Data Applied:Outliers
1 like•169 views

This document describes an algorithm for detecting outliers in a database. It differs from conventional outlier detection algorithms by having an improved running time. The pseudo code provided outlines the steps: it takes a dataset, calculates the k nearest neighbors of each point, and returns the top n outliers based on a score comparing points to their nearest neighbors, improving on a basic nested loop approach. The document then briefly mentions how outliers can be detected using an online tool from Data-Applied.com.







Data Applied:Outliers
- 2. IntroductionOutliers are examples in a database with unusual propertiesThey can produce erroneous results and hence should be removedThe algorithm we will define, differs from a conventional nested loop outlier detection algorithm by an improved running time
- 3. Pseudo codeProcedure: Find OutliersInput: k, the number of nearest neighbours; n, the number of outliers to return; D, a set of examples in random order.Output: O, a set of outliers.Let maxdist(x, Y ) return the maximum distance between x and an example in Y .Let Closest(x, Y , k) return the k closest examples in Y to x.begin1. c <- 0 // set the cut off for pruning to 02. O <- Null // initialize to the empty set3. while B<- get-next-block(D) {// load a block of examples from D4. Neighbours(b) <- NULL for all b in B
- 4. Pseudo code (contd.)5. for each d in D {6. for each b in B, b != d { 7. if |Neighbours(b)| < k or distance(b, d) < maxdist(b, Neighbours(b)) { 8. Neighbours(b) <- Closest(b, Neighbours(b) U d, k)9. if score(Neighbours(b),b) < c {10. remove b from B11. }}}}12. O <- Top(B U O, n) // keep only the top n outliers13. c <- min(score(o)) for all o in O // the cutoff is the score of the weakest outlier14. }15. return Oend
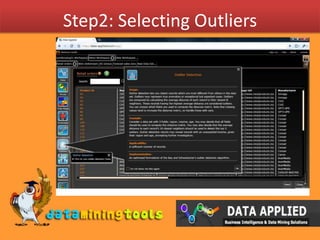
- 5. Outliers using Data Applied’s web interface
- 6. Step1: Selection of data
- 9. Visit more self help tutorialsPick a tutorial of your choice and browse through it at your own pace.
- 10. The tutorials section is free, self-guiding and will not involve any additional support.
- 11. Visit us at www.dataminingtools.net