


























![REST Example
Specify station ID, data type and datum
(I used water level, mean sea level), latest data point, JSON
Call
https://api.tidesandcurrents.noaa.gov/api/prod/datagetter?date=latest&station=8724580&
product=water_level&datum=msl&units=metric&time_zone=gmt&application=instaclustr&
format=json
Returns
{"metadata": {
"id":"8724580",
"name":"Key West",
"lat":"24.5508”,
"lon":"-81.8081"},
"data":[{
"t":"2020-09-24 04:18",
"v":"0.597",
"s":"0.005", "f":"1,0,0,0", "q":"p"}]}
©Instaclustr Pty Limited, 2020](https://image.slidesharecdn.com/paulbrebnerinstaclustrsponsoredbuildingarealtimedataprocessingpipeline-201001071503/85/Building-a-real-time-data-processing-pipeline-using-Apache-Kafka-Kafka-Connect-Elasticsearch-and-Kibana-30-320.jpg)







![Polls every 10 minutes, writes result to Kafka topic, picked 5 sensors
to use, so 5 connector instances running.
Now have tidal data coming into the tides topic, what next?
REST source
connector
Tides Topic
REST call
JSON result
{"metadata": {
"id":"8724580",
"name":"Key West",
"lat":"24.5508”,
"lon":"-81.8081"},
"data":[{
"t":"2020-09-24 04:18",
"v":"0.597"}]}
©Instaclustr Pty Limited, 2020](https://image.slidesharecdn.com/paulbrebnerinstaclustrsponsoredbuildingarealtimedataprocessingpipeline-201001071503/85/Building-a-real-time-data-processing-pipeline-using-Apache-Kafka-Kafka-Connect-Elasticsearch-and-Kibana-38-320.jpg)

![And configure the included Elasticsearch sink connector
to send data to Elasticsearch
REST source
connector
Tides Topic
REST call
JSON result
{"metadata": {
"id":"8724580",
"name":"Key West",
"lat":"24.5508”,
"lon":"-81.8081"},
"data":[{
"t":"2020-09-24 04:18",
"v":"0.597"}]}
Elastic sink connector Tides Index
©Instaclustr Pty Limited, 2020](https://image.slidesharecdn.com/paulbrebnerinstaclustrsponsoredbuildingarealtimedataprocessingpipeline-201001071503/85/Building-a-real-time-data-processing-pipeline-using-Apache-Kafka-Kafka-Connect-Elasticsearch-and-Kibana-40-320.jpg)

![REST source
connector
Tides Topic
REST call
JSON result
{"metadata": {
"id":"8724580",
"name":"Key West",
"lat":"24.5508”,
"lon":"-81.8081"},
"data":[{
"t":"2020-09-24 04:18",
"v":"0.597"}]}
Elastic sink connector Tides Index
Great! It’s All Working!? Sort Of!
Tide data arriving in Tides Index!
But, in default index mappings, everything is a String.
To graph them as time series by name need a custom mapping.
©Instaclustr Pty Limited, 2020
{"metadata": {
"id":”String",
"name":”String",
"lat":”String”,
"lon":”String"},
"data":[{
"t":”String",
"v":”String"}]}](https://image.slidesharecdn.com/paulbrebnerinstaclustrsponsoredbuildingarealtimedataprocessingpipeline-201001071503/85/Building-a-real-time-data-processing-pipeline-using-Apache-Kafka-Kafka-Connect-Elasticsearch-and-Kibana-42-320.jpg)















![curl -u elasticName:elasticPassword ”elasticURL:9201/ _ingest/pipeline/locationPipe" -X PUT -H 'Content-Type:
application/json' -d'
{
"description" : ”construct geo-point String field",
"processors" : [
{
"set" : {
"field": "metadata.location",
"value": "{{metadata.lat}},{{metadata.lon}}"
}
}
]
}
'
2. Create new ingest pipeline to construct new location geo-point
String from existing lat lon fields
©Instaclustr Pty Limited, 2020](https://image.slidesharecdn.com/paulbrebnerinstaclustrsponsoredbuildingarealtimedataprocessingpipeline-201001071503/85/Building-a-real-time-data-processing-pipeline-using-Apache-Kafka-Kafka-Connect-Elasticsearch-and-Kibana-58-320.jpg)

![REST source
connector
Tides Topic
REST call
JSON result
{"metadata": {
"id":"8724580",
"name":"Key West",
"lat":"24.5508”,
"lon":"-81.8081"},
"data":[{
"t":"2020-09-24 04:18",
"v":"0.597"}]}
Elastic sink connector Tides Index
Now we have a pipeline transforming the raw data and adding
geo-point location data in Elasticsearch
{"metadata": {
"id":"8724580",
"name":"Key West",
"lat":"24.5508”,
"lon":"-81.8081”,
”location”: “24.5508,-81.8081”},
"data":[{
"t":"2020-09-24 04:18",
"v":"0.597"}]}
LocationPipe
ingestor
©Instaclustr Pty Limited, 2020](https://image.slidesharecdn.com/paulbrebnerinstaclustrsponsoredbuildingarealtimedataprocessingpipeline-201001071503/85/Building-a-real-time-data-processing-pipeline-using-Apache-Kafka-Kafka-Connect-Elasticsearch-and-Kibana-60-320.jpg)








































Ad
More Related Content
What's hot (20)
Similar to Building a real-time data processing pipeline using Apache Kafka, Kafka Connect, Elasticsearch and Kibana (20)


















Ad
More from Paul Brebner (20)




















Ad
Recently uploaded (20)




















Building a real-time data processing pipeline using Apache Kafka, Kafka Connect, Elasticsearch and Kibana
- 1. Building a Real-Time Data Processing Pipeline Using Apache Kafka, Kafka Connect, Elasticsearch, and Kibana Paul Brebner Instaclustr—Technology Evangelist Instaclustr Sponsored Booth Presentation 30 September ApacheCon 2020 ©Instaclustr Pty Limited, 2020
- 2. Blogs (54): www.instaclustr.com/paul-brebner/ Who Am I? What do I do? 1 year ago (ApacheCon Europe 2019)—Look it’s a light! ©Instaclustr Pty Limited, 2020
- 3. Who Is Instaclustr? ©Instaclustr Pty Limited, 2020
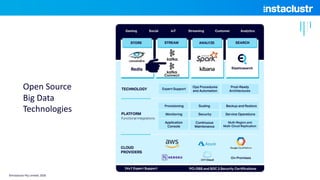
- 4. A complete ecosystem to support mission critical applications. Instaclustr Managed Platform ©Instaclustr Pty Limited, 2020
- 5. Open Source Big Data Technologies ©Instaclustr Pty Limited, 2020
- 6. Open Source Big Data Technologies ©Instaclustr Pty Limited, 2020
- 7. Open Source Big Data Technologies ©Instaclustr Pty Limited, 2020
- 8. Open Source Big Data Technologies ©Instaclustr Pty Limited, 2020
- 9. Open Source Big Data Technologies ©Instaclustr Pty Limited, 2020
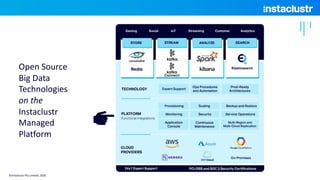
- 10. Open Source Big Data Technologies on the Instaclustr Managed Platform ©Instaclustr Pty Limited, 2020
- 11. ©Instaclustr Pty Limited, 2020 Open Source Big Data Technologies on the Instaclustr Managed Platform
- 12. ©Instaclustr Pty Limited, 2020 Open Source Big Data Technologies on the Instaclustr Managed Platform
- 13. ©Instaclustr Pty Limited, 2020 Open Source Big Data Technologies on the Instaclustr Managed Platform on multiple cloud providers
- 14. This talk… Focuses on three recent additions to our managed platform: • Kafka Connect • Elasticsearch • Kibana ©Instaclustr Pty Limited, 2020
- 15. • Technology Overview • What’s the Story? • Data sources • Provisioning clusters • Configuring Kafka source and sink connectors • Elasticsearch mappings • Kibana Visualizations • Elasticsearch Ingest Pipeline • Kibana Maps • Handling failure Overview ©Instaclustr Pty Limited, 2020
- 16. In general integration can be—complicated… ©Instaclustr Pty Limited, 2020
- 17. ● Zero-code integration ● High availability ● Elastic scaling independent of Kafka Source Connectors Sink Connectors Kafka Connect cluster Syslog Kafka Cluster and many more.. and many more.. Sources Sinks Or—Easy, with Kafka Connect What? Why? ● Distributed solution to integrate Kafka with other heterogeneous data sources/stores. ● Connectors (source or sink) handle specifics of particular integrations o Source Kafka o Kafka Sink ©Instaclustr Pty Limited, 2020
- 18. Elasticsearch—scalable search of indexed documents Kibana—visualization Open Distro for Elasticsearch—100% Apache 2.0 licensed Documents Indices Managed Elasticsearch + Kibana ©Instaclustr Pty Limited, 2020
- 19. What’s The Story? ©Instaclustr Pty Limited, 2020
- 20. What’s The Story? ©Instaclustr Pty Limited, 2020 Kafka Summit—CDC built Kafka COVID-19 pipeline in < 30 days
- 21. What’s The Story? ©Instaclustr Pty Limited, 2020 Instaclustr consultants built an integration demo using public climate change data via REST connectors running on docker Kafka Summit—CDC built Kafka COVID-19 pipeline in < 30 days
- 22. What’s The Story? ©Instaclustr Pty Limited, 2020 Instaclustr consultants built an integration demo using public climate change data via REST connectors running on docker Idea: Use streaming REST public data sources AND deploy on Instaclustr managed platform Kafka Summit—CDC built Kafka COVID-19 pipeline in < 30 days
- 23. What’s The Story? ©Instaclustr Pty Limited, 2020 Instaclustr consultants built an integration demo using public climate change data via REST connectors running on docker Idea: Use streaming REST public data sources AND deploy on Instaclustr managed platform Look for public streaming REST APIs with easy to use JSON data format, complete data, interesting domain, not political or apocalyptic… Impossible? Kafka Summit—CDC built Kafka COVID-19 pipeline in < 30 days
- 24. https://oceanservice.noaa.gov/ Success! Tides follow Lunar Day USA Tidal Data National Oceanic and Atmospheric Administration ©Instaclustr Pty Limited, 2020
- 25. Bonus, NOAA tidal map https://tidesandcurrents.noaa.gov/map/ ©Instaclustr Pty Limited, 2020
- 26. Bonus, NOAA tidal map https://tidesandcurrents.noaa.gov/map/ What’s here? ©Instaclustr Pty Limited, 2020
- 27. ©Instaclustr Pty Limited, 2020
- 28. ©Instaclustr Pty Limited, 2020
- 29. API description https://api.tidesandcurrents.noaa.gov/api/prod/ ©Instaclustr Pty Limited, 2020
- 30. REST Example Specify station ID, data type and datum (I used water level, mean sea level), latest data point, JSON Call https://api.tidesandcurrents.noaa.gov/api/prod/datagetter?date=latest&station=8724580& product=water_level&datum=msl&units=metric&time_zone=gmt&application=instaclustr& format=json Returns {"metadata": { "id":"8724580", "name":"Key West", "lat":"24.5508”, "lon":"-81.8081"}, "data":[{ "t":"2020-09-24 04:18", "v":"0.597", "s":"0.005", "f":"1,0,0,0", "q":"p"}]} ©Instaclustr Pty Limited, 2020
- 31. REST call JSON result Let’s start the pipeline using this REST API for data sources… ©Instaclustr Pty Limited, 2020
- 32. What Else Do We Need? The Instaclustr Console Provision Kafka and Kafka Connect clusters ©Instaclustr Pty Limited, 2020
- 33. What Else Do We Need? Select cloud provider, region, instance size and number, security etc. ©Instaclustr Pty Limited, 2020
- 34. What Else Do We Need? Tell Kafka connect cluster which Kafka cluster to use, then provision ©Instaclustr Pty Limited, 2020 Your IP
- 35. Now we have a Kafka and Kafka Connect clusters ©Instaclustr Pty Limited, 2020
- 36. Next, find a REST connector, deploy to S3 bucket, tell connect cluster which bucket, configure connector and run REST source connector Tides Topic REST call JSON result (Automatically created) ©Instaclustr Pty Limited, 2020 BYO connectors instructions https://www.instaclustr.com/support/documentation/kafka- connect/accessing-and-using-kafka-connect/updating-custom- connectors/
- 37. curl https://connectorClusterIP:8083/connectors -k -u name:password -X POST -H 'Content-Type: application/json' -d ' { "name": "source_rest_tide_1", "config": { "key.converter":"org.apache.kafka.connect.storage.StringConverter", "value.converter":"org.apache.kafka.connect.storage.StringConverter", "connector.class": "com.tm.kafka.connect.rest.RestSourceConnector", "tasks.max": "1", "rest.source.poll.interval.ms": "600000", "rest.source.method": "GET", "rest.source.url": "https://api.tidesandcurrents.noaa.gov/api/prod/datagetter?date=latest&station=8454000&product=water_level&datum= msl&units=metric&time_zone=gmt&application=instaclustr&format=json", "rest.source.headers": "Content-Type:application/json,Accept:application/json", "rest.source.topic.selector": "com.tm.kafka.connect.rest.selector.SimpleTopicSelector", "rest.source.destination.topics": "tides-topic" } }' REST source connector configuration including connector name, class, URL, topic ©Instaclustr Pty Limited, 2020
- 38. Polls every 10 minutes, writes result to Kafka topic, picked 5 sensors to use, so 5 connector instances running. Now have tidal data coming into the tides topic, what next? REST source connector Tides Topic REST call JSON result {"metadata": { "id":"8724580", "name":"Key West", "lat":"24.5508”, "lon":"-81.8081"}, "data":[{ "t":"2020-09-24 04:18", "v":"0.597"}]} ©Instaclustr Pty Limited, 2020
- 39. Next - Provision Elasticsearch+Kibana clusters ©Instaclustr Pty Limited, 2020
- 40. And configure the included Elasticsearch sink connector to send data to Elasticsearch REST source connector Tides Topic REST call JSON result {"metadata": { "id":"8724580", "name":"Key West", "lat":"24.5508”, "lon":"-81.8081"}, "data":[{ "t":"2020-09-24 04:18", "v":"0.597"}]} Elastic sink connector Tides Index ©Instaclustr Pty Limited, 2020
- 41. curl https://connectorClusterIP:8083/connectors -k -u name:password -X POST -H 'Content-Type: application/json' -d ' { "name" : "elastic-sink-tides", "config" : { "connector.class" : "com.datamountaineer.streamreactor.connect.elastic7.ElasticSinkConnector", "tasks.max" : 3, "topics" : "tides", "connect.elastic.hosts" : ”ip", "connect.elastic.port" : 9201, "connect.elastic.kcql" : "INSERT INTO tides-index SELECT * FROM tides-topic", "connect.elastic.use.http.username" : ”elasticName", "connect.elastic.use.http.password" : ”elasticPassword" } }' Configure sink connector name, class, index and topic. The index is created with default mappings if it doesn’t already exist. ©Instaclustr Pty Limited, 2020
- 42. REST source connector Tides Topic REST call JSON result {"metadata": { "id":"8724580", "name":"Key West", "lat":"24.5508”, "lon":"-81.8081"}, "data":[{ "t":"2020-09-24 04:18", "v":"0.597"}]} Elastic sink connector Tides Index Great! It’s All Working!? Sort Of! Tide data arriving in Tides Index! But, in default index mappings, everything is a String. To graph them as time series by name need a custom mapping. ©Instaclustr Pty Limited, 2020 {"metadata": { "id":”String", "name":”String", "lat":”String”, "lon":”String"}, "data":[{ "t":”String", "v":”String"}]}
- 43. curl -u elasticName:elasticPassword ”elasticURL:9201/tides-index" -X PUT -H 'Content-Type: application/json' -d' { "mappings" : { "properties" : { "data" : { "properties" : { "t" : { "type" : "date", "format" : "yyyy-MM-dd HH:mm" }, "v" : { "type" : "double" }, "f" : { "type" : "text" }, "q" : { "type" : "text" }, "s" : { "type" : "text" } } }, "metadata" : { "properties" : { "id" : { "type" : "text" }, "lat" : { "type" : "text" }, "long" : { "type" : "text" }, "name" : { "type" : ”keyword" } }}}} }' Custom mapping “t” is a date, “v” is a double, and “name” is a keyword. ©Instaclustr Pty Limited, 2020
- 44. • Every time you • Change an Elasticsearch index mapping, you have to • Delete the index • Index all the data again • But where does the data come from? • Two options: • Using a Kafka sink connector the data is already in the Kafka topic, so just replay it, or, • Use Elasticsearch reindex operation • The hard part is over, now… Reindexing! ©Instaclustr Pty Limited, 2020
- 45. Start Kibana With A Single Click ©Instaclustr Pty Limited, 2020
- 46. ©Instaclustr Pty Limited, 2020
- 47. Visualization Steps 1: Index Pattern (to get data from Elasticsearch) Settings -> Index Patterns -> Create Index Pattern -> Define -> Configure with “t” as timefilter field 2. Create Visualization (to create a graph type) Visualizations -> Create Visualization -> New Visualization -> Line -> Choose Source = pattern from 1 3. Configure Graph Settings (to display data correctly) Select time range, select aggregation for y-axis = average -> data.v -> select Buckets -> Split series metadata.name -> X-axis -> Data Histogram = data.t ©Instaclustr Pty Limited, 2020
- 48. Time (x axis) vs. average (over 30m) tide level (relative to average level) in meters for the 5 sample stations ©Instaclustr Pty Limited, 2020
- 49. Showing Lunar Day (24 hours 50 minutes) Lunar Day (24h 50m) ©Instaclustr Pty Limited, 2020
- 50. Tidalrange Showing Tidal Range (high tide – low tide) ©Instaclustr Pty Limited, 2020
- 51. By R. Ray, NASA Goddard Space Flight Center, Jet Propulsion Laboratory, Scientific Visualization Studio - TOPEX/Poseidon: Revealing Hidden Tidal Energy, Public Domain Tide range varies depending on moon, sun, local geography, and weather! ©Instaclustr Pty Limited, 2020
- 52. By R. Ray, NASA Goddard Space Flight Center, Jet Propulsion Laboratory, Scientific Visualization Studio - TOPEX/Poseidon: Revealing Hidden Tidal Energy, Public Domain Neah Bay is near here ©Instaclustr Pty Limited, 2020
- 53. By R. Ray, NASA Goddard Space Flight Center, Jet Propulsion Laboratory, Scientific Visualization Studio - TOPEX/Poseidon: Revealing Hidden Tidal Energy, Public Domain Australia’s Biggest Tide is here ©Instaclustr Pty Limited, 2020
- 54. Tides of over 11 meters are forced through two narrow passes creating the popular tourist attraction known as the Horizontal Waterfalls in the Kimberley's Talbot Bay. Next, a map to show the sensor locations to understand tidal ranges (Photo by Richard Costin) ©Instaclustr Pty Limited, 2020
- 55. ©Instaclustr Pty Limited, 2020 But, there are no geo-points in the data!
- 56. Mapping Steps 1. Add geo-point field to index mapping 2. Create Elasticsearch ingest pipeline to construct new field 3. Add as default ingest pipeline to index Problem: Elasticsearch doesn’t recognize separate lat lon fields as geo-points Solution: Add an Elasticsearch ingest pipeline to pre- process documents before they are indexed (Need to reindex again) ©Instaclustr Pty Limited, 2020
- 57. curl -u elasticName:elasticPassword ”elasticURL:9201/tides-index" -X PUT -H 'Content-Type: application/json' -d' { "mappings" : { "properties" : { "data" : { "properties" : { "t" : { "type" : "date", "format" : "yyyy-MM-dd HH:mm" }, "v" : { "type" : "double" }, "f" : { "type" : "text" }, "q" : { "type" : "text" }, "s" : { "type" : "text" } } }, "metadata" : { "properties" : { "id" : { "type" : "text" }, "lat" : { "type" : "text" }, "long" : { "type" : "text" }, "location" : { "type" : "geo_point" }, "name" : { "type" : ”keyword" } }}}} }' 1. Add a new “location” field with a geo_point data type to the mapping and index ©Instaclustr Pty Limited, 2020
- 58. curl -u elasticName:elasticPassword ”elasticURL:9201/ _ingest/pipeline/locationPipe" -X PUT -H 'Content-Type: application/json' -d' { "description" : ”construct geo-point String field", "processors" : [ { "set" : { "field": "metadata.location", "value": "{{metadata.lat}},{{metadata.lon}}" } } ] } ' 2. Create new ingest pipeline to construct new location geo-point String from existing lat lon fields ©Instaclustr Pty Limited, 2020
- 59. 3. Add locationPipe as default pipeline to the index curl -u elasticName:elasticPassword ”elasticURL:9201/tides-index/_settings?pretty" -X PUT -H 'Content-Type: application/json' -d' { "index" : { "default_pipeline" : ”locationPipe" } } ' ©Instaclustr Pty Limited, 2020
- 60. REST source connector Tides Topic REST call JSON result {"metadata": { "id":"8724580", "name":"Key West", "lat":"24.5508”, "lon":"-81.8081"}, "data":[{ "t":"2020-09-24 04:18", "v":"0.597"}]} Elastic sink connector Tides Index Now we have a pipeline transforming the raw data and adding geo-point location data in Elasticsearch {"metadata": { "id":"8724580", "name":"Key West", "lat":"24.5508”, "lon":"-81.8081”, ”location”: “24.5508,-81.8081”}, "data":[{ "t":"2020-09-24 04:18", "v":"0.597"}]} LocationPipe ingestor ©Instaclustr Pty Limited, 2020
- 61. Mapping Visualization Steps 1. Create Visualization Visualizations -> Create visualization -> New Coordinate Map -> Select index patterns -> Visualization with default map 2. Configure Graph Settings (to display data correctly) Select Metrics -> Aggregation (min) -> Field -> data.v -> Buckets -> Geo coordinates -> Geohash -> Field -> metadata.location Reuse existing index pattern ©Instaclustr Pty Limited, 2020
- 62. ©Instaclustr Pty Limited, 2020 Map showing sensor locations and min values over last week
- 63. Add your own custom Web Map Service (WMS) layers URL https://services.nationalmap.gov/arcgis/services/USGSNAIPPlus/MapServer/WMSServer Layers 1,2,3,5,6,7,9,10,11,13,14,15,17,18,19,21,22,23,25,26,27,29,30,31,32 ©Instaclustr Pty Limited, 2020
- 64. REST source connector Tides Topic REST call JSON result {"error": {"message":"No data was found. This product may not be offered at this station at the requested time."}} Elastic sink connector Tides Index What can go wrong? REST call can return error message, but doesn’t treat it as an error so it’s sent to Tides Topic. LocationPipe ingestor ©Instaclustr Pty Limited, 2020
- 65. REST source connector Tides Topic REST call JSON result {"error": {"message":"No data was found. This product may not be offered at this station at the requested time."}} Elastic sink connector Tides Index Elastic sink connector tries to read the error message and fails to FAILED state. Exceptions viewable in the Kafka connect logs topic. Exceptions viewable in the Kafka connect logs topic. LocationPipe ingestor ©Instaclustr Pty Limited, 2020 X FAILED X Connect logs topic
- 66. REST source connector Tides Topic REST call JSON result {"error": {"message":"No data was found. This product may not be offered at this station at the requested time."}} Elastic sink connector Tides Index Current workaround is to monitor and regularly restart failed connectors. Exceptions viewable in the Kafka connect logs topic. LocationPipe ingestor ©Instaclustr Pty Limited, 2020 FAILED? RUNNING Restart! X
- 67. REST source connector Tides Topic REST call JSON result {"error": {"message":"No data was found. This product may not be offered at this station at the requested time."}} Elastic sink connector Tides Index Better solution - if connectors support KIP-298 “Error Handling in Connect” (not all do) then configure to ignore input errors. Errors sent to ”dead letter” topic. LocationPipe ingestor ©Instaclustr Pty Limited, 2020 Ignore Dead letter topic
- 68. • Instaclustr consultants, Kafka and Elasticsearch dev teams , graphic design and marketing teams • Zeke, Mussa, Michael, Hendra, Rob, Harvey, Jill, Gina and more! • Try us out! Build the same or your own pipeline with our free trial at Instaclustr.com Thanks to… ©Instaclustr Pty Limited, 2020
- 69. ©Instaclustr Pty Limited, 2020