How to develop Big Data Pipelines for Hadoop, by Costin Leau
Download as PPTX, PDF0 likes1,863 views

Hadoop is not an island. To deliver a complete Big Data solution, a data pipeline needs to be developed that incorporates and orchestrates many diverse technologies. In this session we will demonstrate how the open source Spring Batch, Spring Integration and Spring Hadoop projects can be used to build manageable and robust pipeline solutions to coordinate the running of multiple Hadoop jobs (MapReduce, Hive, or Pig), but also encompass real-time data acquisition and analysis.





















![Spring Integration – Configuration and Tooling
Behind the scenes, configuration is XML or Scala DSL based
<!-- copy from input to staging -->
<file:inbound-channel-adapter id="filesInAdapter" channel="filInChannel"
directory="#{systemProperties['user.home']}/input">
<integration:poller fixed-rate="5000"/>
</file:inbound-channel-adapter>
Integration with Eclipse
24](https://image.slidesharecdn.com/bigdatapipelines-v91-120529102908-phpapp02/85/How-to-develop-Big-Data-Pipelines-for-Hadoop-by-Costin-Leau-23-320.jpg)










































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to How to develop Big Data Pipelines for Hadoop, by Costin Leau (20)




















Ad
More from Codemotion (20)




















Recently uploaded (20)




















How to develop Big Data Pipelines for Hadoop, by Costin Leau
- 1. Big Data Pipelines for Hadoop Costin Leau @costinl – SpringSource/VMware
- 2. Agenda Spring Ecosystem Spring Hadoop • Simplifying Hadoop programming Use Cases • Configuring and invoking Hadoop in your applications • Event-driven applications • Hadoop based workflows Applications (Reporting/Web/…) Analytics Data Structured Collection Data Data copy MapReduce HDFS 3
- 3. Spring Ecosystem Spring Framework • Widely deployed Apache 2.0 open source application framework • “More than two thirds of Java developers are either using Spring today or plan to do so within the next 2 years.“ – Evans Data Corp (2012) • Project started in 2003 • Features: Web MVC, REST, Transactions, JDBC/ORM, Messaging, JMX • Consistent programming and configuration model • Core Values – “simple but powerful’ • Provide a POJO programming model • Allow developers to focus on business logic, not infrastructure concerns • Enable testability Family of projects • Spring Security • Spring Integration • Spring Data • Spring Batch • Spring Hadoop (NEW!) 4
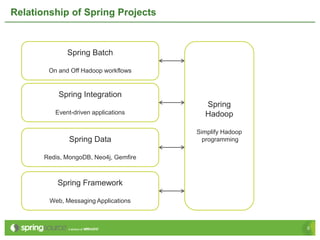
- 4. Relationship of Spring Projects Spring Batch On and Off Hadoop workflows Spring Integration Spring Event-driven applications Hadoop Simplify Hadoop Spring Data programming Redis, MongoDB, Neo4j, Gemfire Spring Framework Web, Messaging Applications 5
- 5. Spring Hadoop Simplify creating Hadoop applications • Provides structure through a declarative configuration model • Parameterization based on through placeholders and an expression language • Support for environment profiles Start small and grow Features – Milestone 1 • Create, configure and execute all type of Hadoop jobs • MR, Streaming, Hive, Pig, Cascading • Client side Hadoop configuration and templating • Easy HDFS, FsShell, DistCp operations though JVM scripting • Use Spring Integration to create event-driven applications around Hadoop • Spring Batch integration • Hadoop jobs and HDFS operations can be part of workflow 6
- 6. Configuring and invoking Hadoop in your applications Simplifying Hadoop Programming 7
- 7. Hello World – Use from command line Running a parameterized job from the command line applicationContext.xml <context:property-placeholder location="hadoop-${env}.properties"/> <hdp:configuration> fs.default.name=${hd.fs} </hdp:configuration> <hdp:job id="word-count-job" input-path=“${input.path}" output-path="${output.path}" mapper="org.apache.hadoop.examples.WordCount.TokenizerMapper" reducer="org.apache.hadoop.examples.WordCount.IntSumReducer"/> <bean id="runner" class="org.springframework.data.hadoop.mapreduce.JobRunner" p:jobs-ref="word-count-job"/> hadoop-dev.properties input.path=/user/gutenberg/input/word/ output.path=/user/gutenberg/output/word/ hd.fs=hdfs://localhost:9000 java –Denv=dev –jar SpringLauncher.jar applicationContext.xml 8
- 8. Hello World – Use in an application Use Dependency Injection to obtain reference to Hadoop Job • Perform additional runtime configuration and submit public class WordService { @Inject private Job mapReduceJob; public void processWords() { mapReduceJob.submit(); } } 9
- 9. Hive Create a Hive Server and Thrift Client <hive-server port="${hive.port}" > someproperty=somevalue hive.exec.scratchdir=/tmp/mydir </hive-server/> <hive-client host="${hive.host}" port="${hive.port}"/>b Create Hive JDBC Client and use with Spring JdbcTemplate • No need for connection/statement/resultset resource management <bean id="hive-driver" class="org.apache.hadoop.hive.jdbc.HiveDriver"/> <bean id="hive-ds" class="org.springframework.jdbc.datasource.SimpleDriverDataSource" c:driver-ref="hive-driver" c:url="${hive.url}"/> <bean id="template" class="org.springframework.jdbc.core.JdbcTemplate" c:data-source-ref="hive-ds"/> String result = jdbcTemplate.query("show tables", new ResultSetExtractor<String>() { public String extractData(ResultSet rs) throws SQLException, DataAccessException { // extract data from result set } }); 10
- 10. Pig Create a Pig Server with properties and specify scripts to run • Default is mapreduce mode <pig job-name="pigJob" properties-location="pig.properties"> pig.tmpfilecompression=true pig.exec.nocombiner=true <script location="org/company/pig/script.pig"> <arguments>electric=sea</arguments> </script> <script> A = LOAD 'src/test/resources/logs/apache_access.log' USING PigStorage() AS (name:chararray, age:int); B = FOREACH A GENERATE name; DUMP B; </script> </pig> 11
- 11. HDFS and FileSystem (FS) shell operations <hdp:script id="inlined-groovy" language=“groovy"> Use Spring File System Shell name = UUID.randomUUID().toString() API to invoke familiar scriptName = "src/test/resources/test.properties" fs.copyFromLocalFile(scriptName, name) “bin/hadoop fs” commands // use the shell (made available under variable fsh) • mkdir, chmod, .. dir = "script-dir" if (!fsh.test(dir)) { Call using Java or JVM fsh.mkdir(dir); fsh.cp(name, dir); fsh.chmod(700, dir) } scripting languages println fsh.ls(dir).toString() fsh.rmr(dir) Variable replacement inside <hdp:script/> scripts <script id="inlined-js" language="javascript"> importPackage(java.util); importPackage(org.apache.hadoop.fs); Use FileSystem API to call println("${hd.fs}") copyFromFocalFile name = UUID.randomUUID().toString() scriptName = "src/test/resources/test.properties“ // use the file system (made available under variable fs) fs.copyFromLocalFile(scriptName, name) // return the file length fs.getLength(name) </script> 12
- 12. Hadoop DistributedCache Distribute and cache • Files to Hadoop nodes • Add them to the classpath of the child-jvm <cache create-symlink="true"> <classpath value="/cp/some-library.jar#library.jar" /> <classpath value="/cp/some-zip.zip" /> <cache value="/cache/some-archive.tgz#main-archive" /> <cache value="/cache/some-resource.res" /> </cache> 13
- 13. Cascading Spring supports a type safe, Java based configuration model Alternative or complement to XML Good fit for Cascading configuration @Configuration public class CascadingConfig { @Value("${cascade.sec}") private String sec; @Bean public Pipe tsPipe() { DateParser dateParser = new DateParser(new Fields("ts"), "dd/MMM/yyyy:HH:mm:ss Z"); return new Each("arrival rate", new Fields("time"), dateParser); } @Bean public Pipe tsCountPipe() { Pipe tsCountPipe = new Pipe("tsCount", tsPipe()); tsCountPipe = new GroupBy(tsCountPipe, new Fields("ts")); } } <bean class="org.springframework.data.hadoop.cascading.CascadingConfig "/> <bean id="cascade" class="org.springframework.data.hadoop.cascading.HadoopFlowFactoryBean" p:configuration-ref="hadoop-configuration" p:tail-ref="tsCountPipe" /> 14
- 14. Mixing Technologies Simplifying Hadoop Programming 15
- 15. Hello World + Scheduling Schedule a job in a standalone or web application • Support for Spring Scheduler and Quartz Scheduler Submit a job every ten minutes • Use PathUtil’s helper class to generate time based output directory • e.g. /user/gutenberg/results/2011/2/29/10/20 <task:scheduler id="myScheduler"/> <task:scheduled-tasks scheduler="myScheduler"> <task:scheduled ref=“mapReduceJob" method=“submit" cron="10 * * * * *"/> </task:scheduled-tasks> <hdp:job id="mapReduceJob" scope=“prototype" input-path="${input.path}" output-path="#{@pathUtils.getTimeBasedPathFromRoot()}" mapper="org.apache.hadoop.examples.WordCount.TokenizerMapper" reducer="org.apache.hadoop.examples.WordCount.IntSumReducer"/> <bean name="pathUtils" class="org.springframework.data.hadoop.PathUtils" p:rootPath="/user/gutenberg/results"/> 16
- 16. Hello World + MongoDB Combine Hadoop and MongoDB in a single application • Increment a counter in a MongoDB document for each user runnning a job • Submit Hadoop job <hdp:job id="mapReduceJob" input-path="${input.path}" output-path="${output.path}" mapper="org.apache.hadoop.examples.WordCount.TokenizerMapper" reducer="org.apache.hadoop.examples.WordCount.IntSumReducer"/> <mongo:mongo host=“${mongo.host}" port=“${mongo.port}"/> <bean id="mongoTemplate" class="org.springframework.data.mongodb.core.MongoTemplate"> <constructor-arg ref="mongo"/> <constructor-arg name="databaseName" value=“wcPeople"/> </bean> public class WordService { @Inject private Job mapReduceJob; @Inject private MongoTemplate mongoTemplate; public void processWords(String userName) { mongoTemplate.upsert(query(where(“userName”).is(userName)), update().inc(“wc”,1), “userColl”); mapReduceJob.submit(); } } 17
- 17. Event-driven applications Simplifying Hadoop Programming 18
- 18. Enterprise Application Integration (EAI) EAI Starts with Messaging Why Messaging •Logical Decoupling •Physical Decoupling • Producer and Consumer are not aware of one another Easy to build event-driven applications • Integration between existing and new applications • Pipes and Filter based architecture 19
- 19. Pipes and Filters Architecture Endpoints are connected through Channels and exchange Messages File Producer Endpoint JMS Consumer Endpoint TCP Route Channel $> cat foo.txt | grep the | while read l; do echo $l ; done 20
- 20. Spring Integration Components Channels Adapters • Point-to-Point • File, FTP/SFTP • Publish-Subscribe • Email, Web Services, HTTP • Optionally persisted by a • TCP/UDP, JMS/AMQP MessageStore • Atom, Twitter, XMPP Message Operations • JDBC, JPA • Router, Transformer • MongoDB, Redis • Filter, Resequencer • Spring Batch • Splitter, Aggregator • Tail, syslogd, HDFS Management • JMX • Control Bus 21
- 21. Spring Integration Implementation of Enterprise Integration Patterns • Mature, since 2007 • Apache 2.0 License Separates integration concerns from processing logic • Framework handles message reception and method invocation • e.g. Polling vs. Event-driven • Endpoints written as POJOs • Increases testability Endpoint Endpoint 22
- 22. Spring Integration – Polling Log File example Poll a directory for files, files are rolled over every 10 seconds. Copy files to staging area Copy files to HDFS Use an aggregator to wait for “all 6 files in 1 minute interval” to launch MR job 23
- 23. Spring Integration – Configuration and Tooling Behind the scenes, configuration is XML or Scala DSL based <!-- copy from input to staging --> <file:inbound-channel-adapter id="filesInAdapter" channel="filInChannel" directory="#{systemProperties['user.home']}/input"> <integration:poller fixed-rate="5000"/> </file:inbound-channel-adapter> Integration with Eclipse 24
- 24. Spring Integration – Streaming data from a Log File Tail the contents of a file Transformer categorizes messages Route to specific channels based on category One route leads to HDFS write and filtered data stored in Redis 25
- 25. Spring Integration – Multi-node log file example Spread log collection across multiple machines Use TCP Adapters • Retries after connection failure • Error channel gets a message in case of failure • Can startup when application starts or be controlled via Control Bus • Send(“@tcpOutboundAdapter.retryConnection()”), or stop, start, isConnected. 26
- 26. Hadoop Based Workflows Simplifying Hadoop Programming 27
- 27. Spring Batch Enables development of customized enterprise batch applications essential to a company’s daily operation Extensible Batch architecture framework • First of its kind in JEE space, Mature, since 2007, Apache 2.0 license • Developed by SpringSource and Accenture • Make it easier to repeatedly build quality batch jobs that employ best practices • Reusable out of box components • Parsers, Mappers, Readers, Processors, Writers, Validation Language • Support batch centric features • Automatic retries after failure • Partial processing, skipping records • Periodic commits • Workflow – Job of Steps – directed graph, parallel step execution, tracking, restart, … • Administrative features – Command Line/REST/End-user Web App • Unit and Integration test friendly 28
- 28. Off Hadoop Workflows Client, Scheduler, or SI calls job launcher to start job execution Job is an application component representing a batch process Job contains a sequence of steps. • Steps can execute sequentially, non- sequentially, in parallel • Job of jobs also supported Job repository stores execution metadata Steps can contain item processing flow <step id="step1"> <tasklet> <chunk reader="flatFileItemReader" processor="itemProcessor" writer=“jdbcItemWriter" commit-interval="100" retry-limit="3"/> </chunk> </tasklet> </step> Listeners for Job/Step/Item processing 29
- 29. Off Hadoop Workflows Client, Scheduler, or SI calls job launcher to start job execution Job is an application component representing a batch process Job contains a sequence of steps. • Steps can execute sequentially, non- sequentially, in parallel • Job of jobs also supported Job repository stores execution metadata Steps can contain item processing flow <step id="step1"> <tasklet> <chunk reader="flatFileItemReader" processor="itemProcessor" writer=“mongoItemWriter" commit-interval="100" retry-limit="3"/> </chunk> </tasklet> </step> Listeners for Job/Step/Item processing 30
- 30. Off Hadoop Workflows Client, Scheduler, or SI calls job launcher to start job execution Job is an application component representing a batch process Job contains a sequence of steps. • Steps can execute sequentially, non- sequentially, in parallel • Job of jobs also supported Job repository stores execution metadata Steps can contain item processing flow <step id="step1"> <tasklet> <chunk reader="flatFileItemReader" processor="itemProcessor" writer=“hdfsItemWriter" commit-interval="100" retry-limit="3"/> </chunk> </tasklet> </step> Listeners for Job/Step/Item processing 31
- 31. On Hadoop Workflows Reuse same infrastructure for Hadoop based workflows HDFS PIG Step can any Hadoop job type MR Hive or HDFS operation HDFS 32
- 32. Spring Batch Configuration <job id="job1"> <step id="import" next="wordcount"> <tasklet ref=“import-tasklet"/> </step> <step id="wordcount" next="pig"> <tasklet ref="wordcount-tasklet" /> </step> <step id="pig"> <tasklet ref="pig-tasklet" </step> <split id="parallel" next="hdfs"> <flow> <step id="mrStep"> <tasklet ref="mr-tasklet"/> </step> </flow> <flow> <step id="hive"> <tasklet ref="hive-tasklet"/> </step> </flow> </split> <step id="hdfs"> <tasklet ref="hdfs-tasklet"/> </step> </job> 33
- 33. Spring Batch Configuration Additional XML configuration behind the graph Reuse previous Hadoop job definitions • Start small, grow <script-tasklet id=“import-tasklet"> <script location="clean-up-wordcount.groovy"/> </script-tasklet> <tasklet id="wordcount-tasklet" job-ref="wordcount-job"/> <job id=“wordcount-job" scope=“prototype" input-path="${input.path}" output-path="#{@pathUtils.getTimeBasedPathFromRoot()}" mapper="org.apache.hadoop.examples.WordCount.TokenizerMapper" reducer="org.apache.hadoop.examples.WordCount.IntSumReducer"/> <pig-tasklet id="pig-tasklet"> <script location="org/company/pig/handsome.pig" /> </pig-tasklet> <hive-tasklet id="hive-script"> <script location="org/springframework/data/hadoop/hive/script.q" /> </hive-tasklet> 34
- 34. Questions At milestone 1 – welcome feedback Project Page: http://www.springsource.org/spring-data/hadoop Source Code: https://github.com/SpringSource/spring-hadoop Forum: http://forum.springsource.org/forumdisplay.php?87-Hadoop Issue Tracker: https://jira.springsource.org/browse/SHDP Blog: http://blog.springsource.org/2012/02/29/introducing-spring- hadoop/ Books 35
- 35. Q&A @costinl 36
Editor's Notes
- #3: 600-700TB of data during first years.
- #4: This diagram shows some of the main components in a big data pipelines.The main flows are collecting data into HDFS, analyzing that data with a combinatin of on-hadoop and off hadoop analytics.Results of analysis are copied to structured data (memcache, mysql) for analysis and consumption by applications
- #5: All projects Apache 2.0Spring’s features have greatly increrased developers productivity bringing in creating applications.A family of projects have grown up around spring dedicated to providing similar productivyt gains in different application areas.
- #6: Notes: all apache 2.0 projects.Can be deployed as standalone apps and web apps
- #9: What you see here is a spring configuration file, can also be type safe java code.
- #11: Get a PigServer instance.
- #12: Get a PigServer instance.
- #13: ****
- #17: Why the & ?runAtStartup should be false by defalut
- #22: Enpoints can be message operations, transformation, adaptesr….
- #23: Know there are other solutions, storm, flume, sqoop, S4,
- #24: Broke up process into mulitple reusable blocks.Transformer adds data needed by aggregator to specifcy that “this is the first file of 10 for a given minute”
- #29: 5 major releases.2 books
- #30: Can also have a “job of jobs” so you can compose larger and larger workflows.
- #31: Can also have a “job of jobs” so you can compose larger and larger workflows.
- #32: Can also have a “job of jobs” so you can compose larger and larger workflows.