Comparison of Learning Algorithms for Handwritten Digit Recognition
Download as pptx, pdf0 likes537 views

This document compares different machine learning algorithms for handwritten digit recognition on the MNIST dataset. Convolutional neural networks achieved the best results, with LeNet5 achieving 0.9% error and boosted LeNet4 achieving the lowest error rate of 0.7%. Neural networks required more training time but had faster recognition times and lower memory requirements compared to nearest neighbor classifiers. Overall, convolutional neural networks were best suited for handwritten digit recognition due to their ability to handle variations in size, position and orientation of digits.



























































More Related Content
What's hot (20)
Similar to Comparison of Learning Algorithms for Handwritten Digit Recognition (20)


















Recently uploaded (20)




















Comparison of Learning Algorithms for Handwritten Digit Recognition
- 1. Comparison of learning algorithms for handwritten digit recognition Y LeCun, L Jackel, L Bottou, A Brunot, C Cortes, J Denker, H, Drucker, I Guyon, U Muller, E Sackinger, P Simard, and V Vapnik 1995 Author | Safaa Alnabulsi
- 2. Index Introduction Database The Classifiers Linear Classifiers Nearest Neighbor Classifiers Neural Networks Classifiers Convolutional Neural Networks Classifiers Discussion Conclusions Author | Safaa Alnabulsi
- 3. Introduction This paper compares the relative merits of several classification algorithms develop ed at Bell Laboratories and elsewhere for the purpose of recognizing handwritten digits. It is an excellent benchmark for comparing shapes not only digits. They consider: o Raw accuracy o Rejection training time o Recognition time o Memory requirement Author | Safaa Alnabulsi
- 4. Database The MNIST database of handwritten digits was constructed from NIST's Special Database 3 and Special Database 1 which contain binary images of handwritten digits: • Training set was composed of 60,000 pattern contained examples from approximately 250 disjoint writes. • Test set was composed of 10,000 patterns. All the images were size-normalized to fit in a 20x20 pixel box while preserving the aspect ratio. Author | Safaa Alnabulsi
- 5. The Classifiers Author | Safaa Alnabulsi LINEAR NEAREST NEIGHBOR NEURAL NETWORK CONVOLUTIONAL NEURAL NETWORK
- 6. Linear Classifiers Baseline Linear Classifier Pairwise Linear Classifier PCA and Polynomial Classifier Optimal Margin OMC Author | Safaa Alnabulsi
- 7. Baseline Linear Classifier The simplest classifier. Each input pixel value contributes to a weighted sum for each output unit. The output unit with the highest sum indicates the class of the input character. Thus, as we can see, the image is treated as a 1D vector and connected to a 10-output vector. The test error rate is 8.4%. Author | Safaa Alnabulsi
- 8. Pairwise Linear Classifier A simple improvement of the basic linear classifier. The idea is to train each unit of a single-layer network to classify one class from one other class. The final score for class i is : the sum of the outputs all the units labelled i/z minus the sum of the output of all the units labelled y/i, for all z and y. Error rate on the test set was 7.6%, only slightly better than a linear classifier. Author | Safaa Alnabulsi 45
- 9. PCA and Polynomial Classifier This classifier can be seen as a linear classifier with 821 inputs, preceded by a stage which computes the projection of the input pattern on the 40 principal components of the set of training vectors. The 40.dimensional feature vector was used as the input of a second degree polynomial classifier. Error on the test set was 3.3%. Author | Safaa Alnabulsi From “Handbook Of Character Recognition And Document Image Analysis” Page 111
- 10. Optimal Margin Classifier (OMC) OMC is called SVM now, which constructs a hyperplane or set of hyperplanes in a high or infinite-dimensional space, which can be used for classification. Best hyperplane is the one that represents the largest separation, or margin, between the two classes Using Regular SVM, a test error of 1.4% was reached. Whereas, using a slighlty different techinqe, Soft Margin Classifier (Cortes & Vapnik ) with a 4-th degree decision surface, a test error of 1.1% was reached. Author | Safaa Alnabulsi
- 11. Nearest neighbor Classifiers Baseline Nearest Neighbor Classifier Tangent Distance Classifier (TDCs) Author | Safaa Alnabulsi
- 12. Baseline Nearest Neighbor Classifier Another simple classifier with a Euclidean distance measure between input images. It would operate on feature vectors rather than directly on the pixels No training time and no brain on the part of the designer The memory requirement and recognition time are large Deslanted 20x20 images were used. The test error for k = 3 is 2.4%. Author | Safaa Alnabulsi
- 13. Tangent Distance Classifier (TDC) Author | Safaa Alnabulsi
- 14. Tangent Distance Classifier (TDC) It is a nearest-neighbor method where the distance function is made insensitive to small distortions and translations of the input image. Tangent plane ? If we consider an image as a point in a high dimensional pixel space then an evolving distortion traces out a curve in pixel space.Taken together, all these distortions define a low-dimensional manifold in pixel space which can be approximated by a tangent plane. An excellent measure of „closeness“for character images is the distance between their tangent planes A test error rate of 1.1% was achieved using 16x16 pixel images. Author | Safaa Alnabulsi
- 15. Neural Networks Classifiers Radial Basis Function Network Large Fully Connected Multi-Layer Neural Network Author | Safaa Alnabulsi
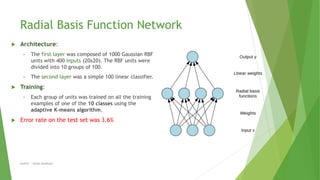
- 16. Radial Basis Function Network Architecture: • The first layer was composed of 1000 Gaussian RBF units with 400 inputs (20x20). The RBF units were divided into 10 groups of 100. • The second layer was a simple 100 linear classifier. Training: • Each group of units was trained on all the training examples of one of the 10 classes using the adaptive K-means algorithm. Error rate on the test set was 3.6% Author | Safaa Alnabulsi
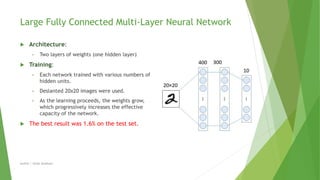
- 17. Large Fully Connected Multi-Layer Neural Network Architecture: • Two layers of weights (one hidden layer) Training: • Each network trained with various numbers of hidden units. • Deslanted 20x20 images were used. • As the learning proceeds, the weights grow, which progressively increases the effective capacity of the network. The best result was 1.6% on the test set. Author | Safaa Alnabulsi
- 18. Convolutional Neural Networks Classifiers Letet1 LeNet4 LeNet5 Boosted LeNet4 Author | Safaa Alnabulsi
- 19. Motiviation Behind CNN To solve the dilemma between small networks that cannot learn the training set, and large networks that seem overparameterized, one can design specialized network architectures that are specifically designed to recognize two-dimensional shapes such as digits, while eliminating irrelevant distortions and variability. These considerations lead us to the idea of convolutional network. Author | Safaa Alnabulsi
- 20. LeNet1 Because of LeNet 1‘s small input field, the images were down-sampled to 16x16 pixels and centered in the 28x28 input layer. Small number of free parameters, only about 3000. LeNet 1 achieved 1.7% test error. Author | Safaa Alnabulsi
- 21. LeNet4 LeNet 4 was designed to address the problem of large size of the training. It is an expanded version of LeNet 1 that has a 32x32 input layer in which the 20x20 images (not deslanted) were centered by center of mass. It includes more feature maps and an additional layer of hidden units that is fully connected to both the last layer of features maps and to the output units. LeNet 4 contains about 260,000 connections and has about 17,000 free parameters. Test error was 1.1%. Author | Safaa Alnabulsi
- 22. LeNet5 LeNet 5, has an architecture similar to LeNet 4, but has more feature maps, a larger fully-connected layer. LeNet 5 has a total of about 340,000 connections, and 60,000 free parameters, most of them in the last two layers. the training procedure included a module that distorts the input images during training using randomly picked affine transformations (shift, scaling, rotation, and procedureing small skewing). It achieved 0.9% error. Author | Safaa Alnabulsi
- 23. Boosted LeNet4 Author | Safaa Alnabulsi
- 24. Boosted LeNet4 Three LeNet 4 are combined: • The first one is trained the usual way. • The second one is trained on a mix of patterns that are filtered by the first net (50% of which the first net got right, and 50% of which it got wrong). • The third net is trained on new patterns on which the first and the second nets disagree. During testing, the outputs of the three nets are simply added. The test error rate was 0.7%, the best of any of our classifiers. At first glance, bossting appears to be three times more expensive as a single net. In fact, when the first net produces a high confidence answer, the other nets are not called. The cost is bout 1.75 times that of a single net. Author | Safaa Alnabulsi
- 25. Discussion Author | Safaa Alnabulsi ERROR RATE REJECTION TRAINING TIME TRAINING TIME MEMORY
- 26. Discussion – Error Rate Author | Safaa Alnabulsi Boosted LeNet 4 is clearly the best, achieving score of 0.7%, closely followed by LeNet 5 at 0.9%. This can be compared to our estimate of human performance , 0.2%
- 27. Discussion – Rejection Training Time Author | Safaa Alnabulsi In many applications, rejection performance is more significant than raw error rate. Again Boosted LeNet 4 has the best score.
- 28. Discussion – Trainig Time Author | Safaa Alnabulsi K-nearest neighbors and TDC have essentially zero training time. While the single-layer net, the pairwise net, and PCA+quadratic net could be trained in less than an hour, the multilayer net training times were expectedly much longer: 3 days for LeNet 1, 7 days for the fully connected net, 2 weeks for LeNet 4 and 5, and about a month for boosted LeNet 4. Training the Soft Margin classifier took about 10 days.
- 29. Discussion – Memory Author | Safaa Alnabulsi Memory requirements for the neural networks assume 4 bytes. Of the high-accuracy classifiers, LeNet 4 requires the least memory.
- 30. Conclusions Performance depends on many factors including high accuracy, low run time, and low memory requirements. Furture: As computer technology improves, larger capacity recognizers become feasible. The neural nets advantage will become more striking as training databases continue to increase in size. Boosting: We find that boosting gives a substantial improvement in accuracy, with a relatively modest penalty in memory and computing expense. Training Data: When plenty of data is available, many methods can attain respectable accuracy. Optimal margin classifier: it has excellent accuracy, which is most remarkable, because unlike the other high performance classifiers, it does not include a priori knowledge about the problem. It is still much slower and memory hungry than the convolutional nets. Convolutional networks: are particularly well suited for recognizing or rejecting shapes with widely varying size, position, and orientation. Trained neural networks can run much faster and require much less space than memory-based techniques. Author | Safaa Alnabulsi
- 31. Author | Safaa Alnabulsi
Editor's Notes
- #8: The simplest classifier
- #9: For the n(=10) classes you build all n(n-1)/2 = 45 Binary classifiers, denoted by i/j where i and j are different classes. The i/z classifier output tells what makes i favorable over class z. On the other hand x/i tells what speaks against i compared to class x. Then you add up all 9 unique comparisons where i is either left or right of the dash. If i is right, you should note that x/i so to say equals -i/x.
- #10: To compute the principal components: the mean of each input component was first computed and subtracted from the training vectors. The covariance matrix of the resulting vectors was then computed, and diagonalized using Singular Value Decomposition (SVD).
- #11: Challange: Polynomial classifiers are well studied methods for generating complex decision surfaces. Unfortunately, they are impractical for high-dimensional problems. One reasonable choice as the best hyperplane is the one that represents the largest separation, or margin, between the two classes. So we choose the hyperplane so that the distance from it to the nearest data point on each side is maximized. If such a hyperplane exists, it is known as the maximum-margin hyperplane and the linear classifier it defines is known as a maximum-margin classifier; or equivalently, the perceptron of optimal stability.[citation needed] SVM? More formally, a support-vector machine constructs a hyperplane or set of hyperplanes in a high- or infinite-dimensional space, which can be used for classification, regression, or other tasks like outliers detection. Intuitively, a good separation is achieved by the hyperplane that has the largest distance to the nearest training-data point of any class (so-called functional margin), since in general the larger the margin, the lower the generalization error of the classifier.[4] The drawing: H1 does not separate the classes. H2 does, but only with a small margin. H3 separates them with the maximal margin. Additional info: In addition to performing linear classification, SVMs can efficiently perform a non-linear classification using what is called the kernel trick, implicitly mapping their inputs into high-dimensional feature spaces.
- #13: Naturally, a realistic Euclidean distance nearest-neighbor system would operate on feature vectors rather than directly on the pixels
- #14: an unlabeled image of a "9" must be classified by finding the closest prototype image out of two images representing respectively a "9" and a "4". According to the Euclidean distance (sum of the squares of the pixel to pixel differences), the "4" is closer even though the "9" is much more similar once it has been rotated and thickened. The result is an incorrect classification. The key idea is to construct a distance measure which is invariant with respect to some chosen transformations such as translation, rotation and others.
- #15: Explainaition of the picture from paper below: P, E are patterns Sp, Se are manifolds, obtained through small transformations of P such as (rotation, translation, scaling, etc.). he Euclidean distance between two patterns P and E is in general not appropriate because it is sensitive to irrelevant transformations of P and of E. In contrast, the distance D(E, P) defined to be the minimal distance between the two manifolds Sp and SE is truly invariant with respect to the transformation used to generate Sp and SE. Unfortunately, these manifolds have no analytic expression in general, and finding the distance between them is a hard optimization problem with multiple local minima. Besides, t.rue invariance is not necessarily desirable since a rotation ofa "6" into a "9" does not preserve the correct classification. https://pdfs.semanticscholar.org/8314/dda1ec43ce57ff877f8f02ed89acb68ca035.pdf
- #17: Radial basis function (RBF) networks typically have three layers: an input layer, a hidden layer with a non-linear RBF activation function and a linear output layer. The second layer weights were computed using a regularized pseudo-inverse method.
- #20: Convolution: extract features from the input image. By using “feature map”A shared filter (therefore small number of parameters) specifically designed for the data-type at hand (here pictures), that, when trained implicitly learns structured features such as edges in the picture. Pooling or Sub Sampling: reduces the dimensionality of each feature map but retains the most important information. (parameter-free) Classification (Fully Connected Layer)
- #21: It should be intuitively clear to the audience that convolutions + (down-sampling) lead to small number of parameters, and that mixing those with fully connected layers is still more parameter-efficient compared to deep fully connected networks.
- #22: In previous experiments with ZIP code data, replacing the last layer of LeNet 4 with a Euclidean Nearest Neighbor classifier, and with the “local learning” method of Bottou and Vapnik, in which a local linear classifier is retrained each time a new test pattern is shown. Neither of those improve the raw error rate, although they did improve the rejection
- #24: Boosting is a technique to combine the results from several/many weak classifiers to get a more accurate results
- #27: Boosted LeNet 4 is clearly the best, achieving score of 0.7%, closely followed by LeNet 5 at 0.9%. This can be compared to our estimate of human performance , 0.2%
- #28: In many applications, rejection performance is more significant than raw error rate. Again boosted LeNet 4 has the best score. The enhanced LeNet 4 did better than original LeNet 4.
- #29: Expectedly, memory-based method are much slower than neural networks. Single-board hardware designed with LeNet in mind performs recognition at 1000 characters/sec (Säckinger & Graf 94). Cost-effective hardware implementations of memory-based techniques are more elusive, due to their enormous memory requirements. Training time was also measured. However, while the training time is marginally relevant to the designer, it is totally irrelevant to the customer.
- #31: training time