฉพาะประสบการณ์การติดต้ัง Hadoop หรือ NoSQL บน Public Cloud ซ่ึงข้อดีของการใช้ Public Cloud คือเราไม่ ต้องจัดหา Server ขนาดใหญ่จำานวนมาก และสามารถ Provision ระบบ ได้อย่างรวดเร็ว แต่มีข้อเสียคือค่าใช้จ่ายระยะยาวจะแพงกว่าการจัดหา Server เอง และถ้ามีข้อมูลจำานวนมากท่ีต้อง Transfer ไปอาจไม่เหมาะสม เพราะจะเกิดความล่าช้า นอกจากน้ียังอาจมีปัญหาเร่ืองความปลอดภัยของ ข้อมูล แต่การใช้ Public Cloud จะเหมาะมากกับการใช้งานเพ่ือเรียนรู้ หรือการ ทำา Development หรือ Test Environment นอกจากน้ียังมีบางกรณีท่ี การใช้ Public Cloud มาทำา Big Data Analytics อาจมีความเหมาะสม กว่าการจัดหา Server ขนาดใหญ่มาใช้งานเอง อาทิเช่น • กรณีท่ีระบบปัจจุบันขององค์กรทำางานอยู่บน Public Cloud อยู่แล้ว อาทิเช่นมีระบบ Web Application ท่ีรันอยู่บน Azure หรือมีระบบอยู่ Salesforce.com • กรณีท่ีข้อมูลท่ีต้องการวิเคราะห์ส่วนใหญ่เป็นข้อมูลภายนอกท่ีอยู่บน Cloud เช่นการวิเคราะห์ข้อมูลจาก Facebook ท่ีการนำาข้อมูลขนาด ใหญ่เหล่าน้ันกลับมาเก็บไว้ภายในจะทำาให้เปลืองเน้ือท่ีและล่าช้าในการ โอนย้ายข้อมูล • กรณีท่ีมีโครงการเฉพาะด้านในการวิเคราะห์ข้อมูลขนาดใหญ่เพียงคร้ัง คราว ซ่ึงไม่คุ้มค่ากับการลงทุนจัดหาเคร่ืองมาใช้เอง [slideshare id=45780994&doc=f6lut6yaq3imouoa1moi- signature-77ce298b6caf34571b21943912199c3dcaec64e6ce35768146f3141c gate01] การใช้ Public Cloud สำาหรับการวิเคราะห์ข้อมูลโดยใช้ Hadoop หรือ NoSQL มีสองรูปแบบคือ 1) กำรใช้ Virtual Server ในการติดต้ัง Middleware อาทิเช่นการ ใช้ EC2 ของ AWS หรือ Compute Engine ของ Google Cloud มา ลงซอฟต์แวร์ ข้อดีของวิธีการน้ีคือเราสามารถเลือกซอฟต์แวร์มาติดต้ังได้ เสมือนกับเราจัดหา Server มาเอง และสามารถควบคุมการติดต้ังได้ ท่ีผ่าน มาผมได้เขียนแบบฝึกหัดท่ีติดต้ังระบบแบบน้ีอยู่หลายแบบฝึกหัดดังน้ี 100 THANACHART
- 109. • Big Data using Hadoop ท่ีใช้ Amazon EC2 • Mahout Workshop on Google Cloud Platform ท่ีใช้ Google Compute Engine • Setup Hadoop Cluster on Amazon EC2 • Running Cassandra on Amazon EC2 2) กำรใช้ PaaS ท่ีอำจเป็น Hadoop as a Service หรือ NoSQL as a Service ซ่ึงในปัจจุบัน Public Cloud รายใหญ่ๆทุกค่ายจะมีระบบอย่าง น้ี เช่น EMR สำาหรับ Hadoop และ Dynamo DB สำาหรับ NoSQL บน AWS หรือค่ายอย่าง Microsoft Azure ก็มี HDInsight สำาหรับ Hadoop และ DocumentDB สำาหรับ NoSQL ข้อดีของระบบแบบน้ีคือ เราจ่ายตาม การใช้งานไม่ต้องรัน Server ไว้ตลอด, ติดต้ังง่ายเพราะผู้ให้บริการ Cloud ลงระบบมาให้แล้ว แต่ข้อเสียก็คือเราไม่สามารถปรับเปล่ียนซอฟต์แวร์ท่ี ติดต้ังได้เอง อาทิเช่น Hadoop ท่ีอยู่บน EMR มีให้เลือกแค่ Amazon Distribution หรือ MapR Distribution ผมเองก็ได้เขียนแบบฝึกหัดl สำาหรับการใช้ Amazon EMR ไว้ดังน้ี • Big Data Analytics on Hadoop Cluster using Amazon EMR สำาหรับผู้ท่ีต้องการศึกษาการติดต้ัง Hadoop Cluster ผมอาจแนะนำาให้ใช้ Google Cloud Platform ครับ เพราะระบบมีให้ทดลองใช้ 60 วัน โดย เราสามารถท่ีจะลองใช้ Compute Engine ขนาด 4 vCPU ได้ (ดูข้ันตอน การติดต้ัง Hadoop บน Google Cloud ตามน้ี) และถ้าต้องการใช้ Hadooo[ as a Service ผมแนะนำาให้ใช้ Amzon EMR ตามแบบฝึกหัด ข้างต้น แต่ก็มีค่าใช่จ่ายในการรันแต่ละคร้ัง วันน้ีขอแค่น้ีครับและอาจเขียนออกเป็นเทคนิคมากหน่อยครับ เพราะไม่ ได้เขียนบล็อกมาหลายสัปดาห์ มัวแต่ไปเขียนแบบฝึกหัดท่ีเป็นด้านเทคนิค ให้ผู้เข้าอบรมได้เรียนกัน ธนชาติ นุ่มนนท์ IMC Institute เมษายน 2558 BIG DATA บน PUBLIC CLOUD 101
- 111. CHAPTER 20 งานประชุม Hadoop Summit 2015 สัปดาห์น้ีผมเดินทางมาเมือง Brussels ประเทศเบลเย่ียม เพ่ือร่วมงาน Hadoop Summit 2015 ซ่ึงเป็นงานประจำาปีของกลุ่มคนท่ีสนใจ เทคโนโลยี Hadoop สำาหรับการทำา Big Data ซ่ึงจัดเป็นประจำาทุกปี และปี น้ีเป็นปีท่ีแปด โดยปีน้ีนอกจากจัดงานท่ี San Jose สหรัฐอเมริกาแล้วยังมา จัดในยุโรปท่ีประเทศเบลเย่ียม ซ่ึงก็เป็นคร้ังแรกท่ีจัดข้ึนท่ีน่ี โดยปีท่ีแล้วจัดท่ี ประเทศเนเธอร์แลนด์ เจ้าภาพงาน Hadoop Summit คือบริษัท Hortonworks หน่ึงใน Hadoop Distributor รายใหญ่ ซ่ึงได้รับสนับสนุนโดยบริษัท Yahoo จึง ไม่แปลกใจท่ีเห็น Keynote รายๆหลายท่ีเป็นพันธมิตรกับ Hortonworks
- 112. อาทิเช่น Yahoo, IBM, SAP และ Microsoft และก็มี vendor รายใหญ่ๆ อีกหลายรายเข้ามาเป็น sponsor ในงานน้ีไม่ว่าจะเป็น HP, EMC, Cisco, Teradata, Cloudera, Intel, Google. pentaho, SAS หรือ BMC มีคน รวมงานมากกว่า 1,500 คน ซ่ึงงานน้ีมี session การบรรยายของ Hadoop Distributor เกือบทุกรายท้ัง Cloudera, Hortonworks, MapR, IBM, Pivoltal และ Teradata รวมถึง Distributor บน Cloud ท่ีเป็น Hadoop as a Service อย่าง Microsoft Azure HDInsight และ Google Cloud Platform ถ้าจะขาดรายใหญ่ก็คงแค่ Amazon Web Services ท่ีมี Hadoop Distribution บน Cloud รายใหญ่อีกรายหน่ึง การบรรยายงานน้ีน่าสนใจมาก ทำาให้ได้เห็นแนวโน้มของ Hadoop ท่ีคงไม่ ได้เป็นแค่เทคโนโลยีธรรมดาแล้ว แต่มันกำาลังกลายเป็น Data Opearting System (Data OS) สำาหรับรัน Application ต่างๅในการเก็บและวิเคราะห์ ข้อมูลทุกรูปแบบท้ัง Structure และ Unstructure Data นอกจากน้ี Forrester ยังระบุอีกด้วยว่าต่อไปทุกองค์กรจะต้องใช้ Hadoop เหมือนกับ ท่ีทุกองค์กรต้องใช้ฐานข้อมูล RDBMS ในการเก็บข้อมูลในปัจจุบัน แน่นอน ครับว่า Hadoop มีอนาคตท่ีชัดเจนและเป็นหน่ึงในเทคโนโลยีท่ีน่าศึกษา และเป็นอนาคตของผู้ท่ีกำาลังศึกษาด้านคอมพิวเตอร์ อาจบอกได้ว่าถ้า อยากได้งานท่ีดีในอนาคตคงต้องมาศึกษาเทคโนโลยีอย่าง Hadoop และ วิชาอย่าง Data Science หรือ Machine Learning อีกเร่ืองหน่ึงท่ีเป็นการประกาศท่ีสำาคัญในงานน้ีคือการรวมตัวของ Vendors รายต่างๆท้ัง Hortonworks, IBM, Yahoo, Pivotal, SAP. ใน 104 THANACHART
- 113. การสร้างมาตราฐาน Open Data Platform เพ่ือให้เทคโนโลยีต่างๆท่ีมี vendor หลายรายทำาอยู่ให้มีมาตราฐานเดียวกัน เพ่ือสร้าง competibility โดยในเบ้ืองต้นเน้นอยู่ท่ีสองเทคโนโลยีหลักคือ Hadoop และ Ambari ท่ี เป็น open source สำาหรับการบริหารจัดการ Hadoop Cluster งาน Summit น้ีมีหัวข้อทางด้าน Business ท่ีพูดถึงการนำา Hadoop มา ใช้งานในหลายๆองค์กรและหลายคลัสเตอร์ท้ังกลุ่ม Bank, Telecom, Energy, Transportaion และ Retails โดยมีการพูดถึงเคร่ืองมือใน วิเคราะห์ข้อมูลเพ่ือทำา BI มากมายท้ัง Tabular, Pentaho, SAP หรือ SAS และก็ยังเน้นการถึงเทคโนโลยีในการทำา Data Analytics อย่าง Spark หรือ Mahout งานน้ีมี sesion ในการบรรยายพูดเทคโนโลยีสำาหรับ Hadoop 2 อย่าง YARN, Tez, Storm, Hive, Pig, Spark, Solr, Kafka, Lambda. และอ่ืนๆ โดยมีหัวข้อต่างท่ีน่าสนใจอาทิเช่น • 5 Ways Hadoop Is Changing The World And 2 Ways It Will Change Yours • Unlocking Hadoop’s Potential • Hadoop in the Enterprise • Design Patterns for Real Time Streaming Data Analytics • Making the Case for Hadoop in a Large Enterprise • Hive Now Sparks • Storm as an ETL Engine to Hadoop • Hadoop YARN: Past, Present and Future • Hadoop in the Cloud – Common Architectural Patterns • Driving Enterprise Data Governance for Big Data systems through Apache Falcon • Oozie or Easy: Managing Hadoop Work]ows the EASY Way ข้อมูลในงานท้ังหมดน้ีผมจะนำามาบรรยายสรุปในงานฟรีสัมมนา Thailand Hadoop User Group คร้ังท่ี 3 ท่ีทาง IMC institute ต้ังใจจะจัดร่วมกับ สำานักงานรัฐบาลอิเล็กทรอนิกส์ (EGA) ในปลายเดือนพฤษภาคม ธนชาติ นุ่มนนท์ งานประชุม HADOOP SUMMIT 2015 105
- 114. IMC Institute เมษายน 2558 106 THANACHART
- 115. CHAPTER 21 เอกสารการอบรม Big Data Certification Course (ตอนท่ี 1) IMC Institute เปิดหลักสูตร Big Data Certication รุ่นท่ีหน่ึงต้ังแต่กลาง เดือนมีนาคมน้ี มีผู้เข้าอบรมร่วม 30 ท่านจากหลายๆหน่วยงานท้ังภาครัฐ
- 116. และภาคเอกชน โดยมีวิทยากรร่วม 7 ท่านโดยมีการสอนท้ังหมด 4 โมดูล คือ • Module 1: Big Data Essentials and NoSQL • Module 2: Big Data Using Hadoop • Module 3: Business Intelligence Design&Process • Module 4: Data Scientist Essentials ซ่ึงตอนน้ีได้มีการอบรมเสร็จไปแล้วสองโมดูล ผมจึงขอนำาเอกสารการ บรรยายท้ังสองโมดูลมาแชร์ให้ดังน้ี Module 1: Big Data Essentials and NoSQL • Introduction to Big Data (Asst.Prof. Dr.Putchong Uthayopas) • Big Data Uses Cases (Mr. Danairat Thanabodithammachari) • Data Science/Data Mining /BI (Assoc.Prof. Dr.Jirapun Daengdej) • Big Data Planning/Strategy (Assoc.Prof.Dr.Thanachart Numnonda) • Big Data Trends (Assoc.Prof.Dr.Thanachart Numnonda) • Big Data Project Management (Mr. Danairat Thanabodithammachari) • Big Data Governance/ Matuarity(Mr. Danairat Thanabodithammachari) • Introduction to NoSQL (Assoc.Prof.Dr.Thanachart Numnonda) • Introduction to MongoDB (Mr. Dendej Sawarnkatat ) • Introduction to Cassandra (Assoc.Prof.Dr.Thanachart Numnonda) Module 2: Big Data Using Hadoop 108 THANACHART
- 117. • Introduction to Hadoop (Assoc.Prof.Dr.Thanachart Numnonda) • Hadoop 2.6 Handon Labs(Assoc.Prof.Dr.Thanachart Numnonda &Mr. Danairat Thanabodithammachari ) • Analyse Tweets using Flume 1.4, Hadoop 2.7 and Hive (Assoc.Prof.Dr.Thanachart Numnonda) • Install Cloudera on Amazon EC2 (Assoc.Prof.Dr.Thanachart Numnonda) ธนชาติ นุ่มนนท์ IMC Institute พฤษภาคม 2558 เอกสารการอบรม BIG DATA CERTIFICATION COURSE (ตอนท่ี 1) 109
- 119. CHAPTER 22 การติดต้ังและเปรียบเทียบ Hadoop Distribution ต่างๆ Hadoop เป็นหน่ึงในเทคโนโลยีการทำา Big Data ท่ีกำาลังเป็นท่ีนิยม อย่างมากเน่ืองจากมีความสามารถในการเก็บข้อมูลนับเป็น PetaByte และ นำามาใช้งานในเว็บใหญ่ๆและหน่วยงานต่างๆจำานวนมากอาทิเช่น Yahoo หรือ Facebook แม้ Hadoop จะเป็น Open Source แต่ก็มีผู้ผลิตหลาย รายต่างทำา Distribution ของ Hadoop ออกมาอาทิเช่น IBM, Amazon, Intel, Microsoft, Cloudera และ Hortonworks เป็นต้น โดย Forrester Research ได้เปรียบเทียบ Hadoop Distribution ต่างๆในรูปท่ี 1
- 120. รูปท่ี 1 การเปรียบ Hadoop Distribution ของ Forrester Research Hadoop Distribution แบ่งออกเป็น 4 กลุ่ม ดังแสดงในรูปท่ี 2 • Apache Open source: ตัวท่ีเป็น Open Source Project ของ Apache ท่ีเราสามารถ Download ได้จากเว็บ hadoop.apache.org • Hadoop Software Vendors: กลุ่มน้ีคือผู้ผลิตท่ีไม่ได้ผูกติดกับ Hardware Vendor โดยสามารถจะติดต้ัง Hadoop Distribution กับ Server ค่ายใดก็ได้ กลุ่มน้ีจะเป็นผู้นำาตลาดด้าน Hadoop โดยมีราย หลักสามรายคือ Cloudera, Hortonworks และ MapR • Hadoop Distribution ของผู้ผลิต Hardware: ผู้ผลิต Hardware บางรายก็จะทำา Hadoop Distribution ออกมา และมักจะแนะนำาให้ผู้ใช้ เลือกใช้เคร่ือง Server ของตัวเองอาทิเช่น IBM Inforsphere BigInsight, Pivotal HD ของ EMC และ Teradata • Hadoop Distribution ของผู้ให้บริกำร Cloud: กลุ่มน้ีจะเป็น Hadoop ท่ีรันอยู่บน Cloud เท่าน้ันและไม่สามารถติดต้ังบน Server ท่ัวไปได้ ตัวอย่างของ Hadoop ในกลุ่มน้ีคือ Amazon EMR และ Microsoft Azure HDInsight 112 THANACHART
- 121. รูปท่ี 2 ประเภทของ Hadoop Distribution ผมเองเคยทดลองใช้และติดต้ัง Hadoop Cluster สำาหรับ Distribution ต่างๆดังน้ี Apache Hadoop, Cloudera, Hortonworks, Amazon EMR, Microsoft Azure และ Google Cloud Platform ซ่ึงการติดต้ัง Hadoop Cluster จะมีปัญหาในเร่ืองการหา Server ผมจึงเลือกใช้ Virtual Server ท่ีอยู่บน Cloud ท่ีเป็น EC2 ของ Amazon Web Services หรือ ไม่ก็จะเลือกใช้ Hadoop as a Services ท่ีอยู่บน Cloud ซ่ึงง่ายต่อการ ติดต้ัง สำาหรับเอกสารการติดต้ัง Hadoop Distribution ต่างๆท่ีผมและทีม งานเคยเขียนไว้หรือจากแหล่งอ่ืนๆมีดังน้ี • เอกสารการติดต้ัง Apache Hadoop 2.6 บน EC2 • เอกสารการติดต้ัง Apache Hadoop Cluster บน EC2 • เอกสารการติดต้ัง Apache Hadoop 1.x Cluster บน EC2 • เอกสารการติดต้ัง Cloudera Express Cluster บน EC2 • เอกสารการติดต้ัง Hortonworks Cluster บน EC2 การติดต้ังและเปรียบเทียบ HADOOP DISTRIBUTION ต่างๆ 113
- 122. • เอกสารการติดต้ัง Amazon EMR Cluster จากการทดลองติดต้ังใช้งาน Cluster ต่างๆ ขอเปรียบเทียบดังน้ี • Apache Hadoop Distribution: มีข้อเด่นคือเป็น Opensource และไม่ต้องห่วงเร่ือง License การใช้งานแต่มีข้อจำากัดคือเราต้องบริหาร จัดการ Distribution ต่างๆของ Hadoop เอง ซ่ึงบางคร้ังอาจจะเจอ ปัญหาเร่ือง Bug หรือ Con]ict ระหว่าง version ตัวอย่างเช่น Flume 1.5 อาจจะต้องปรับบางไฟล์เพ่ือให้ทำางานกับ Hadoop 2.7 ได้ นอกจาก น้ีข้ันตอนในการติดต้ังต่างๆจะยากกว่า Distribution ต่างๆ • Hortonworks สามารถติดต้ังได้โดยง่ายแต่ผู้ใช้ต้องจัดการลง SSH ในแต่ Server เอง ข้อดีอีกอย่างคือมี โปรแกรมบริหาร Cluster ทีเป็น Opensource ท่ีช่ือ Ambari ทำาให้เพ่ิมหรือลด Server ได้โดยง่าย • Cloudera น่าจะเป็น Distribution ทีติดต้ังได้ง่ายท่ีสุดท่ีผมได้ทดลอง มา ข้อดีอีกอย่างคืมีโปรแกรม Hue ท่ีช่วยทำา Web GUI สำาหรับผู้ ต้องการใช้งาน Hadoop ส่วนโปรแกรมจัดการ Cluster คือ Cloudera Manager น้ันอาจผูกติดกับบริษัท Cloudera ไปหน่อย 114 THANACHART
- 123. • Hadoop as a Service on Cloud มีข้อดีคือติดต้ังได้โดยอัตโนมัติ เราเพียงแต่บอกขนาดของ Server จำานวนโหนด และซอฟต์แวร์ท่ี ต้องการจะติดต้ัง จากประสบการณ์ของผมค่อนข้างจะชอบของ Amazon EMR มากสุด แต่การใช้งาน Hadoop as a Service มีข้อ จำากัดตรงต้องใช้ Hadoop และ Ecosystem ตามท่ีผู้ให้บริการ Cloud กำาหนดมาเท่าน้ัน เราไม่สามารถเลือกใช้เองได้ ผมคิดว่าทางท่ีดีท่ีสุดสำาหรับผู้ต้องการทดลองทำา Big Data คือทดลอง ติดต้ัง Hadoop Distribution ใดก็ได้บน Cloud Server แล้วเราจะเข้าใจ ระบบและการใช้งานได้ดีข้ึน ธนชาติ นุ่มนนท์ IMC Institute พฤษภาคม 2558 การติดต้ังและเปรียบเทียบ HADOOP DISTRIBUTION ต่างๆ 115
- 125. CHAPTER 23 โครงการ Big Data กับความจำาเป็น ต่อการลงทุนด้านเทคโนโลยี คำาถามหน่ึงท่ีเรามักจะเจอบ่อยคือ “ข้อมูลใหญ่ขนาดไหนถึงจะเรียกว่า Big Data” หรือบางทีเราก็มักจะเจอคำาถามว่า “เราต้องซ้ือ Product อะไรเพ่ือ มาทำาโครงการ Big Data เราต้องลงทุนซ้ือเทคโนโลยี Hadoop หรือไม่” จริงๆแล้ว Big Data มันก็เป็นศัพท์ทางการตลาดท่ีพยายามจะบอกให้ผู้คน เข้าใจได้ว่าข้อมูลในปัจจุบันมีขนาดใหญ่ข้ึน (Volume) เพ่ิมข้ึนอย่างรวดเร็ว (Velocity) มีรูปแบบท่ีหลากหลาย (Variety) และมีความไม่แน่นนอน (Vacirity) ซ่ึงข้อมูลมหาศาลเหล่าน้ีมีท้ังข้อมูลภายใน ภายนอกองค์กรหรือ จาก Social Media การท่ีข้อมูลปัจจุบันเป็นอย่างน้ีถ้าใครรู้จักนำาข้อมูล เหล่าน้ีมาวิเคราะห์มาใช้งานก็จะเป็นประโยชน์ต่อองค์กรมหาศาล หลาย องค์กรเร่ิมสนใจจะทำาโครงการ Big Data แต่บางคร้ังไปเร่ิมท่ีฝ่ายไอที ก็มัก จะกลายเป็นโจทย์ในการหาโซลูช่ันหรือ Product ซ่ึงพอเป็นโครงการอย่าง น้ีบางทีก็คิดว่าจะต้องลงทุนด้วยงบประมาณสูงๆ ทางบริษัท Vendor ต่างๆ ก็จะพยายามนำาเสนอโซลูช่ันราคาแพงท่ีสามารถเก็บข้อมูลจำานวนมหาศาล ได้และสามารถประมวลผลได้อย่างรวดเร็วท้ังๆท่ีอาจยังไม่รู้ด้วยว่าจะนำา โซลูช่ันไปวิเคราะห์ข้อมูลอะไร โครงการ Big Data ท่ีดีควรเร่ิมท่ีฝ่ังธุรกิจ ควรจะต้องพิจารณาก่อนว่าต้องการทำาอะไร อาทิเช่นต้องการหาข้อมูล ลูกค้าเพ่ิม วิเคราะห์ความเส่ียง พยากรณ์ยอดขาย ทำา Social Media Analysis. ต้องการคาดการณ์ความต้องการของลูกค้า ซ่ึงโจทย์แต่ละอย่าง
- 126. อาจมีความต้องการข้อมูลท่ีแตกต่างกัน Product ท่ีต่างกันและวิธีการ วิเคราะห์ข้อมูลต่างกัน Big Data มีองค์ประกอบท่ีสำาคัญสามอย่าง • Data Source คือแหล่งข้อมูลท่ีาจจะเป็นข้อมูลภายในองค์กร หรือข้อมูล ภายนอกองค์กร หรืออาจต้องนำาข้อมูลจากSocial Media มาใช้ ข้อมูล อาจเป็นข้อมูลรูปแบบเดิมท่ีเป็น structure หรือข้อมูลแบบใหม่ท่ีเป็น unstructure แต่หลักการหน่ึงท่ีสำาคัญในเร่ืองของ Big Data คือถ้าเรา มีข้อมูลมากข้ึนก็น่าจะมีประโยชน์ต่อองค์กรมากข้ึนตาม • Technology คือโซลูช่ันท่ีจะช่วยทำาให้เราสามารถจะเก็บข้อมูลและ ประมวลผลได้รวดเร็วข้ึน การจะใช้เทคโนโลยีใดก็ข้ึนอยู่กับข้อมูลท่ี ต้องการ ถ้าขนาดข้อมูลไม่ได้มากไปข้อมูลท่ีต้องการยังเป็นแบบเดิมก็ อาจใช้เทคโนโลยีแบบเดิมในการเก็บ หรือถ้าข้อมูลมีจำานวนมากก็อาจ พิจารณาเทคโนโลยใหม่ๆท่ีเป็น Hadoop หรือ MPP รวมถึงอาจต้อง พิจารณาเคร่ืองมือต่างๆในการวิเคราะห์ข้อมูลเช่น BI หรือ Analytics Tool • Analytics คือกระบวนการในการนำาข้อมูลมาวิเคราะห์ ท้ังน้ีก็ข้ึนอยู่กับ 118 THANACHART
- 127. โจทย์ว่าต้องการทำาอะไรงานบางอย่างก็อาจใช้เคร่ืองมือ BI ท่ัวๆไปแต่ งานบางงานก็อาจต้องหาผู้เช่ียวชาญท่ีเป็น Data Scientists เข้ามาช่วย โดยเฉพาะกรณีท่ีต้องการใช้ข้อมูลเพ่ือคาดการณ์ต่างๆท่ีอาจต้องหา อัลกอริทึมท่ีเหมาะสม จากท่ีกล่าวมาจะเห็นว่าบางคร้ังโครงการ Big Data อาจไม่ต้องลงทุนซ้ือ เทคโนโลยีใดเลยก็ได้ ถ้าเร่ิมจากความต้องการทางธุรกิจและเข้าใจว่า ต้องการ Data Source และต้องวิเคราะห์ข้อมูลอย่างไร ธนชำติ นุ่มนนท์ IMC Institute กรกฎาคม 2558 โครงการ BIG DATA กับความจำาเป็นต่อการลงทุนด้านเทคโนโลยี 119
- 129. CHAPTER 24 เทคโนโลยีสำาหรับ Big Data: Storage และ Analytics เม่ือพูดถึง Big Data หลายๆคนก็คงเร่ิมเข้าใจความหมายของ 3Vs (Volume, Velocity, Variety) และเร่ิมท่ีจะเห็นภาพว่าข้อมูลจะมีขนาดใหญ่ ข้ึนและมีหลากหลายรูปแบบ ดังน้ันจึงไม่แปลกใจท่ีหลายองค์กรจำาเป็นต้อง ปรับ Information Infrastructure เพ่ือให้รองรับกับการบริหารจัดการ Big Data ได้ เทคโนโลยีฐานข้อมูลเดิมท่ีเป็น RDBMS และภาษา SQL ก็ยังคงอยู่แต่ การท่ีจะนำามาใช้ในการเก็บข้อมูลขนาดใหญ่มากๆเป็นหลายร้อย TeraByte หรือนับเป็น PetaByte อาจไม่สามารถทำาได้และอาจมีต้นทุนท่ี สูงเกินไป และย่ิงถ้าข้อมูลเป็นแบบ Unstructure ก็คงไม่สามารถจะเก็บ ได้ นอกจากน้ีการจะประมวลผลข้อมูลหลายร้อยล้านเรคอร์ดโดยใช้ เทคโนโลยี RDBMS ผ่านภาษา SQL ก็อาจใช้เวลานานและบางคร้ังอาจไม่ สามารถประมวลผลได้
- 130. รูปท่ี 1 ตัวอย่างของ Big Data Technology ด้วยเหตุน้ีจึงเร่ิมมีการคิดถึงเทคโนโลยีอ่ืนๆในเก็บและประมวลผลข้อมูล ท่ีเป็น Big Data ดังท่ีได้แสดงตัวอย่างในรูปท่ี 1 ซ่ึงหากเราแบ่งเทคโนโลยี เป็นสองด้านคือ การเก็บข้อมูล (Storage) และการประมวลผล/วิเคราะห์ ข้อมูล (Process/Analytics) เราอาจสามารถจำาแนกเทคโนโลยีต่างๆได้ ดังน้ี เทคโนโลยีกำรเก็บข้อมูล ข้อมูลท่ีเป็น Big Data อาจจะมีขนาดใหญ่เกินกว่าท่ีเทคโนโลยีการเก็บ ข้อมูลแบบเดิมท่ีเรามีอยู่เก็บได้หรืออาจเจอปัญหาในแง่โครงสร้างของ ข้อมูลท่ีอาจไม่เหมาะกับเทตโนโลยี RDBMS ตัวอย่างเช่น Telecom operator อาจต้องการเก็บข้อมูล Call Detail Records (CDR) ท่ีอาจมี ปริมาณสูงถึง 1 TeraByte ต่อวันเป็นระยะเวลายาวนานข้ึน หรือเราอาจ ต้องเก็บข้อมูลในอีเมลจำานวนมากท่ีเป็นรูปแบบของ Text File หรือเก็บ ภาพจากกล้อง CCTV จำานวนหลายสิบ TB หรืออาจต้องการเก็บข้อมูลจาก Facebook ซ่ึงข้อมูลต่างๆเหล่าน้ีท่ีกล่าวมา อาจไม่เหมาะกับเทคโนโลยี ฐานข้อมูลแบบเดิม RDBMS ท่ีเป็น Vertical Scaling จากท่ีกล่าวมาจ่ึงได้มีการนำาเทคโนโลยีต่างๆเข้ามาเพ่ือท่ีจะให้เก็บข้อมูล ได้มากข้ึน โดยมีเทคโนโลยีต่างๆอาทิเช่น 122 THANACHART
- 131. • ฐำนข้อมูล RDBMS แบบเดิม ก็ยังเป็นเทคโนโลยีท่ีเหมาะสมท่ีสุดใน การเก็บข้อมูลแบบ Structure แต่ถ้าข้อมูลมีขนาดใหญ่มากก็จะเจอ ปัญหาเร่ืองต้นทุนท่ีสูง และหากข้อมูลมีจำานวนเป็น PetaByte ก็คงยาก ท่ีจะเก็บ ถึงแม้ในปัจจุบันจะมี MPP Datanbase อย่าง Oracle ExaDta หรือ SAP HANA แต่ราคาก็สุงมาก • Hadoop HDFS เป็นเทคโนโลยีท่ีมีการคาดการณ์ว่าหน่วยงานส่วน ใหญ่จะต้องใช้ในอนาคต เพราะมีความต้องการเก็บข้อมูลขนาดใหญ่ท้ังท่ี เป็น Unstrucure Data หรือนำาข้อมูลท่ีเป็น structure มาเก็บไว้ โดย สามารถจะเก็บข้อมูลได้เป็น PetaByte ท้ังน้ีข้ึนอยู่กับจำานวนเคร่ืองท่ีมี อยู่ในลักษณะ scale-out ข้อสำาคัญ Hadoop มีต้นทุนท่ีค่อนข้างต่ำาเม่ือ เทียบกับเทคโนโลยีการเก็บข้อมูลแบบอ่ืน ดังแสดงในรูปท่ี 2 • NoSQL เป็นเทคโนโลยีท่ีต้องการเก็บข้อมูลจำานวนมากกว่าของ RDBMS ในลักษณะ scale-out เป็นจำานวนหลาย TeraByte แต่อาจไม่ ได้เน้นเร่ือง Consistency หรือ ACID ของข้อมูลมากนัก เหมาะกับ Application บางประเภท ท้ังน้ีเราสามารถจะแบ่งเทคโนโลยี NoSQL ออกไปได้ส่ีกลุ่มคือ Column Oriented, Document Oriented, Key- Value และ Graph • Cloud Storage ข้อมูลขนาดใหญ่ขององค์กรบางส่วนอาจต้องเก็บไว้ใน Public Cloud Storage เช่น Amazon S3 โดยเฉพาะข้อมูลภายนอก อาทิเช่น Social Media Data หรือข้อมูลท่ีเป็น Archiving ท่ีไม่ได้มี ความสำาคัญมาก เพราะ Cloud Storage จะมีราคาในการเก็บท่ีถูกสุด และสามารถท่ีจะเก็บได้โดยมีขนาดไม่จำากัด แต่ข้อเสียคือเร่ืองความ ปลอดภัยและความเร็วในการถ่ายโอนข้อมูล เทคโนโลยีสำาหรับ BIG DATA: STORAGE และ ANALYTICS 123
- 132. รูปท่ี 2 เปรียบเทียบราคาของ Storage Technology เทคโนโลยีกำรประมวลผลข้อมูล การประมวลผลข้อมูลท่ีเป็น Big Data จะมีท้ังการวิเคราะห์ข้อมูลท่ีเป็น business intelligence (BI) เพ่ือท่ีจะดึงข้อมูลมานำาเสนอ หรือการทำา Predictive Analytics โดยใช้หลักการของ Data Science ความยากของ การประมวลผลคือต้องการความเร็วในการประมวลผลข้อมูลท่ีนอกจากมี ขนาดใหญ่แล้วบางคร้ังยังเป็นข้อมูลท่ีไม่มีโครงสร้าง ดังน้ันต้องจึงมีการนำา เทคโนโลยีหรือภาษาต่างๆมาเพ่ือให้สามารถประมวลผลข้อมูลได้ ซ่ึงในบาง คร้ังหน่วยงานอาจต้องพิจารณาต้องเลือกใช้ อาทิเช่น • SQL ก็เป็นภาษาท่ียังต้องใช้ในการประมวลผลข้อมูลโดยเฉพาะ Structure Data ท่ีเก็บอยู่ใน RDBMS และสามารถประมวลผลแบบ RealTime ได้ • APIs ข้อมูลท่ีเก็บอยู่ใน Storage ต่างๆท่ีกล่าวมาข้างต้นเช่น NoSQL หรือ Cloud Storage อาจต้องพัฒนาโปรแกรมด้วยภาษาคอมพิวเตอร์ ต่างๆ ในการประมวลผลข้อมูลโดยใช้ APIs ในการเข้าถึงข้อมูล • MapReduce เป็นเทคโนโลยีท่ีพัฒนาโดย Google ในการประมวลผล ข้อมูลท่ีอยู่ใน HDFS โดยใช้ภาษาคอมพิวเตอร์อย่าง Java ในการพัฒนา 124 THANACHART
- 133. โปรแกรม โดยจะประมวลผลแบบ Batch และเป็นวิธีการประมวลผลท่ีมา กับเทคโนโลยี Hadoop • Hive หรือ Pig เป็นภาษาคล้าย SQL หรือ Scripting ท่ีทำาให้เรา สามารถประมวลผลข้อมูลท่ีอยู่ใน Hadoop HDFS ได้โดยไม่ต้องพัฒนา โปรแกรม MapReduce แต่ท้ังน้ีข้อมูลจะต้องอยู่ในรูปแบบท่ีเหมาะสม เช่น ไฟล์ csv หรือ ไฟล์ข้อความบางประเภท • Impala เป็นภาษาคล้าย SQL ท่ีทำาให้เราสามารถประมวลผลข้อมูลท่ี อยู่ใน Hadoop HDFS ได้ โดยทำางานได้รวดเร็วกว่า Hive มาก แต่มีข้อ เสียคือเป็นภาษาท่ีเป็น proprietary ของ Cloudera • Spark เป็นเทคโนโลยีท่ีสามารถประมวลผลข้อมูลขนาดใหญ่แบบ Real- time โดยอาจมี Data Source มาจากหลากหลายแหล่งเช่น RDBMS, Cloud Storage, NoSQL หรือ Hadoop ซ่ึงสามารถเขียนโปรแกรม โดยใช้ภาษา Scala, Java, Python หรือจะเขียนโดยใช้ภาษาคล้าย SQL ก็ได้ และมี Library สำาหรับการทำา Data Science คือ MLib เป็น เทคโนโลยีท่ีน่าสนใจมากอันหน่ึง • ภำษำและเทคโนโลยีในกำรทำำ Machine Learning ซ่ึงก็จะมี หลากหลายท้ัง R Hadoop, Mahout, Azure Machine Learning หรือ AWS ML • เทคโนโลยีสำำหรับกำรทำำ Data Visualisation และ BI อาทิเช่น Tableau, Pentaho, SaS, Excel และอ่ืนๆ จากท่ีกล่าวมาท้ังหมดน้ี ถ้าหน่วยงานจะมีโครงการ Big Data และข้อมูลมี ขนาดใหญ่จริง เราคงต้องเลือกหาเทคโนโลยีท่ีเหมาะสมมาใช้งาน ธนชำติ นุ่มนนท์ IMC Institute สิงหาคม 2558 เทคโนโลยีสำาหรับ BIG DATA: STORAGE และ ANALYTICS 125
- 135. CHAPTER 25 Azure HDInsight หน่ึงในกลยุทธ์ท่ี เปล่ียนไปของ Microsoft (มี Link เอกสารการอบรม) วันก่อนมีโอกาสไปจัดอบรม Big Data using Azure HDinsight ท่ี ออฟฟิศของ Microsoft มีคนเข้ามาร่วมอบรมจำานวน 50กว่าคน ทำาให้มี โอกาสคิดได้ว่าถ้าเป็นสมัยก่อนคงยากท่ีผมจะสอนเทคโนโลยีของ Microsoft โดยเฉพาะมาท่ีออฟฟิศของเขาเลย เพราะผมสอนและใช้ เทคโนโลยีตรงข้ามกับMicrosoft มาตลอด • ผมเขียนโปรแกรมและสอน Java Technology • ผมเป็น Certied Java instructor • ผมใช้เทคโนโลยีฝ่ัง Server ท่ีเป็น Linux, MySQL database และ Java App/Web Server • ผมใช้เคร่ือง Mac ใช้ ipad และเลือกใช้ smartphone ท่ีเป็น Android • ผมทำาเอกสารต่างๆโดยใช้ OpenO^ce ใช้ Gmail, Google Docs แม้ ว่าจะซ้ือ account ของO^ce 365 แต่ก็ใช้ยามจำาเป็น แต่วันน้ีกลยุทธ์ของ Microsoft มาท่ี Mobile กับ Cloud ทำาให้ผมต้องเข้า
- 136. มาใช้ Microsoft Azure ท่ีเป็นระบบ Cloud ของ Microsoft ซ่ึงมีท้ัง IaaS และ PaaS การใช้ IaaS โดยมากก็เป็นการใช้ Virtual Server ท่ีเป็น Ubuntu Linux ในการติดต้ัง Hadoop Clusterสำาหรับ PaaS ท่ีน่าสนใจก็ มี HDinsight ซ่ึงเป็น Hadoop as a Service ซ่ึงเหมาะกับการใช้ Hadoop Cluster ในช่วงระยะเวลาส้ันๆ เพราะเป็นระบบท่ีติดต้ังโดยอัตโนมัติและ เป็น Hadoop Distribution ของ Microsoft ท่ีพัฒนาบน Hortonworks เพ่ือให้สามารถเช่ือม HDFS กับ Azure Blob บริการ PaaS อีกอันของ azure ทีน่าสนใจคือ Machine Learning ซ่ึง จัดเป็น Analytics as a Service ท่ีผู้ใช้สามารถจะเข้ามาทำาการวิเคราะห์ ข้อมูลโดยใช้ Machine Learning Algorithm ต่างๆอาทิเช่น Linear Regression, K-Mean หรือ Recommendation สำาหรับข้อมูลขนาดใหญ่ โดยมี ML Studio ท่ีผู้ใช้งานสามารถใช้งานโดยง่านได้ สำาหรับการอบรมท่ีผมไปสอนผมใช้ HDInsight บน Linux จะเห็นได้ว่าวัน น้ี Microsoft เป็นระบบท่ีมีหลากหลาย Platform แม้แต่ HDInsight ก็ สามารถท่ีจะพัฒนาโปรแกรม MapReduce ด้วยภาษา Java ผู้ท่ีต้องการ เรียนรู้การพัฒนาโปรแกรม Big Data ผมแนะนำาท่ีจะให้ใช้ Azure HDInsight เพราะจะได้ไม่ต้องไปวุ่นวายในการติดต้ัง Hadoop Cluster และ Microsoft เองก็มี Azure Free Trial ให้ใช้ สำาหรับการใช้งานจริง 128 THANACHART
- 137. HDInsight เหมาะสำาหรับการทำางานเพียงระยะส้ันสำาหรับผู้ท่ีต้องการหา Cluster ใหญ่ๆมาประมวลผล เพราะหลักการ HDInsight คือจะสร้างแล้ว ปิดระบบไม่ได้ นอกจากจะ Terminate ท้ิง แต่ถ้าต้องการต้ัง Hadoop Cluster ไว้ระยะยาวบนคราว ผมอยากจะแนะนำาให้ติดต้ัง Hadoop Distribution บน Vitual Server จะประหยัดกว่าเพราะสามารถเปิดปิด Server โดยไม่ต้อง Terminate เคร่ืองได้ สำาหรับ Slide ประกอบการบรรยายคร้ังน้ีผมมีสองชุด – ชุดแรกเป็น Big Data using Azure HDInsight โดยสามารถ Download Slide ได้ท่ี >> http://tinyurl.com/oco4z8n – ชุดท่ีสองเป็นแบบฝึกหัด Azure HDInsight Workshop โดยสามารถ Download Slide ได้ท่ี >> http://tinyurl.com/obv34og ซ่ึงการอบรมน้ีจะครอบคลุมเน้ือหา การติดต้ัง HDInsight, แนะนำา MapReduce, การใช้โปรแกรม Hive, การใช้โปรแกรมPig และการ Import ข้อมูลจากฐานข้อมูล RDBMS โดยใช้ Sqoop นอกจาก Slide ชุดน้ีเราสามารถศึกษาการใช้ HDInsight ได้เพ่ิมเติม จาก Tutorial ของMicrosoft Azure ได้ท่ี >> http://azure.microsoft.com/en-us/documentation/services/ hdinsight/ ผมเองยังได้เขียน Slide ท่ีเป็นแบบฝึกหัดสำาหรับการใช้ Azure Machine Learning โดยมีแบบฝึกหัดทดลองทำา ML 4 เร่ืองคือ • Classication เพ่ือคาดการณ์ราคารถยนต์โดยใช้ Linear Regression Algorithm • Clustering เพ่ือแบ่งกลุ่มประเทศตามการบริโภคอาหารโดยใช้ K- Mean Algorithm • Recommendation แนะนำาร้านอาหารจากข้อมูลในอดีต และ • Classication เพ่ือคาดการณ์ว่าเท่ียวบินท่ีมาถึงล่าช้าหรือไม่โดยใช้ Decision Tree Algorithm โดยสามารถ Download Slide ได้ท่ี >> http://tinyurl.com/pkjonbn สุดท้ายน้ีทาง IMC Institute เองจะเปิดสอนหลักสูตร Azure โดยไม่มี ค่าใช้จ่ายอีกคร้ังในวันท่ี 30 ตุลาคม โดยงานน้ีได้รับการสนับสนุนจาก Microsoft เช่นเคย AZURE HDINSIGHT หน่ึงในกลยุทธ์ท่ีเปล่ียนไปของ MICROSOFT (มี LINK เอกสารการอบรม) 129
- 138. ธนชาติ นุ่มนนท์ IMC Institute กันยายน 2558 130 THANACHART
- 139. CHAPTER 26 Big Data Technology ต่างๆ: Storage และ Analytics เม่ือพูดถึง Big Data หลายๆคนก็คงเร่ิมเข้าใจความหมายของ 3Vs (Volume, Velocity, Variety) และเร่ิมท่ีจะเห็นภาพว่าข้อมูลจะมีขนาดใหญ่ ข้ึนและมีหลากหลายรูปแบบ ดังน้ันจึงไม่แปลกใจท่ีหลายองค์กรจำาเป็นต้อง ปรับ Information Infrastructure เพ่ือให้รองรับกับการบริหารจัดการ Big Data ได้ เทคโนโลยีฐานข้อมูลเดิมท่ีเป็น RDBMS และภาษา SQL ก็ยังคงอยู่แต่ การท่ีจะนำามาใช้ในการเก็บข้อมูลขนาดใหญ่มากๆเป็นหลายร้อย TeraByte หรือนับเป็น PetaByte อาจไม่สามารถทำาได้และอาจมีต้นทุนท่ี สูงเกินไป และย่ิงถ้าข้อมูลเป็นแบบ Unstructure ก็คงไม่สามารถจะเก็บ ได้ นอกจากน้ีการจะประมวลผลข้อมูลหลายร้อยล้านเรคอร์ดโดยใช้ เทคโนโลยี RDBMS ผ่านภาษา SQL ก็อาจใช้เวลานานและบางคร้ังอาจไม่ สามารถประมวลผลได้ ด้วยเหตุน้ีจึงเร่ิมมีการคิดถึงเทคโนโลยีอ่ืนๆในเก็บและประมวลผลข้อมูล ท่ีเป็น Big Data ดังท่ีได้แสดงตัวอย่างในรูปท่ี 1 ซ่ึงหากเราแบ่งเทคโนโลยี เป็นสองด้านคือ การเก็บข้อมูล (Storage) และการประมวลผล/วิเคราะห์ ข้อมูล (Process/Analytics) เราอาจสามารถจำาแนกเทคโนโลยีต่างๆได้ ดังน้ี เทคโนโลยีการเก็บข้อมูล Big Data
- 140. • ฐำนข้อมูล RDBMS แบบเดิม ก็ยังเป็นเทคโนโลยีท่ีเหมาะสมท่ีสุดใน การเก็บข้อมูลแบบ Structure แต่ถ้าข้อมูลมีขนาดใหญ่มากก็จะเจอ ปัญหาเร่ืองต้นทุนท่ีสูง และหากข้อมูลมีจำานวนเป็น PetaByte ก็คงยาก ท่ีจะเก็บ ถึงแม้ในปัจจุบันจะมี MPP Datanbase อย่าง Oracle ExaDta หรือ SAP HANA แต่ราคาก็สุงมาก • NoSQL Database เป็นเทคโนโลยีท่ีเก็บข้อมูลได้ขนาดมากกว่า RDBMS แต่ก็มีข้อจำากัดในเร่ืองรูปแบบของข้อมูลท่ีเก็บ และก็เหมาะกับ Application ในบางประเภท แต่ในอนาคตองค์กรก็คงจะมีข้อมูลจำานวน มากเก็บไว้เทคโนโลยี NoSQL แบบน้ีอาทิเช่น Cassandra, MongoDB, HBase หรือ Elasticsearch เป็นต้น • Cloud Storage ข้อมูลขนาดใหญ่ขององค์กรบางส่วนอาจต้องเก็บไว้ใน Public Cloud Storage เช่น Amazon S3 โดยเฉพาะข้อมูลภายนอก อาทิเช่น Social Media Data หรือข้อมูลท่ีเป็น Archiving ท่ีไม่ได้มี ความสำาคัญมาก เพราะ Cloud Storage จะมีราคาในการเก็บท่ีถูกสุด และสามารถท่ีจะเก็บได้โดยมีขนาดไม่จำากัด แต่ข้อเสียคือเร่ืองความ ปลอดภัยและความเร็วในการถ่ายโอนข้อมูล • Hadoop HDFS เทคโนโลยี Hadoop จะมี Storage ท่ีเรียกว่า HDFS และสามารถขยายขนาดการเก็บข้อมูลเป็น PetaByte เหมาะสำาหรับการ เก็บข้อมูลแบบ Unstrusture ข้อสำาคัญมีต้นทุนท่ีค่อนข้างต่ำาเม่ือเทียบ กับเทคโนโลยีการเก็บข้อมูลแบบอ่ืน ดังแสดงในรูปท่ี 2 สำาหรับการประมวลผลและวิเคราะห์ข้อมูลท่ีเป็น Big Data • SQL ก็เป็นภาษาท่ียังต้องใช้ในการประมวลผลข้อมูลโดยเฉพาะ Structure Data ท่ีเก็บอยู่ใน RDBMS และสามารถประมวลผลแบบ RealTime ได้ • APIs ข้อมูลท่ีเก็บอยู่ใน Storage ต่างๆท่ีกล่าวมาข้างต้นเช่น NoSQL หรือ Cloud Storage อาจต้องพัฒนาโปรแกรมด้วยภาษาคอมพิวเตอร์ ต่างๆอาทิเช่น Python หรือ Java ในการประมวลผลข้อมูลโดยใช้ APIs ในการเข้าถึงข้อมูล • MapReduce การประมวลผลข้อมูลท่ีอยู่ใน Hadoop HDFS สามารถ 132 THANACHART
- 141. ทำาได้โดยใช้ MapReduce ท่ีอาจพัฒนาด้วยภาษาต่างๆอาทิเช่น Python หรือ Java แต่การประมวลผลจะต้องเป็นแบบ Batch • Hive หรือ Pig เป็นภาษาคล้าย SQL หรือ Scripting ท่ีทำาให้เรา สามารถประมวลผลข้อมูลท่ีอยู่ใน Hadoop HDFS ได้โดยไม่ต้องพัฒนา โปรแกรม MapReduce แต่ท้ังน้ีข้อมูลจะต้องอยู่ในรูปแบบท่ีเหมาะสม เช่น ไฟล์ csv หรือ ไฟล์ข้อความบางประเภท • Impala เป็นภาษาคล้าย SQL ท่ีทำาให้เราสามารถประมวลผลข้อมูลท่ี อยู่ใน Hadoop HDFS ได้ โดยทำางานได้รวดเร็วกว่า Hive มาก แต่มีข้อ เสียคือเป็นภาษาท่ีเป็น proprietary ของ Cloudera • Spark เป็นเทคโนโลยีประมวลผลแบบ Realtime ท่ีทำาให้เราสามารถ ประมวลผลข้อมูลท่ีอยู่ใน storage ต่างๆท้ัง Cloud Storage หรือ Hadoop HDFS ท้ังน้ี Spark มีแนวโน้มท่ีจะนำามาแทนท่ี MapReduce เพราะมีความรวดเร็วกว่า ซ่ึงการใช้ Spark อาจต้องพัฒนาโปรแกรม ภาษา Python, Scala หรือ Java เช่นเดียวกับ MapReduce แต่หาก ต้องการใช้ภาษาคล้าย SQL ก็มี Spark SQL ท่ีช่วยให้เราประมวลผล ข้อมูลโดยใช้คำาส่ังแบบ SQL ได้ • Mahout, RHadoop หรือ MLib คือภาษาหรือ APIsท่ีช่วยในการทำา Predictive Analytics ข้อมูล Big Data โดยใช้ Machine Algorithm • BIG DATA TECHNOLOGY ต่างๆ: STORAGE และ ANALYTICS 133
- 143. CHAPTER 27 Hadoop Application Architecture วันน้ีมางาน Strata + Hadoop World ท่ีสิงคโปร์วันแรกซ่ึงเป็นวัน Tutorial ผมเลือกท่ีจะเข้าสอง session คือ Hadoop Application Architectures ในตอนเช้าและ Apache Hadoop Operations for production systems ในตอนบ่าย Session แรกน่าสนใจมากเพราะผู้บรรยายท้ังส่ีท่านคือคนเขียนหนังสือ เร่ือง Hadoop Application Architectures และได้แนะนำาสถาปัตยกรรม ของ Hadoop สำาหรับการวิเคราะห์ข้อมูล Network Fraud แบบ Near Real Time ดังรูปท่ี 1
- 144. รูปท่ี 1: Architecture สำาหรับ Fraud Detection จาก Architecture น้ีมีประเด็นท่ีน่าสนใจคือ Storage: เลือกใช้ HDFS สำาหรับเก็บข้อมูลท่ีดึงมาจาก Network และ ต้องการประมวลผลแบบ Batch และเลือก HBase สำาหรับการเก็บ Proile ของ Network ท่ีต้องการอ่านและเขียนอย่างรวดเร็ว นอกจากน้ียังมีการ พูดถึง Kudu ว่าน่าจะเป็นเทคโนโลยีใหม่ท่ีอาจเหมาะกับการเก็บข้อมูลท่ี Google ค้นคิดข้ึนมาท่ีผสมระหว่าง HDFS และ HBase ดังรูปท่ี 2 รูปท่ี 2 Kudu Ingestion: มี Work]ow ในการดึงข้อมูลจาก Network Devices ดัง รูป โดยข้ันตอนแรกดึงข้อมูลมาเก็บใน Queue โดยใช้ Kafka และใช้ Flume ทำาหน้าท่ีเป็น Event Handler จัดการเลือกเฉพาะข้อมูลท่ีน่าสงสัย รูปท่ี 3 Ingestion WorkFow Processing: ในการประมวลผลข้อมูลมีได้หลายวิธีดังรูปท่ี 4 แต่ในใน กรณีของ Streaming เลือกใช้ Spark Streaming ส่วนกรณีของ Batch Processing เลือกใช้ Spark สำาหรับการทำา Machine Learning, Impala 136 THANACHART
- 145. สำาหรับการทำารายงาน และ MapReduce ดังรูปท่ี 5 โดยทีมงานก็ พยายามเน้นให้เห็นว่า MapReduce กำาลังถูกแทนท่ีด้วย Spark และ Hive กำาลังถูกแทนท่ีด้วย Impala รูปท่ี 4 การประมวลผลข้อมูลใน Hadoop ด้วยวิธีต่างๆ รูปท่ี 5 Processing สำาหรับกรณีศึกษาน้ี สรุปส่ิงท่ีได้จาก Session น้ีคือเห็นการเก็บข้อมูลท่ีต้องผสมผสานท้ัง HDFS และ HBase การดึงข้อมูลคงต้องพิจารณาเร่ืองของ KafKa และการ ประมวลผลควรเน้นเร่ืองของ Spark และ Impala HADOOP APPLICATION ARCHITECTURE 137
- 146. ธนชาติ นุ่มนนท์ IMC Institute ธันวาคม 2558 138 THANACHART
- 147. CHAPTER 28 การพัฒนาบุคลากรสำาหรับงานทาง ด้าน Big Data กระแสของBig Data กำาลังมาแรงหลายสถาบันการศึกษาต่างก็สนใจเปิด หลักสูตรด้านน้ี. แต่ขณะเดียวกันสถาบันหลายแห่งก็บังไม่ได้ให้ความ สำาคัญยังเน้นสอนแต่ Database, Data Structure ในรูปแบบเดิมๆ ท้ังๆท่ี โดยแท้จริงแล้วสถาบันการศึกษามีหน้าท่ีจะต้องสอนคนให้ออกไปทำางานใน อนาคต สอนให้คิดเป็นทำาเป็นและเรียนรู้เพ่ืออยู่กับอนาคตทำางานใน 10 ปี ข้างหน้า ไม่ใช่แค่สอนเทคโนโลยีปัจจุบันหรือส่ิงท่ีอาจารย์เรียนรู้มาเม่ือ 10-20 ปีโดยไม่ได้เพ่ิมเน้ือหาท่ีเป็นองค์ความรู้หรือเทคโนโลยีใหม่ๆแล้ว อ้างแค่เพียงว่า นักศึกษาต้องมีความรู้พ้ืนฐาน ท้ังๆท่ีวันน้ีความรู้พ้ืนฐาน ด้านเทคโนโลยีไอทีหลายอย่างก็เปล่ียนไป โดยเฉพาะในช่วง 4-5 ปีท่ีผ่าน มา ซ่ึงในอีก 10 ปีข้างหน้าจะย่ิงเปล่ียนไปกว่าน้ีอีกมาก ถ้าเราไม่สร้างคน เพ่ืออนาคตเราจะแข่งกับเขาได้อย่างไร แม้หลายแห่งพยายามจะสอนหลักสูตร Big Data แต่ก็พยายามจะเปิดสอน ระดับปริญญาโทข้ึนไปเน้นเร่ืองData Science หรือ Machine Learning ค่อนข้างมากเพราะอาจผูกกับงานวิจัยอาจารย์ และหลายๆแห่งมอง หลักสูตร Big Data ค่อนข้างสับสนไปหมดท้ังๆท่ีเราควรจะเน้นสอนเร่ืองน้ี ต้ังแต่ปริญญาตรี และควรมองอนาคตว่า Big Data คือส่ิงจำาเป็น และเรา ต้องพัฒนาคนไอทีเราให้ถูกทักษะรงต่ออาชีพท่ีจะต้องทำา
- 148. งานด้าน Big Data ไม่ใช่มีแค่ Data Scientist เรียน Big Data ไม่ใช่แค่ เน้นเรียน Machine Learning และ Learning Path ทางด้านน้ีมี หลากหลายมาก เราจึงต้องวางแผนก่อนว่าเราจะพัฒนาคนประเภทไหน ออกมา ซ่ึงอุตสาหกรรมต้องการคนมาทำางานด้าน Big Data ในอนาคต จำานวนมาก แต่จะมีบทบาทหน้าท่ีหลากหลาย ดังน้ันทุกภาคส่วนก็คงต้องช่วยกันเตรียมคนเพ่ือรองรับการเปล่ียนแปลงใน อนาคต หากจะพิจารณางานด้าน Big Data ในอนาคตเราคงสร้างคน ท่ีมีหน้าท่ีท่ี หลากหลาย คนแต่ละคนมีทักษะไม่เหมือนกัน เราไม่สามารถสร้างคนทุกคน เป็น Data Scientist ได้ ทำานองเดียวกันคนท่ีเป็น Data Scientist ก็อาจ ไม่เก่งท่ีจะเป็น Data Engineer มาติดต้ังระบบ หรืออาจไม่เก่งทำา Visualization ท่ีอาจต้องคนมีความสามารถในการทำา Infographics หรือ Dashborad ให้คนเข้าใจได้โดยง่าย ถ้าเราจะแบ่งคนทางด้านน้ีในอนาคตเราอาจแบ่งคนตามสายอาชีพดังน้ี เพ่ือให้อุตสาหกรรมมาเร่งช่วยกันพัฒนาคนออกมา 1) Data Engineer คนกลุ่มน้ีจะทำาหน้าท่ีติดต้ังและดูแลระบบข้อมูลต่างๆ ต้องมีทักษะด้าน System Administration เข้าใจการติดต้ังและดูแลระบบ อย่าง Database, Hadoop Cluster, NoSQL หรือสามารถออกแบบ Data Architecture ต่างๆ 2) Data Developer มีหน้าท่ีในการพัฒนาโปรแกรมท่ีนำาข้อมูลมา วิเคราะห์ โดยต้องเรียนรู้ทักษะในการเขียนโปรแกรมภาษาต่างๆท้ัง Java, Python หรือSQL เพ่ือจะใช้เทคโนโลยีอย่าง Spark, Hive, Impala ฯลฯ 3) Data Analyst คนกลุ่มน้ีจะมีความรู้ในการท่ีจะนำาข้อมูลมาวิเคราะห์ มี 140 THANACHART
- 149. ความเข้าใจเร่ือง Business a intelligence เข้าใจ Business Domain และมีความรู้ด้านสถิติดี 4) Data Visualizer คนกลุ่มน้ีจะมีความสามารถในการนำาข้อมูลมาแสดง ผลเพ่ือให้ผู้คนเข้าใจ.สามารถทำา Dashboard หรือ Infographics ได้ สวยงามและเข้าใจง่าย 5) Data Scientist คือคนท่ีจะนำาข้อมูลมาวิเคราะห์ท่ีอาจเป็น Predictive Analytics คนกลุ่มน้ีต้องเก่งคณิตศาสตร์เรียนรู้ Machine Learning เข้าใจ Algorithm ต่างๆ จากท่ีกล่าวมาจะเห็นได้ว่าถ้าเราจะสร้างอนาคตของประเทศให้สามารถ แข่งขันได้ด้วย Big Data เราต้องการคนในทุกด้านและก็หน้าท่ีของทุกฝ่าย ท่ีต้องช่วยกัน สร้างคนเพ่ืออนาคต ธนชาติ นุ่มนนท์ IMC Institute ธันวาคม 2558 การพัฒนาบุคลากรสำาหรับงานทางด้าน BIG DATA 141
- 150. 142 THANACHART
- 151. CHAPTER 29 การประมวลผล Big Data ควรใช้ เทคโนโลยีไหนดี? องค์ประกอบท่ีสำาคัญท่ีสุดอีกอันหน่ึงการทำา Big Data คือการประมวล ผลข้อมูลจากแหล่งข้อมูลขนาดใหญ่ต่างๆ ท้ังน้ีการประมวลผลข้อมูลท่ีเก็บ อยู่สามารถแบ่งออกได้ 4 รูปแบบคือ • Interactive analysis • Batch analysis • Real time analysis • Machine Learning โดยควรจะมีเทคโนโลยีสองกลุ่มคือ การประมวลผลโดยใช้เทคโนโลยี Hadoop จากข้อมูลใน HDFS และการประมวลผลโดยใช้เทคโนโลยี Spark โดยอาจมีข้อมูลจากแหล่งต่างๆ กำรประมวลผลโดยใช้ Hadoop โดยปกติ Hadoop จะใช้เทคโนโลยีอย่าง MapReduce ในการประมวล ผลข้อมูลใน HDFS แต่ท้ังน้ีเน่ืองจาก MapReduce เป็นเทคโนโลยีท่ีทำางาน แบบ Batch และต้องพัฒนาโปรแกรมด้วยภาษาต่างๆ อาทิเช่น Java ใน การประมวลผล จึงทำาให้ MapReduce ได้รับความนิยมน้อยลงและมี
- 152. แนวโน้มว่าจะถูกแทนท่ีด้วยเทคโนโลยี Spark วันน้ีเราอาจไม่ต้องเน้นการ ประมวลผลผ่านบริการ MapReduce มากนักแต่ควรให้บริการเทคโนโลยี ประมวลสำาหรับ Hadoop ท่ีเป็นภาษาคล้าย SQL โดยแนะนำาให้บริการ เทคโนโลยีต่างๆ คือ Hive เป็นเทคโนโลยีท่ีใช้ภาษา Hive QL ลักษณะ SQL โดย Hive จะทำาหน้าท่ีในการแปล SQL like ให้มาเป็น MapReduce แล้วก็ทำาการรันแบบ Batch • Impala เป็นเคร่ืองมือท่ีคล้ายกับ Hive แต่เขียนด้วยภาษา C++ และ ติดต่อกับข้อมูล HDFS ตรงโดยไม่ต้องผ่าน MapReduce ซ่ึงจะทำางาน แบบ Interactive • Pig เป็นเคร่ืองมือคล้ายๆ กับ Hive ท่ีช่วยให้ประมวลผลข้อมูลโดยไม่ ต้องเขียนโปรแกรม Map/Reduce ซ่ึง Pig จะใช้โปรแกรมภาษา script ง่ายๆท่ีเรียกว่า Pig Latin แทน ท้ังน้ีจะทำางานแบบ Batch กำรประมวลผลโดยใช้ Spark Spark เป็นเทคโนโลยีในการประมวลข้อมูลขนาดใหญ่ โดยสามารถจะ ประมวลผลข้อมูลท้ังท่ีอยู่ใน HDFS หรือแหล่งอ่ืนๆ อาทิเช่น Cloud Storage, NoSQL, RDBMS ดังแสดงในรูปท่ี 1 ท้ังน้ี Spark สามารถ ทำางานแบบ Standalone หรือจะทำางานบน Hadoop Cluster ผ่าน YARN ก็ได้ โดยจะทำางานแบบ Interactive โดยมีการระบุว่า Spark สามารถประมวลผลบน Hadoop ได้เร็วกว่า MapReduce อย่างน้อย 10 เท่า ซ่ึง Spark มีบริการประมวลผลแบบต่างๆ ดังน้ี 144 THANACHART
- 153. รูปท่ี 1 ระบบประมวลผลของ Apache Spark • Spark core ก็คือระบบประมวลผลโดยผ่าน API ซ่ึงให้ผู้ใช้บริการ สามารถเลือกใช้ภาษา Java, Scala, Python หรือ R • Spark streaming สำาหรับการประมวลผลแบบ Realtime Streaming • Spark SQL สำาหรับการประมวลผลท่ีใช้ภาษาคล้ายกับ SQL • MLlib สำาหรับการประมวลท่ีเป็นแบบ Machine Learning ท้ังน้ีเราสามารถท่ีจะสรุปเปรียบเทียบเทคโนโลยีการประมวลผลข้อมูล ต่างๆ ได้ดังน้ี การประมวลผล BIG DATA ควรใช้เทคโนโลยีไหนดี? 145
- 154. ธนชาติ นุ่มนนท์ IMC Institute กุมภาพันธ์ 2559 146 THANACHART
- 155. CHAPTER 30 Hadoop Distribution ต่างๆ สำาหรับการทดลองใช้งาน เทคโนโลยีด้าน Big Data โดยเฉพาะ Hadoop เป็นเร่ืองท่ีคนให้ความ สนใจอย่างมาก และเร่ิมมีการคาดการณ์กันว่าในอนาคตองค์กรต่างๆแทบ ทุกแห่งก็จะต้องมีการใช้งานระบบ Hadoop ในต่างประเทศให้ความสำาคัญ กับการอบรมด้านน้ีมาก ซ่ึงทางผมเองภายใต้สถาบันไอเอ็มซีก็ได้จัดการ อบรมเทคโนโลยีให้กับผู้เข้าอบรมจำานวนมากในรอบสามปีท่ีผ่านมาโดยมี จำานวนมากหน่ึงพันคน และสามารถท่ีจะ Download Slide การอบรมด้าน น้ีของทางสถาบันได้ท่ี www.slideshare.net/imcinstitute
- 156. ประเด็นสำาคัญเร่ืองหน่ึงท่ีมักจะถูกถามจากผู้เข้าอบรมว่า เราสามารถท่ีจะ หา Hadoop Cluster จากไหนมาทดลองเล่น จริงๆเราสามารถจะฝึกใช้ Hadoop ได้โดยติดต้ังระบบต่างๆดังน้ี 1) กำรใช้ Hadoop Sandbox Distribution หลายรายเช่น Cloudera, Hortonworks หรือ MapR จะ มี Hadoop Sandbox ให้เราทำาลองใช้งานได้ แต่ระบบน้ีจะเป็นเคร่ืองเพียง เคร่ืองเดียวท่ีมี Image ให้เรารันผ่าน Virtual Box, VMWare หรือ KVM โดยเราอาจต้อง Download Image ขนาดใหญ่ประมาณ 4-6 GByte ลง มาเก็บไว้ก่อน ท้ังน้ีเราสามารถจะ Download Image ของ Hadoop Distribution ต่างๆได้ท่ีน้ี • Cloudera Quickstart • Hortonworks Sandbox • MapR Sandbox นอกจากน้ีล่าสุด Cloudera ยังสามารถรันผ่าน Docker โดยมีข้ันตอนการ ติดต้ัง Docker Image ดังน้ี >> การติดต้ัง Cloudera Quickstart บน Docker 2) กำรติดต้ัง Hadoop Cluster เอง เรายังสามารถท่ีจะติดต้ัง Apache Hadoop Cluster ได้เอง ซ่ึงวิธีน้ี 148 THANACHART
- 157. จะต่างกับการใช้ Sandbox เพราะสามารถใช้งานได้จรีง และผมเองได้เคย เขียนแบบฝึกหัดให้ทดลองติดต้ังในหลายๆระบบดังน้ี • การติดต้ังผ่าน Virtual Machine หรือ Local Server • การติดต้ังโดยใช้ Amazon EC2 • การติดต้ังโดยใช้ Virtual Server ของ Google Cloud Platform นอกจากน้ีผมยังมีแบบฝึกหัดให้ติดต้ัง Cloudera Cluster บน Amazon EC2 ซ่ึงจะมีข้ันตอนการติดต้ังดังน้ี >> แบบฝึกหัดติดต้ัง Cloudera Cluster 3) กำรใช้ Hadoop as a Service กรณีน้ีเป็นการใช้ Hadoop Service ท่ีอยู่บน Cloud แบบน้ีเหมาะท่ีจะ ใช้ในการประมวลผล แต่ไม่เหมาะจะใช้เก็ยข้อมูลบน HDFS เน่ืองจากระบบ Hadoop as a Service จะไม่สามารถ Stop ได้ และมีค่าใช้จ่ายต่อช่ัวโมง ค่อนข้างสูง จึงเหมาะกับใช้ในการประมวลผลข้อมูลขนาดใหญ่ท่ีอยู่ใน Cloud Storage หรือข้อมูลบนอินเตอร์เน็ตแบบช่ัวควาร ผมเองมีแบบฝึกหัดทีให้ทดลองใช้ Hadoop แบบน้ีสองระบบตือ • Hadoop as a Service on Microsoft Azure (HDInsight) • Hadoop as a Service on Amazon Web Services (EMR) ผมหวังว่าบทความส้ันๆท่ีเขียนมาน้ี คงเป็นจุดเร่ิมต้นให้ทุกท่านได้เร่ีมใช้ Hadoop ได้ วันน้ีไม่ใช่แค่มาศึกษาว่าอะไรคือ Hadoop แต่มันถึงเวลาท่ี ต้องลงมือปฎิบัตืแล้ว มิฉะน้ันเราคงก้าวตามเร่ือง Big Data ไม่ทัน ธนชาติ นุ่มนนท์ IMC Institute กุมภาพันธ์ 2559 HADOOP DISTRIBUTION ต่างๆสำาหรับการทดลองใช้งาน 149
- 159. CHAPTER 31 ความต้องการบุคลากรทางด้าน Big Data Big Data เป็นเร่ืองท่ีกล่าวขานกันอย่างมากในปัจจุบัน และอาจเป็น เทคโนโลยีไอทีเพียงไม่ก่ีอย่างท่ีกล่าวกันมากในวงการธุรกิจ กลุ่มผู้บริหาร เร่ิมเห็นความสำาคัญของการนำาข้อมูลขนาดใหญ่มาวิเคราะห์หรือคาดการณ์ แนวโน้มของธุรกิจ เร่ือง Big Data ยังเป็นเร่ืองใหม่ คนจำานวนมากย้งไม่ เข้าใจเร่ืองน้ีอย่างแท้จริง มันเหมือนศัพท์ข้ันเทพท่ีทุกคนอยากกล่าวถึงแต่ก็ ย้งไม่เข้าใจอย่างแท้จริง เร่ืองบุคลากรก็เป็นอีกเร่ือง บางหน่วยงานพอมีคำา ว่า Big Data ผู้บริหารก็เร่ิมบอกว่าต้องการ Data Scientist ท้ังๆท่ียังไม่รู้ ว่าจะกำาหนด Job Description ในองค์กรให้เขาอย่างไร หรือจำาเป็นแค่ไหน ท่ีเราต้องการบุคลากรด้านน้ีในองค์กร คำาถามท่ีมักจะเจอก็คือเราจะเร่ิมต้นทำา Big Data อย่างไร เราต้องการ บุคลากรอย่างไร ทักษะเปล่ียนไปจากเดิมมากน้อยอย่างไร เราต้องการ Data Scientist ในองค์กรเพ่ือทำา Big Data จริงหรือ? คำาถามเหล่าน้ีไม่ มีคำาตอบท่ีชัดเจน แต่มันก็ข้ึนอยู่กับระดับความต้องการใช้งาน Big Data ขององค์กร แต่ท่ีแน่ๆทักษะของบุคลากรในยุคใหม่ท่ีมีเทคโนโลยี Big Data จะเปล่ียนแปลงจากสมัยเดิมท่ีเร่ืองแต่เร่ืองของ RDBMS ในมุมมองของผม งานทางด้าน Big Data น่าจะแบ่งบุคลากรด้านต่างๆได้ดังน้ี • Chief Data OEcer ในอดีตเราอาจมีผู้บริหารสูงสุดด้านไอที แต่
- 160. แนวโน้มเราอาจต้องการผู้บริหารสูงสุดด้านข้อมูล ท่ีมีอำานาจในการดูแล ข้อมูลภายในและภายนอกองค์กร การนำาข้อมูลไปใช้งาน การบริหาร จัดการเทคโนโลยีสารสนเทศด้านข้อมูล การออกแบบสถาปัตยกรรม การดูแลเร่ืองคุณภาพข้อมูล และอาจรวมไปถึงทรัพย์สินทางปัญญาท่ีอาจ เกิดข้ึน จากข้อมูลหรืออัลกอริทึกจากการวิเคราะห์คาดการณ์ข้อมูล • Big Data Architect เทคโนโลยีด้านข้อมูลเปล่ียนไปจากเดิมมากท่ีแต่ ก่อนอาจพูดถึงแค่ RDBMS หรือ Data WareHouse แต่ในปัจจุบันทุก องค์กรจะต้องปรับโครงสร้างพ้ืนฐานด้านข้อมูลและอาจต้องนำา เทคโนโลยีใหม่เข้ามาใช้งานท้ัง Hadoop, NoSQL, Storage หรือ แม้ แต่ Cloud Service ซ่ึงเทคโนโลยีเหล่าน้ียังมีบริการหรือเทคโนโลยี เสริมต่างๆท่ีหลากหลาย อาทิเช่น Data Ingestion อย่าง KafKa, Sqoop หรือ Flume หรือเทคโนโลยีด้านประมวลผลเช่น Spark, Impala หรือเทคโนโลยีการทำา Visualisation ดังจะเห็นได้จากรูปท่ี 1 ท่ี แสดง Big Data Landscape ท่ีประกอบด้วยเทคโนโลยีต่างในปัจจุบัน ซ่ึงเราจำาเป็นต้องการ IT Architect ท่ีเข้าใจการออกแบบระบบท่ีรองรับ เทคโนโลยีหลากหลายเหล่าน้ีได้ • Big Data Engineer/Administrator งานอีกด้านหน่ึงท่ีจำาเป็นคือ คนท่ีมีความสามารถในการติดต้ังระบบ Big Data ต่างๆเช่น Hadoop, RDBMS, NoSQL รวมถึงการ Monitor และการทำา Performance Tuning ซ่ึงงานแบบน้ีอาจต้องการทักษะคนท่ีเข้าใจระบบปฎิบัติการ มี ความสามารถท่ีจะเป็นผู้ดูแลระบบเหมือน System Admin แต่ บุคลากรแต่ละรายอาจไม่สามารถดูแลทุกระบบได้เพราะแต่ละระบบ ต้องการทักษะท่ีต่างกัน • Big Data Developerในอดีตงานน้ีอาจหมายถึงคนท่ีจะมาช่วยพัฒนา SQL เพ่ือจะเรียกดูข้อมูลจาก DataBase แต่ปัจจุบันระบบประมวลผล ขนาดใหญ่ต้องการทักษะด้าน Programming มากข้ึนและมีเทคโนโลยี ท่ีหลากหลายมากข้ึนท้ัง MapReduce, Spark, Hive, Pig หรือ Impala แต่ละเทคโนโลยีก็ต้องการทักษะท่ีต่างกัน ดังน้ันก็มีแนวโน้มท่ีองค์กร ต้องการบุคลากรด้านน้ีจำานวนมากและแต่ละคนอาจทำางานใช้เทคโนโลยี คนละด้านกัน • Big Data Analyst หมายถึงนักวิเคราะห์ข้อมูลท่ีอาจรวมไปถึงการนำา ข้อมูลมาแสดงผล โดยใช้ Visualisation Tool ท่ีหลากหลาย โดยใน 152 THANACHART
- 161. ปัจจุบันอาจต้องดึงข้อมูลมาจาก Data Lake และใช้ Tool ใหม่ๆ บาง คร้ังบุคลากรด้านน้ีอาจไม่ได้เก่งด้านการพัฒนาโปรแกรมนัก แต่จะต้องรู้ ว่าจะวิเคราะห์ข้อมูลอะไร และมีทักษะในการผลท่ีได้มาแสดงให้คนท่ัวไป เข้าใจ คนกลุ่มน้ีควรมีพ้ืนฐานด้านสถิติและรู้ด้านธุรกิจ • Data Scientist ตำาแหน่งงานท่ีดูน่าสนใจท่ีสุดในปัจจุบัน แต่ก็ใช่ว่าทุก องค์กรต้องการ เพราะบุคลากรด้านน้ีจำาเป็นถ้าเราต้องการวิเคราะห์ ข้อมูลโดยเฉพาะในลักษณะ Predictive Analytics บุคลากรด้านน้ีต้อง รู้เร่ืองของ Algorithm อาจต้องเก่งด้านคณิตศาสตร์ เข้าใจเร่ือง Machine Learning และต้องมีความเข้าใจด้านธุรกิจท่ีต้องการ วิเคราะห์ โดยมากคนเก่งทางด้านน้ีน่าจะจบปริญญาโทหรือเอกด้านคณิต ศาตร์, Computer Science หรือ Computer Engineering มา รูปท่ี 1 Big Data Landscape 2016 จากท่ีกล่าวมาท้ังหมดจะเห็นว่า ในอนาคตองค์กรยังมีความต้องการ บุคลากรด้านน้ีท่ีหลากหลาย และยังมีความต้องการอีกจำานวนมาก ผมคิด ว่าถึงเวลาท่ีหน่วยงานต่างๆต้องมาวางแผนการพัฒนาบุคลากรด้านน้ีร่วม กัน เท่าท่ีทราบทาง สำานักงานการอุดมศึกษาก็มีการต้ังอนุกรรมการดู ความต้องการบุคลากรทางด้าน BIG DATA 153
- 162. หลักสูตรท่ัวประเทศเพ่ือพัฒนาคนทางด้านน้ี และได้ให้ผมเข้าร่วม แต่ก็ยัง ขับเคล่ือนกันช้าอยู่ ถึงเวลาท่ีเราคงต้องรีบเร่งแล้วครับ ธนชำติ นุ่มนนท์ IMC Institute กุมภาพันธ์ 2559 154 THANACHART
- 163. CHAPTER 32 Data Lake: Redefine Data WareHouse วันท่ี 3 มีนาคมน้ีทาง IMC Institute จะจัดฟรีสัมมนา Big Data User Group 1/2016 โดยคร้ังน้ีเป็น Theme เร่ือง Data Lake: Redene Data WareHouse ซ่ึงงานน้ีได้รับการสนับสนุนจาก Hitachi Data Systems และบริษัท Vintcom โดยมีสำานักงานรัฐบาลอิเล็กทรอนิกส์ (องค์กรมหาชน) หรือ EGA มาร่วมจัดงาน เม่ือถึงหลักการของการพัฒนาระบบข้อมูล ในอดีตเราก็จะนึกถึงการทำา DataBase ตามด้วยการทำา Data WareHouse จนบางคร้ังบางคนคิดไป ว่าเราต้องทำาโปรเจ็ค Data WareHouse เพ่ือท่ีจะจัดระเบียบข้อมูลใน หน่วยงาน ทำา Data Cleansing และ Data Governance ต่างๆก่อนท่ีจะ ทำาโครงการ Big Data ซ่ึงรูปแบบในการทำา Data WareHouse โดยมาก มักจะมีข้ันตอนต่างๆคือ • การออกแบบระบบจาก Top Down หรือ Bottom Up • กำาหนด Data Model • Extract Transform Load (ETL) • การทำา Data Governance • จัดหา BI Tool สำาหรับ Data WareHouse
- 164. • จัดทำารายงาน ข้ันตอนการทำา Data WareHouse จะเป็นรูปแบบเดิมท่ีเน้นข้อมูลท่ีเป็น Structure แล้วจึงทำาการดึงข้อมูลมาวิเคราะห์ (Structure -> Ingest -> Analyse) โดยจะต้องใช้ทรัพยากรท่ีมีความจุจำากัดและไม่มีความ หลากหลาย แต่ในโลกของ Big Data ข้อมูลจะมีความหลากหลาย จะมี จำานวนเข้ามามหาศาลและเพ่ิมข้ึนอย่างไม่จำากัด ดังน้ัน เราจำาเป็นจะต้อง เปล่ียนหลักการเป็น การดึงข้อมูลหลากหลายชนิดทำาการวิเคราะห์แล้วจึง ทำาการเก็บจ้อมูล (Ingest -> Analyse -> Structure) หลักการท่ีกล่าวใหม่ข้างต้นคือ Data Lake ซ่ึงเป็นเร่ืองใหม่ในโลกของ Big Data ท่ีใช้ในปัจจุบัน ซ่ึงจะประกอบไปด้วย Component ต่างๆดังรูป ท่ี 1 และเหตุท่ีหลักการเปล่ียนแปลงไปก็เพราะเทคโนโลยี Big Data ใหม่ได้ ช่วยทำาให้ส่ิงต่างๆเหล่าน้ีทำาได้ดังรูปท่ี 2 อาทิเช่น • เทคโนโลยีการเก็บข้อมูล Unstructure ขนาดใหญ่อย่าง Hadoop HDFS, Amazon S3 หรือ NoSQL • เทคโนโลยีในการประมวลผลข้อมูลอย่าง MapReduce, Hive, Spaek, Impala • เทคโนโลยีในการทำา Data Acquisition อย่าง KafKa, Sqoop, Flume • เทคโนโลยีในการแสดงผลข้อมูลใหม่อย่าง Pentaho BI, Tableau 156 THANACHART
- 165. รูปท่ี 1 Data Lake Components [Source: Building the Enterprise Data Lake: A look at architecture, Mark Madsen] รูปท่ี 2 หลักการของ Data Lake ความแตกต่างระหว่าง Data Lake เม่ือเทียบกับ Data WareHouse ท่ี สำาคัญมีดังน้ี • Data Lake จะเก็บข้อมูลท้ังหมด • Data Lake สนับสนุนข้อมูลทุกชนิดไม่แค่ข้อมูลแบบ Structure • Data Lake มีเพ่ือให้ผู้ใช้ทุกประเภทสามารถใช้งานได้ • Data Lake สามารถติดต้ังได้ง่ายและเปล่ียแปลงได้เร็ว • Data Lake จะประมวลและวิเคราะห์ข้อมูลได้รวดเร็วกว่า ซ่ึงทาง AWS ก็สรุปความแตกต่างระหว่าง Data Lake และ Data WareHouse ไว้ดังรูปท่ี 3 DATA LAKE: REDEFINE DATA WAREHOUSE 157
- 166. รูปท่ี 3 Data Lake v.s Data WareHouse สำาหรับรายละเอียดท้ังหมดคงได้มาฟังกันในงานสัมมนาวันท่ี 3 มีนาคม น้ี แต่ต้องขอบอกว่าตอนน้ีท่ีน่ังเต็มและปิดรับลงทะเบียนแล้ว ธนชาติ นุ่มมนท์ IMC Institute กุมภาพันธ์ 2559 158 THANACHART
- 167. CHAPTER 33 IMC Institute ให้ทุนอบรม Big Data Certification 120 ชม.สองทุน IMC Institute จะเปิดหลักสูตร Big Data Certication ท่ีเรียนเข้มข้น 120 ช่ัวโมง วันพฤหัสบดีตอนเย็น 18.00-21.00 และวันเสาร์ท้ังวันรุ่นท่ี 3 โดยเร่ิมสอนต้ังแต่วันท่ี 17 มีนาคม 2559 หลักสูตรเปิดมาแล้วสองรุ่น รุ่น หน่ึงเรียน 30 คนในปีท่ีแล้ว โดยมีอาจารย์สอนร่วมกันหลายท่าน ท้ังเร่ือง ของหลักการ Big Data การใช้เทคโนโลยีต่างๆ ท้ัง Hadoop, NoSQL, Big Data on Cloud, BI Tool การประมวลผลในรูปแบบต่างๆ เรียนรู้เร่ือง Machine Learning IMC Institute มองเห็นความสำาคัญของการพัฒนาบุคลากร Big Data ในบ้านเราและได้จัดอบรมและกิจกรรมสัมมนาทางด้านน้ี อย่างต่อเน่ือง มี ท้ังฟรีสัมมนา หลักสูตรราคาท่ีเหมาะสม การจัด Big Data User Group การจัดอบรมแบบฟรีในลักษณะ Big Data Challenge การให้ทุนบุคลากร ในภาคส่วนต่างๆ การจัด Train the Trainer ให้กับอาจารย์สถาบัน อุดมศึกษา แม้ IMC Institute จะเป็นหน่วยงานเอกชนแต่ก็ตระหนักถึง ความรับผิดชอบท่ีจะต้องช่วยพัฒนาบุคลากรด้านไอทีของประเทศซ่ึงบาง คร้ังจำาเป็นต้องช่วยหน่วยงานของรัฐในการทำา จึงได้ทำากิจกรรมต่างๆเหล่า น้ี ท้ังน้ีในรอบ 3 ปีท่ีผ่านมา IMC Institute ได้จัดอบรมหลักสูตรด้าน Big Data จำานวน 60 คร้ัง จัดฟรีสัมมนา/กิจกรรมจำานวน 8 คร้ังโดยมีผู้มาร่วม ท้ังส้ิน 1,735 ราย
- 168. 160 THANACHART
- 169. การพัฒนาอาจารย์อุดมศึกษาเร่ืองของ Big Data ทางสถาบันไอเอ็มซีเคย จัด Train the Trainer มาแล้วสองรุ่น โดยเก็บค่าเรียนเพียง 5,500 บาท เพ่ือให้เพียงพอกับค่าเช่าห้องอบรมและค่าอาหารในเวลา 5 วัน โดยงานท้ัง สองก็เป็นการใช้เงินของสถาบันเองในการทำางาน และปีน้ีก็ต้ังใจจะจัด หลักสูตร Train the Trainers อีกคร้ังในเดือนกรกฎาคม อาจารย์ท่านใด สนใจก็โปรดติดตามข้อมูลอบรมน้ีท่ีจะประกาศเร็วๆน้ี สำาหรับหลักสูตร Big Data Certication ในสองรุ่นท่ีผ่านมา ทาง IMC Institute ให้ทุนอบรมฟรีมาแล้วรุ่นละสองทุน โดยรุ่นแรกให้กับ อาจารย์สถาบันอุดมศึกษาสองท่านและรุ่นท่ีสองให้กับหน่วยงานภาครัฐ สองท่าน นอกจากน้ีทางสำานักงานรัฐบาลอิเล็กทรอนิกส์ก็ได้มอบทุนมาให้ กับบุคลากรภาครัฐท้ังสองรุ่น โดยรุ่นแรกมีจำานวน 10 คนและรุ่นท่ี 2 จำานวน 5 คน ในหลักสูตร Big Data Certication รุ่นท่ีสามน้ีเรามีการปรับปรุงเน้ือหา เล็กน้อย โดยจะเน้นให้มีการทำา Mini-Project และมีการติดต้ังระบบจริง บน Cloud Server มากข้ึน มีการสอนระบบประมวลผลใหม่ท่ีเน้น Spark และ R มีการนำาเคร่ืองมือใหม่ๆเช่น Tableau เข้ามา โดยส่ิงท่ีต้ังใจจะ อบรมมีเคร่ืองมือหลักๆดังน้ี • Hadoop Distribution: Apache, Cloudera และ Amazon EMR • NoSQL: Cassandra, Mongo DB และ HBase • Visualisation Tools: Tableau และ Microsoft SQL Server • Big Data Processing: MapReduce, Spark, Hive, Pig, R และ Impala • Big Data Ingestion: Sqoop และ Flume • Machine Learning: Microsoft Azure ML , R และ Spark MLib • Cloud Platform: Amazon Web Services และ Microsoft Azure ผู้สนใจสามารถท่ีจะหาดูรายละเอียดข้อมูลได้ท่ี www.imcinstitute.com/ bigdatacert สำาหรับหลักสูตร Big Data Certication รุ่นน้ีทาง IMC Institute ต้ังใจจะมอบทุนอบรมฟรีให้กับอำจำรย์สถำบันอุดมศึกษำอีก 2 ท่ำน เหตุผลท่ีเราพยายามเน้นมอบให้กับอาจารย์เพราะคิดว่าอาจารย์สามารถท่ี IMC INSTITUTE ให้ทุนอบรม BIG DATA CERTIFICATION 120 ชม. สองทุน 161
- 170. จะนำาความรู้ไปสอนนักศึกษาต่อและขยายผลได้ โดยได้กำาหนดคุณสมบัติ ไว้ดังน้ี • เป็นอาจารย์สอนในระดับอุดมศึกษาในสถาบันของรัฐหรือเอกชน • มีอายุต้ังแต่ 28 ปีข้ึนไป • ต้องสามารถมาเรียนได้อย่างน้อยร้อยละ 85 ของการเรียน • สามารถท่ีจะนำาไปสอนหรือทำางานวิจัยต่อไปได้ ท้ังน้ี IMC Institute อยำกให้ผู้ท่ีสนใจเขียนประวัติและแรงจูงใจท่ีอยำก เรียนหลักสูตร Big Data CertiDcation ส่งอีเมลมำท่ี [email protected] ภำยในวันท่ี 5 มีนำคม 2559 และถ้า IMC Institute จะขออนุญาตเชิญผู้ท่ีผ่านการคัดเลือกรอบแรกมาสัมภาษณ์ ระหว่างวันท่ี 6-10 มีนาคม และจะประกาศผลในวันท่ี 11 มีนาคม 2559 ธนชาติ นุ่มนนท์ IMC Institute กุมภาพันธ์ 2559 162 THANACHART
- 171. CHAPTER 34 การฝึกงานแบบ Big Data School ของ IMC Institute ปิดเทอมน้ี วันก่อนน้องท่ีสนิทท่านหน่ึงเอารายการทีวีดูให้รู้ ตอน “โรงเรียนฝึกคนหัวใจ เพชร” เป็นโรงเรียนฝึกเด็กช่างไม้ในญ่ีปุ่น สอนเด็กให้แกร่ง อดทน มีวินัย และใช้สมอง เห็นความยากลำาบากในการเรียนกว่าจะออกมาเป็นช่างไม้ท่ี เก่งและมีคุณภาพ น้องถามว่าเราทำาโรงเรียนพัฒนา Developer อย่างน้ีใน เมืองไทยไหม เราคุยกันว่าอยากจะทำาแต่ก็ยังไม่ได้ลงมือทำาอะไรมากนัก [youtube https://www.youtube.com/watch?v=hpyh7HF3eog] พฤษภาคมน้ีผมกำาลังย้ายออฟฟิทของ IMC Institute ไปอยู่ตึกสกุลไทย แถวสุริวงศ์เราคงมีพ้ืนท่ีกว่างข้ึน มีห้องฝึกอบรมท่ีพร้อมจะรองรับผู้เรียนได้ จำานวนหน่ึง การอบรมส่วนใหญ่ของ IMC Institute ยังคงอยู่ข้างนอก แต่ ห้องอบรมน้ีผมได้บอกกับทีมงานว่าเราใช้งานเพ่ือสังคม งาน CSR งาน อบรมฟรีราคาถูกมากท่ีน่ีเลยไม่ว่าจะเป็นงาน Big Data Challenge, Big Data User Group, Train the trainers ตลอดจนกิจกรรมอ่ืนๆท่ีเราคง สามารถทำาอะไรได้มากข้ึน ผมก็เลยเร่ิมคิดถึงการฝึกคน ผมอาจจะยังไม่สามารถทำาโรงเรียนฝึก Developer หัวใจเพชรได้ทันที แต่ก็นึกข้ึนมาว่าวันน้ีเราหา Developer เก่งๆได้ยากโดยคนท่ีจะซ่ือสัตย์และต้ังใจทำางานให้กับหน่วยงาน ไม่ใช่แค่ คิดหวังจะร่ำารวย นอกเหนือจากมีความรู้ ก็ต้องอดทนและมีจริยธรรมท่ีดี เรา มาฝึกงานเขาไหม? อาจเป็นช่วงเวลาส้ันๆ 2-3 เดือน พอฝึกงานเสร็จมาเขา จะกลับไปเรียนต่อหรือไปทำางานท่ีไหนก็ตามอย่างน้อยเราก็ได้สร้าง
- 172. ประโยชน์ให้กับสังคมบ้าง พอคิดได้อย่างน้ีก็เร่ิมคุยกับเพ่ือนและอาจารย์ บางคนแล้วบอกว่า กลางเดือนพฤษภาคมน้ีผมจะทำา Big Data Intern School ฝึกงานนักศึกษาซัก 6-7 คนให้ทำา Big Data แล้วก็ลองร่างส่ิงท่ีจะ ฝึกเขาดังน้ี • การเรียนรู้หลักการของ Big Data • สามารถติดต้ังระบบ Big Data ได้ไม่ว่าจะเป็น Apache Hadoop, Cloudera, Hortonworks, Amazon EMR และ Microsoft Azure HDInsight • เปิดระบบ Cloud Computing อย่าง Amazon AWS และ Microsoft Azure ให้เล่นเต็มท่ี • สามารถติดต้ังระบบNoSQL ต่างๆอย่าง Cassandra, NoSQL, MongoDB • เรียนรู้การประมวลข้อมูลขนาดใหญ่โดยใช้ Hive, Impala, Spark • สามารถท่ีจะดึงข้อมูลเข้าโดยใช้เทคโนโลยีอย่าง Sqoop, Flume, Kafka • เรียนรู้การทำา Machine Learning โดยใช้ภาษา R, Spark MLib หรือ เคร่ืองมืออย่าง Azure Machine Learning • ทำาโปรเจ็คด้าน Big Data กับบริษัท พอคิดได้อย่างน้ีก็รู้ว่าส่วนหน่ึงคงต้องสอนเอง บางอย่างก็ต้องไปเชิญ อาจารย์ท่านอ่ืนๆมาสอนท้ังท่ีบริษัทหรือ Teleconference รวมถึงบาง อย่างอาจต้องให้เรียนผ่าน Online Class บน YouTube โดยคนมาฝึกงาน คงไม่มีค่าใช้จ่ายและได้เรียนรู้ส่ิงต่างๆเหล่าน้ีแต่คงต้องมีกฎเกณฑ์ • ไม่มีค่าใช้จ่ายใดๆ • ผู้เข้าฝึกงาน (อบรม) ต้องกำาลังศึกษาหรือสำาเร็จการศึกษาในระดับ ปริญญาตรีสาขาวิศวกรรมคอมพิวเตอร์ วิทยากรคอมพิวเตอร์ หรือ เทคโนโลยีสารสนเทศ • อายุไม่เกิน 24 ปี 164 THANACHART
- 173. • มีความต้ังใจจะเข้าฝึกงานจริงจัง อาจเป็นส่วนหน่ึงของการจบการศึกษา หรือไม่ก็ได้ • สามารถเข้าฝึกงานได้ต้ังแต่วันจันทร์-เสาร์ เวลา เวลา 8.30 – 17.30 น. • ต้องเข้ามาฝึกงานทุกวันตามข้อตกลงและต้องมีเวลาเข้าฝึกงานไม่น้อย กว่า 95% • ผู้เข้าฝึกงานต้องเขียนรายงานส่งทุกวัน หากไม่ส่งถือว่าเป็นการยุติการ ฝึกงาน • หากมาสายเกิน 4 คร้ังโดยไม่มีเหตุผลถือว่าเป็นการยุติการฝึกงาน • จะมีการสอบและวัดผลสัมฤทธ์ิของการฝึกงาน และทางสถาบันจะออก ใบรับรองว่าผ่านการฝึกงาน และผู้ท่ีผ่านหากต้องการไปฝึกงานหรือทำา สหกิจศึกษา การทำาโครงการเพ่ิมเติมระหว่างเรียน ทางสถาบันจะติดต่อ และให้การรับรองให้ ท้ังน้ีผมเองได้กำาหนดโปรแกรมการฝึกงานคร่าวๆดังน้ี 30 พฤษภาคม วันแรกแรกการฝึกงาน จัดปฐมเทศ อบรมระเบียบวินัย ศึกษาแนวโน้มของเทคโนโลยี และพูดคุยเพ่ือหาคำาตอบว่า ทำาไมการศึกษา ในยุคปัจจุบันทำาให่คนเรียนด้านคอมพิวเตอร์ตกงาน 30พฤษภาคม – 4 มิถุนายน เรียนรู้ระบบ Public Cloud ของค่ายต่าง อาทิเช่น Amazon Web Services, Microsoft Azure การใช้บริการต่างๆ อาทิเช่น Virtual Server, Cloud Storage, Auto-Scaling Servers, Application Development Servers, Docker Servet 6 – 11 มิถุนายน เรียนรู้หลักการของ Big Data การติดต้ัง Apache Hadoop การติดต้ัง Hadoop Cluster และการติดต้ัง Cloudera/ Hortonworks Cluster 13-18 มิถุนายน เรียนรู้บริการต่างๆของ Hadoop ต่อ การใช้บริการ ต่างๆท้ัง Flume, Sqoop, Kafka, Cloudera Manager, Amabari และ ให้เขียนข้อสรุปเปรียบเทียบ Big Data ต่างๆ 20-25 มิถุนายนเรียนรู้ NoSQL และติดต้ังระบบต่างๆท้ัง Cassandra, MongoDB และ HBase ร่วมถึงระบบอย่าง ElasticSearch และ Solr 27 มิถุนายน – 2 กรกฎาคม เรียนรู้การประมวลผลข้อมูลขนาดใหญ๋ผ่าน SQL โดยใช้ Hive หรือ Impala พร้อมท้ัง Mini-Project 4-9 กรกฎาคม เรียนรู้ Spark และการพัฒนาโครงการโดยใช้ Spark การฝึกงานแบบ BIG DATA SCHOOL ของ IMC INSTITUTE ปิด เทอมน้ี 165
- 174. 11-16 กรกฎาคม เรียนรู้ Machine Learning การใช้เคร่ืองมือและ ภาษาต่างๆอาทิเช่น R, MLib และ Azure Machine Learning 20-28 กรกฎาคม ทำา Mini-Project ให้เสร็จพร้อมท้ังเตรียมนำาเสนอ 29 กรกฎาคม นำาเสนอ Mini-Project และปิดการฝึกงาน ผมเขียนเล่ามาเพ่ือท่ีจะบอกว่าผมคิดจะทำาอะไร มันเป็นความคิดท่ีจะ ลงมือทำาจริงๆ ถ้าน้กศึกษาหรือใครท่ีสนใจมีตามเกณฑ์ท่ีผมบอกสนใจ ลอง ส่งประวัติมาท่ี [email protected] และเขียนบทความส้ันๆมาให้ หน่ึงหน้าว่า “Before I die…” ขอบคุณครับ ธนชาติ นุ่มนนท์ IMC Institute. มีนาคม 2559 166 THANACHART
- 175. CHAPTER 35 Big Data School กับการติดต้ัง Hadoop Distributions ตามท่ีผมเคยเล่าไว้ว่าเราจะจัด Big Data School รับนักศึกษา 15 คน มาฝึกงานสองเดือนในช่วงปิดเทอม โดยโครงการน้ีเป็นงานท่ี IMC Institute จัดร่วมกับ ICE Solution สุดท้ายเราก็ได้รับนักศึกษามาจากท่ี ต่างๆท้ัง จุฬาลงกรณ์มหาวิทยาลัย ลาดกระบัง พระนครเหนือ มหาวิทยาลัย ราชมงคลรัตนโกสินทร์ ธุรกิจบัณฑิต หรือมาไกลๆจาก มหาวิทยาลัย นครพนม มหาวิทยาลัยฟาฏอนี หรือนักศึกษาไทยในต่างประเทศอย่าง Wesleyan University โดยเราเร่ิมโครงการน้ีต้ังแต่วันท่ี 31 พฤษภาคม 2559
- 176. โครงการท่ีทำาในสัปดาห์แรกนอกจากมีเร่ืองของกลุ่มสัมพันธ์แล้ว เราก็เร่ิม สอนให้นักศึกษาใช้ Cloud เร่ืองรู้และได้ทดลองระบบ Cloud ต่างๆท้ัง Amazon Web Services (AWS), Google Cloud และ Microsoft Azure โดยได้ทดลองใช้ EC2, RDS และ Auto-scaling ซ่ึงความรู้จากการใช้ Cloud Services น้ีก็เพ่ือท่ีจะนำาไปใช้ในการติดต้ัง Big Data Platform ต่างๆ นอกเหนือจากการเรียนรู้เร่ือง Cloud แล้วในสัปดาห์แรกก็ยังมีการ แนะนำา Big Data Technology ต่างๆ และนักศึกษาเองก็เร่ิมได้เห็นกับ 168 THANACHART
- 177. Hadoop Technology ทดลองเล่น Hadoop Cloudera ขนาด 5 เคร่ือง ใหญ่ท่ีติดต้ังบน Cloud Cluster ท่ีเป็น Account ของ IMC Institute ในสัปดาห์ท่ีสอง ตอนต้นเราเร่ิมสอนต้ังแต่การใช้ Vitualization Tool อย่าง VirtualBox และ Container อย่าง Docker จากน้ัน เราก็แบ่งกลุ่ม ให้ใช้ Hadoop Sandbox ท่ีเป็น Distribution ต่างๆ เช่น • Cloudera Quickstart • Hortonworks Sandbox • MapR Sandbox • Apache Hadoop โดยในเบ้ืองต้นให้ VM ท่ีเป็น VirtualBox ลงท่ีเขียนตัวเอง จากน้ันก็ เปล่ียนไปให้ Docker โดยใช้ Virtual Server ท่ีเป็น Amazon EC2 ท่ี น่าสนใจคือนักศึกษาได้ทำากันสมบูรณ์และเขียนสรุปกันมาเป็น Slide ให้คน สามารถไปติดต้ังต่อได้ดังน้ี • Slide MapR Sandbox using Docker • Slide Cloudera Quickstart using Docker • Slide Apache Hadoop using Docker • Slide Hortonworks Sandbox using Docker ตอนน้ีนักศึกษากำาลังติดต้ัง Hadoop Cluster ท้ัง 4 distributions โดยจะ ลงในเคร่ือง Server ขนาดใหญ่ 4 เคร่ืองซ่ึงถ้ามี Slide และข้อมูลดีๆผมจะ มา Update อีกคร้ัง ธนชาติ นุ่มนนท์ IMC Institute มิถุนายน 2559 BIG DATA SCHOOL กับการติดต้ัง HADOOP DISTRIBUTIONS 169
- 179. CHAPTER 36 Big Data กับการใช้งานในภาครัฐ และอุตสาหกรรมอ่ืนๆ การนำาข้อมูลขนาดใหญ่ไปใช้งานจริงๆ ยังมีไม่มากนัก ท้ังน้ีด้วยข้อจำากัดใน เร่ืองของเทคโนโลยีและจำานวนบุคลากรท่ีมีความสามารถ ซ่ึงทางสมาคม PIKOM ของมาเลเซียได้ทำารายงานเร่ือง Global Business Services Outlook Report 2015 ช้ีให้เห็นผลกระทบของเทคโนโลยีด้าน Big Data ในประเทศกลุ่ม APAC และอุตสาหกรรมต่างๆ โดยสรุปมาเป็นตารางดังน้ี ตำรำงท่ี 11 ระดับผลกระทบของเทคโนโลยี Big Data [แหล่งข้อมูลจาก PIKOM] ซ่ึงจะเห็นได้ว่ากลุ่มอุตสาหกรรมท่ีมีผลกระทบต่อการประยุกต์ใช้เทคโนโลยี Big Data อย่างมากคือ อุตสาหกรรมด้านการเงินการธนาคาร (BFSI) ด้าน
- 180. โทรคมนาคม ด้านค้าปลีกรวมถึงพาณิชย์อิเล็กทรอนิกส์ (E-commerce) และด้านสุขภาพ ส่วนกลุ่มภาครัฐบาลและกลุ่มอุตสาหกรรมการผลิตมีผล กระทบปานกลาง สำาหรับประเทศท่ีมีการประยุกต์ใช้ Big Data อย่างมาก คือสหรัฐอเมริกาและสหราชอาณาจักร โดยประเทศญ่ีปุ่น สิงคโปร์ และ ออสเตรเลียมีผลกระทบการประยุกต์ใช้งานปานกลาง ส่วนประเทศไทยอยู่ ในกลุ่มท่ีเหลือท่ียังมีการประยุกต์ใช้งานน้อย สำาหรับตัวอย่างของการนำาเทคโนโลยี Big Data มาใช้งานในภาค อุตสาหกรรมต่างๆ มีดังน้ี • อุตสาหกรรมค้าปลีก อาจนำามาเพ่ือวิเคราะห์ความต้องการของลูกค้า เพ่ือทำาให้เห็นข้อมูลของลูกค้ารอบด้าน (Customer 360) หรือการแบ่ง กลุ่มลูกค้า (Customer Segmentation) นำามาจัดแผนการตลาด สร้าง แคมเปญตอบสนองต่อพฤติกรรมการอุปโภค บริโภค ท่ีปรับเปล่ียนอยู่ ตลอดเวลา ให้ดึงดูดลูกค้าเข้ามาจับจ่ายใช้สอยมากท่ีสุด ในสภาพการ แข่งขันท่ีสูง และมีช่องทางอ่ืนๆ ใหม่ๆ เข้ามาเป็นทางเลือกมากข้ึน • อุตสาหกรรมโทรคมนาคม อาจนำาเพ่ือใช้ในการวิเคราะห์เครือข่าย โทรศัพท์เคล่ือนท่ี วิเคราะห์การใช้งานของลูกค้า การวิเคราะห์แนวโน้ม การย้ายค่ายของลูกค้า (Customer Churn) และนำาเอาข้อมูลไป ต่อยอดเพ่ิมการให้บริการอีกมากมาย อีกท้ังยังสามารถนำาข้อมูลมา วิเคราะห์ เร่ืองความม่ันคงปลอดภัย ให้เป็นประโยชน์กับลูกค้าและเพ่ือ สาธารณะได้อีกด้วย • อุตสาหกรรมการเงิน อาจนำามาเพ่ือวิเคราะห์การฉ้อโกงเงิน การคาด การณ์ความต้องการของลูกค้า การแบ่งกลุ่มลูกค้า และการวิเคราะห์ ความเส่ียงของลูกค้า • ด้านวิทยาศาสตร์และเทคโนโลยีเช่น การพยากรณ์อากาศ การคาด การณ์ข้อมูลน้ำา หรือการวิเคราะห์ข้อมูลจากเซ็นเซอร์ต่างๆ การใช้งาน พลังงาน • งานด้านการตลาด อาจนำามาเพ่ือวิเคราะห์ข้อมูลจากเครือข่ายสังคม ออนไลน์ (Social Media) การวิเคราะห์ข้อมูลท่ีพูดถึงสินค้าหรือแบรนด์ ของหน่วยงาน (Sentiment Analysis) การค้นหาลูกค้าใหม่ๆ บนโลก ออนไลน์ • งานด้านบันเทิง หรือการท่องเท่ียว เป็นการวิเคราะห์กระแส ความนิยม 172 THANACHART
- 181. talk of the town ในแต่ละกลุ่มบริการซ่ึงมีส่วนเก่ียวโยงกับ ข้อมูล ความคิดเห็น ในโซเชียลมีเดีย เป็นส่วนใหญ่ เพ่ือจัดโปรแกรมหรืองาน ท่ี สร้างความสนใจให้ได้ตรงกับความสนใจของตลาด ในแต่ละช่วง แต่ละ เวลา กับกลุ่มเป้าหมายท่ีต่างกันไป การประยุกต์ใช้งาน BIG DATA ในภาครัฐ สำาหรับตัวอย่างการใช้ประยุกต์ใช้งาน Big Data ในภาครัฐสามารถนำามา ใช้งานได้ในหลายๆ หน่วยงานเช่น ด้านสาธารณสุข ด้านวิทยาศาสตร์ ด้าน ความม่ันคง ด้านการเงิน ด้านการบริการประชาชน ด้านเกษตรกรรม ด้าน สาธารณูปโภค หรือด้านคมนาคม อาทิเช่น • การใช้เพ่ือวิเคราะห์ข้อมูลอุตุนิยมวิทยาในการพยากรณ์อากาศ • การใช้เพ่ือวิเคราะห์ข้อมูลการจราจร • การวิเคราะห์ข้อมูลเพ่ือลดปัญหาและป้องกันการเกิดอาชญากรรม • การวิเคราะห์ข้อมูลด้านสาธารณสุข เช่น แนวโน้มของผู้ป่วย การรักษา พยาบาล หรือการเกิดโรคระบาด • การวิเคราะห์ข้อมูลด้านน้ำา แหล่งน้ำา ปริมาณฝน และการใช้น้ำา • การวิเคราะห์ข้อมูลการใช้ไฟฟ้า ค่าการใช้พลังงาน • การวิเคราะห์ข้อมูลการทหารและความม่ันคงต่างๆ • การวิเคราะห์ข้อมูลเพ่ือตรวจสอบการเสียภาษีของประชาชนหรือบริษัท ห้างร้านต่างๆ ข้อดีของการประยุกต์ใช้เทคโนโลยี Big Data ในภาครัฐสามารถสรุปได้ ดังน้ี 1. การใช้เงินงบประมาณและเงินรายได้ต่างๆ ของภาครัฐจะมี ประสิทธิภาพมากข้ึน เพราะ Big Data จะช่วยคาดการณ์และวิเคราะห์ ได้แม่นยำามากข้ึน 2. ภาครัฐสามารถท่ีจะตรวจสอบข้อมูลการใช้งบประมาณได้ดีย่ิงข้ึน 3. ภาครัฐจะมีรายได้มากข้ึนหากมีการนำา Big Data มาใช้วิเคราะห์ ข้อมูลการเสียภาษีด้านต่างๆ ว่ามีความถูกต้องเพียงใด BIG DATA กับการใช้งานในภาครัฐและอุตสาหกรรมอ่ืนๆ 173
- 182. 4. ประชาชนจะได้รับการบริการท่ีดีข้ึน เช่นการนำามาแก้ปัญหาจราจร การให้บริการสาธารณสุข การให้บริการสาธารณูปโภค 5. ประชาชนจะมีคุณภาพชีวิตท่ีดีข้ึน เช่นเพ่ิมความปลอดภัยโดยการ วิเคราะห์แนวโน้มอาชญากรรม การมีสุขภาพท่ีดีข้ึนจากการวิเคราะห์ ข้อมูลสาธารณสุข 6. เกิดความร่วมมือกับภาคเอกชนมากข้ึน จากการนำาข้อมูลไปใช้ 7. จะมีข้อมูลใหม่ๆ มากข้ึนจากประชาชน (Crowdsourcing) หรือข้อมูล จากอุปกรณ์ Internet of Things 8. เป็นการสร้างทักษะและผู้เช่ียวชาญด้านข้อมูลมากข้ึน อย่างไรก็ตามความท้าทายของการประยุกต์ใช้เทคโนโลยี Big Data ยังอยู่ ท่ีความร่วมมือของหน่วยงานต่างๆ โดยอาจสรุปปัญหาต่างๆ ท่ีควรแก้ไข ดังน้ี 1. วัฒนธรรมของหน่วยงานจำานวนมากท่ีจะรู้สึกหรือคิดว่าข้อมูลเป็นของ หน่วยงานตนเอง โดยไม่มีการแชร์ข้อมูลให้กับหน่วยงานภายนอกหรือ หน่วยงานอ่ืนในองค์กรเดียวกัน 2. คุณภาพของข้อมูลท่ีอาจไม่สมบูรณ์หรือขาดความถูกต้อง 3. ปัญหาเร่ืองข้อมูลท่ีเป็นสิทธิส่วนบุคคล หรือความเท่าเทียมกันของการ เข้าถึงข้อมูลของภาคประชาชน 4. การขาดบุคลากรท่ีมีความสามารถทางด้านเทคโนโลยี Big Data ดังน้ันส่ิงท่ีภาครัฐควรจะต้องเร่งทำาเพ่ือให้มีการประยุกต์ใช้ Big Data ใน องค์กรคือ 1. พัฒนาความรู้ความเข้าใจในการประยุกต์ใช้เทคโนโลยี Big Data และสร้างวัฒนธรรมการร่วมมือการแชร์ข้อมูล 2. ออกกฎหมายหรือกฎระเบียบเพ่ือให้เกิดการเปิดข้อมูลของภาครัฐ (Open Data) 3. พัฒนาทักษะบุคลากรให้มีความรู้ด้านเทคโนโลยี Big Data 4. มีหน่วยงานกลางท่ีให้บริการเทคโนโลยี Big Data เพ่ือไม่ให้เกิดการ ลงทุนซ้ำาซ้อน และไม่ควรให้ทุกหน่วยงานลงทุนซ้ือเทคโนโลยีมากเกิน ไป ธนชาติ นุ่มนนท์ 174 THANACHART
- 183. IMC Institute มิถุนายน 2559 BIG DATA กับการใช้งานในภาครัฐและอุตสาหกรรมอ่ืนๆ 175
- 185. CHAPTER 37 Slide สำาหรับการเรียนรู้ Big Data Hadoop ของ IMC Institute IMC Institute จัดอบรม Big Data Hadoop มาหลายรุ่นและมีคนผ่าน อบรมมาจำานวนมาก และเคยทำาเอกสารประกอบการบรรยายหลายชุด วัน น้ีผมเลยรวบรวม Slide ต่างๆมาเพ่ือให้ทุกท่านได้เรียนรู้ Apache Hadoop + Spark ท่ีมี Service ต่างๆมากมาย โดยได้เป็นแบบฝึกหัดท่ีผู้ อ่านสารมารถนำาไปฝึกและทดลองใช้งานได้จริง ท้ังน้ี Slide ต่างๆเหล่าน้ีจะ อ้างอิงกับ Cloudera Quickstart ท่ีใช้ Docker Image ดังน้ันผู้ท่ีสนใจจะ เรียนรู้จาก Slide ชุดน้ีจะต้องมีเคร่ืองคอมพิวเตอร์หรือ Server ท่ีมี Docker Engine อยู่ โดยสามารถไปดูข้ันตอนการติดต้ังได้ท่ี >> https://docs.docker.com/engine/installation/
- 186. รูปท่ี 1 Hadoop Ecosystem สำาหรับ Service ต่างๆท่ีเคยทำาเอกสารการสอนมาก็เป็นไปดังรูปท่ี 1 โดยมีเอกสารดังน้ี Service ด้ำนเก็บข้อมูล • HDFS • HBase Service ด้ำนกำรประมวลผล • MapReduce • Hive • Pig • Impala Service ด้ำนกำรนำำข้อมูลเข้ำ • Sqoop • Flume • Kafka 178 THANACHART
- 187. Apache Spark • Apache Spark & SparkSQL & Spark Streaming • Spark MLlib ธนชาติ นุ่มนนท์ IMC Institute มิถุนายน 2559 SLIDE สำาหรับการเรียนรู้ BIG DATA HADOOP ของ IMC INSTITUTE 179
- 189. CHAPTER 38 Hortonworks เทียบกับ Hadoop Distribution อ่ืนๆ ช่วงสองสัปดาห์ท่ีผ่านมา ผมให้ทีมนักศึกษาฝึกงานของ IMC Institute ใน โครงการ Big Data School ได้ทดลองติดต้ังและเปรียบเทียบ Hadoop Distribution ต่างๆ ซ่ึงผมได้เคยเขียนเร่ือง การติดต้ัง Hadoop Distributions พร้อมท้ังวิธีการติดต้ังไว้แล้ว ในบทความ “Big Data School กับการติดต้ัง Hadoop Distributions” ซ่ึงในการเปรียบเทียบ Distribution ต่างๆ ผมให้นักศึกษาทดลองติดต้ังสองแบบคือ • การติดต้ัง Hadoop Cluster 4-5 เคร่ืองบน Amazon EC2 หรือ Microsoft Azure สำาหรับท่ีจะใช้เป็น Production • การใช้ Hadoop Sandbox บนเคร่ือง Server หรือเคร่ือง PC หน่ึง เคร่ือง สำาหรับท่ีจะใช้เป็นเคร่ืองทดลองหรือทำา Development ซ่ึงนักศึกษาก็ได้แบ่งกลุ่มกันทำา Hadoop Distribution 4 ชุดคือ • Cloudera Quickstart • Hortonworks Sandbox • MapR Sandbox
- 190. • Apache Hadoop และผมได้ให้พวกเขาสรุปเปรียบเทียบในประเด็นต่างๆเช่น ราคา, ความ ยากง่ายในการใช้งาน, ความยากง่ายในการติดต้ัง, Opensource Compatibity, คู่มือเอกสารต่างๆและชุมชน, การสนับสนุนจากผู้ผลิต ซ่ึง พอสรุปประเด็นต่างๆได้ดังน้ี • รำคำ: ในแง่ราคา Apache Hadoop เป็นฟรีซอฟต์แวร์แต่ก็ไม่มี support ใดๆ ซ่ึงถ้าเปรียบเทียบกรณีน้ี Hortonworks จะดีสุดเพราะ ฟรีเช่นกันยกเว้นต้องการซ้ือ support ขณะท่ี Cloudera จะหรีเฉพาะ Express Version และ MapR จะฟรีเฉพาะเวอร์ช่ัน M3 ซ่ึงท้ังสอง เวอร์ช่ันไม่ใช่ Full Feature ท่ีท้ังสองรายมีให้ • ควำมง่ำยในกำรติดต้ัง Cluster: เม่ือพิจารณาจากประเด็นน้ี Cloudera จะติดต้ังง่ายสุดโดยผ่าน Cloudera Manager แต่จริงๆแล้ว การติดต้ัง Hortonworks ก็ไม่ยากเกินไปถ้าติดต้ังผ่าน Public Cloud หรือ Private Cloud ท่ีเป็น Openstack โดยใช้ Cloudbreak ส่วน Apache Hadoop ติดต้ังค่อนข้างยากแต่อาจใช้ Ambari ได้ • ควำมง่ำยในกำรใช้งำน: Cloudera และ MapR จะมีส่วนติดต่อผู้ใช้ท่ี เป็น Hue ท่ีค่อนข้างง่ายต่อการใช้งาน ส่วนของ Hortonworks ใช้ 182 THANACHART
- 191. Ambari ท่ีมี Feature เพียงบางส่วน ส่วนของ Apache Hadoop จะ ต้องติดต้ัง Hue เองซ่ึงค่อนข้างยาก • Opensource Compatibility: กรณีน้ี Hortonworks จะดีกว่าราย อ่ืนมากเพราะจะสอดคล้องกับ Apache Hadoop ท่ีเป็น Opensource ขณะท่ี Cloudera จะเป็น Vendor Lockin หลายตัว อาทิเช่น Cloudera Manager หรือ Impala เช่นเดียวกับ MapR ท่ี Lockin ต้ังแต่ MapR- FS และ MapR Streaming • Sandbox: ถ้าต้องการหาตัวทดลองเล่น Cloudera มีจุดเด่นท่ีมี Docker Image ให้เลยสามารถเล่นกับเคร่ืองใดก็ได้ ขณะท่ี Hortonworks จะเน้นให้เล่นกับ VMware/VirtualBox หรือจะรันผ่าน Microsoft Azure เท่าน้ัน ส่วน distributation อ่ืนๆ (MapR, Apache Hadoop) ก็ไม่มี O^cial Docker Image เช่นกัน • คู่มือเอกสำรต่ำงๆและ Community: ในแง่น้ีท้ังสามรายท่ีเป็น Commercial Distribution ต่างก็มีเอกสารพอๆกัน แต่ถ้าพูดถึง Community เราอาจเห็นจำานวนคนท่ีจะแชร์ข้อมูล Cloudera มากกว่า Hortonworks แต่ท้ังน้ีเราสามารถใช้ Community กลุ่มเดียวกับ Pure Apache Hadoop เพราะ Hortonworks จะมีความ Opensource Compatibity ค่อนข้างสูงแต่สองรายใหญ่ต่างก็มีงาน ประจำาปีหลายท่ีคือ Hadoop Summit ของ Hortonworks และ Hadoop World ของ Cloudera ส่วน MapR จำานวน Community น้อยสุด • กำรสนับสนุนจำกผู้ผลิต: ถ้ามองในแง่ประเทศไทย การสนับสนุนจากผู้ ผลิตของ Cloudera ยังนำารายอ่ืนๆอยู่มาก ทำาให้หน่วยงานในประเทศ ไทยรายแห่งสนใจใช้ Cloudera ท้ังน้ีเม่ือพิจารณาโดยรวมแล้ว เราสรุปกันว่า ถ้าจะทำา Product ท่ีมีราคาถูก สุดและสอดคล้องกับ Pure Apache Hadoop มากท่ีสุดควรเลือกใช้ Hortonworks ท้ังน้ีเพราะ Commercial Distribution จะมีค่าใช้จ่าย ในแง่ License หรือ Subscribtion แต่ถ้ามีงบประมาณค่อนข้างเยอะก็อาจ เลือกใช้ได้ แต่ไม่ควรใช้ Free Version ของสองรายดังกล่าว (Cloudera และ MapR) ท้ังน้ีเน่ืองจากไม่ใช่ Full Features และบางอย่างขาดความ เสถียร HORTONWORKS เทียบกับ HADOOP DISTRIBUTION อ่ืนๆ 183
- 192. แต่ถ้าต้องการทดลองหรือใช้เพ่ือทำา Development โดยผ่าน Hadoop Sandbox ก็จะแนะนำาให้ใช้ Cloudera Quickstart ซ่ึงผมเองก็ใช้ตัวน้ีใน การอบรม ดังตัวอย่างเอกสารอบรมของผมดังน้ี >> Big data processing using Cloudera Quickstart สุดท้ายผมมี Slide ทีนักฝึกงานของ IMC Institute ได้ทำาข้ึนเพ่ือ เปรียบเทียบ Hadoop Distribution ต่างๆดังน้ี • Hortonworks >> https://docs.google.com/presentation/d/ 1U6sQSAyQMzFg9Dq9ZLIt_2E_a-6q3kyScMtJV9V2g2g/ edit?usp=sharing • MapR >> https://docs.google.com/presentation/d/10I- YWfSVlhsGbt5NCQbnAy8nws3zFU_wWBZwo4C]nQ/ edit?usp=sharing • Cloudera >> https://docs.google.com/presentation/d/ 1Wbi6Q1sGWEjUwXzbsewQBqZ3mFAfA51EbtMLluMKB4I/ edit?ts=57621459#slide=id.g14f5cc73fc_22_8 • Pure Apache Hadoop ◦ Pure Hadoop Original Apache Hadoop Series >> https://docs.google.com/presentation/d/ 1ujHiqi1ZnKRkaN03k0f9UazJiVpR-LDQt4Pno_Xi-pU/ edit#slide=id.g14f6b587f9_1_327 Apache hadoop cluster on Docker: >> https://docs.google.com/presentation/d/ 171diV930LZb4J_GkXfdbhsx4zB5BbVHrFTYZSUMR5Vw/ edit?ts=575e207c#slide=id.g14f01e49ed_0_240 Original Apache Hadoop 2.7.1 Multi-node Cluster Installation >> https://docs.google.com/presentation/d/ 1ghTF6Medv_szeEh1lwoupOj5u11c7GB4R7- ธนชาติ นุ่มมนท์ IMC Institute 184 THANACHART
- 193. มิถุนายน 2559 HORTONWORKS เทียบกับ HADOOP DISTRIBUTION อ่ืนๆ 185
- 195. CHAPTER 39 Big Data School: การอบรม On the Job Training สำาหรับนักศึกษา รุ่นท่ีสอง ปีท่ีผ่านมาทาง IMC Institute ได้เปิดอบรมหลักสูตรทางด้าน Emerging Technology ต่างๆเป็นจำานวนมาก โดยเฉพาะทางด้าน Big Data ได้เปิดหลักสูตรต่างๆท้ังทางด้าน Hadoop, Apache Spark, Business Intellegence, Data Science, Data Visualisation, R Programming และ Machine Learning โดยอบรมคนไปร่วม 1,600 คน นอกจากน้ีก็ยังมีโครงการต่างๆท้ัง การจัดฟรีสัมมนา Big Data User Group การจัดงาน Big Data Challenge ร่วมกับสำานักงานรัฐบาล อิเล็กทรอนิกส์ (องค์การมหาชน) และการจัดอบรม Train the trainer : Big Data Analytics & Machine Learning ให้กับอาจารย์มหาวิทยาลัยต่างๆ จำานวน 30 คนในช่วงเดือนกรกฎาคม โครงการหน่ึงท่ีจัดให้กับนักศึกษามหาวิทยาลัยคือ Big Data School โดยทาง IMC Institute จัดร่วมกับ ICE Solution และได้รับนักศึกษา 15 คนมาฝึกงานสองเดือนแบบ On the job training ในช่วงปิดเทอมในช่วง เดือน มิถุนายน จนถึง กรกฎาคม ปีท่ีผ่านมา ซ่ึงก็มีนักศึกษามาร่วม โครงการจากหลากหลายสถาบันท้ัง จุฬาลงกรณ์มหาวิทยาลัย ลาดกระบัง พระนครเหนือ มหาวิทยาลัยราชมงคลรัตนโกสินทร์ ธุรกิจบัณฑิต หรือมา
- 196. ไกลๆจาก มหาวิทยาลัยนครพนม มหาวิทยาลัยฟาฏอนี หรือนักศึกษาไทย ในต่างประเทศอย่าง Wesleyan University จริงๆโครงการน้ีได้แรงบันดาลใจมาจากรุ่นน้องคนหน่ึงท่ีเอารายการทีวี ร่ือง “โรงเรียนฝึกคนหัวใจเพชร” ให้ดู ซ่ึงเป็นโรงเรียนฝึกเด็กช่างไม้ในญ่ีปุ่น สอนเด็กให้แกร่ง อดทน มีวินัยและใช้สมอง เห็นความยากลำาบากในการ เรียนกว่าจะออกมาเป็นช่างไม้ท่ีเก่งและมีคุณภาพ น้องเลยถามผมว่าเราทำา โรงเรียนพัฒนาโปรแกรมเมอร์อย่างน้ีในเมืองไทยไหม ผมก็เลยเร่ิมคิดถึง การฝึกคน ผมอาจจะยังไม่สามารถทำาโรงเรียนฝึกโปรแกรมเมอร์หัวใจเพชร ได้ทันที แต่ก็นึกข้ึนมาว่าวันน้ีอุตสาหกรรมไอทีในบ้านเราหาโปรแกรมเมอร์ เก่งๆได้ยากโดยเฉพาะคนท่ีซ่ือสัตย์และต้ังใจทำางานให้กับหน่วยงาน ไม่ใช่ แค่คิดหวังจะร่ำารวย นอกเหนือจากมีความรู้ ก็ต้องอดทนและมีจริยธรรมท่ีดี เรามาฝึกงานเขาไหม? อาจเป็นช่วงเวลาส้ันๆ 2-3 เดือน พอฝึกงานเสร็จมา เขาจะกลับไปเรียนต่อหรือไปทำางานท่ีไหนก็ตามอย่างน้อยเราก็ได้สร้าง ประโยชน์ให้กับสังคมบ้าง พอคิดได้อย่างน้ีก็เร่ิมคุยกับเพ่ือนและอาจารย์ บางคนแล้วบอกว่า กลางเดือนปีท่ีผ่านมาผมก็เร่ิมทำา Big Data Intern School ฝึกงานนักศึกษา 15 คนให้ทำา Big Data แล้วก็กำาหนดเป้าหมายส่ิง ท่ีจะฝึกเขาดังน้ี • ให้เรียนรู้หลักการของ Big Data และเทคโนโลยีต่างๆ • สามารถติดต้ังระบบ Big Data ได้ไม่ว่าจะเป็น Apache Hadoop, Cloudera, Hortonworks, Amazon EMR และ Microsoft Azure HDInsight • ให้ใช้ระบบ Cloud Computing อย่าง Amazon AWS และ Microsoft Azure ใท่ีทางสถาบันจัดให้ • สามารถติดต้ังระบบ NoSQL ต่างๆอย่าง Cassandra, NoSQL, MongoDB • เรียนรู้การประมวลข้อมูลขนาดใหญ่โดยใช้ Hive, Impala, Spark • สามารถท่ีจะดึงข้อมูลเข้าโดยใช้เทคโนโลยีอย่าง Sqoop, Flume, Kafka • เรียนรู้การทำา Machine Learning โดยใช้ภาษา R, Spark MLLib หรือ เคร่ืองมืออย่าง Azure Machine Learning 188 THANACHART
- 197. • ทำาโปรเจ็คด้าน Big Data กับบริษัท ผมเองก็ได้อาจารย์ประจำาสถาบันไอเอ็มซีหลายท่านเข้ามาช่วยอบรม นักศึกษาท้ัง 15 คน อาทิเช่น อ.โกเมษ จันทวิมล,อ.ธีรชัย หลาวทอง, อ.ชิน วิทย์ ชลิดาพงศ์, อ. อารยา ฟลอเรนซ์และตัวผมเอง เข้ามาสอน รวมถึงคุณ ดนุพล สยามวาลา และก็มีรุ่นพ่ีจาก Ice Solution สองคนเข้าช่วยเป็นพ่ี เล่ียงตลอดท้ังสองเดือน นักศึกษาเองก็ได้เรียนรู้จากท่ีทางอาจารย์สอนและ ฝึกหัดทำาเร่ืองต่างๆด้วยตัวเอง โดยการฝึกงานในช่วงต้นจะฝึกเน้นให้ นักศึกษามีความเข้าใจเร่ืองของ Big Data Technology ต่างๆ และ Big Data Architecure จากน้ันก็จะเป็นการเน้นการใช้เทคโนโลยี Hadoop โดยให้นักศึกษาแบ่งกลุ่มกันติดต้ัง Hadoop Distribution ต่างๆท้ัง Cloudera, Hortoworks, MapR และ Pure Apache Hadoop แล้วทำา การเปรียบเทียบกัน ซ่ึงนักศึกษาก็สามารถทำาได้เป็นอย่างดี โดยได้ลงมือ ติดต้ังบน Server cluster บน Cloud สุดท้ายก็ให้นักศึกษาได้เรียนรู้การ ทำา Big Data Analytics และ Machine Learning Techniques โดย ใช้เคร่ืองมือต่างๆอย่าง Apache Spark, Spark MLlib และ Azure Machine Learning ตลอดเวลาสองเดือนนักศึกษาได้ฝึกทักษะด้าน Big Data เป็นอย่างดี ซ่ึง นักศึกษาท่ีมาฝึกงานมีท้ังปี 2 ปี 3 รวมถึงนักศึกษาปีท่ี 4 จบแล้ว 3-4 คนซ่ึง ยอมมาฝึกงานก่อนออกไปทำางาน ผลของการฝึกงานก็ทำาให้นักศึกษาเหล่า น้ีสามารถลงมือทำาการวิเคราะห์ข้อมูลขนาดใหญ่โดยใช้ Hadoop และ BIG DATA SCHOOL: การอบรม ON THE JOB TRAINING สำาหรับ นักศึกษารุ่นท่ีสอง 189
- 198. เทคโนโลยีต่างๆได้ และทุกคนก็ได้ใช้ผลของการฝึกงานเข้าไปทำางานใน บริษัทต่างๆได้ นักศึกษาท่ีฝึกงานในโครงการน้ีก็ยังสามารถแสดงความ สามารถไปชนะการประกวดด้าน Big Data Analytics ต่างๆ ท้ังงาน Big Data Challenge ของ IMC Institute เองท่ีต้องแข่งกับผู้ใหญ่และนัก พัฒนาท่ีทำางานแล้ว และก็ไปได้รางวัลการประกวด Data Science Contest ของสถาบันบัณฑิตพัฒนบริหารศาสตร์ (NIDA) ซ่ึงผลของการ ฝึกงานทางสถาบันไอเอ็มซีก็ถือว่าเป็นความภาคภูมิใจอย่างหน่ึงท่ีเราได้ทำา เพ่ือพัฒนาบุคลากรเข้าสู่ภาคอุตสาหกรรม สำาหรับในปีน้ีทางสถาบันไอเอ็มซีต้ังใจจะรับนักศึกษามาฝึกงานใน โครงการ Big Data School รุ่นท่ีสอง โดยในปีน้ีเน้นจะรับนักศึกษาปีท่ี 4 ท่ีจบการศึกษาแล้วแต่ต้องการฝึกงานเพ่ือเรียนรู้เพ่ิมเติมอีกสองเดือนก่อน เข้าไปทำางานในภาคอุตสาหกรรม โดยทางสถาบันเองจะร่วมมือกับบริษัท NetBay และบริษัทสยามวาลา เพ่ือร่วมกันพัฒนา Big Data Platform และให้นักศึกษาได้ทดลองฝึกงานกับโจทย์จริงในภาคอุตสาหกรรม นอกจากน้ียังมุ่งเน้นให้นักศึกษาได้เรียนเพ่ือท่ีจะสอบประกาศนียบัตรระดับ สากลอย่าง CCA Spark and Hadoop Developer Exam (CCA175) โดยทางสถาบันจะสนับสนุนค่าใช้จ่ายจำานวนหน่ึงให้กับนักศึกษาท่ีคาดว่า น่าจะสอบผ่าน สำาหรับกำาหนดการ การฝึกงานในปีน้ีจะมีโปรแกรมคร่าวๆดังน้ี 29 พฤษภาคม วันแรกแรกการฝึกงาน จัดปฐมเทศ อบรมระเบียบวินัย ศึกษาแนวโน้มของเทคโนโลยี 30พฤษภาคม – 3 มิถุนายน เรียนรู้ระบบ Public Cloud ของค่ายต่าง อาทิเช่น Google Cloud, Amazon Web Services, Microsoft Azure การใช้บริการต่างๆ อาทิเช่น Virtual Server, Cloud Storage, Auto- Scaling Servers, Application Development Servers รวมถึงศึกษา เร่ือง Docker 5 – 10 มิถุนายน เรียนรู้หลักการของ Big Data Architecture การ ติดต้ัง Apache Hadoop การติดต้ัง Hadoop Cluster และการติดต้ัง Cloudera/Hortonworks Cluster รียนรู้ NoSQL และติดต้ังระบบต่างๆ ท้ัง Cassandra, MongoDB และ HBase ร่วมถึงระบบอย่าง ElasticSearch และ Solr 12-17 มิถุนายน เรียนรู้บริการต่างๆของ Hadoop ต่อ การใช้บริการ 190 THANACHART
- 199. ต่างๆท้ัง Hive, Impala, Flume, Sqoop, Kafka, Cloudera Manager, Amabari และให้เขียนข้อสรุปเปรียบเทียบ Big Data ต่างๆ 19-24 มิถุนายน เรียนรู้ Apache Spark และการทำา Big Data Analytics โดยใช้ Spark Python, Spark Scala, Spark SQL และ Spark Streaming 26 มิถุนายน – 1 กรกฎาคม เรียนรู้ Machine Learning การใช้ เคร่ืองมือและภาษาต่างๆอาทิเช่น , MLLib และ Azure Machine Learning และติวการสอบ CCA Spark and Hadoop Developer Exam 3-27 กรกฎาคม ทำา Mini-Project 28 กรกฎาคม นำาเสนอ Mini-Project และปิดการฝึกงาน ท้ังน้ีการอบรมเชิงฝึกงานคร้ังน้ีไม่มีค่าใช้จ่ายใดๆ ซ่ึงทางสถาบันคาดว่า ผู้ท่ีผ่านการอบรมจะเป็นผู้ท่ีเข้าใจหลักการและเทคโนโลยีด้าน Big Data พร้อมท้ังสามารถทำาด้าน Data Science ได้ โดยทางสถาบันจะมีการสอบ และวัดผลสัมฤทธ์ิของการฝึกงาน และทางสถาบันจะออกใบรับรองว่าผ่าน การฝึกงาน และผู้ท่ีผ่านหากต้องการไปฝึกงานหรือทำาสหกิจศึกษา การทำา โครงการเพ่ิมเติมระหว่างเรียน ทางสถาบันจะติดต่อและให้การรับรองให้ พร้อมกันน้ีนักศึกษาท่ีทำาคะแนนสอบจากการทดลองสอบ CCA Spark and Hadoop Developer Exam สูงสุดสามอันดับแรกทางสถาบันจะออกค่าใช้ จ่ายการสอบจริงให้มูลค่ารายละ $295 เพ่ือให้ได้ประกาศนียบัตร ท้ังน้ีผู้เข้า อบรมไม่มีอะไรต้องผูกมัดกับทางสถาบัน และทางสถาบันยินดีประสาน ติดต่อกับบริษัทอ่ืนๆเพ่ือไปทำางานด้าน Big Data ต่อไป สำาหรับคุณสมบัติผู้ท่ีจะเข้ารับการอบรมน้ีมีดังน้ี • กำาลังศึกษาหรือสำาเร็จการศึกษาในระดับปริญญาตรีสาขาวิศวกรรม คอมพิวเตอร์ วิทยากรคอมพิวเตอร์ หรือเทคโนโลยีสารสนเทศ [ถ้าเป็น นักศึกษาปี 4 ท่ีกำาลังจบการศึกษาจะได้รับการพิจารณาก่อน] • มีความต้ังใจจะเข้าฝึกงานจริงจัง อาจเป็นส่วนหน่ึงของการจบการศึกษา หรือไม่ก็ได้ • สามารถเข้าฝึกงานได้ต้ังแต่วันจันทร์-ศุกร์ เวลา เวลา 8.30 – 17.30 น. • ต้องเข้ามาฝึกงานทุกวันตามข้อตกลงและต้องมีเวลาเข้าฝึกงานไม่น้อย กว่า 95% ผู้ท่ีมีความสนใจการอบรมน้ีสามารถดูรายละเอียดเพ่ิมเติมได้ท่ี www. BIG DATA SCHOOL: การอบรม ON THE JOB TRAINING สำาหรับ นักศึกษารุ่นท่ีสอง 191
- 200. imcinstitute.com/bigdataschool พร้อมท้ังส่งใบสมัครออนไลย์และ ติดต่อท่ีสถาบันไอเอ็มซี ก่อนวันท่ี 31 มีนาคม 2560 ธนชาติ นุ่มนนท์ IMC Institute กุมภาพันธ์ 2560 192 THANACHART
- 201. CHAPTER 40 Big Data เพ่ือสร้าง Digital Disruption ในองค์กร (ตอนท่ี 1) การใช้ชีวิตประจำาวันของผู้คนท้ังเร่ืองการทำางานและเร่ืองส่วนตัว ล้วนแล้วแต่เป็นการสร้างข้อมูลใหม่ข้ึนมา ต้ังแต่เราต่ืนนอนก็อาจมีเวลาท่ี เราต่ืน การทานอาหารท่ีใด ไปท่ีไหน การทำางานก็มีข้อมูลตลอดว่าเราทำา อะไร ส่งเอกสารหาใคร เขียนข้อความอะไร หน่วยงานทุกแห่งล้วนมีข้อมูล จำานวนมากจากการทำางาน การติดต่อลูกค้า และการทำาธุรกรรมต่างๆแต่ใน อดีตข้อมูลเหล่าน้ีไม่ถูกบันทึกในรูปแบบของดิจิทัลท้ังหมดท้ังน้ีเพราะมีข้อ จำากัดในเร่ืองเทคโนโลยี การเข้ามาของเทคโนโลยีใหม่อย่าง Internet of Things หรืออุปกรณ์ ต่างๆ ประกอบกับการเปล่ียนของเทคโนโลยีในการเก็บข้อมูล ท่ีรูปแบบ ข้อมูลเปล่ียนไป และราคาท่ีถูกลง รวมถึงการท่ีคอมพิวเตอร์มีประสิทธิภาพ สูงข้ึน ทำาให้เราสามารถบันทึกข้อมูลต่างๆในการทำางาน การใช้ชีวิตประจำา ลงไปได้มากข้ึน และเก็บรวบรวมเป็นข้อมูลขนาดใหญ่ (Big Data) ท่ีแตก ต่างจากการเก็บข้อมูลเพียงแค่ในฐานข้อมูลแบบเดิมท่ีเป็น Database หรือ Datawarehouse ในอดีตท่ีจะต้องเลือกเก็บข้อมูลบางอย่าง ไม่ใช่ Big Data ท่ีควรจะเป็น เม่ือหน่วยงานมี Big Data ท่ีสามารถรวบรวมข้อมูลจำานวนมากลงมาใน รูปแบบของ Data Lake ก็เกิดความท้าทายข้ึนมาว่า แล้วเราจะนำาข้อมูลเรา น้ันมาวิเคราะห์ให้เกิดประโยชน์อย่างไร กล่าวคือการทำา Big Data
- 202. Analytics หลายๆหน่วยงานเข้าใจแต่เพียงว่าคือการนำามาสร้างรายงานให้ เห็นข้อมูลต่างๆในรูปแบบของ Business Intelligence และไปเข้าใจว่า การทำา Digital Transformation ของหน่วยงานคือการนำาเทคโนโลยี ดิจิทัลมาใช้ แล้วนำารายงานท่ีได้จาก Big Data มาใช้ประโยชน์ จริงๆทุกวันน้ีเราพูดถึงคำาว่า Digital Disruption เราพูดคำาว่า Industry 4.0 แล้วก็บอกว่า Robot หรือ Articial Intelligent / Machine Learning กำาลังเข้ามา เราเห็นธุรกิจหลายอย่างกำาลังเปล่ียนแปลงไป แต่ เราไปคิดว่ามันก็คือแค่การใช้ดิจิทัล การหาซอฟต์แวร์เข้ามาใช้งาน หลาย หน่วยงานก็พยายามจะปรับหน่วยงานไอทีในองค์กร หานักพัฒนา ซอฟต์แวร์ ลงทุนฮาร์ดแวร์เพ่ิมด้วยความเข้าใจว่า เราต้องทำา Digital Transformation หรือพยายามเต้นตามกระแส Industria; 4.0/ Thailand 4.0 อย่างไม่เข้าใจ แต่จริงๆแล้วธุรกิจหลายๆอย่างท่ีกำาลังทำาให้เกิด Digital Disruption อย่าง Amazon.com, Alibaba, Uber, AirBnb, eBay หรือ Facebook ล้วนแต่เกิดการจากการนำา Big Data องค์กรท่ีได้จากการบันทึกข้อมูลจาก การทำางานมาใช้เช่นข้อมูลการทำาธุรกรรมของลูกค้าในการทำาธุรกรรมมา วิเคราะห์ หน่วยงานเหล่าน้ีต่างมีทีมงาน Data Scientist จำานวนมาก มี แผนก Data Science ท่ีคอยคิดวิเคราะห์ว่าจะนำา Big Data มา เปล่ียนแปลงธุรกิจได้อย่างไร จะนำามาสร้างรูปแบบธุรกิจใหม่ๆได้อย่างไร 194 THANACHART
- 203. และก็มีผลทำาให้โลกเกิดการเปล่ียนแปลงอย่างมาก ทำาให้รุกคืบเข้าไป เปล่ียนธุรกิจต่างๆ ทำาให้ธุรกิจท่ีไม่มีการวิเคราะห์ข้อมูลแข่งขันไม่ได้ ดังน้ันการรู้จักนำา Big Data มาใช้ในองค์กร ท่ีสำาคัญคือการรู้จักใช้ หลักการของ Data Science มาเพ่ือทำาการคาดการณ์ธุรกิจ ซ่ึงนอกเหนือ จากจะทำาให้เป็นการเพ่ิมประสิทธิภาพในการทำางานแล้ว ท่ีสำาคัญคือ Big Data อาจทำาให้เกิด Digital Disruption อาจทำาให้เห็นโอกาสทางธุรกิจ ใหม่ๆท่ีเกิดข้ึนจากการวิเคราะห์ โดยใช้หลักการของ Machine Learning หรือการนำาข้อมูลมาใช้โดยทีมงาน Data Scientist แล้วอาจทำาให้โอกาส ใหม่ๆดังเช่นบริษัทท่ีกล่าวข้างต้น และก็จะทำาให้หน่วยงานสามารถแข่งขัน กับคู่แข่งได้ แต่ Big Data ไม่ใช่แค่เร่ืองของ Business Intelligence ไม่ใช่งานแบบ เดิมๆของหน่วยงานอย่าง Datawarehouse ไม่ใช่แค่ใช้ทักษะของนัก พัฒนาโปรแกรม หรือคนดูแลฐานข้อมูล แต่เป็นงานของคุนกลุ่มใหม่ท่ี องค์กรจะต้องกล้าและต้องสร้างทีมใหม่ข้ึนมา ข้อสำำคัญBig Data ไม่ใช่ Quick win ไม่ใช่โปรเจ็คระยะส้ัน แต่มันคือกำรลงทุนเพ่ืออนำคต ลงทุน คน ลงทุนเทคโนโลยีใหม่ แล้วต้องหวังผลระยะยำว มันคือคำาถามท่ีว่าผู้ บริหารระดับสูงจะกล้าเส่ียงไหม เพ่ือเห็น Digital Disruption ขององค์กร วันน้ีผมขอเร่ิมต้นแค่น้ีก่อน แล้วจะมาต่อเป็นประเด็นต่างๆทีควรทำาใน คร้ังหน้า ธนชาติ นุ่มนนท์ IMC Institute เมษายน 2560 BIG DATA เพ่ือสร้าง DIGITAL DISRUPTION ในองค์กร (ตอนท่ี 1) 195
- 205. CHAPTER 41 Big Data เพ่ือสร้าง Digital Disruption ในองค์กร (ตอนท่ี 2) ผมเขียนบทความน้ีตอนท่ี 1 ไว้นานมากแล้ว (Big Data เพ่ือสร้าง Digital Disruption ในองค์กร (ตอนท่ี 1)) เพ่ิงมีเวลาเขียนตอนท่ีสองในวันน้ี ซ่ึงใน ตอนน้ีจะกล่าวถึงประเด็นท่ีควรทำาในเร่ืองของการทำา Big Data ต่างๆดังน้ี 1. Big Data คือหลักการของ Data Lake องค์กรท่ีคิดว่าจะนำา Big Data มาสร้างความเปล่ียนแปลงองค์กร จำำเป็นต้องรวบรวม Data ต่ำงๆท่ีมีอยู่ท้ังภำยในและภำยนอกในลักษณะข้อมูลดิบ (Raw Data) มำเก็บไว้ใน Data Lake เพ่ือท่ีนำาข้อมูลต่างๆมาใช้ในการวิเคราะห์ และประมวลต่อไป กล่าวคือ Big Data จะเร่ิมต้นด้วยการเก็บรวบรวม ข้อมูลแล้วค่อยต้ังคำาถามต่างๆในอนาคต 2. Big Data ไม่ใช่เร่ิมด้วยกำรทำำ Data Warehouse หรือกำรทำำ Business Intelligence (BI) แบบเดิม แต่ Data Warehouse และ BI คือส่วนหน่ึงของ Big Data ท้ังน้ีการทำา Data Warehouse จะคำานึงถึงการทำา Data Cleansing และการทำารายงานเป็นคร้ังๆไป ซ่ึงการทำา Data Cleansing และ Load Data เข้าสู่ Data Warehouse จะทำาให้ Information หลายๆอย่างในข้อมูลดิบ จำานวนมากถูกลดทอนไปเพ่ือทำารายงาน และเม่ือต้องการทำารายงาน ใหม่ๆ ก็อาจจะทำาการ Load Data ชุดใหม่เข้ามาทำาให้เสียเวลาใน การทำางาน
- 206. 3. องค์กรจะต้องมีการลงทุนโครงสร้างพ้ืนฐานสำาหรับ Big Data ซ่ึงควร จะเป็นกำรลงทุนด้ำน Data Lake เช่นการจัดหา Hadoop มาใช้ใน องค์กร ดังแสดงในรูปท่ี 1 และไม่ควรท่ีจะต้องลงทุนไปกับ Data Warehouse ด้วยอุปกรณ์หรือซอฟต์แวร์ท่ีราคาสูงเกินไป เพราะ Data Lake จะมีราคาท่ีถูกกว่า และสามารถ O_oad ข้อมูลจาก Data Warehouse ลงมาได้ ดังน้ันการทำา Big Data Project คือ การเร่ิมต้นจากการทำา Data Lake 4. องค์กรท่ีสามารถใช้ Public Cloud ได้ อาจพิจารณาการทำา Big Data โดยใช้ Big Data as a Service ท่ีอยู่บน Platform ต่างๆเช่น AWS, Google Cloud หรือ Microsoft Azure ซ่ึงจะมีบริการอย่าง Cloud Storage หรือ Hadoop as a Service 5. คุณค่าของ Big Data ทีสำาคัญเป็นเร่ืองของการทำา Predictive Analytics ซ่ึงต้องการทีมงานท่ีมีความรู้ทาง Data Science ท่ีมีความ รู้และแนวคิดท่ีแตกต่างจากกลุ่มคนท่ีทำา Data Warehouse และ BI องค์กรควรจะสร้ำงทีมข้ึนมำใหม่ท่ีมีควำมรู้ด้ำน Data Science แยกออกมำจำกกลุ่มคนเดิม ทีมงาน Data Science จำาเป็นอย่างย่ิง ท่ีต้องมีคนท่ีเข้าใจธุรกิจขององค์กร ดังน้ันบางคร้ังการสร้างทีมจาก ภายในจะเป็นเร่ืองท่ีดีกว่า โดยอาจผสมผสานกับคนใหม่ท่ีมาจาก ภายนอก ท้ังน้ีการเลือกคนมาทำาต้องเน้นคนท่ีมีความเข้าใจเร่ือง คณิตศาสตร์และสถิติ มากกว่าคนไอทีท่ีเน้นการพัฒนาโปรแกรม 6. องค์กรควรจะมีกำรพัฒนำบุคลำกรในทุกระดับให้เข้ำใจหลักกำรของ Big Data และประโยชน์ท่ีจะได้รับ ให้เข้าใจว่า Big Data จะมา Disrupt ธุรกิจอย่างไร 7. การทำา Big Data Analytics แต่ละเร่ืองจำาเป็นต้องใช้เวลาในการ ศึกษาข้อมูล หา Algorithm ท่ีเหมาะสม ผู้บริหารไม่ควรท่ีจะคาดหวัง ว่าจะได้ผลลัพธ์ภายในระยะเวลาอันส้ัน ซ่ึงแตกต่างจากการขอ รายงานท่ีได้จาก BI ท่ีพนักงานสามารถจะหารายงานได้รวดเร็วกว่า มาก 8. อย่าเร่ิมต้นการทำา Big Data ด้วยการลงทุนขนาดใหญ่ และโครงการ Big Data ท่ีดีไม่ควรเร่ิมจากฝ่ายไอทีตามลำาพัง 198 THANACHART
- 207. รูปท่ี 1 ตัวอย่างของ Data Lake Architecture โดยใช้ Hadoop ท้ังหมดน้ีคือข้อคิดส้ันๆท่ีผมอยากแนะนำาต่อ เพ่ือให้องค์กรเร่ิมทำา โครงการ Big Data ในแนวทางท่ีเหมาะสม ธนชาติ นุ่มนนท์ IMC Institute กรกฎาคม 2560 BIG DATA เพ่ือสร้าง DIGITAL DISRUPTION ในองค์กร (ตอนท่ี 2) 199
- 209. CHAPTER 42 ระดับการวัดความสามารถในการนำา Big Data ไปใช้ในองค์กร ผมเห็นว่าวันน้ีทุกคนต่างก็พูดเร่ือง Big Data ต้ังแต่คนไอทีไปจนถึง นายกรัฐมนตรี ต่างก็บอกว่าจะเอา Big Data มาใช้ในองค์กร บ้างก็บอกว่า ทำาแล้วบ้างก็บอกว่ากำาลังทำา บางคนทำารายงานอะไรเล็กน้อยก็บอกว่าทำา Big Data อยู่ ซ่ึงผมก็ไม่แน่ใจว่าแต่ละคนเข้าใจความหมายของ Big Data แค่ไหน แต่ไม่ว่าจะมองนิยาม Big Data อย่างไรก็ตามผมมองว่า Big Data มีเป้าหมายสำาหรับองค์กรในสามประเด็นดังน้ี 1. กำรนำำข้อมูลขนำดใหญ่มำช่วยในกำรตัดสินใจได้ดีข้ึน เช่นสามารถ ตอบได้ว่าเราควรจะทำาอะไร นำาสินค้าใดมาขาย ลูกค้าเราอยู่ท่ีใด จะ ใช้จ่ายงบประมาณอย่างไร 2. กำรนำำข้อมูลขนำดใหญ่มำช่วยให้กำรทำำงำนดีข้ึน เช่นทราบข้อมูลโดย ทันทีว่าลูกค้าต้องการอะไร ทราบตำาแหน่งของลูกค้าเป้าหมาย หรือ ช่วยเพ่ิมยอดขาย จะใช้งบประมาณให้มีประสิทธิภาพอย่างไร 3. กำรทำำให้ข้อมูลเป็นทรัพย์สินขององค์กร และทำำให้เกิด Business Transformation เช่นการนำาข้อมูลท่ีมีอยู่ไปต่อยอดร่วมกับคู่ค้า รายอ่ืนๆเพ่ือสร้างสินค้าใหม่ๆ การทำา Big Data ไม่ใข่แค่เร่ืองของการทำา Data Cleansing, Data Warehouse, Business Intelligence หร่ือเร่ืองของเทคโนโลยี องค์กรท่ี
- 210. จะทำา Big Data อาจต้องเปล่ียนทัศนคติในรูปแบบเดิมๆอยู่หลายเร่ือง ซ่ึง ผมมักจะยกคำาพูดส้ันมา 3-4 ประโยคเก่ียวกับ Big Data ดังน้ี • Don’t think technology, think business transformation. • Don’t think data warehouse, think data lake. • Don’t think business intelligence, think data science. • Don’t think “what happened”, think “what will happen”. สุดท้ายต้องทำาความเข้าใจเร่ืองระดับความสามารถของการนำา Big Data ไปใช้ในองค์กร (Big Data Matuarity Model) ว่ามีอยู่ 5 ระดับดังรูปน้ี ซ่ึง จะบอกได้ว่าองค์กรของเราอยู่ในระดับใด รูปท่ี 1 Big Data Business Model Maturity Index, จาก Big Data MBA, Bernard Marr 1. Business Monitoring ในข้ันตอนน้ีองค์กรยังเพียงแค่ทำา Business Intelligence หรือยังทำา Data Warehouse ซ่ึงเป็น ข้ันตอนท่ีเราจะแสดงข้อมูลหรือทำารายงานต่างๆขององค์กรในลักษณะ ของ Descriptive Analytic ท่ีเราจะดูข้อมูลในอดีตเพ่ือให้ทราบว่า What happened? 2. Business Insights ในข้ันตอนน้ีจะเป็นการเร่ิมต้นทำา Big Data 202 THANACHART
- 211. Project ท่ีมีการทำา Data Lake เพ่ือรวบรวมข้อมูลจากท้ังภายในและ ภายนอกองค์กรท้ังข้อมูลท่ีเป็น structure, unstructure หรือ semi-structure เพ่ือทำา Predictive Analytic เพ่ือให้ทราบว่า What will happen? 3. Business Optimization ในข้ันตอนน้ีจะเร่ิมเห็นความคุ้มค่าของ การลงทุนทำา Big Data Project โดยจะเป็นการทำา Prescriptive Analytic เพ่ือให้ทราบว่า How should we make in happen? 4. Data Monetization ในข้ันตอนน้ีจะเป็นการขยายผลเพ่ือนำา Data ท่ีจะเป็นทรัพยากรขององค์กรไปใช้เป็นสินทรัพย์ในการทำางานร่วมกับ คู่ค้าหรือองค์กรอ่ืนๆ 5. Business Metamorphosis ในข้ันตอนน้ีจะเป็นข้ันสูงสุดของการ ทำา Big Data ท่ีจะเห็นเร่ืองของ Business Transformation ใน องค์กรซ่ึงอาจเห็นรูปแบบการทำางานใหม่ๆ ธุรกิจใหม่ หร่ือผลิตภัณฑ์ ใหม่ๆขององค์กร จากท่ีกล่าวมาท้ังหมดน้ีจะเห็นได้ว่า การทำา Big Data Project ไม่ใช่เร่ือง ง่ายๆอย่างท่ีเข้าใจ จำาเป็นต้องปรับวิธีคิดในองค์กรอย่างมาก และต้อง เข้าใจเป้าหมายและระดับข้ันของการทำา Big Data ในองค์กร ธนชาติ นุ่มนนท์ IMC Institute พฤศจิกายน 2560 ระดับการวัดความสามารถในการนำา BIG DATA ไปใช้ในองค์กร 203
- 213. CHAPTER 43 Big Data as a Service แนวทาง การทำาโครงการ Big Data ท่ีไม่ต้อง ลงทุนโครงสร้างพ้ืนฐาน ช่วงหลายเดือนท่ีผ่านมาผมเดินสายบรรยายเร่ือง Big Data Jumpstart โดยแนะนำาให้องค์กรต่างๆทำา Big Data as a Service ซ่ึงเป็นการใช้ Cloud Services ของ Public cloud หลายใหญ่ต่างๆท้ัง Google Cloud Platform, Microsoft Platform หรือ Amazon Web Services (AWS) ทำาให้เราสามารถท่ีจะลดค่าใช้จ่ายได้มหาศาลโดยเฉพาะกับองค์กรขนาด กลางหรือขนาดเล็กท่ีไม่มีงบประมาณหลายสิบล้านในการลงทุนโครงสร้าง พ้ืนฐานด้าน Big Data
- 214. รูปท่ี 1 องค์ประกอบของเทคโนโลยีสำาหรับการทำา Big Data การลงทุนโครงสร้างพ้ืนฐานหรือการจัดหาเทคโนโลยีสำาหรับโครงการ Big Data โดยมากจะมีการลงทุนอยู่ส่ีด้านคือ 1) Data Collection/ Ingestion สำาหรับการนำาข้อมูลเข้ามาเก็บ 2) Data Storage สำาหรับการ เก็บข้อมูลท่ีเป็นท้ัง structure และ unstructure 3) Data Analysis/ Processing สำาหรับการประมวลผลข้อมูลท่ีอยู่ใน data storage และ 4) Data visualisation สำาหรับการแสดงผล ปัญหาท่ีองค์กรต่างๆมักจะมีก็คือการจัดหาเทคโนโลยีด้าน Data storage ท่ีจะต้องสามารถเก็บ Big Data ซ่ึงนอกจากจะมีขนาดใหญ่แลัว ข้อมูลยังมีความหลากหลาย จึงต้องหาเทคโนโลยีราคาถูกอย่าง Apache Hadoop มาเก็บข้อมูล แต่การติดต้ังเทคโนโลยีเหล่าน้ีก็มีค่าใช้จ่ายในการ หาเคร่ืองคอมพิวเตอร์ Server จำานวนมากมาใช้ และค่าใช้จ่ายด้าน Hardware ก็ค่อนข้างสูงหลายล้านบาท บางทีเป็นสิบล้านหรือร้อยล้าน บาท ซ่ึงอาจไม่เหมาะกับองค์กรขนาดเล็ก หรือแม้แต่องค์กรขนาดใหญ่ก็มี คำาถามท่ีจะต้องหา Use case ท่ีดีเพ่ือตอบเร่ืองความคุ้มค่ากับการลงทุน (Returm of Investment) ให้ได้ ดังน้ันการทำาโครงการ Big Data ไม่ควรจะเร่ิมต้นจากการลงทุนเร่ือง เทคโนโลยี ไม่ใช่เป็นการจัดหาระบบอย่างการทำา Apache Hadoop แต่ ควรจะเป็นการเร่ิมจากคิดเร่ืองของธุรกิจเราต้องคิดเร่ืองของ Business Transformation (Don’t thing technology, think business transformation) การทำาโครงการ Big Data ควรเร่ิมจากทีมด้านธุรกิจ ไม่ใช้หานักเทคโนโลยีมาแนะนำาการติดต้ังระบบหรือลง Hadoop หรือหา 206 THANACHART
- 215. นักวิทยาศาสตร์ข้อมูลมาทำางานทันที เพราะหากฝ่ายบริหารหรือฝ่ายธุรกิจ มีกลยุทธ์ด้าน Big Data เข้าใจประโยชน์ของการทำา Big Data ได้ เรา สามารถเร่ิมต้นโครงการ Big Data ได้อย่างง่าย โดยใช้ประโยชน์จาก บริการ Big Data as a Service บน Public cloud ซ่ึงทำาให้องค์กรไม่ต้อง เสียค่าใช้จ่ายเร่ิมต้นในราคาแพง ท่ีอาจไม่คุ้มค่ากับการลงทุน เทคโนโลยีในการทำา Big Data ต่างๆเช่น Big data storage (อย่าง Hadoop HDFS) เราสามารถใช้ Cloud Storage อย่าง Amazon S3, Google Cloud Storage หรือ Azure Blob เข้ามาแทนท่ีได้ โดยบริการ เหล่าน้ีค่าใช้จ่ายในการใช้จ่ายในการใช้งานจะต่ำากว่าการติดต้ัง Hadoop มาใช้งานเป็นสิบหรือร้อยเท่า แม้อาจมีข้อเสียเร่ืองเวลาในการ Transfer ข้อมูลจาก site ของเราข้ึน Public Cloud แต่หากมีการวางแผนท่ีดีแล้ว สามารถทำางานได้อย่างมีประสิทธิภาพ เช่นเดียวกับเร่ืองความปลอดภัย ของข้อมูบบน Public cloud หากมีการพิจารณาการใช้ข้อมูลท่ีเหมาะสม หรือการเข้ารหัสข้อมูลก็จะตัดปัญหาเร่ืองเหล่าน้ีไปได้ เช่นเดียวกันในการประมวลผลเราสามารถใช้บริการบน Public cloud ท่ี ใช้ระบบประมวลผลอย่าง Hadoop as a service เช่น DataProc บน Google Cloud Platform, HDInsight ของ Microsoft Azure หรือ EMR ของ AWS ซ่ึงมีค่าใช้จ่ายตามระยะเวลาการใช้งาน (pay-as-you-go) ซ่ึง เราไม่จำาเป็นต้องเปิดระบบตลอด และมีค่าใช้จ่ายท่ีต่ำามาก รวมถึงการใช้ บริการอ่ืนๆอย่าง Machine Learning as a Service บน public cloud ท่ีมีความสามารถท่ีค่อนข้างสูง ทำาให้เราสามารถทำางานได้อย่างมี ประสิทธิภาพ แม้แต่การทำา Data Visualisation เราก็สามารถท่ีจะใช้เคร่ืองมือบน public cloud ท่ีจัดเป็น Big Data Software as a Service อย่างเช่น Google Data Studio 360, PowerBI บน Microsoft Azure หรือ Quicksight ของ AWS ได้ ซ่ึงรูปท่ี 2 ก็แสดงสรุปให้เห็นบริการ Cloud Service เหล่าน้ี บน public cloud platform ต่างๆ BIG DATA AS A SERVICE แนวทางการทำาโครงการ BIG DATA ท่ี ไม่ต้องลงทุนโครงสร้างพ้ืนฐาน 207
- 216. รูปท่ี 2 Tradition Big Data Technology เทียบกับ Big Data as a Service ต่าง ซ่ึงการทำาโครงการ Big Data โดยใช้ public cloud เหล่าน้ีสามารถท่ี จะเร่ิมทำาได้เลย ไม่ได้มีค่าใช้จ่ายเร่ิมต้น และค่าใช้จ่ายท่ีตามมาก็เป็นค่า บริการต่อการใช้งาน ซ่ึงค่าบริการท่ีอาหมดไปหลักๆก็จะเป็นค่า Cloud Storage ท่ีอาจเสียประมาณเดือนละไม่ถึงพันบามต่อ Terabyte และหาก เราต้องการเปล่ียนแปลงหรือยกเลิกบริการเหล่าน้ีก็สามารถใช้ได้ทันที ซ่ึง วิธีการตัดสินใจท่ีจะทำาโครงการ Big Data เหล่าน้ีก็จะไม่ได้เน้นเร่ืองของ ความคุ้มค่ากับการลงทุนมากนัก เพราะค่าใช้จ่ายเร่ิมต้นต่ำามาก แต่มันจะ กลายเป็นว่า เราจะทำาโครงการอะไรท่ีให้ประโยชน์กับธุรกิจมากสุด และเม่ือ เร่ิมทำาลงทุนเร่ืมต้นเล็กน้อยก็จะเห็นผลทันทีว่าคุ้มค่าหรือไม่ กล่าวโดยสรุป วันน้ีเราสามารถเร่ิมทำาโครงการ Big Data ได้เลยโดย เร่ิมท่ีโจทย์ทางธุรกิจ คุยกับฝ่ังธุรกิจ ไม่ใช่เร่ิมท่ีเทคโนโลยี ธนชาติ นุ่มนนท์ IMC Institute ตุลาคม 2560 208 THANACHART
- 217. CHAPTER 44 การทำาโครงการ Big Data อย่าง รวดเร็ว ควรเร่ิมอย่างไร ช่วงน้ีเวลาผมอ่านข่าวจากส่ือต่างๆก็จะเห็นผู้คนในทุกวงการออกมาพูด เร่ืองการทำา Big Data เป็นจำานวนมาก มีการเขียนบทความ มีการออกข่าว ต่างๆ กำาหนดนโยบาย บ้างก็เข้าใจหลักการ บ้างก็พูดกันตามกระแส จน เหมือนกับว่า Big Data เป็นเคร่ืองมือวิเศษท่ีจะมาปรับเปล่ียนองค์กรให้เข้า สู่การเปล่ียนแปลงเชิงดิจิทัลได้โดยง่าย ท้ังๆท่ีการวิเคราะห์ข้อมูล Big Data มันซับซ้อนกว่าน้ันและต้องมีการปรับเปล่ียนโครงสร้างพ้ืนฐานด้าน เทคโนโลยีสารสนเทศในองค์กรพอสมควร ผมเองค่อนข้างจะโชคดีท่ียังเป็นคนลงมือปฎิบัติ ทำา Big Data Project เอง ศึกษาเอง มาเปิดและติดต้ังระบบอย่าง Hadoop มาใช้ Cloud Services ต่างๆในการทำา Big Data Analytics ได้ลงมือทำา Machine Learning ตลอดจนศึกษาทฤษฎีท้ังในมุมมองของผู้บริหารและนักไอที เห็น Use Cases ในท่ีต่างๆ และก็ได้เจอผู้คนมากมายในองค์กรต่างๆ พร้อมท้ัง มีโอกาสได้ไปบรรยายและสอนเร่ืองน้ีในหลายๆท่ี ท้ังระดับบริหารและสอน คนลงมือปฎิบัติจริงจัง จึงพอท่ีจะบอกได้คร่าวๆบ้างว่า เราควรจะเร่ิมต้นทำา Big Data ได้อย่างไร ผมอยากจะสรุปประเด็นการเร่ิมต้นทำาโครงการ Big Data ท่ีสำาคัญสามเร่ืองดังน้ี 1. กำรทำำ Big Data ควรเร่ิมต้นทำำกับข้อมูลประเภทใด Big Data คือข้อมูลขนาดใหญ่มากๆท้ังท่ีเป็น Structure และ
- 218. unstructure ซ่ึงผมมักจะได้ยินว่าเราควรเอา Big Data มาเพ่ือวิเคราะห์ พฤติกรรมลูกค่้า บ้างก็บอกว่าไปเอาข้อมูลใน Social Media มาเพ่ือเข้าใจ ลูกค้าหรือแบรนด์เราเองมากข้ึน แต่จริงๆแล้วถ้าเราแบ่งข้อมูลท่ีจะนำามาใช้ เราอาจแบ่งได้เป็นส่ีประเภท • ข้อมูลท่ีมีอยู่แล้ว และได้ทำาการวิเคราะห์แล้ว • ข้อมูลท่ีมีอยู่แล้ว แต่ไม่เคยนำามาวิเคราะห์ใดๆ • ข้อมูลท่ียังไม่เคยเก็บ แต่น่าจะมีประโยชน์ • ข้อมูลจากคู่ค้าหรือแหล่งอ่ืนๆ การเร่ิมต้นทำา Big Data ท่ีง่ายๆอาจพิจารณาท่ี “ข้อมูลท่ีมีอยู่แล้ว แต่ไม่ เคยนำำมำวิเครำะห์ใดๆ” ก่อน เช่นข้อมูล Transaction การทำาธุรกรรม ต่างๆของลูกค้าท่ีจะเป็นข้อมูลรายละเอียด แต่เราไม่เคยนำามาวิเคราะห์ หรือรายการขายสินค้าในแต่ละรายการ เพราะโดยมากข้อมูลท่ีเราเคย วิเคราะห์แล้ว มักจะเป็นข้อมูลสรุปตัวเลข ยอดสินค้า ยอดขาย จำานวนลูกค้า แต่รายละเอียดย่อยๆเหล่าน้ี จะเป็นข้อมูลขนาดใหญ่และอาจไม่เคยนำามา วิเคราะห์ 2.กำรทำำ Big Data ต้องลงทุนโครงสร้ำงพ้ืนฐำนมำกน้อยเพียงใด การวิเคราะห์ข้อมูลของ Big Data ท่ีดีต้องมีการลงทุนโครงสร้างพ้ืนฐาน ท่ีแตกต่างจากการจัดทำาฐานข้อมูลแบบเดิมๆหรือการทำาโครงการ Data warehouse ซ่ึงจะเป็นการลงทุนด้าน Data Lake ท่ีจะมาใช้ในการเก็บ ข้อมูลขนาดใหญ่ ดังแสดงรูปท่ี 1 ซ่ึงหลายๆองค์กรจะลงทุนไปกับ เทคโนโลยีอย่าง Hadoop เพราะจะมีค่าใช้จ่ายในการเก็บ Storage ท่ีค่อน ข้างถูกกว่าเทคโนโลยีอ่ืนๆ ดังแสดงในรูปท่ี 2 ท่ีอาจถูกกว่า Database เกือบ 20 เท่า แต่อย่างไรก็ตามการท่ีจะทำา Hadoop cluster ท่ีเป็นแบบ on-Promise ก็ยังมีค่าใช้จ่ายท่ีสูง อาทิเช่นการติดต้ัง Hadoop Servers 18 ตัวอาจมีค่าใช้จ่ายสูงถึง 30 ล้าน ดังแสดงในรูปท่ี 3 210 THANACHART
- 219. รูปท่ี 1 การทำาโครงการ Big Data Analytics โดยการทำา Data Lake รูปท่ี 2 เปรียบเทียบค่าใช้จ่ายการทำา Big Data Platform การทำาโครงการ BIG DATA อย่างรวดเร็ว ควรเร่ิมอย่างไร 211
- 220. ดังน้ันจึงไม่แปลกใจท่ีหน่วยงานจำานวนมากไม่สามารถท่ีจะลงทุน โครงสร้างพ้ืนฐานเร่ืองของ Big Data Platform ได้ เน่ืองด้วยค่าใช้จ่าย ท่ีสูง และอาจคำานวณหาผลตอบแทนในการลงทุนลำาบาก รวมถึงอาจหา Business case ค่อนข้างยาก ข้อสำาคัญการลงทุน Hadoop อาจพบว่าส่วน ใหญ่ก็คือการรวบรวมข้อมูลมาใส่ลงใน Data Lake มากกว่าการใช้ CPU ในการประมวลผลผ่าน Processing Tools อย่าง Hive, Spark, Impala เพราะนานๆคร้ังจะทำาการประมวลผลท่ี และบางคร้ังหากต้องการประมวล ผลก็จะพบว่าความเร็วหรือจำานวน CPU ไม่พอ จึงอาจเกิดคำาถามข้ึนมาว่า เราต้องลงทุนโครงสร้างพ้ืนฐานจำานวนหลายสิบล้านบาทเพียงเพียงเพ่ือใช้ ในการเก็บช้อมูลท่ีเป็น archieve จะคุ้มค่าหรือไม่ รูปท่ี 3 ค่าใช้จ่ายการทำา Hadoop Cluster จำานวน 18 เคร่ือง [ข้อมูลจาก https://blogs.oracle.com] แนวทางท่ีดีสำาหรับการลงทุนโครงการ Big Data คือการใช้บริการ Public Cloud ดังท่ีผมเคยเขียนไว้ในบทความ “Big Data as a Service แนวทางการทำาโครงการ Big Data ท่ีไม่ต้องลงทุนโครงสร้างพ้ืนฐาน” ท้ังน้ี เราจะแยกส่วนการเก็บข้อมูลขนาดใหญ่ท่ีเป็น Data Lake ไว้ใน Cloud Storage อาทิเช่นการใช้ Google Cloud Storage, AWS S3 หรือ Microsoft Azure Blob มาแทนท่ีการใช้ Hadoop HDFS ซ่ึงจะเป็นการ ประหยัดค่าใช้จ่ายกว่าการลงทุน Hadoop Cluster มากและก็มีความ เสถียรของระบบท่ีดีกว่า นอกจากองค์กรก็ยังลดค่าใช้จ่ายในการบริหาร จัดการและดูแลระบบ ซ่ึงจะถูกกว่าการลงทุน Hadoop Cluster หลายสิบ เท่า โดยอาจมีค่าใช้จ่ายเพียงการเก็บข้อมูลเดือนหน่ึงหลักเพียงหม่ืนบาท ในการเก็บข้อมูลเป็น Terabyte ท้ังน้ีข้อมูลท่ีนำามาเก็บบน Cloud 212 THANACHART
- 221. storage ก็เป็นข้อมูลเช่นเดียวกับ Hadoop HDFS ท่ีเน้นข้อมูลท่ีเป็น Archeive ซ่ึงอาจเป็น Warm data หรือ Cold data และหากองค์กรกังวล เร่ืองความปลอดภัยก็สามารถเข้ารหัสก่อนนำาข้อมูลเหล่าน้ีไปเก็บไว้บน Cloud รูปท่ี 4 เปรียบเทียบค่าใช้จ่ายการใช้ Cloud Storageกับ Hadoop HDFS ในด้านการประมวลผล เราก็สามารถท่ีจะใช้จำานวน CPU ไม่จำากัดเพราะ เราสามารถท่ีจะใช้บริการ Hadoop as a Services ท่ีมีค่าใช้จ่ายตามการ ใช้งานเช่นการใช้ Amazon EMR. Google DataProc หรือ Microsoft HDInsight ซ่ึงจะเสียค่าใช้จ่ายน้อยมากตามจำานวน CPU ท่ีใช้ในการ ประมวลผล ซ่ึงจากประสบการณ์ของผมท่ีทำาโครงการ Big Data Analytics ท่ีทาง IMC Institute รับทำาให้กับลูกค้าน้ัน บางคร้ังเราเปิด Server ขนาด 4 vCPU ถึงสามสิบเคร่ือง เสียค่าใช้จ่ายเพียงหลักร้อยบาท ดังน้ันจะเห็น ได้ว่าการลงทุนโครงการ Big Data โดยใช้ Cloud Computing ก็จะลงทุน เพียงเล็กน้อยและสามารถเร่ิมทำางานได้ทันที 3.กำรทำำ Big Data ต้องจะพัฒนำคนเพียงใด การวิเคราะห์ข้อมูล Big Data จะแตกต่างกับการทำาโครงการ Data warehouse ท่ีอาจเน้นการทำา Data Cleansing ซ่ึงจะเน้นการใช้ SQL แต่การทำา Big Data จะต้องการ Developer ท่ีสามารถพัฒนาโปรแกรม อย่างภาษา Python หรือ SQL ได้ ตลอกจนอาจต้องการ Data Sciencetist ท่ีมีความรู้ด้าน Machine Learning Algorithm ต่างๆ หาก ต้องการเห็นการทำา Big Data Analytics อย่างจริงจัง องค์กรจำาเป็นต้อง การทำาโครงการ BIG DATA อย่างรวดเร็ว ควรเร่ิมอย่างไร 213
- 222. พัฒนาบุคลากรข้ึนมาเพ่ือให้ใช้ Processing Tools ต่างๆอย่าง Apache Spark และควรมีความเข้าใจด้าน Machine Learning ซ่ึงระยะต้นท่ีเป็น โจทย์วิเคราะห์ข้อท่ีหน่ึงหรือสอง เราอาจเรียนรู้โดยการว่าจ้าง Outsource มาทำาแล้วทำางานร่วมกัน เพ่ือเป็นการพัฒนาบุคลากรเพ่ือแก้โจทย์ Big Data Analytics อ่ืนๆในอนาคต ธนชาติ นุ่มนนท์ IMC Institute พฤศจิกายน 2560 214 THANACHART
- 223. CHAPTER 45 การอบรม Big Data และกิจกรรม ด้านน้ีของ IMC Institute ในปี 2018 IMC Institute เปิดการอบรมด้าน Emerging Technology ต่างๆท้ัง Cloud computing, Big data, Internet of things และ Blockchain มา เป็นเวลา 5 ปี ตลอดเวลาท่ีผ่านมา IMC Institute ได้มีโอกำสอบรมคน ท้ังหมด 14,882 คน/คร้ัง*(ผู้เข้าอบรมบางท่านอาจเข้าอบรมมากกว่าหน่ึง คร้ัง) โดยแบ่งเป็นการอบรมท่ีเป็นหลักสูตรท่ีเปิดสอนท่ัวไปจำานวน 308 คร้ังมีผู้เข้าอบรม 5,628 คน/คร้ัง หลักสูตรท่ีเป็น In-House ท่ีจัดให้หน่วย
- 224. งานต่างๆจำานวน 195 คร้ังมีผู้เข้าอบรม 6,233 คน/คร้ัง และการอบรมแบบ ฟรีสัมมนาหรืองานฟรีต่างๆจำานวน 43 คร้ังมีผู้เข้าอบรม 3,021 คน/คร้ัง ในการอบรมด้านเทคโนโลยี Big Data ทาง IMC Institute ได้เร่ิมสอน หลักสูตรด้าน Hadoop ต้ังแต่เดือนมีนาคมปี 2013 และในปัจจุบันได้เปิด หลักสูตรออกมาในหลายๆหลักสูตรสำาหรับหลายๆกลุ่ม ท้ังในระดับผู้ บริหารอย่างหลักสูตร Big data for senior management หรือหลักสูตร สำาหรับ Developer หรือ Big Data Engineer อย่าง Big Data Architecture and Analytics Platform และ Big Data Analytics as a Service for Developer หรือ หลักสูตรสำาหรับ Business Analyst อย่าง Business Intelligence Design and Process หรือ Data Visualisation Workshop รวมถึงหลักสูตรด้าน Data Science อย่าง Machine Learning for Data Science รงมถึงมีหลักสูตรท่ีใช้เวลาเรียนท้ังหมด 120 ช่ัวโมงอย่าง Big Data Certication Course ท่ีสอนไปแล้ว 6 รุ่นรวม 180 คน ซ่ึงหลักสูตรด้าน Big Data ท้ังหมดของ IMC Institute แสเงไว้ดัง รูป หากมองถึงจำานวนผู้เข้าอบรมหลักสูตรด้าน Big Data ทาง IMC Institute ได้จัดการอบรมไปท้ังส้ิน 182 คร้ัง แบ่งเป็นการอบรมท่ัวไป 91 คร้ัง, การ อบรม In-house 66 คร้ัง และงานฟรีสัมมนา/Hackaton 25 คร้ัง โดยมี ผู้เข้ำอบรมท้ังส้ินรวม 5,943 คน/คร้ัง เป็นการอบรมท่ัวไป 1,860 คน/คร้ัง, การอบรม In-house 2,045 คน/คร้ัง และงานฟรีสัมมนา/Hackaton 2,038 คน/คร้ัง 216 THANACHART
- 225. ในช่วง 5 ปีท่ีผ่านมาทาง IMC Institute ยังมีการอบรมให้กับอาจารย์ใน สถาบันอุดมศึกษาลักษณะ Train the trainer หลักสูตรด้าน Big Data และ Machine Learning ปีละหน่ึงรุ่นๆละประมาณ 30 คน เพ่ือให้อาจารย์นำา เอาเน้ือหาและเอกสารต่างๆไปสอนกับนักศึกษาในสถาบัน โดยอบรมมา แล้ว 5 รุ่นจำานวนอาจารย์ท่ีมาเรียนกว่า 150 คน และเม่ือสองปีก่อนทาง IMC Institute ก็ได้จัดการอบรมในลักษณะ On the job training ให้กับ นักศึกษาในมหาวิทยาลัยปี 3 และ 4 เป็นเวลาสองเดือนโดยไม่ได้คิดค่าใช้ จ่ายใดๆกับนักศึกษาผู้เข้าอบรม ทาง IMC Institute ได้จัดไปแล้วสองรุ่น มีผู้ผ่านการอบรมจำานวน 26 คน ซ่ึงนักศึกษาปีส่ีท่ีผ่านการอบรมก็เข้าไป ทำางานต่อด้าน Big Data กับบริษัทต่างๆจำานวนมากอาทิเช่น G-Able, Humanica หรือ PTG Energy นอกจากน้ีทาง IMC Institute ก็ยังมีโครงการฟรีสัมมนาทางด้านน้ีเป็น ประจำาทุกเดือนให้กับผู้ท่ีสนใจท่ัวไปเข้าฟัง โดยมีหัวข้อต่างๆอาทิเช่น Big Data on Public Cloud หรือ AI Trend to Realistic cases รวมถึงการจัด Big Data Hackatonในช่วงวันเสาร์-อาทิตย์ท่ีทำามาแล้ว 5 คร้ัง สำาหรับในปี 2018 ทาง IMC Institute ก็ยังเปิดหลักสูตรด้าน Big Data ต่างๆอยู่เป็นจำานวนมากและมีการปรับเน้ือหาให้ผู้เข้าอบรมสามารถเข้าไป ทำางานได้จริงโดยใช้ Public cloud computing service และ Big data as a service ท่ีเป็นบริการบน public cloud ท่ีทำาให้องค์กรต่างๆสามารถ การอบรม BIG DATA และกิจกรรมด้านน้ีของ IMC INSTITUTE ในปี 2018 217
- 226. เร่ืมทำาโครงการ Big Data ได้อย่างรวดเร็ว โดยผู้สนใจสามารถมาดูข้อมูล หลักสูตรต่างๆด้าน Big Data ได้ท่ี >> Big Data Track นอกจากน้ียังมีโครงการอบรมต่างๆท่ีน่าสนใจดังน้ี • Big Data Certication Course รุ่นท่ี 7 ท่ีเป็นหลักสูตร 120 ช่ัวโมง เรียนทุกวันพฤหัสบดีเย็นและวันเสาร์ โดยจะเปิดเรียนวันท่ี 15 มีนาคม 2018 • Big Data Hackathon คร้ังท่ี 6 โครงกำรฟรีให้กับบุคคลท่ีเคยผ่าน หลักสูตรการอบรมแบบ Hands-on ของ IMC Institute โดยจะจัดเพ่ือ ให้ผู้สนใจได้ฝึกการแก้ปัญหากับข้อมูลขนาดใหญ่โดยมีรางวัลเป็น Google Home Mini สำาหรับทีมท่ีชนะแกสมาชิกในทีมท่านละหน่ึง โดย จะจัดข้ึนวันท่ี 24-25 กุมภาพันธ์ 2018 • Big Data School: On the job training รุ่นท่ี 3 เป็นโครงกาiฝึกงานน้ี มีเป้าหมายเพ่ือจะอบรมและสอนให้ผู้เข้าฝึกงานได้เรียนรู้เร่ือง Big Data Technology อย่างเข้มข้น จะทำาให้ผู้เรียนมีทักษะท่ีจะเป็น Data Engineer, Data Analyst และสามารถต่อยอดเป็น Data Scientist ได้ ในการทำาโครงการ Big Data จากการติดต้ัง Big Data Infrastructure จริง ๆ บนระบบ Cloud โดยเป็นโครงกำรอบรมฟรีจำานวนสองเดือนให้ กับนักศึกษาปีท่ี 4 หรือ 3 โดยจัดต้ังแต่วันท่ี 30 พฤษภาคม – 26 กรกฎาคม 2018 หากท่านใดสนใจโครงการอบรมต่างๆเหล่าน้ีก็สามารถติดต่อได้ท่ี [email protected] หรือเบอร์มือถือ 088-192-7975, 087-593-7974 ธนชาติ นุ่มนนท์ IMC Institute มกราคม 2561 218 THANACHART
- 227. CHAPTER 46 Big data ต้องเร่ิมต้นจากการ วิเคราะห์ Transactional data ไม่ ใช่เล่นกับ summary data ผมเคยเข้าไปหลายหน่วยงานท่ีมีความต้องการทำา Big Data Analytics แต่ พอไปถามหาข้อมูลท่ีมีอยู่และจะให้หน่วยงานย่อยต่างๆรวบรวมมาก็มักจะ มองเร่ืองข้อมูลสรุป (Summary data) แต่หน่วยงานกลับคาดหวังว่าจะนำา ข้อมูลสรุปเหล่าน้ีมาวิเคราะห์ข้อมูลต่างๆเช่นพฤติกรรมลูกค้าหรือทำาความ เข้าใจกับปัญหาต่างๆอย่างละเอียด ซ่ึงผมก็มักจะตอบไปว่าทำาได้ยาก การจะทำา Big Data Analytics ท่ีดีได้ต้องมีข้อมูลท่ีเป็นรำยละเอียดย่อย มำกท่ีสุดเท่ำท่ีทำำได้ อาทิเช่น Transactional data ท่ีอาจมองถึงการทำา ธุรกรรมทุกรายการ เพ่ือให้เห็นภาพท่ีชัดเจนข้ึน ผมขอเปรียบเทียบรูปท่ี 1 ซ่ึงเป็นข้อมูลสรุปท่ีบอกถึงการใช้บัตร Startbucks ของลูกค้ารายหน่ึง กับ ข้อมูลท่ีเป็น Transaction ของลูกค้ารายเดียวกันในรูปท่ี 2 จากข้อมูลสรุป ของลูกค้าเราอาจเห็นเพียงว่าลูกค้ามีบัตรสามใบและเป็นลูกค้าบัตรทองท่ีมี วงเงินอยู่ 1,871.25 บาท แต่ถ้าจะถามและวิเคราะห์ข้อมูลต่างๆอาทิเช่น • ลูกค้ามาทาน Starbucks บ่อยแค่ไหน? • ลูกค้าจะมาร้านเวลาไหน และคาดการณ์ว่าเขาจะมาอีกเม่ือไร? • ลูกค้ามาทานกาแฟปกติคนเดียวหรือหลายคน?
- 228. ข้อมูลต่างๆเหล่าน้ี ท่ีเราต้องการทำา Big Data Analytics ในลักษณะการ คาดการณ์จะไม่สามารถท่ีจะหามาได้จากการใช้ Summary data แต่ถ้า เรามีข้อมูลรายละเอียดอย่าง Transaction data ในรูปท่ี 2 เราจะเห็นได้ว่า เราอาจพอคาดการณ์ได้ว่า ลูกค้ารายน้ีมักจะมาทานกาแฟตอนเช้าและอาจ มาคนเดียวโดยดูจากเวลาท่ีมาและอาจดูยอดเงินท่ีใช้จ่าย และหาก Transaction data มีรายละเอียดมากกว่าน้ีเช่น รายการอาหารท่ีส่ัง หรือ สาขาท่ีไปทาน เราก็จะย่ิงสามารถวิเคราะห์ข้อมูลได้ละเอียดย่ิงข้ึน รูปท่ี 1 Summary data บัตร Starbucks ของลูกค้ารายหน่ึง 220 THANACHART
- 229. รูปท่ี 2 Transactional data ของลูกค้ารายเดียวกัน ดังน้ันหลักการสำาคัญของ Big Data Analytics ก็คือการท่ีเราสามารถ เก็บข้อมูล Transactional data ให้มากท่ีสุดและมีรายละเอียดมากท่ีสุด เท่าท่ีทำาได้ ผมมักจะถามคนเสมอว่าหน่วยงานในประเทศหน่วยงานมีข้อมูล ท่ีมีขนาดใหญ่และเหมาะกับการทำา Big Data อย่างมาก หลำยคร้ังผมมัก จะได้ยินคำำตอบว่ำเป็นข้อมูลของกรมกำรปกครองท่ีเก็บข้อมูลประชำชน ซ่ึง โดยแท้จริงแล้วกรมฯจะมีเพียงข้อมูลสรุปและข้อมูลเคล่ือนไหวในลักษณะ Transactional data จะมีน้อยมาก (จึงไม่แปลกใจท่ีบางคร้ังท่ีอยู่ในบัตรก็ ยังไม่ถูกต้องเม่ือเทียบกับท่ีอยู่จริงๆ) แต่จริงๆหน่วยงานท่ีมีข้อมูลเยอะจริงๆ ในประเทศไทยคือกลุ่ม Telecom ท่ีให้บริการโทรศัพท์เคล่ือนท่ี ซ่ึงจะมี ข้อมูลการใช้มือถือตลอดเวลาท่ีป้อนเข้ามาอย่างเช่น CDR ท่ีมีปริมาณ ข้อมูลต่อวันเป็นหม่ืนหรือแสนล้านเรคอร์ด ด้วยข้อมูลมหาศาลขนาดน้ีก็ ทำาให้ผู้ให้บริการมือถือสามารถวิเคราะห์ข้อมูลลูกค้าได้เป็นอย่างดี เพราะ ทราบตำาแหน่ง รูปแบบการใช้งาน เวลาในการโทร โทรศัพท์ท่ีใช้ ค่าใช้จ่าย ต่างๆ นอกเหนือจากกลุ่มผู้ให้บริการโทรศัพท์เคล่ือนท่ีแล้วธุรกิจกลุ่มไหนอีกละ ท่ีมีข้อมูลขนาดใหญ่ในลักษณะ Transactional data BIG DATA ต้องเร่ิมต้นจากการวิเคราะห์ TRANSACTIONAL DATA ไม่ใช่เล่นกับ SUMMARY DATA 221
- 230. • ธนาคารจะมีข้อมูล Transaction จากการท่ีลูกค้ามาทำาธุรกรรมท่ีสาขา, Intenet banking หรือ mobile banking และหากมีข้อมูลจาก QR payment ในอนาคตก็จะมีข้อมูลลูกค้าละเอียดย่ิงข้ึน • หลักทรัพย์ก็จะมีธุรกรรมการซ้ือขายแต่ละรายการอย่างละเอียด ทำาให้ ทราบว่าใครซ้ือขาย หุ้นตัวไหน เวลาใด • ค้าปลีกจะมีข้อมูลรายการซ้ือ ขายและส่ังสินค้ามาอย่างละเอียด และถ้า สามารถเก็บข้อมูลลูกค้าได้ ก็จะย่ิงทำาให้เข้าใจได้ว่าลูกค้าคือใคร ย่ิงมี จำานวนธุรกรรมมากข้ึนเท่าไรก็ย่ิงสามารถวิเคราะห์ได้ละเอียดย่ิงข้ึน • โรงพยายบาลก็จะมีข้อมูลการเข้ามาตรวจรักษาของลูกค้า การส่ังยา • Smart home จะมีข้อมูล Log การใช้งานอุปกรณ์ต่างๆ จากท่ีกล่าวมาท้ังหมดน้ีจะเห็นได้ว่าถ้าเราจะทำา Big Data Analytics ได้ดี เราต้องพยายามหา Transactional data มาเก็บให้มากท่ีสุด อาทิเช่น • หากภาครัฐมีข้อมูลรายละเอียดการจ่ายภาษี VAT ของผู้เสียภาษีแบบ ปลีกย่อยมาท่ีสุดลงเป็นรายการ รายวัน หรือมีข้อมูลรายรับของ ประชาชนเป็นรายการย่อยมากท่ีสุดก็จะทำาให้วิเคราะห์และประมาณการ ภาษีได้อย่างถูกต้อง • หากเราต้องการทราบข้อมูลคนจนท่ีลงทะเบียนผู้มีรายได้น้อยของภาค รัฐ เราอาจต้องเก็บข้อมูลการใช้บัตรคนจนตามร้านธงฟ้าหรือบริการ ต่างๆของภาครัฐเป็นรายการย่อยๆท้ังหมด เราก็อาจวิเคราะห์พฤติกรรม และตอบได้ว่าคนเหล่าน้ีจนจริงหรือไม่ • หากกระทรวงสาธารณสุขมีข้อมูลรายละเอียดการใช้บริการการแพทย์ ของประชาขน อย่างละเอียดมากท่ีสุด เราก็จะสามารถบริหารงานด้าน สาธารณสุขให้มีประสิทธิภาพได้ดีย่ิงข้ึน ดังน้ันการเร่ิมทำา Big Data จำาเป็นต้องคำานึงถึง Transactional data ท่ี มีในองค์กรและต้องเอามาเก็บให้ได้เสียก่อน ถึงจะทำาการวิเคราะห์ข้อมูลได้ อย่างถูกต้อง ไม่ใช่เป็นการเล่นกับ Summary data โดยเราอาจต้องต้ังคำา ถามว่าเรามีข้อมูลลูกค้าแต่ละรายหรือข้อมูลสินค้าแต่ละรายการมากพอท่ี จะมาทำาการวิเคราะห์หรือไม่ ถ้ามีข้อมูลลูกค้าเพ่ือเดือนละรายการมัน เพียงพอไหม หรือควรจะต้องเห็นทุกวัน หรือต้องเห็นทุกช่ัวโมง หรือบาง 222 THANACHART
- 231. อย่างอาจมีข้อมูลทุกนาที ข้ึนอยู่กับธุรกิจและลักษณะงานแล้วเราถึงจะ วิเคราะห์ข้อมูลได้ ธนชาติ นุ่มนนท์ IMC Institute มกราคม 2561 BIG DATA ต้องเร่ิมต้นจากการวิเคราะห์ TRANSACTIONAL DATA ไม่ใช่เล่นกับ SUMMARY DATA 223
- 233. CHAPTER 47 Mini Project ในหลักสูตร Big data certification เม่ือวันเสาร์ท่ี 20 มกราคม ทาง IMC Institute ได้จัดให้ผู้เรียนหลักสูตร Big Data Certication รุ่นท่ี 6 ท่ีเรียนกันมาส่ีเดือนต้ังแต่เดือนกันยายนปี ท่ีแล้ว รวม 120 ช่ัวโมง ได้มานำาเสนอ Mini-project ของตัวเองโดยมีผู้นำา เสนอสามกลุ่มคือ • กลุ่ม Anime Recommendation ท่ีมีการนำาข้อมูลการดูการ์ตูนจำานวน 7.8 ล้านเรคอร์ดจากหนังการ์ตูน 12,294 เร่ืองจาก Kaggle มาทำา Recommendation โดยใช้ ALS algorithm, ทำา Clustering โดยใช้
- 234. K-Means algorithm และมีการวิเคราะห์จำานวนการดูหนังแบบ Real- time โดยใช่ KafKa และ Spark streaming (Slide การนำาเสนอ สามารถดูได้ท่ี >> Anime slide) • กลุ่ม Telecom churn analysis ท่ีมีการวิเคราะห์การย้ายค่ายโทรศัพท์ มือถือของผู้ใช้ โดยการนำาข้อมูลมาวิเคราะห์ดูลักษณะของการย้ายค่าย ทำา Visualisation แสดงผลการวิเคราะห์ต่างๆและมีการทำา Predictive analytic โดยใช้ Decision Tree Algorithm (Slide การนำาเสนอ สามารถดูได้ท่ี >> Telecom churn slide) • กลุ่ม Crime Analysis เป็นการนำาข้อมูลอาชญากรรมในเมือง Chicago จำานวน 6 ล้านเรคอร์ด มาทำา Classication โดยใช้ Decision Tree Algorithm เพ่ือจะวิเคราะห์ว่าอาชญกรรมกรณีไหน ในสถานการณ์และ วันอย่างไร ท่ีมีโอกาสท่ีจะจับผู้ร้ายได้สูง (Slide การนำาเสนอสามารถดู ได้ท่ี >> Crime analysis slide) ผมพบกว่านำาเสนอของท้ังสามกลุ่ม เข้าใจหลักการของการทำา Big data ได้ เป็นอย่างดีต้ังแต่ การทำาความเข้าใจปัญหา การเตรียมข้อมูล การใช้ เทคโนโลยีและเคร่ืองมือต่างๆ และรวมถึงการใช้ Algorithm ในการ วิเคราะห์ แต่ผัญหาท่ีเรามักจะเห็นมนบ้านเรากลับเป็นเร่ืองของข้อมูลท่ียังมี 226 THANACHART
- 235. ไม่มากทำาให้ขาดโอกาสท่ีจะใช้ความรู้ในการวิเคราะห์ข้อมูลของบ้านเรา มากกว่า ซ่ึงหากมีข้อมูลคนท่ีผ่านหลักสูตร Big data certication เหล่า น้ีจำานวน 6 รุ่นแล้ว ก็น่าจะเป็นกำาลังสำาคัญท่ีเข้ามาช่วยพัฒนาการวิเคราะห์ ข้อมูลขนาดใหญ่ในบ้านเราได้ในอนาคต สำาหรับ IMC Institute เราก็จะจัดงานเพ่ือให้ผู้ทีผ่านการอบรมหรือ บุคคลท่ัวไปได้ลองมาแข่งกันทำา Mini project ในลักษณะน้ี ในโครงการท่ี ช่ือว่า Big data hackathon โดยต้ังใจจะจัดข้ึนในวันท่ี 24-25 กุมภาพันธ์น้ี โดยไม่มีค่าใช้จ่ายใดๆ ซ่ึงผู้สนใจสามารถติดต่อเข้าร่วมโครงการสามารถดู รายละเอียดการสมัครได้ท่ี www.imcinstitute.com/hackathon ภายใน วันท่ี 16 กุมภาพันธ์ พ.ศ. 2561 ธนชาติ นุ่มนนท์ IMC Institute มกราคม 2561 MINI PROJECT ในหลักสูตร BIG DATA CERTIFICATION 227
- 237. CHAPTER 48 จะทำา Big Data ต้องเร่ิมต้นท่ีทำา Data Lake ช่วงน้ีเห็นหน่วยงานต่างๆออกมาพูดเร่ือง Big Data กันอย่างมาก บางคนก็ บอกว่าหน่วยงานใช้ Big Data ในการบริหารและตัดสินใจ บ้างก็บอกว่าใช้ ในการวิเคราะห์พฤติกรรมประชาชนหรือลูกค้า เราพูดเหมือนกับว่าตอนน้ี บ้านเราเร่ืองน้ีก้าวหน้าไปมาก เสมือนว่าเรามีข้อมูลใหญ่มหาศาลท่ีเก็บและ นำามาใช้แล้ว เสมือนว่าเรามีโครงสร้างพ้ืนฐานด้านข้อมูลท่ีดีพอ และเสมือน ว่าเรามีนักวิเคราะห์ข้อมูลจำานวนมาก แต่พอหันกลับไปถามว่า แล้ว Big Data ท่ีว่าข้อมูลใหญ่แค่ไหน บางคน
- 238. พูดแค่หลักล้านต้นๆ ไม่มี Transaction Data พอพูดถึงข้อมูลท่ีเปิดออกมา (Open data) ก็กลายเป็นแค่ Summary data บ้างก็เปิดมาในรูป PDF ไม่ใช่ข้อมูลในฟอร์แมทดิจิทัลท่ีพร้อมใช้งาน (อย่าง CSV) ท้ังท่ีการทำา Big Data ต้องเน้นท่ีการมี Transactional Data หรือ Detail Data ท่ีเก็บ รายละเอียดให้มากท่ีสุด ซ่ึงผมเคยเขียนบทความเร่ือง “Big data ต้อง เร่ิมต้นจากการวิเคราะห์ Transactional data ไม่ใช่เล่นกับ summary data” แต่ก็แปลกใจท่ีหลายๆหน่วยงานบอกว่าทำา Big Data แต่แทบไม่มี การนำา Transactional Data มาวิเคราะห์แต่อย่างใด อีกประเด็นท่ีสำาคัญคือโครงสร้างพ้ืนฐาน ท่ีเคยเน้นบ่อยๆว่า เราต้องปรับ โครงสร้างพ้ืนฐานด้านข้อมูล (Information infrastructure) โดยเน้นท่ี การทำา Data Lake แล้วใช้ Data Science ไม่ใช่การทำา Data Warehouse แล้วใช้ Business Intelligence ในรูปแบบเดิมๆ ซ่ึงผมเคย เขียนเร่ืองน้ีในบทความ “การทำาโครงการ Big Data อย่างรวดเร็ว ควรเร่ิม อย่างไร” แต่ในปัจจุบันหลายๆหน่วยงานก็ยังไม่เข้าใจกับการทำา Data Lake แล้วก็ยังเน้นไปท่ี Data Warehouse อย่างเดิมท้ังๆท่ี Data Warehouse จะไม่สามารถรองรับข้อมูลขนาดใหญ่ (Volume) หรือข้อมูล หลากหลายประเภท (Variety) ซ่ึงเป็นนิยามสำาคัญของ Big Data ได้ Data Lake คืออะไร Tamara Dull จาก SAS ให้คำานิยามของ Data Lake ไว้ว่า Dark lake is a storage repository that holds a vast amount of raw data in its native format, including structured, unstructured and semi-structured data. The data structure and requirements are not deEned until the data is needed. จะเห็นได้ว่า Data Lake คือคลังข้อมูลขนาดใหญ่มหาศาล ซ่ึงเราจะใช้ เก็บข้อมูลท่ีเป็น Raw data ในหลากหลายรูปแบบท้ัง Structure, unstructure หรือ semi-structure โดยข้อมูลท่ีเก็บจะยังไม่ต้องคำานึงถึง โครงสร้างหรือนิยามการใช้งานในตอนต้น 230 THANACHART
- 239. รูปท่ี 1 องค์ประกอบต่างๆของ Data Lake เทคโนโลยีท่ีใช้เป็น Data Lake โดยมากคือ Hadoop เพราะมีราคาถูก กว่าเทคโนโลยีอ่ืนๆและมีเคร่ืองมือในการประมวลผลได้ ในขณะท่ี Database หรือ No SQL จะมีข้อจำากัดท่ีขนาดของข้อมูลหรือรูปแบบข้อมูล ท่ีจะนำามาเก็บซ่ึงอาจได้เฉพาะ Structure data หรือ semi-structure data บางประเภท นอกจาก Hadoop ก็อาจมีเทคโนโลยีอ่ืนท่ีเหมาะในการ ทำาเป็น Data lake ก็คือ Cloud storage หรือ Object storage ท่ีราคาถูก กว่า ซ่ึงข้ึนอยู่กับหน่วยงานว่าจะเลือกเทคโนโลยีใดมาเป็น Data Lake ข้อมูลท่ีเก็บใน Data Lake จะเป็น Raw Data ท่ีไม่สามารถแก้ไขได้ แต่ จะทำาให้ผู้ใช้สามารถตรวจสอบและดูรายละเอียดของข้อมูลได้มากท่ีสุด และอาจดูข้อมูลย้อนหลังได้ แต่จุดด้อยของข้อมูลใน Data Lake คือยังเป็น ข้อมูลดิบท่ีอาจไม่สมบูรณ์และขาดความถูกต้อง (Poor quality of data) ซ่ึงผู้ใช้งานเช่น Data developer หรือ Data science จะต้องทำาการ Cleansing ข้อมูลก่อนให้ Data analyst หรือ Business user นำาไป ใช้งาน นอกจากก็อาจมีเร่ืองของความปลอดภัยของข้อมูล ดังน้ันการใช้งาน Data lake จำาเป็นต้องมีการทำา Data Governance ท่ีดี กำรจัด Zone สำำหรับ Data Lake เน่ืองจาก Data Lake เป็นท่ีเก็บข้อมูลขนาดใหญ่ซ่ึงมาจากหลายแหล่ง รวมถึงข้อมูลท่ีผ่านการประมวลผลแล้ว ดังน้ันการติดต้ัง Data Lake จะต้อง ทำาการแบ่งออกเป็นโซนต่างๆ ท้ังหมด 4 ส่วน ดังน้ี จะทำา BIG DATA ต้องเร่ิมต้นท่ีทำา DATA LAKE 231
- 240. รูปท่ี 2 แสดงโซนต่างๆ ของ Data Lake (จาก Data Lake Governance Best Practices, Parth Patel and Adam Diaz) 1. Transient Zone ข้อมูลท่ีเข้าสู่ Data Lake จะถูกนำามาพักไว้ใน Zone น้ีก่อนบันทึกลง Storage 2. Raw Zone เป็นข้อมูลดิบท่ียังไม่ผ่านการทำาความสะอาดหรือปรับ รูปแบบใดๆ ซ่ึงโดยส่วนใหญ่แล้วนักพัฒนาข้อมูล หรือนัก วิทยาศาสตร์ข้อมูลมักจะใช้ข้อมูลใน Raw Zone น้ี 3. Trusted Zone เป็นข้อมูลท่ีมาจาก Raw Zone ซ่ึงผ่านกระบวนการ ทำาความสะอาดข้อมูลตามมาตรฐานและกฎเกณฑ์ท่ีกำาหนดแล้วเพ่ือ คุณภาพข้อมูล ข้อมูลใน Zone น้ีเป็นแหล่งข้อมูลหลักท่ีจะถูกใช้โดย นักวิเคราะห์ข้อมูลและผู้ใช้โดยท่ัวไป เพ่ือให้สามารถใช้ข้อมูลได้ง่าย 4. Rened Zone เป็นข้อมูลท่ีผ่านกระบวนการประมวลผลแล้ว กำรจัดทำำ Data Catalog การแบ่งโฟลเดอร์ต่างๆ ใน Data Lake อาจช่วยทำาให้ผู้ใช้สามารถเข้าใจ โครงสร้างข้อมูลต่างๆ ท่ีอยู่ใน Hadoop Cluster ได้ดีข้ึน แต่ยังจำาเป็น ต้องหาเคร่ืองมือมาทำา Data Catalog เพ่ือ • เพ่ิมประสิทธิภาพของการค้นหาข้อมูล ทำาให้ค้นหาข้อมูลได้เร็วและ สะดวกข้ึน • จัดการสิทธิการเข้าถึงข้อมูลได้ดีข้ึน โดยเฉพาะข้อมูลท่ีอาจละเมิดสิทธิ ส่วนบุคคล • สามารถลดค่าใช้จ่ายในการเก็บข้อมูลซ้อนหรือกักตุนข้อมูล 232 THANACHART
- 241. • สนับสนุนการติดตามข้อมูลตลอดท้ังวงจรชีวิต ของข้อมูลทำาให้การทำา Data Governance สะดวกและปลอดภัยข้ึน โดยเฉพาะข้อมูลท่ี เก่ียวข้องทางด้านกฎหมาย ควรจะต้องเป็นเคร่ืองมือท่ีสามารถทำา Catalog ได้โดยอัตโนมัติและ สามารถใช้งานได้โดยง่าย ซ่ึงในปัจจุบันมีผู้ผลิตหลายราย เช่น Teradata Loom, Waterline Data Invertory, Cloudera Navigator, Informatica Governed หรือ Apache Atlas เป็นต้น กำรใช้งำน Data Lake เราสามารถสรุปตัวอย่างการทำางานต่างๆของ Data Lake ได้ในรูปท่ี 3 ซ่ึงจะเห็นข้ันตอนต่างๆในการใช้งาน Data Lake (ในรูปคือ Hadoop ท่ี อาจใช้ Distribution ต่างๆอาทิเช่น Cloudera, Hortonworks หรือ MapR) ดังน้ี รูปท่ี 3 Data Lake WorkFow (จาก Enterprise Data Lake: Architecture Using Big Data Technologies – Bhushan Satpute) 1. มีการดึงมูลจากแหล่งต่างๆอาทิเช่น Transaction, OLTP, Document, IoT หรือ Social Media เข้ามาเก็บใน Data Lake 2. ข้อมูลท่ีดึงเข้ามาอาจเป็น Real-time streaming data ในบางกรณี 3. กรณีข้อมูลท่ีเก็บใน Data lake เป็นข้อมูลท่ีมีความอ่อนไหว (sensitive data) เราอาจต้องทำาการเข้ารหัสข้อมูล 4. Data developer สามารถใช้เคร่ืองมือในการประมวลข้อมูลท่ีมากับ จะทำา BIG DATA ต้องเร่ิมต้นท่ีทำา DATA LAKE 233
- 242. Data Lake เช่น Apache spark หรือ Hive เพ่ือปรับปรุงข้อมูลให้มี คุณภาพมากข้ึน และอาจเก็บใน Trusted zone 5. ทำาการเคล่ือนย้ายข้อมูลท่ีมีคุณภาพมากข้ึนเข้าสู่ Data warehouse เพ่ือให้นักวิเคราะห์ข้อมูล (Data Analyst) หรือผู้ใช้ท่ัวไป (Business user) ใช้งานต่อ 6. มีการสร้าง Schema หรือ meta-data ของข้อมูล รวมถึงการทำา Governance 7. นักวิเคราะห์ข้อมูลหรือผู้ใช้ท่ัวไป สามารถใช้เคร่ืองมืออย่าง Data visualization เพ่ือวิเคราะห์ข้อมูลจาก Data warehouse ได้ 8. Data scientist หรือ Data developer ก็สามารถท่ีจะเข้าถึงข้อมูล ของ Data Lake แล้วนำาข้อมูลมาทำา Big data analytics ได้ ท่ีเขียนมาท้ังหมดน้ีก็เพ่ือสร้างความเข้าใจให้เห็นภาพว่า หัวใจสำาคัญของ การทำา Big data เร่ืองหน่ึงคือการพัฒนา Data Lake ในองค์กร ธนชาติ นุ่มนนท์ IMC Institute มีนาคม 2561 234 THANACHART
- 243. TRAINING | IT TRENDS 35 COURSE SCHEDULE 2018 DESCRIPTION LEVELRATE DAY DECNOVOCTSEPAUGJULJUNAPRMARFEBJAN MAY BIG DATA CERTIFICATION COURSE INSTRUCTOR: ASSOC. PROF. DR. THANACHART NUMNONDA ASST. PROF. DR. PUTCHONG UTHAYOPAS MR. DANAIRAT THANABODITHAMMACHARI MR. TEERACHAI LAOTHONG MR. AEKANUN THONGTAE MR. KOMES CHANDAVIMOL BIG DATA IN ACTION FOR SENIOR MANAGEMENT INSTRUCTOR: ASSOC. PROF. DR. THANACHART NUMNONDA AND TEAM BIG DATA ARCHITECTURE AND ANALYTICS PLATFORM INSTRUCTOR: MR.AEKANUN THONGTAE AND ASSOC. PROF. DR. THANACHART NUMNONDA" BIG DATA ANALYTICS AS A SERVICE FOR DEVELOPER INSTRUCTOR: MR.AEKANUN THONGTAE AND ASSOC. PROF. DR. THANACHART NUMNONDA BIG DATA MODELING WITH NOSQL INSTRUCTOR: MR.AEKANUN THONGTAE AND MR. TEERACHAI LAOTHONG INTRODUCTION TO IOT ANALYTICS USING HADOOP INSTRUCTOR: MR. AEKANUN THONGTAE" MACHINE LEARNING FOR DATA SCIENCE INSTRUCTOR: MR. AEKANUN THONGTAE DATA VISUALISATION WORKSHOP INSTRUCTOR: MR. KOMES CHANDAVIMOL BUSINESS INTELLIGENCE DESIGN AND PROCESS IMC INSTITUTE INSTRUCTOR: FINTECH FOR SENIOR MANAGEMENT INSTRUCTOR: ASSOC. PROF. DR. THANACHART NUMNONDA AND TEAM BLOCKCHAIN FOR MANAGEMENT AND EXECUTIVES INSTRUCTOR: MR.TITITORN SEMANGERN BLOCKCHAIN TECHNOLOGY FOR DEVELOPER INSTRUCTOR: MR. TEERACHAI LAOTHONG BUSINESS TRIP TO CHINA INFORMATION TECHNOLOGY EXPO (CITE) BUSINESS TRIP CLOUD EXPO ASIA 2018 BUSINESS TRIP TO CHINA HI-TECH FAIR DIGITAL TRANSFORMATION STRATEGY INSTRUCTOR: ASSOC. PROF. DR. THANACHART NUMNONDA AND MR. PRINYA HOM-ANEK PRACTICAL CLOUD COMPUTING FOR SENIOR MANAGEMENT INSTRUCTOR: ASSOC. PROF. DR. THANACHART NUMNONDA AND TEAM PRACTICAL AZURE WORKSHOP INSTRUCTOR: MR. TEERACHAI LAOTHONG ARCHITECTING WITH GOOGLE CLOUD PLATFORM INSTRUCTOR: ASSOC. PROF. DR. THANACHART NUMNONDA AND TEAM AZURE IOT, MACHINE LEARNING AND ADVANCED ANALYTICS INSTRUCTOR: MR. TEERACHAI LAOTHONG 59,000BAHT BRINGYOUROWNCOMPUTER 10,900BAHT (EARLYBIRD9,900) 8,900BAHT (8,500WITHYOURNOTEBOOK) 10,900BAHT (8,500WITHYOURNOTEBOOK) 12,900BAHT (10,900WITHYOURNOTEBOOK) 10,900BAHT (8,900WITHYOURNOTEBOOK) 12,900BAHT (10,900WITHYOURNOTEBOOK) 9,900BAHT (EARLYBIRD9,500) BRINGYOUROWNCOMPUTER 15,900BAHT (12,900WITHYOURNOTEBOOK) 10,900BAHT (EARLYBIRD9,900) 8,900BAHT (EARLYBIRD8,500) PLEASEBRINGYOURNOTEBOOK 8,900BAHT (EARLYBIRD8,500) PLEASEBRINGYOURNOTEBOOK 25,000BAHT 45,000BAHT 25,000BAHT 56,000BAHT(COURSEONLY36,900BAHT) (BUSINESSTRIPONLY25,000BAHT) CHINAINFORMATION TECHNOLOGYEXPO 59,000BAHTEARLYBIRD55,000BAHT (COURSEONLY11,900BAHT)(BUSINESSTRIP ONLY45,000BAHT)CLOUDEXPOASIA2017 10,900BAHT (8,500BAHTWITHYOURNOTEBOOK) 10,900BAHT (8,900BAHTWITHYOURNOTEBOOK) 10,900BAHT (8,500BAHTWITHYOURNOTEBOOK) INTER MEDIATE BASIC INTER MEDIATE BASIC INTER MEDIATE INTER MEDIATE ADVANCE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE ADVANCE ADVANCE TRAINING (120HR.) 2 3 3 3 3 3 3 5 2 2 2 4 3 3 5 3 3 3 3 - - - - - - - - - - 22-24 JAN - - - - - - - - - - - - - - - - 21-23 MAR - - - - 10-11 APR - 8-11 APR - - - - - 23-25 APR - 28-29 MAY - 3-4 MAY - - - - - 16-18 MAY - - - - - - - - - - - - - 25-26 OCT - - - 9-11OCT - รุ่นที่2 TRAINING 18,25SEP, 2,9,16OCT - 29-31 OCT - - 13-14 NOV - - - TBD - - - - - - - 3-4 DEC - - - - - - - - - 16-17 JUL - - - - - - - - 23-24 JUL - - 9-10 AUG - - - - - - - - - - - - - - - 5-7 SEP - - - - - - - - - - - - - - 7-9 FEB - 21-23 FEB 13-15 FEB - - - 16-17 AUG - - - - - - - - - 18-20 JUL - 3-5 JUL - - - - - 20-22 MAR - 6-8 MAR - - - - 19-20 APR - - - - - 3-5 APR - - - - - - - - - - - - - - - - - - 2-4 OCT - - 17-19 OCT 9-11 OCT - - - - 6-8 NOV 27-29 NOV - - 19-23 NOV - 19-21 DEC - - - - - - - - 5-7 JUN - 26-28 JUN 20-22 JUN - เริ่มเรียน15มีนาคม2018(120HR.) เรียนทุกวันพฤหัสบดีตอนเย็น18.00-21.00น. และวันเสาร์9.00-17.00น. 28MAY-1JUN เริ่มเรียน13กันยายน2018(120HR.) เรียนทุกวันพฤหัสบดีตอนเย็น18.00-21.00น. และวันเสาร์9.00-17.00น. BIG DATA TRACK BLOCKCHAIN TRACK BUSINESS TRIPS TRACK DIGITAL TRANSFORMATION TRACK CLOUD COMPUTING TRACK TRAINING 3-5OCT BUSINESSTRIP 9-11OCT รุ่นที่1 TRAINING 27FEB, 6,13,20,27MAR
- 244. IT TRENDS | TRAINING36 ENTERPRISE ARCHITECTURE IN CLOUD ERA INSTRUCTOR: MR. DANAIRAT THANABODITHAMMACHARI AND ASSOC. PROF. DR. THANACHART NUMNONDA" SOA/SOA GOVERNANCE FOR EXECUTIVES INSTRUCTOR: MR. TEERACHAI LAOTHONG AND ASSOC. PROF. DR. THANACHART NUMNONDA" IT ARCHITECTURE FOR THE FUTURE MR. SUTUM CHAIYAWAT SOA DESIGN PATTERNS INSTRUCTOR: MR. TEERACHAI LAOTHONG SMINGFRAMEWORK IOT DEVICE (ESP8266) (C++) INSTRUCTOR: MR. SITTIPONG JANSORN RASPBERRY PY WIN10 IOT CORE (C#) INSTRUCTOR: MR. SITTIPONG JANSORN RASPBERRY PI PYTHON PROGRAMMING (PYTHON) INSTRUCTOR: MR. SITTIPONG JANSORN ARDUINO PROGRAMMING IOT STARTING POINT INSTRUCTOR: MR. SITTIPONG JANSORN INTERNET OF THINGS DEVELOPMENT WITH ANDROID INSTRUCTOR: MR. SITTIPONG JANSORN IPHONE DEVELOPMENT USING SWIFT INSTRUCTOR: MR. THONGROP RODSAVAS ADVANCED IPHONE DEVELOPMENT USING SWIFT INSTRUCTOR: MR. THONGROP RODSAVAS AUTOMATE TESTING FOR IOS APPLICATION ON SWIFT INSTRUCTOR: MR. SOMKIAT PUISUNGNOEN AND MR. THAWATCHAI JONGSUWANPISAN AUTOMATE TESTING FOR ANDROID APPLICATION INSTRUCTOR: MR. SOMKIAT PUISUNGNOEN AND MR. THAWATCHAI JONGSUWANPISAN DESIGNING CROSS-PLATFORM MOBILE APPLICATION WITH CLOUD ARCHITECTURE INSTRUCTOR: MR. TEERACHAI LAOTHONG PROJECT MANAGEMENT ESSENTIALS INSTRUCTOR: MR. PIYA CHIEWCHARAT AGILE PROJECT MANAGEMENT INSTRUCTOR: SIAM CHAMNANKIT LEAN IT OVERVIEW INSTRUCTOR: MR. PIYA CHIEWCHARAT ITSERVICEMANAGEMENTOVERVIEWITIL&ISO20000(V2011) INSTRUCTOR: MR. PIYA CHIEWCHARAT SOURCECODEMANAGEMENTWITHGIT INSTRUCTOR: MR. PRATHAN DANSAKULCHAROENKIT AND MR. SOMKIAT PUISUNGNOEN TEST-DRIVENDEVELOPMENTONJAVA INSTRUCTOR: MR. SOMKIAT PUISUNGNOEN AND MR. THAWATCHAI IT TRENDS: SEMINAR 2019 OUTLINE L REGISTER INSTRUCTOR: 20 INSTRUCTOR FROM IT INDUSTRY 8,900BAHT (EARLYBIRD7,900) REGISTRATION3PERSONSPAYONLY2 10,900BAHT (EARLYBIRD9,500) REGISTRATION3PERSONSPAYONLY2" 59,000BAHTEARLYBIRD55,000BAHT (COURSEONLY11,900BAHT)(BUSINESSTRIP ONLY45,000BAHT)DATACENTERWORLD2017 10,900BAHT (9,500WITHYOURNOTEBOOK) 9,900BAHT (EARLYBIRD9,500) BRINGYOUROWNCOMPUTER 8,900BAHT (EARLYBIRD8,500) BRINGYOUROWNCOMPUTER 9,900BAHT (EARLYBIRD9,500) BRINGYOUROWNCOMPUTER 5,900BAHT (EARLYBIRD5,500) BRINGYOUROWNCOMPUTER 10,900BAHT (EARLYBIRD10,500) BRINGYOUROWNCOMPUTER 12,900BAHT (EARLYBIRD11,900) BRINGYOUROWNCOMPUTER 12,900BAHT (EARLYBIRD11,900) BRINGYOUROWNCOMPUTER 11,900BAHT (EARLYBIRD10,900) BRINGYOUROWNMACBOOK 11,900BAHT (EARLYBIRD10,900) BRINGYOUROWNCOMPUTER 13,900BAHT (11,900WITHYOURNOTEBOOK) 17,900BAHT (EARLYBIRD15,900) 11,900BAHT (EARLYBIRD10,900) 6,900BAHT (EARLYBIRD6,500) 17,900BAHT (EARLYBIRD15,900) 8,900BAHT (EARLYBIRD8,500) BRINGYOUROWNCOMPUTER 8,900BAHT (EARLYBIRD8,500) BRINGYOUROWNCOMPUTER 7,900BAHT (SPECIALREGISTERFOR3PERSONSFOR ONLY19,900BAHT) INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE 2 2 2 2 3 2 3 1 4 5 4 2 2 5 3 2 1 3 2 2 2 - - - - - - - - - - - - - - - 25-26 JAN - - - - - - - - - 1-3 FEB - - 12 FEB - - 6-9 FEB - - - 12-14 FEB - - - 19-20 FEB - - 26-27 MAR - - 29-30 MAR - 15-16 MAR - - - 5-9 MAR - 12-13 MAR - - - - 16 MAR - - - - - 26-27 APR 2-3 APR - - - 9-11 APR - - - - - - - - - - - - - - - - - - - - - - 14-17 MAY - - - 14-15 MAY 21-25 MAY - - - 2-4 MAY - - - - - - - 4-6 JUN - - - - - - - - - - - - - - 18-19 JUN - - - BUSINESS TRIP ............. - - - - - 8-11 OCT - - - - - - - - - - - - 22-24 NOV - - - - - - - - 5-9 NOV - - 15-16 NOV 26-30 NOV 28-30 NOV - - - - - - - 6-7 DEC - - - - - - - - - - - - - - - - - 17-18 DEC 13-14 DEC 9-10 JUL - - - - - - 11 JUL - 2-6 JUL - - - - 23-24 JUL - - - - - - - 2-3 AUG - - - 20-21 AUG - - - - 7-10 AUG - - - - 28-29 AUG 20 AUG - - - - - - 13-14 SEP 17-18 SEP - - 19-21 SEP - - - - 10-11 SEP - - - - - 26-28 SEP 24-25 SEP - - DESCRIPTION LEVELRATE DAY DECNOVOCTSEPAUGJULJUNAPRMARFEBJAN MAY IT ARCHITECTURE/STRATEGY TRACK INTERNET OF THINGS (IOT) TRACK MOBILE DEVELOPMENT TRACK PROJECT/SERVICE MANAGEMENT TRACK SOFTWARE DEVELOPMENT TRACK IT TRENDS TRACK
- 245. TRAINING | IT TRENDS 37 SALESTRAININGCONDENSEDCOURSE OUTLINE L REGISTER INSTRUCTOR: IMC INSTITUTE TEAM "EFFECTIVENEGOTIATIONSKILLS OUTLINE L REGISTER IMC INSTITUTE TEAM "HOWTOCREATEVALUEADDEDTOITSOLUTION OUTLINE L REGISTER INSTRUCTOR: IMC INSTITUTE TEAM 10,900BAHT (EARLYBIRD9,900BAHT) 6,500BAHT (EARLYBIRD5,900BAHT) 6,900BAHT (EARLYBIRD6,500BAHT) BASIC BASIC BASIC 1 1 1 INTRODUCTIONTODOCKER INSTRUCTOR: MR. SOMKIAT PUISUNGNOEN" DESIGNINGANDIMPLEMENTINGHYBRIDCLOUDAPPLICATION INSTRUCTOR: MR. TEERACHAI LAOTHONG" DESIGNPATTERNS&CODEARCHITECTURE INSTRUCTOR: MR. PASSAPONG THAITHATGOON" MICROSERVICEONJAVAPLATFORM INSTRUCTOR: MR. PASSAPONG THAITHATGOON" AGILEWORKSHOP:ANALTERNATIVESOFTWAREDEVELOPMENT INSTRUCTOR: SIAM CHAMNANKIT" BASICSOFTWARETESTING INSTRUCTOR: MS. CHERAPA WANNASUK AGILETESTINGINPRACTICE INSTRUCTOR: SIAM CHAMNANKIT SECURESOFTWARELIFECYCLE INSTRUCTOR: MS. CHERAPA WANNASUK REQUIREMENTANALYSIS,DESIGNANDMANAGEMENT INSTRUCTOR: MS. CHERAPA WANNASUK ISTQB-CERTIFIEDTESTERFOUNDATIONLEVEL(CTFL)TRAINING INSTRUCTOR: MR. NARUPAT KUMNURTRATH ISO/IEC27001:2013FUNDAMENTALTRAININGCOURSE FOR EXECUTIVE OUTLINE L REGISTERINSTRUCTOR MS. WANPEN PUANGRAT" ISO/IEC27001:2013INTRODUCTIONANDIMPLEMENTATION OUTLINE L REGISTERINSTRUCTOR MS. WANPEN PUANGRAT" ISO/IEC27001:2013IMPLEMENTATIONANDINTERPRETATION COURSE OUTLINE L REGISTERINSTRUCTOR MS. WANPEN PUANGRAT" INFORMATIONSECURITYAWARENESSTRAININGCOURSE OUTLINE L REGISTERINSTRUCTOR MS. WANPEN PUANGRAT" INFORMATIONSECURITYRISKMANAGEMENT OUTLINE L REGISTERINSTRUCTOR MS. WANPEN PUANGRAT" GUIDELINEFORINFORMATIONSECURITYAWARENESSBUILDING COURSE OUTLINE L REGISTERINSTRUCTOR MS. WANPEN PUANGRAT" 8,900BAHT (EARLYBIRD8,500BAHT) BRINGYOUROWNCOMPUTER" 10,900BAHT (8,900BAHTWITHYOURNOTEBOOK) 8,900BAHT (EARLYBIRD8,500BAHT) BRINGYOUROWNCOMPUTER" 8,900BAHT (EARLYBIRD8,500BAHT) BRINGYOUROWNCOMPUTER" 8,900BAHT (EARLYBIRD8,500BAHT) PLEASE BRING YOUR NOTEBOOK ON DAY 2 - 3 11,900BAHT (EARLYBIRD10,900BAHT) REGISTRATION3PERSONSPAYONLY 11,900BAHT (EARLYBIRD10,900BAHT) BRINGYOUROWNCOMPUTER 12,900BAHT (EARLYBIRD11,900BAHT) 12,900BAHT (EARLYBIRD11,900BAHT) 14,900BAHT (EARLYBIRD13,900BAHT) 8,900BAHT (EARLYBIRD8,500BAHT) 21,900BAHT (EARLYBIRD19,900BAHT) 12,900BAHT (EARLYBIRD12,500BAHT) 6,900BAHT (EARLYBIRD6,500BAHT) 12,900BAHT (EARLYBIRD12,500BAHT) 8,900BAHT (EARLYBIRD8,500BAHT) INTER MEDIATE ADVANCE INTER MEDIATE INTER MEDIATE INTER MEDIATE BASIC INTER MEDIATE ADVANCE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE INTER MEDIATE 2 3 2 2 3 2 3 2 2 2 1 2 2 1 2 1 - - 29-30 JAN - - - - - 18-19 JAN - - - - 7-8 FEB 26-28 FEB - - - - 10-11 FEB 29-30 MAR - - - - 13-14 MAR - - - - - - - - - - 23-25 APR 19-20 APR - - - - 23-24 MAY - 21-23 MAY - - - - - - - 13-14 JUN - 12-13 JUN - - - - - - 17-18 OCT 28-29 OCT - - 29-31 OCT - - - 13-14 NOV - - - 19-21 NOV - - 15-16 NOV - 10-11 NOV - - - - - 17-18 DEC - - - - 16-17 JUL 4-6 JUL - - - - - - 12-13 JUL 14-15 JUL - - - - 22-24 AUG - - - - - - - - - - 11-12 SEP - - - - DESCRIPTION LEVELRATE DAY DECNOVOCTSEPAUGJULJUNAPRMARFEBJAN MAY SOFTWARE DEVELOPMENT TRACK (CONTINUED) SOFTWARE ENGINEERING TRACK IT SECURITY TRACK SOFTSKILL TRACK SOFTSKILL: MANAGEMENT TRAINING ONREQUEST ONREQUEST ITLEADERASACOACH OUTLINE L REGISTER INSTRUCTOR: MS. KANNIKAR SETHI PRACTICALTIMEMANAGEMENT OUTLINE L REGISTER INSTRUCTOR: MS. KANNIKAR SETHI MANAGEMENTTRAININGFORTHEDIGITALERA OUTLINE L REGISTER INSTRUCTOR: IMC INSTITUTE TEAM 6,900BAHT (EARLYBIRD6,500BAHT) 6,900BAHT (EARLYBIRD6,500BAHT) 10,900BAHT (EARLYBIRD9,900BAHT) BASIC BASIC BASIC 1 1 1 ONREQUEST SOFTSKILL: SALES TRAINING ย้ายไปช่องMAY
- 246. IT TRENDS | TRAINING38 CONSTRUCTIVEFEEDBACKSIMULATIONWORKSHOP OUTLINE L REGISTER INSTRUCTOR: MS. KANNIKAR SETHI SHARPENYOURCREATIVITYSKILLS OUTLINE L REGISTER INSTRUCTOR: IMC INSTITUTE TEAM PROMOTINGITSERVICEEXCELLENCE OUTLINE L REGISTER INSTRUCTOR: IMC INSTITUTE TEAM" BUILDINGHIGHPERFORMANCETEAM OUTLINE L REGISTER INSTRUCTOR: IMC INSTITUTE TEAM" COMMUNICATION3.0 OUTLINE L REGISTERINSTRUCTOR IMC INSTITUTE TEAM" CONSTRUCTIVEFEEDBACKSIMULATIONWORKSHOP OUTLINE L REGISTER INSTRUCTOR: MS. KANNIKAR SETHI" PRESENTINGWITHCONFIDENCE:SIMULATIONWORKSHOP OUTLINE L REGISTERINSTRUCTOR MS. KANNIKAR SETHI" สุนทรียสนทนา(DIALOGUE)ส�าหรับนักบริหารสารสนเทศ OUTLINE L REGISTERINSTRUCTOR IMC INSTITUTE TEAM" EFFECTIVECOLLABORATIONWORKUSINGMODERNITTOOLS OUTLINE L REGISTER INSTRUCTOR: IMC INSTITUTE TEAM" IEEETECHNICALPRESENTATIONWORKSHOP OUTLINE LREGISTER INSTRUCTOR: IEEE CERTIFIED INSTRUCTOR" IEEETECHNICALWRITINGWORKSHOP OUTLINE L REGISTER INSTRUCTOR: IEEE CERTIFIED INSTRUCTOR" 6,900BAHT (EARLYBIRD6,500BAHT) 5,900BAHT (EARLYBIRD5,500BAHT) 6,900BAHT (EARLYBIRD6,500BAHT) 6,900BAHT (EARLYBIRD6,500BAHT) 6,900BAHT (EARLYBIRD6,500) 6,900BAHT (EARLYBIRD6,500BAHT) 11,900BAHT (EARLYBIRD10,900BAHT) 6,900BAHT (EARLYBIRD6,500BAHT) 7,900BAHT DURINGTHEPROMOTION 5,500BAHT(EARLYBIRD4,900BAHT) WITHYOUROWNCOMPUTER" 12,900BAHT (EARLYBIRD11,900BAHT) 12,900BAHT (EARLYBIRD11,900BAHT) BASIC BASIC BASIC BASIC BASIC BASIC BASIC BASIC BASIC INTER MEDIATE INTER MEDIATE 1 1 1 1 1 1 2 1 2 2 2 DESCRIPTION LEVELRATE DAY DECNOVOCTSEPAUGJULJUNAPRMARFEBJAN MAY SOFTSKILL TRACK SOFTSKILL: IT LEADERSHIP SOFTSKILL: IEEE COURSES ONREQUEST ONREQUEST สถาบันไอเอ็มซีให้บริการหลักสูตร In-House Training โดยออกแบบเนื้อหาให้ เหมาะกับความต้องการของแต่ละองค์กร ไม่ว่าจะเป็นความต้องการในระดับพื้นฐาน ระดับ ปฏิบัติ หรือระดับสูง ซึ่งสามารถเรียนรู้เฉพาะเจาะจงได้ตามเป้าหมายหลัก สถาบันมีหลักสูตร อบรมเทคโนโลยีใหม่ๆ ที่องค์กรทั้งภาครัฐและเอกชนสามารถน�าไปใช้เพิ่มประสิทธิภาพ การท�างาน คุณภาพของผลงาน อันน�าไปสู่การเพิ่มศักยภาพทางการแข่งขันในตลาด ได้อย่างต่อเนื่อง โดยมีทีมวิทยากรผู้ทรงคุณวุฒิในสาขาต่างๆ ร่วมถ่ายทอดความรู้และ ประสบการณ์ หลักสูตรที่เปิดให้บริการ และออกแบบเนื้อหาการเรียนการสอนให้กับองค์กร ได้แก่ IT Trends, Big Data, Cloud Computing, Enterprise Architecture, Digital Transformation, Software Development, Agile Workshop, Blockchain, Mobile Development, Project Management เป็นต้น นอกจากนี้ ยังมีหลักสูตรทางด้านพัฒนาทักษะต่างๆ (Soft Skill) เช่น Sales Technique, IT Leader as a Coach, Time Management, Effective Negotiation Skills, Promoting IT Service Excellence, Building High Performing Team อีกด้วย ตัวอย่างหน่วยงานที่สถาบันให้การออกแบบเนื้อหาและท�าการอบรม มีดังนี้ In-House Training สนใจจัดอบรมแบบ Inhouse หรือสอบถามข้อมูลเพิ่มเติม ติดต่อ IMC Institute คุณชลาลัย ใจหาญ (น�้า) Corporate Training Program and Project Consultant Mobile: 082-452-6464 E-Mail: [email protected]
- 248. ÃÐÂÐàÇÅÒͺÃÁ 35 ªÑ่ÇâÁ§ àÃÕ¹·Ø¡ÇѹÍѧ¤ÒÃàÇÅÒ 9.00 - 17.00.¹. ÃØ‹¹·Õ่ 1 àÃÔ่ÁàÃÕ¹ 27 ¡ØÁÀҾѹ¸, 6, 13, 20, 27 ÁÕ¹Ò¤Á 2018 ÃØ‹¹·Õ่ 2 àÃÔ่ÁàÃÕ¹ 18, 25 ¡Ñ¹ÂÒ¹, 2, 9, 16 µØÅÒ¤Á 2018 ÃØ‹¹·Õ่ 7 àÃÔ่ÁàÃÕ¹ 15 ÁÕ¹Ò¤Á 2018 ÃØ‹¹·Õ่ 8 àÃÔ่ÁàÃÕ¹ 13 ¡Ñ¹ÂÒ¹ 2018 àÃÕ¹·Ø¡Çѹ¾ÄËÑʺ´ÕàÇÅÒ 18.00 -21.00 ¹. áÅÐÇѹàÊÒà 9.00 - 17.00 ¹. ¡ÒùÓà·¤â¹âÅÂÕãËÁ‹àª‹¹ Hadoop, NoSQL ËÃ×Í NewSQL ࢌÒÁÒ㪌§Ò¹ µŒÍ§ÁÕ¡ÒþѲ¹ÒºØ¤ÅÒ¡Ãà¾×่ÍãˌࢌÒ㨡ÒÃ㪌෤â¹âÅÂÕàËÅ‹Ò¹Õ้ ÃÇÁ¶Ö§ÁÕ¤ÇÒÁÃٌ㹡Òà ÇÔà¤ÃÒÐË¢ŒÍÁÙŵ‹Ò§æ ËÅÑ¡Êٵà Big Data Certification ໚¹ËÅÑ¡ÊÙµÃ120 ªÑ่ÇâÁ§ ·Õ่µŒÍ§¡ÒþѲ¹ÒãËŒ¼ÙŒàÃÕ¹䴌ࢌÒ㨶֧àÃ×่ͧ¢Í§ Big Data ÁÕ¤ÇÒÁÊÒÁÒö 㹡ÒÃ㪌à¤Ã×่ͧÁ×͵‹Ò§æ ࢌÒã¨ã¹àÃ×่ͧ¢Í§ Business Intelligence áÅÐ Data Science µÅÍ´¨¹àÃ×่ͧÃÙŒ¡ÒÃ·Ó Big Data µÑ้§áµ‹ÇÒ§¡ÅÂØ·¸ ¨¹¶Ö§¡ÒÃ·Ó Predictive Analytics ´ŒÇ Large-Scale Machine Learning ¡ÒÃÊ͹ã¹ËÅÑ¡ÊٵùÕ้»ÃСͺ仴ŒÇ¡Òà ºÃÃÂÒ ¡ÒÃ·Ó Workshop â´Â¨ÐÁÕ¡ÒõԴµÑ้§ãªŒà¤Ã×่ͧÁ×Í Big Data ¨ÃÔ§æ ·Õ่ÊÒÁÒö ·Ó§Ò¹ä´ŒÃÇÁ¶Ö§¡ÒÃ㪌§Ò¹º¹Ãкº Cloud ¡ÒùÓà·¤â¹âÅÂÕãËÁ‹àª‹¹ Hadoop, NoSQL ËÃ×Í NewSQL ࢌÒÁÒ㪌§Ò¹ µŒÍ§ÁÕ¡ÒþѲ¹ÒºØ¤ÅÒ¡Ãà¾×่ÍãˌࢌÒ㨡ÒÃ㪌෤â¹âÅÂÕàËÅ‹Ò¹Õ้ ÃÇÁ¶Ö§ÁÕ¤ÇÒÁÃٌ㹡Òà ÇÔà¤ÃÒÐË¢ŒÍÁÙŵ‹Ò§æ ËÅÑ¡Êٵà Big Data Certification ໚¹ËÅÑ¡ÊÙµÃ120 ªÑ่ÇâÁ§ ·Õ่µŒÍ§¡ÒþѲ¹ÒãËŒ¼ÙŒàÃÕ¹䴌ࢌÒ㨶֧àÃ×่ͧ¢Í§ Big Data ÁÕ¤ÇÒÁÊÒÁÒö 㹡ÒÃ㪌à¤Ã×่ͧÁ×͵‹Ò§æ ࢌÒã¨ã¹àÃ×่ͧ¢Í§ Business Intelligence áÅÐ Data Science µÅÍ´¨¹àÃ×่ͧÃÙŒ¡ÒÃ·Ó Big Data µÑ้§áµ‹ÇÒ§¡ÅÂØ·¸ ¨¹¶Ö§¡ÒÃ·Ó Predictive Analytics ´ŒÇ Large-Scale Machine Learning ¡ÒÃÊ͹ã¹ËÅÑ¡ÊٵùÕ้»ÃСͺ仴ŒÇ¡Òà ºÃÃÂÒ ¡ÒÃ·Ó Workshop â´Â¨ÐÁÕ¡ÒõԴµÑ้§ãªŒà¤Ã×่ͧÁ×Í Big Data ¨ÃÔ§æ ·Õ่ÊÒÁÒö ·Ó§Ò¹ä´ŒÃÇÁ¶Ö§¡ÒÃ㪌§Ò¹º¹Ãкº Cloud Digital Transformation Strategy ໚¹ËÅÑ¡Êٵ÷Õ่¶Ù¡Í͡ẺÁÒà¾×่ÍÁØ‹§à¹Œ¹ ª‹ÇÂàµÔÁàµ็Á¤ÇÒÁÃÙŒ¤ÇÒÁࢌÒã¨áÅÐÊÌҧ»ÃÐ⪹ãˌᡋ·‹Ò¹ã¹¡Ò÷Õ่¨Ð … 1. ࢌÒ㨶֧¡ÒÃà»ÅÕ่¹á»Å§áÅмšÃзº·Õ่¨Ðà¡Ô´¢Ö้¹ã¹âÅ¡´Ô¨Ô·ÑÅ 2. ࢌÒ㨶֧á¹Ç⹌Á¢Í§à·¤â¹âÅÂÕÊÒÃʹà·Èµ‹Ò§æ ·Ñ้§·Õ่¡ÓÅѧ¨ÐࢌÒÁÒ Disrupt ¡Ò÷ӸØáԨ áÅÐÁÒª‹ÇÂÊÌҧÁÙŤ‹Ò㹡Ò÷ӸØáԨ ÃÇÁ·Ñ้§·ÓãËŒà¡Ô´¤ÇÒÁàÊÕ่§ µ‹Í¸ØáԨ¢Í§·‹Ò¹ â´ÂÃÇÁ件֧¹âºÒÂáÅС¯ËÁÒµ‹Ò§æ ·Õ่à¡Õ่ÂÇ¢ŒÍ§ 3. ÃѺ·ÃÒº¡Ã³ÕÈÖ¡ÉÒÊÓ¤ÑÞÍѹ໚¹º·àÃÕ¹·Õ่໚¹»ÃÐ⪹µ‹Í¡ÒûÃѺ»ÃÐÂØ¡µãªŒ à¾×่Í¡ÒõÑ้§ÃѺ¡Ñº¡ÒÃà»ÅÕ่¹á»Å§ã¹âÅ¡´Ô¨Ô·ÑÅ 4. ÊÒÁÒö¡Ó˹´·ÔÈ·Ò§ÇҧἹ¡ÒÃÊÌҧ¡ÅÂØ·¸´ŒÒ¹´Ô¨Ô·ÑÅãËŒ¡ÑºÍ§¤¡Ã ¡ÒÃÊÌҧ ÇѲ¹¸ÃÃÁáÅСÒþѲ¹ÒºØ¤ÅÒ¡Ã à¾×่Íãˌͧ¤¡ÃÊÒÁÒöᢋ§¢Ñ¹áÅСŒÒǷѹÀÒÂ㵌 ¡ÃÐáÊ¡ÒÃà»ÅÕ่¹á»Å§¢Í§âÅ¡´Ô¨Ô·ÑÅ 5. ÊÒÁÒö·Õ่¨ÐµÔ´µÒÁáÅлÃÐàÁÔ¹¼Å¤ÇÒÁ¡ŒÒÇ˹ŒÒáÅСÒÃà»ÅÕ่¹á»Å§ã¹Í§¤¡Ã·Õ่ à¡Ô´¨Ò¡¡ÒÃÇÒ§¡ÅÂØ·¸´ŒÒ¹´Ô¨Ô·ÑÅ