



![Term Based Example 1: Cosine similarity
Term based Distances:
Let us consider two example sentences to calculate the term based text similarity
- Jenny loves burger more than Linda loves pizza
- Jane likes pizza more than Jenny loves burger
Cosine Similarity:
Words = [burger, jenny, loves, linda, than, more, likes, jane, pizza ]
If you take the word count , you will get a matrix like mentioned on right side.
Now calculating cosine similarity between a and b
a : [1,1,2,1,1,1,0,0,1]
b : [1,1,1,0,1,1,1,1,1]
The cosine of the angle between vectors is their similarity ,
cos α =
𝑎 . 𝑏
𝑎 ⋅ 𝑏
= dot product of vectors / Vectors magnitude
Cos α = 7 / 8.942 = 0.782 and cos dissimilarity = 1 – 0.782 = 0.217
Terms Seq 1 Seq 2
Burger 1 1
Jenny 1 1
Loves 2 1
Linda 1 0
Than 1 1
More 1 1
Likes 0 1
Jane 0 1
pizza 1 1](https://image.slidesharecdn.com/chatbotusingtextsimilarityapproach-180916155448/85/Chat-bot-using-text-similarity-approach-6-320.jpg)








































Ad
More Related Content
Similar to Chat bot using text similarity approach (20)
Recently uploaded (20)


















Ad
Chat bot using text similarity approach
- 1. Chat bot TEXT SIMILARITY DISTANCES
- 2. Introduction on Chat bot techniques There are two main technique involved in chat bot to understand the user input such as Pattern matching and Intent classification. Types of response: Static Response: The simplest way is to have a static response, with eventually a list of variants, for each user input. These static responses could be templates, such as “John is located in <Location details>”, where <Location details> is a variable computed by the chat bot. Dynamic Response: A different approach would be to use resources, such as a knowledge base, to get a list of potential responses, and then score them to choose the better response. This is particularly appropriate if the chat bot acts mainly like a question-answering system. Generated Response: If you have a huge corpus of examples of conversations, you could use a deep learning technique (Recurrent Neural Network) to train a generative model that, given an input, will generate the answer. You will need millions of examples to reach a decent quality and sometimes the results are going to be unexpected, but it could be interesting.
- 3. Introduction on Text Similarity 1. Words are similar in two ways lexically and semantically. 2. Words are similar lexically if they have a similar character sequence. 3. Words are similar semantically if they have the same thing, are opposite of each other, used in the same way , used in the same context. 4. Lexical similarity is introduced through String based algorithms and semantic similarity is introduced through Corpus based and Knowledge based algorithms. 5. String based measures operates on string sequences and character composition.
- 4. Text similarity approaches 1. Measuring the similarity between words, sentences, paragraphs and documents is an important component in various tasks such as information retrieval, document clustering, word-sense disambiguation, automatic essay scoring, short answer grading, machine translation, topic tracking, question generation, question answering and text summarization. 2. Text similarity is partitioned into three approaches Text similarity String based similarity Corpus based similarity Knowledge based similarity
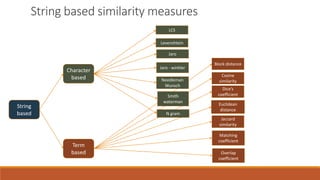
- 5. String based Character based Jaro LCS Levenshtein Jaro - winkler Smith waterman Needleman Wunsch N gram Term based Dice’s coefficient Block distance Cosine similarity Euclidean distance Matching coefficient Jaccard similarity Overlap coefficient String based similarity measures
- 6. Term Based Example 1: Cosine similarity Term based Distances: Let us consider two example sentences to calculate the term based text similarity - Jenny loves burger more than Linda loves pizza - Jane likes pizza more than Jenny loves burger Cosine Similarity: Words = [burger, jenny, loves, linda, than, more, likes, jane, pizza ] If you take the word count , you will get a matrix like mentioned on right side. Now calculating cosine similarity between a and b a : [1,1,2,1,1,1,0,0,1] b : [1,1,1,0,1,1,1,1,1] The cosine of the angle between vectors is their similarity , cos α = 𝑎 . 𝑏 𝑎 ⋅ 𝑏 = dot product of vectors / Vectors magnitude Cos α = 7 / 8.942 = 0.782 and cos dissimilarity = 1 – 0.782 = 0.217 Terms Seq 1 Seq 2 Burger 1 1 Jenny 1 1 Loves 2 1 Linda 1 0 Than 1 1 More 1 1 Likes 0 1 Jane 0 1 pizza 1 1
- 7. Term Based Example 2 : Jaccard Similarity Jaccard similarity : J(a , b) = a ∩ 𝑏/a ∪ 𝑏 a : { jenny, loves, burger, more, than, pizza, Linda} b : { jane, likes, pizza, more, than, burger, loves, jenny} a ∩ 𝑏 : { jenny, loves, burger, more, pizza, than} a ∪ 𝑏 : { burger, jenny, loves, linda, than, more, likes, jane, pizza } Jaccard similarity = 6 / 9 = 0.666 Removing stop words by parsing , Jaccard similarity = 5 / 8 = 0.625 and Jaccard dissimilarity = 1 - Jaccard similarity
- 8. Examples of Character based distance Hamming distance: It measures the minimum number of substitutions required to change one string into the other for a fixed length of strings. For example the hamming distance between , “Dinesh” - “Ramesh” = 3 and “John” – “Jack” = 3 Levenshtein Distance: For comparing strings of different lengths of strings where not just substitutions but also insertions or deletions have to be expected, then Levenshtein distance is appropriate. For example the Levenshtein distance between Artist and Artificial is 6 which is computed as follows ,
- 9. Corpus based ESA HAL LSA PMI-IR DISCO NGD Corpus based similarity measures GLSA CL-ESA SOC-PMI DISCO1 DISCO2
- 10. Corpus based similarity measures 1. Hyperspace Analogue to Language (HAL) creates a semantic space from word co-occurrences. A word-by-word matrix is formed with each matrix element is the strength of association between the word represented by the row and the word represented by the column. 2. Latent semantic Analysis (LSA) is the most popular technique of Corpus-Based similarity. LSA assumes that words that are close in meaning will occur in similar pieces of text. A matrix containing word counts per paragraph is constructed from a large piece of text and a mathematical technique which called singular value decomposition (SVD) is used to reduce the number of columns while preserving the similarity structure among rows. Generalized Latent Semantic Analysis (GLSA) is a framework for computing semantically motivated term and document vectors. It extends the LSA approach by focusing on term vectors instead of the dual document-term representation. 3. Explicit Semantic Analysis (ESA) is a measure used to compute the semantic relatedness between two arbitrary texts. The Cross-language explicit semantic analysis (CL-ESA) is a multilingual generalization of ESA. CL-ESA exploits a document-aligned multilingual reference collection such as Wikipedia to represent a document as a language independent concept vector.
- 11. Corpus based similarity measures 4. Pointwise Mutual Information – Information Retrieval (PMI-IR) is a method for computing the similarity between pairs of words, it uses AltaVista's Advanced Search query syntax to calculate probabilities. The more often two words co- occur near each other on a web page, the higher is their PMI-IR similarity score. Second-order co-occurrence pointwise mutual information (SCO-PMI) is a semantic similarity measure using pointwise mutual information to sort lists of important neighbor words of the two target words from a large corpus. The advantage of using SOC-PMI is that it can calculate the similarity between two words that do not co-occur frequently, because they co-occur with the same neighboring words. 5. Normalized Google Distance (NGD) is a semantic similarity measure derived from the number of hits returned by the Google search engine for a given set of keywords. NGD(x , y) = max{log f(x),log f(y)} – log f(x , y) / log M - min{log f(x),log f(y)} where M is the total number of web pages searched by Google; f(x) and f(y) are the number of hits for search terms x and y, respectively; and f(x, y) is the number of web pages on which both x and y occur. If the two search terms x and y never occur together on the same web page, but do occur separately, the normalized Google distance between them is infinite. If both terms always occur together, their NGD is zero, or equivalent to the coefficient between x squared and y squared.
- 12. Corpus based similarity measures 6. Extracting Distributionally similar words using Co-occurrences (DISCO) Distributional similarity between words assumes that words with similar meaning occur in similar context. Large text collections are statistically analyzed to get the distributional similarity. DISCO is a method that computes distributional similarity between words by using a simple context window of size ±3 words for counting co-occurrences. When two words are subjected for exact similarity DISCO simply retrieves their word vectors from the indexed data, and computes the similarity according to Lin measure . If the most Distributionally similar word is required; DISCO returns the second order word vector for the given word. DISCO has two main similarity measures DISCO1 and DISCO2; DISCO1 computes the first order similarity between two input words based on their collocation sets. DISCO2 computes the second order similarity between two input words based on their sets of Distributionally similar words
- 13. Knowledge based Similarity Relatedness Knowledge based similarity measures Information content Path length lesk vector hso res lin jcn lch wup path
- 14. Knowledge based similarity measures 1. Knowledge-Based Similarity is one of semantic similarity measures that bases on identifying the degree of similarity between words using information derived from semantic networks. 2. WordNet is the most popular semantic network in the area of measuring the Knowledge-Based similarity between words. 3. WordNet is a large lexical database of English. Nouns, verbs, adjectives and adverbs are grouped into sets of cognitive synonyms (synsets), each expressing a distinct concept. 4. Knowledge-based similarity measures can be divided roughly into two groups: measures of semantic similarity and measures of semantic relatedness. 5. Semantically similar concepts are deemed to be related on the basis of their likeness. Semantic relatedness, on the other hand, is a more general notion of relatedness, not specifically tied to the shape or form of the concept. 6. In other words, Semantic similarity is a kind of relatedness between two words, it covers a broader range of relationships between concepts that includes extra similarity relations such as is-a-kind-of, is-a-specific example-of, is-a-part-of, is-the-opposite-of.
- 15. Knowledge based similarity measures Resnik (res) measure is equal to the information content (IC) of the Least Common Subsumer (most informative subsumer). This means that the value will always be greater-than or equal-to zero. The upper bound on the value is generally quite large and varies depending upon the size of the corpus used to determine information content values. Lin and Jiang & conrath (lin and jcn ) measures augment the information content of the Least Common Subsumer with the sum of the information content of concepts. The lin measure scales the information content of the Least Common Subsumer by this sum, while jcn takes the difference of this sum and the information content of the Least Common Subsumer. (Leacock & Chodorow) lch measure returns a score denoting how similar two word senses are, based on the shortest path that connects the senses and the maximum depth of the taxonomy in which the senses occur. Wu & Palmer (wup) measure returns a score denoting how similar two word senses are, based on the depth of the two senses in the taxonomy and that of their Least Common Subsumer. Path measure returns a score denoting how similar two word senses are, based on the shortest path that connects the senses in the is-a (hypernym/ hyponym ) taxonomy.
- 16. Knowledge based similarity measures St.Onge (hso) measure works by finding lexical chains linking the two word senses. There are three classes of relations that are considered: extra-strong, strong, and medium-strong. The maximum relatedness score is 16. Lesk (lesk) measure works by finding overlaps in the glosses of the two synsets. The relatedness score is the sum of the squares of the overlap lengths. Vector pairs (vector) measure creates a co–occurrence matrix for each word used in the WordNet glosses from a given corpus, and then represents each gloss/concept with a vector that is the average of these co–occurrence vectors. The most popular packages that cover knowledge-based similarity measures are WordNet::Similarity and Natural Language Toolkit (NLTK).