Branch Management in Git Fusion
Download as PPTX, PDF1 like802 views

Git Fusion manages two inherently different branching models. Learn the ramifications of changing branch mappings, using fully populated or lightweight branches in Git Fusion and the purpose of “ghost” changes.











![12
Branch Mapping in Git Fusion
[projx1-master]
git-branch-name = master
view = //depot/projx/main/src/... ...
[projx1-stage]
git-branch-name = stage
view = //depot/projx/stage/src/... ...
stream = //Projx/mainline #stream example](https://image.slidesharecdn.com/git-fusion-branch-managementpv8-160413165727/85/Branch-Management-in-Git-Fusion-12-320.jpg)





![18
New Depot Path on Existing Mapping
[projx1-master]
git-branch-name = master
view = //depot/projx/main/src/... ...](https://image.slidesharecdn.com/git-fusion-branch-managementpv8-160413165727/85/Branch-Management-in-Git-Fusion-18-320.jpg)

![20
New Depot Path on Existing Mapping
[projx1-master]
git-branch-name = master
view = //depot/projx/main/src/... ...
//depot/projx/main/doc/... doc/...](https://image.slidesharecdn.com/git-fusion-branch-managementpv8-160413165727/85/Branch-Management-in-Git-Fusion-20-320.jpg)





![26
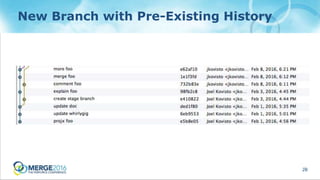
New Branch with Pre-Existing History
[projx1-master]
git-branch-name = master
view = //depot/projx/main/src/... ...
-//depot/projx/main/src/doc/... doc/...
//depot/projx/main/doc/... doc/...
[projx1-stage]
git-branch-name = stage
view = //depot/projx/stage/src/... ...
-//depot/projx/stage/src/doc/... doc/...
//depot/projx/stage/doc/... doc/...](https://image.slidesharecdn.com/git-fusion-branch-managementpv8-160413165727/85/Branch-Management-in-Git-Fusion-26-320.jpg)






![34
Fully-Populated Branches
[@repo]
description = Projx1 repo
depot-branch-creation-enable = explicit
depot-branch-creation-depot-path = //depot/{repo}/{user}/{git_branch_name}
$ git push origin mytask:depot-branch/mytask
//depot/projx1/jkovisto/mytask/...](https://image.slidesharecdn.com/git-fusion-branch-managementpv8-160413165727/85/Branch-Management-in-Git-Fusion-34-320.jpg)































![[Tel aviv merge world tour] Perforce Server Update](https://cdn.slidesharecdn.com/ss_thumbnails/telavivmergeworldtourperforceserverupdate-130718081007-phpapp01-thumbnail.jpg?width=560&fit=bounds)




Ad
More Related Content
What's hot (20)
Similar to Branch Management in Git Fusion (20)


















Ad
More from Perforce (20)




















Ad
Recently uploaded (20)



![Get & Download Wondershare Filmora Crack Latest [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/revolutionizingresidentialwi-fi-250422112639-60fb726f-250429170801-59e1b240-thumbnail.jpg?width=560&fit=bounds)
















Branch Management in Git Fusion
- 1. Branch Management in Git Fusion Joel Kovisto Technical Account Manager
- 2. 2 Helix Branches vs. Git Branches 1. Compare Helix and Git data models 2. Changing branch mappings 3. Lightweight and Fully-populated branches 4. Ghost changelists
- 3. 3 Helix Branch Data Model • Branches of depot hierarchy • Set of files and the changes made to each file over time • Tracks integration history between branches for each file
- 4. 4 Git Concepts not in Helix • Commit hierarchy • Branch references • Common history across branches • Anonymous branches
- 5. “Master Git,” said the historian, “what is the nature of history?” “History is immutable. To rewrite it later is to tamper with the very fabric of existence.” - Only the Gods, Git Koans, Steve Losh
- 6. 6 Anatomy of a Commit • Comment • Author • Committer • Tree • Parent(s)
- 7. “I have a historical record of a merge commit with two parents. How can I find out which branch each parent was originally made on?” “History is ephemeral,” replied Master Git,“the knowledge you seek can be answered only by the gods.” - Only the Gods, Git Koans, Steve Losh
- 8. 8 Git Branches • A branch is simply a pointer to a commit • History is a stream or series of workspace snapshots
- 9. 9 Helix Concepts not in Git • Depot hierarchy • Client view mapping • File actions • Individual file revisions are not tracked • File integration history • Branch on which a commit was made
- 10. What will it mean if I change branch mappings?
- 11. 11 Changing Branch Mappings • Adding a new branch • Removing a branch or depot path • Adding a depot path to existing branch mapping • Adding a branch mapping with pre-existing history
- 12. 12 Branch Mapping in Git Fusion [projx1-master] git-branch-name = master view = //depot/projx/main/src/... ... [projx1-stage] git-branch-name = stage view = //depot/projx/stage/src/... ... stream = //Projx/mainline #stream example
- 13. 13 Add A New Branch Mapping 1. Create the branch in Helix 2. Add mapping to the repo config 3. git pull
- 14. 14 Add A New Branch Mapping New branch in Git you want to push to a depot path 1. Add mapping to repo config 2. git push origin branch-name
- 15. 15 Removing a Branch or Depot Path
- 16. Can I add a depot path to an existing branch mapping?
- 17. 17 New Depot Path on Existing Mapping
- 18. 18 New Depot Path on Existing Mapping [projx1-master] git-branch-name = master view = //depot/projx/main/src/... ...
- 19. 19 New Depot Path on Existing Mapping Changes to docs not included
- 20. 20 New Depot Path on Existing Mapping [projx1-master] git-branch-name = master view = //depot/projx/main/src/... ... //depot/projx/main/doc/... doc/...
- 21. 21 New Depot Path on Existing Mapping
- 22. 22 New Depot Path on Existing Mapping
- 23. 23 New Depot Path on Existing Mapping
- 24. 24 New Depot Path on Existing Mapping
- 25. What if I add a new branch mapping with old history?
- 26. 26 New Branch with Pre-Existing History [projx1-master] git-branch-name = master view = //depot/projx/main/src/... ... -//depot/projx/main/src/doc/... doc/... //depot/projx/main/doc/... doc/... [projx1-stage] git-branch-name = stage view = //depot/projx/stage/src/... ... -//depot/projx/stage/src/doc/... doc/... //depot/projx/stage/doc/... doc/...
- 27. 27 Both Branches Always Mapped
- 28. 28 New Branch with Pre-Existing History
- 29. 29 Changing Branch Mappings • Fabric of space and time remains intact • Cannot affect history • Best if you get it right the first time
- 30. 30 Lightweight vs. Fully Populated Branches • Lightweight branches • Fully-populated brances
- 32. 32 Fully-Populated Branches • Fully-populated branches reflect the Git workspace • Mapped branches are fully-populated branches • Create fully-populated depot path on the fly
- 33. 33 Fully-Populated Branches depot-branch-creation-enable no : Unmapped branches are lightweight all : Unmapped branches are fully-populated explicit : Hybrid depot-branch-creation-depot-path: {repo} {git_branch_name} {user} depot-branch-creation-p4group
- 34. 34 Fully-Populated Branches [@repo] description = Projx1 repo depot-branch-creation-enable = explicit depot-branch-creation-depot-path = //depot/{repo}/{user}/{git_branch_name} $ git push origin mytask:depot-branch/mytask //depot/projx1/jkovisto/mytask/...
- 35. 35 Who’s Afraid Of Ghosts? Ghost changelists make Helix history reflect Git History • One-to-one mapping between Git and Perforce file actions • Diffing against previous revision
- 36. 36 What Manifests a Ghost? • Pushing to a new fully-populated depot path • Pushing to a commit to a new lightweight branch • Push that must make the depot reflect a commit’s parent
- 37. 37 Identifying Ghost Changes Change 14378 by git-fusion-user@git-fusion--temp-1-jk-centos-64-projx1 on 2016/02/23 14:02:16 Git Fusion branch management Imported from Git ghost-of-change-num: 14360 ghost-of-sha1: 709b0d2dd013dfe86022197633e528cc9db8c3f1 ghost-precedes-sha1: bff18f1bfb9e63a3a6e773deee946579457b210 parent-branch: None@14360 push-state: incomplete
- 38. 38 Branch Management Planning • Anticipate branch mapping needs • New fully-populated branches in real time • Recognize ghosts
- 39. Q&A
- 40. Thank you Meet me at the Helix Hive [email protected]
Editor's Notes
- #2: - Already have, or are considering adding, one of our Git solutions. - Recognize benefits of - narrow cloning or the ability to slice and dice your depot into any manner of Git repo - File-level protections - Perforce Helix as single source of truth - Security benefits and the ability to comply with some industry’s regulations
- #3: - Discuss core functionality of our Git solutions - reconciling Perforce Helix branches and Git branches. Two very different models. - Consider the two data models, and what branches mean in the two systems - Look at how these branches are mapped between the systems and what it means to change those mappings - LW vs FP - Lastly, purpose ghost change lists
- #4: Essential characteristics of Helix branches: - Helix branches depict hierarchy - branches of depot hierarchy - Changes to files tracked individually over time - Integration history between file revisions is tracked. Resolve decisions (accept yours, theirs, merge? conflict resolved?) Each decision recorded
- #5: • commit hierarchy: Each Git commit has one or more parents. Can’t say the changelist that came before this changelist is its parent • branch references: Git branch references point to specific commits within the commit hierarchy. • common history across branches: Git history often shares the same sequence of commits across several branches. * anonymous branches: Git branch references can be deleted, or just not included with a git push. The result is that many sub-paths through Git commit history have no branch name.
- #6: Now let’s look at the Git data model. The first aspect of Git history to consider is its immutability. Actually, you can rewrite history, but you’ll probably tick your colleagues off if you do so.
- #7: Anatomy of a Commit Core objects in Git are blobs, which are files, trees, which are snapshots of files and directories, and commits. Commits make are what make sense of it all, and are analogous to change lists. Each object gets a SHA1 calculation Commit message Author of the commit Committer - usually the same as the author Tree Parent(s) - The SHA1 of one or more parent commits. All part of SH A1 calc Did you notice what was not in the commit?
- #8: Git does not store branch info in its core data model. While immutable, much of Git history is unknowable.
- #9: Git history is just a series of of workspace snapshots, identified by its commits A branch is simply a lightweight movable pointer to a commit.
- #10: Git lacks helix concepts Depot hierarchy - Git’s hierarchy is only the workspace tree, or workspace hierarchy, and commit hierarchy Client view mapping - With no hierarchy, there is nothing to map File actions - whether the file was added, edited, deleted, or moved, is not recorded. The action can only be inferred when comparing commits Can’t refer to individual file revisions File integration history - without file actions, per-file integration history is another step removed On what branch was this commit made? not tracked
- #11: - Git history immutable - Changing anything in a commit causes a cascading effect - Commit and changelist become bound Early days Support had admonitions not to do anything that would “break history” “Rebuild” if feasible
- #12: Let’s consider the effects of making various changes to branch mappings, including… Adding a new branch to the repo Removing a branch or depot path Adding a new depot path to an existing branch mapping Adding branch mapping with pre-existing history
- #13: Describe branch mapping example
- #14: Adding a mapping for a new branch has always been expected behavior To go from Helix to Git: Create the branch in Helix with p4 integ or p4 populate Add the new branch mapping to your repo configuration Pull it into your repo
- #15: Same thing from the other side. Say you have a git branch you want mapped to a fully-populated branch in Helix Add the mapping to the repo config Push it to Git Fusion or GitSwarm
- #16: - Core functionality rebuild a repo from Helix - recovery or new instance - Stores commit and tree objects, blobs stored as file revisions - Process commit, tree refers to blob that is no longer part of the repo’s view. Breakage
- #18: 4 changelists. 2 in src directory and the other 2 in a doc folder
- #19: Map src only
- #20: Expected Git history
- #21: Wish you had included doc
- #22: Another look at Helix history Note change 14323 with “start doc”.
- #23: Only 2nd commit in doc included. Earlier history not touched, did not break history
- #24: If doc included from beginning…
- #25: By adding the doc depot path late, you don’t break anything. But it’s not perfect – what if the git user was trying find when a bug was introduced? She’d find the first commit available for this path, but the change that actually introduced it might have come before.
- #26: Next we’ll consider adding a new branch mapping.
- #27: Describe mapping for 2 branches
- #28: note “merge foo” - merge commit, 2 parents - “comment foo” and “explain foo”
- #29: - “merge foo” still there, but only one parent - time of commit was processes, only 1 parent was known - stage branch did not exist for this repo - content same - new history will capture merge commits
- #30: When making most changes to branch mappings, just know: You can’t break Git history Git Fusion protects To most accurately reflect Helix history, think about what is needed
- #31: Next we look at lightweight and fully populated branches, the differences between the two and the options you have for using them.
- #32: - 2013.1 - unmapped branches were LW - LW branches only capture what has changed - Since creating integration history is a bit heavy, this reduced work We had a way to accommodate any Git history But paths are jarring to P4 users – describe path Customers wanted predictable depot paths on the fly
- #33: Enter the fully-populated branch. Fully populated - target depot view reflects the state of the Git workspace for that branch. (To be clear) All mapped branches are fully populated. In 2014.2, we made it possible for Git users to create fully-populated Helix branches on the fly. No longer need update config file manually!
- #34: Describe slide
- #35: Describe slide Our Git solutions generally put no onus on the end user. Git services look like regular git remotes “explicit” setting is an exception.
- #36: Make Helix history reflect Git history Helix needs to branch a file into existence before you can delete it or easily compare a new revision to the previous revision Diffing a new commit on new branch in git is the same as if it was on the same branch Describe branch for delete It’s this conceptual mismatch that led to the need for ghost changelists
- #37: New FP depot path Same for JIT on LW Describe branch reuse - “task1” don’t forget deleting branch locally after first use Create task1 Do some work, push Merge into master, push1 Delete the local branch ref, and push 1 month later reuse task1 Do some work, push task1 – totally new basis, from a new parent
- #38: Describe slide – identifying features
- #39: Hopefully you better understand ramifications of making changes to repo branch mappings - You recognize how projects are structured in Helix and how Git users will use the repo, and how the repo will likely evolve, will help you define your repos from the beginning You have better idea whether to use FP branches on demand See a ghost, don’t panic, you can figure out how it came about