Building NLP solutions using Python
Download as PPTX, PDF2 likes501 views

Charlotte Bots and AI group meetup presentation for September 2018 on Building Natural Language Processing solutions


















































Ad
More Related Content
What's hot (20)
Similar to Building NLP solutions using Python (20)


















Ad
More from botsplash.com (14)














Ad
Recently uploaded (20)




















Building NLP solutions using Python
- 1. Building NLP solutions using Python By Ramu Pulipati, @botsplash
- 2. Introduction to NLP • Natural Language: • General purpose communications • Distinct difference between humans and Animals • Much difficult to interpret from Formal Language • Natural Language Processing (NLP) Advancements • Earlier focus was on Linguistics and Computer Science • Current evolution is focused on Machine Learning, specifically Deep Learning and Neural Networks • Varied degrees of implementation based on use case
- 3. Scope of Natural Language Processing • Read • Natural Language Understanding (NLU) • Write • Natural Language Generation (NLG) • Speak • Speech Recognition / Syntesis
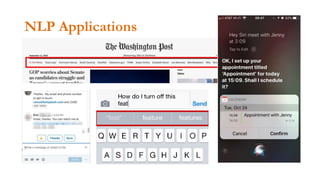
- 5. More Applications … • Email Spam • Siri / Alexa / Cortana • Legal Contacts to find Action clauses • Health Care Records • Energy Sector / Utilities / Inspection Records • Automated Agents • Appointment Scheduling • Auto Email Responses • Typing Suggestions • Spelling Check • Predicting Crops • Social Media Propaganda • Press/Earnings releases • Weather Reports • Search Engines • News categorization • Chatbot • NY Times Oped author analysis
- 6. State of NLP Source: https://www.slideshare.net/healess/sk-t-academy-lecture-note
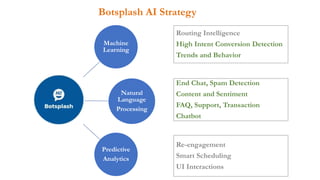
- 7. Botsplash AI Strategy Machine Learning Natural Language Processing Predictive Analytics Routing Intelligence High Intent Conversion Detection Trends and Behavior End Chat, Spam Detection Content and Sentiment FAQ, Support, Transaction Chatbot Re-engagement Smart Scheduling UI Interactions
- 8. Focus on solvable/acceptable problems I’m looking for 30yr mortgage loan in Charlotte, NC (Named Entity Recognition) Thanks for your help. Great chatting with you. (classification) Lets connect tomorrow. Anytime evening will work for me. (classification / intent / actionable) This rate is unacceptable. What can you do? (sentiment)
- 9. Leading NLP Providers • AWS Comprehend • Google Cloud NLP • Microsoft Project Oxford • IBM Watson • Aylien • Cennest Comparison: https://cognitiveintegratorapp.azurewebsites.net/
- 10. Text Processing Roundup • Normalization • Text Classification • Text Similarity • Text Extraction • Topic Modeling • Semantic Search • Sentiment Analysis
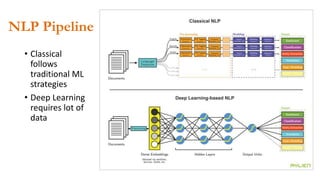
- 11. NLP Pipeline • Classical follows traditional ML strategies • Deep Learning requires lot of data
- 12. Getting started • Python Installation. Use 3+. • Data science packages installation. Use “pip install” or Anaconda • Always use “virtualenv” when setting up environments. • Start with Jupyter notebooks and convert it production code. • Use cloud hosted jupyter notebooks with access to GPU from floydhub, paperspace, Google, Amazon or Azure
- 13. Python packages for NLP • NLP Focus Packages • NLTK • Spacy • Gensim • Textblob • Scikit Learn • Stanford NLP (java) • WordNet, SentiWordNet • FastText / MUSE / Faiss • Deep Learning Frameworks • Tensorflow / Keras • Pytorch • Other Noteworth • Scrapy • Newspaper • nlp-architect
- 14. NLTK Code Tour • Tokenization (Dictionary and Regex) • Stemming • Lemma • NLP Grammar - Chunking and Chinking • Entity Recognition • WikiQuiz
- 15. Word Embeddings • Paper published by Mikolov 2013 Example: Man is to Woman, then King is to _______ • Multi-dimensional space of word representations with proximity based on similarity of the words (word vectors) • Algebraic expressions can be applied on Word vectors • Building Word embedding: Provide lot of data with features to look • Word2vec is a popular word embedding implemented with Neural network • Other implementations such as Glove use co-occurrence matrices
- 17. Spacy.io Lightning Tour • Industrial Strength, Fast • POS Tagging and Dependency Parsing • Named Entities, Word embedding and Similarity • Custom Pipelines • Visualization
- 18. Text classification • Use cases: Spam, Actionable events, Intents • For Content based or Request based classification • Steps involve Preparing -> Training -> Prediction • Feature Extractions • Bag of Words • TD-IDF model • Word Vectors: Averaged, TD-IDF, tc • Starspace model • FastText • Classification alg: Multinomial Bayes or SVM
- 19. Steps to classifying your data 1. Identify tags to be applied 2. Manually add tags for the data (possibly in the application) 3. Build a classification algorithm 4. Setup your application to auto classify tags 5. Evaluate silently and then enable the actions
- 20. Sentiment Analysis • Use case: Reviews, Chat transcripts, etc • Supervised techniques are effective for a domain • Packages: • SentiWordNet • StanfordNLP • Spacy Sentiment Analysis (incomplete)
- 21. Summarization • Summarization is hard • Uses variety of techniques including Text extraction, Feature Matrix, TD-IDF, Co-location, SVD and other methods • Implement LSA to under • Review of implementations: • Spacy • TextRank • Pyteaser • Textteaser • Sumy
- 22. Code Review / Demo Apps • Jupyter Notebooks • NLTK Code Review • Space Code Review • NLTK Grammar Parsing • WikiQuiz • Sequence to Sequence Chatbot • DeepQA demo • Topic Modeling Code Review • Text Similarity – Phrase Matcher API
- 23. Follow up Learning • Websites: • Allen AI - NLP • Fast AI • Malabuba • Coursera • Youtube • Resources • Sanni Oluwatoyin Yetunde Google Slides • Cambridge Data Science Group presentation • nlp.fast.ai
Editor's Notes
- #3: Natural language is ambiguous, where formal language is precise Formal language: Programming language
- #8: The botsplash framework encompasses and build on strong concepts and strategy to augment business processes to achieve best outcome for business and customers of the business botsplash is a Software-as-a-Service platform on a model of B-2-b-2-C. We want the “B”(business) to provide “C”(consumers of business) the best, easy to use and reliable technology to reduce costs , increase business transactions, efficiency and customer satisfaction.
- #12: ML Strategies: * Explore data and use visualizations * Create Train and Test data * Setup training algorithm and feature * Train Model * Test the result * Rinse and Repeat until the results are satisfactory
- #19: Multinomial Naïve Bayes is used to predict more than 2 classes. Popular Bayes algorithm that expects each feature is independent Support vector machine are supervised algorithms used for classification, regression, anomaly and outlier detections For classification algorithm, we focus on following metrics: accuracy, precision, recall and f1 score