
































































































Ad
More Related Content
Viewers also liked (12)
Similar to Computational Biology, Part 4 Protein Coding Regions (20)










Ad
More from butest (20)




















Ad
Computational Biology, Part 4 Protein Coding Regions
- 1. Computational Biology, Part 7 Supervised Machine Learning and Searching for Sequence Families Robert F. Murphy Copyright 2008-2009. All rights reserved.
- 3. What is Machine Learning? Fundamental Question of Computer Science: How can we build machines that solve problems, and which problems are inherently tractable/intractable? Fundamental Question of Statistics: What can be inferred from data plus a set of modeling assumptions, with what reliability? Tom Mitchell white paper
- 4. Fundamental Question of Machine Learning How can we build computer systems that automatically improve with experience, and what are the fundamental laws that govern all learning processes? Tom Mitchell Tom Mitchell white paper
- 5. Why Machine Learning? Learn relationships from large sets of complex data: Data mining Predict clinical outcome from tests Decide whether someone is a good credit risk Do tasks too complex to program by hand Autonomous driving Customize programs to user needs Recommend book/movie based on previous likes Tom Mitchell white paper
- 6. Why Machine Learning? Economically efficient Can consider larger data spaces and hypothesis spaces than people can Can formalize learning problem to explicitly identify/describe goals and criteria
- 7. Successful Machine Learning Applications Speech recognition Telephone menu navigation Computer vision Mail sorting Bio-surveillance Identifying disease outbreaks Robot control Autonomous driving Empirical science Tom Mitchell white paper
- 8. Machine Learning Paradigms Supervised Learning Classification Regression Unsupervised Learning Clustering Semi-supervised Learning Cotraining Active learning
- 9. Supervised Learning Approaches Classification (discrete predictions) Regression (continuous predictions) Common considerations Representation (Features) Feature Selection Functional form Evaluation of predictive power
- 10. Classification vs. Regression If I want to predict whether a patient will die from a disease within six months, that is classification If I want to predict how long the patient will live, that is regression
- 11. Representation Definition of thing or things to be predicted Classification: classes Regression: regression variable Definition of things ( instances ) to make predictions for Individuals Families Neighborhoods, etc. Choice of descriptors ( features ) to describe different aspects of instances
- 12. Formal description Defining X as a set of instances x described by features Given training examples D from X Given a target function c that maps X- >{0,1} Given a hypothesis space H Determine an hypothesis h in H such that h(x) = c(x) for all x in D Courtesy Tom Mitchell
- 13. Inductive learning hypothesis Any hypothesis found to approximate the target function well over a sufficiently large set of training examples will also approximate the target function over other unobserved examples Courtesy Tom Mitchell
- 14. Hypothesis space The hypothesis space determines the functional form It defines what are allowable rules/functions for classification Each classification method uses a different hypothesis space
- 15. - + ??? Simple two class problem Describe each image by features Train classifier
- 16. k-Nearest Neighbor (kNN) In feature space, training examples are
- 17. k-Nearest Neighbor (kNN) We want to label ‘ ? ’ Feature #1 (e.g.., ‘area’) Feature #2 (e.g.., roundness) + - + + + + + + - - - - - ?
- 18. k-Nearest Neighbor (kNN) Find k nearest neighbors and vote for k=3, nearest neighbors are So we label it +
- 19. Linear Discriminants Fit multivariate Gaussian to each class Measure distance from ? to each Gaussian area bright. + - + + + + - - - - - ?
- 20. Decision trees Again we want to label ‘ ? ’ Slide courtesy of Christos Faloutsos
- 21. Decision trees so we build a decision tree: 50 40 Slide courtesy of Christos Faloutsos
- 22. Decision trees so we build a decision tree: Slide courtesy of Christos Faloutsos
- 23. Decision trees Goal: split address space in (almost) homogeneous regions Slide courtesy of Christos Faloutsos area<50 Y + round. <40 N - ... Y N ‘ area’ round. + - + + + + + + - - - - - ? 50 40
- 24. Support vector machines Again we want to label ‘ ? ’ Feature #1 (e.g.., ‘area’) Feature #2 (e.g.., roundness) + - + + + + + + - - - - - ? Slide courtesy of Christos Faloutsos
- 25. Support Vector Machines (SVMs) Use single linear separator?? area round. + - + + + + - - - - - ? Slide courtesy of Christos Faloutsos
- 26. Support Vector Machines (SVMs) Use single linear separator?? area round. + - + + + + - - - - - ? Slide courtesy of Christos Faloutsos
- 27. Support Vector Machines (SVMs) Use single linear separator?? area round. + - + + + + - - - - - ? Slide courtesy of Christos Faloutsos
- 28. Support Vector Machines (SVMs) Use single linear separator?? + - + + + + - - - - - ? area round. Slide courtesy of Christos Faloutsos
- 29. Support Vector Machines (SVMs) Use single linear separator?? + - + + + + - - - - - ? area round. Slide courtesy of Christos Faloutsos
- 30. Support Vector Machines (SVMs) we want to label ‘ ? ’ - linear separator?? A: the one with the widest corridor! area round. + - + + + + - - - - - ? Slide courtesy of Christos Faloutsos
- 31. Support Vector Machines (SVMs) What if the points for each class are not readily separated by a straight line? Use the “kernel trick” – project the points into a higher dimensional space in which we hope that straight lines will separate the classes “ kernel” refers to the function used for this projection
- 32. Support Vector Machines (SVMs) Definition of SVMs explicitly considers only two classes What if we have more than two classes? Train multiple SVMs Two basic approaches One against all (one SVM for each class) Pairwise SVMs (one for each pair of classes) Various ways of implementing this
- 33. Cross-Validation If we train a classifier to minimize error on a set of data, have no ability to estimate (generalize) error that will be seen on new dataset To calculate generalizable accuracy, we use n- fold cross-validation Divide images into n sets, train using n -1 of them and test on the remaining set Repeat until each set is used as test set and average results across all trials Variation on this is called leave-one-out
- 34. Describing classifier errors For binary classifiers (positive or negative), define TP = true positives, FP = false positives TN = true negatives, FN = false negatives Recall = TP / (TP + FN) Precision = TP / (TP + FP) F-measure= 2*Recall*Precision/(Recall + Precision)
- 35. Confusion matrix - binary True \ Predicted Positive Negative Positive True Positive False Negative Negative False Positive True Negative
- 36. Precision-recall analysis Vary classifier parameter to “loosen” some performance estimate: i.e., confidence Ideal performance
- 37. Describing classifier errors For multi-class classifiers, typically report Accuracy = # test images correctly classified # test images Confusion matrix = table showing all possible combinations of true class and predicted class
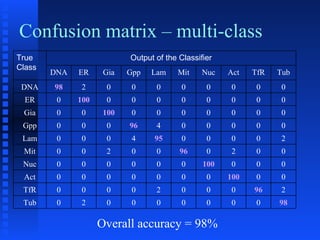
- 38. Confusion matrix – multi-class Overall accuracy = 98% True Class Output of the Classifier DNA ER Gia Gpp Lam Mit Nuc Act TfR Tub DNA 98 2 0 0 0 0 0 0 0 0 ER 0 100 0 0 0 0 0 0 0 0 Gia 0 0 100 0 0 0 0 0 0 0 Gpp 0 0 0 96 4 0 0 0 0 0 Lam 0 0 0 4 95 0 0 0 0 2 Mit 0 0 2 0 0 96 0 2 0 0 Nuc 0 0 0 0 0 0 100 0 0 0 Act 0 0 0 0 0 0 0 100 0 0 TfR 0 0 0 0 2 0 0 0 96 2 Tub 0 2 0 0 0 0 0 0 0 98
- 39. Ground truth What is the source and confidence of a class label? Most common: Human assignment, unknown confidence Preferred: Assignment by experimental design, confidence ~100%
- 40. Stating Goals vs. Approaches Temptation when first considering using a machine learning approach to a biological problem is to describe the problem as automating the approach that you would solve the problem “ I need a program to predict how much a gene is expressed by measuring how well its promoter matches a template”
- 41. Stating Goals vs. Approaches “ I need a program that given a gene sequence predicts how much that gene is expressed by measuring how well its promoter matches a template” “ I need a program that given a gene sequence predicts how much that gene is expressed by learning from sequences of genes whose expression is known”
- 42. Resources Association for the Advancement of Artificial Intelligence http://www.aaai.org/AITopics/pmwiki/pmwiki.php/AITopics/MachineLearning Machine Learning – Mitchell, Carnegie Mellon http://www.cs.cmu.edu/afs/cs.cmu.edu/user/mitchell/ftp/mlbook.html Practical Machine Learning – Jordan, UC Berkeley http://www.cs.berkeley.edu/~asimma/294-fall06/ Learning and Empirical Inference – Rish, Tesauro, Jebara, Vadpnik – Columbia http://www1.cs.columbia.edu/~jebara/6998/
- 44. Goals for sequence families Find previously unrecognized members of a family Develop a model of a family
- 45. Possible Approaches Model-based Motif-based (MEME/MAST) Hidden Markov model-based (HMMER) Cobbling Cobbled FPS Non-model-based Family Pairwise Search (FPS)
- 46. PSSMs Motifs can be summarized and searched for using P osition- S pecific S coring M atrices Calculated from a multiple alignment of a conserved region for members of a family
- 47. Learning PSSMs However, unsupervised learning methods can be used to find motifs in unaligned sequences Best characterized algorithm is MEME T.L. Bailey & C. Elkan (1995) Unsupervised Learning of Multiple Motifs in Biopolymers Using Expectation Maximization. Machine Learning J. 21 :51-83 Program for searching with MEME-generated PSSM is called MAST
- 48. Position Specific Iterated BLAST (PSI-BLAST) Use PSSMs, instead of a similarity matrix, to score matches between query and database Iterate: using a multiple alignment of high scoring sequences found in each search round to generate a new PSSM for use in the next round of searching Search until no new sequences are found, or the user specified maximum number of iterations is reached, whichever comes first Very similar to MEME/MAST
- 49. Problems with PSSMs Some families are characterized by two or more “sub”-motifs with variable spacing between them Deciding upon motif boundaries difficult Possible information in intervening sequences lost if only motifs are used
- 50. Cobbling Pick “most representative” protein sequence from a family Convert it to a profile by replacing each amino acid by the corresponding column from a similarity matrix
- 51. Cobbling For each recognized “motif” in the family, replace the corresponding section of the profile with the profile of the motif
- 52. Cobbling Advantage: At least some sequence information between motifs is retained. S. Henikoff & J.G. Henikoff (1997) Embedding strategies for effective use of information from multiple sequence alignments. Protein Science 6 :698-705
- 53. Cobbler Illustration sequence of “most representative” family member scores from profiles of conserved motifs similarity scores for sequence from “most representative” family member
- 54. Family Pairwise Search For all known members of family, calculate (pairwise) homology to each sequence in database (using BLAST) and sum those scores
- 55. Family Pairwise Search Does not generate a model of the motif Analogous to k nearest neighbor classification
- 56. Which method is best? Compare BLAST using randomly chosen family member BLAST FPS MAST (uses MEME to build PSSM) HMMER W.N. Gundy (1998) Homology Detection via Family Pairwise Search. J. Comput. Biol. 5 :479-492
- 57. Comparison Protocol For each method For each known protein family Train with family members Search database for matches Rank by score from search Determine how many known family members are ranked highly
- 58. Evaluation Training Sequences Training Model Testing Sequences All other Sequences Known Family Members Searching Ranked List of Matches
- 59. Evaluation metric - ROC Define ROC n ROC n is the fraction of true positives detected at a threshold giving n false positives
- 60. Example of Evaluation for ROC 2 Assume 8 Known Family Members If Ranked List of Matches is: Known Family Member 1 Known Family Member 7 Known Family Member 4 Known Family Member 2 Other Sequence 1 Known Family Member 3 Known Family Member 8 Other Sequence 2 Known Family Member 5 Known Family Member 6 ROC 2 score is 0.75 (six of the eight scored higher than the second highest scoring non-member) Sequences up to 2 non-family members
- 61. Protocol for Comparison of Methods Calculate ROC 50 for each family Average over all families Bigger is better!
- 62. Results BLAST FPS HMMER MAST BLAST FPS MAST HMMER BLAST
- 63. Conclusion FPS better than single sequence BLAST FPS better than model-based methods
- 64. Comparison Protocol Caution! True positive defined as being listed as a member of the family in the PROSITE compilation Some false positives could be actual family members that were missed during PROSITE compilation! (Should be minor effect)
- 65. Which is best (part 2)? Compare BLAST BLAST FPS cobbled BLAST cobbled BLAST FPS W.N. Grundy and T.L. Bailey (1999) Family pairwise search with embedded motif models. Bioinformatics 15: 463-470
- 66. Comparison Protocol Evaluation metric rank sum calculate difference in ROC 50 for two methods for a given family sort by absolute value of difference sum ranks of families for which one method is better than the other Bigger is better!
- 67. Results
- 68. Conclusions For task of finding members of a family given a reasonable number of known members of that family, cobbled FPS is best of the methods tested! As number of known sequences in a family grows, HMM methods may do better
Editor's Notes
- #16: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #17: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #18: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #19: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #20: ISAC Tutorial - 5/17/08 - Copyright (c) 2008, R.F. Murphy
- #21: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #22: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #23: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #24: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #25: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #26: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #27: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #28: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #29: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #30: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #31: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #32: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #33: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #34: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #35: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy
- #38: Feature Calculation Lecture 3D IP workshop 2005 - R.F. Murphy