Case Study: Elasticsearch Ingest Using StreamSets @ Cisco Intercloud
Download as pptx, pdf4 likes3,057 views

The document provides a detailed case study on the implementation of StreamSets Data Collector and Elasticsearch at Cisco Intercloud, highlighting the architecture, data flows, and benefits of the system. It discusses the challenges faced, including container management issues and performance optimization, while showcasing the adaptability and efficiency of the StreamSets pipelines for data processing. Additionally, the document emphasizes the collaborative efforts with the StreamSets team to resolve scalability and operational challenges, showcasing the system's capacity to handle high message throughput effectively.
1 of 36
Downloaded 122 times



































Ad
Recommended
Streamsets and spark
Streamsets and sparkHari Shreedharan StreamSets can process data using Apache Spark in three ways:
1) The Spark Evaluator stage allows user-provided Spark code to run on each batch of records in a pipeline and return results or errors.
2) A Cluster Pipeline can leverage Apache Spark's Direct Kafka DStream to partition data from Kafka across worker pipelines on a cluster.
3) A Spark Executor can kick off a Spark application when an event is received, allowing tasks like model updating to run on streaming data using Spark.
Streamsets and spark at SF Hadoop User Group
Streamsets and spark at SF Hadoop User GroupHari Shreedharan Hari Shreedharan is a software engineer at StreamSets, specializing in data flow management with a background at Cloudera and Yahoo!. He discusses the StreamSets Data Collector, focusing on its capabilities to read data from various sources, process records, and write to multiple destinations using Apache Spark. The document highlights features such as real-time processing, integration with Kafka, and cloud support for efficient data handling in complex pipelines.
Building a data pipeline to ingest data into Hadoop in minutes using Streamse...
Building a data pipeline to ingest data into Hadoop in minutes using Streamse...Guglielmo Iozzia The document outlines the process of building a data pipeline for ingesting data into Hadoop using StreamSets Data Collector, addressing challenges like data redundancy and team skills. It emphasizes the need for a single tool that simplifies data ingestion while providing real-time monitoring and security features. It also includes a demo and links for further information on StreamSets Data Collector.
Building Data Pipelines with Spark and StreamSets
Building Data Pipelines with Spark and StreamSetsPat Patterson The document discusses the challenges of data drift, which occurs due to the evolution of data characteristics in systems, impacting data quality and analysis. It introduces StreamSets Data Collector as a solution for building efficient data pipelines with Spark, offering capabilities for managing data drift and improving data flow reliability. Future integration plans include leveraging Databricks and enhancing Spark connectivity for various data sources and applications.
Streamsets and spark in Retail
Streamsets and spark in RetailHari Shreedharan This document discusses how StreamSets and Spark can be used together for analytics insights in retail. Some key points:
- StreamSets Data Collector (SDC) is used to ingest IoT and sensor data from various sources into a common format and process the data in real-time using Spark evaluators.
- The Spark evaluator allows running Spark transformations on batches of data within SDC pipelines to do tasks like anomaly detection, sentiment analysis, and fraud detection.
- SDC can also be used to move data to and from Spark for end-of-batch processing using a Spark executor, such as running jobs on Databricks after files land in S3.
- Together, SDC and Spark
Telco analytics at scale
Telco analytics at scaledatamantra This document discusses Telco analytics at scale using distributed stream processing. It describes using technologies like Apache Spark Streaming, Kafka, and Hadoop (HDFS, Hive, HBase) to ingest and process large volumes of streaming data from various sources in real-time or near real-time. Example use cases discussed include fraud detection, real-time rating, security information and event management. It also covers strategies for distributed in-memory caching and rule processing to enable low latency analytics at high throughput scales needed for telco data and applications.
A Big Data Lake Based on Spark for BBVA Bank-(Oscar Mendez, STRATIO)
A Big Data Lake Based on Spark for BBVA Bank-(Oscar Mendez, STRATIO)Spark Summit This document describes BBVA's implementation of a Big Data Lake using Apache Spark for log collection, storage, and analytics. It discusses:
1) Using Syslog-ng for log collection from over 2,000 applications and devices, distributing logs to Kafka.
2) Storing normalized logs in HDFS and performing analytics using Spark, with outputs to analytics, compliance, and indexing systems.
3) Choosing Spark because it allows interactive, batch, and stream processing with one system using RDDs, SQL, streaming, and machine learning.
Data Policies for the Kafka-API with WebAssembly | Alexander Gallego, Vectorized
Data Policies for the Kafka-API with WebAssembly | Alexander Gallego, VectorizedHostedbyConfluent The document discusses data policies for the Kafka API using WebAssembly, authored by Alex Gallego of Vectorized, highlighting the challenges and advantages of streaming data. It emphasizes the keystone problem of consuming relevant data while managing the cost of architecture, network saturation, and specialized clusters. Additionally, it introduces modern hardware benefits, unique memory management strategies, and the implementation of WebAssembly in Kafka topics for performance improvements.
Modern ETL Pipelines with Change Data Capture
Modern ETL Pipelines with Change Data CaptureDatabricks The document discusses GetYourGuide's modern ETL pipelines, highlighting their legacy and Rivulus ETL systems designed for efficient data extraction, transformation, and loading. It emphasizes the shift to automated handling of schema changes, maximum parallelism, and better SLAs, resulting in a 70% reduction in processing time. The conclusion notes the success of Rivulus SQL in democratizing ETL processes, enhancing testability, and addressing performance bottlenecks.
From Batch to Streaming ET(L) with Apache Apex
From Batch to Streaming ET(L) with Apache ApexDataWorks Summit The document discusses the transition from batch to streaming data processing with Apache Apex, highlighting its benefits for real-time insights in various applications like advertising tech. It outlines the capabilities of Apache Apex in handling data with reduced latency, fault tolerance, and scalability. Additionally, it provides technical details on integration with various data sources, transformations, and real-time visualizations.
Kafka Summit SF 2017 - Keynote - Go Against the Flow: Databases and Stream Pr...
Kafka Summit SF 2017 - Keynote - Go Against the Flow: Databases and Stream Pr...confluent The document discusses how businesses can adopt a streaming-first approach using stream processing tools like Apache Kafka and KSQL. It argues that databases are no longer suitable for analyzing real-time streaming data and processing events. KSQL is presented as an open source tool that allows users to write SQL queries against streaming data in Kafka. It supports features like continuous queries, stream-table joins, and streaming materialized views. The document also provides a demo of how KSQL can be used for real-time anomaly detection on streaming web user data.
Meetup070416 Presentations
Meetup070416 PresentationsAna Rebelo This document summarizes a presentation on the Elastic Stack. It discusses the main components - Elasticsearch for storing and searching data, Logstash for ingesting data, Kibana for visualizing data. It provides examples of using Elasticsearch for search, analytics, and aggregations. It also briefly mentions new features across the Elastic Stack like update by query, ingest nodes, pipeline improvements, and APIs for management and metrics.
Big Telco - Yousun Jeong
Big Telco - Yousun JeongSpark Summit This document provides an overview of SK Telecom's use of big data analytics and Spark. Some key points:
- SKT collects around 250 TB of data per day which is stored and analyzed using a Hadoop cluster of over 1400 nodes.
- Spark is used for both batch and real-time processing due to its performance benefits over other frameworks. Two main use cases are described: real-time network analytics and a network enterprise data warehouse (DW) built on Spark SQL.
- The network DW consolidates data from over 130 legacy databases to enable thorough analysis of the entire network. Spark SQL, dynamic resource allocation in YARN, and integration with BI tools help meet requirements for timely processing and quick
More Data, More Problems: Scaling Kafka-Mirroring Pipelines at LinkedIn
More Data, More Problems: Scaling Kafka-Mirroring Pipelines at LinkedIn confluent The document discusses the challenges of scaling Kafka MirrorMaker (KMM) pipelines at LinkedIn, which are facing issues with scalability, operability, and fragility due to rapid data growth and complex configurations. It introduces Brooklin MirrorMaker (BMM), which is built on the Brooklin stream ingestion service, designed for higher stability and performance management. The document details BMM's architecture, diagnostics, and performance metrics, highlighting its efficiency in managing data mirroring across multiple data centers.
Lambda architecture: from zero to One
Lambda architecture: from zero to OneSerg Masyutin The document presents a detailed overview of implementing a lambda architecture for a live voting service, highlighting its goals of high throughput, scalability, and low latency. It discusses the architectural evolution, technologies used (such as Kafka, Redis, and Spark), and the importance of benchmarking and optimization for performance. The project aims to create a robust and fault-tolerant system while providing efficient real-time data processing and reporting capabilities.
Low-latency data applications with Kafka and Agg indexes | Tino Tereshko, Fir...
Low-latency data applications with Kafka and Agg indexes | Tino Tereshko, Fir...HostedbyConfluent The document details Firebolt’s capabilities as a high-performance data warehouse optimized for low-latency use cases with features like indexing and a modern Kafka connector. It highlights various applications, performance comparisons, and the ease of setup of Firebolt’s integration with Kafka for efficient data streaming. The content emphasizes Firebolt’s advancements in data management and its potential benefits across diverse industries.
Streaming Data Lakes using Kafka Connect + Apache Hudi | Vinoth Chandar, Apac...
Streaming Data Lakes using Kafka Connect + Apache Hudi | Vinoth Chandar, Apac...HostedbyConfluent The document discusses the architecture and implementation of streaming data lakes using Kafka Connect and Apache Hudi. It covers the importance of data lakes in modern analytics, the functionality and advantages of Hudi for managing data streams and transactional writes, and a case study of Robinhood's data lake solution. Key features, usage examples, and community engagement avenues are also presented to facilitate adoption and integration of Hudi in streaming infrastructures.
Insights Without Tradeoffs Using Structured Streaming keynote by Michael Armb...
Insights Without Tradeoffs Using Structured Streaming keynote by Michael Armb...Spark Summit The document discusses insights from Michael Armbrust's presentation at Spark Summit East 2017 on structured streaming, emphasizing the importance of parallelism, developer productivity, and efficiency in data processing. It highlights structured streaming's ability to handle large datasets while providing up-to-date analytical answers and includes several production use cases. Additional resources and office hours information are shared for further engagement with the engineering community.
August 2016 HUG: Open Source Big Data Ingest with StreamSets Data Collector
August 2016 HUG: Open Source Big Data Ingest with StreamSets Data Collector Yahoo Developer Network The document discusses StreamSets Data Collector, an open-source tool for developing and operating complex data flows, focusing on issues such as data drift, which includes structure, semantic, and infrastructure changes that can lead to data loss and poor quality. It highlights the tool's efficiency, control, and agility in handling data ingestion from various sources and provides insights into upcoming events related to big data. Additionally, the document emphasizes the importance of addressing data drift to improve analysts' productivity, as a significant portion of their time is spent on data preparation rather than analysis.
The delta architecture
The delta architecturePrakash Chockalingam The document discusses the delta architecture as an evolution of lambda architecture, highlighting its ability to unify batch and streaming data processing while addressing complexities that arise in traditional data pipelines. Key features include continuous data flow, infinite retention for historical data replay, and elastic computing/storage to optimize costs. The delta architecture simplifies data engineering tasks, reduces operational burdens, and enhances data quality management.
Data platform architecture principles - ieee infrastructure 2020
Data platform architecture principles - ieee infrastructure 2020Julien Le Dem This document discusses principles for building a healthy data platform, including:
1. Establishing explicit contracts between teams to define dependencies and service level agreements.
2. Abstracting the data platform into services for ingesting, storing, and processing data in motion and at rest.
3. Enabling observability of data pipelines through metadata collection and integration with tools like Marquez to provide lineage, availability, and change management visibility.
Real-Time Data Pipelines with Kafka, Spark, and Operational Databases
Real-Time Data Pipelines with Kafka, Spark, and Operational DatabasesSingleStore The document discusses MemSQL's strategy for building real-time data pipelines using technologies like Kafka, Spark, and operational databases. It highlights the importance of real-time analytics for businesses to stay competitive and outlines the architecture that supports both transactional and analytical processing. MemSQL aims to enable every company to become a real-time enterprise, offering unified queries and fast data processing capabilities.
Tangram: Distributed Scheduling Framework for Apache Spark at Facebook
Tangram: Distributed Scheduling Framework for Apache Spark at FacebookDatabricks Tangram is a distributed scheduling framework developed by Facebook for managing various batch workloads in Apache Spark, emphasizing efficient resource management and scalability. It supports diverse scheduling policies for different job types, focusing on hierarchical queue structures and resource allocation constraints. Future enhancements include integrating mixed workloads under a single resource manager and optimizing resource utilization through automatic tuning.
Kappa Architecture on Apache Kafka and Querona: datamass.io
Kappa Architecture on Apache Kafka and Querona: datamass.ioPiotr Czarnas This document discusses Kappa Architecture, an alternative to Lambda Architecture for event processing. Kappa Architecture uses a single stream of events from Apache Kafka as the input, rather than separating batch and stream processing. It reads all events from Kafka and runs analytics on the full data set to enable both learning from historical events and reacting to new events. The document outlines how Kappa Architecture provides benefits like avoiding duplicate processing logic and making actionable analytics easier. It also describes how to read bounded batches of events from Kafka for analytics using tools like Apache Spark.
Interactive Visualization of Streaming Data Powered by Spark by Ruhollah Farc...
Interactive Visualization of Streaming Data Powered by Spark by Ruhollah Farc...Spark Summit This document discusses how to visualize streaming data using Spark. It describes how Spark Streaming can be used to process streaming data in real-time and integrate it with visualization tools. Key points include:
- Spark Streaming receives streaming data from sources like Kafka and processes it using in-memory computations in a single JVM cluster.
- The processed data can be stored in buffers like MongoDB or output to systems like MemSQL, Solr to enable interactive visualizations that update in real-time.
- A demo is shown of Twitter data being streamed and analyzed using Spark Streaming with results stored in MemSQL and Solr for visualization.
- Benefits of this approach include being able to work with streaming data
Databricks Delta Lake and Its Benefits
Databricks Delta Lake and Its BenefitsDatabricks The document discusses Delta Lake, an open-source project from Databricks that enhances data lakes with features like ACID transactions, schema enforcement, and time travel capabilities. It highlights benefits such as improved metadata handling, support for both batch and streaming data, and efficient data processing. The agenda includes insights from data professionals and addresses common challenges faced with traditional data lakes.
What to Expect for Big Data and Apache Spark in 2017
What to Expect for Big Data and Apache Spark in 2017 Databricks The document discusses trends for big data and Apache Spark in 2017, highlighting the stabilization of structured APIs, significant performance improvements, and the increased use of Spark in production applications. Key trends include addressing hardware bottlenecks, democratizing access to big data applications, and the integration of streaming and batch processing into a unified API for continuous applications. It also touches on ongoing developments to enhance Spark's performance, usability, and integration with other systems and technologies.
ASPgems - kappa architecture
ASPgems - kappa architectureJuantomás García Molina Kappa Architecture is an alternative to Lambda Architecture that simplifies real-time data processing. It uses a distributed log like Kafka to store all input data immutably to allow reprocessing from the beginning if the processing code changes. This avoids having to maintain separate batch and real-time processing systems. The ASPgems team has implemented Kappa Architecture for several clients using Kafka, Spark Streaming, and Cassandra to provide real-time analytics and metrics in sectors like telecommunications, IoT, insurance, and energy.
Monitoring Kafka w/ Prometheus
Monitoring Kafka w/ Prometheuskawamuray This document discusses monitoring Apache Kafka clusters and applications with Prometheus. It provides an overview of the architecture used, including deploying Prometheus servers, Kafka and HBase exporters, and a JSON exporter for YARN applications. Specific exporters are discussed for Kafka brokers using JMX, Kafka clients using the Prometheus Java library, and exposing application metrics via HTTP. Important Prometheus configurations and query functions are also covered. The summary highlights the key components of the monitoring architecture and some of the exporters and techniques discussed.
ElasticSearch Basic Introduction
ElasticSearch Basic IntroductionMayur Rathod Elasticsearch is an open-source, distributed search and analytics engine built on Apache Lucene, featuring a RESTful API for easy scalability and complex querying. It supports multi-tenancy and document-oriented storage with a schema-free design, enabling advanced search capabilities, including full-text search and aggregations. The software has an active community, allowing for extensive configurability and extensibility while ensuring data safety through optimistic version control.
More Related Content
What's hot (20)
Modern ETL Pipelines with Change Data Capture
Modern ETL Pipelines with Change Data CaptureDatabricks The document discusses GetYourGuide's modern ETL pipelines, highlighting their legacy and Rivulus ETL systems designed for efficient data extraction, transformation, and loading. It emphasizes the shift to automated handling of schema changes, maximum parallelism, and better SLAs, resulting in a 70% reduction in processing time. The conclusion notes the success of Rivulus SQL in democratizing ETL processes, enhancing testability, and addressing performance bottlenecks.
From Batch to Streaming ET(L) with Apache Apex
From Batch to Streaming ET(L) with Apache ApexDataWorks Summit The document discusses the transition from batch to streaming data processing with Apache Apex, highlighting its benefits for real-time insights in various applications like advertising tech. It outlines the capabilities of Apache Apex in handling data with reduced latency, fault tolerance, and scalability. Additionally, it provides technical details on integration with various data sources, transformations, and real-time visualizations.
Kafka Summit SF 2017 - Keynote - Go Against the Flow: Databases and Stream Pr...
Kafka Summit SF 2017 - Keynote - Go Against the Flow: Databases and Stream Pr...confluent The document discusses how businesses can adopt a streaming-first approach using stream processing tools like Apache Kafka and KSQL. It argues that databases are no longer suitable for analyzing real-time streaming data and processing events. KSQL is presented as an open source tool that allows users to write SQL queries against streaming data in Kafka. It supports features like continuous queries, stream-table joins, and streaming materialized views. The document also provides a demo of how KSQL can be used for real-time anomaly detection on streaming web user data.
Meetup070416 Presentations
Meetup070416 PresentationsAna Rebelo This document summarizes a presentation on the Elastic Stack. It discusses the main components - Elasticsearch for storing and searching data, Logstash for ingesting data, Kibana for visualizing data. It provides examples of using Elasticsearch for search, analytics, and aggregations. It also briefly mentions new features across the Elastic Stack like update by query, ingest nodes, pipeline improvements, and APIs for management and metrics.
Big Telco - Yousun Jeong
Big Telco - Yousun JeongSpark Summit This document provides an overview of SK Telecom's use of big data analytics and Spark. Some key points:
- SKT collects around 250 TB of data per day which is stored and analyzed using a Hadoop cluster of over 1400 nodes.
- Spark is used for both batch and real-time processing due to its performance benefits over other frameworks. Two main use cases are described: real-time network analytics and a network enterprise data warehouse (DW) built on Spark SQL.
- The network DW consolidates data from over 130 legacy databases to enable thorough analysis of the entire network. Spark SQL, dynamic resource allocation in YARN, and integration with BI tools help meet requirements for timely processing and quick
More Data, More Problems: Scaling Kafka-Mirroring Pipelines at LinkedIn
More Data, More Problems: Scaling Kafka-Mirroring Pipelines at LinkedIn confluent The document discusses the challenges of scaling Kafka MirrorMaker (KMM) pipelines at LinkedIn, which are facing issues with scalability, operability, and fragility due to rapid data growth and complex configurations. It introduces Brooklin MirrorMaker (BMM), which is built on the Brooklin stream ingestion service, designed for higher stability and performance management. The document details BMM's architecture, diagnostics, and performance metrics, highlighting its efficiency in managing data mirroring across multiple data centers.
Lambda architecture: from zero to One
Lambda architecture: from zero to OneSerg Masyutin The document presents a detailed overview of implementing a lambda architecture for a live voting service, highlighting its goals of high throughput, scalability, and low latency. It discusses the architectural evolution, technologies used (such as Kafka, Redis, and Spark), and the importance of benchmarking and optimization for performance. The project aims to create a robust and fault-tolerant system while providing efficient real-time data processing and reporting capabilities.
Low-latency data applications with Kafka and Agg indexes | Tino Tereshko, Fir...
Low-latency data applications with Kafka and Agg indexes | Tino Tereshko, Fir...HostedbyConfluent The document details Firebolt’s capabilities as a high-performance data warehouse optimized for low-latency use cases with features like indexing and a modern Kafka connector. It highlights various applications, performance comparisons, and the ease of setup of Firebolt’s integration with Kafka for efficient data streaming. The content emphasizes Firebolt’s advancements in data management and its potential benefits across diverse industries.
Streaming Data Lakes using Kafka Connect + Apache Hudi | Vinoth Chandar, Apac...
Streaming Data Lakes using Kafka Connect + Apache Hudi | Vinoth Chandar, Apac...HostedbyConfluent The document discusses the architecture and implementation of streaming data lakes using Kafka Connect and Apache Hudi. It covers the importance of data lakes in modern analytics, the functionality and advantages of Hudi for managing data streams and transactional writes, and a case study of Robinhood's data lake solution. Key features, usage examples, and community engagement avenues are also presented to facilitate adoption and integration of Hudi in streaming infrastructures.
Insights Without Tradeoffs Using Structured Streaming keynote by Michael Armb...
Insights Without Tradeoffs Using Structured Streaming keynote by Michael Armb...Spark Summit The document discusses insights from Michael Armbrust's presentation at Spark Summit East 2017 on structured streaming, emphasizing the importance of parallelism, developer productivity, and efficiency in data processing. It highlights structured streaming's ability to handle large datasets while providing up-to-date analytical answers and includes several production use cases. Additional resources and office hours information are shared for further engagement with the engineering community.
August 2016 HUG: Open Source Big Data Ingest with StreamSets Data Collector
August 2016 HUG: Open Source Big Data Ingest with StreamSets Data Collector Yahoo Developer Network The document discusses StreamSets Data Collector, an open-source tool for developing and operating complex data flows, focusing on issues such as data drift, which includes structure, semantic, and infrastructure changes that can lead to data loss and poor quality. It highlights the tool's efficiency, control, and agility in handling data ingestion from various sources and provides insights into upcoming events related to big data. Additionally, the document emphasizes the importance of addressing data drift to improve analysts' productivity, as a significant portion of their time is spent on data preparation rather than analysis.
The delta architecture
The delta architecturePrakash Chockalingam The document discusses the delta architecture as an evolution of lambda architecture, highlighting its ability to unify batch and streaming data processing while addressing complexities that arise in traditional data pipelines. Key features include continuous data flow, infinite retention for historical data replay, and elastic computing/storage to optimize costs. The delta architecture simplifies data engineering tasks, reduces operational burdens, and enhances data quality management.
Data platform architecture principles - ieee infrastructure 2020
Data platform architecture principles - ieee infrastructure 2020Julien Le Dem This document discusses principles for building a healthy data platform, including:
1. Establishing explicit contracts between teams to define dependencies and service level agreements.
2. Abstracting the data platform into services for ingesting, storing, and processing data in motion and at rest.
3. Enabling observability of data pipelines through metadata collection and integration with tools like Marquez to provide lineage, availability, and change management visibility.
Real-Time Data Pipelines with Kafka, Spark, and Operational Databases
Real-Time Data Pipelines with Kafka, Spark, and Operational DatabasesSingleStore The document discusses MemSQL's strategy for building real-time data pipelines using technologies like Kafka, Spark, and operational databases. It highlights the importance of real-time analytics for businesses to stay competitive and outlines the architecture that supports both transactional and analytical processing. MemSQL aims to enable every company to become a real-time enterprise, offering unified queries and fast data processing capabilities.
Tangram: Distributed Scheduling Framework for Apache Spark at Facebook
Tangram: Distributed Scheduling Framework for Apache Spark at FacebookDatabricks Tangram is a distributed scheduling framework developed by Facebook for managing various batch workloads in Apache Spark, emphasizing efficient resource management and scalability. It supports diverse scheduling policies for different job types, focusing on hierarchical queue structures and resource allocation constraints. Future enhancements include integrating mixed workloads under a single resource manager and optimizing resource utilization through automatic tuning.
Kappa Architecture on Apache Kafka and Querona: datamass.io
Kappa Architecture on Apache Kafka and Querona: datamass.ioPiotr Czarnas This document discusses Kappa Architecture, an alternative to Lambda Architecture for event processing. Kappa Architecture uses a single stream of events from Apache Kafka as the input, rather than separating batch and stream processing. It reads all events from Kafka and runs analytics on the full data set to enable both learning from historical events and reacting to new events. The document outlines how Kappa Architecture provides benefits like avoiding duplicate processing logic and making actionable analytics easier. It also describes how to read bounded batches of events from Kafka for analytics using tools like Apache Spark.
Interactive Visualization of Streaming Data Powered by Spark by Ruhollah Farc...
Interactive Visualization of Streaming Data Powered by Spark by Ruhollah Farc...Spark Summit This document discusses how to visualize streaming data using Spark. It describes how Spark Streaming can be used to process streaming data in real-time and integrate it with visualization tools. Key points include:
- Spark Streaming receives streaming data from sources like Kafka and processes it using in-memory computations in a single JVM cluster.
- The processed data can be stored in buffers like MongoDB or output to systems like MemSQL, Solr to enable interactive visualizations that update in real-time.
- A demo is shown of Twitter data being streamed and analyzed using Spark Streaming with results stored in MemSQL and Solr for visualization.
- Benefits of this approach include being able to work with streaming data
Databricks Delta Lake and Its Benefits
Databricks Delta Lake and Its BenefitsDatabricks The document discusses Delta Lake, an open-source project from Databricks that enhances data lakes with features like ACID transactions, schema enforcement, and time travel capabilities. It highlights benefits such as improved metadata handling, support for both batch and streaming data, and efficient data processing. The agenda includes insights from data professionals and addresses common challenges faced with traditional data lakes.
What to Expect for Big Data and Apache Spark in 2017
What to Expect for Big Data and Apache Spark in 2017 Databricks The document discusses trends for big data and Apache Spark in 2017, highlighting the stabilization of structured APIs, significant performance improvements, and the increased use of Spark in production applications. Key trends include addressing hardware bottlenecks, democratizing access to big data applications, and the integration of streaming and batch processing into a unified API for continuous applications. It also touches on ongoing developments to enhance Spark's performance, usability, and integration with other systems and technologies.
ASPgems - kappa architecture
ASPgems - kappa architectureJuantomás García Molina Kappa Architecture is an alternative to Lambda Architecture that simplifies real-time data processing. It uses a distributed log like Kafka to store all input data immutably to allow reprocessing from the beginning if the processing code changes. This avoids having to maintain separate batch and real-time processing systems. The ASPgems team has implemented Kappa Architecture for several clients using Kafka, Spark Streaming, and Cassandra to provide real-time analytics and metrics in sectors like telecommunications, IoT, insurance, and energy.
Viewers also liked (20)
Monitoring Kafka w/ Prometheus
Monitoring Kafka w/ Prometheuskawamuray This document discusses monitoring Apache Kafka clusters and applications with Prometheus. It provides an overview of the architecture used, including deploying Prometheus servers, Kafka and HBase exporters, and a JSON exporter for YARN applications. Specific exporters are discussed for Kafka brokers using JMX, Kafka clients using the Prometheus Java library, and exposing application metrics via HTTP. Important Prometheus configurations and query functions are also covered. The summary highlights the key components of the monitoring architecture and some of the exporters and techniques discussed.
ElasticSearch Basic Introduction
ElasticSearch Basic IntroductionMayur Rathod Elasticsearch is an open-source, distributed search and analytics engine built on Apache Lucene, featuring a RESTful API for easy scalability and complex querying. It supports multi-tenancy and document-oriented storage with a schema-free design, enabling advanced search capabilities, including full-text search and aggregations. The software has an active community, allowing for extensive configurability and extensibility while ensuring data safety through optimistic version control.
Case Study: Elasticsearch Ingest Using StreamSets at Cisco Intercloud
Case Study: Elasticsearch Ingest Using StreamSets at Cisco IntercloudRick Bilodeau This document outlines a case study on the implementation of Elasticsearch and StreamSets at Cisco Intercloud, emphasizing the architecture, data flow, and performance management of data streams. It highlights the challenges faced in managing data efficiently, the adaptability of StreamSets for building ingest pipelines with minimal coding, and the integration of microservices within the framework. The study demonstrates the benefits of using the Elastic Stack for analytics and the successful processing of large volumes of data across various environments.
Bad Data is Polluting Big Data
Bad Data is Polluting Big DataStreamsets Inc. The key findings of the survey of 314 big data professionals are:
- 87% said 'bad data' pollutes their data stores and 74% said 'bad data' is currently in their stores. Ensuring data quality was the top challenge cited.
- 72% build data flows through hand coding while 53% change pipelines several times per month.
- Only 12% rated their ability to detect issues like stopped pipelines or degraded performance as 'good' or 'excellent'.
- There are significant gaps between the real-time visibility needed and what current tools provide across metrics like error rates, divergent data, and privacy detection.
- 81% said upgrading big data components has significant operational impact.
Logging infrastructure for Microservices using StreamSets Data Collector
Logging infrastructure for Microservices using StreamSets Data CollectorCask Data This document discusses using StreamSets Data Collector (SDC) to build a logging infrastructure for microservices. SDC can ingest logs from microservices running in containers and handle issues like schema changes and new log formats. It processes and transforms the logs, sending them to destinations like Kafka. SDC pipelines can run on Spark clusters on Yarn and Mesos to handle large volumes of log data and load it into systems like HDFS, HBase and Elasticsearch for analysis.
ElasticSearch on AWS - Real Estate portal case study (Spitogatos.gr)
ElasticSearch on AWS - Real Estate portal case study (Spitogatos.gr) Andreas Chatzakis The document presents a case study on the implementation of Elasticsearch for the real estate portal Spitogatos.gr, aimed at improving property search in Greece. It outlines the challenges of property searches, the decision-making process for selecting Elasticsearch over other solutions, and describes the architecture, indexing, and operational aspects of the deployment on AWS. Key features include the ability to provide complex and flexible search capabilities, faceted navigation, and scalable infrastructure.
Adaptive Data Cleansing with StreamSets and Cassandra (Pat Patterson, StreamS...
Adaptive Data Cleansing with StreamSets and Cassandra (Pat Patterson, StreamS...DataStax The document discusses adaptive data cleansing using StreamSets and Cassandra, focusing on processing IoT sensor data through RabbitMQ and identifying outlier temperature readings. It details the implementation of user-defined aggregate functions in Cassandra to dynamically detect outliers based on statistical methods. Additionally, it describes methods to feed processed statistics back into the data pipeline for improved data integrity and real-time analysis.
Real-time personal trainer on the SMACK stack
Real-time personal trainer on the SMACK stackAnirvan Chakraborty The document outlines the architecture of an automated personal training system called Muvr, which uses various technologies including iOS, Akka, Spark, Neon, and Cassandra to deliver real-time personalized exercise recommendations and monitor user performance. It details the system's capabilities, such as exercise session suggestions, proper form tips, and machine learning applications for continuous improvement. It also discusses deployment strategies using Docker and resource management on AWS for cost-effectiveness.
Demystifying salesforce for developers
Demystifying salesforce for developersHeitor Souza This document provides an overview of Salesforce for developers. It defines CRM and Salesforce, explains Salesforce's multi-tenant architecture and how it provides reliability, customizability and security. It also covers the Salesforce platform, development tools like Force.com, Apex and SOQL, and governor limits for developers to be aware of. The presentation includes an agenda, definitions of key terms, and a demo of developing on the platform.
Kafka Lambda architecture with mirroring
Kafka Lambda architecture with mirroringAnant Rustagi This document outlines a master plan for a lambda architecture that involves mirroring data from multiple Kafka clusters into a Hadoop cluster for batch processing and analytics, as well as real-time processing using Storm/Spark on the mirrored data in the Kafka clusters, with data from various sources integrated into the Kafka clusters with the topic name "Data".
Extreme Salesforce Data Volumes Webinar
Extreme Salesforce Data Volumes WebinarSalesforce Developers The document outlines best practices for managing extreme data volumes within the Salesforce platform, highlighting key considerations during design, load, configuration, and maintenance phases. It emphasizes the importance of understanding operational requirements, estimating data growth, and implementing effective data management strategies to minimize data volume and optimize query performance. Additionally, it provides resources and supports for attendees to engage with experts and learn more about architecting solutions effectively.
How Apache Kafka is transforming Hadoop, Spark and Storm
How Apache Kafka is transforming Hadoop, Spark and StormEdureka! This document provides an overview of Apache Kafka and how it is transforming Hadoop, Spark, and Storm. It begins with explaining why Kafka is needed, then defines what Kafka is and describes its architecture. Key components of Kafka like topics, producers, consumers and brokers are explained. The document also shows how Kafka can be used with Hadoop, Spark, and Storm for stream processing. It lists some companies that use Kafka and concludes by advertising an Edureka course on Apache Kafka.
Large volume data analysis on the Typesafe Reactive Platform - Big Data Scala...
Large volume data analysis on the Typesafe Reactive Platform - Big Data Scala...Martin Zapletal The document discusses distributed machine learning and data processing. It covers several topics including reasons for using distributed machine learning, different distributed computing architectures and primitives, distributed data stores and analytics tools like Spark, streaming architectures like Lambda and Kappa, and challenges around distributed state management and fault tolerance. It provides examples of failures in distributed databases and suggestions to choose the appropriate tools based on the use case and understand their internals.
Cassandra Day Atlanta 2016 - Monitoring Cassandra
Cassandra Day Atlanta 2016 - Monitoring Cassandraaaronmorton This document discusses monitoring Apache Cassandra using metrics. It describes various metric types like gauges, histograms, meters, and timers that can be used to monitor Cassandra. It provides examples of specific metrics that can be monitored for requests, latencies, memory usage, clients, errors, inconsistencies, compactions, thread pools, commit logs, and more. Reporting mechanisms like Graphite and JMX are also covered. The presentation aims to help understand how to gain insights into a Cassandra cluster through effective metric collection and monitoring.
Towards Benchmaking Modern Distruibuted Systems-(Grace Huang, Intel)
Towards Benchmaking Modern Distruibuted Systems-(Grace Huang, Intel)Spark Summit This document discusses StreamingBench, a benchmarking tool for streaming systems. It aims to help users understand and select streaming platforms, identify factors that impact performance, and provide guidance on optimizing resources. The document outlines StreamingBench workloads and scoring metrics, compares the performance of Spark Streaming, Storm, Trident and Samza, and analyzes how configuration choices like serialization, partitions, and acknowledgements affect throughput and latency.
Prometheus lightning talk (Devops Dublin March 2015)
Prometheus lightning talk (Devops Dublin March 2015)Brian Brazil This document introduces Prometheus, an open-source monitoring system that allows instrumentation of everything including RPCs, interfaces, business logic, and logs. It provides client libraries that make instrumentation easy across many languages. The Prometheus server can handle over a million time series in one instance with no dependencies. It offers dashboards, expression queries, alerts and integrates with many systems. Time series have structured labels allowing flexible aggregation and complex math for rules and alerts. Prometheus costs less than $.001 per time series per month and is developed by SoundCloud, Boxever and Docker with an active community.
Handling of Large Data by Salesforce
Handling of Large Data by SalesforceThinqloud The document discusses how Salesforce handles large data volumes through its multitenant infrastructure, optimizing performance techniques, and best practices for data management. It covers key strategies like using custom indexes, employing the Salesforce bulk API for data operations, and reducing data complexity in queries. Several case studies illustrate successful implementations and considerations for performance improvements while managing large datasets.
Big Data Day LA 2015 - Event Driven Architecture for Web Analytics by Peyman ...
Big Data Day LA 2015 - Event Driven Architecture for Web Analytics by Peyman ...Data Con LA The document discusses event-driven architecture for web analytics, emphasizing the importance of understanding customer experiences through event analytics compared to traditional business intelligence. It outlines various components and use cases of event analytics, including mobile and social media integrations, machine learning applications, and the unified data architecture. The architecture aims to support real-time applications and enable effective data integration across an enterprise for enhanced customer insights.
Machine learning at Scale with Apache Spark
Machine learning at Scale with Apache SparkMartin Zapletal This document discusses scaling machine learning using Apache Spark. It covers several key topics:
1) Parallelizing machine learning algorithms and neural networks to distribute computation across clusters. This includes data, model, and parameter server parallelism.
2) Apache Spark's Resilient Distributed Datasets (RDDs) programming model which allows distributing data and computation across a cluster in a fault-tolerant manner.
3) Examples of very large neural networks trained on clusters, such as a Google face detection model using 1,000 servers and a IBM brain-inspired chip model using 262,144 CPUs.
Salesforce REST API
Salesforce REST API Bohdan Dovhań The document provides an introduction to the Salesforce REST API, detailing its architecture based on Representational State Transfer (REST) principles, such as statelessness and caching. It discusses the structure of REST resources, various HTTP methods used (GET, POST, PATCH, DELETE), and the differences between REST, SOAP, and Bulk APIs. The document also covers authentication, resource access, and examples of using the API, along with references for further information.
Ad
Similar to Case Study: Elasticsearch Ingest Using StreamSets @ Cisco Intercloud (20)
Centralized log-management-with-elastic-stack
Centralized log-management-with-elastic-stackRich Lee Centralized log management is implemented using the Elastic Stack including Filebeat, Logstash, Elasticsearch, and Kibana. Filebeat ships logs to Logstash which transforms and indexes the data into Elasticsearch. Logs can then be queried and visualized in Kibana. For large volumes of logs, Kafka may be used as a buffer between the shipper and indexer. Backups are performed using Elasticsearch snapshots to a shared file system or cloud storage. Logs are indexed into time-based indices and a cron job deletes old indices to control storage usage.
IBM Cloud Native Day April 2021: Serverless Data Lake
IBM Cloud Native Day April 2021: Serverless Data LakeTorsten Steinbach - The document discusses serverless data analytics using IBM's cloud services, including a serverless data lake built on cloud object storage, serverless SQL queries using Spark, and serverless data processing functions.
- It provides an example of a COVID-19 data lake built on IBM Cloud that collects and integrates data from various sources, prepares and transforms the data, and makes it available for analytics and dashboards through serverless SQL queries.
Kafka streams decoupling with stores
Kafka streams decoupling with storesYoni Farin The document discusses the optimization and redesign of data pipelines using Apache Kafka, focusing on enhancing real-time data processing by decoupling external I/O operations. The new architecture improves performance and resiliency against external source failures, resulting in an 80% reduction in resource requirements and better CPU efficiency. It highlights the importance of carefully selecting data keys to avoid hot partitions and provides insights into using Kafka Streams for building scalable stream processing applications.
Serverless SQL
Serverless SQLTorsten Steinbach Serverless SQL provides a serverless analytics platform that allows users to analyze data stored in object storage without having to manage infrastructure. Key features include seamless elasticity, pay-per-query consumption, and the ability to analyze data directly in object storage without having to move it. The platform includes serverless storage, data ingest, data transformation, analytics, and automation capabilities. It aims to create a sharing economy for analytics by allowing various users like developers, data engineers, and analysts flexible access to data and analytics.
Centralized Logging System Using ELK Stack
Centralized Logging System Using ELK StackRohit Sharma Centralized Logging System using ELK Stack
The document discusses setting up a centralized logging system (CLS) using the ELK stack. The ELK stack consists of Logstash to capture and filter logs, Elasticsearch to index and store logs, and Kibana to visualize logs. Logstash agents on each server ship logs to Logstash, which filters and sends logs to Elasticsearch for indexing. Kibana queries Elasticsearch and presents logs through interactive dashboards. A CLS provides benefits like log analysis, auditing, compliance, and a single point of control. The ELK stack is an open-source solution that is scalable, customizable, and integrates with other tools.
IBM Cloud Day January 2021 Data Lake Deep Dive
IBM Cloud Day January 2021 Data Lake Deep DiveTorsten Steinbach This document summarizes an IBM Cloud Day 2021 presentation on IBM Cloud Data Lakes. It describes the architecture of IBM Cloud Data Lakes including data skipping capabilities, serverless analytics, and metadata management. It then discusses an example COVID-19 data lake built on IBM Cloud to provide trusted COVID-19 data to analytics applications. Key aspects included landing, preparation, and integration zones; serverless pipelines for data ingestion and transformation; and a data mart for querying and reporting.
ELK Ruminating on Logs (Zendcon 2016)
ELK Ruminating on Logs (Zendcon 2016)Mathew Beane The document provides an overview of the ELK stack (Elasticsearch, Logstash, and Kibana), detailing its components, installation process, and production considerations. It covers architecture, data flow, and challenges associated with utilizing ELK for logging and analytics, while emphasizing its capability to scale and manage log data effectively. Additionally, it addresses the various plugins, configurations, and security measures necessary for optimizing the ELK stack in a production environment.
Otimizações de Projetos de Big Data, Dw e AI no Microsoft Azure
Otimizações de Projetos de Big Data, Dw e AI no Microsoft AzureLuan Moreno Medeiros Maciel The document discusses the optimization of big data projects through various architectures like ETL (Extract/Transform/Load) and ELT (Extract/Load/Transform), emphasizing the differences between batch and real-time processing. It explores the complexities of the Lambda and Kappa architectures while highlighting technologies such as Apache Kafka and Databricks that enhance data analytics capabilities in cloud environments. Finally, it contrasts traditional data warehouses with modern solutions like Databricks Delta, which provide improved management, real-time capabilities, and transactional storage.
Databricks Platform.pptx
Databricks Platform.pptxAlex Ivy The document provides an overview of the Databricks platform, which offers a unified environment for data engineering, analytics, and AI. It describes how Databricks addresses the complexity of managing data across siloed systems by providing a single "data lakehouse" platform where all data and analytics workloads can be run. Key features highlighted include Delta Lake for ACID transactions on data lakes, auto loader for streaming data ingestion, notebooks for interactive coding, and governance tools to securely share and catalog data and models.
AWS re:Invent presentation: Unmeltable Infrastructure at Scale by Loggly
AWS re:Invent presentation: Unmeltable Infrastructure at Scale by Loggly SolarWinds Loggly This document summarizes Loggly's transition from their first generation log management infrastructure to their second generation infrastructure built on Apache Kafka, Twitter Storm, and ElasticSearch on AWS. The first generation faced challenges around tightly coupling event ingestion and indexing. The new system uses Kafka as a persistent queue, Storm for real-time event processing, and ElasticSearch for search and storage. This architecture leverages AWS services like auto-scaling and provisioned IOPS for high availability and scale. The new system provides improved elasticity, multi-tenancy, and a pre-production staging environment.
DEVNET-1140 InterCloud Mapreduce and Spark Workload Migration and Sharing: Fi...
DEVNET-1140 InterCloud Mapreduce and Spark Workload Migration and Sharing: Fi...Cisco DevNet The document discusses Cisco Intercloud Services' Customer Interaction Analytics and its migration to the Cisco Intercloud Services Analytics platform. It highlights the integration of AWS and Cisco solutions, the analytics capabilities through various data sources, and the focus on optimizing customer interactions across multiple touch points for better business outcomes. It also delves into performance metrics, requirements for the analytics platform, and potential use cases illustrating the benefits and applications of the data integration and analytics services provided.
Instrumenting and Scaling Databases with Envoy
Instrumenting and Scaling Databases with EnvoyDaniel Hochman The document discusses the use of Envoy for instrumenting and scaling cloud-native databases, highlighting challenges such as connection limits and latency issues. It details various protocols supported by Envoy for database interactions, including DynamoDB and MongoDB, and emphasizes the observability provided through telemetry data. Additionally, it outlines future plans for improving Envoy's capabilities in terms of fault injection, tracing integration, and introducing more codecs.
Typesafe spark- Zalando meetup
Typesafe spark- Zalando meetupStavros Kontopoulos This document discusses Typesafe's Reactive Platform and Apache Spark. It describes Typesafe's Fast Data strategy of using a microservices architecture with Spark, Kafka, HDFS and databases. It outlines contributions Typesafe has made to Spark, including backpressure support, dynamic resource allocation in Mesos, and integration tests. The document also discusses Typesafe's customer support and roadmap, including plans to introduce Kerberos security and evaluate Tachyon.
Enabling Microservices Frameworks to Solve Business Problems
Enabling Microservices Frameworks to Solve Business ProblemsKen Owens Ken Owens discusses enabling microservices frameworks to address business challenges through rapid innovation and deployment in various cloud environments. The document outlines the integration of multiple data storage and processing technologies, emphasizing the orchestration of services with tools like Kubernetes and Mesos. It also highlights ongoing partnerships and development efforts for advancing networking and application capabilities in hybrid cloud settings.
Logging, Metrics, and APM: The Operations Trifecta
Logging, Metrics, and APM: The Operations TrifectaElasticsearch The document discusses the integration and benefits of logs, metrics, and application performance monitoring (APM) within a unified operational data stack. It highlights features such as unified dashboards, alerting, and machine learning for anomaly detection, while detailing the evolution and capabilities of the Elastic Stack for these purposes. Additionally, it outlines practical implementations, data sources, and future roadmaps for enhancing operational data analysis.
Fluentd at Bay Area Kubernetes Meetup
Fluentd at Bay Area Kubernetes MeetupSadayuki Furuhashi Fluentd is a log collection tool that is well-suited for container environments. It allows for flexible log collection from containers through its variety of input plugins. Logs can be aggregated and buffered by Fluentd before being sent to output destinations like Elasticsearch. This addresses problems with traditional log collection in container environments by decoupling log collection from applications and making the infrastructure more scalable and reliable.
Kafka & Hadoop in Rakuten
Kafka & Hadoop in RakutenRakuten Group, Inc. The document outlines the use of Apache Kafka, Elasticsearch, and Hadoop at Rakuten, focusing on their functionalities and performance metrics. It details the architecture, challenges, and use cases for each technology in handling data pipelines and analytics, particularly emphasizing Rakuten's achievements during a 2021 super sale. Future challenges and operational improvements for these technologies are also discussed, including self-service capabilities and advanced data management strategies.
Cloud Security Monitoring and Spark Analytics
Cloud Security Monitoring and Spark Analyticsamesar0 This document summarizes a presentation about Threat Stack's use of Spark analytics to process security event data from their cloud monitoring platform. Key points:
- Threat Stack uses Spark to perform rollups and aggregations on streaming security event data from their customers' cloud environments to detect threats and monitor compliance.
- The event data is consumed from RabbitMQ by an "Event Writer" process and written to S3 in batches, where it is then processed by Spark jobs running every 10 minutes.
- Spark analytics provides scalable rollups of event counts and other metrics that are written to Postgres. This replaced less scalable homegrown solutions and Elasticsearch facets.
- Ongoing work includes optimizing
Big Data_Architecture.pptx
Big Data_Architecture.pptxbetalab The document explains various big data architecture frameworks including the Lambda, Kappa, SMACK, and Microservices architectures, highlighting their components, strengths, and weaknesses. It details orchestration and choreography in data processing, emphasizing the importance of real-time and batch processing in data workflows. Additionally, it covers essential aspects like data storage, stream processing, and analytical data stores to illustrate the mechanisms for managing and processing large datasets.
Choose Right Stream Storage: Amazon Kinesis Data Streams vs MSK
Choose Right Stream Storage: Amazon Kinesis Data Streams vs MSKSungmin Kim The document compares Amazon Kinesis Data Streams and Amazon Managed Streaming for Kafka (MSK) in the context of real-time analytics, highlighting their key features, monitoring metrics, and architectural patterns. It emphasizes the importance of stream storage, producer-consumer decoupling, and operational characteristics such as scalability and throughput. Additionally, it provides guidance on metrics to monitor for both services and outlines various use cases and best practices.
Ad
Recently uploaded (20)
最新版美国加利福尼亚大学旧金山法学院毕业证(UCLawSF毕业证书)定制
最新版美国加利福尼亚大学旧金山法学院毕业证(UCLawSF毕业证书)定制taqyea 一比一还原加利福尼亚大学旧金山法学院毕业证/UCLawSF毕业证书2025原版【q薇1954292140】我们专业办理澳洲大学毕业证成绩单,美国大学毕业证成绩单,英国大学毕业证成绩单,加拿大大学毕业证成绩单,新加坡大学毕业证成绩单,新西兰大学毕业证成绩单,韩国大学毕业证成绩单,日本大学毕业证成绩单。
【复刻一套加利福尼亚大学旧金山法学院毕业证成绩单信封等材料最强攻略,Buy University of California College of the Law, San Francisco Transcripts】
购买日韩成绩单、英国大学成绩单、美国大学成绩单、澳洲大学成绩单、加拿大大学成绩单(q微1954292140)新加坡大学成绩单、新西兰大学成绩单、爱尔兰成绩单、西班牙成绩单、德国成绩单。成绩单的意义主要体现在证明学习能力、评估学术背景、展示综合素质、提高录取率,以及是作为留信认证申请材料的一部分。
加利福尼亚大学旧金山法学院成绩单能够体现您的的学习能力,包括加利福尼亚大学旧金山法学院课程成绩、专业能力、研究能力。(q微1954292140)具体来说,成绩报告单通常包含学生的学习技能与习惯、各科成绩以及老师评语等部分,因此,成绩单不仅是学生学术能力的证明,也是评估学生是否适合某个教育项目的重要依据!
我们承诺采用的是学校原版纸张(原版纸质、底色、纹路)我们工厂拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有成品以及工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!
【主营项目】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理毕业证|办理文凭: 买大学毕业证|买大学文凭【q薇1954292140】加利福尼亚大学旧金山法学院学位证明书如何办理申请?
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理美国成绩单加利福尼亚大学旧金山法学院毕业证【q薇1954292140】国外大学毕业证, 文凭办理, 国外文凭办理, 留信网认证
三.材料咨询办理、认证咨询办理请加学历顾问【微信:1954292140】加利福尼亚大学旧金山法学院毕业证购买指大学文凭购买,毕业证办理和文凭办理。学院文凭定制,学校原版文凭补办,扫描件文凭定做,100%文凭复刻。
Microsoft Power BI - Advanced Certificate for Business Intelligence using Pow...
Microsoft Power BI - Advanced Certificate for Business Intelligence using Pow...Prasenjit Debnath Completed Power BI - Advanced Masterclass from Skill Nation
Data Visualisation in data science for students
Data Visualisation in data science for studentsconfidenceascend Data visualisation is explained in a simple manner.
The Influence off Flexible Work Policies
The Influence off Flexible Work Policiessales480687 This topic explores how flexible work policies—such as remote work, flexible hours, and hybrid models—are transforming modern workplaces. It examines the impact on employee productivity, job satisfaction, work-life balance, and organizational performance. The topic also addresses challenges such as communication gaps, maintaining company culture, and ensuring accountability. Additionally, it highlights how flexible work arrangements can attract top talent, promote inclusivity, and adapt businesses to an evolving global workforce. Ultimately, it reflects the shift in how and where work gets done in the 21st century.
最新版美国芝加哥大学毕业证(UChicago毕业证书)原版定制
最新版美国芝加哥大学毕业证(UChicago毕业证书)原版定制taqyea 2025原版芝加哥大学毕业证书pdf电子版【q薇1954292140】美国毕业证办理UChicago芝加哥大学毕业证书多少钱?【q薇1954292140】海外各大学Diploma版本,因为疫情学校推迟发放证书、证书原件丢失补办、没有正常毕业未能认证学历面临就业提供解决办法。当遭遇挂科、旷课导致无法修满学分,或者直接被学校退学,最后无法毕业拿不到毕业证。此时的你一定手足无措,因为留学一场,没有获得毕业证以及学历证明肯定是无法给自己和父母一个交代的。
【复刻芝加哥大学成绩单信封,Buy The University of Chicago Transcripts】
购买日韩成绩单、英国大学成绩单、美国大学成绩单、澳洲大学成绩单、加拿大大学成绩单(q微1954292140)新加坡大学成绩单、新西兰大学成绩单、爱尔兰成绩单、西班牙成绩单、德国成绩单。成绩单的意义主要体现在证明学习能力、评估学术背景、展示综合素质、提高录取率,以及是作为留信认证申请材料的一部分。
芝加哥大学成绩单能够体现您的的学习能力,包括芝加哥大学课程成绩、专业能力、研究能力。(q微1954292140)具体来说,成绩报告单通常包含学生的学习技能与习惯、各科成绩以及老师评语等部分,因此,成绩单不仅是学生学术能力的证明,也是评估学生是否适合某个教育项目的重要依据!
我们承诺采用的是学校原版纸张(原版纸质、底色、纹路)我们工厂拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有成品以及工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!
【主营项目】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理毕业证|办理文凭: 买大学毕业证|买大学文凭【q薇1954292140】芝加哥大学学位证明书如何办理申请?
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理美国成绩单芝加哥大学毕业证【q薇1954292140】国外大学毕业证, 文凭办理, 国外文凭办理, 留信网认证
最新版美国威斯康星大学河城分校毕业证(UWRF毕业证书)原版定制
最新版美国威斯康星大学河城分校毕业证(UWRF毕业证书)原版定制taqyea 2025原版威斯康星大学河城分校毕业证书pdf电子版【q薇1954292140】美国毕业证办理UWRF威斯康星大学河城分校毕业证书多少钱?【q薇1954292140】海外各大学Diploma版本,因为疫情学校推迟发放证书、证书原件丢失补办、没有正常毕业未能认证学历面临就业提供解决办法。当遭遇挂科、旷课导致无法修满学分,或者直接被学校退学,最后无法毕业拿不到毕业证。此时的你一定手足无措,因为留学一场,没有获得毕业证以及学历证明肯定是无法给自己和父母一个交代的。
【复刻威斯康星大学河城分校成绩单信封,Buy University of Wisconsin-River Falls Transcripts】
购买日韩成绩单、英国大学成绩单、美国大学成绩单、澳洲大学成绩单、加拿大大学成绩单(q微1954292140)新加坡大学成绩单、新西兰大学成绩单、爱尔兰成绩单、西班牙成绩单、德国成绩单。成绩单的意义主要体现在证明学习能力、评估学术背景、展示综合素质、提高录取率,以及是作为留信认证申请材料的一部分。
威斯康星大学河城分校成绩单能够体现您的的学习能力,包括威斯康星大学河城分校课程成绩、专业能力、研究能力。(q微1954292140)具体来说,成绩报告单通常包含学生的学习技能与习惯、各科成绩以及老师评语等部分,因此,成绩单不仅是学生学术能力的证明,也是评估学生是否适合某个教育项目的重要依据!
我们承诺采用的是学校原版纸张(原版纸质、底色、纹路)我们工厂拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有成品以及工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!
【主营项目】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理毕业证|办理文凭: 买大学毕业证|买大学文凭【q薇1954292140】威斯康星大学河城分校学位证明书如何办理申请?
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理美国成绩单威斯康星大学河城分校毕业证【q薇1954292140】国外大学毕业证, 文凭办理, 国外文凭办理, 留信网认证
Artigo - Playing to Win.planejamento docx
Artigo - Playing to Win.planejamento docxKellyXavier15 Excelente artifo para quem está iniciando processo de aquisiçãode planejamento estratégico
Model Evaluation & Visualisation part of a series of intro modules for data ...
Model Evaluation & Visualisation part of a series of intro modules for data ...brandonlee626749 Model Evaluation & Visualisation part of a series of intro modules for data science
Residential Zone 4 for industrial village
Residential Zone 4 for industrial villageMdYasinArafat13 based on assumption that failure of such a weld is by shear on the
effective area whether the shear transfer is parallel to or
perpendicular to the axis of the line of fillet weld. In fact, the
strength is greater for shear transfer perpendicular to the weld axis;
however, for simplicity the situations are treated the same.
美国毕业证范本中华盛顿大学学位证书CWU学生卡购买
美国毕业证范本中华盛顿大学学位证书CWU学生卡购买Taqyea 1:1原版中华盛顿大学毕业证+CWU成绩单【Q微:1954 292 140】鉴于此,CWUdiploma中华盛顿大学挂科处理解决方案CWU毕业证成绩单专业服务学历认证【Q微:1954 292 140】办理教育部学历认证,留学回国证明,中华盛顿大学毕业证、中华盛顿大学成绩单、中华盛顿大学文凭(留信学历认证+永久存档查询)办理本科+硕士+博士毕业证成绩单学历认证,我们一直是留学生的首选,质量行业第一,诚信可靠。
【中华盛顿大学成绩单一站式办理专业技术完美呈现Central Washington University Transcripts】
购买日韩成绩单、英国大学成绩单、美国大学成绩单、澳洲大学成绩单、加拿大大学成绩单(q微1954292140)新加坡大学成绩单、新西兰大学成绩单、爱尔兰成绩单、西班牙成绩单、德国成绩单。成绩单的意义主要体现在证明学习能力、评估学术背景、展示综合素质、提高录取率,以及是作为留信认证申请材料的一部分。
中华盛顿大学成绩单能够体现您的的学习能力,包括中华盛顿大学课程成绩、专业能力、研究能力。(q微1954292140)具体来说,成绩报告单通常包含学生的学习技能与习惯、各科成绩以及老师评语等部分,因此,成绩单不仅是学生学术能力的证明,也是评估学生是否适合某个教育项目的重要依据!
【主营项目】
一.毕业证【q微1954292140】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
Starbucks in the Indian market through its joint venture.
Starbucks in the Indian market through its joint venture.sales480687 This topic focuses on the growth and challenges of Starbucks in the Indian market through its joint venture with Tata. It covers localization strategies, menu adaptations, expansion goals, and financial performance. The topic also examines consumer perceptions, market competition, and how Starbucks navigates economic and cultural factors in one of its most promising international markets.
NVIDIA Triton Inference Server, a game-changing platform for deploying AI mod...
NVIDIA Triton Inference Server, a game-changing platform for deploying AI mod...Tamanna36 NVIDIA Triton Inference Server! 🌟
Learn how Triton streamlines AI model deployment with dynamic batching, support for TensorFlow, PyTorch, ONNX, and more, plus GPU-optimized performance. From YOLO11 object detection to NVIDIA Dynamo’s future, it’s your guide to scalable AI inference.
Check out the slides and share your thoughts! 👇
#AI #NVIDIA #TritonInferenceServer #MachineLearning
Case Study: Elasticsearch Ingest Using StreamSets @ Cisco Intercloud
- 1. Case Study Elasticsearch Ingest @ Cisco Intercloud
- 2. Agenda • Express Overview of StreamSets Data Collector Kirit Basu, Product Management, StreamSets • Introduction to Elastic CatherineJohnson, Solutions Architect, Elastic • Implementing Shipped Analytics Using StreamSets and Elasticsearch Dmitri Chtchourov, Innovation Architect, Cloud Solutions CTO Group Group
- 3. Performance Management for Data Flows
- 4. © 2015 StreamSets, Inc. All rights reserved. May not be copied, modified, or distributed in whole or part without written consent of StreamSets, Inc. History Founded by Informatica and Cloudera veterans. Mission Bring operational excellence to managing data in motion. Challenge Move data efficiently and with quality in the face of change. Solution Open source software enabling performance management of data flows. Use cases Hadoop Ingest, Search Ingest, Message Broker Enablement, Log Shipping, Cloud Migration, IoT, ... Momentum Thousands of downloads, hundreds of companies using. StreamSets At a Glance
- 5. © 2015 StreamSets, Inc. All rights reserved. May not be copied, modified, or distributed in whole or part without written consent of StreamSets, Inc. StreamSets Data Collector Adaptable Flows for Efficiency Design ingest pipelines with minimal coding and maximum flexibility. Data Flow KPIs for Control Monitor and act on data flow performance and data quality. Containerized Architecture for Agility Operate continuously in the face of constant change. Open source software for the rapid development and reliably operation of complex data flows.
- 6. Get Started with StreamSets http://streamsets.com/opensource https://github.com/streamsets/datacollector/ #streamsets
- 7. March 2016 Introduction to Elastic
- 8. Software that makes massive amounts of structured and unstructured data usable for search, logging, analytics, and more in mission critical systems and applications
- 9. Examples: Elastic Stack Use Cases Logging IT Operations Application Management Security Analytics Analytics Search Marketing Insights Business Development Customer Sentiment Website Search Internal/Intranet Search URL Search Internal Systems/Applications External Systems/Applications Developers IT/Ops Business Users
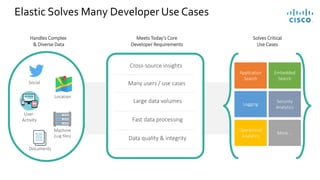
- 10. Elastic Solves Many Developer Use Cases Social Location User- Activity Machine (Log files) Documents Handles Complex & Diverse Data Meets Today’s Core Developer Requirements Developer requirements Many users / use cases Fast data processing Large data volumes Data quality & integrity Cross-source insights Solves Critical Use Cases Application Search Embedded Search Logging Security Analytics Operational Analytics More …
- 11. The Elastic Stack Ingest Store, Index, & Analyze User Interface Plugins Monitoring Security Alerting Elastic Cloud: Hosted Elasticsearch
- 13. Implementing Shipped Analytics Using Streamsets and Elasticsearch Dmitri Chtchourov, Innovation Architect, Cloud Solutions CTO Group Tymofii Polekhin, Software Engineer
- 14. Agenda MANTL & Shipped Shipped Analytics for Shipped Why we need Shipped Analytics? Archtecture and Data Flow Streamsets Pipelines End to end dataflow and performance with Elasticsearch Benefits of Streamsets Demo
- 15. Microservices managed and scaled separately Microservices managed by Mesos in a single platform Microservices architecture for Mesos frameworks and other components CIS/AWS/Metastack/vSphere/UCS… Terraform Spark Executor N Spark Executor 1 Spark Scheduler Kafka Broker N Kafka Broker 1 Kafka Scheduler Docker Docker TraefikMicroservices … REST API REST API Scripted provisioning Direct provisioning Policy, Auto-scaling VM1 or BM1 VM2 or BM2 VM3 or BM3 VM4 or BM4 VM5 or BM5
- 17. Shipped Analytics Cluster Probe Probe Probe • Both Shipped and Shipped Analytics running on MANTL • Shipped Analytics – infra and app logs and metrics analysis
- 18. mesos-master mesos-slave marathon zookeeper consul syslog frameworks collectd cpu memory interface disk df load docker zookeeper marathon mesos-slave mesos-master CollectD and Filebeat processes running on every node in the cluster.
- 19. Infrastructure Layer Zookeeper Cluster Consul Cluster Mesos Cluster Marathon Framework Kafka Cluster topbeat filebeat journalbeat dockerbeat • Experimenting with Elastic Beats (unified arch., closer to micro-services model) • Elastic Beats to replace collectd plugins and cAdvisor for containers
- 20. <file | top | *>beat collectd logstash DNS SRV beats.logstash.service.consul Data normalization Tagging Cluster name decoration Logstash is a single process per cluster, discoverable with standard inter-cluster discovery mechanism, which will get metrics from collectd on every slave and logs from filebeat on every slave, normalize data and send to desired output DNS SRV collectd.logstash.service.consul NOTE: currently Logstash is running in Docker container on every node, will be moving to Filebeat and Logstash mesos framework soon
- 21. logstash Kafka 0.9.0.0 supports SSL authentication and data encryption for producers. This is must-have security when sending data to external destination through WAN. Sending data to central SA cluster for long-term analytics SSL encryption WAN kafka SSL authentication Shipped cluster Shipped Analytics
- 22. StreamSets running in Mesos Spark Cluster mode processing data from multiple source Shipped clusters and storing it in Elasticsearch cluster. kafka elasticsearch Streamsets Spark Streaming Cluster Spark Job Master instance Spark Job Spark Job Spark Job
- 23. Lambda Reference Architecture Monitoring / Analytics Cluster (local, Texas-3) Global Monitoring / Analytics Cluster (global, Texas-1) Monitoring / Analytics Cluster (local, Ams. -1 ) Monitoring / Analytics Cluster (local, Lon.-1) Local components and deployment is the same as global, just smaller Real-time and batch processing (Lambda), anomaly detection, visualization SSL Kafka SSL SSL MQTT
- 24. Divide nodes by role for more stable cluster operation and ease of scalability 3 master/search nodes 5 live data nodes 3 archive data nodes master/ search master/ search master/ search live/ data live/ data live/ data live/ data live/ data archive /data archive /data archive /data Shards=5 Replicas=4 Shards=5 Replicas=1 archive /data archive /data CPU=4 RAM=30GB HDD=4TB CPU=4 RAM=30GB HDD=4TB CPU=4 RAM=30GB HDD=4TB
- 25. Streamsets pipelines process incoming messages and transform them according to business logic requirements, normalizing metrics and parsing log lines; popping up important information using GROK filters or scripts. Cluster Name Decorator Fields Type Normalization Metrics/Logs Stream Splitter ES Logs Output General GROK Filters Float Value Truncate ES Metrics Output Shipped GROK Logic
- 26. Marathon • Streamsets instances running in docker containers in Marathon o Easy deployment and scaling o Fast upgrade to newer version • Issues we faced with this approach: o Containers were killed by marathon o Needed to re-import pipeline every time we launch container
- 27. Marathon • Working with Streamsets trying to resolve the OOM issue we increased container memory and SDC heap size • At first, all looked normal and we thought that it was just starving on resources, but several days later we had SDC killed again • We increased MEM and HEAP even more – to 16G, but we bought just another day or two before is was killed again • Looked like SDC heap were constantly filling with data that don’t go away and eventually it kills the container • Also GC was working hard and sometimes we got freezes up to 60 seconds • Decided to move out from Docker
- 28. Marathon • Streamsets reading JSON messages from Kafka cluster and output to Elasticsearch cluster o De-serializing and serializing JSON was very slow with single threaded process o Consuming from Kafka performance test showed: JSON format: 5k records/sec avg Text format: 50k records/sec avg Binary format: 250k records/sec avg • Streamsets team were very proactive with this issues and in 2 days we received a fix for multi-threaded JSON parsing o New testing showed: JSON format: 66k records/sec avg
- 29. Marathon • Streamsets has never failed because of any internal logic bugs but we kept seeing this oom-killer popping up and recovering was not automated • We decided to leave docker and run SDC natively on host, still using Marathon for scaling and failover • Without docker, we now can upload our pipeline on SDC startup, and it will start working as soon as instance has loaded We can freely scale up/down whenever we need Also, we got rid of oom-killer issue as well
- 30. Each one of our 3 SDC instances already processes ~3B messages, with no issues!
- 31. • Streamsets pipeline consume metrics gathered by collectd and logs gathered by logstash from 4 different clusters (including self), transform and decorate them and send to Elasticsearch for storage and analytics. • First of all we consume messages from Kafka topic at average of 5,000 messages per second. The consumer itself parses JSON-format and sends further. • Next stage is a JavaScript script that decorates messages with cluster name, based on a instance hostname in that message • Finally, we exclude Marathon events from stream sending them directly to ES
- 32. • Next stage will splits stream into 2 parts: logs and metrics • Metrics are send straight to ES without any transformation • Logs are the most interesting part: o We pop docker container logs from stream and delete “time” field that’s duplicate timstamp and sending them to ES o We separate logs from specific clusters, because we need to apply special logic for them o Separation is done though mapping IP’s to clusters in the pipeline realtime
- 33. • Collecting data from several Mesos clusters and need to correlate container metrics with it’s logs • Use appID taskID and runID to identify specific containers logs • Container logs itself have all three of this, while mesos- master and mesos-agent logs lacks runID • All unidentified data is discarded
- 34. Current ShippedAnalytics prod cluster configuration: Kafka Cluster: 7 brokers with 4CPU and 16GB RAM each Logstash topic for all incoming messages with 7 partitions and 2 replicas Current data flow is avg 5000 messages/sec to Kafka Current data size is avg 1,2MB/sec to Kafka Streamsets: 3 instances with identical pipeline configuration reading from Kafka cluster 7 partitions are split between 3 instances like 3/2/2 All 3 instances running natively on host (non-docker) with Marathon Marathon restarts failed instance with automatic pipeline upload and start Elasticsearch: 7 nodes with 4CPU, 16GB RAM and 2TB storage each Each metrics is written to its own index, total of 15 indexes Each index has 5 primary shards and 5 replica shards Total Doc count: 17,5B Total Doc size: 3.84TB 1 Day rate count: ~500M 1 Day rate size: ~120GB
- 35. Streamsets is a great product to work with, also team is super helpful and works fast • Lots of input and output connectors, huge processing capabilities • Very intuitive and rich User Interface • Easy to create pipelines visually, instead of writing code • Clear data flow paths • Small resource consumption compared to performance • Easily can handle up to 10k records/sec to Elasticsearch with 1CPU 2GB RAM • Simple configuration and deployment process • Opensource(!) • Fast logic changes with minimum downtime • Preview mode(!) – check every stage before throwing all your data it • Rich data transformation possibilities • GROK filters – easy to migrate from Logstash • Smart Errors handling • Reliable: not once did Streamets crashed by itself – only Docker, Marathon, Mesos issues
- 36. Thank You!