Cassandra introduction mars jug
1 like1,019 views

This document provides an introduction and overview of Cassandra including: - Cassandra's history as a NoSQL database created at Facebook and open sourced in 2008. - Key features of Cassandra including linear scalability, continuous availability, ability to span multiple data centers, and operational simplicity. - A high-level overview of Cassandra's architecture including its use of Dynamo and BigTable papers for the cluster and data storage layers. - Concepts related to Cassandra's data model including data distribution, token ranges, replication, write path, and "last write wins" consistency.





















![Data distribution!
@doanduyhai
22
Random: hash of #partition → token = hash(#p)
Hash: ]-X, X]
X = huge number (264/2)
n1
n2
n3
n4
n5
n6
n7
n8](https://image.slidesharecdn.com/cassandraintroductionmarsjug-141212091418-conversion-gate02/85/Cassandra-introduction-mars-jug-22-320.jpg)
![Token Ranges!
@doanduyhai
23
A: ]0, X/8]
B: ] X/8, 2X/8]
C: ] 2X/8, 3X/8]
D: ] 3X/8, 4X/8]
E: ] 4X/8, 5X/8]
F: ] 5X/8, 6X/8]
G: ] 6X/8, 7X/8]
H: ] 7X/8, X]
n1
n2
n3
n4
n5
n6
n7
n8
A
B
C
D
E
F
G
H](https://image.slidesharecdn.com/cassandraintroductionmarsjug-141212091418-conversion-gate02/85/Cassandra-introduction-mars-jug-23-320.jpg)













































![WHERE clause restrictions!
@doanduyhai
71
What if I want to perform « arbitrary » WHERE clause ?
• search form scenario, dynamic search fields
☞ Apache Solr (Lucene) integration (Datastax Enterprise)
SELECT * FROM users WHERE solr_query = ‘age:[33 TO *] AND gender:male’;
SELECT * FROM users WHERE solr_query = ‘lastname:*schwei?er’;](https://image.slidesharecdn.com/cassandraintroductionmarsjug-141212091418-conversion-gate02/85/Cassandra-introduction-mars-jug-71-320.jpg)





































Cassandra introduction mars jug
- 1. Introduction to Cassandra DuyHai DOAN, Technical Advocate @doanduyhai
- 2. Shameless self-promotion! @doanduyhai 2 Duy Hai DOAN Cassandra technical advocate • talks, meetups, confs • open-source devs (Achilles, …) • OSS Cassandra point of contact ☞ [email protected] • production troubleshooting
- 3. Datastax! @doanduyhai 3 • Founded in April 2010 • We contribute a lot to Apache Cassandra™ • 400+ customers (25 of the Fortune 100), 200+ employees • Headquarter in San Francisco Bay area • EU headquarter in London, offices in France and Germany • Datastax Enterprise = OSS Cassandra + extra features
- 4. Agenda! @doanduyhai 4 Architecture • Cluster, Replication, Consistency Data model • Last Write Win (LWW), CQL basics, From SQL to CQL Dev Center Demo DSE overview CQL In Depth (time permitted)
- 5. Cassandra history! @doanduyhai 5 NoSQL database • created at Facebook • open-sourced since 2008 • current version = 2.1 • column-oriented ☞ distributed table
- 6. Cassandra 5 key facts! @doanduyhai 6 Linear scalability C* C*C* NetcoSports 3 nodes, ≈3GB NetFlix 1k+ nodes, PB+ YOU
- 7. Cassandra 5 key facts! @doanduyhai 7 Continuous availability (≈100% up-time) • resilient architecture (Dynamo)
- 8. Rolling Upgrades! @doanduyhai 8 n1 n2 n3 n4 n5 n6 n7 n8 Live production
- 9. Rolling Upgrades! @doanduyhai 9 n1 n2 n3 n4 n5 n6 n7 n8 Live production
- 10. Rolling Upgrades! @doanduyhai 10 n1 n2 n3 n4 n5 n6 n7 n8 Live production
- 11. Cassandra 5 key facts! @doanduyhai 11 Continuous availability (≈100% up-time) • resilient architecture (Dynamo) • rolling upgrades • data backward compatible n/n+1 versions
- 12. Cassandra 5 key facts! @doanduyhai 12 Multi-data centers • out-of-the-box (config only) • AWS conf for multi-region DCs • GCE/CloudStack support
- 13. Muti-DC usages! @doanduyhai 13 New York (DC1) London (DC2) Data-locality, disaster recovery n2 n3 n4 n5 n6 n7 n8 n1 n2 n3 n n4 5 n1 Async replication
- 14. Muti-DC usages! @doanduyhai 14 Workload segregation/virtual DC n2 n3 n4 n5 n6 n7 n8 n1 n2 n3 n n4 5 n1 Production (Live) Analytics (Spark/Hadoop) Same DC
- 15. Muti-DC usages! @doanduyhai 15 Prod data copy for testing/benchmarking n2 n3 n4 n5 n6 n7 n8 n1 n2 n1 n3 Use LOCAL consistency My tiny test cluster Data copy ❌ Never read back
- 16. Cassandra 5 key facts! @doanduyhai 16 Operational simplicity • 1 node = 1 process + 1 config file • deployment automation • OpsCenter for monitoring
- 17. Cassandra 5 key facts! @doanduyhai 17
- 18. Cassandra 5 key facts! @doanduyhai 18 Analytics combo • Cassandra + Spark = awesome ! • realtime streaming
- 19. Cassandra architecture! Cluster Replication Consistency
- 20. Cassandra architecture! @doanduyhai 20 Cluster layer • Amazon DynamoDB paper • masterless architecture Data-store layer • Google Big Table paper • Columns/columns family
- 21. Cassandra architecture! @doanduyhai 21 API (CQL & RPC) CLUSTER (DYNAMO) DATA STORE (BIG TABLES) DISKS Node1 Client request API (CQL & RPC) CLUSTER (DYNAMO) DATA STORE (BIG TABLES) DISKS Node2
- 22. Data distribution! @doanduyhai 22 Random: hash of #partition → token = hash(#p) Hash: ]-X, X] X = huge number (264/2) n1 n2 n3 n4 n5 n6 n7 n8
- 23. Token Ranges! @doanduyhai 23 A: ]0, X/8] B: ] X/8, 2X/8] C: ] 2X/8, 3X/8] D: ] 3X/8, 4X/8] E: ] 4X/8, 5X/8] F: ] 5X/8, 6X/8] G: ] 6X/8, 7X/8] H: ] 7X/8, X] n1 n2 n3 n4 n5 n6 n7 n8 A B C D E F G H
- 24. Linear scalability! @doanduyhai 24 n1 n2 8 nodes 10 nodes n3 n4 n5 n6 n7 n8 n1 n2 n3 n4 n5 n6 n7 n9 n8 n10
- 25. Failure tolerance! @doanduyhai 25 Replication Factor (RF) = 3 n1 n2 n3 n4 n5 n6 n7 n8 1 2 3 {B, A, H} {C, B, A} {D, C, B} A B C D E F G H
- 26. Coordinator node! Incoming requests (read/write) Coordinator node handles the request Every node can be coordinator àmasterless @doanduyhai n1 n2 n3 n4 n5 n6 n7 n8 1 2 3 coordinator request
- 27. Consistency! @doanduyhai 27 Tunable at runtime • ONE • QUORUM (strict majority w.r.t. RF) • ALL Apply both to read & write
- 28. Write consistency! Write ONE • write request to all replicas in // @doanduyhai n1 n2 n3 n4 n5 n6 n7 n8 1 2 3 coordinator
- 29. Write consistency! Write ONE • write request to all replicas in // • wait for ONE ack before returning to client @doanduyhai n1 n2 n3 n4 n5 n6 n7 n8 1 2 3 coordinator 5 μs
- 30. Write consistency! Write ONE • write request to all replicas in // • wait for ONE ack before returning to client • other acks later, asynchronously @doanduyhai n1 n2 n3 n4 n5 n6 n7 n8 1 2 3 coordinator 5 μs 10 μs 120 μs
- 31. Write consistency! Write QUORUM • write request to all replicas in // • wait for QUORUM acks before returning to client • other acks later, asynchronously @doanduyhai n1 n2 n3 n4 n5 n6 n7 n8 1 2 3 coordinator 5 μs 10 μs 120 μs
- 32. Read consistency! Read ONE • read from one node among all replicas @doanduyhai n1 n2 n3 n4 n5 n6 n7 n8 1 2 3 coordinator
- 33. Read consistency! Read ONE • read from one node among all replicas • contact the fastest node (stats) @doanduyhai n1 n2 n3 n4 n5 n6 n7 n8 1 2 3 coordinator
- 34. Read consistency! Read QUORUM • read from one fastest node @doanduyhai n1 n2 n3 n4 n5 n6 n7 n8 1 2 3 coordinator
- 35. Read consistency! Read QUORUM • read from one fastest node • AND request digest from other replicas to reach QUORUM @doanduyhai n1 n2 n3 n4 n5 n6 n7 n8 1 2 3 coordinator
- 36. Read consistency! Read QUORUM • read from one fastest node • AND request digest from other replicas to reach QUORUM • return most up-to-date data to client @doanduyhai n1 n2 n3 n4 n5 n6 n7 n8 1 2 3 coordinator
- 37. Read consistency! Read QUORUM • read from one fastest node • AND request digest from other replicas to reach QUORUM • return most up-to-date data to client • repair if digest mismatch n1 @doanduyhai n2 n3 n4 n5 n6 n7 n8 1 2 3 coordinator
- 39. Consistency in action! @doanduyhai 39 RF = 3, Write ONE, Read ONE B A A B A A Read ONE: A data replication in progress … Write ONE: B
- 40. Consistency in action! @doanduyhai 40 RF = 3, Write ONE, Read QUORUM B A A Write ONE: B Read QUORUM: A data replication in progress … B A A
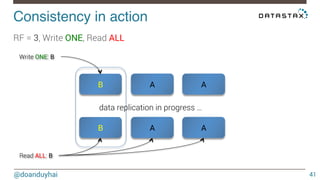
- 41. Consistency in action! @doanduyhai 41 RF = 3, Write ONE, Read ALL B A A Read ALL: B data replication in progress … B A A Write ONE: B
- 42. Consistency in action! @doanduyhai 42 RF = 3, Write QUORUM, Read ONE B B A Write QUORUM: B Read ONE: A data replication in progress … B B A
- 43. Consistency in action! @doanduyhai 43 RF = 3, Write QUORUM, Read QUORUM B B A Read QUORUM: B data replication in progress … B B A Write QUORUM: B
- 44. Consistency level! @doanduyhai 44 ONE Fast, may not read latest written value
- 45. Consistency level! @doanduyhai 45 QUORUM Strict majority w.r.t. Replication Factor Good balance
- 46. Consistency level! @doanduyhai 46 ALL Paranoid Slow, no high availability
- 47. Consistency summary! ONERead + ONEWrite ☞ available for read/write even (N-1) replicas down QUORUMRead + QUORUMWrite ☞ available for read/write even 1+ replica down @doanduyhai 47
- 48. ! " ! Q & R
- 49. Data model! Cassandra Write Path! Last Write Win! CQL basics! From SQL to CQL!
- 50. Cassandra Write Path! @doanduyhai 50 Commit log1 . . . 1 Commit log2 Commit logn Memory
- 51. Cassandra Write Path! @doanduyhai 51 Memory MemTable Table1 Commit log1 . . . 1 Commit log2 Commit logn MemTable Table2 MemTable TableN 2 . . .
- 52. Cassandra Write Path! @doanduyhai 52 Commit log1 Commit log2 Commit logn Table1 Table2 Table3 SStable2 SStable3 3 SStable1 Memory . . .
- 53. Cassandra Write Path! @doanduyhai 53 MemTable . . . Memory Table1 Commit log1 Commit log2 Commit logn Table1 SStable1 Table2 Table3 SStable2 SStable3 MemTable Table2 MemTable TableN . . .
- 54. Cassandra Write Path! @doanduyhai 54 Commit log1 Commit log2 SStable3 . . . Commit logn Table1 SStable1 Memory Table2 Table3 SStable2 SStable3 SStable1 SStable2
- 55. Last Write Win (LWW)! INSERT INTO users(login, name, age) VALUES(‘jdoe’, ‘John DOE’, 33); @doanduyhai 55 jdoe age name 33 John DOE #partition
- 56. Last Write Win (LWW)! @doanduyhai jdoe age (t1) name (t1) 33 John DOE 56 INSERT INTO users(login, name, age) VALUES(‘jdoe’, ‘John DOE’, 33); auto-generated timestamp .
- 57. Last Write Win (LWW)! @doanduyhai 57 UPDATE users SET age = 34 WHERE login = jdoe; jdoe SSTable1 SSTable2 age (t1) name (t1) 33 John DOE jdoe age (t2) 34
- 58. Last Write Win (LWW)! @doanduyhai 58 DELETE age FROM users WHERE login = jdoe; tombstone SSTable1 SSTable2 SSTable3 jdoe age (t3) ý jdoe age (t1) name (t1) 33 John DOE jdoe age (t2) 34
- 59. Last Write Win (LWW)! @doanduyhai 59 SELECT age FROM users WHERE login = jdoe; ? ? ? SSTable1 SSTable2 SSTable3 jdoe age (t3) ý jdoe age (t1) name (t1) 33 John DOE jdoe age (t2) 34
- 60. Last Write Win (LWW)! @doanduyhai 60 SELECT age FROM users WHERE login = jdoe; ✕ ✕ ✓ SSTable1 SSTable2 SSTable3 jdoe age (t3) ý jdoe age (t1) name (t1) 33 John DOE jdoe age (t2) 34
- 61. Compaction! @doanduyhai 61 SSTable1 SSTable2 SSTable3 jdoe age (t3) ý jdoe age (t1) name (t1) 33 John DOE jdoe age (t2) 34 New SSTable jdoe age (t3) name (t1) ý John DOE
- 62. Historical data! You want to keep data history ? • do not use internal generated timestamp !!! • ☞ time-series data modeling @doanduyhai 62 history id SSTable1 SSTable2 date1(t1) date2(t2) … date9(t9) … … … … id date10(t10) date11(t11) … … … … … …
- 63. CRUD operations! @doanduyhai 63 INSERT INTO users(login, name, age) VALUES(‘jdoe’, ‘John DOE’, 33); UPDATE users SET age = 34 WHERE login = jdoe; DELETE age FROM users WHERE login = jdoe; SELECT age FROM users WHERE login = jdoe;
- 64. Simple Table! @doanduyhai 64 CREATE TABLE users ( login text, name text, age int, … PRIMARY KEY(login)); partition key (#partition)
- 65. Clustered table (1 – N)! @doanduyhai 65 CREATE TABLE mailbox ( login text, message_id timeuuid, interlocutor text, message text, PRIMARY KEY((login), message_id)); partition key clustering column (sorted) unicity
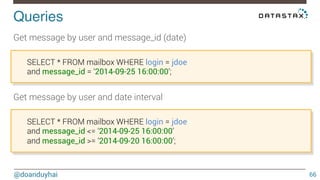
- 66. Queries! @doanduyhai 66 Get message by user and message_id (date) SELECT * FROM mailbox WHERE login = jdoe and message_id = ‘2014-09-25 16:00:00’; Get message by user and date interval SELECT * FROM mailbox WHERE login = jdoe and message_id <= ‘2014-09-25 16:00:00’ and message_id >= ‘2014-09-20 16:00:00’;
- 67. Queries! @doanduyhai 67 Get message by message_id only (#partition not provided) SELECT * FROM mailbox WHERE message_id = ‘2014-09-25 16:00:00’; Get message by date interval (#partition not provided) SELECT * FROM mailbox WHERE and message_id <= ‘2014-09-25 16:00:00’ and message_id >= ‘2014-09-20 16:00:00’;
- 68. Queries! Get message by user range (range query on #partition) Get message by user pattern (non exact match on #partition) @doanduyhai 68 SELECT * FROM mailbox WHERE login >= hsue and login <= jdoe; SELECT * FROM mailbox WHERE login like ‘%doe%‘;
- 69. WHERE clause restrictions! @doanduyhai 69 All queries (INSERT/UPDATE/DELETE/SELECT) must provide #partition Only exact match (=) on #partition, range queries (<, ≤, >, ≥) not allowed • ☞ full cluster scan On clustering columns, only range queries (<, ≤, >, ≥) and exact match WHERE clause only possible on columns defined in PRIMARY KEY
- 70. WHERE clause restrictions! @doanduyhai 70 What if I want to perform « arbitrary » WHERE clause ? • search form scenario, dynamic search fields
- 71. WHERE clause restrictions! @doanduyhai 71 What if I want to perform « arbitrary » WHERE clause ? • search form scenario, dynamic search fields ☞ Apache Solr (Lucene) integration (Datastax Enterprise) SELECT * FROM users WHERE solr_query = ‘age:[33 TO *] AND gender:male’; SELECT * FROM users WHERE solr_query = ‘lastname:*schwei?er’;
- 72. Collections & maps! @doanduyhai 72 CREATE TABLE users ( login text, name text, age int, friends set<text>, hobbies list<text>, languages map<int, text>, … PRIMARY KEY(login));
- 73. User Defined Type (UDT)! Instead of @doanduyhai 73 CREATE TABLE users ( login text, … street_number int, street_name text, postcode int, country text, … PRIMARY KEY(login));
- 74. User Defined Type (UDT)! @doanduyhai 74 CREATE TYPE address ( street_number int, street_name text, postcode int, country text); CREATE TABLE users ( login text, … location frozen <address>, … PRIMARY KEY(login));
- 75. UDT insert! @doanduyhai 75 INSERT INTO users(login,name, location) VALUES ( ‘jdoe’, ’John DOE’, { ‘street_number’: 124, ‘street_name’: ‘Congress Avenue’, ‘postcode’: 95054, ‘country’: ‘USA’ });
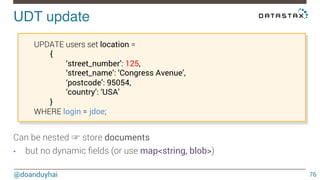
- 76. UDT update! @doanduyhai 76 UPDATE users set location = { ‘street_number’: 125, ‘street_name’: ‘Congress Avenue’, ‘postcode’: 95054, ‘country’: ‘USA’ } WHERE login = jdoe; Can be nested ☞ store documents • but no dynamic fields (or use map<string, blob>)
- 77. From SQL to CQL! @doanduyhai 77 Remember…
- 78. From SQL to CQL! @doanduyhai 78 Remember… CQL is not SQL
- 79. From SQL to CQL! @doanduyhai 79 Remember… there is no join (do you want to scale ?)
- 80. From SQL to CQL! @doanduyhai 80 Remember… there is no integrity constraint (do you want to read-before-write ?)
- 81. From SQL to CQL! @doanduyhai 81 Normalized User 1 n Comment CREATE TABLE comments ( article_id uuid, comment_id timeuuid, author_id text, // typical join id content text, PRIMARY KEY((article_id), comment_id));
- 82. From SQL to CQL! @doanduyhai 82 De-normalized User 1 n Comment CREATE TABLE comments ( article_id uuid, comment_id timeuuid, author person, // person is UDT content text, PRIMARY KEY((article_id), comment_id));
- 83. Data modeling best practices! @doanduyhai 83 Start by queries • identify core functional read paths • 1 read scenario ≈ 1 SELECT
- 84. Data modeling best practices! @doanduyhai 84 Start by queries • identify core functional read paths • 1 read scenario ≈ 1 SELECT Denormalize • wisely, only duplicate necessary & immutable data • functional/technical trade-off
- 85. Data modeling best practices! @doanduyhai 85 Person UDT - firstname/lastname - date of birth - gender - mood - location
- 86. Data modeling best practices! @doanduyhai 86 John DOE, male birthdate: 21/02/1981 subscribed since 03/06/2011 ☉ San Mateo, CA ’’Impossible is not John DOE’’ Full detail read from User table on click
- 87. ! " ! Q & R
- 88. DSE (Datastax Enterprise)! @doanduyhai 88 Security Analytics (Spark & Hadoop) Search (Solr)
- 89. Use Cases! @doanduyhai 89 Messaging Collections/ Playlists Fraud detection Recommendation/ Personalization Internet of things/ Sensor data
- 90. CQL In Depth! Simple Table! Clustered Table!
- 91. Storage Engine! @doanduyhai 91 #partition1 #col1 #col2 #col3 #col4 cell1 cell2 cell3 cell4 #partition2 #col1 #col2 #col3 cell1 cell2 cell3 #partition3 #col1 #col2 cell1 cell2 #partition4 #col1 #col2 #col3 #col4 … cell1 cell2 cell3 cell4 … Partition Key Column Name Cell
- 92. Data Model Abstraction! @doanduyhai 92 Table ≈ Map<#p,SortedMap<#col,cell>> SortedMap<token,…>
- 93. Data Model Abstraction! @doanduyhai 93 Table ≈ Map<#p,SortedMap<#col,cell>> SortedMap<#col,cell>> ! ! SortedMap<token,…> Unicity Sort
- 94. Static Data Type! Partition Key Type Column Name Type Cell Type @doanduyhai 94 Table ≈ Map<#p,SortedMap<#col,cell>> Native types: bigint, blob, counter, decimal, double, float, inet, int, timestamp, timeuuid, uuid.
- 95. Simple Table Mapping! @doanduyhai 95 CREATE TABLE users ( login text, name text, age int, … PRIMARY KEY(login)); Map<login,SortedMap<column_label,value>>! text text blob
- 96. Simple Table Mapping! @doanduyhai 96 INSERT INTO users(login, name, age) VALUES(‘jdoe’, 33, ‘John DOE’); INSERT INTO users(login, name, age) VALUES(‘hsue’, 26, ‘Helen SUE’); RowKey: jdoe => (name=, value=, timestamp=1412419763515000) => (name=age, value=00000021, timestamp=1412419763515000) => (name=name, value=4a6f686e20444f45, timestamp=1412419763515000) RowKey: hsue => (name=, value=, timestamp=1412419776578000) => (name=age, value=0000001c, timestamp=1412419776578000) => (name=name, value=48656c656e20535545, timestamp=1412419776578000)!
- 97. Simple Table Mapping! @doanduyhai 97 INSERT INTO users(login, name, age) VALUES(‘jdoe’, 33, ‘John DOE’); INSERT INTO users(login, name, age) VALUES(‘hsue’, 26, ‘Helen SUE’); RowKey: jdoe => (name=, value=, timestamp=1412419763515000) => (name=age, value=00000021, timestamp=1412419763515000) => (name=name, value=4a6f686e20444f45, timestamp=1412419763515000) RowKey: hsue => (name=, value=, timestamp=1412419776578000) => (name=age, value=0000001c, timestamp=1412419776578000) => (name=name, value=48656c656e20535545, timestamp=1412419776578000)! Marker column
- 98. Simple Table Mapping! @doanduyhai 98 INSERT INTO users(login, name, age) VALUES(‘jdoe’, 33, ‘John DOE’); INSERT INTO users(login, name, age) VALUES(‘hsue’, 26, ‘Helen SUE’); RowKey: jdoe => (name=, value=, timestamp=1412419763515000) => (name=age, value=00000021, timestamp=1412419763515000) => (name=name, value=4a6f686e20444f45, timestamp=1412419763515000) RowKey: hsue => (name=, value=, timestamp=1412419776578000) => (name=age, value=0000001c, timestamp=1412419776578000) => (name=name, value=48656c656e20535545, timestamp=1412419776578000)! Sorted column_label
- 99. Simple Table Mapping! @doanduyhai 99 INSERT INTO users(login, name, age) VALUES(‘jdoe’, 33, ‘John DOE’); INSERT INTO users(login, name, age) VALUES(‘hsue’, 26, ‘Helen SUE’); RowKey: jdoe => (name=, value=, timestamp=1412419763515000) => (name=age, value=00000021, timestamp=1412419763515000) => (name=name, value=4a6f686e20444f45, timestamp=1412419763515000) RowKey: hsue => (name=, value=, timestamp=1412419776578000) => (name=age, value=0000001c, timestamp=1412419776578000) => (name=name, value=48656c656e20535545, timestamp=1412419776578000)! Values as bytes
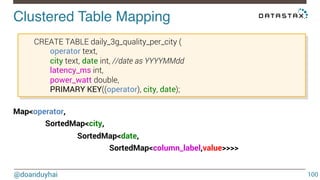
- 100. Clustered Table Mapping! @doanduyhai 100 CREATE TABLE daily_3g_quality_per_city ( operator text, city text, date int, //date as YYYYMMdd latency_ms int, power_watt double, PRIMARY KEY((operator), city, date); Map<operator, SortedMap<city, SortedMap<date, SortedMap<column_label,value>>>>!
- 101. Clustered Table Mapping! @doanduyhai 101 RowKey: verizon => (name=Austin:20140910:, value=, timestamp=…) => (name=Austin:20140910:latency_ms, value=000000e6, timestamp=…) => (name=Austin:20140910:power_watt, value=3ff3333333333333, timestamp=…) => (name=Austin:20140911:, value=, timestamp=…) => (name=Austin:20140911:latency_ms, value=000000d4, timestamp=…) => (name=Austin:20140911:power_watt, value=3ff6666666666666, timestamp=…) => (name=New York:20140913:, value=, timestamp=1412422893832000) => (name=New York:20140913:latency_ms, value=0000007b, timestamp=…) => (name=New York:20140913:power_watt, value=3ffb333333333333, timestamp=…) => (name=New York:20140917:, value=, timestamp=…) => (name=New York:20140917:latency_ms, value=00000067, timestamp=…) => (name=New York:20140917:power_watt, value=3ffe666666666666, timestamp=…)
- 102. Clustered Table Mapping! @doanduyhai 102 RowKey: verizon => (name=Austin:20140910:, value=, timestamp=…) => (name=Austin:20140910:latency_ms, value=000000e6, timestamp=…) => (name=Austin:20140910:power_watt, value=3ff3333333333333, timestamp=…) => (name=Austin:20140911:, value=, timestamp=…) => (name=Austin:20140911:latency_ms, value=000000d4, timestamp=…) => (name=Austin:20140911:power_watt, value=3ff6666666666666, timestamp=…) => (name=New York:20140913:, value=, timestamp=1412422893832000) => (name=New York:20140913:latency_ms, value=0000007b, timestamp=…) => (name=New York:20140913:power_watt, value=3ffb333333333333, timestamp=…) => (name=New York:20140917:, value=, timestamp=…) => (name=New York:20140917:latency_ms, value=00000067, timestamp=…) => (name=New York:20140917:power_watt, value=3ffe666666666666, timestamp=…) Sort first by city
- 103. Clustered Table Mapping! @doanduyhai 103 RowKey: verizon => (name=Austin:20140910:, value=, timestamp=…) => (name=Austin:20140910:latency_ms, value=000000e6, timestamp=…) => (name=Austin:20140910:power_watt, value=3ff3333333333333, timestamp=…) => (name=Austin:20140911:, value=, timestamp=…) => (name=Austin:20140911:latency_ms, value=000000d4, timestamp=…) => (name=Austin:20140911:power_watt, value=3ff6666666666666, timestamp=…) => (name=New York:20140913:, value=, timestamp=1412422893832000) => (name=New York:20140913:latency_ms, value=0000007b, timestamp=…) => (name=New York:20140913:power_watt, value=3ffb333333333333, timestamp=…) => (name=New York:20140917:, value=, timestamp=…) => (name=New York:20140917:latency_ms, value=00000067, timestamp=…) => (name=New York:20140917:power_watt, value=3ffe666666666666, timestamp=…) … then by date
- 104. Clustered Table Mapping! @doanduyhai 104 RowKey: verizon => (name=Austin:20140910:, value=, timestamp=…) => (name=Austin:20140910:latency_ms, value=000000e6, timestamp=…) => (name=Austin:20140910:power_watt, value=3ff3333333333333, timestamp=…) => (name=Austin:20140911:, value=, timestamp=…) => (name=Austin:20140911:latency_ms, value=000000d4, timestamp=…) => (name=Austin:20140911:power_watt, value=3ff6666666666666, timestamp=…) => (name=New York:20140913:, value=, timestamp=1412422893832000) => (name=New York:20140913:latency_ms, value=0000007b, timestamp=…) => (name=New York:20140913:power_watt, value=3ffb333333333333, timestamp=…) => (name=New York:20140917:, value=, timestamp=…) => (name=New York:20140917:latency_ms, value=00000067, timestamp=…) => (name=New York:20140917:power_watt, value=3ffe666666666666, timestamp=…) … then by column_label
- 105. Query With Clustered Table! Select by operator and city for all dates Select by operator and city range for all dates @doanduyhai 105 SELECT * FROM daily_3g_quality_per_city WHERE operator = ‘verizon’ AND city = ‘Austin’ SELECT * FROM daily_3g_quality_per_city WHERE operator = ‘verizon’ AND city >= ‘Austin’ AND city <= ‘New York’
- 106. Query With Clustered Table! Select by operator and city and date Select by operator and city and range of date @doanduyhai 106 SELECT * FROM daily_3g_quality_per_city WHERE operator = ‘verizon’ AND city = ‘Austin’ AND date = 20140910 SELECT * FROM daily_3g_quality_per_city WHERE operator = ‘verizon’ AND city = ‘Austin’ AND date >= 20140910 AND date <= 20140913
- 107. Query With Clustered Table! @doanduyhai 107 Select by operator and city and date tuples SELECT * FROM daily_3g_quality_per_city WHERE operator = ‘verizon’ AND city = ‘Austin’ AND date IN (20140910, 20140913)
- 108. Query With Clustered Table! @doanduyhai 108 Select by operator and date without city SELECT * FROM daily_3g_quality_per_city WHERE operator = ‘verizon’ AND date = 20140910 Map<operator, SortedMap<city, SortedMap<date, SortedMap<column_label,value>>>>!
- 109. ! " ! Q & R
- 110. Thank You @doanduyhai [email protected] https://academy.datastax.com/