Cassandra design patterns
Download as PPTX, PDF1 like976 views

Доклад о Cassandra предназначен для разработчиков, знакомых с системой, и охватывает ее внутреннее устройство, включая механизмы записи и чтения, а также сильные и слабые стороны. Обсуждаются ключевые вопросы проектирования, включая выбор partition key и влияние на производительность, а также способы работы с лайками и уведомлениями. Особое внимание уделяется стратегиям удаления данных и рекомендациям по оптимизации запросов.


























Cassandra design patterns
- 2. Для кого доклад Для разработчиков, которые уже знают что такое Cassandra, для чего она нужна и попробовали ее использовать.
- 3. Cassandra. Internals. Cassandra имеет внутри структуру хранения, похожую на lsm tree + wal. Верхний уровень - memtable (sorted by row key, btree-like). Нижний уровень - disk (sstable + bloom filter).
- 4. Cassandra. Java point of view. SortedMap<RowKey, SortedMap<ColumnKey, ColumnValue>>
- 5. Cassandra. Internals. Write path.
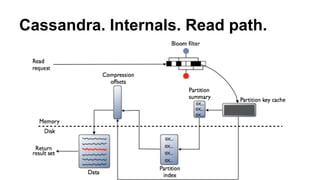
- 6. Cassandra. Internals. Read path.
- 7. Cassandra. Сильные стороны. Почти линейная масштабируемость записи и чтения Не нужно backup, все восстанавливается на лету Есть поддержка нескольких ДЦ Настраиваемая модель (в терминах CAP) Стабильный продукт с первоклассным community
- 8. Нет ACID транзакций Частое удаление данных это проблема Нет хороших secondary index* * Индексы сейчас улучшаются: https://github.com/xedin/sasi и CASSANDRA- 10661) Cassandra. Слабые стороны.
- 9. Лайки CREATE TABLE LikedByObject( user_id bigint, object_id bigint, created bigint, PRIMARY KEY (object_id, user_id) ); CREATE TABLE LikedByUser( user_id bigint, object_id bigint, created bigint, type_id int, PRIMARY KEY ((user_id, type_id), object_id) );
- 10. Лайки Выбрать всех кто лайкал объект select * from LikedByObject where object_id = 42 Выбрать все что лайкал пользователь select * from LikedByUser where user_id = 42 and type_id in (1, 2, 3)
- 11. Лайки Нет secondary index, используем materialized view. Почти всегда копирование данных более предпочтительно, так как самое затратное при чтении данных с диска это seek. Прочитать чуть больше данных, но из одного место быстрее, чем из двух.
- 12. Уведомления
- 13. Уведомления CREATE TABLE NotificationByUser ( user_id bigint, shard_part text, id timeuuid, type_id int, ..... PRIMARY KEY ((user_id, shard_part), id) ) WITH CLUSTERING ORDER BY (id DESC); CREATE TABLE NotificationByUserAndType ( ..... PRIMARY KEY ((user_id, type_id, shard_part), id) ) WITH CLUSTERING ORDER BY (id DESC); CREATE TABLE NotificationSeen ( user_id bigint, id timeuuid, value boolean, PRIMARY KEY (user_id, id) ) WITH CLUSTERING ORDER BY (id DESC);
- 14. Уведомления Уведомления всегда отсортированы по времени события, к которому они относятся. Используем clustering order, чтобы данные физически хранились в нужном порядке. Уведомления могут быть непросмотренные и просмотренные. Выделим мутабельную часть данных в отдельную cf. Это упрощает процесс обновления данных и API.
- 15. Уведомления CREATE TABLE NotificationByUser ( user_id bigint, shard_part text, id timeuuid, type_id int, ..... PRIMARY KEY ((user_id, shard_part), id) ) WITH CLUSTERING ORDER BY (id DESC); У одного пользователя может быть очень много уведомлений. Таким образом у нас могут появится wide rows. Их нужно избегать (OOM, additional seeks, вот это вот все). Добавим в partition key дату.
- 16. Partition keys Как правильно выбрать partition key? Распределение колонок внутри строки должно быть равномерным в идеале. В одной строке не должно быть слишком много данных (wide rows). Варианты: Сам ключ Ключ + timebased часть Ключ + partition (n of partitions fixed or any)
- 17. Partition keys Лайки. У одного объекта очень редко бывает слишком много лайков. Object id хороший partition key. Уведомления. У одного пользователя может быть очень много уведомлений, так как они накапливаются со временем. User id плохой partition key. Нужно добавить что-то еще. User id + date. Можно также сделать предположение, что уведомления более- менее распределены по дням равномерно, поэтому date подходит.
- 18. Partition keys Лента постов по тегу. CREATE TABLE TagPosts ( tag text, partition int, post_id bigint, PRIMARY KEY((tag, partition), post_id) ) WITH CLUSTERING ORDER BY (post_id DESC); Просто tag взять нельзя, потому что распределение имеет выбросы (тренды) и длинный хвост. Date плохая идея, так как хвост и тренды не зависят от даты.
- 19. Partition keys Неестественное разбиение данных на любое количество partitions сложнее. При вставке нужно вычислять partition. CREATE TABLE TagPostsPartitions ( tag text, partition int, post_count counter, PRIMARY KEY (tag, partition) ) WITH CLUSTERING ORDER BY (partition DESC);
- 20. Partition keys Если вы уверены, что кол-во данных по каждому ключу примерно одинаково, то вычисление partition может быть простым: key % n partitions
- 21. Partition keys Вопрос: можно ли делать skinny partitions*? *skinny partition - в одной партиции одна строка Ответ: да, если паттерн доступа random и нет range queries. CREATE TABLE BlackList ( login text, created bigint, PRIMARY KEY (login) );
- 22. Вставка Используйте batches, только если вам действительно нужна атомарность Для производительности используйте асинхронные операции (в драйвере) с одиночными запросами* *http://lostechies.com/ryansvihla/2014/08/28/cassandra-batch-loading- without-the-batch-keyword/
- 23. Удаление CREATE TABLE Queues ( queue_id bigint, enqueued timeuuid, PRIMARY KEY (queue_id, enqueued) ); Классический anti-pattern!
- 24. Удаление Как и в любом log-structure engine, данные физически сразу не удаляются. Удаленные данные будут помечены, как tombstone, и через некоторое время (настраивается) будут физически удалены при очередном compaction. Операция DELETE по ключу ввполняется за O(1). Операция выборки вида: select * from Queues where queue_id = 42 order by enqueued limit 1 может выполняться за O(n).
- 25. Удаление Думайте про удаление заранее Старайтесь удалять партиции целиком
- 26. Избегайте RMW Делайте операции идемпотентными и переписывайте данные Используйте counter columns Используйте транзакции осторожно, они замедляют производительность и все равно не ACID