Bigdata and Hadoop Introduction
0 likes427 views

- Big data refers to large sets of data that businesses and organizations collect, while Hadoop is a tool designed to handle big data. Hadoop uses MapReduce, which maps large datasets and then reduces the results for specific queries. - Hadoop jobs run under five main daemons: the NameNode, DataNode, Secondary NameNode, JobTracker, and TaskTracker. - HDFS is Hadoop's distributed file system that stores very large amounts of data across clusters. It replicates data blocks for reliability and provides clients high-throughput access to files.


















































Ad
More Related Content
What's hot (19)
Viewers also liked (16)













Ad
Similar to Bigdata and Hadoop Introduction (20)




















Ad
Recently uploaded (20)




















Bigdata and Hadoop Introduction
- 1. Presentation By , M.Tech(CSE).,(PhD), Big Data Education Group, Bangalore
- 2. Big Data Vs Hadoop Big data is simply the large sets of data that businesses and other parties put together to serve specific goals and operations. Big data can include many different kinds of data in many different kinds of formats. For example, businesses might put a lot of work into collecting thousands of pieces of data on purchases in currency formats, on customer identifiers like name or Social Security number, or on product information in the form of model numbers, sales numbers or inventory numbers. All of this, or any other large mass of information, can be called big data. As a rule, it’s raw and unsorted until it is put through various kinds of tools and handlers. Hadoop is one of the tools designed to handle big data. Hadoop and other software products work to interpret or parse the results of big data searches through specific proprietary algorithms and methods. Hadoop is an open-source program under the Apache license that is maintained by a global community of users. It includes various main components, including a Map Reduce set of functions and a Hadoop distributed file system (HDFS).
- 3. The idea behind Map Reduce is that Hadoop can first map a large data set, and then perform a reduction on that content for specific results. A reduce function can be thought of as a kind of filter for raw data. The HDFS system then acts to distribute data across a network or migrate it as necessary. Database administrators, developers and others can use the various features of Hadoop to deal with big data in any number of ways. For example, Hadoop can be used to pursue data strategies like clustering and targeting with non-uniform data, or data that doesn't fit neatly into a traditional table or respond well to simple queries.
- 4. Hadoop was created by Doug Cutting and Mike Cafarella in 2005. Cutting, who was working at Yahoo! at the time, named it after his son's toy elephant. It was originally developed to support distribution for the Nutch search engine project. Hadoop jobs run under 5 daemons mainly, Name node Data Node Secondary Name node Job Tracker Task Tracker Starting Daemons
- 5. Hadoop is a large-scale distributed batch processing infrastructure. Its true power lies in its ability to scale to hundreds or thousands of computers, each with several processor cores. Hadoop is also designed to efficiently distribute large amounts of work across a set of machines. Hadoop is built to process "web-scale" data on the order of hundreds of gigabytes to terabytes or petabytes. At this scale, it is likely that the input data set will not even fit on a single computer's hard drive, much less in memory. So Hadoop includes a distributed file system which breaks up input data and sends fractions of the original data to several machines in your cluster to hold. This results in the problem being processed in parallel using all of the machines in the cluster and computes output results as efficiently as possible.
- 6. Hadoop Advantages Hadoop is an open source, versatile tool that provides the power of distributed computing. By using distributed storage & transferring code instead of data, Hadoop avoids the costly transmission step when working with large data sets. Redundancy of data allows Hadoop to recover from single node fail. Ease to create programs with Hadoop As it uses the Map Reduce framework. Need not worry about partitioning the data, determining which nodes will perform which tasks, or handling communication between nodes as It is all done by Hadoop for you. Hadoop leaving you free to focus on what is most important to you and your data and what you want to do with it.
- 7. Challenges: Performing large-scale computation is difficult. Whenever multiple machines are used in cooperation with one another, the probability of failures rises. In a distributed environment, however, partial failures are an expected and common occurrence. Networks can experience partial or total failure if switches and routers break down. Data may not arrive at a particular point in time due to unexpected network congestion. Clocks may become desynchronized, lock files may not be released, parties involved in distributed atomic transactions may lose their network connections part-way through, etc. In each of these cases, the rest of the distributed system should be able to recover from the component failure or transient error condition and continue to make progress.
- 8. Synchronization between multiple machines remains the biggest challenge in distributed system design. For example, if 100 nodes are present in a system and one of them crashes, the other 99 nodes should be able to continue the computation, ideally with only a small penalty proportionate to the loss of 1% of the computing power. Hadoop typically isn't a one-stop-shopping product and must be used in coordination with Map Reduce and a range of other complementary technologies from what is referred to as the Hadoop ecosystem. Although it's open source, it's by no means free. Companies implementing a Hadoop cluster generally choose one of the commercial distributions of the framework, which poses maintenance and support costs. They need to pay for hardware and hire experienced programmers or train existing employees on working with Hadoop, Map Reduce and related technologies such as Hive, HBase and Pig.
- 9. Challenges: Following are the major common areas found as weaknesses of Hadoop framework or system: As you know Hadoop uses HDFS and Map Reduce, Both of their master processes are single points of failure, Although there is active work going on for High Availability versions. Until the Hadoop 2.x release, HDFS and Map Reduce will be using single-master models which can result in single points of failure. Hadoop does not offer storage or network level encryption which is very big concern for government sector application data. HDFS is inefficient for handling small files, and it lacks transparent compression. As HDFS is not designed to work well with random reads over small files due to its optimization for sustained throughput. Map Reduce is a shared-nothing architecture hence Tasks that require global synchronization or sharing of mutable data are not a good fit which can pose challenges for some algorithms
- 11. • HDFS Introduction • HDFS, the Hadoop Distributed File System, is a distributed file system designed to hold very large amounts of data (terabytes or even petabytes), and provide high-throughput access to this information. • Files are stored in a redundant fashion across multiple machines to ensure their durability to failure and high availability to very parallel applications. This module introduces the design of this distributed file system and instructions on how to operate it. • A distributed file system is designed to hold a large amount of data and provide access to this data to many clients distributed across a network. There are a number of distributed file systems that solve this problem in different ways. • HDFS should store data reliably. If individual machines in the cluster malfunction, data should still be available. • HDFS should provide fast, scalable access to this information. It should be possible to serve a larger number of clients by simply adding more machines to the cluster. * HDFS should integrate well with Hadoop Map Reduce, allowing data to be read and computed upon locally when possible.
- 12. • Applications that use HDFS are assumed to perform long sequential streaming reads from files. HDFS is optimized to provide streaming read performance; this comes at the expense of random seek times to arbitrary positions in files. • Due to the large size of files, and the sequential nature of reads, the system does not provide a mechanism for local caching of data. The overhead of caching is great enough that data should simply be re-read from HDFS source. • Individual machines are assumed to fail on a frequent basis, both permanently and intermittently. The cluster must be able to withstand the complete failure of several machines, possibly many happening at the same time (e.g., if a rack fails all together). While performance may degrade proportional to the number of machines lost, the system as a whole should not become overly slow, nor should information be lost. Data replication strategies combat this problem. • The design of HDFS is based on the design of GFS, the Google File System. Its design was described in a paper published by Google.
- 13. • HDFS Architecture • HDFS is a block-structured file system: individual files are broken into blocks of a fixed size. These blocks are stored across a cluster of one or more machines with data storage capacity. • Individual machines in the cluster are referred to as Data Nodes. A file can be made of several blocks, and they are not necessarily stored on the same machine; the target machines which hold each block are chosen randomly on a block-by-block basis. • Thus access to a file may require the cooperation of multiple machines, but supports file sizes far larger than a single-machine DFS; individual files can require more space than a single hard drive could hold. • If several machines must be involved in the serving of a file, then a file could be rendered unavailable by the loss of any one of those machines. HDFS combats this problem by replicating each block across a number of machines (3, by default). • Most block-structured file systems use a block size on the order of 4 or 8 KB. By contrast, the default block size in HDFS is 64MB -- orders of magnitude larger. This allows HDFS to decrease the amount of metadata storage required per file (the list of blocks per file will be smaller as the size of individual blocks increases).
- 14. Master node Two slave nodes HADOOPARCHITECTURE
- 15. • HDFS expects to read a block start-to-finish for a program. This makes it particularly useful to the Map Reduce style of programming. • Because HDFS stores files as a set of large blocks across several machines, these files are not part of the ordinary file system. Typing ls on a machine running a Data Node daemon will display the contents of the ordinary Linux file system being used to host the Hadoop services -- but it will not include any of the files stored inside the HDFS. • This is because HDFS runs in a separate namespace, isolated from the contents of your local files. The files inside HDFS (or more accurately: the blocks that make them up) are stored in a particular directory managed by the Data Node service, but the files will named only with block ids. • It is important for this file system to store its metadata reliably. Furthermore, while the file data is accessed in a write once and read many model, the metadata structures (e.g., the names of files and directories) can be modified by a large number of clients concurrently. • It is important that this information is never desynchronized. Therefore, it is all handled by a single machine, called the Name Node. • The Name Node stores all the metadata for the file system. Because of the relatively low amount of metadata per file (it only tracks file names, permissions, and the locations of each block of each file), all of this information can be stored in the main memory of the Name Node machine, allowing fast access to the metadata.
- 16. Centralized namenode - Maintains metadata info about files Many data node (1000s) - Store the actual data - Files are divided into blocks - Each block is replicated N times (Default = 3) File F 1 2 3 4 5 Blocks (64 MB)
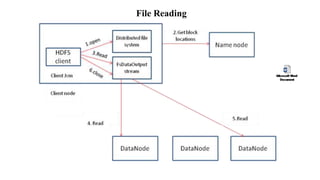
- 17. • To open a file, a client contacts the Name Node and retrieves a list of locations for the blocks that comprise the file. These locations identify the Data Nodes which hold each block. • Clients then read file data directly from the Data Node servers, possibly in parallel. The Name Node is not directly involved in this bulk data transfer, keeping its overhead to a minimum. • Name Node information must be preserved even if the Name Node machine fails; there are multiple redundant systems that allow the Name Node to preserve the file system's metadata even if the Name Node itself crashes irrecoverably. • Name Node failure is more severe for the cluster than Data Node failure. While individual Data Nodes may crash and the entire cluster will continue to operate, the loss of the Name Node will render the cluster inaccessible until it is manually restored. • Fortunately, as the Name Node's involvement is relatively minimal, the odds of it failing are considerably lower than the odds of an arbitrary Data Node failing at any given point in time.
- 18. File Reading
- 19. File Writing
- 20. Summary Big data is simply the large sets of data, Hadoop is one of the tools designed to handle big data. Map Reduce is that Hadoop can first map a large data set, and then perform a reduction on that content for specific results. Hadoop jobs run under 5 daemons mainly, Name node, Data Node, Secondary Name node Job Tracker, Task Tracker HDFS, the Hadoop Distributed File System, is a distributed file system designed to hold very large amounts of data (terabytes or even petabytes), and provide high-throughput access to this information.