Continuous Delivery: automated testing, continuous integration and continuous deployment.
22 likes2,412 views

Continuous Delivery: automated testing, continuous integration and continuous deployment.




































































More Related Content
What's hot (20)
Similar to Continuous Delivery: automated testing, continuous integration and continuous deployment. (20)


















More from Jimmy Lai (20)
![[PyCon US 2025] Scaling the Mountain_ A Framework for Tackling Large-Scale Te...](https://cdn.slidesharecdn.com/ss_thumbnails/pyconus2025scalingthemountainaframeworkfortacklinglarge-scaletechdebt-250517122757-38c6df76-thumbnail.jpg?width=560&fit=bounds)









![[LDSP] Solr Usage](https://cdn.slidesharecdn.com/ss_thumbnails/searchengineldspsolr-140127194826-phpapp02-thumbnail.jpg?width=560&fit=bounds)
![[LDSP] Search Engine Back End API Solution for Fast Prototyping](https://cdn.slidesharecdn.com/ss_thumbnails/searchengineldsp-140126193834-phpapp02-thumbnail.jpg?width=560&fit=bounds)








Continuous Delivery: automated testing, continuous integration and continuous deployment.
- 1. Continuous Delivery: automated testing, continuous integration and continuous deployment. 持續發佈:利⽤用⾃自動化測試與持續 集成來持續發佈⾼高品質的軟體 Jimmy Lai 2014.10.15 ! Jimmy Lai是⾃自然語⾔言處理與機器學習領域的 Python愛好者。 更多他的分享: http://www.slideshare.net/jimmy_lai/
- 2. Outline 1. 持續發佈的概念 2. 持續發佈的⼯工具 3. 以Python專案為範例建構部署流⽔水 線 2
- 3. Continuous Delivery 持續發佈 • 軟體發佈了才算做完了 • 只有commit程式碼還不算完成 • 提交程式碼到軟體發佈的過程必須完全⾃自動 化 • 可重複使⽤用的發佈與部署流程,以確保軟體 品質 • 程式碼與設定檔等產出必須要進⾏行版本控 制,以便快速的追蹤與回復 3
- 4. Version Control 版本控制 • 需要版本控制的項⺫⽬目 • 原始碼 • 套件相依管理 • 系統參數設定 • 主流⼯工具: Git 4
- 5. Continuous Integration 持續整合 • 在合作開發的團隊中,持續地將每個⼈人的變 更整合在⼀一起,越頻繁地整合就可以減少嚴 重的衝突發⽣生 • 要件: • 頻繁的commit原始碼 • ⾃自動化的測試 • 簡短的建置與測試週期,以及早獲得回饋 • 主流⼯工具: Jenkins 5
- 6. Testing 測試 • ⾃自動化測試 • 單元測試: 針對function/class • 功能測試: 針對客⼾戶端需求 • 系統整合測試: 針對⼦子系統的整合 • 效能與覆載測試 • 安全性測試 • ⼿手動測試 • 探索性測試、使⽤用者接受度測試 • Python測試⼯工具: nosetests 6
- 7. 部署流⽔水線 1. 建置與單元測試(當commit程式碼時) 2. ⾃自動化的功能測試 3. 使⽤用者接受度測試(測試⼯工程師) 4. 發佈 過程中有任何錯誤即⾃自動通知開發者, 開發者應優先修復部署流⽔水線後再繼續 開發新功能 7
- 8. Git版本控制 • 分散式版本控制 • 每⼀一台機器都有⼯工作⺫⽬目錄和版本資料 庫 • 每⼀一台機器的版本資料庫都可以與任 意機器同步 • 開發時先對本地資料庫進⾏行commit, 不需要網路連線 http://git-scm.com/ 8
- 9. Git實務 • ⼯工作⺫⽬目錄 <-> 暫存區 <-> 版本資料庫 • ⼯工作⺫⽬目錄為某個版本分⽀支的狀態加上新的修改 • git add: 將檔案當前的狀態加⼊入暫存區 • git commit -m “commit message”: 將⺫⽬目前暫存區 當中的所有檔案更改儲存到版本資料庫 • git push origin master: 將當前分⽀支的本機更新推送 到遠端(origin)版本資料庫的master分⽀支 • git pull origin master: 將遠端(origin)版本資料庫的 master分⽀支的更新下載到當前⼯工作⺫⽬目錄分⽀支 http://git-scm.com/docs/gittutorial 9
- 10. Git Code Review • 透過Github的code review來確保軟體品質: 1. git checkout -b branch: 在本地建⽴立分⽀支並切換到該分⽀支 2. git commit: 在本地分⽀支提交變更 3. git push origin branch_a: 將變更推送到Github 4. 在Github建⽴立pull request 5. Reviewer進⾏行審查 6. 審查修改完善後將branch merge回master • master branch⽤用來發佈軟體,新的修改都先在其他分⽀支 進⾏行,經過審查後才merge • Code Review有助於團隊成員互相學習並提⾼高程式碼品質 http://nvie.com/posts/a-successful-git-branching-model/ 10
- 11. Git Code Review Demo https://github.com/jimmylai/continuous_delivery_demo
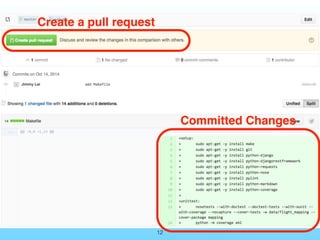
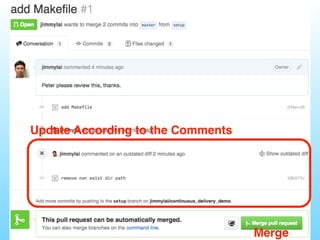
- 12. Git Code Review 範例 • 需求: 撰寫設定系統套件的Makefile, 並進⾏行Code Review • 步驟: 1. 於git建⽴立新分⽀支 2. 在新分⽀支提交修改 3. 更新到github後,建⽴立pull request 4. Review確認後merge 12
- 13. 13 Committed Changes Create a pull request
- 15. Post Review Message 15
- 16. Update According to the Comments 16 Merge
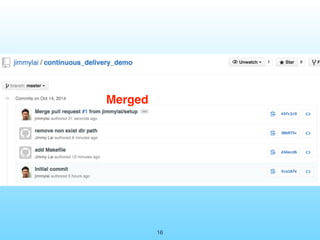
- 17. 17 Merged
- 18. 單元測試 • 單元測試: 對程式碼單元(funtion, class)進 ⾏行撰寫測試案例 • 被測試的程式碼必須要減少與其他程式碼 的相依性才容易測試,通常可以透過適當 的封裝函數來達成。必要時必須要利⽤用 Mock技術來隔離相依性,例如呼叫資料 庫連線、外部IO. • Python測試⼯工具nosetest 18
- 19. Unit Test with nosetests https://github.com/jimmylai/continuous_delivery_demo/tree/ master/web/calculator
- 20. Unit Test with nosetests範例 • 需求: 撰寫⼀一個函式,有兩個整數作為 參數,回傳兩個參數相加之和 • 步驟: 1. 撰寫函式 2. 利⽤用doctest做為說明及測試 3. 撰寫測試函數 20
- 21. Unit test with Nosetest doctest: 作為函式說明範例,也是單元測試 21
- 22. 將測試檔案以xxx_test.py命名, 測試函式以! test_xxx()命名, nosetests就會找出來執⾏行 22
- 23. 功能測試 • 針對客⼾戶端要求的功能進⾏行驗證,測試 的對象可能是由數個元件組成的系統 • 針對不同界⾯面的系統需要使⽤用不同的⽅方 式來測試,例如網⾴頁就必須以瀏覽器來 測試才完整 • 範例: 基於先前的add( ), 提供⼀一個⽤用來 進⾏行加法RESTful API, 針對輸⼊入進⾏行檢 查,計算後回傳結果 23
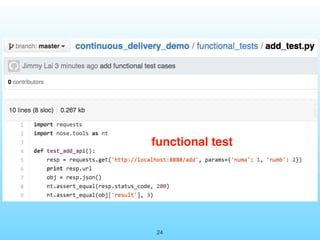
- 24. Functional Test of RESTful API https://github.com/jimmylai/continuous_delivery_demo/tree/ master/functional_tests
- 25. Functional Test of RESTful API 範例 • 需求: 實作⼀一個Restful API, 透過HTTP GET 輸⼊入兩個參數, 呼叫前⼀一範例的add( )進⾏行加 總, 以json格式回傳結果 • 步驟: 1. 使⽤用Django rest framework撰寫API 2. 驗證輸⼊入的兩個參數存在且為整數 3. 將運算結果回傳 4. 測試客⼾戶端送出HTTP GET request來 進⾏行測試 25
- 26. Django RESTful API - View 26
- 28. 28 start web server functional test test successfully
- 29. Jenkins • 廣受歡迎的持續整合軟體 • 根據設定的條件(如提交程式碼時、定 時排程)觸發建置,如建置發⽣生錯誤便 ⽴立即通知開發者,建置順利可繼續下⼀一 階段建制或⾃自動發佈 • 建置的結果報表以網⾴頁的⽅方式呈現 • 建置的過程與產出皆有存檔,⽅方便回溯 http://jenkins-ci.org/ 29
- 30. Unitest when Commits with Jenkins
- 31. Unitest when Commits with Jenkins範例 • 需求:透過Jenkins Job, 當有新的程式 碼被提交時, 便⾃自動運⾏行unit test, 輸出 測試結果報表 • 步驟: 1. 設定Jenkins Job與Github的授權 2. 設定當有新的change時, 由Github 觸發Jenkins 3. 設定測試結果報表資訊 31
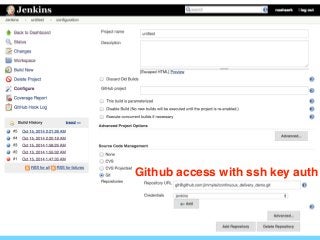
- 32. Github access with ssh key auth 32
- 33. Jenkins settings build when new changes come in Github settings 33
- 34. Unit test coverage Unit test report 34
- 35. 35
- 36. ⾃自動部署 • ⾃自動將建置好的軟體安裝與設定到不 同的環境,進⾏行後續的測試、交付產 品 • 不同的環境可能有不同的系統相依套 件、不同的設定 • 設定檔與部署程式都應進⾏行版本控制 36
- 37. Deploy after Unit Tests Success
- 38. Deploy after Unit Tests Success範例 • 需求: 使⽤用Apache作為Web server, 設 定Jenkins Job當unit test完成後, 發佈 到Apache Server • 步驟: 1. 準備Apache設定檔 2. 準備deploy scripts 3. 設定Jenkins job 38
- 39. Apache Config 39
- 40. Jenkins Setting 40 Deploy script
- 41. 部署流⽔水線 1. unittest: 由⼯工程師提交程式碼觸發 2. deploy 3. functional test 4. release, … 過程中有任何錯誤即⾃自動通知開發者, 開發者應優先修復部署流⽔水線後再繼續 開發新功能 41
- 42. 42
- 43. 43