Building a Modern Data Architecture with Enterprise Hadoop
27 likes9,156 views

Presentation that I gave at the '2014 Open-BDA Hadoop Summit' on November 18th, 2014 on Modern Data Architecture with Enterprise Hadoop







































































Ad
More Related Content
What's hot (19)
Viewers also liked (14)











Ad
Similar to Building a Modern Data Architecture with Enterprise Hadoop (20)









![Discover.hdp2.2.ambari.final[1]](https://cdn.slidesharecdn.com/ss_thumbnails/discover-150114162536-conversion-gate01-thumbnail.jpg?width=560&fit=bounds)










Ad
More from Slim Baltagi (15)















Recently uploaded (20)





![PRE-NATAL GRnnnmnnnnmmOWTH seminar[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/pre-natalgrowthseminar1-250427093235-de04befc-thumbnail.jpg?width=560&fit=bounds)














Building a Modern Data Architecture with Enterprise Hadoop
- 1. Page 1 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Building A Modern Data Architecture (MDA) Using Enterprise Hadoop Slim Baltagi, Systems Architect Hortonworks Inc. Open-BDA Hadoop Summit 2014 November 18th, 2014
- 2. Page 2 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Your Presenter Slim Baltagi • Currently a Systems Architect in the Professional Services Organization of Hortonworks in the central region (US and Canada). • Over 4 years of Hadoop experience working on 9 Big Data projects. • Slim has over 16 years of IT experience working in various architecture, design, development and consulting roles. • Slim Baltagi holds a master’s degree in Mathematics and is an ABD in computer science from Université Laval, Québec, Canada. • Twitter: @SlimBaltagi
- 3. Page 3 © Hortonworks Inc. 2011 – 2014. All Rights Reserved © Hortonworks Inc. 2013 Outline 1. Drivers for an MDA 2. What’s an MDA 3. Hadoop’s role in an MDA 4. Use Cases related to an MDA 5. Learn More 6. Q&A Page 3
- 4. Page 4 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Traditional Data Architecture Under PressureAPPLICATIONS DATA SYSTEM SOURCES Business Analy:cs Custom Applica:ons Packaged Applica:ons Exis:ng Sources (CRM, ERP, Clickstream, Logs) SILO SILO RDBMS SILO SILO SILO SILO EDW MPP Data growth: New Data Types OLTP, ERP, CRM Systems Unstructured docs, emails Clickstream Server logs Social/Web Data Sensor. Machine Data Geoloca:on 85% Source: IDC ?? " Can’t manage new data paradigm " Constrains data to specific schema " Siloed data " Limited scalability " Economically unfeasible " Limited analytics
- 5. Page 5 © Hortonworks Inc. 2011 – 2014. All Rights Reserved A Modern Data Architecture for New DataAPPLICATIONS DATA SYSTEM REPOSITORIES SOURCES Exis:ng Sources (CRM, ERP, Clickstream, Logs) RDBMS EDW MPP Business Analy:cs Custom Applica:ons Packaged Applica:ons OLTP, ERP, CRM Systems Unstructured documents, emails Clickstream Server logs Sen>ment, Web Data Sensor. Machine Data Geoloca>on New Data Requirements: • Scale • Economics • Flexibility Traditional Data Architecture
- 6. Page 6 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Enterprise Goals for the Modern Data Architecture ü Centrally manage new and existing data ü Provide single view of the customer, product, supply chain ü Run batch, interactive & real time analytic applications on shared datasets ü Assure enterprise-grade security, operations and governance ü Leverage new and existing data center infrastructure investments ü Scalable and affordable; low cost per TB ü Deployment flexibility APPLICATIONSDATASYSTEM Business Analytics Custom Applications Packaged Applications RDBMS EDW MPP YARN: Data Operating System 1 ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° N Interactive Real-TimeBatch CRM ERP Other 1 ° ° ° ° ° ° ° HDFS (Hadoop Distributed File System) SOURCES EXISTING Systems Clickstream Web & Social Geoloca:on Sensor & Machine Server Logs Unstructured
- 7. Page 7 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 1. Drivers for a Modern Data Architecture (MDA) • Semi-Structured and Unstructured – NEW DATA Unstructured documents, emails, Sentiment, Web Data, Sensor, Machine Data, Geolocation, ... • Enterprise Data Warehouse Optimization – REDUCED COSTS Low-value computing tasks such as ETL consume significant EDW resources. When offloaded to Hadoop, these ETL processes can be performed much more efficiently, freeing up your data warehouse to perform high-value functions like analytics and operations.
- 8. Page 8 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 1. Drivers for a Modern Data Architecture (Continued) • Advanced Analytics – NEW ANALYTICS APPS Unlike schema-on-write, which transforms data into specified schema upon load, Hadoop empowers you to store data in any format, and then create schema at that moment when you choose to analyze your data. This unprecedented flexibility opens up new possibilities for iterative analytics and delivers new business value. • Single Cluster, Multiple Workloads – ANY WORKLOAD With Apache Hadoop YARN supporting multiple access methods (such as batch, interactive, streaming and real-time) on a common data set, Hadoop enables you to transform and view data in multiple ways simultaneously, dramatically reducing time to insight.
- 9. Page 9 © Hortonworks Inc. 2011 – 2014. All Rights Reserved © Hortonworks Inc. 2013 Outline 1. Drivers for an MDA 2. What’s an MDA 3. Hadoop’s role in an MDA 4. Use Cases related to an MDA 5. Learn More 6. Q&A Page 9
- 10. Page 10 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 2. What’s a Modern Data Architecture (MDA)? • Apache Hadoop is a core component of a Modern Data Architecture, allowing organizations to collect, store, analyze and manipulate massive quantities of data on their own terms—regardless of the source of that data, how old it is, where it is stored, or under what format. • The Hortonworks Data Platform (HDP) delivers Enterprise Apache Hadoop, deeply integrated with existing systems to create a highly efficient, highly scalable way to manage all your enterprise data. • Integrate new & existing data sets, with existing tools & skills. • Make all data available for shared access and processing in multitenant infrastructure • Batch, interactive & real-time use cases
- 11. Page 11 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 4. Hadoop’s role in an MDA
- 12. Page 12 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 3. What’s a Modern Data Architecture (MDA)?
- 13. Page 13 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
- 14. Page 14 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
- 15. Page 15 © Hortonworks Inc. 2011 – 2014. All Rights Reserved © Hortonworks Inc. 2013 Outline 1. Drivers for an MDA 2. What’s an MDA 3. Hadoop’s role in an MDA 4. Use Cases related to an MDA 5. Learn More 6. Q&A Page 15
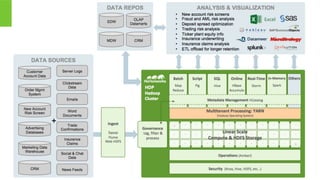
- 16. Page 16 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Key Drivers of Hadoop OPERATIONS TOOLS Provision, Manage & Monitor DEV & DATA TOOLS Build & Test DATA SYSTEM REPOSITORIES SOURCES RDBMS EDW MPP APPLICATIONS Business Analy:cs Custom Applica:ons Packaged Applica:ons Unlock New Approach to Analy:cs • Agile analy>cs via “Schema on Read” with ability to store all data in na>ve format • Create new apps from new types of data A Op:mize Investments, Cut Costs • Focus EDW on high value workloads • Use commodity servers & storage to enable all data (original and historical) to be accessible for ongoing explora>on B Enable a Modern Data Architecture • Integrate new & exis>ng data sets • Make all data available for shared access and processing in mul>tenant infrastructure • Batch, interac>ve & real-‐>me use cases • Integrated with exis>ng tools & skills C EXISTING Systems Clickstream Web & Social Geoloca:on Sensor & Machine Server Logs Unstructured YARN: Data Operating System ° ° ° ° ° ° ° ° ° Interactive Real-TimeBatch HDFS: Hadoop Distributed File System
- 17. Page 17 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Hadoop: It’s About Scale & Structure Hadoop schema governance best fit use processing Required on write Required on read Standards and structured Multiple Structures Limited, no data processing Processing coupled with data data typesStructured Multi and unstructured Complex ACID Transactions Operational Data Store Data Discovery Processing unstructured data Interactive Analytics Traditional RDBMS SCALE (storage & processing) transactionsOptimized, reliable Optimized for analytics
- 18. Page 18 © Hortonworks Inc. 2011 – 2014. All Rights Reserved YARN and HDP Enables the Modern Data Architecture YARN is the architectural center of Hadoop and HDP • YARN enables a common data set across all applications • Batch, interactive & real-time workloads • Support multi-tenant access & processing HDP enables Apache Hadoop to become Enterprise Viable Data Platform with centralized services • Security • Governance • Operations • Productization Enabled broad ecosystem adoption Hortonworks drove this innovation of Hadoop through YARN Hortonworks Data Platform 2.2 YARN: Data Operating System (Cluster Resource Management) 1 ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° Script Pig SQL Hive Tez Tez Java Scala Cascading Tez ° ° ° ° ° ° ° ° ° ° ° ° ° ° HDFS (Hadoop Distributed File System) Stream Storm Search Solr NoSQL HBase Accumulo Slider Slider SECURITYGOVERNANCE OPERATIONSBATCH, INTERACTIVE & REAL-TIME DATA ACCESS In- Memory Spark Provision, Manage & Monitor Ambari Zookeeper Scheduling Oozie Data Workflow, Lifecycle & Governance Falcon Sqoop Flume Kafka NFS WebHDFS Authentication Authorization Audit Data Protection Storage: HDFS Resources: YARN Access: Hive Pipeline: Falcon Cluster: Ranger Cluster: Knox Deployment ChoiceLinux Windows Cloud Others ISV Engines On-Premises
- 19. Page 19 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
- 20. Page 20 © Hortonworks Inc. 2011 – 2014. All Rights Reserved © Hortonworks Inc. 2013 Outline 1. Drivers for an MDA 2. What’s an MDA 3. Hadoop’s role in an MDA 4. Use Cases related to an MDA 5. Learn More 6. Q&A Page 20
- 21. Page 21 © Hortonworks Inc. 2011 – 2014. All Rights Reserved …to real-time personalizationFrom static branding …to repair before breakFrom break then fix …to designer medicineFrom mass treatment …to automated algorithmsFrom educated investing …to 1x1 targetingFrom mass branding A shift in Advertising A shift in Financial Services A shift in Healthcare A shift in Retail A shift in Manufacturing Hadoop enables organizations to cost effectively store and use all of the data available in a way that shifts the business from… Reactive Proactive Shift to Data-driven Means Treating Data like Capital
- 22. Page 22 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Create New Applications from New Types of Data INDUSTRY USE CASE Sentiment & Web Clickstream & Behavior Machine & Sensor Geographic Server Logs Structured & Unstructured Financial Services New Account Risk Screens ✔ ✔ Trading Risk ✔ ✔ Insurance Underwriting ✔ ✔ ✔ Telecom Call Detail Records (CDR) ✔ ✔ Infrastructure Investment ✔ ✔ Real-time Bandwidth Allocation ✔ ✔ ✔ ✔ ✔ Retail 360° View of the Customer ✔ ✔ ✔ Localized, Personalized Promotions ✔ Website Optimization ✔ Manufacturing Supply Chain and Logistics ✔ Assembly Line Quality Assurance ✔ Crowd-sourced Quality Assurance ✔ Healthcare Use Genomic Data in Medical Trials ✔ ✔ Monitor Patient Vitals in Real-Time ✔ ✔ Pharmaceuticals Recruit and Retain Patients for Drug Trials ✔ ✔ Improve Prescription Adherence ✔ ✔ ✔ ✔ Oil & Gas Unify Exploration & Production Data ✔ ✔ ✔ ✔ Monitor Rig Safety in Real-Time ✔ ✔ ✔ Government ETL Offload/Federal Budgetary Pressures ✔ ✔ Sentiment Analysis for Government Programs ✔
- 23. Page 23 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 4.1 Advertising • Mine Grocery & Drug Store POS Data to Identify High-Value Shoppers • Target Ads to Customers in Specific Cultural or Linguistic Segments • Syndicate Videos According to Behavior, Demographics & Channel • ETL Toy Market Research Data for Longer Retention & Deeper Insight • Optimize Online Ad Placement for Retail Websites
- 24. Page 24 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 5. Use Cases related to an MDA (Continued)
- 25. Page 25 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 4.2 Financial Services • Screen New Account Applications for Risk of Default • Monetize Anonymous Banking Data in Secondary Markets • Improve Underwriting Efficiency for Usage-Based Auto Insurance • Analyze Insurance Claims with a Shared Data Lake • Maintain Sub-Second SLAs with a Hadoop “Ticker Plant” • Surveillance of Trading Logs for Anti-Laundering Analysis
- 26. Page 26 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
- 27. Page 27 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 4.3 Healthcare • Access Genomic Data for Medical Trials • Monitor Patient Vitals in Real-Time • Reduce Cardiac Re-Admittance Rates • Machine Learning to Screen for Autism with In-Home Testing • Store Medical Research Data Forever • Recruit Research Cohorts for Pharmaceutical Trials • Track Equipment and Medicines with RFID Data • Improve Prescription Adherence
- 28. Page 28 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
- 29. Page 29 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 4.4 Manufacturing • Assure Just-In-Time Delivery of Raw Materials • Control Quality with Real-Time & Historical Assembly Line Data • Avoid Stoppages with Proactive Equipment Maintenance • Increase Yields in Drug Manufacturing • Crowdsource Quality Assurance
- 30. Page 30 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
- 31. Page 31 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 4.5 Oil & Gas • Slow Decline Curves with Production Parameter Optimization • Define Operational Set Points for Each Well & Receive Alerts on Deviations • Optimize Lease Bidding with Reliable Yield Predictions • Report on Compliance with Environmental , Health and Safety Regulations • Repair Equipment Preventatively with Targeted Maintenance • Integrate Exploration with Seismic Image Processing
- 32. Page 32 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
- 33. Page 33 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 4.6 Public Sector • Understand Public Sentiment About Government Performance • Protect Critical Networks from Threats (Both Internal and External) • Prevent Fraud and Waste • Analyze Social Media to Identify Terrorist Threats • Decrease Budget Pressures by Offloading Expensive SQL Workloads • Crowdsource Reporting for Repairs to Roads and Public Infrastructure • Fulfill “Open Records” and Freedom of Information Requests
- 34. Page 34 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 4.7 Retail • Build a 360 degrees View of the Customer • Analyze Brand Sentiment • Localize & Personalize Promotions • Optimize Websites • Optimize Store Layouts
- 35. Page 35 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
- 36. Page 36 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 4.8 Telecom • Analyze Call Detail Records (CDRs) • Service Equipment Proactively • Rationalize Infrastructure Investments • Recommend Next Product to Buy (NPTB) • Allocate Bandwidth in Real-time • Develop New Products
- 37. Page 37 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
- 38. Page 38 © Hortonworks Inc. 2011 – 2014. All Rights Reserved © Hortonworks Inc. 2013 What is a Data Lake? • An architectural pattern in the data center that uses Hadoop to deliver deeper insight across a large, broad, diverse set of data at efficient scale § But What is it? – It is a PLATFORM for your data. (It is not a database) – Multipurpose open PLATFORM to land all data in a single place and interact with it many ways. § A platform that allows for the ecosystem to provide higher level services (SAS, SAP, Microsoft, Streaming, MPP, In-memory, etc..) § Provides first class APIs and frameworks to enable this integration § Provides first class data management capabilities (metadata management, security, transformation pipelines, replication, retention, etc..) Page 38
- 39. Page 39 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Knox – Perimeter Level Security compute & storage . . . . . . . . compute & storage . . YARN Data Lake HDP Grid AMBARI HDP Data Lake Reference Architecture Page 39 HCATALOG (table & user-defined metadata) Step 2: Model/Apply Metadata Use Case Type 1: Materialize & Exchange Opens up Hadoop to many new use cases Stream Processing, Real-time Search, MPI YARN Apps INTERACTIVE Hive Server (Tez/Stinger) Query/ Analytics/Reporting Tools Tableau/Excel Datameer/Platfora/SAP Use Case Type 2: Explore/Visualize FALCON (data pipeline & flow management) Manage Steps 1-4: Data Management with Falcon Oozie (Batch scheduler) (data processing) HIVE PIG Mahout Exchange HBase Client Sqoop/Hive Downstream Data Sources OLTP HBase EDW (Teradata) Storm SAS SOLR TEZ Step 3: Transform, Aggregate & Materialize MR2 Step 4: Schedule and Orchestrate Ingestion SQOOP FLUME Web HDFS NFS SOURCE DATA ClickStream Data Sales Transaction/Data Product Data Marketing/ Inventory Social Data EDW File JMS REST HTTP Streaming STORM Step 1:Extract & Load
- 40. Page 40 © Hortonworks Inc. 2011 – 2014. All Rights Reserved © Hortonworks Inc. 2013 Outline 1. Drivers for an MDA 2. What’s an MDA 3. Hadoop’s role in an MDA 4. Use Cases related to an MDA 5. Learn More 6. Q&A Page 40
- 41. Page 41 © Hortonworks Inc. 2011 – 2014. All Rights Reserved © Hortonworks Inc. 2013 5. Learn More … Page 41 Resource Location MDA White Paper http://info.hortonworks.com/data-lake-hadoop-whitepaper.html Learn more about Modern Data Architecture (MDA) MDA Web Page http://hortonworks.com/hadoop-modern-data-architecture/ Explore Use Cases by Industry Hortonworks Sandbox http://hortonworks.com/products/hortonworks-sandbox/ Get Started on Hadoop with Hortonworks Sandbox Hadoop Tutorials http://info.hortonworks.com/On-demand-Tutorials_Sign-Up-Page.html On-Demand Hadoop Tutorials Delivered to Your Inbox Enterprise Data Lake http://hortonworks.com/blog/enterprise-hadoop-journey-data-lake/ Enterprise Hadoop and the journey to Data Lake
- 42. Page 42 © Hortonworks Inc. 2011 – 2014. All Rights Reserved © Hortonworks Inc. 2013 Outline 1. Drivers for an MDA 2. What’s an MDA 3. Hadoop’s role in an MDA 4. Use Cases related to an MDA 5. Learn More 6. Q&A Page 42
- 43. Page 43 © Hortonworks Inc. 2011 – 2014. All Rights Reserved 6. Q&A… Thank you!