ConditionalPointDiffusion.pdf
0 likes773 views

2022/05/15に開催された、第10回全日本コンピュータビジョン勉強会「生成モデル縛り論文読み会」発表資料 https://kantocv.connpass.com/event/243586/




![Denoising Diffusion Probabilistic Model
5
画像生成のモデル
元画像に徐々にノイズを付与し、ランダムな画像を生成
上記の逆過程をたどることでランダムな画像からなんらかの
それっぽい画像を自動生成
[Ho, J., Jain,A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 2020-
December(NeurIPS 2020), 1–12.]より引用](https://image.slidesharecdn.com/conditionalpointdiffusion-220515044814-581417e2/95/ConditionalPointDiffusion-pdf-5-638.jpg)






































![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=560&fit=bounds)


![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=560&fit=bounds)






![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=560&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=560&fit=bounds)


![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=560&fit=bounds)



![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=560&fit=bounds)



![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=560&fit=bounds)

![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=560&fit=bounds)



Ad
More Related Content
What's hot (20)
Similar to ConditionalPointDiffusion.pdf (20)
![[CV勉強会]Active Object Localization with Deep Reinfocement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20160204objectdetectionrl-160206032348-thumbnail.jpg?width=560&fit=bounds)







![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=560&fit=bounds)









Ad
More from Takuya Minagawa (20)




















Ad
ConditionalPointDiffusion.pdf
- 1. 第10回全日本CV勉強会 生成モデル論文読み会 A Conditional Point Diffusion-Refinement Paradigm for 3D Point Cloud Completion 2022/05/15 takmin
- 2. 自己紹介 2 株式会社ビジョン&ITラボ 代表取締役 皆川 卓也(みながわ たくや) 博士(工学) 「コンピュータビジョン勉強会@関東」主催 株式会社フューチャースタンダード 技術顧問 略歴: 1999-2003年 日本HP(後にアジレント・テクノロジーへ分社)にて、ITエンジニアとしてシステム構築、プリ セールス、プロジェクトマネジメント、サポート等の業務に従事 2004-2009年 コンピュータビジョンを用いたシステム/アプリ/サービス開発等に従事 2007-2010年 慶應義塾大学大学院 後期博士課程にて、コンピュータビジョンを専攻 単位取得退学後、博士号取得(2014年) 2009年-現在 フリーランスとして、コンピュータビジョンのコンサル/研究/開発等に従事(2018年法人化) http://visitlab.jp
- 3. 紹介する論文 3 A Conditional Point Diffusion-Refinement Paradigm for 3D Point Cloud Completion Zhaoyang Lyu, Zhufeng Kong, Xudong Xu, Liang Pan, Dahua Lin ICLR2022 選んだ理由: 拡散モデル(Denoising Diffusion Probabilistic Model)を勉強し たかった 仕事でPoint Cloudに関わることが多いので、拡散モデルを使 用した論文の中でも点群を使用したものを船体
- 4. 拡散モデル (Denoising Diffusion Probabilistic Model) 4
- 5. Denoising Diffusion Probabilistic Model 5 画像生成のモデル 元画像に徐々にノイズを付与し、ランダムな画像を生成 上記の逆過程をたどることでランダムな画像からなんらかの それっぽい画像を自動生成 [Ho, J., Jain,A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 2020- December(NeurIPS 2020), 1–12.]より引用
- 6. Denoising Diffusion Probabilistic Model 6 𝑞 𝐱𝑡 𝐱𝑡−1 ≔ 𝒩 𝐱𝑡; 1 − 𝛽𝑡𝐱𝑡−1, 𝛽𝑡𝐈 Forward Diffusion Process 画像の各画素にガウスノイズを追加 Step毎にガウスノイズを付与 最終的にただ のガウスノイズ になる
- 7. Denoising Diffusion Probabilistic Model 7 𝑞 𝐱𝑡 𝐱𝑡−1 ≔ 𝒩 𝐱𝑡; 1 − 𝛽𝑡𝐱𝑡−1, 𝛽𝑡𝐈 Reverse Diffusion Process ただのガウス ノイズ Step毎にガウスノイズを除去 𝑝𝜃 𝐱𝑡−1 𝐱𝑡 ≔ 𝒩 𝐱𝑡−1; 𝝁𝜃 𝐱𝑡, 𝑡 , 𝚺𝜃 𝐱𝑡, 𝑡 𝛽𝑡が小さいとき逆拡散 過程もガウス分布
- 8. Denoising Diffusion Probabilistic Model 8 𝑞 𝐱𝑡 𝐱𝑡−1 ≔ 𝒩 𝐱𝑡; 1 − 𝛽𝑡𝐱𝑡−1, 𝛽𝑡𝐈 Reverse Diffusion Process 𝑝𝜃 𝐱𝑡−1 𝐱𝑡 ≔ 𝒩 𝐱𝑡−1; 𝝁𝜃 𝐱𝑡, 𝑡 , 𝚺𝜃 𝐱𝑡, 𝑡 𝛽𝑡が小さいとき逆拡散 過程もガウス分布 ・ ・ ・ 画像分布全体 顔画像分布
- 9. Denoising Diffusion Probabilistic Model 9 𝑞 𝐱𝑡 𝐱𝑡−1 ≔ 𝒩 𝐱𝑡; 1 − 𝛽𝑡𝐱𝑡−1, 𝛽𝑡𝐈 Reverse Diffusion Process 𝑝𝜃 𝐱𝑡−1 𝐱𝑡 ≔ 𝒩 𝐱𝑡−1; 𝝁𝜃 𝐱𝑡, 𝑡 , 𝚺𝜃 𝐱𝑡, 𝑡 𝛽𝑡が小さいとき逆拡散 過程もガウス分布 ・ ・ ・ 画像分布全体 顔画像分布
- 10. Denoising Diffusion Probabilistic Model 10 𝑞 𝐱𝑡 𝐱𝑡−1 ≔ 𝒩 𝐱𝑡; 1 − 𝛽𝑡𝐱𝑡−1, 𝛽𝑡𝐈 Reverse Diffusion Process 𝑝𝜃 𝐱𝑡−1 𝐱𝑡 ≔ 𝒩 𝐱𝑡−1; 𝝁𝜃 𝐱𝑡, 𝑡 , 𝚺𝜃 𝐱𝑡, 𝑡 𝛽𝑡が小さいとき逆拡散 過程もガウス分布 ・ ・ ・ 画像分布全体 顔画像分布 学習により求めたい
- 11. Denoising Diffusion Probabilistic Model 11 学習 元画像 ノイズ Neural Network ノイズ 画像 推定 ノイズ 二乗誤差 Back Prop 推論 Neural Network 入力画 像 推定 ノイズ ー ノイズ低 減画像 Step: t Step: t
- 12. 拡散モデルの導出 12 𝑞 𝐱0 : 元画像(ex.顔画像)の真の確率密度分布 𝑝𝜃 𝐱0 : 推定したい元画像の分布関数(𝜃:パラメータ) ・ ・ ・ 𝑞 𝐱𝒕 𝑞 𝐱0 𝑞 𝐱𝑇 max 𝜃 𝑖 log 𝑝𝜃 𝐱0 𝑖 学習画像 𝑝𝜃で𝑞をうまく表したい。 →対数尤度が最大となるパラメータ𝜃求めたい (1)
- 13. 拡散モデルの導出 13 ・ ・ ・ 𝑞 𝐱𝒕 𝑞 𝐱0 𝑞 𝐱𝑇 max 𝜃 𝑖 log 𝑝𝜃 𝐱0 𝑖 = min 𝜃 −𝔼𝑞(𝐱0) log 𝑝𝜃 𝐱0 学習画像の分布は𝑞 𝐱0 に従うので、 (2)
- 14. 拡散モデルの導出 14 ・ ・ ・ 𝑞 𝐱𝒕 𝑞 𝐱0 𝑞 𝐱𝑇 イェンセンの不等式を用いて下界が求まる 途中計算は省略 𝐱0:𝑇 ≔ 𝐱0, 𝐱1, … , 𝐱𝑇 −𝔼𝑞(𝐱0) log 𝑝𝜃 𝐱0 ≤ 𝔼𝑞(𝐱0:𝑇) log 𝑞 𝐱1:𝑇|𝐱0 𝑝𝜃 𝐱0:𝑇 こっちを最小化する (3)
- 15. 拡散モデルの導出 15 下界を式展開すると、3つの項に分解できる 𝐷𝐾𝐿: KLダイバージェンス (4) log 𝑞 𝐱1:𝑇|𝐱0 𝑝𝜃 𝐱0:𝑇 = 𝐷𝐾𝐿 𝑞 𝐱𝑇|𝐱0 ∥ 𝑝𝜃 𝐱0 + 𝑡=2 𝑇 𝐷𝐾𝐿 𝑞 𝐱𝑡−1|𝐱𝑡, 𝐱0 ∥ 𝑝𝜃 𝐱𝑡−1|𝐱𝑡 − log 𝑝𝜃 𝐱0|𝐱1 𝑳𝑇 :定数 𝑳0: 計算可能 𝑳𝑡−1: 最小化する ・ ・ ・ 𝑞 𝐱𝒕 𝑞 𝐱0 𝑞 𝐱𝑇
- 16. 拡散モデルの導出 16 𝐿𝑡−1は2つのガウス分布のKLダイバージェンス 𝐿𝑡−1 = 𝐷𝐾𝐿 𝑞 𝐱𝑡−1|𝐱𝑡, 𝐱0 ∥ 𝑝𝜃 𝐱𝑡−1|𝐱𝑡 𝐱0で条件付けることで 計算可能 ガウス分布: 𝒩 𝐱𝑡−1; 𝝁𝜃 𝐱𝑡, 𝑡 , 𝚺𝜃 𝐱𝑡, 𝑡 ガウス分布: 𝒩 𝐱𝑡−1; 𝝁 𝐱𝑡, 𝑡 , ෨ 𝛽𝑡𝐈 ・ ・ ・ 𝑞 𝐱𝒕 𝑞 𝐱0 𝑞 𝐱𝑇
- 17. 拡散モデルの導出 17 𝐿𝑡−1の最小化は𝑞と𝑝𝜃の平均の差を最小化 𝐿𝑡−1 = 𝐷𝐾𝐿 𝑞 𝐱𝑡−1|𝐱𝑡, 𝐱0 ∥ 𝑝𝜃 𝐱𝑡−1|𝐱𝑡 𝐱0で条件付けることで 計算可能 ガウス分布: 𝒩 𝐱𝑡−1; 𝝁𝜃 𝐱𝑡, 𝑡 , 𝚺𝜃 𝐱𝑡, 𝑡 ガウス分布: 𝒩 𝐱𝑡−1; 𝝁 𝐱𝑡, 𝑡 , ෨ 𝛽𝑡𝐈 𝚺𝜃 𝐱𝑡, 𝑡 = 𝜎𝑡 2 𝐈 = ෨ 𝛽𝑡𝐈 と単純化する 𝐿𝑡−1 = 𝔼𝒒 1 2𝜎𝑡 2 𝝁 𝐱𝑡, 𝑡 − 𝝁𝜃 𝐱𝑡, 𝑡 2 + 𝐶
- 18. 拡散モデルの導出 18 𝐿𝑡−1の最小化は𝐱𝑡と𝐱𝑡−1間のノイズを推定すること 𝐿𝑡−1 = 𝐷𝐾𝐿 𝑞 𝐱𝑡−1|𝐱𝑡, 𝐱0 ∥ 𝑝𝜃 𝐱𝑡−1|𝐱𝑡 𝐿𝑡 simple = 𝔼𝐱0,𝐳 𝐳𝑡 − 𝐳𝜃 𝐱𝑡, 𝑡 2 Step tで加 えたノイズ 推定した ノイズ = 𝔼𝒒 1 2𝜎𝑡 2 𝝁 𝐱𝑡, 𝑡 − 𝝁𝜃 𝐱𝑡, 𝑡 2 + 𝐶 𝝁, 𝝁𝜃を代入して計算
- 19. Denoising Diffusion Probabilistic Model 19 学習 元画像 ノイズ Neural Network ノイズ 画像 推定 ノイズ 二乗誤差 Back Prop 推論 Neural Network 入力画 像 推定 ノイズ ー ノイズ低 減画像 Step: t Step: t 𝐱0 𝐱𝑡 𝐳1:𝑡 𝐳𝜃
- 20. Denoising Diffusion Probabilistic Model 20 学習 元画像 ノイズ Neural Network ノイズ 画像 推定 ノイズ 二乗誤差 Back Prop 推論 Neural Network 入力画 像 推定 ノイズ ー ノイズ低 減画像 Step: t Step: t 𝐱0 𝐱𝑡 𝐳𝑡 𝐳𝜃 𝐱𝑡は 𝐱0にt回ガウスノイズを加えたものなので 𝐱𝑡 = ത 𝛼𝑡𝐱0 + 1 − ത 𝛼𝑡𝐳𝑡 とかける (ただし ത 𝛼𝑡 = σ𝑖=1 𝑡 (1 − 𝛽𝑖) )
- 21. Denoising Diffusion Probabilistic Model 21 学習 元画像 ノイズ Neural Network ノイズ 画像 推定 ノイズ 二乗誤差 Back Prop 推論 Neural Network 入力画 像 推定 ノイズ ー ノイズ低 減画像 Step: t Step: t 𝐱0 𝐱𝑡 𝐳𝑡 𝐳𝜃 𝐱𝑡 𝐱𝑡−1 𝐳𝜃
- 22. Denoising Diffusion Probabilistic Model 22 学習 元画像 ノイズ Neural Network ノイズ 画像 推定 ノイズ 二乗誤差 Back Prop 推論 Neural Network 入力画 像 推定 ノイズ ー ノイズ低 減画像 Step: t Step: t 𝐱0 𝐱𝑡 𝐳𝑡 𝐳𝜃 𝐱𝑡 𝐱𝑡−1 𝐳𝜃 𝐱𝑡−1 = 1 𝛼𝑡 𝐱𝑡 − 1 − 𝛼𝑡 1 − ത 𝛼𝑡 𝒛𝜽 + 𝜎𝑡𝒛 (ただし 𝛼𝑡 = 1 − 𝛽𝑖)
- 23. A Conditional Point Diffusion-Refinement Paradigm for 3D Point Cloud Completion 23
- 24. A Conditional Point Diffusion-Refinement Paradigm for 3D Point Cloud Completion 24 LiDAR等の測定では、オクルージョン等によりすべての 箇所の点群データが取れるわけではない。 拡散モデル用いてデータの取得できなかった箇所の点 群を生成する。 Coarse-to-Fineに点群生成 Conditional Generation Network (Coarse) Refinement Network (Fine)
- 25. Point Cloud Completion 25 生成された点群とGround Truthの比較(Loss)に、従来は Chamfer DistanceやEarth Mover Distanceが使用されて いた。 Chamfer Distance 点群全体の密度分布を捉えない 補間結果の質が一様でない Earth Mover Distance 計算が非常に重い Denoise Diffusion Probabilistic Model (DDPM) 一様で高品質な補間が行えるのではないか?
- 26. Conditional Point Diffusion-Refinement (PDR) Paradigm 26 1. Conditional Generation Network 拡散モデル(DDPM)によるCoarseな点群補間 各点の座標(x,y,z)にガウスノイズを付与 2. Refinement Network Coarseな点群の高品質化
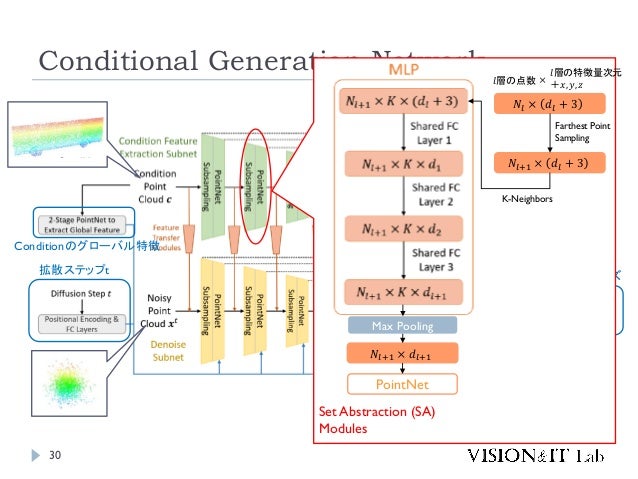
- 28. Conditional Generation Network 28 部分的な点群(Condition)から各段階の特徴量抽出 各Step tでのノイズを推定 PointNet++ like
- 29. Conditional Generation Network 29 各Step tでのノイズを推定 拡散ステップt Conditionのグローバル特徴 部分点群の各レベルの特徴を入力 推定ノイズ
- 30. Conditional Generation Network 30 拡散ステップt Conditionのグローバル特徴 推定ノイズ Set Abstraction (SA) Modules Max Pooling 𝑁𝑙+1 × 𝑑𝑙+1 PointNet 𝑁𝑙 × 𝑑𝑙 + 3 𝑁𝑙+1 × 𝑑𝑙 + 3 𝑙層の特徴量次元 +𝑥, 𝑦, 𝑧 𝑙層の点数 × Farthest Point Sampling K-Neighbors
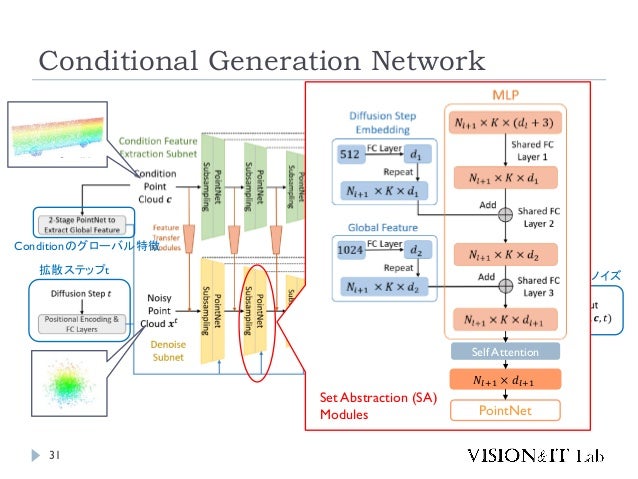
- 31. Conditional Generation Network 31 拡散ステップt Conditionのグローバル特徴 推定ノイズ Self Attention 𝑁𝑙+1 × 𝑑𝑙+1 PointNet Set Abstraction (SA) Modules
- 32. Conditional Generation Network 32 拡散ステップt Conditionのグローバル特徴 推定ノイズ Feature Propagation (FP) Modules 𝑁𝑙+1 × 𝑑′𝑙+1 + 3 PointNet Self Attention 𝑁𝑙 × 𝑑𝑙 𝑁𝑙 × 𝐾 × 𝑑′𝑙+1 + 3 MLP 𝑁𝑙 × 𝑑′𝑙 𝑁𝑙 × 3 Concatenate From Skip Connection K-Neighbors Upsampling 後の座標
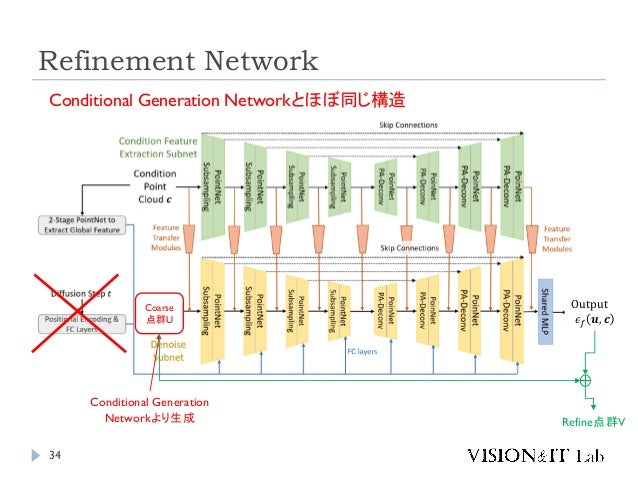
- 34. Refinement Network 34 Conditional Generation Networkとほぼ同じ構造 Coarse 点群U Conditional Generation Networkより生成 Output 𝜖𝑓 𝒖, 𝒄 Refine点群V
- 35. Refinement Network 35 学習 Chamfer Distance Loss 教師点群との距離 ℒCD 𝑽, 𝑿 = 1 𝑽 σ𝑣∈𝑽 min 𝑥∈𝑿 𝑣 − 𝑥 2 + 1 𝑿 σ𝑥∈𝑿 min 𝑣∈𝑽 𝑣 − 𝑥 2 𝑽: Refinement Networkの生成点群 𝑿: 教師データ 学習中はConditional Generation Networkのパラメータは固 定 出力𝜖𝑓 𝒖, 𝒄 の次元数を上げることで解像度を増やせる
- 36. Experiments 36 データセット MVP 62400訓練データ、41600テストデータ ShapeNetより生成 MVP-40 41600訓練データ、64160テストデータ 40カテゴリ ModelNet40より生成 Completion3D 28974訓練データ 1184テストデータ 8カテゴリ ShapeNetより生成
- 37. Experiments 37 評価指標 𝑽: Refinement Networkの生成点群 𝑿: 教師データ Chamfer Distance 点同士の距離を元にしたLoss ℒCD 𝑽, 𝑿 = 1 𝑽 σ𝑣∈𝑽 min 𝑥∈𝑿 𝑣 − 𝑥 2 + 1 𝑿 σ𝑥∈𝑿 min 𝑣∈𝑽 𝑣 − 𝑥 2 Earth Mover Distance 分布の最小移動量 ℒEMD 𝑽, 𝑿 = min 𝜙:𝑽⟷𝑿 σ𝑣∈𝑽 𝑣 − 𝜙 𝑣 2
- 38. Experiments 38 評価指標(続き) F1 Score RecallおよびPrecisionを加味した指標 ℒF1 = 2ℒ𝑃 𝜌 ℒ𝑅 𝜌 ℒ𝑃 𝜌 +ℒ𝑅 𝜌 ℒ𝑃 𝜌 = 1 𝑽 σ𝑣∈𝑽 min 𝑥∈𝑿 𝑣 − 𝑥 2 < 𝜌 ℒ𝑅 𝜌 = 1 𝑿 σ𝑥∈𝑿 min 𝑣∈𝑽 𝑣 − 𝑥 2 < 𝜌
- 41. Experiments 41 Ablation Study PA-Deonv & Att.: 本手法 PA-Deonv:Attentionを除いたもの PointNet++: さらにPA-Deonv moduleを除いたもの Concate 𝑥𝑡 & 𝑐: Ftmoduleを除いたもの Pointwise-net: 部分点群(Condition)から取得したグローバル特 徴のみ使用
- 42. Experiments 42
- 44. まとめ 44 拡散モデルを利用した点群補間方法を提案 Conditional Generation Networkで全体構造を推定し、 Refinement Networkで詳細化 他の手法と比較し、性能が大きく上回った Controllable Point Cloud Generationのような、そのほか の点群を使用したタスクにも応用可能
- 45. PointNet 45 Qi, C. R., Su, H., Mo, K., & Guibas, L. J. (2017). PointNet : Deep Learning on Point Sets for 3D Classification and Segmentation Big Data + Deep Representation Learning. IEEE Conference on ComputerVision and Pattern Recognition (CVPR). 各点群の点を独立に畳み込む Global Max Poolingで点群全体の特徴量を取得 各点を個別 に畳み込み アフィン変換 各点の特徴を統合
- 46. PointNet++ 46 Qi, C. R.,Yi, L., Su, H., & Guibas, L. J. (2017). PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. Conference on Neural Information Processing Systems (NIPS). PointNetを階層的に適用 点群をクラスタ分割→PointNet→クラスタ内で統合を繰り返す