Building a Real-Time Data Pipeline: Apache Kafka at LinkedIn
39 likes11,324 views

The document discusses LinkedIn's implementation of a real-time data pipeline using Apache Kafka, emphasizing the need to leverage large volumes of data for product development. Key strategies include using a central data pipeline, enforcing data cleanliness, optimizing ETL processes, and ensuring evidence-based correctness. It details Kafka's performance at LinkedIn, reporting billions of messages processed daily across numerous services.





























Building a Real-Time Data Pipeline: Apache Kafka at LinkedIn
- 1. Building a Real-Time Data Pipeline: Apache Kafka at Linkedin Hadoop Summit 2013 Joel Koshy June 2013 LinkedIn Corporation ©2013 All Rights Reserved
- 2. HADOOP SUMMIT 2013 Network update stream
- 3. LinkedIn Corporation ©2013 All Rights Reserved We have a lot of data. We want to leverage this data to build products. Data pipeline
- 4. HADOOP SUMMIT 2013 People you may know
- 5. HADOOP SUMMIT 2013 System and application metrics/logging LinkedIn Corporation ©2013 All Rights Reserved 5
- 6. How do we integrate this variety of data and make it available to all these systems? LinkedIn Confidential ©2013 All Rights Reserved
- 7. HADOOP SUMMIT 2013 Point-to-point pipelines
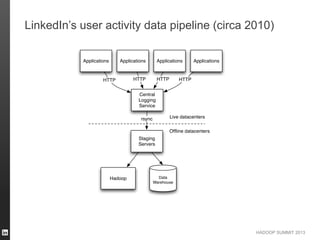
- 8. HADOOP SUMMIT 2013 LinkedIn’s user activity data pipeline (circa 2010)
- 9. HADOOP SUMMIT 2013 Point-to-point pipelines
- 10. HADOOP SUMMIT 2013 Four key ideas 1. Central data pipeline 2. Push data cleanliness upstream 3. O(1) ETL 4. Evidence-based correctness LinkedIn Corporation ©2013 All Rights Reserved 10
- 11. HADOOP SUMMIT 2013 Central data pipeline
- 12. First attempt: don’t re-invent the wheel LinkedIn Confidential ©2013 All Rights Reserved
- 14. Second attempt: re-invent the wheel! LinkedIn Confidential ©2013 All Rights Reserved
- 15. Use a central commit log LinkedIn Confidential ©2013 All Rights Reserved
- 16. HADOOP SUMMIT 2013 What is a commit log?
- 17. HADOOP SUMMIT 2013 The log as a messaging system LinkedIn Corporation ©2013 All Rights Reserved 17
- 18. HADOOP SUMMIT 2013 Apache Kafka LinkedIn Corporation ©2013 All Rights Reserved 18
- 19. HADOOP SUMMIT 2013 Usage at LinkedIn 16 brokers in each cluster 28 billion messages/day Peak rates – Writes: 460,000 messages/second – Reads: 2,300,000 messages/second ~ 700 topics 40-50 live services consuming user-activity data Many ad hoc consumers Every production service is a producer (for metrics) 10k connections/colo LinkedIn Corporation ©2013 All Rights Reserved 19
- 20. HADOOP SUMMIT 2013 Usage at LinkedIn LinkedIn Corporation ©2013 All Rights Reserved 20
- 21. HADOOP SUMMIT 2013 Four key ideas 1. Central data pipeline 2. Push data cleanliness upstream 3. O(1) ETL 4. Evidence-based correctness LinkedIn Corporation ©2013 All Rights Reserved 21
- 22. HADOOP SUMMIT 2013 Standardize on Avro in data pipeline LinkedIn Corporation ©2013 All Rights Reserved 22 { "type": "record", "name": "URIValidationRequestEvent", "namespace": "com.linkedin.event.usv", "fields": [ { "name": "header", "type": { "type": "record", "name": ”TrackingEventHeader", "namespace": "com.linkedin.event", "fields": [ { "name": "memberId", "type": "int", "doc": "The member id of the user initiating the action" }, { "name": ”timeMs", "type": "long", "doc": "The time of the event" }, { "name": ”host", "type": "string", ... ...
- 23. HADOOP SUMMIT 2013 Four key ideas 1. Central data pipeline 2. Push data cleanliness upstream 3. O(1) ETL 4. Evidence-based correctness LinkedIn Corporation ©2013 All Rights Reserved 23
- 24. HADOOP SUMMIT 2013 Hadoop data load (Camus) Open sourced: – https://github.com/linkedin/camus One job loads all events ~10 minute ETA on average from producer to HDFS Hive registration done automatically Schema evolution handled transparently
- 25. HADOOP SUMMIT 2013 Four key ideas 1. Central data pipeline 2. Push data cleanliness upstream 3. O(1) ETL 4. Evidence-based correctness LinkedIn Corporation ©2013 All Rights Reserved 25
- 26. Does it work? “All published messages must be delivered to all consumers (quickly)” LinkedIn Confidential ©2013 All Rights Reserved
- 27. HADOOP SUMMIT 2013 Audit Trail
- 28. HADOOP SUMMIT 2013 Kafka replication (0.8) Intra-cluster replication feature – Facilitates high availability and durability Beta release available https://dist.apache.org/repos/dist/release/kafka/ Rolled out in production at LinkedIn last week LinkedIn Corporation ©2013 All Rights Reserved 28
- 29. HADOOP SUMMIT 2013 Join us at our user-group meeting tonight @ LinkedIn! – Thursday, June 27, 7.30pm to 9.30pm – 2025 Stierlin Ct., Mountain View, CA – http://www.meetup.com/http-kafka-apache-org/events/125887332/ – Presentations (replication overview and use-case studies) from: RichRelevance Netflix Square LinkedIn LinkedIn Corporation ©2013 All Rights Reserved 29
- 30. HADOOP SUMMIT 2013LinkedIn Corporation ©2013 All Rights Reserved 30