Burst data retrieval after 50k GPU Cloud run
0 likes6,126 views

We ran a 50k GPU multi-cloud simulation to support the IceCube science. This talk provided an overview of what happened to the associated data. Presented at the Internet2 booth at SC19.































































![Frossie Economou & Angelo Fausti [Vera C. Rubin Observatory] | How InfluxDB H...](https://cdn.slidesharecdn.com/ss_thumbnails/veracrubininfluxdays2020-201111202349-thumbnail.jpg?width=560&fit=bounds)


Ad
More Related Content
What's hot (19)
Similar to Burst data retrieval after 50k GPU Cloud run (20)

















Ad
More from Igor Sfiligoi (20)




















Ad
Recently uploaded (20)




















Burst data retrieval after 50k GPU Cloud run
- 1. Burst retrieval of data from multiple Cloud regions for Multi-Messenger Astrophysics with IceCube Igor Sfiligoi UCSD/SDSC
- 2. Jensen Huang keynote yesterday 2 The Largest Cloud Simulation in History 50k NVIDIA GPUs in the Cloud 350 Petaflops for 2 hours Distributed across US, Europe & Asia On Saturday morning we bought all GPU capacity that was for sale in Amazon Web Services, Microsoft Azure, and Google Cloud Platform worldwide
- 3. Jensen Huang keynote yesterday 3 The Largest Cloud Simulation in History 50k NVIDIA GPUs in the Cloud 350 Petaflops for 2 hours Distributed across US, Europe & Asia On Saturday morning we bought all GPU capacity that was for sale in Amazon Web Services, Microsoft Azure, and Google Cloud Platform worldwide About 20TBytes of data produced in the process
- 5. IceCube 5 A cubic kilometer of ice at the south pole is instrumented with 5160 optical sensors. Astrophysics: • Discovery of astrophysical neutrinos • First evidence of neutrino point source (TXS) • Cosmic rays with surface detector Particle Physics: • Atmospheric neutrino oscillation • Neutrino cross sections at TeV scale • New physics searches at highest energies Earth Science: • Glaciology • Earth tomography A facility with very diverse science goals Restrict this talk to high energy Astrophysics
- 6. High Energy Astrophysics Science case for IceCube 6 Universe is opaque to light at highest energies and distances. Only gravitational waves and neutrinos can pinpoint most violent events in universe. Fortunately, highest energy neutrinos are of cosmic origin. Effectively “background free” as long as energy is measured correctly.
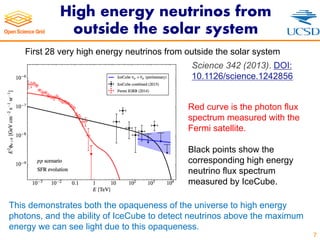
- 7. High energy neutrinos from outside the solar system 7 First 28 very high energy neutrinos from outside the solar system Red curve is the photon flux spectrum measured with the Fermi satellite. Black points show the corresponding high energy neutrino flux spectrum measured by IceCube. This demonstrates both the opaqueness of the universe to high energy photons, and the ability of IceCube to detect neutrinos above the maximum energy we can see light due to this opaqueness. Science 342 (2013). DOI: 10.1126/science.1242856
- 8. Understanding the Origin 8 We now know high energy events happen in the universe. What are they? p + g D + p + 0 p + g g p + g D + n + + n + + Co Aya Ishihara The hypothesis: The same cosmic events produce neutrinos and photons We detect the electrons or muons from neutrino that interact in the ice. Neutrino interact very weakly => need a very large array of ice instrumented to maximize chances that a cosmic neutrino interacts inside the detector. Need pointing accuracy to point back to origin of neutrino. Telescopes the world over then try to identify the source in the direction IceCube is pointing to for the neutrino. Multi-messenger Astrophysics
- 9. The ν detection challenge 9 Optical Pro Aya Ishiha Combining all the possible info These features are included in We re al a s be de eloping h Nature never tell us a perfec satisfactory agreem Ice properties change with depth and wavelength Observed pointing resolution at high energies is systematics limited. Central value moves for different ice models Improved e and τ reconstruction Þ increased neutrino flux detection Þ more observations Photon propagation through ice runs efficiently on single precision GPU. Detailed simulation campaigns to improve pointing resolution by improving ice model. Improvement in reconstruction with better ice model near the detectors
- 10. First evidence of an origin 10 First location of a source of very high energy neutrinos. Neutrino produced high energy muon near IceCube. Muon produced light as it traverses IceCube volume. Light is detected by array of phototubes of IceCube. IceCube alerted the astronomy community of the observation of a single high energy neutrino on September 22 2017. A blazar designated by astronomers as TXS 0506+056 was subsequently identified as most likely source in the direction IceCube was pointing. Multiple telescopes saw light from TXS at the same time IceCube saw the neutrino. Science 361, 147-151 (2018). DOI:10.1126/science.aat2890
- 11. IceCube’s Future Plans 11 | IceCube Upgrade and Gen2 | Summer Blot | TeVPA 2018 The IceCube-Gen2 Facility Preliminary timeline MeV- to EeV-scale physics Surface array High Energy Array Radio array PINGU IC86 2016 2017 2018 2019 2020 2021 2022 2023 2024 2025 2026 … 2032 Today Surface air shower ConstructionR&D Design & Approval IceCube Upgrade IceCube Upgrade Deployment Near term: add more phototubes to deep core to increase granularity of measurements. Longer term: • Extend instrumented volume at smaller granularity. • Extend even smaller granularity deep core volume. • Add surface array. Improve detector for low & high energy neutrinos
- 12. Details on the Cloud Burst
- 13. The Idea • Integrate all GPUs available for sale worldwide into a single HTCondor pool. - use 28 regions across AWS, Azure, and Google Cloud for a burst of a couple hours, or so. • IceCube submits their photon propagation workflow to this HTCondor pool. - we handle the input, the jobs on the GPUs, and the output as a single globally distributed system. 13 Run a GPU burst relevant in scale for future Exascale HPC systems.
- 14. A global HTCondor pool • IceCube, like all OSG user communities, relies on HTCondor for resource orchestration - This demo used the standard tools • Dedicated HW setup - Avoid disruption of OSG production system - Optimize HTCondor setup for the spiky nature of the demo § multiple schedds for IceCube to submit to § collecting resources in each cloud region, then collecting from all regions into global pool 14
- 15. HTCondor Distributed CI 15 Collector Collector Collector Collector Collector Negotiator Scheduler SchedulerScheduler IceCube VM VM VM 10 schedd’s One global resource pool
- 16. Using native Cloud storage • Input data pre-staged into native Cloud storage - Each file in one-to-few Cloud regions § some replication to deal with limited predictability of resources per region - Local to Compute for large regions for maximum throughput - Reading from “close” region for smaller ones to minimize ops • Output staged back to region-local Cloud storage - To be transferred back asynchronously after the compute is done • Deployed simple wrappers around Cloud native file transfer tools - IceCube jobs do not need to customize for different Clouds - They just need to know where input data is available (pretty standard OSG operation mode) 16
- 17. Using native Cloud storage • Input data pre-staged into native Cloud storage - Each file in one-to-few Cloud regions § some replication to deal with limited predictability of resources per region - Local to Compute for large regions for maximum throughput - Reading from “close” region for smaller ones to minimize ops • Output staged back to region-local Cloud storage - To be transferred back asynchronously after the compute is done • Deployed simple wrappers around Cloud native file transfer tools - IceCube jobs do not need to customize for different Clouds - They just need to know where input data is available (pretty standard OSG operation mode) 17 Done at a leisurely pace
- 18. Using native Cloud storage • Input data pre-staged into native Cloud storage - Each file in one-to-few Cloud regions § some replication to deal with limited predictability of resources per region - Local to Compute for large regions for maximum throughput - Reading from “close” region for smaller ones to minimize ops • Output staged back to region-local Cloud storage - To be transferred back asynchronously after the compute is done • Deployed simple wrappers around Cloud native file transfer tools - IceCube jobs do not need to customize for different Clouds - They just need to know where input data is available (pretty standard OSG operation mode) 18 The focus of this talk
- 19. Science with 50k GPUs achieved as peak performance 19 Time in Minutes Each color is a different cloud region in US, EU, or Asia. Total of 28 Regions in use. Peaked at about 50k GPUs ~350 Petaflops of fp32 8 generations of NVIDIA GPUs used.
- 20. A Heterogenous Resource Pool 20 28 cloud Regions across 4 world regions providing us with 8 GPU generations. No one region or GPU type dominates!
- 21. Science Produced 21 Distributed High-Throughput Computing (dHTC) paradigm implemented via HTCondor provides global resource aggregation. Largest cloud region provided 10.8% of the total dHTC paradigm can aggregate on-prem anywhere HPC at any scale and multiple clouds
- 22. Data Produced 22 Size of the data created was proportional to the events processed Largest cloud region provided 10.8% of the total Just as distributed as the compute has been About 20 TB total
- 23. Getting the data out of the Clouds
- 24. Timeline • IceCube is actually in no hurry in getting the data out of the Clouds - Sooner is of course better - But not time critical • But Cloud great for urgent computing - And there getting the data promptly out would be as important as getting the compute done in the first place 24
- 25. LIGO example • The LIGO is the other MMA experiment that can be used to detect large Cosmic events and point other Astronomy observations • They are currently limited by compute on how accurate their pointing is - More compute would mean better pointing - Must must be prompt 25
- 26. LIGO example • The LIGO is the other MMA experiment that can be used to detect large Cosmic events and point other Astronomy observations • They are currently limited by compute on how accurate their pointing is - More compute would mean better pointing - Must must be prompt 26 20k GPUs for 30 mins with a 30min ramp- up gets us into the regime where we can reasonably run a multi-approximant/multi- EOS analysis to dramatically improve confidence in probability of an EM counter part in ~1 hour, so that classifications are as accurate as they're going to get before an optical counterpart fades James Clark, LIGO
- 27. Demonstrating a Burt Transfer • We thus decided to move ~10 TB of the data back from the Clouds in a short burst - 10 TB dictated by the available storage options • Trying two options - Directly to UW using many commodity nodes - Stage to a Internet2 DTN 27
- 28. UW commodity setup • We fully expected to be disk I/O bound - Single spinning disk per node • We managed to secure 30 nodes for the purpose 28
- 29. UW commodity setup • Managed to transfer about 9 TB in 90 minutes 29
- 30. UW commodity setup • About 16 Gbps aggregate bandwidth - But huge variations between Cloud regions - 3.5Gbps from best, <0.5 Gbps from worst 30
- 31. Internet2 DTN • Wanted to see how a single high-end node with flash-based storage would fare • We also had previous network measurements that suggested that we may be able to beat the 30-node US setup - See my CHEP19 talk, if interested http://chep2019.org 31
- 32. Network measurements 32 US East US West 2 35 Gbps 36 Gbps 33 Gbps 36 Gbps AWS From Cloud storage /dev/shm
- 33. Network measurements 33 US East US West 2 36 Gbps 31 Gbps 27 Gbps 29 Gbps Azure From Cloud storage /dev/shm
- 34. Network measurements 34 US East 1 36 Gbps US West 1 35 Gbps Google Cloud From Cloud storage /dev/shm
- 35. Internet2 DTN • Took about 2 hours to transfer 2 TB - We did not beat UW 35
- 36. Internet2 DTN • Peaked at slightly less than 10 Gbps - Likely limited by the storage • Again, huge differences in performance between Cloud regions 36
- 37. Summary • Large scale cloud computing is feasible - We almost matched Summit in FLOP32s - And can be ramped up very fast • Getting data between on-prem and Cloud not a big deal either - We exceeded 10 Gbps while going to virtually all Cloud regions - But needs adequate on-prem capabilities 37
- 38. Acknowledgements • Internet2 was the main network provider for this activity. • This work was partially sponsored by NSF grants OAC-1941481, MPS-1148698, OAC-1841530 and OAC-1826967. 38