


















![@SpringBootApplication
public class FacebookCloneServerApplication {
public static void main(String[] args) {
SpringApplication.run(FacebookCloneServerApplication.class, args);
}
}
FacebookCloneServerApplication
My preferred place to start when working on server code is the database. I might start with the webservice if I have an API in mind but I usually pick the database as it's
easier to quantify.
But before we go there we need to add some boilerplate. Assuming you created your app with the initializer you would have this class. If you don't have it then you need
this class as it's the entry point for your application.](https://image.slidesharecdn.com/creatingafacebookclone-partxvii-transcript-220804094217-ddbf9c6d/85/Creating-a-Facebook-Clone-Part-XVII-Transcript-pdf-20-320.jpg)



























































More Related Content
Similar to Creating a Facebook Clone - Part XVII - Transcript.pdf (20)
More from ShaiAlmog1 (20)


















Recently uploaded (20)




















Creating a Facebook Clone - Part XVII - Transcript.pdf
- 1. Creating a Facebook Clone - Part XVII Brace yourselves a bit. Server programming isn't as "exciting" as client side code. It includes lots of boilerplate code and some complex concepts. Please bare with me… Facebooks backend server logic is remarkably complex, what I built took roughly a day of work. Maybe a bit longer with debugging. I cut a lot of corners to get this working especially in the complex data driven aspects. Some features such as search will be discussed later.
- 2. © Codename One 2017 all rights reserved This seems like a lot to swallow but this architecture is remarkably simple once you start looking at it. We have 4 big pieces…
- 3. © Codename One 2017 all rights reserved WebServices - these are thin layers that provide a standard RESTful API. They are encapsulated in the RestController classes that expose the JSON web API
- 4. © Codename One 2017 all rights reserved Services - provide a generic implementation of the underlying logic so it isn't mixed with webservice specific adaptations. Service beans abstract the business logic and JPA from the webservice. This means in the future we can port everything to use something like websockets and reuse 100% of the code within the service classes
- 5. © Codename One 2017 all rights reserved DAO - Data transfer object are used to move data from the storage layer all the way to the client. Spring Boot can translate a DAO object to JSON in a response and create a DAO from JSON
- 6. © Codename One 2017 all rights reserved JPA Entities - We use JPA to access the database and query/write into it. This includes both the entities & the crud repositories. This architecture lets us mix and match pieces as we evolve. I chose to use WebServices for this app but tomorrow we could migrate the code to websockets and reuse most of the code as all the pieces from the services layer onward wouldn't need to change. The same is true for the database. Replacing mySQL should be trivial as JPA can work with any SQL database. However, you could go even further and replace the entire way data is stored e.g. with a NoSQL database or with direct SQL access. Since the data is hidden from the user this can be accomplished while leaving major portions of the code intact.
- 7. © Codename One 2017 all rights reserved To understand how this works lets review a small example of the new user creation logic.
- 8. © Codename One 2017 all rights reserved A request arrives to the server as a WebService
- 9. © Codename One 2017 all rights reserved It then passes between the layers. Initially the request comes in as a UserDAO object containing the attributes of the user. The response is a new `UserDAO` object that includes additional attributes specifically the user ID and security token.
- 10. © Codename One 2017 all rights reserved The response is a new UserDAO object that includes additional attributes specifically the user ID and security token.
- 11. Setup Spring Boot ✦JPA ✦Jersey ✦Security ✦Web-services ✦mySQL © Codename One 2017 all rights reserved I'm assuming you have mySQL installed and ready to use. So the next step is the new Spring Boot Project. We will need the following features from Spring Boot. JPA, Jersey, Security, Web-services & mySQL
- 12. <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http:// www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http:// maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.codename1.fbclone.server</groupId> <artifactId>FacebookCloneServer</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>FacebookCloneServer</name> <description>Server code for the facebook clone</description> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.0.1.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</ project.reporting.outputEncoding> pom.xml For completeness this is the pom.xml file dependency section. Notice I’m using Spring boot 2.
- 13. <artifactId>spring-boot-starter-parent</artifactId> <version>2.0.1.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</ project.reporting.outputEncoding> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jersey</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-security</artifactId> </dependency> <dependency> pom.xml We need JPA
- 14. <artifactId>spring-boot-starter-parent</artifactId> <version>2.0.1.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</ project.reporting.outputEncoding> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jersey</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-security</artifactId> </dependency> <dependency> pom.xml Jersey allows us to automatically marshal objects to-from JSON
- 18. <scope>runtime</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.security</groupId> <artifactId>spring-security-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>com.mashape.unirest</groupId> <artifactId>unirest-java</artifactId> <version>1.4.9</version> </dependency> <dependency> <groupId>com.twilio.sdk</groupId> <artifactId>twilio</artifactId> <version>7.17.0</version> </dependency> </dependencies> <build> <plugins> pom.xml We might as well add two additional dependencies. This is a simple REST API which we'll use to communicate with mailgun to send emails
- 19. </dependency> <dependency> <groupId>com.mashape.unirest</groupId> <artifactId>unirest-java</artifactId> <version>1.4.9</version> </dependency> <dependency> <groupId>com.twilio.sdk</groupId> <artifactId>twilio</artifactId> <version>7.17.0</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <fork>true</fork> </configuration> </plugin> </plugins> </build> </project> pom.xml Twilio allows us to send SMS messages for device activation. Now that all of that is in place lets proceed to the code.
- 20. @SpringBootApplication public class FacebookCloneServerApplication { public static void main(String[] args) { SpringApplication.run(FacebookCloneServerApplication.class, args); } } FacebookCloneServerApplication My preferred place to start when working on server code is the database. I might start with the webservice if I have an API in mind but I usually pick the database as it's easier to quantify. But before we go there we need to add some boilerplate. Assuming you created your app with the initializer you would have this class. If you don't have it then you need this class as it's the entry point for your application.
- 21. @Configuration public class SecurityConfiguration extends WebSecurityConfigurerAdapter { @Override protected void configure(HttpSecurity httpSecurity) throws Exception { httpSecurity.authorizeRequests().antMatchers("/").permitAll(); httpSecurity.csrf().disable(); } @Bean public PasswordEncoder passwordEncoder() { return new BCryptPasswordEncoder(); } } FacebookCloneServerApplication Next to it we can place the SecurityConfiguration class which handles basic security boilerplate as such. Here we disable some security protections in Spring Boot. These make sense for browser clients but not so much for native mobile clients where we might need to jump through hoops to get things working
- 22. @Configuration public class SecurityConfiguration extends WebSecurityConfigurerAdapter { @Override protected void configure(HttpSecurity httpSecurity) throws Exception { httpSecurity.authorizeRequests().antMatchers("/").permitAll(); httpSecurity.csrf().disable(); } @Bean public PasswordEncoder passwordEncoder() { return new BCryptPasswordEncoder(); } } FacebookCloneServerApplication This is the password encoder that we will use later to hash the user password
- 23. JPA Entities & DAO ✦I’m starting with JPA ✦Starting with User ✦UUID’s as Primary Keys ✦Primary Key Queries are FAST ✦Database migration would be easier © Codename One 2017 all rights reserved As I mentioned before, the best place to start a server implementation is the data structure. I will skip the database schema & instead discuss the object entities that we need & how they can serve us. The nice thing about JPA is that it can automatically create the schema for us which is really useful for fast prototyping. The most obvious object to start with is User. The User class is an entity that handles the data of a person using the app. Facebook obviously holds far more data over each user but this should be pretty simple to extend. Before I go into the code there is one concept I'd like to discuss first: unique ID’s aka primary keys. A very common concept in databases is the usage of an auto- increment unique id. This means a database would automatically generate a numeric primary key for us matching every user. This is a really cool but also problematic notion. If our ID's are numeric and sequential that means we can't really use them outside of the server. If we expose them to the outside world someone can just scan all our users numerically. A far better approach is a string based long random id which we can generate with the UUID API in Java. The chief value of using this as a primary key is performance. Since queries based on primary key are practically free it makes a lot of sense to expose the primary key to the client side. Another advantage is database flexibility. It would be possible to migrate to a different database type in the future if we use this approach. An autogenerating strategy can cause a problem as we try to move live data from one database to another
- 24. @Entity @Indexed public class User { @Id private String id; @Field private String firstName; @Field private String familyName; @Column(unique=true) private String email; @Column(unique=true) private String phone; private String gender; private String verificationCode; private String verifiedEmailAddress; private String verifiedPhone; User Now that we got that out of the way lets go to the code. You will notice that the User object in the server is very similar to the User object in the client. There are some differences but essentially they correlate to one another. We'll start with the field declarations. This is the Sting id as mentioned before, notice it lacks the auto-generate annotation you often see in JPA entities
- 25. @Entity @Indexed public class User { @Id private String id; @Field private String firstName; @Field private String familyName; @Column(unique=true) private String email; @Column(unique=true) private String phone; private String gender; private String verificationCode; private String verifiedEmailAddress; private String verifiedPhone; User Most of the other fields are simple persistent fields with the exception of email & phone where we demand uniqueness from the SQL database
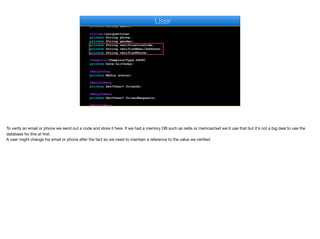
- 26. private String familyName; @Column(unique=true) private String email; @Column(unique=true) private String phone; private String gender; private String verificationCode; private String verifiedEmailAddress; private String verifiedPhone; @Temporal(TemporalType.DATE) private Date birthday; @ManyToOne private Media avatar; @ManyToMany private Set<User> friends; @ManyToMany private Set<User> friendRequests; @ManyToMany User To verify an email or phone we send out a code and store it here. If we had a memory DB such as redis or memcached we'd use that but it's not a big deal to use the database for this at first. A user might change his email or phone after the fact so we need to maintain a reference to the value we verified.
- 27. private String familyName; @Column(unique=true) private String email; @Column(unique=true) private String phone; private String gender; private String verificationCode; private String verifiedEmailAddress; private String verifiedPhone; @Temporal(TemporalType.DATE) private Date birthday; @ManyToOne private Media avatar; @ManyToMany private Set<User> friends; @ManyToMany private Set<User> friendRequests; @ManyToMany User Since dates in Java are technically timestamps we need to explicitly state the SQL data we need here
- 28. private String familyName; @Column(unique=true) private String email; @Column(unique=true) private String phone; private String gender; private String verificationCode; private String verifiedEmailAddress; private String verifiedPhone; @Temporal(TemporalType.DATE) private Date birthday; @ManyToOne private Media avatar; @ManyToMany private Set<User> friends; @ManyToMany private Set<User> friendRequests; @ManyToMany User We store Media files such as pictures in a separate Media entity, we'll discuss that entity soon
- 29. private Date birthday; @ManyToOne private Media avatar; @ManyToMany private Set<User> friends; @ManyToMany private Set<User> friendRequests; @ManyToMany private Set<User> peopleYouMayKnow; private String password; @Column(unique=true) private String authtoken; public User() { id = UUID.randomUUID().toString(); } public boolean isFriendById(String id) { return friends != null && friends.stream().anyMatch(f -> f.getId().equals(id)); } User We have 3 relations to other users for friend, friend requests & people you may know
- 30. private Date birthday; @ManyToOne private Media avatar; @ManyToMany private Set<User> friends; @ManyToMany private Set<User> friendRequests; @ManyToMany private Set<User> peopleYouMayKnow; private String password; @Column(unique=true) private String authtoken; public User() { id = UUID.randomUUID().toString(); } public boolean isFriendById(String id) { return friends != null && friends.stream().anyMatch(f -> f.getId().equals(id)); } User This field stores a hashed version of the password which is encrypted, it's never exposed to the user. Passwords in the database are hashed & salted. This is handled automatically by Spring as we'll see soon enough. Hashing is a form of encryption that only goes one way. E.g. if my password is xyz I can hash it and generate a value that looks completely random. I can't decrypt it ever again. However, if I know the password is xyz I can verify it against the hash. Salting means random data is inserted into the hash to make it even harder to break the hash.
- 31. private Date birthday; @ManyToOne private Media avatar; @ManyToMany private Set<User> friends; @ManyToMany private Set<User> friendRequests; @ManyToMany private Set<User> peopleYouMayKnow; private String password; @Column(unique=true) private String authtoken; public User() { id = UUID.randomUUID().toString(); } public boolean isFriendById(String id) { return friends != null && friends.stream().anyMatch(f -> f.getId().equals(id)); } User The token is a special field that allows us to edit a user. We expose it only to the logged in user and he can use that token to edit the data. We have a unique id for every user but we don't use it for write operations. Our ID is public knowledge so if a user needs to refer to my user object he'd use my unique id. This is efficient and accurate since id's never change (they are primary keys). When a user logs in we provide the token so only the user can update his own data. This means the password isn't stored on the device and a token can be updated/ revoked. It's also long enough and random enough which isn't always the case for passwords. Naturally tokens can't be primary keys... Since tokens might need resetting in case of a vulnerability and primary keys are forever. If I was super concerned about security to a paranoid level I'd encrypt the tokens in the database in the same way we encrypt the passwords. That would mean we would need to give a different token to every device (since hashing is a one way street). Naturally that's a pain to handle so I avoided it here.
- 32. private Set<User> peopleYouMayKnow; private String password; @Column(unique=true) private String authtoken; public User() { id = UUID.randomUUID().toString(); } public boolean isFriendById(String id) { return friends != null && friends.stream().anyMatch(f -> f.getId().equals(id)); } public boolean isFriendByToken(String token) { return friends != null && friends.stream().anyMatch(f->f.getAuthtoken().equals(token)); } public String fullName() { return firstName + " " + familyName; } private Long longBirthday() { User We initialize the primary key in the constructor, this will be overriden when loading from database but makes sure we have a unique ID when saving a new user
- 33. private Set<User> peopleYouMayKnow; private String password; @Column(unique=true) private String authtoken; public User() { id = UUID.randomUUID().toString(); } public boolean isFriendById(String id) { return friends != null && friends.stream().anyMatch(f -> f.getId().equals(id)); } public boolean isFriendByToken(String token) { return friends != null && friends.stream().anyMatch(f->f.getAuthtoken().equals(token)); } public String fullName() { return firstName + " " + familyName; } private Long longBirthday() { User These methods check the list of friends to see if a person with the given id or token is in our friend list, we'll use it later. Codename One on the client doesn't support Java 8 streams at this time. They help writing some complex ideas a bit more concisely but we find them hard to compile to efficient code for iOS. On the server this isn't a problem.
- 34. friends.stream().anyMatch(f -> f.getId().equals(id)); } public boolean isFriendByToken(String token) { return friends != null && friends.stream().anyMatch(f->f.getAuthtoken().equals(token)); } public String fullName() { return firstName + " " + familyName; } private Long longBirthday() { return (birthday == null) ? null : birthday.getTime(); } static List<UserDAO> toUserDAOList(Set<User> s) { if(s != null) { List<UserDAO> r = new ArrayList<>(); s.stream().forEach(f -> r.add(f.getDAO())); return r; } return null; } public UserDAO getDAO() { User s.stream().forEach(f -> r.add(f.getDAO())); for(User f : s) r.add(f.getDAO()); Here we have another case of a stream with a forEach method. This is pretty easy to explain with the block above, the stream code is roughly identical to the standard Java for loop. This method handles conversion of lists of users to list of UserDAO. This is a common practice as we get a lot of those.
- 35. friends.stream().anyMatch(f -> f.getId().equals(id)); } public boolean isFriendByToken(String token) { return friends != null && friends.stream().anyMatch(f->f.getAuthtoken().equals(token)); } public String fullName() { return firstName + " " + familyName; } private Long longBirthday() { return (birthday == null) ? null : birthday.getTime(); } static List<UserDAO> toUserDAOList(Set<User> s) { if(s != null) { List<UserDAO> r = new ArrayList<>(); s.stream().forEach(f -> r.add(f.getDAO())); return r; } return null; } public UserDAO getDAO() { User We'll use the full name a lot in the code so it makes sense to have this as a helper method
- 36. friends.stream().anyMatch(f -> f.getId().equals(id)); } public boolean isFriendByToken(String token) { return friends != null && friends.stream().anyMatch(f->f.getAuthtoken().equals(token)); } public String fullName() { return firstName + " " + familyName; } private Long longBirthday() { return (birthday == null) ? null : birthday.getTime(); } static List<UserDAO> toUserDAOList(Set<User> s) { if(s != null) { List<UserDAO> r = new ArrayList<>(); s.stream().forEach(f -> r.add(f.getDAO())); return r; } return null; } public UserDAO getDAO() { User The birthday can be null so we need to check before converting to a long value
- 37. return r; } return null; } public UserDAO getDAO() { return new UserDAO(id, firstName, familyName, email, phone, gender, longBirthday(), avatar == null ? null : avatar.getId()); } public UserDAO getLoginDAO() { UserDAO u = getDAO(); u.setAuthtoken(authtoken); u.setFriends(toUserDAOList(friends)); u.setFriendRequests(toUserDAOList(friendRequests)); u.setPeopleYouMayKnow(toUserDAOList(peopleYouMayKnow)); return u; } public String getId() { return id; } public void setId(String id) { this.id = id; } public String getFirstName() { User Here we create a DAO object matching this user. I’ll discuss the DAO in more detail soon but as you recall from before we use it to transfer data to the client. Notice that no private information is passed when the DAO is created, not even the friend list! No password, token etc.
- 38. return r; } return null; } public UserDAO getDAO() { return new UserDAO(id, firstName, familyName, email, phone, gender, longBirthday(), avatar == null ? null : avatar.getId()); } public UserDAO getLoginDAO() { UserDAO u = getDAO(); u.setAuthtoken(authtoken); u.setFriends(toUserDAOList(friends)); u.setFriendRequests(toUserDAOList(friendRequests)); u.setPeopleYouMayKnow(toUserDAOList(peopleYouMayKnow)); return u; } public String getId() { return id; } public void setId(String id) { this.id = id; } public String getFirstName() { User We pass the auth token here (but not the password) this method is invoked when a user logs in and returns to the user his own data
- 39. this.id = id; } public String getFirstName() { return firstName; } public void setFirstName(String firstName) { this.firstName = firstName; } public String getFamilyName() { return familyName; } public void setFamilyName(String familyName) { this.familyName = familyName; } public String getEmail() { return email; } public void setEmail(String email) { this.email = email; } public String getPhone() { return phone; } public void setPhone(String phone) { this.phone = phone; } User Looking over the rest of the code you will notice
- 40. } public void setPhone(String phone) { this.phone = phone; } public String getGender() { return gender; } public void setGender(String gender) { this.gender = gender; } public Date getBirthday() { return birthday; } public void setBirthday(Date birthday) { this.birthday = birthday; } public Media getAvatar() { return avatar; } public void setAvatar(Media avatar) { this.avatar = avatar; } public Set<User> getFriends() { return friends; } User That the rest is just a lot of boilerplate setters & getters
- 41. } public Set<User> getFriends() { return friends; } public void setFriends(Set<User> friends) { this.friends = friends; } public Set<User> getFriendRequests() { return friendRequests; } public void setFriendRequests(Set<User> friendRequests) { this.friendRequests = friendRequests; } public Set<User> getPeopleYouMayKnow() { return peopleYouMayKnow; } public void setPeopleYouMayKnow(Set<User> peopleYouMayKnow) { this.peopleYouMayKnow = peopleYouMayKnow; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } public String getAuthtoken() { User There is nothing interesting here
- 42. public void setPassword(String password) { this.password = password; } public String getAuthtoken() { return authtoken; } public void setAuthtoken(String authtoken) { this.authtoken = authtoken; } public String getVerificationCode() { return verificationCode; } public void setVerificationCode(String verificationCode) { this.verificationCode = verificationCode; } public String getVerifiedEmailAddress() { return verifiedEmailAddress; } public void setVerifiedEmailAddress(String verifiedEmailAddress) { this.verifiedEmailAddress = verifiedEmailAddress; } public String getVerifiedPhone() { return verifiedPhone; } public void setVerifiedPhone(String verifiedPhone) { User But we need this for JPA to function properly
- 43. return authtoken; } public void setAuthtoken(String authtoken) { this.authtoken = authtoken; } public String getVerificationCode() { return verificationCode; } public void setVerificationCode(String verificationCode) { this.verificationCode = verificationCode; } public String getVerifiedEmailAddress() { return verifiedEmailAddress; } public void setVerifiedEmailAddress(String verifiedEmailAddress) { this.verifiedEmailAddress = verifiedEmailAddress; } public String getVerifiedPhone() { return verifiedPhone; } public void setVerifiedPhone(String verifiedPhone) { this.verifiedPhone = verifiedPhone; } } User These setters and getters are made through IDE refactoring so I didn't write them.
- 44. public class UserDAO { private String id; private String firstName; private String familyName; private String email; private String phone; private String gender; private Long birthday; private String avatar; private List<UserDAO> friends; private List<UserDAO> friendRequests; private List<UserDAO> peopleYouMayKnow; private String password; private String authtoken; public UserDAO() { } public UserDAO(String id, String firstName, String familyName, String email, String phone, String gender, Long birthday, String avatar) { this.id = id; this.firstName = firstName; this.familyName = familyName; UserDAO Before we move to the methods I'd like to discuss the concept of a DAO. DAO stands for Data Access Object. This is a conceptual idea, there is no DAO API or requirement. You can skip it entirely! However, it's a very common "best practice" when working with backend systems. E.g. in our application we have 3 layers: * WebServices - the user facing code * Service - the backend logic * Entities/JPA - the database The roles are clearly separate, that's important as it means we can replace or change one layer significantly without impacting the others. E.g. we can move to websockets replacing the WebServices layer or we can move to a NoSQL DB and throw away the entity layer. So how do we transfer data between the layers while keeping them logically separate? Enter the DAO objects, they aren't entities. Entities are too close to the data and are hard to modify. DAO's are in place simply to pass along the data. The cool part about DAO's is that Spring Boot can automatically convert them to JSON when sending a response from the webservice and automatically create a new instance from JSON when receiving a call. We could just pass the entity itself but that would break the separation of layers and might inadvertently expose private data to the client side! So for the User object we have a similar UserDAO equivalent. The fields are almost identical to the fields of the User object
- 45. public class UserDAO { private String id; private String firstName; private String familyName; private String email; private String phone; private String gender; private Long birthday; private String avatar; private List<UserDAO> friends; private List<UserDAO> friendRequests; private List<UserDAO> peopleYouMayKnow; private String password; private String authtoken; public UserDAO() { } public UserDAO(String id, String firstName, String familyName, String email, String phone, String gender, Long birthday, String avatar) { this.id = id; this.firstName = firstName; this.familyName = familyName; UserDAO You will notice that even the relations are DAO objects
- 46. public class UserDAO { private String id; private String firstName; private String familyName; private String email; private String phone; private String gender; private Long birthday; private String avatar; private List<UserDAO> friends; private List<UserDAO> friendRequests; private List<UserDAO> peopleYouMayKnow; private String password; private String authtoken; public UserDAO() { } public UserDAO(String id, String firstName, String familyName, String email, String phone, String gender, Long birthday, String avatar) { this.id = id; this.firstName = firstName; this.familyName = familyName; UserDAO Notice that the class includes private data such as password and auth! As you might recall from the User object we never pass the password into the DAO and it’s hashed anyway. So why do we need the password in the DAO? When the user is created or updated the password value can be set. The DAO is sent from the client side too and that value may come from there. The token is returned in the DAO once after login or create.
- 47. private List<UserDAO> friendRequests; private List<UserDAO> peopleYouMayKnow; private String password; private String authtoken; public UserDAO() { } public UserDAO(String id, String firstName, String familyName, String email, String phone, String gender, Long birthday, String avatar) { this.id = id; this.firstName = firstName; this.familyName = familyName; this.email = email; this.phone = phone; this.gender = gender; this.birthday = birthday; this.avatar = avatar; } public String getId() { return id; } public void setId(String id) { this.id = id; } public String getFirstName() { UserDAO The DAO must include a no-arg constructor so it can be instantiated by Spring Boot. We also have a convenience constructor for our use.
- 48. public List<UserDAO> getFriendRequests() { return friendRequests; } public void setFriendRequests(List<UserDAO> friendRequests) { this.friendRequests = friendRequests; } public List<UserDAO> getPeopleYouMayKnow() { return peopleYouMayKnow; } public void setPeopleYouMayKnow(List<UserDAO> peopleYouMayKnow) { this.peopleYouMayKnow = peopleYouMayKnow; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } public String getAuthtoken() { return authtoken; } public void setAuthtoken(String authtoken) { this.authtoken = authtoken; } } UserDAO The rest of the code is all automatically generated getters and setters…
- 49. public interface UserRepository extends CrudRepository<User, String> { public List<User> findByPhone(String phone); public List<User> findByEmailIgnoreCase(String email); public List<User> findByAuthtoken(String authtoken); } UserRepository The one last missing piece for the User object is the UserRepository interface which allows us to query the user objects. The implementation for these queries is generated automatically by Spring Boot based on the names of the JPA fields
- 50. public interface UserRepository extends CrudRepository<User, String> { public List<User> findByPhone(String phone); public List<User> findByEmailIgnoreCase(String email); public List<User> findByAuthtoken(String authtoken); } UserRepository IgnoreCase is a special keyword for Spring which works exactly as one would think. With that we have the first entity in the data area and a basic Spring Boot server.