Cloudera Impala + PostgreSQL
Download as PPTX, PDF4 likes3,786 views
Hacking Cloudera Impala for running on PostgreSQL cluster as MPP style. Performances under typical sql stmt and concurrence case are verified.
1 of 24
Downloaded 75 times























Ad
Recommended
Hd insight essentials quick view
Hd insight essentials quick viewRajesh Nadipalli These slides provide highlights of my book HDInsight Essentials. Book link is here: http://www.packtpub.com/establish-a-big-data-solution-using-hdinsight/book
Migrating structured data between Hadoop and RDBMS
Migrating structured data between Hadoop and RDBMSBouquet - The document discusses migrating structured data between Hadoop and relational databases using a tool called Bouquet.
- Bouquet allows users to select data from a relational database, which is then sent to Spark via Kafka and stored in HDFS/Tachyon for processing.
- The enriched data in Spark can then be re-injected back into the original database.
Impala Architecture presentation
Impala Architecture presentationhadooparchbook Impala Architecture Presentation at Toronto Hadoop User Group, in January 2014 by Mark Grover.
Event details:
http://www.meetup.com/TorontoHUG/events/150328602/
Incredible Impala 
Incredible Impala Gwen (Chen) Shapira Cloudera Impala: The Open Source, Distributed SQL Query Engine for Big Data. The Cloudera Impala project is pioneering the next generation of Hadoop capabilities: the convergence of fast SQL queries with the capacity, scalability, and flexibility of a Apache Hadoop cluster. With Impala, the Hadoop ecosystem now has an open-source codebase that helps users query data stored in Hadoop-based enterprise data hubs in real time, using familiar SQL syntax.
This talk will begin with an overview of the challenges organizations face as they collect and process more data than ever before, followed by an overview of Impala from the user's perspective and a dive into Impala's architecture. It concludes with stories of how Cloudera's customers are using Impala and the benefits they see.
Hadoop trainting in hyderabad@kelly technologies
Hadoop trainting in hyderabad@kelly technologiesKelly Technologies kelly technologies is the best Hadoop Training Institutes in Hyderabad. Providing Hadoop training by real time faculty in Hyderaba
www.kellytechno.com
HBaseCon 2013: Apache Drill - A Community-driven Initiative to Deliver ANSI S...
HBaseCon 2013: Apache Drill - A Community-driven Initiative to Deliver ANSI S...Cloudera, Inc. Apache Drill is an interactive SQL query engine for analyzing large scale datasets. It allows for querying data stored in HBase and other data sources. Drill uses an optimistic execution model and late binding to schemas to enable fast queries without requiring metadata definitions. It leverages recent techniques like vectorized operators and late record materialization to improve performance. The project is currently in alpha stage but aims to support features like nested queries, Hive UDFs, and optimized joins with HBase.
Syncsort et le retour d'expérience ComScore
Syncsort et le retour d'expérience ComScoreModern Data Stack France This document summarizes Syncsort's high performance data integration solutions for Hadoop contexts. Syncsort has over 40 years of experience innovating performance solutions. Their DMExpress product provides high-speed connectivity to Hadoop and accelerates ETL workflows. It uses partitioning and parallelization to load data into HDFS 6x faster than native methods. DMExpress also enhances usability with a graphical interface and accelerates MapReduce jobs by replacing sort functions. Customers report TCO reductions of 50-75% and ROI within 12 months by using DMExpress to optimize their Hadoop deployments.
Cloudera impala
Cloudera impalaSwiss Big Data User Group James Kinley from Cloudera:
An introduction to Cloudera Impala. Cloudera Impala provides fast, interactive SQL queries directly on your Apache Hadoop data stored in HDFS or HBase. In addition to using the same unified storage platform, Impala also uses the same metadata, SQL syntax (Hive SQL), ODBC driver and user interface (Hue Beeswax) as Apache Hive. This provides a familiar and unified platform for batch-oriented or real-time queries.
The link to the video: http://zurichtechtalks.ch/post/37339409724/an-introduction-to-cloudera-impala-sql-on-top-of
Introduction to Impala
Introduction to Impalamarkgrover Impala is an open source SQL query engine for Apache Hadoop that allows real-time queries on large datasets stored in HDFS and other data stores. It uses a distributed architecture where an Impala daemon runs on each node and coordinates query planning and execution across nodes. Impala allows SQL queries to be run directly against files stored in HDFS and other formats like Avro and Parquet. It aims to provide high performance for both analytical and transactional workloads through its C++ implementation and avoidance of MapReduce.
October 2014 HUG : Hive On Spark
October 2014 HUG : Hive On SparkYahoo Developer Network This document discusses Hive on Spark, including background on Hive, Spark, and the Shark project. It describes how Hive on Spark keeps the same physical abstraction as Hive on Tez/MR to be architecturally compatible. Examples are provided of how a simple query and join query are executed in MapReduce and Spark formats. Improvements to Spark for reduce-side joins and remote Spark contexts are also discussed.
SQOOP - RDBMS to Hadoop
SQOOP - RDBMS to HadoopSofian Hadiwijaya This document discusses using Sqoop to transfer data between relational databases and Hadoop. It begins by providing context on big data and Hadoop. It then introduces Sqoop as a tool for efficiently importing and exporting large amounts of structured data between databases and Hadoop. The document explains that Sqoop allows importing data from databases into HDFS for analysis and exporting summarized data back to databases. It also outlines how Sqoop works, including providing a pluggable connector mechanism and allowing scheduling of jobs.
Hadoop Ecosystem
Hadoop EcosystemLior Sidi A comprehensive overview on the entire Hadoop operations and tools: cluster management, coordination, injection, streaming, formats, storage, resources, processing, workflow, analysis, search and visualization
Qubole @ AWS Meetup Bangalore - July 2015
Qubole @ AWS Meetup Bangalore - July 2015Joydeep Sen Sarma Qubole is a big data as a service platform that allows users to run analytics jobs on AWS infrastructure. It integrates tightly with various AWS services like EC2, S3, Redshift, and Kinesis. Qubole handles cluster provisioning and management, provides tools for interactive querying using Presto, and allows customers to access data across different AWS data platforms through a single interface. Some key benefits of Qubole include simplified management of AWS resources, optimized performance through techniques like auto-scaling and caching, and unified analytics platform for tools like Hive, Spark and Presto.
Apache Spark & Hadoop
Apache Spark & HadoopMapR Technologies http://bit.ly/1BTaXZP – Hadoop has been a huge success in the data world. It’s disrupted decades of data management practices and technologies by introducing a massively parallel processing framework. The community and the development of all the Open Source components pushed Hadoop to where it is now.
That's why the Hadoop community is excited about Apache Spark. The Spark software stack includes a core data-processing engine, an interface for interactive querying, Sparkstreaming for streaming data analysis, and growing libraries for machine-learning and graph analysis. Spark is quickly establishing itself as a leading environment for doing fast, iterative in-memory and streaming analysis.
This talk will give an introduction the Spark stack, explain how Spark has lighting fast results, and how it complements Apache Hadoop.
Keys Botzum - Senior Principal Technologist with MapR Technologies
Keys is Senior Principal Technologist with MapR Technologies, where he wears many hats. His primary responsibility is interacting with customers in the field, but he also teaches classes, contributes to documentation, and works with engineering teams. He has over 15 years of experience in large scale distributed system design. Previously, he was a Senior Technical Staff Member with IBM, and a respected author of many articles on the WebSphere Application Server as well as a book.
Hadoop Hive Talk At IIT-Delhi
Hadoop Hive Talk At IIT-DelhiJoydeep Sen Sarma Hadoop and Hive are used at Facebook for large scale data processing and analytics using commodity hardware and open source software. Hive provides an SQL-like interface to query large datasets stored in Hadoop and translates queries into MapReduce jobs. It is used for daily/weekly data aggregations, ad-hoc analysis, data mining, and other tasks using datasets exceeding petabytes in size stored on Hadoop clusters.
Using Familiar BI Tools and Hadoop to Analyze Enterprise Networks
Using Familiar BI Tools and Hadoop to Analyze Enterprise NetworksDataWorks Summit This document discusses using Apache Drill and business intelligence (BI) tools to analyze network data stored in Hadoop. It provides examples of querying network packet captures and APIs directly using SQL without needing to transform or structure the data first. This allows gaining insights into issues like dropped sensor readings by analyzing packets alongside other data sources. The document concludes that SQL-on-Hadoop technologies allow network analysis to be done in a BI context more quickly than traditional specialized tools.
Kudu - Fast Analytics on Fast Data
Kudu - Fast Analytics on Fast DataRyan Bosshart This document discusses Apache Kudu, an open source column-oriented storage system that provides fast analytics on fast data. It describes Kudu's design goals of high throughput for large scans, low latency for short accesses, and database-like semantics. The document outlines Kudu's architecture, including its use of columnar storage, replication for fault tolerance, and integrations with Spark, Impala and other frameworks. It provides examples of using Kudu for IoT and real-time analytics use cases. Performance comparisons show Kudu outperforming other NoSQL systems on analytics and operational workloads.
Introduction to AWS Big Data 
Introduction to AWS Big Data Omid Vahdaty a comprehensive good introduction to the the Big data world in AWS cloud, hadoop, Streaming, batch, Kinesis, DynamoDB, Hbase, EMR, Athena, Hive, Spark, Piq, Impala, Oozie, Data pipeline, Security , Cost, Best practices
Apache drill
Apache drillMapR Technologies A talk given by Ted Dunning on February 2013 on Apache Drill, an open-source community-driven project to provide easy, dependable, fast and flexible ad hoc query capabilities.
Hoodie - DataEngConf 2017
Hoodie - DataEngConf 2017Vinoth Chandar An Open Source Incremental Processing Framework called Hoodie is summarized. Key points:
- Hoodie provides upsert and incremental processing capabilities on top of a Hadoop data lake to enable near real-time queries while avoiding costly full scans.
- It introduces primitives like upsert and incremental pull to apply mutations and consume only changed data.
- Hoodie stores data on HDFS and provides different views like read optimized, real-time, and log views to balance query performance and data latency for analytical workloads.
- The framework is open source and built on Spark, providing horizontal scalability and leveraging existing Hadoop SQL query engines like Hive and Presto.
HBaseCon 2012 | HBase for the Worlds Libraries - OCLC
HBaseCon 2012 | HBase for the Worlds Libraries - OCLCCloudera, Inc. WorldCat is the world’s largest network of library content and services. Over 25,000 libraries in 170 countries have cooperated for 40 years to build WorldCat. OCLC is currently in the process of transitioning Worldcat from Oracle to Apache HBase. This session will discuss our data design for representing the constantly changing ownership information for thousands of libraries (billions of data points, millions of daily updates) and our plans for how we’re managing HBase in an environment that is equal parts end user facing and batch.
HBaseCon 2015: Apache Kylin - Extreme OLAP Engine for Hadoop
HBaseCon 2015: Apache Kylin - Extreme OLAP Engine for HadoopHBaseCon Kylin is an open source distributed analytics engine contributed by eBay that provides a SQL interface and OLAP on Hadoop supporting extremely large datasets. Kylin's pre-built MOLAP cubes (stored in HBase), distributed architecture, and high concurrency helps users analyze multidimensional queries via SQL and other BI tools. During this session, you'll learn how Kylin uses HBase's key-value store to serve SQL queries with relational schema.
Nextag talk
Nextag talkJoydeep Sen Sarma Hive provides an SQL-like interface to query data stored in Hadoop's HDFS distributed file system and processed using MapReduce. It allows users without MapReduce programming experience to write queries that Hive then compiles into a series of MapReduce jobs. The document discusses Hive's components, data model, query planning and optimization techniques, and performance compared to other frameworks like Pig.
Introduction to the Hadoop EcoSystem
Introduction to the Hadoop EcoSystemShivaji Dutta This document summarizes Hortonworks' Hadoop distribution called Hortonworks Data Platform (HDP). It discusses how HDP provides a comprehensive data management platform built around Apache Hadoop and YARN. HDP includes tools for storage, processing, security, operations and accessing data through batch, interactive and real-time methods. The document also outlines new capabilities in HDP 2.2 like improved engines for SQL, Spark and streaming and expanded deployment options.
Maintaining Low Latency While Maximizing Throughput on a Single Cluster
Maintaining Low Latency While Maximizing Throughput on a Single ClusterMapR Technologies The good news: Hadoop has a lot of tools. The bad news: Hadoop has a lot of tools, and conflicting priorities. This talk shows how advances in YARN and Mesos allow you to run multiple distinct workloads together. We show how to use SLA and latency rules along with preemption in YARN to maintain high throughput while guaranteeing latency for applications such as HBase and Drill
Exponea - Kafka and Hadoop as components of architecture
Exponea - Kafka and Hadoop as components of architectureMartinStrycek Kafka and Hadoop were introduced at Exponea to address several issues:
- The in-memory database was very fast but limited by memory constraints. Customers wanted the freedom to analyze all their data.
- Processing large volumes of streaming data was problematic.
- HDFS does not support appending new data files. Kafka was introduced to stream data for storage in Hadoop.
- The new technologies introduced monitoring challenges for the expanded data stack.
Intro to Apache Kudu (short) - Big Data Application Meetup
Intro to Apache Kudu (short) - Big Data Application MeetupMike Percy Slide deck from my 20 minute talk at the Big Data Application Meetup #BDAM. See http://getkudu.io for more info.
Big Data Day LA 2016/ NoSQL track - Apache Kudu: Fast Analytics on Fast Data,...
Big Data Day LA 2016/ NoSQL track - Apache Kudu: Fast Analytics on Fast Data,...Data Con LA 1) Apache Kudu is a new updatable columnar storage engine for Apache Hadoop that facilitates fast analytics on fast data.
2) Kudu is designed to address gaps in the current Hadoop storage landscape by providing both high throughput for big scans and low latency for short accesses simultaneously.
3) Kudu integrates with various Hadoop components like Spark, Impala, MapReduce to enable SQL queries and other analytics workloads on fast updating data.
Impala 2.0 - The Best Analytic Database for Hadoop
Impala 2.0 - The Best Analytic Database for HadoopCloudera, Inc. A look at why SQL access in Hadoop is critical and the benefits of a native Hadoop analytic database, what’s new with Impala 2.0 and some of the recent performance benchmarks, some common Impala use cases and production customer stories, and insight into what’s next for Impala.
Protecting Your IP with Perforce Helix and Interset
Protecting Your IP with Perforce Helix and IntersetPerforce The intellectual property stored in your SCM system comprises your company’s most valuable assets. How do you keep those assets safe from threats inside and outside your organization?
This session by Charlie McLouth, Director of Technical Sales at Perforce, and Mark Bennett, Vice President at Interset, will give you a deep dive into how Perforce Helix keeps your assets safe, including real-world scenarios of Interset's Threat Detection. You’ll hear how Interset Threat Detection applies advanced behavioral analytics to user activities to proactively surface threats to the IP stored in the Helix Versioning Engine.
You’ll also hear how Helix’s fine-grained permissions model provides unified security policies that govern access-control based on LDAP authentication and contextual information such as IP address of the client or file paths.
Ad
More Related Content
What's hot (20)
Introduction to Impala
Introduction to Impalamarkgrover Impala is an open source SQL query engine for Apache Hadoop that allows real-time queries on large datasets stored in HDFS and other data stores. It uses a distributed architecture where an Impala daemon runs on each node and coordinates query planning and execution across nodes. Impala allows SQL queries to be run directly against files stored in HDFS and other formats like Avro and Parquet. It aims to provide high performance for both analytical and transactional workloads through its C++ implementation and avoidance of MapReduce.
October 2014 HUG : Hive On Spark
October 2014 HUG : Hive On SparkYahoo Developer Network This document discusses Hive on Spark, including background on Hive, Spark, and the Shark project. It describes how Hive on Spark keeps the same physical abstraction as Hive on Tez/MR to be architecturally compatible. Examples are provided of how a simple query and join query are executed in MapReduce and Spark formats. Improvements to Spark for reduce-side joins and remote Spark contexts are also discussed.
SQOOP - RDBMS to Hadoop
SQOOP - RDBMS to HadoopSofian Hadiwijaya This document discusses using Sqoop to transfer data between relational databases and Hadoop. It begins by providing context on big data and Hadoop. It then introduces Sqoop as a tool for efficiently importing and exporting large amounts of structured data between databases and Hadoop. The document explains that Sqoop allows importing data from databases into HDFS for analysis and exporting summarized data back to databases. It also outlines how Sqoop works, including providing a pluggable connector mechanism and allowing scheduling of jobs.
Hadoop Ecosystem
Hadoop EcosystemLior Sidi A comprehensive overview on the entire Hadoop operations and tools: cluster management, coordination, injection, streaming, formats, storage, resources, processing, workflow, analysis, search and visualization
Qubole @ AWS Meetup Bangalore - July 2015
Qubole @ AWS Meetup Bangalore - July 2015Joydeep Sen Sarma Qubole is a big data as a service platform that allows users to run analytics jobs on AWS infrastructure. It integrates tightly with various AWS services like EC2, S3, Redshift, and Kinesis. Qubole handles cluster provisioning and management, provides tools for interactive querying using Presto, and allows customers to access data across different AWS data platforms through a single interface. Some key benefits of Qubole include simplified management of AWS resources, optimized performance through techniques like auto-scaling and caching, and unified analytics platform for tools like Hive, Spark and Presto.
Apache Spark & Hadoop
Apache Spark & HadoopMapR Technologies http://bit.ly/1BTaXZP – Hadoop has been a huge success in the data world. It’s disrupted decades of data management practices and technologies by introducing a massively parallel processing framework. The community and the development of all the Open Source components pushed Hadoop to where it is now.
That's why the Hadoop community is excited about Apache Spark. The Spark software stack includes a core data-processing engine, an interface for interactive querying, Sparkstreaming for streaming data analysis, and growing libraries for machine-learning and graph analysis. Spark is quickly establishing itself as a leading environment for doing fast, iterative in-memory and streaming analysis.
This talk will give an introduction the Spark stack, explain how Spark has lighting fast results, and how it complements Apache Hadoop.
Keys Botzum - Senior Principal Technologist with MapR Technologies
Keys is Senior Principal Technologist with MapR Technologies, where he wears many hats. His primary responsibility is interacting with customers in the field, but he also teaches classes, contributes to documentation, and works with engineering teams. He has over 15 years of experience in large scale distributed system design. Previously, he was a Senior Technical Staff Member with IBM, and a respected author of many articles on the WebSphere Application Server as well as a book.
Hadoop Hive Talk At IIT-Delhi
Hadoop Hive Talk At IIT-DelhiJoydeep Sen Sarma Hadoop and Hive are used at Facebook for large scale data processing and analytics using commodity hardware and open source software. Hive provides an SQL-like interface to query large datasets stored in Hadoop and translates queries into MapReduce jobs. It is used for daily/weekly data aggregations, ad-hoc analysis, data mining, and other tasks using datasets exceeding petabytes in size stored on Hadoop clusters.
Using Familiar BI Tools and Hadoop to Analyze Enterprise Networks
Using Familiar BI Tools and Hadoop to Analyze Enterprise NetworksDataWorks Summit This document discusses using Apache Drill and business intelligence (BI) tools to analyze network data stored in Hadoop. It provides examples of querying network packet captures and APIs directly using SQL without needing to transform or structure the data first. This allows gaining insights into issues like dropped sensor readings by analyzing packets alongside other data sources. The document concludes that SQL-on-Hadoop technologies allow network analysis to be done in a BI context more quickly than traditional specialized tools.
Kudu - Fast Analytics on Fast Data
Kudu - Fast Analytics on Fast DataRyan Bosshart This document discusses Apache Kudu, an open source column-oriented storage system that provides fast analytics on fast data. It describes Kudu's design goals of high throughput for large scans, low latency for short accesses, and database-like semantics. The document outlines Kudu's architecture, including its use of columnar storage, replication for fault tolerance, and integrations with Spark, Impala and other frameworks. It provides examples of using Kudu for IoT and real-time analytics use cases. Performance comparisons show Kudu outperforming other NoSQL systems on analytics and operational workloads.
Introduction to AWS Big Data
Introduction to AWS Big Data Omid Vahdaty a comprehensive good introduction to the the Big data world in AWS cloud, hadoop, Streaming, batch, Kinesis, DynamoDB, Hbase, EMR, Athena, Hive, Spark, Piq, Impala, Oozie, Data pipeline, Security , Cost, Best practices
Apache drill
Apache drillMapR Technologies A talk given by Ted Dunning on February 2013 on Apache Drill, an open-source community-driven project to provide easy, dependable, fast and flexible ad hoc query capabilities.
Hoodie - DataEngConf 2017
Hoodie - DataEngConf 2017Vinoth Chandar An Open Source Incremental Processing Framework called Hoodie is summarized. Key points:
- Hoodie provides upsert and incremental processing capabilities on top of a Hadoop data lake to enable near real-time queries while avoiding costly full scans.
- It introduces primitives like upsert and incremental pull to apply mutations and consume only changed data.
- Hoodie stores data on HDFS and provides different views like read optimized, real-time, and log views to balance query performance and data latency for analytical workloads.
- The framework is open source and built on Spark, providing horizontal scalability and leveraging existing Hadoop SQL query engines like Hive and Presto.
HBaseCon 2012 | HBase for the Worlds Libraries - OCLC
HBaseCon 2012 | HBase for the Worlds Libraries - OCLCCloudera, Inc. WorldCat is the world’s largest network of library content and services. Over 25,000 libraries in 170 countries have cooperated for 40 years to build WorldCat. OCLC is currently in the process of transitioning Worldcat from Oracle to Apache HBase. This session will discuss our data design for representing the constantly changing ownership information for thousands of libraries (billions of data points, millions of daily updates) and our plans for how we’re managing HBase in an environment that is equal parts end user facing and batch.
HBaseCon 2015: Apache Kylin - Extreme OLAP Engine for Hadoop
HBaseCon 2015: Apache Kylin - Extreme OLAP Engine for HadoopHBaseCon Kylin is an open source distributed analytics engine contributed by eBay that provides a SQL interface and OLAP on Hadoop supporting extremely large datasets. Kylin's pre-built MOLAP cubes (stored in HBase), distributed architecture, and high concurrency helps users analyze multidimensional queries via SQL and other BI tools. During this session, you'll learn how Kylin uses HBase's key-value store to serve SQL queries with relational schema.
Nextag talk
Nextag talkJoydeep Sen Sarma Hive provides an SQL-like interface to query data stored in Hadoop's HDFS distributed file system and processed using MapReduce. It allows users without MapReduce programming experience to write queries that Hive then compiles into a series of MapReduce jobs. The document discusses Hive's components, data model, query planning and optimization techniques, and performance compared to other frameworks like Pig.
Introduction to the Hadoop EcoSystem
Introduction to the Hadoop EcoSystemShivaji Dutta This document summarizes Hortonworks' Hadoop distribution called Hortonworks Data Platform (HDP). It discusses how HDP provides a comprehensive data management platform built around Apache Hadoop and YARN. HDP includes tools for storage, processing, security, operations and accessing data through batch, interactive and real-time methods. The document also outlines new capabilities in HDP 2.2 like improved engines for SQL, Spark and streaming and expanded deployment options.
Maintaining Low Latency While Maximizing Throughput on a Single Cluster
Maintaining Low Latency While Maximizing Throughput on a Single ClusterMapR Technologies The good news: Hadoop has a lot of tools. The bad news: Hadoop has a lot of tools, and conflicting priorities. This talk shows how advances in YARN and Mesos allow you to run multiple distinct workloads together. We show how to use SLA and latency rules along with preemption in YARN to maintain high throughput while guaranteeing latency for applications such as HBase and Drill
Exponea - Kafka and Hadoop as components of architecture
Exponea - Kafka and Hadoop as components of architectureMartinStrycek Kafka and Hadoop were introduced at Exponea to address several issues:
- The in-memory database was very fast but limited by memory constraints. Customers wanted the freedom to analyze all their data.
- Processing large volumes of streaming data was problematic.
- HDFS does not support appending new data files. Kafka was introduced to stream data for storage in Hadoop.
- The new technologies introduced monitoring challenges for the expanded data stack.
Intro to Apache Kudu (short) - Big Data Application Meetup
Intro to Apache Kudu (short) - Big Data Application MeetupMike Percy Slide deck from my 20 minute talk at the Big Data Application Meetup #BDAM. See http://getkudu.io for more info.
Big Data Day LA 2016/ NoSQL track - Apache Kudu: Fast Analytics on Fast Data,...
Big Data Day LA 2016/ NoSQL track - Apache Kudu: Fast Analytics on Fast Data,...Data Con LA 1) Apache Kudu is a new updatable columnar storage engine for Apache Hadoop that facilitates fast analytics on fast data.
2) Kudu is designed to address gaps in the current Hadoop storage landscape by providing both high throughput for big scans and low latency for short accesses simultaneously.
3) Kudu integrates with various Hadoop components like Spark, Impala, MapReduce to enable SQL queries and other analytics workloads on fast updating data.
Viewers also liked (17)
Impala 2.0 - The Best Analytic Database for Hadoop
Impala 2.0 - The Best Analytic Database for HadoopCloudera, Inc. A look at why SQL access in Hadoop is critical and the benefits of a native Hadoop analytic database, what’s new with Impala 2.0 and some of the recent performance benchmarks, some common Impala use cases and production customer stories, and insight into what’s next for Impala.
Protecting Your IP with Perforce Helix and Interset
Protecting Your IP with Perforce Helix and IntersetPerforce The intellectual property stored in your SCM system comprises your company’s most valuable assets. How do you keep those assets safe from threats inside and outside your organization?
This session by Charlie McLouth, Director of Technical Sales at Perforce, and Mark Bennett, Vice President at Interset, will give you a deep dive into how Perforce Helix keeps your assets safe, including real-world scenarios of Interset's Threat Detection. You’ll hear how Interset Threat Detection applies advanced behavioral analytics to user activities to proactively surface threats to the IP stored in the Helix Versioning Engine.
You’ll also hear how Helix’s fine-grained permissions model provides unified security policies that govern access-control based on LDAP authentication and contextual information such as IP address of the client or file paths.
Database aggregation using metadata
Database aggregation using metadataDr Sandeep Kumar Poonia This document describes a simulator for database aggregation using metadata. The simulator sits between an end-user application and a database management system (DBMS) to intercept SQL queries and transform them to take advantage of available aggregates using metadata describing the data warehouse schema. The simulator provides performance gains by optimizing queries to use appropriate aggregate tables. It was found to improve performance over previous aggregate navigators by making fewer calls to system tables through the use of metadata mappings. Experimental results showed the simulator solved queries faster than alternative approaches by transforming queries to leverage aggregate tables.

Impala データサイエンティストのための 高速大規模分散基盤 #tokyowebmining
Impala データサイエンティストのための 高速大規模分散基盤 #tokyowebminingSho Shimauchi Tokyo Webmining #25 で発表したときの資料です。メインはデモの方です
GoでKVSを書けるのか
GoでKVSを書けるのかMoriyoshi Koizumi This document describes code for a Memcached server written in Go. It uses TCP listeners and handlers to accept connections from clients. It maintains an in-memory key-value store using a map. It can handle get and set requests by parsing the request header and building responses. It uses channels for communication between the main listener routine and a backend handler for the key-value store.
Cloudera Impala
Cloudera ImpalaScott Leberknight Slides for presentation on Cloudera Impala I gave at the Near Infinity (www.nearinfinity.com) 2013 spring conference.
The moroccan ethnic groups of Morocco
The moroccan ethnic groups of MoroccoMohsine Mahraj This document provides an overview of the ethnic groups that make up the population of Morocco throughout history. It discusses several indigenous Berber groups like the Masmuda, Zenata, and Sanhaja tribes that settled across Morocco. It also mentions Arab groups that migrated to Morocco like the Doui-Menia and Banu Hilal. The document outlines the history of Morocco from the 8th century onwards and the various dynasties that ruled the country and influenced its ethnic composition. It provides details on current Berber tribes located in different regions of Morocco like the Ait Atta, Ait Waryaghar, Ait Seghrouchen, Ait Yafelman, Chiadma
Elephant Roads: a tour of Postgres forks
Elephant Roads: a tour of Postgres forksCommand Prompt., Inc Josh Berkus
Most users know that PostgreSQL has a 23-year development history. But did you know that Postgres code is used for over a dozen other database systems? Thanks to our liberal licensing, many companies and open source projects over the years have taken the Postgres or PostgreSQL code, changed it, added things to it, and/or merged it into something else. Illustra, Truviso, Aster, Greenplum, and others have seen the value of Postgres not just as a database but as some darned good code they could use. We'll explore the lineage of these forks, and go into the details of some of the more interesting ones.
#cwt2016 Apache Kudu 構成とテーブル設計
#cwt2016 Apache Kudu 構成とテーブル設計Cloudera Japan スライド中のURI
- Kuduのインストール(Cloudera Manager使用)
http://www.cloudera.com/documentation/betas/kudu/latest/topics/kudu_installation.html
- Impala-Kuduのインストール(CDH5.8以前)
http://www.cloudera.com/documentation/betas/kudu/latest/topics/kudu_impala.html#install_impala
- Apache Kudu Troubleshooting
http://kudu.apache.org/docs/troubleshooting.html
- Apache Kudu project page
http://kudu.apache.org/
- Cloudera Engineering Blog
https://blog.cloudera.com/
- Kudu Design Docs
https://github.com/apache/kudu/tree/master/docs/design-docs
Side by Side with Elasticsearch & Solr, Part 2
Side by Side with Elasticsearch & Solr, Part 2Sematext Group, Inc. This document compares the performance and scalability of Elasticsearch and Solr for two use cases: product search and log analytics. For product search, both products performed well at high query volumes, but Elasticsearch handled the larger video dataset faster. For logs, Elasticsearch performed better by using time-based indices across hot and cold nodes to isolate newer and older data. In general, configuration was found to impact performance more than differences between the products. Proper testing with one's own data is recommended before making conclusions.
R-CISC Summit 2016 Borderless Threat Intelligence
R-CISC Summit 2016 Borderless Threat IntelligenceJason Trost Self and supply chain monitoring using External Threat Intelligence. Presented at R-CISC Summit 2016.
HBaseCon 2015: Running ML Infrastructure on HBase
HBaseCon 2015: Running ML Infrastructure on HBaseHBaseCon Sift Science uses online, large-scale machine learning to detect fraud for thousands of sites and hundreds of millions of users in real-time. This talk describes how we leverage HBase to power an ML infrastructure including how we train and build models, store and update model parameters online, and provide real-time predictions. The central pieces of the machine learning infrastructure and the tradeoffs we made to maximize performance will also be covered.
PostgreSQLアーキテクチャ入門(PostgreSQL Conference 2012)
PostgreSQLアーキテクチャ入門(PostgreSQL Conference 2012)Uptime Technologies LLC (JP) 2012年2月24日に開催されたPostgreSQLカンファレンス2012のセッション「PostgreSQLアーキテクチャ入門」の講演資料です。
Presto - Hadoop Conference Japan 2014
Presto - Hadoop Conference Japan 2014Sadayuki Furuhashi Presto is a distributed SQL query engine that allows for interactive analysis of large datasets across various data sources. It was created at Facebook to enable interactive querying of data in HDFS and Hive, which were too slow for interactive use. Presto addresses problems with existing solutions like Hive being too slow, the need to copy data for analysis, and high costs of commercial databases. It uses a distributed architecture with coordinators planning queries and workers executing tasks quickly in parallel.
HBase Storage Internals
HBase Storage InternalsDataWorks Summit Apache HBase is the Hadoop opensource, distributed, versioned storage manager well suited for random, realtime read/write access. This talk will give an overview on how HBase achieve random I/O, focusing on the storage layer internals. Starting from how the client interact with Region Servers and Master to go into WAL, MemStore, Compactions and on-disk format details. Looking at how the storage is used by features like snapshots, and how it can be improved to gain flexibility, performance and space efficiency.
Debunking the Myths of HDFS Erasure Coding Performance 
Debunking the Myths of HDFS Erasure Coding Performance DataWorks Summit/Hadoop Summit The document discusses erasure coding as an alternative to replication in distributed storage systems like HDFS. It notes that while replication provides high durability, it has high storage overhead, and erasure coding can provide similar durability with half the storage overhead but slower recovery. The document outlines how major companies like Facebook, Windows Azure Storage, and Google use erasure coding. It then provides details on HDFS-EC, including its architecture, use of hardware acceleration, and performance evaluation showing its benefits over replication.
Ad
Similar to Cloudera Impala + PostgreSQL (20)
LesFurets.com: From 0 to Cassandra on AWS in 30 days - Tsunami Alerting Syste...
LesFurets.com: From 0 to Cassandra on AWS in 30 days - Tsunami Alerting Syste...DataStax Academy An earthquake occurs in the Sea of Japan. A tsunami is likely to hit the coast. The population must be warned by SMS. A datacenter has been damaged by the earthquake. Will the alerting system still work ?
Building this simple alerting system is a great way to start with Cassandra, as we discovered teaching a bigdata hands-on class in a french university.
What were the reasons that made a majority of students to choose Cassandra to implement a fast, resilient and high availability big data system to be deployed on AWS ?
What were the common pitfalls, the modeling alternatives and their performance impact ?
Inside Freshworks' Migration from Cassandra to ScyllaDB by Premkumar Patturaj
Inside Freshworks' Migration from Cassandra to ScyllaDB by Premkumar PatturajScyllaDB Freshworks migrated from Cassandra to ScyllaDB to handle growing audit log data efficiently. Cassandra required frequent scaling, complex repairs, and had non-linear scaling. ScyllaDB reduced costs with fewer machines and improved operations. Using Zero Downtime Migration (ZDM), they bulk-migrated data, performed dual writes, and validated consistency.
DC Migration and Hadoop Scale For Big Billion Days
DC Migration and Hadoop Scale For Big Billion DaysRahul Agarwal Deck from BigData MeetUp - Bangalore.
Presents challenges faced in Migrating Hadoop cluster with 200+ TB compressed data from one data centre to another, from baremetals to cloud, from DNS based systems to infra without DNS.
MariaDB ColumnStore
MariaDB ColumnStoreMariaDB plc MariaDB ColumnStore is a high performance columnar storage engine for MariaDB that supports analytical workloads on large datasets. It uses a distributed, massively parallel architecture to provide faster and more efficient queries. Data is stored column-wise which improves compression and enables fast loading and filtering of large datasets. The cpimport tool allows loading data into MariaDB ColumnStore in bulk from CSV files or other sources, with options for centralized or distributed parallel loading. Proper sizing of ColumnStore deployments depends on factors like data size, workload, and hardware specifications.
Migration to ClickHouse. Practical guide, by Alexander Zaitsev
Migration to ClickHouse. Practical guide, by Alexander ZaitsevAltinity Ltd This document provides a summary of migrating to ClickHouse for analytics use cases. It discusses the author's background and company's requirements, including ingesting 10 billion events per day and retaining data for 3 months. It evaluates ClickHouse limitations and provides recommendations on schema design, data ingestion, sharding, and SQL. Example queries demonstrate ClickHouse performance on large datasets. The document outlines the company's migration timeline and challenges addressed. It concludes with potential future integrations between ClickHouse and MySQL.
Big Data Analytics with MariaDB ColumnStore
Big Data Analytics with MariaDB ColumnStoreMariaDB plc MariaDB ColumnStore is a massively parallel columnar storage engine for MariaDB that provides high performance analytics on large datasets. It uses a distributed columnar architecture where each column is stored separately and data is partitioned horizontally across nodes. This allows for very fast analytical queries by only accessing the relevant columns and partitions. Some key features include built-in analytics functions, high speed data ingestion, and support for running on-premises or on cloud platforms like AWS. The latest 1.1 version adds capabilities like streaming data ingestion APIs, improved high availability with GlusterFS, and performance optimizations.
Best Practices for Supercharging Cloud Analytics on Amazon Redshift
Best Practices for Supercharging Cloud Analytics on Amazon RedshiftSnapLogic In this webinar, we discuss how the secret sauce to your business analytics strategy remains rooted on your approached, methodologies and the amount of data incorporated into this critical exercise. We also address best practices to supercharge your cloud analytics initiatives, and tips and tricks on designing the right information architecture, data models and other tactical optimizations.
To learn more, visit: http://www.snaplogic.com/redshift-trial
Webinar: SQL for Machine Data?
Webinar: SQL for Machine Data?Crate.io By 2020, 50% of all new software will process machine-generated data of some sort (Gartner). Historically, machine data use cases have required non-SQL data stores like Splunk, Elasticsearch, or InfluxDB.
Today, new SQL DB architectures rival the non-SQL solutions in ease of use, scalability, cost, and performance. Please join this webinar for a detailed comparison of machine data management approaches.
Low-Latency Analytics with NoSQL – Introduction to Storm and Cassandra
Low-Latency Analytics with NoSQL – Introduction to Storm and CassandraCaserta Businesses are generating and ingesting an unprecedented volume of structured and unstructured data to be analyzed. Needed is a scalable Big Data infrastructure that processes and parses extremely high volume in real-time and calculates aggregations and statistics. Banking trade data where volumes can exceed billions of messages a day is a perfect example.
Firms are fast approaching 'the wall' in terms of scalability with relational databases, and must stop imposing relational structure on analytics data and map raw trade data to a data model in low latency, preserve the mapped data to disk, and handle ad-hoc data requests for data analytics.
Joe discusses and introduces NoSQL databases, describing how they are capable of scaling far beyond relational databases while maintaining performance , and shares a real-world case study that details the architecture and technologies needed to ingest high-volume data for real-time analytics.
For more information, visit www.casertaconcepts.com
Overview of data analytics service: Treasure Data Service
Overview of data analytics service: Treasure Data ServiceSATOSHI TAGOMORI Treasure Data provides a data analytics service with the following key components:
- Data is collected from various sources using Fluentd and loaded into PlazmaDB.
- PlazmaDB is the distributed time-series database that stores metadata and data.
- Jobs like queries, imports, and optimizations are executed on Hadoop and Presto clusters using queues, workers, and a scheduler.
- The console and APIs allow users to access the service and submit jobs for processing and analyzing their data.
WyspaIT 2016 - Azure Stream Analytics i Azure Machine Learning w analizie str...
WyspaIT 2016 - Azure Stream Analytics i Azure Machine Learning w analizie str...Łukasz Grala Wzrost ilości danych w postaci strumieni danych spowodował potrzebę analizy danych w czasie rzecyzwistych będących strumieniami. W czasie sesji pokazano połączenie:
- event hub/Iot hub
- Azure Stream Analytics
- Azure Machine Learning
Agility and Scalability with MongoDB
Agility and Scalability with MongoDBMongoDB MongoDB has taken a clear lead in adoption among the new generation of databases, including the enormous variety of NoSQL offerings. A key reason for this lead has been a unique combination of agility and scalability. Agility provides business units with a quick start and flexibility to maintain development velocity, despite changing data and requirements. Scalability maintains that flexibility while providing fast, interactive performance as data volume and usage increase. We'll address the key organizational, operational, and engineering considerations to ensure that agility and scalability stay aligned at increasing scale, from small development instances to web-scale applications. We will also survey some key examples of highly-scaled customer applications of MongoDB.
Real-Time Streaming: Move IMS Data to Your Cloud Data Warehouse
Real-Time Streaming: Move IMS Data to Your Cloud Data WarehousePrecisely With over 22,000 transactions processed every second, your mainframe IMS is a critical source of data for the cloud data warehouses that feed analytics, customer experience or regulatory initiatives. However, extracting data from mainframe IMS can be time-consuming and costly, leading to the exclusion of IMS data from cloud data warehouses all together – and leaving valuable insights unseen.
Never ignore or manually extract mainframe IMS data again. In this on-demand webcast, you will learn how Connect CDC enables your team to develop integrations quickly and easily between mainframe IMS and cloud data warehouses in the most cost-effective way possible.
Rapids: Data Science on GPUs
Rapids: Data Science on GPUsinside-BigData.com In this deck from FOSDEM'19, Christoph Angerer from NVIDIA presents: Rapids - Data Science on GPUs.
"The next big step in data science will combine the ease of use of common Python APIs, but with the power and scalability of GPU compute. The RAPIDS project is the first step in giving data scientists the ability to use familiar APIs and abstractions while taking advantage of the same technology that enables dramatic increases in speed in deep learning. This session highlights the progress that has been made on RAPIDS, discusses how you can get up and running doing data science on the GPU, and provides some use cases involving graph analytics as motivation.
GPUs and GPU platforms have been responsible for the dramatic advancement of deep learning and other neural net methods in the past several years. At the same time, traditional machine learning workloads, which comprise the majority of business use cases, continue to be written in Python with heavy reliance on a combination of single-threaded tools (e.g., Pandas and Scikit-Learn) or large, multi-CPU distributed solutions (e.g., Spark and PySpark). RAPIDS, developed by a consortium of companies and available as open source code, allows for moving the vast majority of machine learning workloads from a CPU environment to GPUs. This allows for a substantial speed up, particularly on large data sets, and affords rapid, interactive work that previously was cumbersome to code or very slow to execute. Many data science problems can be approached using a graph/network view, and much like traditional machine learning workloads, this has been either local (e.g., Gephi, Cytoscape, NetworkX) or distributed on CPU platforms (e.g., GraphX). We will present GPU-accelerated graph capabilities that, with minimal conceptual code changes, allows both graph representations and graph-based analytics to achieve similar speed ups on a GPU platform. By keeping all of these tasks on the GPU and minimizing redundant I/O, data scientists are enabled to model their data quickly and frequently, affording a higher degree of experimentation and more effective model generation. Further, keeping all of this in compatible formats allows quick movement from feature extraction, graph representation, graph analytic, enrichment back to the original data, and visualization of results. RAPIDS has a mission to build a platform that allows data scientist to explore data, train machine learning algorithms, and build applications while primarily staying on the GPU and GPU platforms."
Learn more: https://rapids.ai/
and
https://fosdem.org/2019/
Sign up for our insideHPC Newsletter: http://insidehpc.com/newsletter
NVIDIA Rapids presentation
NVIDIA Rapids presentationtestSri1 This document summarizes a presentation by Dr. Christoph Angerer on RAPIDS, an open source library for GPU-accelerated data science. Some key points:
- RAPIDS provides an end-to-end GPU-accelerated workflow for data science using CUDA and popular tools like Pandas, Spark, and XGBoost.
- It addresses challenges with data movement and formats by keeping data on the GPU as much as possible using the Apache Arrow data format.
- Benchmarks show RAPIDS provides significant speedups over CPU for tasks like data preparation, machine learning training, and visualization.
- Future work includes improving cuDF (GPU DataFrame library), adding algorithms to cuML
MySQL performance monitoring using Statsd and Graphite
MySQL performance monitoring using Statsd and GraphiteDB-Art This session will explain how you can leverage the MySQL-StatsD collector, StatsD and Graphite to monitor your database performance with metrics sent every second. In the past few years Graphite has become the de facto standard for monitoring large and scalable infrastructures.
This session will cover the architecture, functional basics and dashboard creation using Grafana. MySQL-StatsD is really easy to set up and configure. It will allow you to fetch your most important metrics from MySQL, run your own custom queries to parse your production data and if necessary transform this data into something different that can be used as a metric. Having this data with a fine granularity allows you to correlate your production data, system metrics with your MySQL performance metrics.
MySQL-StatsD is a daemon written in Python that was created during one of the hackdays at my previous employer (Spil Games) to solve the issue of fetching data from MySQL using a light weight client and send metrics to StatsD. I currently maintain this open source project on Github as it is my duty as creator of the project to look after it.
Tweaking perfomance on high-load projects_Думанский Дмитрий
Tweaking perfomance on high-load projects_Думанский ДмитрийGeeksLab Odessa This document discusses optimizing the performance of several high-load projects delivering billions of requests per month. It summarizes the evolution and delivery loads of different projects over time. It then analyzes the technical stacks and architectures used, identifying problems and solutions implemented around areas like querying, data storage, processing, and networking. Key lessons learned are around sharding and resharding data, optimizing I/O, using streaming processing like Storm over batch processing like Hadoop, and working within AWS limits and capabilities.
Ops Jumpstart: MongoDB Administration 101
Ops Jumpstart: MongoDB Administration 101MongoDB New to MongoDB? We'll provide an overview of installation, high availability through replication, scale out through sharding, and options for monitoring and backup. No prior knowledge of MongoDB is assumed. This session will jumpstart your knowledge of MongoDB operations, providing you with context for the rest of the day's content.
Solr Power FTW: Powering NoSQL the World Over
Solr Power FTW: Powering NoSQL the World OverAlex Pinkin Solr is an open source, Lucene based search platform originally developed by CNET and used by the likes of Netflix, Yelp, and StubHub which has been rapidly growing in popularity and features during the last few years. Learn how Solr can be used as a Not Only SQL (NoSQL) database along the lines of Cassandra, Memcached, and Redis. NoSQL data stores are regularly described as non-relational, distributed, internet-scalable and are used at both Facebook and Digg. This presentation will quickly cover the fundamentals of NoSQL data stores, the basics of Lucene, and what Solr brings to the table. Following that we will dive into the technical details of making Solr your primary query engine on large scale web applications, thus relegating your traditional relational database to little more than a simple key store. Real solutions to problems like handling four billion requests per month will be presented. We'll talk about sizing and configuring the Solr instances to maintain rapid response times under heavy load. We'll show you how to change the schema on a live system with tens of millions of documents indexed while supporting real-time results. And finally, we'll answer your questions about ways to work around the lack of transactions in Solr and how you can do all of this in a highly available solution.
Scalable IoT platform
Scalable IoT platformSwapnil Bawaskar This document discusses using Apache Geode and ActiveMQ Artemis to build a scalable IoT platform. It introduces IoT and the MQTT protocol. ActiveMQ Artemis is described as a high performance message broker that is embeddable and supports clustering. Geode is presented as a distributed in-memory data platform for building data-intensive applications that require high performance, scalability, and availability. Example users of Geode include large companies handling billions of records and thousands of transactions per second. Key capabilities of Geode like regions, functions, querying, and continuous queries are summarized.
Ad
Recently uploaded (20)
Drupalcamp Finland – Measuring Front-end Energy Consumption
Drupalcamp Finland – Measuring Front-end Energy ConsumptionExove How to measure web front-end energy consumption using Firefox Profiler. Presented in DrupalCamp Finland on April 25th, 2025.
DevOpsDays Atlanta 2025 - Building 10x Development Organizations.pptx
DevOpsDays Atlanta 2025 - Building 10x Development Organizations.pptxJustin Reock Building 10x Organizations with Modern Productivity Metrics
10x developers may be a myth, but 10x organizations are very real, as proven by the influential study performed in the 1980s, ‘The Coding War Games.’
Right now, here in early 2025, we seem to be experiencing YAPP (Yet Another Productivity Philosophy), and that philosophy is converging on developer experience. It seems that with every new method we invent for the delivery of products, whether physical or virtual, we reinvent productivity philosophies to go alongside them.
But which of these approaches actually work? DORA? SPACE? DevEx? What should we invest in and create urgency behind today, so that we don’t find ourselves having the same discussion again in a decade?
How analogue intelligence complements AI
How analogue intelligence complements AIPaul Rowe
Artificial Intelligence is providing benefits in many areas of work within the heritage sector, from image analysis, to ideas generation, and new research tools. However, it is more critical than ever for people, with analogue intelligence, to ensure the integrity and ethical use of AI. Including real people can improve the use of AI by identifying potential biases, cross-checking results, refining workflows, and providing contextual relevance to AI-driven results.
News about the impact of AI often paints a rosy picture. In practice, there are many potential pitfalls. This presentation discusses these issues and looks at the role of analogue intelligence and analogue interfaces in providing the best results to our audiences. How do we deal with factually incorrect results? How do we get content generated that better reflects the diversity of our communities? What roles are there for physical, in-person experiences in the digital world?
Quantum Computing Quick Research Guide by Arthur Morgan
Quantum Computing Quick Research Guide by Arthur MorganArthur Morgan This is a Quick Research Guide (QRG).
QRGs include the following:
- A brief, high-level overview of the QRG topic.
- A milestone timeline for the QRG topic.
- Links to various free online resource materials to provide a deeper dive into the QRG topic.
- Conclusion and a recommendation for at least two books available in the SJPL system on the QRG topic.
QRGs planned for the series:
- Artificial Intelligence QRG
- Quantum Computing QRG
- Big Data Analytics QRG
- Spacecraft Guidance, Navigation & Control QRG (coming 2026)
- UK Home Computing & The Birth of ARM QRG (coming 2027)
Any questions or comments?
- Please contact Arthur Morgan at [email protected].
100% human made.
Mobile App Development Company in Saudi Arabia
Mobile App Development Company in Saudi ArabiaSteve Jonas EmizenTech is a globally recognized software development company, proudly serving businesses since 2013. With over 11+ years of industry experience and a team of 200+ skilled professionals, we have successfully delivered 1200+ projects across various sectors. As a leading Mobile App Development Company In Saudi Arabia we offer end-to-end solutions for iOS, Android, and cross-platform applications. Our apps are known for their user-friendly interfaces, scalability, high performance, and strong security features. We tailor each mobile application to meet the unique needs of different industries, ensuring a seamless user experience. EmizenTech is committed to turning your vision into a powerful digital product that drives growth, innovation, and long-term success in the competitive mobile landscape of Saudi Arabia.
TrustArc Webinar: Consumer Expectations vs Corporate Realities on Data Broker...
TrustArc Webinar: Consumer Expectations vs Corporate Realities on Data Broker...TrustArc Most consumers believe they’re making informed decisions about their personal data—adjusting privacy settings, blocking trackers, and opting out where they can. However, our new research reveals that while awareness is high, taking meaningful action is still lacking. On the corporate side, many organizations report strong policies for managing third-party data and consumer consent yet fall short when it comes to consistency, accountability and transparency.
This session will explore the research findings from TrustArc’s Privacy Pulse Survey, examining consumer attitudes toward personal data collection and practical suggestions for corporate practices around purchasing third-party data.
Attendees will learn:
- Consumer awareness around data brokers and what consumers are doing to limit data collection
- How businesses assess third-party vendors and their consent management operations
- Where business preparedness needs improvement
- What these trends mean for the future of privacy governance and public trust
This discussion is essential for privacy, risk, and compliance professionals who want to ground their strategies in current data and prepare for what’s next in the privacy landscape.
Designing Low-Latency Systems with Rust and ScyllaDB: An Architectural Deep Dive
Designing Low-Latency Systems with Rust and ScyllaDB: An Architectural Deep DiveScyllaDB Want to learn practical tips for designing systems that can scale efficiently without compromising speed?
Join us for a workshop where we’ll address these challenges head-on and explore how to architect low-latency systems using Rust. During this free interactive workshop oriented for developers, engineers, and architects, we’ll cover how Rust’s unique language features and the Tokio async runtime enable high-performance application development.
As you explore key principles of designing low-latency systems with Rust, you will learn how to:
- Create and compile a real-world app with Rust
- Connect the application to ScyllaDB (NoSQL data store)
- Negotiate tradeoffs related to data modeling and querying
- Manage and monitor the database for consistently low latencies
How Can I use the AI Hype in my Business Context?
How Can I use the AI Hype in my Business Context?Daniel Lehner 𝙄𝙨 𝘼𝙄 𝙟𝙪𝙨𝙩 𝙝𝙮𝙥𝙚? 𝙊𝙧 𝙞𝙨 𝙞𝙩 𝙩𝙝𝙚 𝙜𝙖𝙢𝙚 𝙘𝙝𝙖𝙣𝙜𝙚𝙧 𝙮𝙤𝙪𝙧 𝙗𝙪𝙨𝙞𝙣𝙚𝙨𝙨 𝙣𝙚𝙚𝙙𝙨?
Everyone’s talking about AI but is anyone really using it to create real value?
Most companies want to leverage AI. Few know 𝗵𝗼𝘄.
✅ What exactly should you ask to find real AI opportunities?
✅ Which AI techniques actually fit your business?
✅ Is your data even ready for AI?
If you’re not sure, you’re not alone. This is a condensed version of the slides I presented at a Linkedin webinar for Tecnovy on 28.04.2025.
Rusty Waters: Elevating Lakehouses Beyond Spark
Rusty Waters: Elevating Lakehouses Beyond Sparkcarlyakerly1 Spark is a powerhouse for large datasets, but when it comes to smaller data workloads, its overhead can sometimes slow things down. What if you could achieve high performance and efficiency without the need for Spark?
At S&P Global Commodity Insights, having a complete view of global energy and commodities markets enables customers to make data-driven decisions with confidence and create long-term, sustainable value. 🌍
Explore delta-rs + CDC and how these open-source innovations power lightweight, high-performance data applications beyond Spark! 🚀
Linux Professional Institute LPIC-1 Exam.pdf
Linux Professional Institute LPIC-1 Exam.pdfRHCSA Guru Introduction to LPIC-1 Exam - overview, exam details, price and job opportunities
Semantic Cultivators : The Critical Future Role to Enable AI
Semantic Cultivators : The Critical Future Role to Enable AIartmondano By 2026, AI agents will consume 10x more enterprise data than humans, but with none of the contextual understanding that prevents catastrophic misinterpretations.
Massive Power Outage Hits Spain, Portugal, and France: Causes, Impact, and On...
Massive Power Outage Hits Spain, Portugal, and France: Causes, Impact, and On...Aqusag Technologies In late April 2025, a significant portion of Europe, particularly Spain, Portugal, and parts of southern France, experienced widespread, rolling power outages that continue to affect millions of residents, businesses, and infrastructure systems.
Heap, Types of Heap, Insertion and Deletion
Heap, Types of Heap, Insertion and DeletionJaydeep Kale This pdf will explain what is heap, its type, insertion and deletion in heap and Heap sort
Technology Trends in 2025: AI and Big Data Analytics
Technology Trends in 2025: AI and Big Data AnalyticsInData Labs At InData Labs, we have been keeping an ear to the ground, looking out for AI-enabled digital transformation trends coming our way in 2025. Our report will provide a look into the technology landscape of the future, including:
-Artificial Intelligence Market Overview
-Strategies for AI Adoption in 2025
-Anticipated drivers of AI adoption and transformative technologies
-Benefits of AI and Big data for your business
-Tips on how to prepare your business for innovation
-AI and data privacy: Strategies for securing data privacy in AI models, etc.
Download your free copy nowand implement the key findings to improve your business.
Complete Guide to Advanced Logistics Management Software in Riyadh.pdf
Complete Guide to Advanced Logistics Management Software in Riyadh.pdfSoftware Company Explore the benefits and features of advanced logistics management software for businesses in Riyadh. This guide delves into the latest technologies, from real-time tracking and route optimization to warehouse management and inventory control, helping businesses streamline their logistics operations and reduce costs. Learn how implementing the right software solution can enhance efficiency, improve customer satisfaction, and provide a competitive edge in the growing logistics sector of Riyadh.
HCL Nomad Web – Best Practices and Managing Multiuser Environments
HCL Nomad Web – Best Practices and Managing Multiuser Environmentspanagenda Webinar Recording: https://www.panagenda.com/webinars/hcl-nomad-web-best-practices-and-managing-multiuser-environments/
HCL Nomad Web is heralded as the next generation of the HCL Notes client, offering numerous advantages such as eliminating the need for packaging, distribution, and installation. Nomad Web client upgrades will be installed “automatically” in the background. This significantly reduces the administrative footprint compared to traditional HCL Notes clients. However, troubleshooting issues in Nomad Web present unique challenges compared to the Notes client.
Join Christoph and Marc as they demonstrate how to simplify the troubleshooting process in HCL Nomad Web, ensuring a smoother and more efficient user experience.
In this webinar, we will explore effective strategies for diagnosing and resolving common problems in HCL Nomad Web, including
- Accessing the console
- Locating and interpreting log files
- Accessing the data folder within the browser’s cache (using OPFS)
- Understand the difference between single- and multi-user scenarios
- Utilizing Client Clocking
Procurement Insights Cost To Value Guide.pptx
Procurement Insights Cost To Value Guide.pptxJon Hansen Procurement Insights integrated Historic Procurement Industry Archives, serves as a powerful complement — not a competitor — to other procurement industry firms. It fills critical gaps in depth, agility, and contextual insight that most traditional analyst and association models overlook.
Learn more about this value- driven proprietary service offering here.
HCL Nomad Web – Best Practices und Verwaltung von Multiuser-Umgebungen
HCL Nomad Web – Best Practices und Verwaltung von Multiuser-Umgebungenpanagenda Webinar Recording: https://www.panagenda.com/webinars/hcl-nomad-web-best-practices-und-verwaltung-von-multiuser-umgebungen/
HCL Nomad Web wird als die nächste Generation des HCL Notes-Clients gefeiert und bietet zahlreiche Vorteile, wie die Beseitigung des Bedarfs an Paketierung, Verteilung und Installation. Nomad Web-Client-Updates werden “automatisch” im Hintergrund installiert, was den administrativen Aufwand im Vergleich zu traditionellen HCL Notes-Clients erheblich reduziert. Allerdings stellt die Fehlerbehebung in Nomad Web im Vergleich zum Notes-Client einzigartige Herausforderungen dar.
Begleiten Sie Christoph und Marc, während sie demonstrieren, wie der Fehlerbehebungsprozess in HCL Nomad Web vereinfacht werden kann, um eine reibungslose und effiziente Benutzererfahrung zu gewährleisten.
In diesem Webinar werden wir effektive Strategien zur Diagnose und Lösung häufiger Probleme in HCL Nomad Web untersuchen, einschließlich
- Zugriff auf die Konsole
- Auffinden und Interpretieren von Protokolldateien
- Zugriff auf den Datenordner im Cache des Browsers (unter Verwendung von OPFS)
- Verständnis der Unterschiede zwischen Einzel- und Mehrbenutzerszenarien
- Nutzung der Client Clocking-Funktion
Special Meetup Edition - TDX Bengaluru Meetup #52.pptx
Special Meetup Edition - TDX Bengaluru Meetup #52.pptxshyamraj55 We’re bringing the TDX energy to our community with 2 power-packed sessions:
🛠️ Workshop: MuleSoft for Agentforce
Explore the new version of our hands-on workshop featuring the latest Topic Center and API Catalog updates.
📄 Talk: Power Up Document Processing
Dive into smart automation with MuleSoft IDP, NLP, and Einstein AI for intelligent document workflows.
Build Your Own Copilot & Agents For Devs
Build Your Own Copilot & Agents For DevsBrian McKeiver May 2nd, 2025 talk at StirTrek 2025 Conference.
Cloudera Impala + PostgreSQL
- 1. Running Cloudera Impala on PostgreSQL By Chengzhong Liu [email protected] 2013.12
- 2. Story coming from… • Data gravity • Why big data • Why SQL on big data
- 3. Today agenda • • • • • • Big data in Miaozhen 秒针系统 Overview of Cloudera Impala Hacking practice in Cloudera Impala Performance Conclusions Q&A
- 4. What happened in miaozhen • 3 billion Ads impression per day • 20TB data scan for report generation every morning • 24 servers cluster • Besides this – – – – TV Monitor Mobile Monitor Site Monitor …
- 5. Before Hadoop • Scrat – PostgreSQL 9.1 cluster – Write a simple proxy – <2s for 2TB data scan • Mobile Monitor – Hadoop-like distribute computing system – Rabbit MQ + 3 computing servers – Write a Map-Reduce in C++ – Handles 30 millions to 500 millions Ads impression
- 6. Problem & Chance • Database cluster • SQL on Hadoop • Miscellaneous data • Requirements – Most data is rational – SQL interface
- 7. SQL on Hadoop • • • • • Google Dremel Apache Drill Cloudera Impala Facebook Presto EMC Greenplum/Pivotal Latency matters Pig Impala/Drill /Pivotal/Presto Map Reduce HDFS Hive
- 8. What’s this • A kind of MPP engine • In memory processing • Small to big join – Broadcast join • Small result size
- 9. Why Cloudera Impala • The team move fast – UDF coming out – Better join strategy on the way • Good code base – Modularize – Easy to add sub classes • Really fast – Llvm code generation • 80s/95s – uv test – Distributed aggregation Tree – In-situ data processing (inside storage)
- 10. Typical Arch. SQL Interface Meta Store Query Planner Query Planner Query Planner Coordinat or Coordinat or Coordinat or Exec Engine Exec Engine Exec Engine
- 11. Our target • A MPP database – Build on PostgreSQL9.1 – Scale well – Speed • A mixed data source MPP query engine – Join two tables in different sources – In fact…
- 12. Hacking… from where • Add, not change – Scan Node type – DB Meta info • Put changes in configuration – Thrift Protocol update • TDBHostInfo • TDBScanNode
- 13. Front end • Meta store update – Link data to the table name – Table location management • Front end – Compute table location
- 14. Back end • Coordinator – pg host • New scan node type – db scan node • Pg scan node • Psql library using cursor
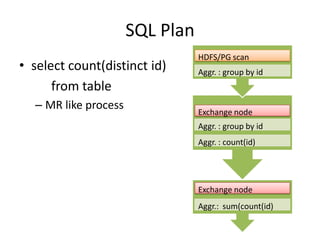
- 15. SQL Plan • select count(distinct id) from table – MR like process HDFS/PG scan Aggr. : group by id Exchange node Aggr. : group by id Aggr. : count(id) Exchange node Aggr.: sum(count(id)
- 16. Env. • Ads impression logs – 150 millions, 100KB/line • 3 servers – – – – 24 cores 32 G mem 2T * 12 HD 100Mbps LAN • Query – Select count(id) from t group by campaign – Select count(distinct id) from t group by campaign – Select * from t where id = ‘xxxxxxxx’
- 17. Performance • Group by speed / core • 20 M /s 700 600 500 400 impala hive 300 pg+impala 200 100 0 1 2 3
- 18. With index
- 19. Codegen on/off • select count(distinct id) from t group by c 100 90 80 70 • select distinct id from t 60 50 en_codegen 40 dis_codegen 30 • 20 select id from t 10 group by id 0 having uv_test count(case when c = '1' then 1 else null end) > 0 and count(case when c= 2' then 1 else null end) > 0 limit 10; distinct duplicated
- 20. Multi-users
- 21. Conclusion • Source quality – Readable – Google C++ style – Robust • MPP solution based on PG – Proved perf. – Easy to scale • Mixed engine usage – HDFS and DB
- 22. What’s next • • • • • Yarn integrating UDF Join with Big table BI roadmap Fail over
- 23. Rerf. • Cloudera Impala online doc. & src • http://files.meetup.com/1727991/Impala%20and %20BigQuery.ppt • http://www.cubrid.org/blog/dev-platform/meetimpala-open-source-real-time-sql-querying-onhadoop/ • http://berlinbuzzwords.de/sites/berlinbuzzwords. de/files/slides/Impala%20tech%20talk.pdf • @datascientist, @dongxicheng, @flyingsk, @zhh
- 24. Thanks! Q&A