




![But what to do? Compression, Chunks, and Open Source!
6
■ The key ideas to enable the efficient storage of billion data objects:
■Split time series into chunks of the same size with data objects
■Compress these chunks to reduce the data volume
■Store the compressed chunks and the attributes in a record
■ Reason for success:
■32 GB disk usage to store 68 billion data objects
■Fast retrieval of data objects within a few milliseconds
■Fast searching on attributes without loading the chunks
■Everything runs on a laptop computer
■… and many more!
Time Series Record
Start
End
Chunk[]
Size
Attributes, …
1 Million
!68.000!](https://image.slidesharecdn.com/odsc-chronix-afastandefficienttimeseriesstoragebasedonapachesolr-170312134034/85/Chronix-A-fast-and-efficient-time-series-storage-based-on-Apache-Solr-6-320.jpg)





















Chronix: A fast and efficient time series storage based on Apache Solr
- 1. Chronix A fast and efficient time series storage based on Apache Solr Caution: Contains technical content.
- 3. 68.000.000.000* time correlated data objects. 3 * ~ collect every 10 seconds 72 metrics x 15 processes x 20 hosts over 1 years How to store such amount of data on your laptop computer and retrieve any point within a few milliseconds?
- 4. Well we tried that approach… 4 ■ Store data objects in a classical RDBMS ■ But… ■Slow import of data objects ■Huge amount of hard drive space ■Slow retrieval of time series ■Limited scalability due to RDBMS ■Missing query functions for time series data !68.000.000.000! Measurement Series Name Start End Time Series Start End Data Object Timestamp Value Metric Attributes Host Process … * * * * Name
- 5. 5 Hence it felt like … Image Credit: http://www.sail-world.com/
- 6. But what to do? Compression, Chunks, and Open Source! 6 ■ The key ideas to enable the efficient storage of billion data objects: ■Split time series into chunks of the same size with data objects ■Compress these chunks to reduce the data volume ■Store the compressed chunks and the attributes in a record ■ Reason for success: ■32 GB disk usage to store 68 billion data objects ■Fast retrieval of data objects within a few milliseconds ■Fast searching on attributes without loading the chunks ■Everything runs on a laptop computer ■… and many more! Time Series Record Start End Chunk[] Size Attributes, … 1 Million !68.000!
- 7. That‘s all. No secrets, nothing special and nothing more to say. Time Series Database - What’s that? Definitions and typical features. Why did we choose Apache Solr and are there alternatives? Chronix Architecture that is based on Solr and Lucene. What’s needed to speed up Chronix to a firehorse. What comes next?
- 8. Time Series Database: What’s that? 8 ■ Definition 1: “A data object d is a tuple of {timestamp, value}, where the value could be any kind of object.” ■ Definition 2: “A time series T is an arbitrary list of chronological ordered data objects of one value type”. ■ Definition 3: “A chunk C is a chronological ordered part of a time series.” ■ Definition 4: “A time series database TSDB is a specialized database for storing and retrieving time series in an efficient and optimized way”. d {t,v} 1 T {d1,d2} T CT T1 C1,1 C1,2 TSDB T3C2,2 T1 C2,1
- 9. A few typical features of a time series database 9 ■ Data management ■Round Robin Storages ■Down-sample old time series ■Compression ■Compaction ■ Arbitrary amount of Attributes ■For time series (Country, Host, Customer, …) ■For data object (Scale, Unit, Type) ■ Performance and Operational ■Rare updates, inserts are additive ■Fast inserts and retrievals ■Distributed and efficient per node ■No need of ACID, but consistency ■ Time series language and API ■Statistics: Aggregation (min, max, median), … ■Transformations: Time windows, time shifting, resampling, .. ■High level: Outlier, trends, similarity search Check out: A good post about the requirements of a time series: http://www.xaprb.com/blog/2014/06/08/time-series-database-requirements/
- 10. 10 Some time series databases out there. ■RRDTool - http://oss.oetiker.ch/rrdtool/ ■Mainly used in traditional monitoring systems ■Graphite – https://github.com/graphite-project ■Uses the concepts of RRDTool and puts some sugar on it ■InfluxDB - https://influxdata.com/time-series-platform/influxdb/ ■A distributed time series database with a very handy query language ■OpenTSDB - http://opentsdb.net/ ■Is a scalable time series database and runs on Hadoop and Hbase ■Prometheus- http://www.scidb.org/ ■ A monitoring system and a time series database ■KairosDB - https://kairosdb.github.io/ ■Like OpenTSDB but is based on Apache Cassandra ■… many more! And of course Chronix! - http://chronix.io/
- 11. “Ey, there are so many time series databases out there? Why did you create a new solution?” 11 Our Requirements ■ A fast write and query performance ■ Run the database on a laptop computer ■ Minimal data volume for stored data objects ■ Storing arbitrary attributes ■ A query API for searching on all attributes ■ Large community and an active development That delivers Apache Solr ■ Based on Lucene which is really fast ■ Runs embedded, standalone, distributed ■ Lucene has a built-in compression ■ Schema or schemaless ■ Solr Query Language ■ Lucidworks and an Apache project “Our tool has been around for a good few years, and in the beginning there was no time series database that complies our requirements. And there isn’t one today!”Elastic Search is an alternative. It is also based on Lucene.
- 12. 12 Let‘s dig deeper into Chronix’ internals. Image Credit: http://www.taringa.net/posts/ciencia-educacion/12656540/La-Filosofia-del-Dr-House-2.html
- 13. Chronix’ architecture enables both efficient storage of time series and millisecond range queries. 13 (1) Semantic Compression (2) Attributes and Chunks (3) Basic Compression (4) Multi-Dimensional Storage Record data:<chunk> attributes Record data:compressed <chunk> attributes Record Storage 1 Million Points 100 Chunks * 10.000 Points ~ 96% Compression Optional
- 14. The key data type of Chronix is called a record. It stores a compressed time series chunk and its attributes. 14 record{ data:compressed{<chunk>} //technical fields id: 3dce1de0−...−93fb2e806d19 version: 1501692859622883300 start: 1427457011238 end: 1427471159292 //optional attributes host: prodI5 process: scheduler group: jmx metric: heapMemory.Usage.Used max: 896.571 } Data:compressed{<chunk of time series data>} ■ Time Series: timestamp, numeric value ■ Traces: calls, exceptions, … ■ Logs: access, method runtimes ■ Complex data: models, test coverage, anything else… Optional attributes ■ Arbitrary attributes for the time series ■ Attributes are indexed ■ Make the chunk searchable ■ Can contain pre-calculated values
- 15. Chronix provides specialized aggregations and analyses in its query language for time series that are commonly used. 15 Aggregations (ag) ■ Min / Max / Average / Sum / Count ■ Standard Deviation ■ Percentile ■ Bottom/Top n-values ■ First / Last ■ Derivative / Non negative derivative ■ Range ■ Moving average ■ Divide / Scale ■ ... Analyses (analysis) ■ Trend Analysis Using a linear regression model ■ Outlier Analysis Using the IQR ■ Frequency Analysis Check occurrence within a time range ■ Fast Dynamic Time Warping Time series similarity search ■ Symbolic Aggregate Approximation Similarity and pattern search ■ Vectorisation for server side data reduction
- 16. Only scalar values? One size fits all? No! What about logs, traces, and others? No problem – Just do it yourself! 16 ■ Chronix Kassiopeia (Format) ■Time Series framework that is used by Chronix. ■Time Series Types: ■Numeric: Doubles (the time series known to be the default) ■Thread Dumps: Stack traces (e.g. java stack traces) ■Strace: Strace dumps (system call, duration, arguments public interface TimeSeriesConverter<T> { /** * Shall create an object of type T from the given binary time series. */ T from(BinaryTimeSeries binaryTimeSeriesChunk, long queryStart, long queryEnd); /** * Shall do the conversation of the custom time series T into the binary time series that is stored. */ BinaryTimeSeries to(T timeSeriesChunk); }
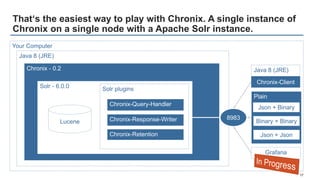
- 17. Plain That‘s the easiest way to play with Chronix. A single instance of Chronix on a single node with a Apache Solr instance. 17 Java 8 (JRE) Chronix - 0.2 Solr - 6.0.0 Lucene Solr plugins 8983 Your Computer Chronix-Query-Handler Chronix-Response-Writer Chronix-Retention Chronix-Client Grafana Json + Binary Binary + Binary Json + Json Java 8 (JRE)
- 18. Code-Slide: How to set up Chronix, ask for time series data, and call some server-side aggregations. 18 ■ Create a connection to Solr and set up Chronix ■ Define and range query and stream its results ■ Call some aggregations solr = new HttpSolrClient("http://localhost:8913/solr/chronix/") chronix = new ChronixClient(new KassiopeiaSimpleConverter<>(), new ChronixSolrStorage(200, groupBy, reduce)) query = new SolrQuery("metric:*Load*") chronix.stream(solr,query) query.addFilterQuery("ag=max,min,count,sdiff") stream = chronix.stream(solr,query) Signed Difference: First=20, Last=-100 -80 Group chunks on a combination of attributes and reduce them to a time series. Get all time series whose metric contains Load
- 19. That’s the four week data that is shipped with the release!
- 20. A more powerful way to work with time series. A Chronix Cloud, a Spark Cluster, and an analysis workbench like Zeppelin. 20 Chronix Cloud Chronix Node Chronix Node Chronix Node Chronix Node Spark Cluster Spark Node Spark Node Spark Node Spark Node Zeppelin Chronix Spark Context Java Scala Various Applications as Workbench Spark SQL Context
- 21. Code-Slide: Use Spark to process time series data that comes out right now from Chronix. 21 ■ Create a ChronixSparkContext ■ Define and range query and stream its results ■ Play with the data conf = new SparkConf().setMaster(SPARK_MASTER).setAppName(CHRONIX) jsc = new JavaSparkContext(conf) csc = new ChronixSparkContext(jsc) sqlc = new SQLContext(jsc) query = new SolrQuery("metric:*Load*") rdd = csc.queryChronixChunks(query,ZK_HOST,CHRONIX_COLLECTION, new ChronixSolrCloudStorage()); DataSet<MetricObservation> ds = rdd.toObservationsDataset(sqlc) rdd.mean() rdd.max() rdd.iterator() Dataset to use Spark SQL features Set up Spark, a JavaSparkContext, a ChronixSparkContext, and a SQLContext Get all time series whose metric contains Load
- 22. Tune Chronix to a firehorse. Even with defaults it’s blazing fast!
- 23. We have tuned Chronix in terms of chunk size, and compression technique to get the ideal default values for you. 23 ■ Tuning Dataset ■Three real-world projects ■15 GB of time series data (typical monitoring data) ■About 500 million points in 15k time series ■92 typical queries with different time range and occurrence ■ We have measured: ■Compression rate for serval compression techniques (T) and chunk sizes (C). ■Total time for all 92 queries in the mix (range + aggregations) ■ What we want to know: Ideal values for T and C
- 24. We have evaluated several compression techniques and chunk sizes of the time series data to get the best parameter values. 24 T= GZIP + C = 128 kBytes Florian Lautenschlager, Michael Philippsen, Andreas Kumlehn, Josef Adersberger Chronix: Efficient Storage and Query of Operational Time Series International Conference on Software Maintenance and Evolution 2016 (submitted) For more details about the tuning check our paper.
- 25. Compared to other time series databases Chronix‘ results for our use case are outstanding. The approach works! 25 ■ We have evaluated Chronix with: ■InfluxDB, Graphite, OpenTSDB, and KairosDB ■All databases are configured to run as single node ■ Storage demand for 15 GB of raw csv time series data ■Chronix (237 MB) takes 4 – 84 times less space ■ Query times on imported data ■49% – 91% faster than the evaluated time series databases ■ Memory footprint: after start, max during import, max during query mix ■Graphite is best (926 MB), Chronix (1.5 GB) is second. Others 16 to 39 GB
- 26. The hard facts. For more details I suggest you to read our research paper about Chronix. 26 Florian Lautenschlager, Michael Philippsen, Andreas Kumlehn, Josef Adersberger Chronix: Efficient Storage and Query of Operational Time Series International Conference on Software Maintenance and Evolution 2016 (submitted)
- 27. Now it’s your turn. Now it’s your turn.
- 28. Open the shell and type. 28
- 29. (mail) [email protected] (twitter) @flolaut (twitter) @ChronixDB (web) www.chronix.io #lovetimeseries Bart Simpson