Composing re-useable ETL on Hadoop
Download as KEY, PDF1 like1,331 views

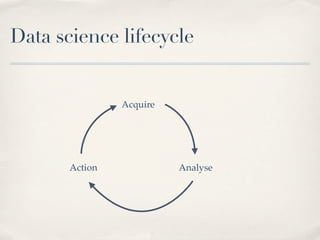
The document discusses composing reusable extract-transform-load (ETL) processes on Hadoop. It covers the data science lifecycle of acquiring, analyzing and taking action on data. It states that 80% of work in data science is spent on acquiring and preparing data. The document then discusses using Cascading, an abstraction framework for building MapReduce jobs, to create reusable ETL processes that are linearly scalable and follow a single-purpose composable design.











Composing re-useable ETL on Hadoop
- 1. Composing re-useable ETL on Hadoop Paul Lam (@Quantisan) Big Data London, 1 October 2012
- 2. Data science lifecycle Acquire Action Analyse
- 3. Data science lifecycle Acquire 80% of work Action Analyse 80% of result
- 4. From these ✤ {:status 200, :scheme http, :pipe ., :request-uri /broadband/? gclid=CPnYgdqj0bECFa4mtAodVEsAYA, :http-x-forwarded-for 92.9.200.50, :msec 1344196910.137, :sent-http-set-cookie -, :body-bytes-sent 18836, :query-string gclid=CPnYgdj0bECa4mtAdVEsAYA, :request-content-type -, :cookie-urefs -, :request GET /broadband/?gclid=CPnYgdj0bECa4mtAdVEsAYA HTTP/1.1, :upstream- response-time 0.164, :sent-http-content-type text/html, :hostname nginx- lb-20120229-1942-24.uswitchinternal.com, :sent-http-location -, :time-local 05/Aug/ 2012:20:01:50 +0000, :http-referer http://www.google.co.uk/aclk? sa=l&ai=D1556&rct=j&q=best%20value%20internet%20uk, :http-user-agent Mozilla/ 5.0 (Windows NT 6.0) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.60 Safari/537.1, :request-time 0.164, :request-body -, :http-host www.uswitch.com, :upstream-addr 178.32.60.100:80, :sent-http-server -, :upstream- status 200, :uscc <ANON>}
- 5. To these ✤ Removing bots and crawlers ✤ Picking out relevant events ✤ Grouping events by users ✤ Sequencing the events ✤ Structuring as a matrix ✤ Graphing
- 6. Using this ✤ an abstraction framework for building MapReduce jobs ✤ linearly scalable data processing ✤ www.cascading.org
- 7. Word Count - MapReduce ✤ public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> ✤ public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException ✤ “take this line and split it to word tokens” ✤ public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> ✤ public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException ✤ “take each word token and increment a counter”
- 8. Word Count - Cascalog
- 9. Benefits of Domain Specific Language ✤ At same level of abstraction of the problem ✤ split words, then do a count on them ✤ Fewer custom code, less prone to implementation bugs ✤ More readable ✤ More productive
- 10. TF-IDF ✤ Extended from word count example ✤ Single-purpose methods ✤ Composition of functions ✤ github.com/Quantisan/Impatient ✤ github.com/Cascading/Impatient
- 11. Our data processing methodology ✤ Apply single-purpose functions to immutable data ✤ Only build what we need as we go ✤ Composability, extensibility, maintainability ✤ Use the right tool for the right task
- 12. Contact ✤ Paul Lam, data scientist at uSwitch ✤ @Quantisan ✤ [email protected]