Practical C++ Generative Programming
4 likes4,695 views

Presentation done at the historic 20 yeras of C++ conference in Las Vegas 2005. This is also the first time I ever spoke on the topic of combing generative programming and C++ template metaprogramming











































































Ad
More Related Content
Viewers also liked (20)
Similar to Practical C++ Generative Programming (20)


















Ad
More from Schalk Cronjé (20)




















Ad
Recently uploaded (20)




















Practical C++ Generative Programming
- 1. Practical Generative Programming Schalk W. Cronjé [email protected]
- 2. Even in this new millennium, many engineers will still build components that have very little reuse potential due to the inflexible way that they were constructed. This leads to excessive time required to adapt a component for usage in another system.
- 3. Welcome to the world of Generative Programming
- 4. Themes • GP 101 • Building a team • Building a single system • Technical footwork • Building multiple systems • Integration & maintenance
- 5. Definition It is a software engineering paradigm where the aim is to automatically manufacture highly customised and optimised intermediate or end- products from elementary, reusable components by means of configuration knowledge.
- 6. Automatic programming • Generative programming is not automatic programming. • AP aims for highest level of automation • GP acknowledges that there are potentialy different levels of automation possible in a complete system. • AP usually involves some form of AI and high amounts of domain knowledge. • GP provides practical leverage of state-of-the art software engineering practices.
- 7. Elements of Generative Programming Problem space Solution space Configuration Knowledge •Illegal feature combinations •Default settings & dependencies •Construction rules •Optimisations •Configured Components •Domain-specific concepts •Features
- 8. Benefits • Economies of scope ● Less time and effort to produce variety of products • Software quality improvement ● Reuse of proven components • Scalability ● Can be applied to parts of a system or to whole systems • Optimisation at domain level ● Maximal combinability ● Minimal redundancy ● Maximum reuse
- 9. Steps • Domain scoping • Feature & concept modelling • Common architecture design and implementation technology identification • Domain-specific notations • Specify configuration knowledge (metadata) • Implement generic components • Apply configuration knowledge using generators There is no specific order to these steps !
- 10. Configuration Knowledge vs Metadata • Configuration knowledge is the term preferred by Czarnecki & Eisenecker • Configuration knowledge can be considered the holistic encapsulation of all knowledge related to building all variants • Metadata is probably a more codified form of configuration knowledge. • Some people find the term metadata easier to grasp and less confusing than configuration knowledge • The rest of this presentation uses the term metadata
- 11. Introducing GP into theProcess • Start small ! ● Use a pilot project or a small subset of an existing system ● Experiential learning is important – learn to learn. • Take an iterative and incremental approach to the different GP steps. • Don't worry too much about modelling up-front.
- 12. Building a Team • Domain experts ● Require the ability to codify configuration knowledge into a reusable form. • Language experts ● Converting configuration knowledge in to programming language representation. • Guiding light ● One person whom understands GP well, ensures that the development process stays on track and not descend into maintenance hell.
- 13. Strategies for C++ • Templates are the C++ way to generic programming • Develop elementary components as generic components ● Fully testable outside of the intended product configuration • Configure these components using generated traits / policy classes • Aim for zero cyclomatic-complexity in the generated classes
- 14. Template Metaprogramming • MPL is a key technology to build generic components ● Best example is Boost C++ MPL • MPL has been suggested as a domain-specific language ● Metadata difficult to review to someone not familiar with MPL • MPL should rather be used as implementation strategy
- 15. Example #1: Configuration system Name: NetworkPort Description: Unrestricted port on which a service can be started Type: uint16 Minimum Value: 1024 Maximum Value: 65535
- 16. Example #1: Configuration system template <typename CfgAttr> typename CfgAttr::value_type get_config(); std::cout << “The network port we'll use is “ << get_config<NetworkPort>();
- 17. Example #1: A traits class struct NetworkPort { typedef uint16_t value_type; static const value_type const_min = 1024; static const value_type const_max = 65535; // ... rest to follow };
- 18. Example #1: Alternative traits Because other non-integral types cannot be initialised inline, it might be more practical to use the following alternative. struct NetworkPort { typedef uint16_t value_type; static value_type min_value() {return 1024;} static value_type max_value() {return 65535;} // ... rest to follow };
- 19. Example #1: Basic generic function std::string get_cfg_string( const char* name ); template <typename CfgAttr> typename CfgAttr::value_type get_config() { // Calls a basic configuration interface function std::string tmp=get_cfg_string( CfgAttr::name() ); // Converts to appropriate type, throws exception // on conversion failure return boost::lexical_cast<typename CfgAttr::value_type>(tmp); }
- 20. Introducing run-time safety • In order to protect the system against external invalid data we need to add boundary checks. ● Use min_values(), max_value() from traits ● Add a default_value() to handle missing data • Additional features could include: ● Throwing an exception, instead of defaulting, when data is missing.
- 21. Example #1: Extending the function template <typename CfgAttr> typename CfgAttr::value_type get_config() { std::string tmp=get_cfg_string( CfgAttr::name() ); if(tmp.empty()) return CfgAttr::default_value(); else { typedef typename CfgAttr::value_type vtype; vtype ret= boost::lexical_cast<vtype>(tmp); return CfgAttr::bounded(ret); } }
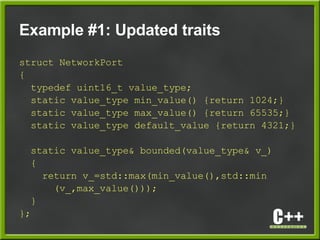
- 22. Example #1: Updated traits struct NetworkPort { typedef uint16_t value_type; static value_type min_value() {return 1024;} static value_type max_value() {return 65535;} static value_type default_value {return 4321;} static value_type& bounded(value_type& v_) { return v_=std::max(min_value(),std::min (v_,max_value())); } };
- 23. Capturing Configuration Knowledge • Various methods have been used for codifying metadata ● Text files ● Graphical Tools ● CASE Tools • XML is a very convenient form for new projects ● Semi-human readable ● Text – Unrestricted source-control ● Easy to transform to other formats • Includes non-code artefacts ● Custom editor can be created in Python or Java
- 24. Example #1: Configuration system <ConfigSystem> <Attr name=”NetworkPort” adt=”uint16”> <Description>Unrestricted port on which a service can be started</Description> <Min>1024</Min> <Max>65535</Max> <Default>4321</Default> </Attr> </ConfigSystem>
- 25. Prefer ADTs • Use abstract data types (ADTs) • Use a XML lookup table to go from ADT to C++ type • Underlying C++ representation can be changed without changing any of the metadata
- 26. Example #1: Simple Generator <xsl:template match="Attr"> struct <xsl:value-of select="@name"/> { typedef <xsl:apply-template select="." mode="adt"/> value_type; static const char* name() {return "<xsl:value- of select="@name"/>";} static value_type min_value() {return <xsl:value-of select="Min/text()"/>;} static value_type max_value() {return <xsl:value-of select="Max/text()"/>;} static value_type default_value() {return <xsl:value-of select="Default/text()"/>;} }; </xsl:template>
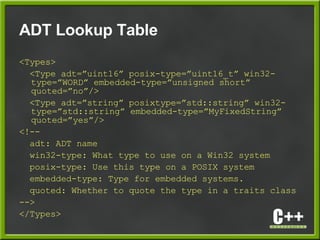
- 27. ADT Lookup Table <Types> <Type adt=”uint16” posix-type=”uint16_t” win32- type=”WORD” embedded-type=”unsigned short” quoted=”no”/> <Type adt=”string” posixtype=”std::string” win32- type=”std::string” embedded-type=”MyFixedString” quoted=”yes”/> <!-- adt: ADT name win32-type: What type to use on a Win32 system posix-type: Use this type on a POSIX system embedded-type: Type for embedded systems. quoted: Whether to quote the type in a traits class --> </Types>
- 28. Example #2 • Logging is an aspect of most systems that crosscuts the architecture. • There might be many requirements in your system, on how logging and reporting is used. ● Loggable entities ● Levels of logging ● User display issues ● Localisation • From a C++ point-of-view one important feature is how logging is generated at logging points • Using a GP approach it is possible to introduce compile-time validation
- 29. Example #2: Legacy Logging #define MINOR_FAILURE 1 #define MAJOR_PROBLEM 2 #define GENERAL_PANIC 3 void log_it( int id, const char* text ); // and then some smartie comes along log_it( MINOR_PROBLEM|GENERAL_PANIC, ”Voila!! An unsupported error” );
- 30. Example #2: Logging Metadata <Logging> <Report id=”1” name=”MINOR_FAILURE”> <Text>The projector's bulb needs replacing</Text> </Report> <Report id=”2” name=”MAJOR_PROBLEM”> <Text>We're out of Belgium beer</Text> </Report> <Report id=”3” name=”GENERAL_PANIC”> <Text>Elvis has left the building</Text> </Report> </Logging>
- 31. Example #2: Logging Function template <typename Report> void log_it( Report const&, const char* text ); log_it( 3,”My code” ); // compile error log_it( MAJOR_PROBLEM, “Out of German beer too” ); log_it( MINOR_FAILURE|MAJOR_PROBLEM, “No way” ); // Compile error
- 32. Example #2: Logging ID Class // Define type class Reportable { public: Reportable( unsigned id_ ); unsigned id() const; }; // then do either, initialising MINOR_FAILURE in .cpp extern const Reportable MINOR_FAILURE; // or namespace { const Reportable MINOR_FAILURE = Reportable(1); }
- 33. Preventing Code-bloat • Only instantiate what is needed ● For constant objects this is very easy using the MPL- value idiom • Due to ways some linkers work, concrete code might be included in a final link even if the code is not used, therefore only generate what is needed ● Control the config elements available to a specific system from metadata ● Only generate the appropriate traits classes • Cleanly separate common concrete class into a mixin class
- 34. The MPL-value idiom template <int V> class A { public: static const A<V> value; private: A(); }; template <int V> static const A<V> A<V>::value;
- 35. Logging Reworked template <unsigned id_> class Reportable { public: unsigned id() const {return id_;} static const Reportable<id_> value; }; const Reportable<id_> Reportable<id_>::value; typedef Reportable<1> MINOR_FAILURE; log_it( MINOR_PROBLEM::value,”Only instantiated when used”);
- 36. Adding logging actions • A user might want to specify that some reports can have certain associated actions. • For the logging example we might have ● GO_BUY ● MAKE_ANNOUNCEMENT ● CALL_SECURITY. • As this is configuration knowledge we can add this to the metadata and then generate appropriate metacode.
- 37. Example #2: Logging Metadata <Logging> <Report id=”1” name=”MINOR_FAILURE”> <Action>GO_BUY</Action> </Report> <Report id=”2” name=”MAJOR_PROBLEM”> <Action>GO_BUY</Action> <Action>MAKE_ANNOUNCEMENT</Action> </Report> <Report id=”3” name=”GENERAL_PANIC”> <Action>CALL_SECURITY</Action> <Action>MAKE_ANNOUNCEMENT</Action> </Report> </Logging>
- 38. Using MPL as glue template <unsigned id_,typename actions_list> class Reportable { public: unsigned id() const {return id_;} static const Reportable<id_> value; typedef actions_list valid_actions; }; // Generated code typedef Reportable<2, boost::mpl::vector<GO_BUY,MAKE_ANNOUNCEMENT> > MAJOR_PROBLEM;
- 39. Using SFINAE as validator template <typename Report,typename Action> void log_it( const char* text, boost::enable_if< boost::mpl::contains< typename Report::valid_actions, Action >::type::value >*_= 0); // Fails to compile log_it<GENERAL_PROBLEM>( GO_BUY,”Bought Elvis beer”); // OK, log_it<MAJOR_PROBLEM>( GO_BUY, ”Imported some Hoegaarden”);
- 40. Multiple Systems • Examples until now have shown the GP steps for a configuration system and a logging system. • The next step is to apply these to three systems: ● System 1 uses XML files for configuration and sends logs to syslog. ● System2 uses INI files, and sends logs to NT Evlog ● System 3 keeps configuration in a binary format (read- only) and sends logs via SNMP.
- 41. Example Product Metadata <Products> <System id=”1”> <Config type=”xml”/> <Logging type=”syslog”/> <Functionality> ... <Functionality> </System> <System id=”2”> <Config type=”ini”/> <Logging type=”ntevlog”/> <Functionality> ... <Functionality> </System> </Products>
- 42. Building Multiple Systems • Four generators can be applied to this product metadata. ● Two of them we have already seen ● These will generate configurations and logging aspects • Another generator looks at logging and configurations and adds the appropriate subsystems. • A fourth generator looks at the functionality and loads up all of the functional classes for the system ● A creative exercise for the reader …
- 43. Testing • Can tests be generated? ● There have been various argument around this topic. • Validate metadata independently • Test data can be generated from metadata • DO NOT generate unit tests to validate that the generated code is correct! ● How can you verify that the generated tests is correct?
- 44. Maintenance • Long-tem maintenance requires upfront investment in building quality generic components • Metadata might have to refactored into smaller XML files or a tools should be developed to edit the metadata. • Refactoring components into more generic components over time means that you will be able to configure and customise products even more.
- 45. Integration • Many modern systems are multi-language / multi-platform • These techniques extend easily into other programming languages / development environments • The same configuration knowledge remains the driver • Localisation data can be generated in various formats • Parts of technical documents can also be generated.
- 46. Further Reading • www.program-transformation.org • www.generative-programming.org • www.research.microsoft.com
- 47. In this new millennium, engineers can build high- quality proven generic components with high reuse potential and adaptively configure them. This leads to decreased time required to use a component in another domain and an increase in the variety of products that can be assembled. Did anyone mention competitive edge?