















![18
[백업] Snowflake 자원 할당 기준
Snowflake 기준으로 시간당 비용 기준 설정 (Tokyo Region/Standard 요금제 기준)
- Snowflake의 경우는 인프라 스펙은 공개하지 않으며, 클러스터 사이즈/비용만 공개 -
시간당 2.8$ ~ 최대 364$까지 존재
데이터 량 및 원하는 조회 성능(속도)에 따라
Virtual Warehouse(WH) 선택하여 실행
Snowflake에서 제공하는
Virtual Warehouse유형
수초 이내로 생성됨](https://image.slidesharecdn.com/clouddwbenchmarkv1-220223000510/85/Cloud-dw-benchmark-using-tpd-ds-Snowflake-vs-Redshift-vs-EMR-Hive-18-320.jpg)
![19
[백업] AWS Redshift 자원 할당 기준 (Tokyo Region)
2가지 Type(DC2, RA3)으로 진행하며, Snowflake 기준으로 동일한 가격의 자원 할당
- 가장 최신 type은 RA3이며, Aurora 옵션은 미 적용(리소스에 따라 enable이 불가능한 경우가 많음) -
Type이 세분화되어 있지 않아서,
비용 증가 폭이 크다. (약 5배 증가)
(즉, 애매한 용량의 경우 비용 과다 지출 가능)
처리 성능 중심의 Test이므로,
저장공간 중심의 Type인 DS2는 제외](https://image.slidesharecdn.com/clouddwbenchmarkv1-220223000510/85/Cloud-dw-benchmark-using-tpd-ds-Snowflake-vs-Redshift-vs-EMR-Hive-19-320.jpg)
![20
[백업] AWS EMR 자원 할당 기준 (Tokyo Region)
EMR은 ec2 Instance를 선택하는 방식이라, 약 150개 유형에서 임의로 선택](https://image.slidesharecdn.com/clouddwbenchmarkv1-220223000510/85/Cloud-dw-benchmark-using-tpd-ds-Snowflake-vs-Redshift-vs-EMR-Hive-20-320.jpg)
![21
테스트 조건 >> 테스트 데이터 (TPC-DS)
기존 TPC-H 대비 Data Warehouse 용으로 많이 사용되는 TPC-DS 선택
- 분석가들이 많이 사용하는 복잡한 Ad-hoc/olap query, reporting 등의 다양한 query(99개) 지원 -
TPC-DS Schema [ 데이터 size 별 Table record 건수]
• 정규화된 테이블 구조를 가지며,
• DW에서 많이 사용하는 star schema로 구성되어,
• 기업의 환경과 유사한 테스트가 가능하다.
• 1TB의 경우 최대 2백 80만 건의 record가 생성됨 (store_sales table)](https://image.slidesharecdn.com/clouddwbenchmarkv1-220223000510/85/Cloud-dw-benchmark-using-tpd-ds-Snowflake-vs-Redshift-vs-EMR-Hive-21-320.jpg)
























Cloud dw benchmark using tpd-ds( Snowflake vs Redshift vs EMR Hive )
- 1. Cloud DW 트렌드 및 성능 비교 ( Snowflake vs AWS Redshift vs AWS EMR ) Performance & Cost Test 2021.07 freepsw
- 2. 2 왜 기업들은 Cloud DW에 주목하는가? Cloud DW 솔루션의 성능은? 기존 Data Lake(EMR) 대비 성능은? 유사 Cloud DW(snowflake vs redshift) 대비 성능은? 시장에는 어떤 제품들이 있는가? 우리 Biz 환경에서는 어떤 제품을 도입해야 하는가?
- 3. 3 Cloud DW ? 왜 많은 기업들에게 주목 받고 있을까?
- 4. 4 왜 기업들은 Cloud DW에 주목할까? 정부 정책 변화 데이터 3법 (2020.01 시행) 빅데이터 센터 (16개소) AI/Data 산업 활성화 데이터 개방은 가속화되며, 기업은 더 많은 데이터를 분석하고자 함 더 많은 데이터를 기업의 데이터 이슈 Data Silo 현상 기존 DW의 한계 운영/투자 비용 증가 통합 관리할 수 있는 Data 아키텍처 진화 ETL à ELT 로 진화 Cloud DW 등장 Data Mesh 아키텍처 데이터 기술 필요
- 5. 5 기업의 데이터 이슈 – Data Silo Data Lake 도입에도 Data Silo 발생 è 데이터 적시 활용 어려움 Data Silos 발생 DW Silo Hadoop Silo 과도한 ETL 작업 실행 (ETL 제품 종속) 동적인 컴퓨팅 자원 할당 어려움 (수많은 배치 스케줄) 분석가가 원하는 데이터를 적시에 확보하기 어려움 또 다른 Data Silo 발생 또 다른 Data Silo 발생 ETL을 통해 생성된 Data Silo 발생 https://databricks.com/glossary/data-lakehouse
- 6. 6 Data 아키텍처의 변화 – ELT 분석가가 필요한 데이터를 원하는 방식으로 변환 및 조회 가능한 ELT 도입 증가 https://blog.naver.com/freepsw/222276087707
- 7. 7 Cloud DW & Lakehouse 제품 등장 모든 데이터를 저장하고, 목적에 따라 DW를 구성하여, 최소화된 운영비로 원하는 성능 제공 Data Warehouse (On-prem) Data Lake Cloud DW Lake House • 정형 데이터 중심 • 저장 공간 및 컴퓨팅 성능 한계 Cloud 스토리지로 저장용량 한계 극복 필요시 DW 즉시 생성 (처리 성능 개선) Manage Service로 운영 부담 제거 • 정형 + 반정형 중심 • Snowflake, Redshift, BigQuery 등 • 신규 제품 지속 출시 및 시장 점유율 증가 • 정형 + 반정형 + 비정형 지원 • 정형 데이터에 최적화된 조회 성능 한계 (ETL을 통해 DW로 데이터 적재 후 조회) • 복잡한 Data Engineering 필요 Cloud 스토리지로 저장용량 한계 극복 필요시 DW 즉시 생성 (처리 성능 개선) Manage Service로 운영 부담 제거 정형 데이터 중심의 Data Lake 고객의 전환 수요 증가 (EMR à Snowflake/Redshift) • 정형 + 반정형 + 비정형 지원 • 복잡한 ETL 없이 빠르게 데이터 조회 (Data Silo 제거) • Delta Lake (Data Bricks)
- 8. 8 https://interworks.com/blog/sparker/2018/03/08/introducing-snowflake-cloud-based-data-warehousing/ Cloud DW 란? Cloud의 동적 자원(컴퓨팅 & 스토리지)를 활용하여 사용자에게 동적인 DW환경을 제공 (성능 개선, 운영 부담 감소, 비용 절감 효과) Snowflake의 서비스 개념 (많은 제품이 유사한 기능 제공)
- 9. 9 Cloud DW는 구체적으로 어떤 기능을 제공하는가? Cloud의 장점을 기반으로 DW의 성능/안정성/비용 최적화 Data integration Data storage Performance Management Security & compliance - 배치/실시간 등 대용량 데이터 유입 - - 정형/반정형 데이터 지원 - - 클라우드 스토리지 장점 활용 - - 칼럼 기반 스토리지 지원 - - 스토리지와 컴퓨팅 노드 분리 - - 동적 scale out 지원 - - 캐싱/분산(MPP) 처리 지원 - - 인증/암호화/접근제어 - - 다양한 법적 규제 지원 - - 빠른 DW 환경 구성- - 데이터 백업 및 복구 용이 - - 운영 비용 감소 -
- 10. 10 시장에는 어떤 Cloud DW 제품들이 있을까 ? On-Prem DW Managed Cloud DW Cloud DW Cloud Data Lake Cloud based Self-DW Public Cloud DW 인프라 및 운영 비용 해결 빠른 성능과 운영 복잡성 감소 Cloud 사업자 제공 서비스 • Oracle Exadata • Teradata • IBM Netezza, • Oracle Exadata • EMC Greenplum Data C omputing Appliance • SAP Sybase IQ • HP Vertica • AWS EMR • GCP Dataproc • Azure HDInsight • Cloudera CDP • AWS Redshift • GCP BigQuery • Azure Synaps DW 전문 기업의 Cloud기반 서비스 • Snowflake • GCP BigQuery omni • Teradata Vantage Data Mart Cloud Infra에 직접 DW 구축 • Vertica • Greenplum • IBM DB2 기존 DW/DataMart 영역과 Data Lake영역을 포함하여 시장을 확장 중 Cloud 사업자 종속 Multi-Cloud 지원 Multi-Cloud + Hybrid Cloud 제품 종속 제거 운영 편의성 DeltaLake (Databricks) Snowflake Firebolt
- 11. 11 시장에는 어떤 Cloud DW 제품들이 있을까 ? On-Prem DW Managed Cloud DW Cloud DW Cloud Data Lake Cloud based Self-DW Public Cloud DW 인프라 및 운영 비용 해결 빠른 성능과 운영 복잡성 감소 Cloud 사업자 제공 서비스 • Oracle Exadata • Teradata • IBM Netezza, • Oracle Exadata • EMC Greenplum Data C omputing Appliance • SAP Sybase IQ • HP Vertica • AWS EMR • GCP Dataproc • Azure HDInsight • Cloudera CDP • AWS Redshift • GCP BigQuery • Azure Synaps DW 전문 기업의 Cloud기반 서비스 • Snowflake • GCP BigQuery omni • Teradata Vantage Data Mart Cloud Infra에 직접 DW 구축 • Vertica • Greenplum • IBM DB2 기존 DW/DataMart 영역과 Data Lake영역을 포함하여 시장을 확장 중 Cloud 사업자 종속 Multi-Cloud 지원 Multi-Cloud + Hybrid Cloud 제품 종속 제거 운영 편의성 Databricks Snowflake Firebolt 기업의 상황에 맞는 최적 제품을 찾아야 함.
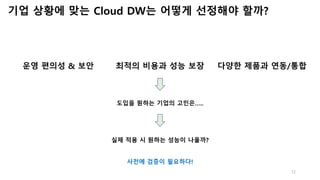
- 12. 12 기업 상황에 맞는 Cloud DW는 어떻게 선정해야 할까? 운영 편의성 & 보안 최적의 비용과 성능 보장 다양한 제품과 연동/통합 도입을 원하는 기업의 고민은….. 실제 적용 시 원하는 성능이 나올까? 사전에 검증이 필요하다!
- 13. 13 Cloud DW의 성능을 어떻게 검증할 것인가? 다양한 기업 환경에 맞는 성능(Benchmark) 결과를 찾기는 어렵다.
- 14. 14 Cloud DW의 성능을 비교해 보자 !
- 15. 15 테스트 제약 조건 동일한 조건에서 성능을 비교할 수 있도록 테스트 자원 설정 표준 데이터 사용 성능/비용 측정 동일한 자원 할당 가장 범용적으로 활용하는 TPC-DS 데이터 생성 50G, 200G, 1000G(1TB) 활용 각 제품에 맞게 데이터 적재 Snowflakes는 자원 스펙을 공개하지 않음 따라서, Snowflake 기준으로 동일한 비용의 자원 할당 (AWS는 Instance 유형 및 노드 개수 조정) (+- 0.24 $ / Hour 오차 있음) DW 생성 시간 (얼마나 빨리 DW를 생성하는가?) 처리 성능 (데이터 로딩 시간 + 쿼리 시간) 소요 비용 (DW 생성 후 쿼리 완료까지 소요된 비용) “ 시간당 동일한 비용의 자원 할당” “ 빅데이터 용 TPC-DS 데이터 활용 ” ” 처리 성능 및 소요 비용 비교 ”
- 16. 16 상세 테스트 환경 설정 AWS Tokyo Region에서 테스트 수행 구분 설명 고려 사항 테스트 대상 Snowflake AWS Redshift AWS EMR - 6.2.0 (Hive) Redshift ra3 type에 Aqua 적용하지 않음 테스트 데이터 TPC-DS Benchmark 데이터 50G, 200G, 1,000G (1TB) 데이터 사용 데이터 포맷 Snowflake와 Redshift는 자체 최적화 포맷 (csv import) EMR은 parquet 포맷 사용 Snowflake/Redshift : gzip으로 압축된 csv 파일 로딩 EMR : parquet 포맷으로 변화하여 S3에 저장 (동일 region) 비용 기준 (DW 서버 스펙) Snowflake (Standard Type, Tokyo region) 비용을 기준 (2021.7월 기준) (Snowflake는 서버 스펙 공개하지 않음) X-Small : 2.8$ Medium : 11.4$ (x-small 대비 4 배) Large : 22.8$ (x-small 대비 8 배) Query 성능 측정 TPC-DS에서 제공하는 99개 Query 실행 (순차적으로 실행하여 전체 쿼리 실행시간 비교) 소요 비용 측정 Cloud DW 서비스(자원)을 사용한 총 비용 DW 생성 à 데이터 로딩 à 성능 측정 à 종료까지 사용된 총 비용
- 17. 17 테스트 조건 >> 동일한 자원 할당 ( Snowflake 기준) Snowflake 기준으로 동일한 시간당 비용의 자원 할당 (AWS Tokyo Region) - 본 테스트에서는 ”X-Small, Medium, Large” 기준으로 각 제품별 Type 선택 - Snowflake와 동일한 비용의 AWS Type 으로 선별
- 18. 18 [백업] Snowflake 자원 할당 기준 Snowflake 기준으로 시간당 비용 기준 설정 (Tokyo Region/Standard 요금제 기준) - Snowflake의 경우는 인프라 스펙은 공개하지 않으며, 클러스터 사이즈/비용만 공개 - 시간당 2.8$ ~ 최대 364$까지 존재 데이터 량 및 원하는 조회 성능(속도)에 따라 Virtual Warehouse(WH) 선택하여 실행 Snowflake에서 제공하는 Virtual Warehouse유형 수초 이내로 생성됨
- 19. 19 [백업] AWS Redshift 자원 할당 기준 (Tokyo Region) 2가지 Type(DC2, RA3)으로 진행하며, Snowflake 기준으로 동일한 가격의 자원 할당 - 가장 최신 type은 RA3이며, Aurora 옵션은 미 적용(리소스에 따라 enable이 불가능한 경우가 많음) - Type이 세분화되어 있지 않아서, 비용 증가 폭이 크다. (약 5배 증가) (즉, 애매한 용량의 경우 비용 과다 지출 가능) 처리 성능 중심의 Test이므로, 저장공간 중심의 Type인 DS2는 제외
- 20. 20 [백업] AWS EMR 자원 할당 기준 (Tokyo Region) EMR은 ec2 Instance를 선택하는 방식이라, 약 150개 유형에서 임의로 선택
- 21. 21 테스트 조건 >> 테스트 데이터 (TPC-DS) 기존 TPC-H 대비 Data Warehouse 용으로 많이 사용되는 TPC-DS 선택 - 분석가들이 많이 사용하는 복잡한 Ad-hoc/olap query, reporting 등의 다양한 query(99개) 지원 - TPC-DS Schema [ 데이터 size 별 Table record 건수] • 정규화된 테이블 구조를 가지며, • DW에서 많이 사용하는 star schema로 구성되어, • 기업의 환경과 유사한 테스트가 가능하다. • 1TB의 경우 최대 2백 80만 건의 record가 생성됨 (store_sales table)
- 22. 22 테스트 환경 및 구성도 AWS 인프라를 이용하여 Test client와 대상 서비스(snowflake, redshift, emr)를 검증한다. - EMR을 제외하고, 나머지 DW 제품들은 데이터를 import하면서 자체 최적화된 포맷으로 저장 (성능 향상) - AWS Tokyo Region (동일 region에서 진행) Data Generator (TPC-DS) 1) 데이터 생성 후 S3 Upload Data Loader 2) S3 Data 적재 (DB 생성 후 Import) 2) Table 생성 Execute Query 3) TPC-DS에서 제공하는 99개 Query 실행 후 성능 기록 ( Parquet format ) ( 자체 최적 format ) ( 자체 최적 format ) ( TPC-DS Query : https://github.com/Agirish/tpcds )
- 23. 23 테스트 케이스 (다양한 관점 별 성능 측정) Data Size > DW Size > DW Type 별로 구분하여 총 30개의 Test Case 실행 50G는 제품의 다양한 Spec을 추가하여 성능 확인
- 24. 24 Cloud DW의 성능 테스트 결과는?
- 25. 25 50G TPC-DS Data 기준
- 26. 테스트 결과 (50G) – Query 실행 속도 (Snowflake) 모든 가격대(XS, Medium, Large)에서 Snowflake가 가장 빠른 성능을 제공한다. - Medium 사이즈는 X-Small 대비 약 30% 성능 개선 - Large Size가 성능 개선 효과가 매우 높음 (X-Small 대비 2배 빠른 성능) Time (Minute)
- 27. 테스트 결과 (50G) – Query 실행 속도 (AWS Redshift) 50G에서는 Instance node 수의 증가가 성능 향상에 영향이 낮음 - 데이터가 많지 않을 경우, 고가의 장비(또는 노드 증가)는 성능에 영향이 낮음 - Ra3.4xlarge type의 3개 node에서 가장 높은 성능 (X-Small 대비 2배) Node를 6개로 증가했으나, 쿼리 소요시간은 더 오래 걸림 Time (Minute) 작은 데이터는 dc2 type이 성능 측면에서 효율적
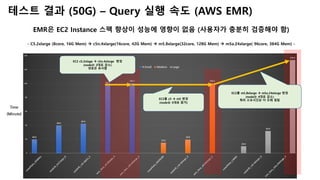
- 28. 테스트 결과 (50G) – Query 실행 속도 (AWS EMR) EMR은 EC2 Instance 스펙 향상이 성능에 영향이 없음 (사용자가 충분히 검증해야 함) - C5.2xlarge (8core, 16G Mem) à c5n.4xlarge(16core, 42G Mem) à m5.8xlarge(32core, 128G Mem) à m5a.24xlarge( 96core, 384G Mem) - EC2를 c5 à m5 변경 (node는 5대로 증가) EC2를 m5.8xlarge à m5a.24xlarge 변경 (node는 4대로 감소) 쿼리 소요시간은 더 오래 걸림 EC2 c5.2xlage à c5n.4xlarge 변경 (node는 2대로 감소) 성능은 유사함 Time (Minute)
- 29. 테스트 결과 (50G) – 비용 대비 성능 비교 작은 데이터(50G)에서는 모든 사이즈(X-small, Medium, Large)에서 Snowflake가 가장 효율적 - 또한 비용을 증가(DW 사이즈 향상)했을 때, 성능 개선효과도 가장 높음 - Snowflake가 비용 대비 가장 효율적 60% 낮은 비용으로, 2배 빠른 성능 Time (Minute) Cost (달러, $) Snowflake가 Redshift 대비 3배 낮은 비용으로, 3배 빠른 성능 Snowflake가 Redshift 대비 35% 낮은 비용으로, 30% 빠른 성능
- 30. 30 200G TPC-DS Data 기준
- 31. 테스트 결과 (200G) – Query 실행 속도 (Snowflake) Medium과 Large에서 빠른 성능을 제공 (200G 이상은 X-small 사용시 성능 한계) - Medium 에서 성능 개선 효과가 가장 높음 (3배 빠른 성능 제공) - Time (Minute) Medium 대비 성능 개선 효과가 높지 않음 (약 1.5배 빠른 성능) 성능 개선효과가 가장 높음 (X-Small 대비 3배) 200G에서는 Snowflake X-Small이 Redshift와 유사하거나, 성능이 떨어짐
- 32. 테스트 결과 (200G) – Query 실행 속도 (AWS Redshift) X-Small size에서는 Redshift(dc2 type)이 가장 빠른 성능 제공 - 200G는 dc2 type에 노드를 확장하는 것이 효과적으로 보임 - Time (Minute) Ra3.4xlarge로 업그레이드 시 2배 이상 성능 개선 DC2 type 성능이 가장 높음 (Node가 8대라 분산 효과?)
- 33. 테스트 결과 (200G) – Query 실행 속도 (AWS EMR) Time (Minute) 32core, 128G 서버를 5 node로 구성 시 성능개선 EMR은 EC2 Instance 스펙 향상이 성능에 영향이 없음 (사용자가 충분히 검증해야 함) - C5.2xlarge (8core, 16G Mem) à m5.8xlarge(32core, 128G Mem) à m5a.24xlarge( 96core, 384G Mem) - 고 성능 장비는 오히려 성능 저하 (이 부분은 좀 더 확인 필요)
- 34. 테스트 결과 (200G) – 비용 대비 성능 비교 200G에서는 X-Small은 Redshift dc2 type이 효율적 (Snowflake X-Small 사이즈 성능부하 발생 ) - Medium 이상의 size에서는 snowflake의 비용 및 성능이 약 30% 뛰어남 - X-Small 사이즈에서는 Redshift dc2 type이 30% 낮은 비용(2.6$)으로, 13% 빠른 성능 Time (Minute) Cost (달러, $) Redshift(large) 대비 30% 낮은 비용(6$)으로, 50% 빠른 성능 Redshift 대비 20% 낮은 비용(4.1$)으로, 20% 빠른 성능
- 35. 35 1TB TPC-DS Data 기준
- 36. 테스트 결과 (1 TB) – Query 실행 속도 (Snowflake) 1TB 이상은 Large Size 이상의 Virtual Warehouse를 선택해야 빠른 성능 제공 가능 - Snowflake는 데이터 사이즈에 따라서 적합한 Virtual Warehouse 선택 필요 (사용자가 잘 선택할 수 있을까?) - Time (Minute) Medium Size도 1TB에서는 Redshift와 성능 유사 Snowflake X-Small은 1 TB 데이터 처리에 가장 낮은 성능 Large Size 부터 Redshift 대비 빠른 성능 제공
- 37. 테스트 결과 (1 TB) – Query 실행 속도 (Redshift) 1TB에서는 ra3 type에서 노드를 확장하면 Query 속도가 빠르게 향상됨 - 1TB 에서는 고사양의 장비와 노드를 확장하는 것이 성능 측면에서 효율적 - Time (Minute) 성능 개선효과 가장 높음 (약 3배 빠른 성능) 1TB는 X-Small로 처리시 성능 낮음 약 2배 빠른 성능
- 38. 테스트 결과 (1 TB) – Query 실행 속도 (EMR) EMR은 데이터가 1TB로 증가하면서 작은 데이터(50G, 200G) 대비 향상된 성능을 제공 - 아주 고사양의 장비 보다는, CPU/Memory 증설과 노드 수를 증가하는 것이 성능에 효과적 - Time (Minute) 데이터가 커질수록 성능 차이가 아주 크지 않음 데이터가 커져도 높은 스펙의 인스턴스의 장점이 거의 없음 Medium 사이즈에서 2배 빠른 성능 제공
- 39. 데이터가 1TB로 증가하면서 Redshift vs Snowflake 성능 & 비용이 거의 유사하게 측정됨 - Snowflake는 데이터 사이즈와 맞지 않는 Virtual Warehouse Size(X-Small)을 선택 시, 비용 증가 & 성능 저하 - - EMR은 가장 낮은 비용으로 Snowflake보다 빠르게 쿼리 실행 가능 - X-Small 사이즈에서는 Redshift ra3 type이 Snowflake 대비 15% 낮은 비용(15.1$)으로, 25% 빠른 성능 Time (Minute) Cost (달러, $) Snowflake와 Redshift의 성능/비용이 거의 유사 Redshift가 Snowflake 대비 5% 낮은 비용(19.4$)으로, 9% 빠른 성능 테스트 결과 (1 TB) – 비용 대비 성능 비교 가장 낮은 비용으로 1TB 처리 가능
- 40. 40 Cloud DW 성능 테스트 결과를 정리해 보면?
- 41. 41 전반적으로 Snowflake가 성능 & 비용 측면에서 효율적 Data Size와 Cluster Type에 따라 성능/비용 차이 발생 DW Type Data Size 사용시 고려사항 50 G 200 G 1000 G (1 TB) Snowflake 가장 빠른 성능 (X-Small, Medium, Large) 가장 낮은 가격 (X-Small, Medium, Large) 가장 빠른 성능 (Medium, Large) 가장 낮은 가격 (Medium, Large) 가장 빠른 성능 (Large) 가장 낮은 가격 (Large) • 쿼리할 데이터 사이즈에 따라, 최적의 Cluster Size 존재 • 기업이 보유한 데이터 & 자주 사용하는 SQL을 이용하여, 사전에 용도별 Cluster Size 확인 필요 (비용&성능 최적화) • 대량의 데이터(1 TB)에 작은 Cluster Size (X-Small)를 할당하면, 최악의 성능과 비용이 나옴 Redshift 가장 빠른 성능 (X-Small, dc2.large_8 node) 가장 낮은 가격 (X-Small, dc2.large_8 node) 가장 빠른 성능 (Medium, ra3.4xplus_3_node) 가장 낮은 가격 (Medium, ra3.4xplus_3_node) • 200G 이상의 데이터에서 비용 대비 성능이 높아짐. • Snowflake 대비 선택 가능한 Type이 작음. • Ra3 type 권장 (ra3.xplus, ra3.4xlarge, ra3.16xlarge) • 비용이 5배 단위로 증가하여, 세분화된 요금 관리 어려움 EMR (Hive) 가장 느린 성능 가장 비싼 가격 가장 느린 성능 가장 비싼 가격 가장 느린 성능 가장 낮은 가격 (X-Small, c5_2xlarge_5_node) • 1 TB 이상의 대량 데이터를 느리더라도 안정적으로 실행하는 환 경에 적합 • 기업의 목적(비용, 성능)에 따라 최적의 Instance Type을 직접 찾 아야 함. (시간과 노력 필요)
- 42. 42 END
- 43. 43 Backup (Cloud DW 제품별 성능)
- 44. 44 제품별 성능 & 비용 비교 (Snowflake) 데이터 사이즈가 클 때, 작은 Cluster 선택하면, 성능 & 비용 모두 최악 데이터 Size 별 성능/비용 비교 DW Size 별 성능/비용 비교 50 G 200 G 1000 G (1 TB) X-Small Medium Large 50G : X-Small 이 최적 200G : Medium이 최적 1TB : Large가 최적 (데이터 사이즈에 따라, 최적의 Cluster Size 존재) (비용 증가에 따른 성능 개선 효과 높음)
- 45. 45 제품별 성능 & 비용 비교 (Redshift) DW Type 업그레이드에 따라, 일부 성능 개선 효과 데이터 Size 별 성능/비용 비교 DW Size 별 성능/비용 비교 50 G 200 G 1000 G (1 TB) X-Small Medium Large 데이터가 클 수록 (1TB), 비용을 증가하면, 성능개선 효과가 높음 (데이터가 클수록, 성능 개선효과 높음) Redshift는 1TB에서 비용 50% 증가로, 6배 빠른 성능 제공 (1 TB에서 비용에 따른 성능 개선효과 높음)
- 46. 46 제품별 성능 & 비용 비교 (EMR) 200G 이하는 DW Type 변경(비용증가)에 따른 성능 개선효과가 없음 데이터 Size 별 성능/비용 비교 DW Size 별 성능/비용 비교 50 G 200 G 1000 G (1 TB) X-Small Medium Large 50G/200G 데이터는 비용을 추가(인스턴스 변경)해도, 성능 개선효과 거의 없음 (200G 까지는 성능 개선 효과 낮음) 1TB는 성능은 개선(50%)되었으나, 비용이 7배 증가 (비용 증가에 따른 성능 개선 효과 낮음) 1TB 데이터는 적합한 인스턴스 선택 시, 성능 개선효과 높음