Chapter-5 The Relational Data Model
Download as PPTX, PDF1 like395 views

This chapter discusses the concepts of the relational data model. We learn how to convert an ER diagram into a relational schema diagram.















































































Ad
More Related Content
What's hot (20)
Similar to Chapter-5 The Relational Data Model (20)


















Ad
More from Kunal Anand (7)







Ad
Recently uploaded (20)




















Chapter-5 The Relational Data Model
- 1. Learning Resource On Database Management Systems Chapter-5 The Relational Data Model Prepared By: Kunal Anand, Asst. Professor SCE, KIIT, DU, Bhubaneswar-24
- 2. Chapter Outcome: • After the completion of this chapter, the students will be able to: – Define different relational model concepts – Explain several keys in relational model – Describe constraints in relational model – Identify the characteristics of relational databases – Convert ER model into relational model 16 March 2021 2
- 3. Organization of this Chapter: • Introduction • Relational Model Concepts • Keys in Relational Model • Relational Model Constraints • Characteristics of Relational Model • Relational Database and its Schema • Logical Database Design: ER to Relational 16 March 2021 3
- 4. Introduction • The relational data model was introduced by Ted Codd of IBM Research in 1970. • The relational data model enables even the novice users to understand the database, and it permits the use of simple, high level language to query the data. • It became very popular in short span of time due to its simplicity and mathematical foundation. • The first commercial implementation of the relational data model became available in early 80s, since then the model has been implemented in a large number of open source systems. • Current popular commercial RDBMSs include DB2 from IBM, Oracle from oracle, Sybase DBMS (now SAP), and SQL server and Microsoft Access from Microsoft. 16 March 2021 4
- 5. Relational Model Concepts • The main construct to represent the data in the relational model is a “Relation” which is used to refer to a table. • In a relation or table, a column header is called an “attribute”, and a row is called a “tuple”. • Mathematically, a tuple is a sequence of values. A relationship between n values can be represented by n-tuples i.e. a tuple of n values, which corresponds to a row in the table. • A relational schema contains the name of the relation and name of all columns or attributes. • In a relational schema, a domain is referred to by the domain name and has a set of associated values. 16 March 2021 5
- 6. contd.. • In the relational database system, the relational instance is represented by a finite set of tuples. Relational instances do not have duplicate tuples. • The degree is the number of attributes/columns in a table, whereas cardinality is the number of tuples/rows in a table. • In a relation, each row has one or more attributes that can identify the row in the relation uniquely. This is known as relational key. • NULL Values: The value which is not known or unavailable is called NULL value. It is represented by blank space. 16 March 2021 6
- 8. The Instructor Relation • The instructor relation is represented using the instructor table, which stores information about the instructors. • The instructor table has 4 column headers: ID, name, dept_name, and salary i.e. the table has 4 attributes. • Each row or tuple of this table records information about an instructor, consisting of the fields specified in the table. – t1 = <10101, Srinivasan, Comp. Sci., 65000> • The relational schema for the instructor table can be Instructor(ID char, name varchar2, dept_name varchar2, salary integer) • The instructor table has an attribute “ID” that can be considered as relational key as it uniquely identifies each tuple of the table. 16 March 2021 8
- 9. Keys in Relational Model • Keys play an important role in the relational database. • A key is a property of the relation, rather than of the tuple. • It is used to uniquely identify any record or row of data from the table. It is also used to establish and identify relationships between tables. • Usually, following types of keys exist in relational model 16 March 2021 9
- 10. Types of Key • A super key is a set of one or more attributes that allows us to uniquely identify a tuple in a relation i.e. table. • A candidate key is a minimal set of super key that cannot have any columns removed from it without losing the unique identification property. This property is sometimes known as minimality or (better) irreducibility. • All candidate key is super key but the reverse is not true. 16 March 2021 10
- 11. contd.. • Primary key is a candidate key that is chosen by the database designer as the principal means of identifying tuples in a table. – The primary key should be chosen such that its attributes are never or very rarely changed. • The remaining candidate keys, except the primary key, are called as Alternate keys. • If none of the columns is a candidate for the primary key in a table, sometimes database designers use an extra column as a primary key instead of using a composite key. Such key is known as the Surrogate key. • Foreign key is the set of attributes that is used to refer to another entity set having the primary key. – In ER diagram, foreign key can not be represented. Foreign Key is specifically for relational model. 16 March 2021 11
- 12. An Example 16 March 2021 12
- 13. contd.. • Super Key (SK) – For Example, the STUDENT table has a super key, SK as (STUD_NO, STUD_PHONE) • Candidate Key (CK) – For Example, STUD_NO, and STUD_PHONE in STUDENT relation. – There can be more than one candidate key in a relation. For Example, STUD_NO as well as STUD_PHONE both are candidate keys for relation STUDENT. – The candidate key can be simple (having only one attribute) or composite as well. • For Example, {STUD_NO, COURSE_NO} is a composite candidate key for relation STUDENT_COURSE. 16 March 2021 13
- 14. contd.. • Primary Key – For Example, STUD_NO as well as STUD_PHONE both are candidate keys for relation STUDENT but STUD_NO can be chosen as primary key. Why not STUD_PHONE??? • Alternate Key – For Example, STUD_NO as well as STUD_PHONE both are candidate keys for relation STUDENT and STUD_NO is selected as primary key. So, STUD_PHONE will be alternate key. • Foreign Key – For Example, STUD_NO in STUDENT_COURSE is a foreign key to STUD_NO in STUDENT relation. 16 March 2021 14
- 15. Relational Model Constraints • Operational Constraints are enforced in the database by the business rules or real world limitations. • Relational Data Integrity: Candidate key is an attribute or set of attributes that can uniquely identify a row or tuple in a table. – Let R be the relation with attributes a1, a2 ... an . The set of attributes of R is said to be a candidate key of R iff the following two properties holds: • Uniqueness: At any given time, no two distinct tuples or rows of R have the same value for ai , the same value for aj ...an • Minimality: No proper subset of the set (ai , aj ... an ) has the uniqueness property 16 March 2021 15
- 16. Integrity Constraints • Integrity constraints are a set of rules that is used to maintain the quality of information. • Integrity constraints ensure that the data insertion, updation, and other processes are performed in such a way that data integrity is not affected. • Thus, integrity constraint is used to guard against accidental damage to the database. 16 March 2021 16
- 17. contd.. • Domain Constraint – They can be defined as the definition of a valid set of values for an attribute. – The data type of domain includes string, character, integer, time, date, currency, etc. The value of the attribute must be available in the corresponding domain. 16 March 2021 17
- 18. contd.. • Entity Integrity Constraint – The entity integrity constraint states that primary key value can't be null. A table can contain a null value other than the primary key field. – This is because the primary key value is used to identify individual rows in relation and if the primary key has a null value, then we can't identify those rows. 16 March 2021 18
- 19. contd.. • Referential Integrity Constraint: A referential integrity constraint is specified between two tables. – In the Referential integrity constraints, if a foreign key in Table 1 refers to the Primary Key of Table 2, then every value of the Foreign Key in Table 1 must be null or be available in Table 2. – A foreign key which references its own relation is known as recursive foreign key. 16 March 2021 19
- 20. contd.. • Key constraints – Keys are the entity set that is used to identify an entity within its entity set uniquely. – An entity set can have multiple keys, but out of which one key will be the primary key. A primary key can contain a unique and null value in the relational table. 16 March 2021 20
- 21. Database Languages • Data Definition Language (DDL) – DDL is used to define the conceptual schema. – The output of the DDL is placed in the Data Dictionary that contains the metadata(data about data). – The data dictionary is considered to be a special type of table, which can only be accessed and updated by the database system itself. – The database system consults the data dictionary, before querying or modifying the actual data, for the validation purpose. – Commands: CREATE, ALTER, DROP, RENAME & TRUNCATE 16 March 2021 21
- 22. contd.. • DML (Data Manipulation Language) – DML is used to manipulate data in the database. – A query is a statement in the DML that requests the retrieval of data from the database. – Commands: SELECT, INSERT, UPDATE & DELETE • DCL (Data Control Languages) •DCL allows in changing the permissions on database structures •Commands: GRANT & REVOKE • TCL (Transaction Control Language) •TCL allows permanently recording the changes made to the rows stored in a table or undoing such changes •Commands: COMMIT, ROLLBACK & SAVEPOINT 16 March 2021 22
- 23. Characteristics of Relational Database • Relational database consists of multiple relations or tables. • The information about an enterprise is broken up into parts, with each relation storing one part of the information • The characteristics of relational database is expressed by Codd in the form of a set of rules that is widely known as CODD's Rules. • CODD's Rules – Rule 0: A relational system should be able to manage databases, entirely through its relational capabilities. 16 March 2021 23
- 24. contd.. – Rule 1: Information representation • The entire information is explicitly and logically represented by the data values of the tables in the relational data model. – Rule 2: Guaranteed access • In relational model, the interaction of each row and column will have one and only one value of data (or NULL value). • Each value of data must be addressable via the combination of a table name, primary key value and the column name. – Rule 3: Systematic treatment of NULL values • NULL values are supported in fully relational DBMS for to represent missing information and inapplicable information in a systematic way independent of data type. 16 March 2021 24
- 25. contd.. – Rule 4: Database description rule • The database description is represented at the logical level in the same way as ordinary data, so that authorized users can apply the same relational language to its interrogation as they apply to the regular data. • This means, the RDBMS must have a data dictionary. • Rule 5: Comprehensive data sub-language – The RDBMS should have its own extension of SQL. – The SQL should support Data Definition, View Definition, Data Manipulation, Integrity Constraint, and Authorization. • Rule 6: Views updation – All views that are theoretically updatable are also updatable by the system. Similarly, the views which are theoretically non- updatable are also non-updatable by the database system. 16 March 2021 25
- 26. contd.. • Rule 7: High-level update, insert, deletes – A RDBMS should not only support retrieval of data as relational sets, but also insertion, updation and deletion of data as a relational set. • Rule 8: Physical data independence – Application programs and terminal activities are not disturbed if any changes are made either to storage representations or access methods. • Rule 9: Logical data independence – User programs and the user should not be aware of any changes to the structure of the tables such as the addition of extra columns. 16 March 2021 26
- 27. contd.. • Rule 10: Distribution independence – RDBMS has distribution independence. The RDBMS may spread across more than one system and across several networks. However to the end-user, the tables should appear no different to those that are local. • Rule 11: Integrity Rules – Integrity rules must be supported by the database and the constraints must be stored within the catalogue, separate from the application. • Rule 12: Data integrity cannot be subverted – If a relational system has a low-level language, that low level cannot be used to subvert or bypass the integrity rules. 16 March 2021 27
- 28. Relational Database and its Schema • Relational database consists of multiple relations or tables. • The information about an enterprise is broken up into parts, with each relation storing one part of the information. • A relational schema contains the name of the relation and name of all columns or attributes. • For the complete database, it is known as relational database schema that is actually a collection of different schemas that refers to different relations or tables available in the database. 16 March 2021 28
- 29. contd.. • For example: A UNIVERSITY database can have a relational database schema as below: – student(ID, name, dept_name, tot_cred) – advisor(s_id,i_id) – teaches(ID, course_ID, sec_ID, semester, year) – takes(ID, course_ID,sec_ID,semester, year, grade) – section(course_ID, sec_ID, semester, year, building, room_no, time_slot_id) – timeslot(time_slot_id, day, start_time, end_time) – prereq(course_ID, prereq_ID) – classroom(building, room_number,capacity) – department(dept_name, building, budget) – instructor(ID, name, dept_name, salary) – course(course_ID, title,dept_name,credits) 16 March 2021 29
- 30. Relational Schema Diagram 16 March 2021 30
- 31. Conversion of ER Diagram to Relational Schema • A database that conforms to an ER diagram can be represented by a collection of relational schemas. • Both, the ER model and Relational data model are abstract i.e. logical representations of real-world enterprises. • Converting Strong entity types Each entity type becomes a table Each single-valued attribute becomes a column Derived attributes are ignored Composite attributes are represented by components Multi-valued attributes are represented by a separate table The key attribute of the entity type becomes the primary key of the table 16 March 2021 31
- 32. Converting Entity Types 16 March 2021 32
- 33. Converting weak entity types 16 March 2021 33
- 34. Converting Relationships • The way relationships are represented depends on the cardinality and the degree of the relationship. • The possible cardinalities are: 1:1, 1:N, N:1, M:N • The degrees are: Unary Binary Ternary … 16 March 2021 34
- 35. Binary 1:1 16 March 2021 35
- 36. contd.. 16 March 2021 36
- 37. Binary 1:N / N:1 16 March 2021 37
- 38. Binary M:N 16 March 2021 38
- 39. Unary 1:1 16 March 2021 39
- 40. Unary 1:N 16 March 2021 40
- 41. Unary M:N 16 March 2021 41
- 42. Ternary relationship 16 March 2021 42
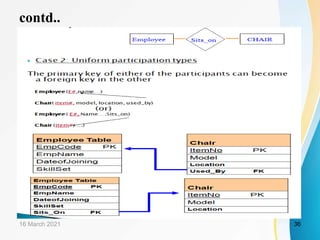
- 43. Case Study: Company Database • Problem Statement: The COMPANY database problem has been discussed in Ch-3: Data Modeling using ER Model. • The ER details of the Company Database is as below: – EMPLOYEE (Entity Type) • Attribute: Emp_name, Emp_ID, SSN, age, address, gender, salary, DOB, and supervisor – DEPARTMENT (Entity Type) • Attribute: Name, Number, Location, Manager, and Manager_start_date – PROJECT (Entity Type) • Attribute: Name, Number, Location, Controlling_dept – DEPENDENT (Entity Type) • Attribute: Name, gender, DOB, Employee, Relationship 16 March 2021 43
- 44. contd.. – MANAGES: • Binary and 1:1 Cardinality • Entity types: EMPLOYEE and DEPARTMENT • Participation: EMPLOYEE (Partial); DEPARTMENT (Total) – WORKS_FOR: • Binary and N:1 Cardinality • Entity types: EMPLOYEE and DEPARTMENT – CONTROLS: • Binary and 1:N Cardinality • Entity types: DEPARTMENT and PROJECT 16 March 2021 44
- 45. contd.. – SUPERVISION: • Unary and 1:N Cardinality • Entity types: EMPLOYEE – WORKS_ON: • Binary and M:N Cardinality • Entity types: EMPLOYEE and PROJECT – DEPENDENTS_OF: • Binary and 1:N Cardinality • Entity types: EMPLOYEE and DEPENDENT 16 March 2021 45
- 46. Case Study: Relational Schema • Employee(Emp_name, Emp_ID, SSN, address, gender, salary, DOB, supervisor, Dept_ID) • Department(Name, Dept_ID, Location, Manager, and Manager_start_date) • Project(Name, Proj_ID, Location, Controlling_dept) • Dependent(Name, gender, DOB, Relationship, Emp_ID) • Works_On(Emp_ID, Proj_ID, no_of_hrs, supervisor) Note: Attributes in “Red” are the FOREIGN KEY in that table 16 March 2021 46
- 47. Relational Schema Diagram 16 March 2021 47
- 48. Representation of Generalization/Specialization • In case of generalization/specialization-related ER diagram, one schema will be constructed for the generalized entity set and the schemas for each of the specialized entity sets • Person = (person_id, name, address) • Employee = (emp_id, salary) • Customer = (cust_id, credit_rating) 16 March 2021 48
- 49. contd.. • When the generalization/specialization is a disjointness case, the schemas are constructed only for the specialized entity sets – Employee = (employee_id, name, address, salary) – Customer = (customer_id, name, address, credit_rating) • Representation of Aggregation – To represent aggregation, create a schema containing the primary key of the aggregated relationship, primary key of the associated entity set and descriptive attributes (if any) 16 March 2021 49
- 50. contd.. •Employee = (eid, name, address) •Branch = (bid, bname, asset) •Job = (jobid, position, responsibility) • Works_on = (eid, bid, jobid) • Manager = (mid, mgrname) • Manages = (eid, bid, jobid, mid) 16 March 2021 50